- Системы искусственного интеллекта

Содержание
- 2. План лекции Линейная регрессия со множеством переменных Метод градиентного спуска для нескольких переменных. Масштабирование признаков. Выбор
- 3. Линейная регрессия с одной переменной Тренировочное множество данных (скажем, всего m) Обозначения: m = число обучающих
- 4. Линейная регрессия с одной переменной Тренировочное множество данных (скажем, всего m) Обозначения: m = число тренировочных
- 5. Линейная регрессия со множеством переменных Тренировочное множество данных (скажем, всего m) Обозначения: n = число свойств/признаков/дескрипторов
- 6. Обозначения: n = число свойств/признаков/дескрипторов x(i) = «вход»/свойства i-го тренировочного примера (x(i), y(i)) xj(i) = j-е
- 7. Градиентный спуск для линейной регрессии со множеством переменных repeat until convergence { } (j = 0,
- 8. Градиентный спуск на практике! Масштабирование признаков Идея: привести все свойства к одному и тому же масштабу
- 9. Нормализация на математическое ожидание Идея: замена xj на, xj – μj с целью создания у свойств
- 10. Градиентный спуск на практике! 10 Отладка. Как убедиться в том, что градиентный спуск работает корректно? J(Q)
- 11. Полиномиальная регрессия 11 Предскажем цену на дом с использованием следующей гипотезы: hQ(x) = QTx = Q0
- 12. Полиномиальная регрессия 12 Полиномиальная регрессия – это тот инструмент, который близко связан с выбором новых свойств
- 13. Аналитическое решение 13 Метод аналитического поиска параметров Q Рассмотрим стоимостную функцию J(Q) Вычислим частные производные J(Q)
- 14. Нормальные уравнения Тренировочное множество данных (скажем, всего m = 4) 14 Масштабирование свойств не нужно! 2019,
- 15. 15 Когда, что лучше использовать? Пусть есть m тренировочных примеров и n свойств Градиентный спуск Необходим
- 16. Классификация. Примеры Классификация (предсказание дискретной выходной величины, например, 0 или 1) Примеры задач классификации Электронная почта
- 17. Классификация Размер опухоли Злокачественная опухоль? 0 (N) 1 (P) 17 Рак молочной железы (злокачественный или доброкачественный)
- 18. Классификация Размер опухоли Злокачественная опухоль? 0 (N) 1 (P) 18 Рак молочной железы (злокачественный или доброкачественный)
- 19. Классификация Размер опухоли Злокачественная опухоль? 0 (N) 1 (P) 19 Рак молочной железы (злокачественный или доброкачественный)
- 20. Классификация Размер опухоли Злокачественная опухоль? 0 (N) 1 (P) 20 Рак молочной железы (злокачественный или доброкачественный)
- 21. Классификация 21 Проблемы классификации на основе линейной регрессии с одной переменной Выход (y) задачи бинарной классификации
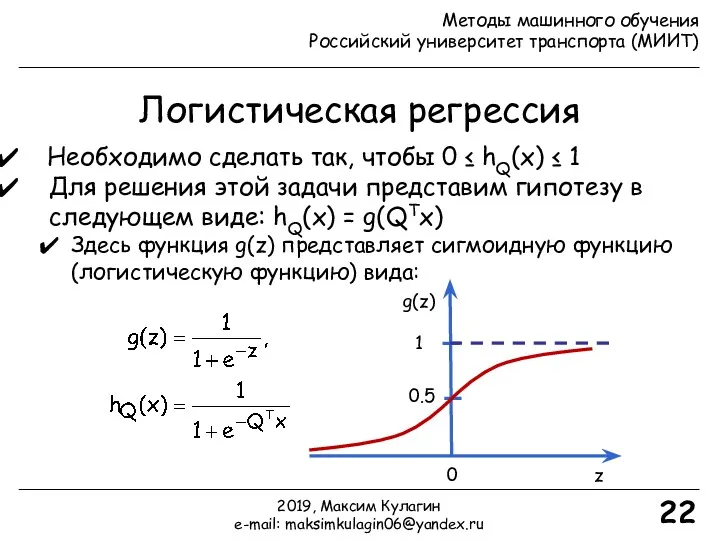
- 22. Логистическая регрессия 22 Необходимо сделать так, чтобы 0 ≤ hQ(x) ≤ 1 Для решения этой задачи
- 23. Интерпретация гипотезы в логистической регрессии 23 hQ(x) = оценке вероятности того, что y = 1 для
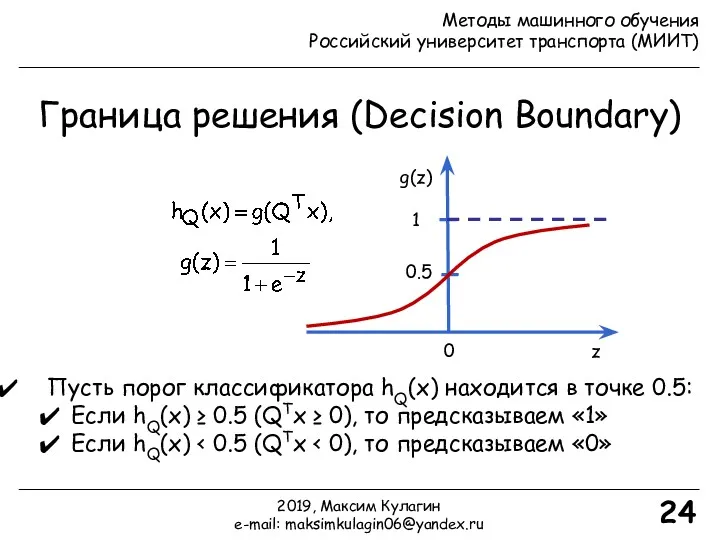
- 24. Граница решения (Decision Boundary) 24 z g(z) 0 1 0.5 Пусть порог классификатора hQ(x) находится в
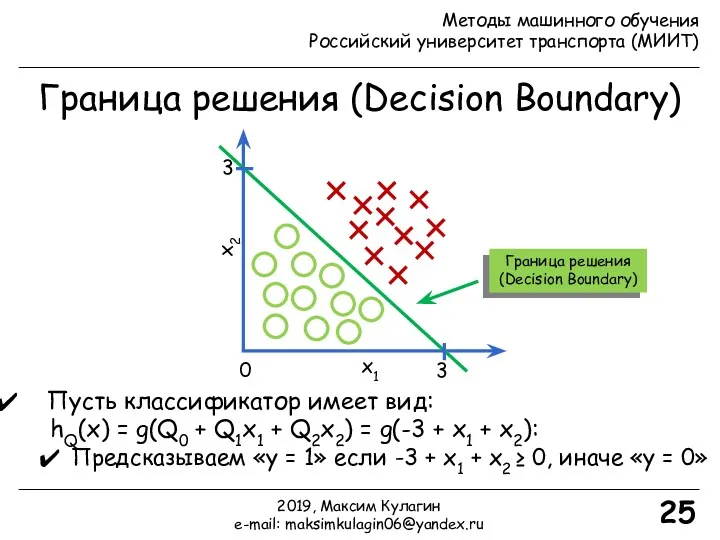
- 25. Граница решения (Decision Boundary) 25 Пусть классификатор имеет вид: hQ(x) = g(Q0 + Q1x1 + Q2x2)
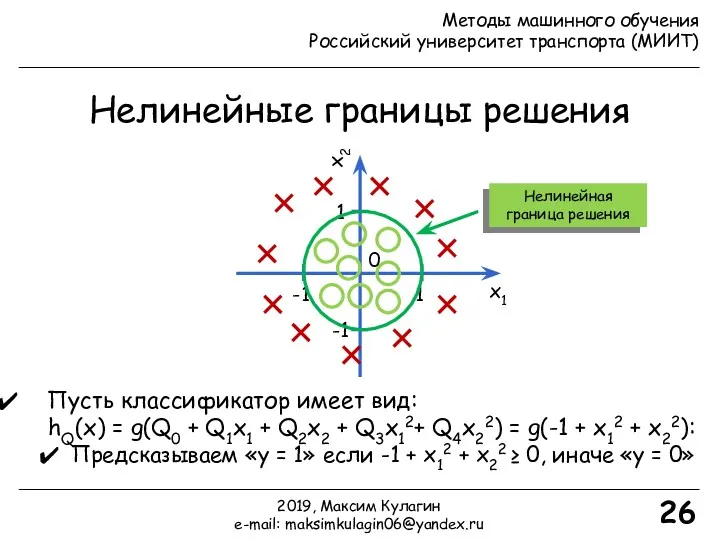
- 26. Нелинейные границы решения 26 Пусть классификатор имеет вид: hQ(x) = g(Q0 + Q1x1 + Q2x2 +
- 27. Стоимостная функция (Cost Function) 27 Дана тренировочная выборка {(x(1), y(1)), (x(2), y(2)), …, (x(m), y(m))}, где
- 28. Стоимостная функция (Cost Function) 28 Дана тренировочная выборка {(x(1), y(1)), (x(2), y(2)), …, (x(m), y(m))}, где
- 29. Стоимостная функция (Cost Function) 29 Дана тренировочная выборка {(x(1), y(1)), (x(2), y(2)), …, (x(m), y(m))}, где
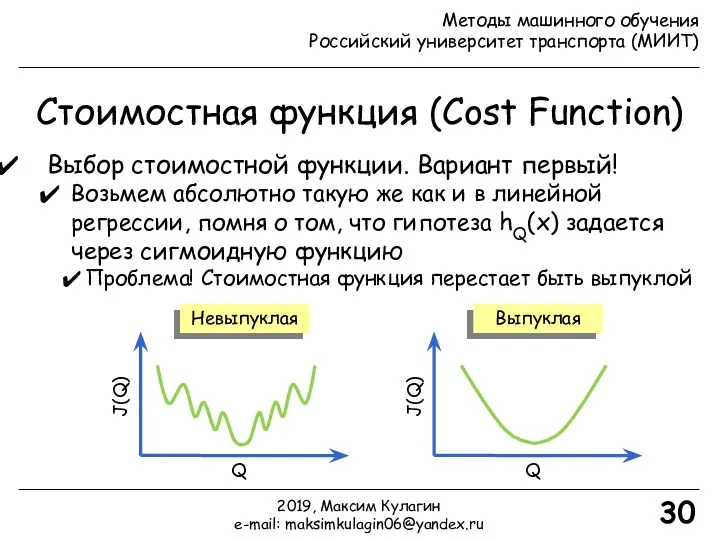
- 30. Стоимостная функция (Cost Function) 30 Выбор стоимостной функции. Вариант первый! Возьмем абсолютно такую же как и
- 31. Стоимостная функция (Cost Function) 31 Выбор стоимостной функции. Вариант второй! Пусть стоимостная функция имеет вид: Заметим,
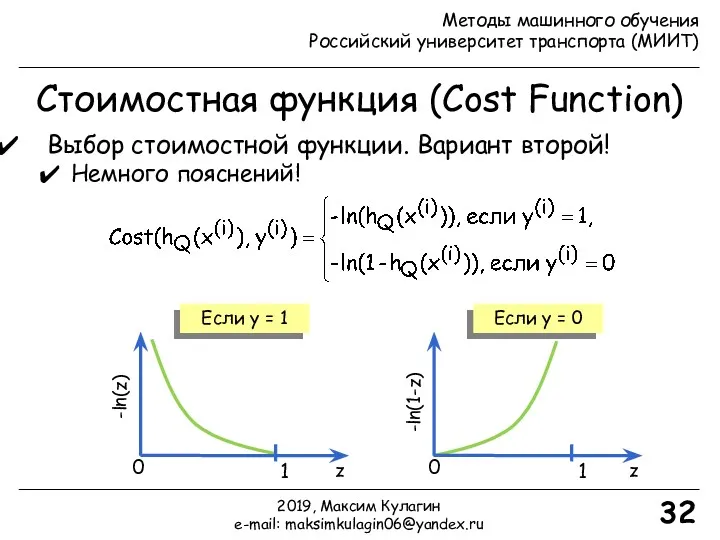
- 32. Стоимостная функция (Cost Function) 32 Выбор стоимостной функции. Вариант второй! Немного пояснений! -ln(z) z Если y
- 33. Стоимостная функция (Cost Function) 33 Для дальнейшего анализа стоимостную функцию для логистической регрессии удобно представить в
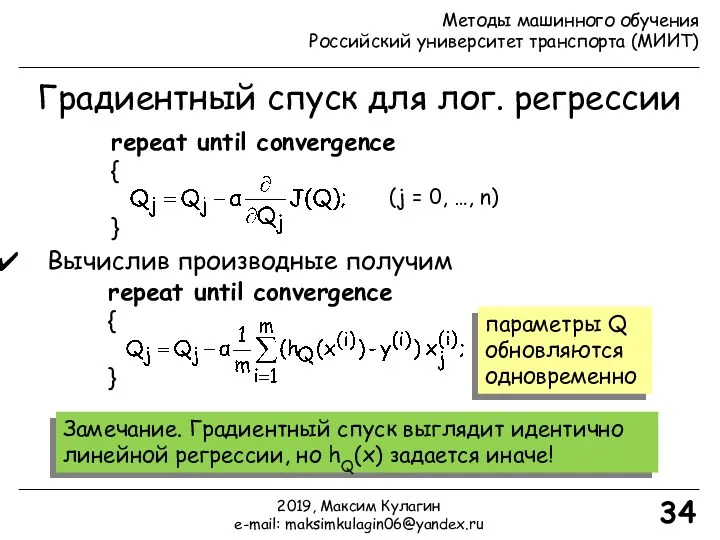
- 34. Градиентный спуск для лог. регрессии 34 repeat until convergence { } Вычислив производные получим repeat until
- 35. Градиентный спуск для лог. регрессии 35 repeat until convergence { } (j = 0, …, n)
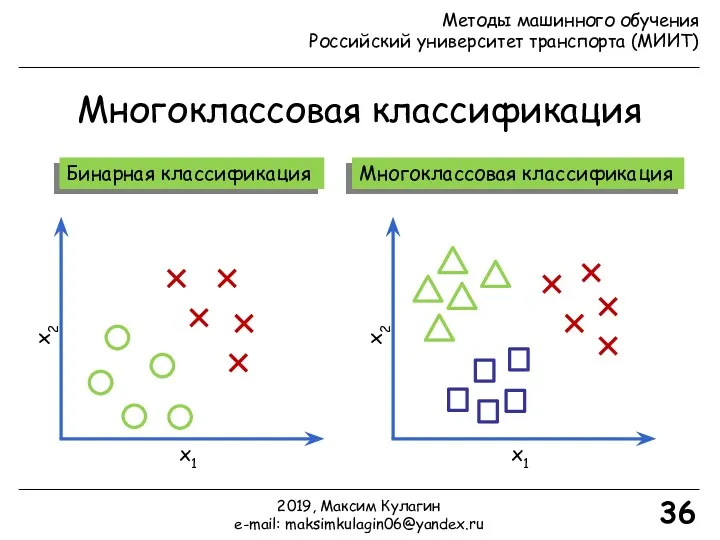
- 36. Многоклассовая классификация 36 Бинарная классификация Многоклассовая классификация x2 x1 x2 x1 2019, Максим Кулагин e-mail: maksimkulagin06@yandex.ru
- 37. Многоклассовая классификация. Подход «один против всех» (One-vs-all) 37 x2 x1 x2 x1 x2 x1 x2 x1
- 38. Многоклассовая классификация. Подход «один против всех» (One-vs-all) 38 Обучаем классификаторы основанные на логистической регрессии hiQ(x) для
- 39. Обучение и переобучение 39 2019, Максим Кулагин e-mail: maksimkulagin06@yandex.ru
- 40. 40 2019, Максим Кулагин e-mail: maksimkulagin06@yandex.ru Обучение и переобучение
- 42. Скачать презентацию

План лекции
Линейная регрессия со множеством переменных
Метод градиентного спуска для нескольких переменных.
План лекции
Линейная регрессия со множеством переменных
Метод градиентного спуска для нескольких переменных.

Линейная регрессия с одной переменной
Тренировочное множество данных (скажем, всего m)
Обозначения: m
Линейная регрессия с одной переменной
Тренировочное множество данных (скажем, всего m)
Обозначения: m

Линейная регрессия с одной переменной
Тренировочное множество данных (скажем, всего m)
Обозначения: m
Линейная регрессия с одной переменной
Тренировочное множество данных (скажем, всего m)
Обозначения: m
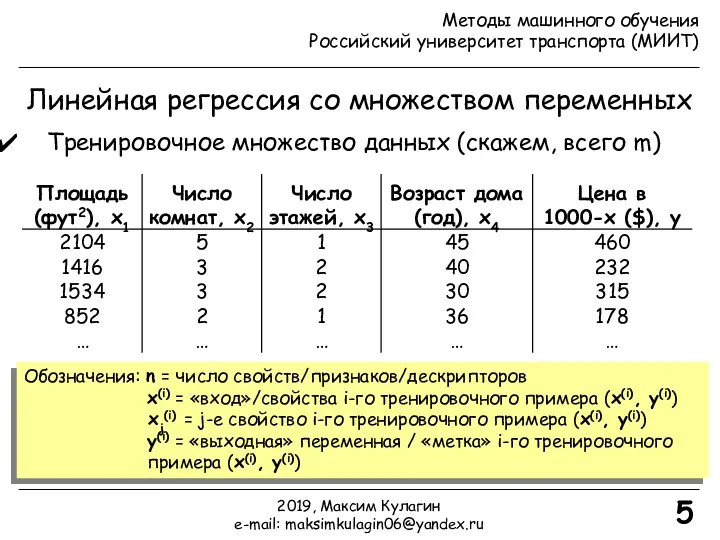
Линейная регрессия со множеством переменных
Тренировочное множество данных (скажем, всего m)
Обозначения: n
Линейная регрессия со множеством переменных
Тренировочное множество данных (скажем, всего m)
Обозначения: n

Обозначения: n = число свойств/признаков/дескрипторов
x(i) = «вход»/свойства i-го тренировочного примера
Обозначения: n = число свойств/признаков/дескрипторов
x(i) = «вход»/свойства i-го тренировочного примера

Градиентный спуск для линейной регрессии со множеством переменных
repeat until convergence
{
}
(j =
Градиентный спуск для линейной регрессии со множеством переменных
repeat until convergence
{
}
(j =
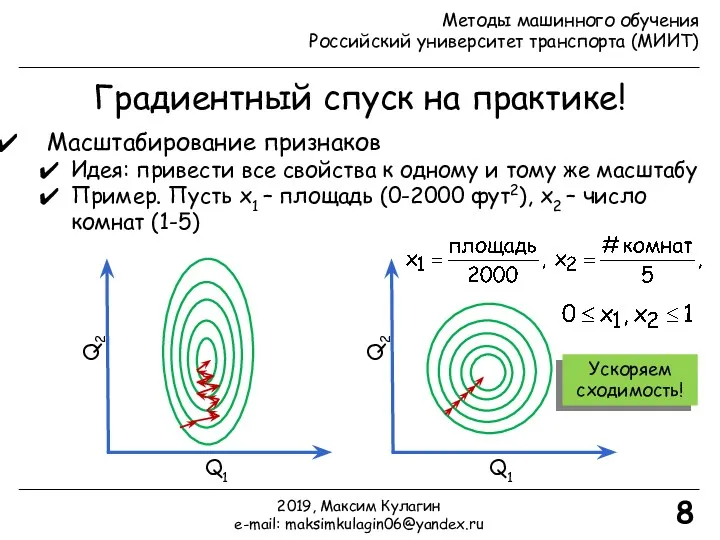
Градиентный спуск на практике!
Масштабирование признаков
Идея: привести все свойства к одному и
Градиентный спуск на практике!
Масштабирование признаков
Идея: привести все свойства к одному и

Нормализация на математическое ожидание
Идея: замена xj на, xj – μj с
Нормализация на математическое ожидание
Идея: замена xj на, xj – μj с

Градиентный спуск на практике!
10
Отладка. Как убедиться в том, что градиентный спуск
Градиентный спуск на практике!
10
Отладка. Как убедиться в том, что градиентный спуск

Полиномиальная регрессия
11
Предскажем цену на дом с использованием следующей гипотезы:
hQ(x) = QTx
Полиномиальная регрессия
11
Предскажем цену на дом с использованием следующей гипотезы:
hQ(x) = QTx
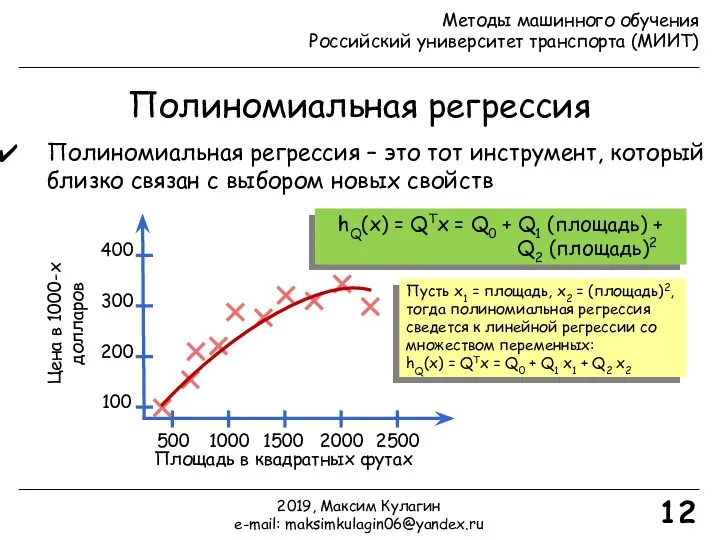
Полиномиальная регрессия
12
Полиномиальная регрессия – это тот инструмент, который близко связан с
Полиномиальная регрессия
12
Полиномиальная регрессия – это тот инструмент, который близко связан с

Аналитическое решение
13
Метод аналитического поиска параметров Q
Рассмотрим стоимостную функцию J(Q)
Вычислим частные производные
Аналитическое решение
13
Метод аналитического поиска параметров Q
Рассмотрим стоимостную функцию J(Q)
Вычислим частные производные

Нормальные уравнения
Тренировочное множество данных (скажем, всего m = 4)
14
Масштабирование свойств не
Нормальные уравнения
Тренировочное множество данных (скажем, всего m = 4)
14
Масштабирование свойств не
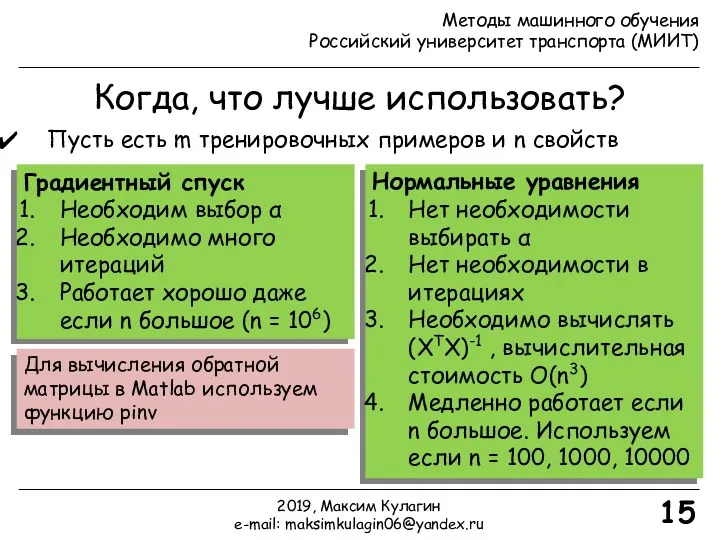
15
Когда, что лучше использовать?
Пусть есть m тренировочных примеров и n свойств
Градиентный
15
Когда, что лучше использовать?
Пусть есть m тренировочных примеров и n свойств
Градиентный

Классификация. Примеры
Классификация (предсказание дискретной выходной величины, например, 0 или 1)
Примеры задач
Классификация. Примеры
Классификация (предсказание дискретной выходной величины, например, 0 или 1)
Примеры задач
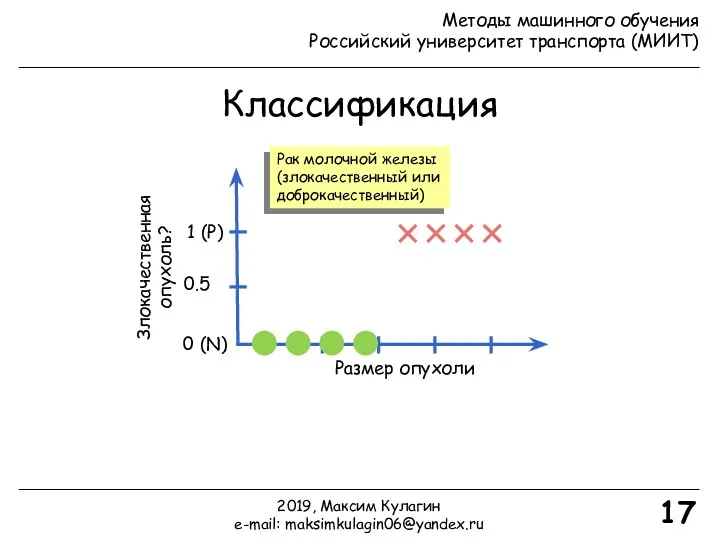
Классификация
Размер опухоли
Злокачественная опухоль?
0 (N)
1 (P)
17
Рак молочной железы
(злокачественный или
доброкачественный)
0.5
2019, Максим
Классификация
Размер опухоли
Злокачественная опухоль?
0 (N)
1 (P)
17
Рак молочной железы
(злокачественный или
доброкачественный)
0.5
2019, Максим
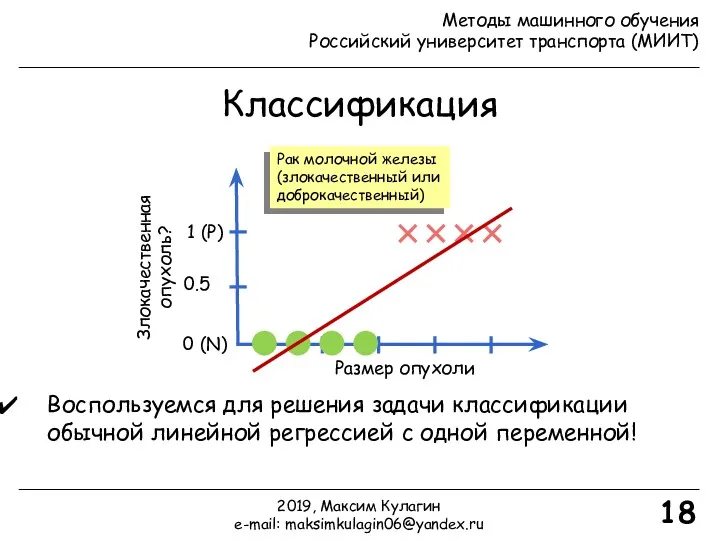
Классификация
Размер опухоли
Злокачественная опухоль?
0 (N)
1 (P)
18
Рак молочной железы
(злокачественный или
доброкачественный)
Воспользуемся для
Классификация
Размер опухоли
Злокачественная опухоль?
0 (N)
1 (P)
18
Рак молочной железы
(злокачественный или
доброкачественный)
Воспользуемся для
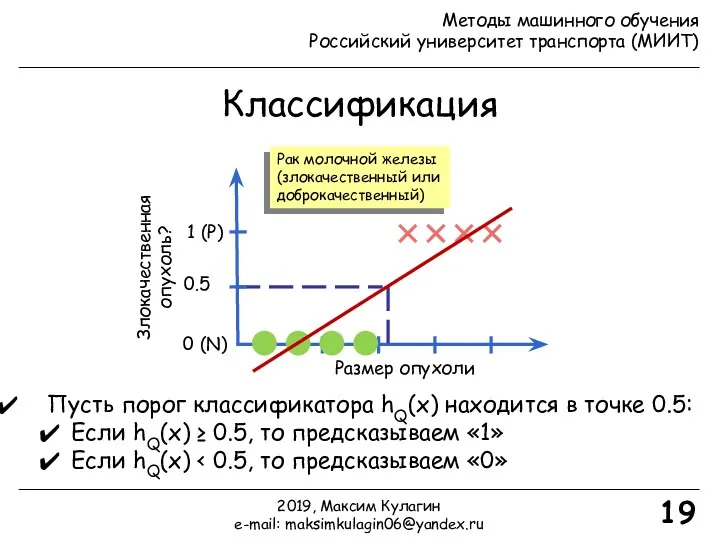
Классификация
Размер опухоли
Злокачественная опухоль?
0 (N)
1 (P)
19
Рак молочной железы
(злокачественный или
доброкачественный)
Пусть порог
Классификация
Размер опухоли
Злокачественная опухоль?
0 (N)
1 (P)
19
Рак молочной железы
(злокачественный или
доброкачественный)
Пусть порог
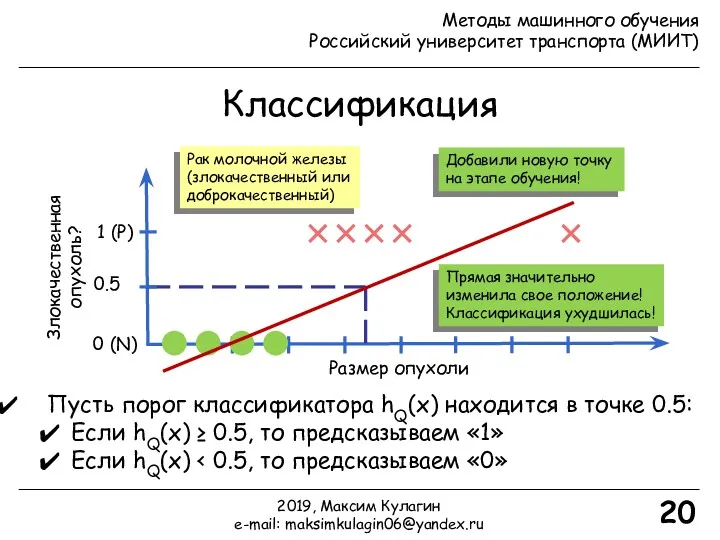
Классификация
Размер опухоли
Злокачественная опухоль?
0 (N)
1 (P)
20
Рак молочной железы
(злокачественный или
доброкачественный)
Пусть порог
Классификация
Размер опухоли
Злокачественная опухоль?
0 (N)
1 (P)
20
Рак молочной железы
(злокачественный или
доброкачественный)
Пусть порог

Классификация
21
Проблемы классификации на основе линейной регрессии с одной переменной
Выход (y) задачи
Классификация
21
Проблемы классификации на основе линейной регрессии с одной переменной
Выход (y) задачи
Логистическая регрессия
22
Необходимо сделать так, чтобы 0 ≤ hQ(x) ≤ 1
Для решения
Логистическая регрессия
22
Необходимо сделать так, чтобы 0 ≤ hQ(x) ≤ 1
Для решения

Интерпретация гипотезы
в логистической регрессии
23
hQ(x) = оценке вероятности того, что y
Интерпретация гипотезы
в логистической регрессии
23
hQ(x) = оценке вероятности того, что y
Граница решения (Decision Boundary)
24
z
g(z)
0
1
0.5
Пусть порог классификатора hQ(x) находится в точке 0.5:
Если
Граница решения (Decision Boundary)
24
z
g(z)
0
1
0.5
Пусть порог классификатора hQ(x) находится в точке 0.5:
Если
Граница решения (Decision Boundary)
25
Пусть классификатор имеет вид:
hQ(x) = g(Q0
Граница решения (Decision Boundary)
25
Пусть классификатор имеет вид:
hQ(x) = g(Q0
Нелинейные границы решения
26
Пусть классификатор имеет вид:
hQ(x) = g(Q0 +
Нелинейные границы решения
26
Пусть классификатор имеет вид:
hQ(x) = g(Q0 +

Стоимостная функция (Cost Function)
27
Дана тренировочная выборка {(x(1), y(1)), (x(2), y(2)), …,
Стоимостная функция (Cost Function)
27
Дана тренировочная выборка {(x(1), y(1)), (x(2), y(2)), …,

Стоимостная функция (Cost Function)
28
Дана тренировочная выборка {(x(1), y(1)), (x(2), y(2)), …,
Стоимостная функция (Cost Function)
28
Дана тренировочная выборка {(x(1), y(1)), (x(2), y(2)), …,

Стоимостная функция (Cost Function)
29
Дана тренировочная выборка {(x(1), y(1)), (x(2), y(2)), …,
Стоимостная функция (Cost Function)
29
Дана тренировочная выборка {(x(1), y(1)), (x(2), y(2)), …,
Стоимостная функция (Cost Function)
30
Выбор стоимостной функции. Вариант первый!
Возьмем абсолютно такую же
Стоимостная функция (Cost Function)
30
Выбор стоимостной функции. Вариант первый!
Возьмем абсолютно такую же

Стоимостная функция (Cost Function)
31
Выбор стоимостной функции. Вариант второй!
Пусть стоимостная функция имеет
Стоимостная функция (Cost Function)
31
Выбор стоимостной функции. Вариант второй!
Пусть стоимостная функция имеет
Стоимостная функция (Cost Function)
32
Выбор стоимостной функции. Вариант второй!
Немного пояснений!
-ln(z)
z
Если y =
Стоимостная функция (Cost Function)
32
Выбор стоимостной функции. Вариант второй!
Немного пояснений!
-ln(z)
z
Если y =

Стоимостная функция (Cost Function)
33
Для дальнейшего анализа стоимостную функцию для логистической регрессии
Стоимостная функция (Cost Function)
33
Для дальнейшего анализа стоимостную функцию для логистической регрессии
Градиентный спуск для лог. регрессии
34
repeat until convergence
{
}
Вычислив производные получим
repeat until
Градиентный спуск для лог. регрессии
34
repeat until convergence
{
}
Вычислив производные получим
repeat until

Градиентный спуск для лог. регрессии
35
repeat until convergence
{
}
(j = 0, …,
Градиентный спуск для лог. регрессии
35
repeat until convergence
{
}
(j = 0, …,
Многоклассовая классификация
36
Бинарная классификация
Многоклассовая классификация
x2
x1
x2
x1
2019, Максим Кулагин
e-mail: maksimkulagin06@yandex.ru
Методы машинного обучения
Российский университет
Многоклассовая классификация
36
Бинарная классификация
Многоклассовая классификация
x2
x1
x2
x1
2019, Максим Кулагин
e-mail: maksimkulagin06@yandex.ru
Методы машинного обучения
Российский университет
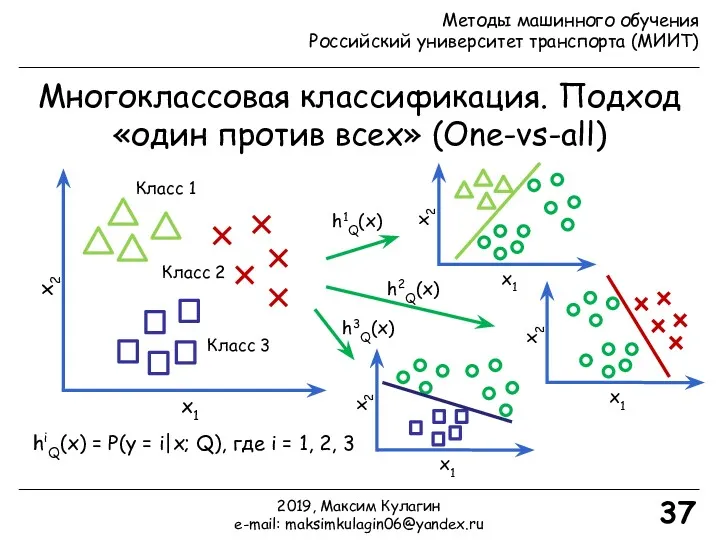
Многоклассовая классификация. Подход «один против всех» (One-vs-all)
37
x2
x1
x2
x1
x2
x1
x2
x1
Класс 1
Класс 3
Класс 2
h1Q(x)
h2Q(x)
h3Q(x)
hiQ(x) =
Многоклассовая классификация. Подход «один против всех» (One-vs-all)
37
x2
x1
x2
x1
x2
x1
x2
x1
Класс 1
Класс 3
Класс 2
h1Q(x)
h2Q(x)
h3Q(x)
hiQ(x) =

Многоклассовая классификация. Подход «один против всех» (One-vs-all)
38
Обучаем классификаторы основанные на логистической
Многоклассовая классификация. Подход «один против всех» (One-vs-all)
38
Обучаем классификаторы основанные на логистической
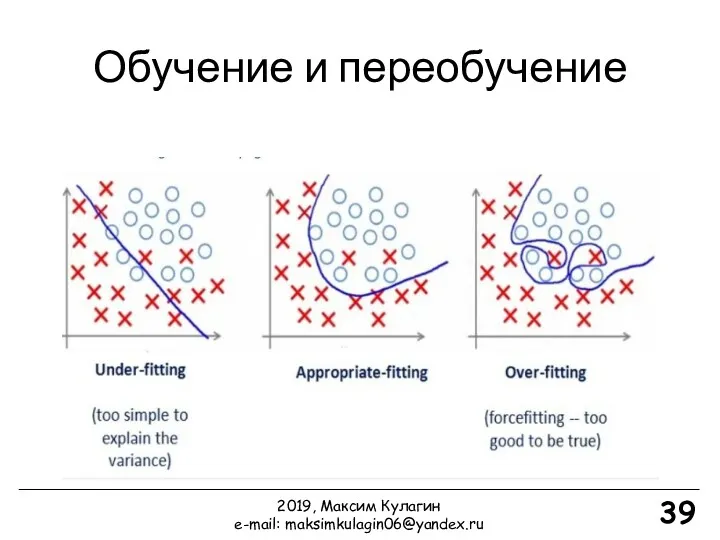
Обучение и переобучение
39
2019, Максим Кулагин
e-mail: maksimkulagin06@yandex.ru
Обучение и переобучение
39
2019, Максим Кулагин
e-mail: maksimkulagin06@yandex.ru
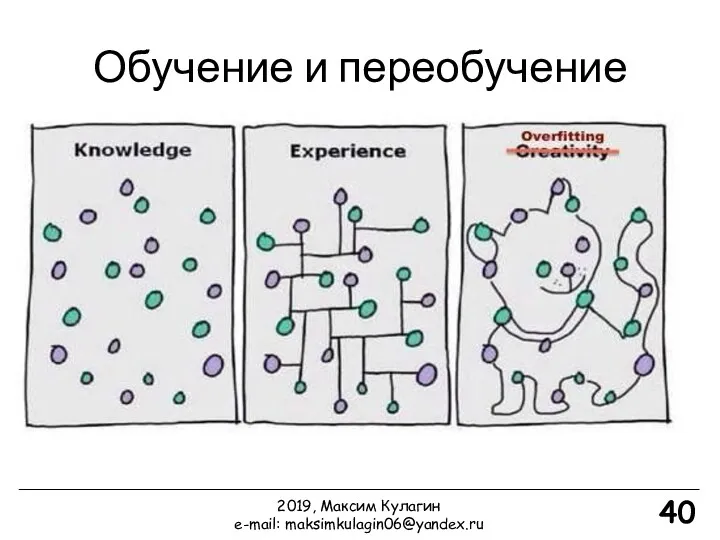
40
2019, Максим Кулагин
e-mail: maksimkulagin06@yandex.ru
Обучение и переобучение
40
2019, Максим Кулагин
e-mail: maksimkulagin06@yandex.ru
Обучение и переобучение
 Как подготовить данные. Семинар 4. Викторина
Как подготовить данные. Семинар 4. Викторина Концепция и возможности подхода .NET
Концепция и возможности подхода .NET Microsoft Access Мәліметтер қорын басқару жүйесі
Microsoft Access Мәліметтер қорын басқару жүйесі Технология создания и обработки графической информации
Технология создания и обработки графической информации Презентация Времена года. 6 класс
Презентация Времена года. 6 класс Строки Паскаль. Чем плох массив символов?
Строки Паскаль. Чем плох массив символов? Научная информация: поиск, накопление и обработка
Научная информация: поиск, накопление и обработка Обслуживание сети
Обслуживание сети Introduction to Data Capture. Module 6
Introduction to Data Capture. Module 6 Решение логических задач
Решение логических задач Передача информации. Приложение к уроку
Передача информации. Приложение к уроку Добровольцы России. Регистрация организации
Добровольцы России. Регистрация организации Упрощение логических выражений. Решение задач
Упрощение логических выражений. Решение задач ВКР: Совершенствование системы управления персоналом сервисного предприятия
ВКР: Совершенствование системы управления персоналом сервисного предприятия Как снимать интересные сториз
Как снимать интересные сториз Память. Что такое память компьютера
Память. Что такое память компьютера Практические аспекты составления алгоритмов
Практические аспекты составления алгоритмов Теоретические основы информатики
Теоретические основы информатики Информационные технологии в государственном управлении
Информационные технологии в государственном управлении Компьютерлік желі
Компьютерлік желі WEB. Visual Studio Code
WEB. Visual Studio Code Браузеры. Яндекс Браузер, Opera, Firefox
Браузеры. Яндекс Браузер, Opera, Firefox SQL. База данных
SQL. База данных Системы управления базами данных (СУБД) MS Access
Системы управления базами данных (СУБД) MS Access Решение задач с использованием операторов цикла
Решение задач с использованием операторов цикла Лекция 15. Основные механизмы защиты, используемые в системах защиты информации (СЗИ) информационных систем (ИС)
Лекция 15. Основные механизмы защиты, используемые в системах защиты информации (СЗИ) информационных систем (ИС) Графический учебный исполнитель. Разработка урока с презентацией
Графический учебный исполнитель. Разработка урока с презентацией Программирование на языке Java. Тема 23. Рекурсия
Программирование на языке Java. Тема 23. Рекурсия