- Словари и множества. Стандартные алгоритмы STL. Лекция 7

Содержание
- 2. Множества Множества — это математические структуры, которые могут хранить в себе уникальные элементы (то есть, каждый
- 3. Множества Множества создаются по аналогии с векторами. Пишем ключевое слово set, за ним — название типа
- 4. Решим следующую задачу Даны N запросов трёх типов: добавить элемент во множество; проверить, входит ли элемент
- 5. Число n – ск-ко запросов Если элемент не нашелся, то вернется указатель на конец множ-ва В
- 6. Ввод элементов множества
- 7. Вывод всех элементов множества Первый способ: Второй способ позволяет выводить элементы множества аналогично выводу всех элементов
- 8. Сортировка с помощью множества Поскольку проход по элементам множества осуществляется в возрастающем порядке, то велик соблазн
- 9. Количество разных элементов С помощью set очень легко подсчитать число различных элементов в последовательности. Для этого
- 10. Подсчет количества вхождений элемента в последовательность Поскольку во множестве все элементы упорядочены, с его помощью легко
- 11. multiset s; int n; cin >> n; for (int i = 0; i int x; cin
- 12. Задача 1 Дан список целых чисел, который может содержать до 100000 чисел. Определите, сколько в нем
- 13. Задача 2 Во входной строке записана последовательность чисел через пробел. Для каждого числа выведите слово YES
- 14. Задача 3 Даны два списка чисел, которые могут содержать до 100000 чисел каждый. Посчитайте, сколько чисел
- 15. Задача 4 Даны два списка чисел, которые могут содержать до 100000 чисел каждый. Выведите все числа,
- 16. Словари В C++ есть ещё одна структура, похожая на множество, которая называется «словарь». Она ставит в
- 17. Словари Рассмотрим такую задачу: на телефон поступает входящий звонок с известного номера телефона. Нужно проверить, есть
- 18. #include #include #include using namespace std; int main() { map s; s[112] = "sos"; if (s.find(112)
- 19. Проход по элементам словаря Проход по всем элементам в словаре делается почти так же, как и
- 20. Сопоставление нескольких значений Часто требуется сопоставить одному ключу несколько значений. Например, в словаре иностранных слов может
- 21. #include #include #include #include using namespace std; int main() { map > s; s["Vasya"] = {
- 22. В этой программе мы сразу инициализировали вектор конкретными значениями, используя фигурные скобки. В принципе, можно создать
- 23. Стандартные алгоритмы STL Сегодня мы будем изучать разные алгоритмы, которые есть в стандартной библиотеке C++. Они
- 24. Сортировка #include #include #include using namespace std; int main() { int n; cin >> n; vector
- 25. Структуры Чтобы описывать объекты, которые характеризуются несколькими разными значениями, нужны структуры. Фактически, структура — это новый
- 27. Устойчивая сортировка Сортировка называется устойчивой, если она сохраняет взаимный порядок одинаковых элементов. Если Вася и Петя
- 28. Задача 5 Отсортируйте массив. Входные данные Первая строка входных данных содержит количество элементов в массиве N
- 29. Ответ на задачу 1 #include #include using namespace std; int main() { set s; int n;
- 30. Ответ на задачу 2 int main() { set s; int n; cin >> n; for (int
- 31. Ответ на задачу 3 set s; set s1; set s2; int n1; cin >> n1; for
- 32. Ответ на задачу 4 set s1; set s2; set s; int n1; cin >> n1; for
- 33. Ответ на задачу 5 set s1; set s2; set s; int n1; cin >> n1; for
- 34. Ответ на задачу 4 set s1; set s2; set s; int n1; cin >> n1; for
- 35. Ответ на задачу 4 set s1; set s2; set s; int n1; cin >> n1; for
- 37. Скачать презентацию

Множества
Множества — это математические структуры, которые могут хранить в себе уникальные элементы
Множества
Множества — это математические структуры, которые могут хранить в себе уникальные элементы

Множества
Множества создаются по аналогии с векторами.
Пишем ключевое слово set, за
Множества
Множества создаются по аналогии с векторами.
Пишем ключевое слово set, за

Решим следующую задачу
Даны N запросов трёх типов:
добавить элемент во множество;
проверить, входит
Решим следующую задачу
Даны N запросов трёх типов:
добавить элемент во множество;
проверить, входит

Число n – ск-ко запросов
Если элемент не нашелся, то вернется указатель
Число n – ск-ко запросов
Если элемент не нашелся, то вернется указатель

Ввод элементов множества
Ввод элементов множества

Вывод всех элементов множества
Первый способ:
Второй способ позволяет выводить элементы множества аналогично
Вывод всех элементов множества
Первый способ:
Второй способ позволяет выводить элементы множества аналогично

Сортировка с помощью множества
Поскольку проход по элементам множества осуществляется в возрастающем
Сортировка с помощью множества
Поскольку проход по элементам множества осуществляется в возрастающем

Количество разных элементов
С помощью set очень легко подсчитать число различных элементов
Количество разных элементов
С помощью set очень легко подсчитать число различных элементов

Подсчет количества вхождений элемента в последовательность
Поскольку во множестве все элементы упорядочены,
Подсчет количества вхождений элемента в последовательность
Поскольку во множестве все элементы упорядочены,

multiset s;
int n;
cin >> n;
for (int i = 0; i
multiset
int n;
cin >> n;
for (int i = 0; i

Задача 1
Дан список целых чисел, который может содержать до 100000 чисел.
Задача 1
Дан список целых чисел, который может содержать до 100000 чисел.

Задача 2
Во входной строке записана последовательность чисел через пробел. Для каждого
Задача 2
Во входной строке записана последовательность чисел через пробел. Для каждого

Задача 3
Даны два списка чисел, которые могут содержать до 100000 чисел
Задача 3
Даны два списка чисел, которые могут содержать до 100000 чисел

Задача 4
Даны два списка чисел, которые могут содержать до 100000 чисел
Задача 4
Даны два списка чисел, которые могут содержать до 100000 чисел

Словари
В C++ есть ещё одна структура, похожая на множество, которая называется
Словари
В C++ есть ещё одна структура, похожая на множество, которая называется

Словари
Рассмотрим такую задачу: на телефон поступает входящий звонок с известного номера
Словари
Рассмотрим такую задачу: на телефон поступает входящий звонок с известного номера

#include
#include
#include
#include

Проход по элементам словаря
Проход по всем элементам в словаре делается почти
Проход по элементам словаря
Проход по всем элементам в словаре делается почти

Сопоставление нескольких значений
Часто требуется сопоставить одному ключу несколько значений. Например, в
Сопоставление нескольких значений
Часто требуется сопоставить одному ключу несколько значений. Например, в

#include
#include
#include
#include

В этой программе мы сразу инициализировали вектор конкретными значениями, используя фигурные
В этой программе мы сразу инициализировали вектор конкретными значениями, используя фигурные

Стандартные алгоритмы STL
Сегодня мы будем изучать разные алгоритмы, которые есть в
Стандартные алгоритмы STL
Сегодня мы будем изучать разные алгоритмы, которые есть в

Сортировка
#include
#include
#include
using namespace std;
int main() {
int n;
cin
Сортировка
#include
#include
#include
using namespace std;
int main() {
int n;
cin

Структуры
Чтобы описывать объекты, которые характеризуются несколькими разными значениями, нужны структуры. Фактически,
Структуры
Чтобы описывать объекты, которые характеризуются несколькими разными значениями, нужны структуры. Фактически,
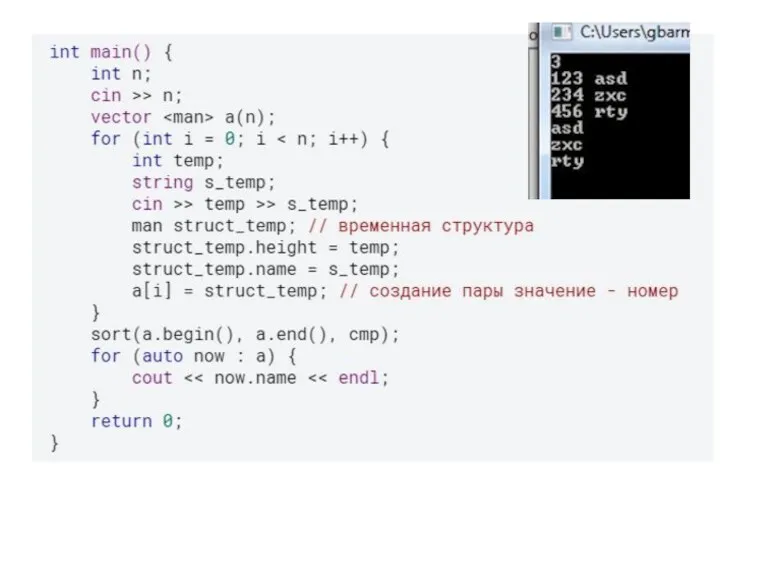

Устойчивая сортировка
Сортировка называется устойчивой, если она сохраняет взаимный порядок одинаковых элементов.
Устойчивая сортировка
Сортировка называется устойчивой, если она сохраняет взаимный порядок одинаковых элементов.

Задача 5
Отсортируйте массив.
Входные данные
Первая строка входных данных содержит количество элементов в
Задача 5
Отсортируйте массив.
Входные данные
Первая строка входных данных содержит количество элементов в

Ответ на задачу 1
#include
#include
using namespace std;
int main() {
set
Ответ на задачу 1
#include
#include
using namespace std;
int main() {
set

Ответ на задачу 2
int main() {
set s;
int n;
Ответ на задачу 2
int main() {
set
int n;

Ответ на задачу 3
set s;
set s1;
set
Ответ на задачу 3
set
set
set

Ответ на задачу 4
set s1;
set s2;
set
Ответ на задачу 4
set
set
set

Ответ на задачу 5
set s1;
set s2;
set
Ответ на задачу 5
set
set
set

Ответ на задачу 4
set s1;
set s2;
set
Ответ на задачу 4
set
set
set

Ответ на задачу 4
set s1;
set s2;
set
Ответ на задачу 4
set
set
set
 Аддитивные технологии
Аддитивные технологии Анти-паттерны в программировании. Классы наиболее часто внедряемых плохих решений проблем
Анти-паттерны в программировании. Классы наиболее часто внедряемых плохих решений проблем Решение задачи О рюкзаке методом динамического программирования
Решение задачи О рюкзаке методом динамического программирования Метрология. Метрики программного обеспечения
Метрология. Метрики программного обеспечения Идентификация и аутентификация
Идентификация и аутентификация Состав объектов. (Урок 3)
Состав объектов. (Урок 3) Модернизация защищенной локальной сети института безопасности СИБГУТИ
Модернизация защищенной локальной сети института безопасности СИБГУТИ Антивирус Avast
Антивирус Avast Роль информации в жизни личности, информация в обществе, ее виды, передача информации и ее обработка
Роль информации в жизни личности, информация в обществе, ее виды, передача информации и ее обработка Коллекция автографов известных ученых на книгах
Коллекция автографов известных ученых на книгах Что можно выбрать в компьютерном меню
Что можно выбрать в компьютерном меню Семинар #13 GIMP
Семинар #13 GIMP Программирование циклов. Урок в 9 классе
Программирование циклов. Урок в 9 классе Основы вычислительных сетей. Модель OSI
Основы вычислительных сетей. Модель OSI Системи опрацювання комп'ютерних презентацій
Системи опрацювання комп'ютерних презентацій Тест по информатике комплексный
Тест по информатике комплексный Оператор ветвления
Оператор ветвления Что такое CSS
Что такое CSS Распределенная тактильная система передачи управляющих сигналов
Распределенная тактильная система передачи управляющих сигналов Лига юных журналистов Воронежа. Годовой отчёт
Лига юных журналистов Воронежа. Годовой отчёт Растровая и векторная графика. Форматы графических файлов
Растровая и векторная графика. Форматы графических файлов GitHub Account Creation Request Form
GitHub Account Creation Request Form Устройства ввода и вывода в компьютере
Устройства ввода и вывода в компьютере Інформаційно-комунікаційні технології
Інформаційно-комунікаційні технології Ақпаратты қорғау негіздері
Ақпаратты қорғау негіздері Использование простого класса в программе на C# с графическим интерфейсом пользователя (GUI)
Использование простого класса в программе на C# с графическим интерфейсом пользователя (GUI) Создание графических объектов в текстовом редакторе
Создание графических объектов в текстовом редакторе Borland Delphi программалау ортасы
Borland Delphi программалау ортасы