- Сортировка массивов

Содержание
- 2. Алгоритмы сортировки одномерных массивов Под сортировкой понимают процесс перестановки объектов данного массива в определенном порядке. Целью
- 3. Алгоритмы сортировки одномерных массивов Пусть есть последовательность a0, a1... an и функция сравнения, которая на любых
- 4. Алгоритмы сортировки одномерных массивов Если значение функции сравнения зависит только от поля x, то x называют
- 5. Алгоритмы сортировки одномерных массивов Для того, чтобы обоснованно сделать такой выбор, рассмотрим параметры, по которым будет
- 6. Сортировка методом парных перестановок (методом «пузырька») Самый простой вариант алгоритма сортировки массива основан на принципе сравнения
- 7. Сортировка методом парных перестановок (методом «пузырька») Для подсчета количества перестановок целесообразно использовать счетчик – специальную переменную
- 8. Сортировка методом парных перестановок (методом «пузырька») Пример кода программы
- 9. Сортировка методом парных перестановок (методом «пузырька») Результат работы программы Этот алгоритм всегда будет делать шагов, независимо
- 10. Сортировка методом парных перестановок (методом «пузырька») Пузырьковая сортировка имеет такую особенность: неупорядоченные элементы на "большом" конце
- 11. Сортировка модифицированным методом простого выбора Этот метод основывается на алгоритме поиска минимального элемента. В массиве А[1..n]
- 12. Сортировка модифицированным методом простого выбора Рассмотрим алгоритмическое решение задачи на примере сортировки некоторого массива значений по
- 13. Схема метода Через i обозначен счетчик (номер) просмотров элементов массива.
- 14. Схема метода Рассмотрим выполнение сортировки данным методом на конкретном примере. Пусть исходный массив содержит 5 элементов
- 15. Схема метода
- 16. Код программы
- 17. Результат работы программы
- 18. Результат работы программы Как и в пузырьковой сортировке, внешний цикл выполняется n-1 раз, а внутренний –
- 19. Результат работы программы Покажем, почему данная реализация является неустойчивой. Рассмотрим следующий массив из элементов, каждый из
- 20. Результат работы программы Существует также двунаправленный вариант сортировки методом выбора, в котором на каждом проходе отыскиваются
- 21. Сортировка методом простого включения (вставками) В этом методе задача формулируется так: есть часть массива, которая уже
- 22. Сортировка методом простого включения (вставками) Метод выбора очередного элемента из исходного массива произволен, однако обычно (и
- 23. Сортировка методом простого включения (вставками) Максимальное количество инверсий содержится в массиве, элементы которого отсортированы по невозрастанию.
- 24. Сортировка методом простого включения (вставками) Рассмотрим на примере числовой последовательности процесс сортировки методом вставок. Клетка, выделенная
- 25. Код программы
- 26. Результат работы
- 27. Сортировка вставками Это устойчивый алгоритм сортировки (не меняет порядок элементов, которые уже отсортированы); может сортировать массив
- 28. Сортировка вставками Это устойчивый алгоритм сортировки (не меняет порядок элементов, которые уже отсортированы); может сортировать массив
- 29. Быстрая сортировка (quick-sort) Быстрая сортировка является улучшенным вариантом алгоритма сортировки с помощью прямого обмена (пузырьковая сортировка).
- 30. Быстрая сортировка (quick-sort) Общая схема алгоритма: из массива выбирается некоторый опорный элемент a[i] запускается процедура разделения
- 31. Быстрая сортировка (quick-sort) для обоих подмассивов: если в подмассиве более двух элементов, рекурсивно запускаем для него
- 32. Быстрая сортировка (quick-sort) Рассмотрим алгоритм подробнее. На входе массив a[0]...a[N] и опорный элемент p, по которому
- 33. Быстрая сортировка (quick-sort) Рассмотрим работу процедуры для массива a[0]...a[6] и опорного элемента p = a[3]. Теперь
- 34. Быстрая сортировка. Оценка сложности алгоритма Операция разделения массива на две части относительно опорного элемента занимает время
- 35. Быстрая сортировка. Оценка сложности алгоритма Лучший случай. В наиболее сбалансированном варианте при каждой операции разделения массив
- 36. Быстрая сортировка. Оценка сложности алгоритма Худший случай. Реализуется если каждый раз в качестве центрального элемента выбирается
- 37. Быстрая сортировка. Метод неустойчив. Поведение довольно естественно, если учесть, что при частичной упорядоченности повышаются шансы разделения
- 38. Рекурсия В языке Си функции могут вызывать сами себя непосредственно или косвенно, т.е. могут быть рекурсивными.
- 39. Рекурсия Каждая цепочка рекурсивных вызовов должна на каком-то шаге завершиться. Условие полного окончания работы рекурсивной функции
- 40. Рекурсия Применять рекурсивные методы программирования стоит в тех задачах, где рекурсия использована в определении обрабатываемых данных.
- 41. Рекурсия Пример программы вычисляющей факториал числа
- 42. Рекурсия При первом вызове f(5) функция возвращает выражение 5*f(4), т.е. функция f() фактически не возвращает значение,
- 43. Код алгоритма quick-sort
- 45. Скачать презентацию

Алгоритмы сортировки одномерных массивов
Под сортировкой понимают процесс перестановки объектов данного массива
Алгоритмы сортировки одномерных массивов
Под сортировкой понимают процесс перестановки объектов данного массива

Алгоритмы сортировки одномерных массивов
Пусть есть последовательность a0, a1... an и функция
Алгоритмы сортировки одномерных массивов
Пусть есть последовательность a0, a1... an и функция

Алгоритмы сортировки одномерных массивов
Если значение функции сравнения зависит только от поля
Алгоритмы сортировки одномерных массивов
Если значение функции сравнения зависит только от поля

Алгоритмы сортировки одномерных массивов
Для того, чтобы обоснованно сделать такой выбор, рассмотрим
Алгоритмы сортировки одномерных массивов
Для того, чтобы обоснованно сделать такой выбор, рассмотрим

Сортировка методом парных перестановок (методом «пузырька»)
Самый простой вариант алгоритма сортировки массива
Сортировка методом парных перестановок (методом «пузырька»)
Самый простой вариант алгоритма сортировки массива
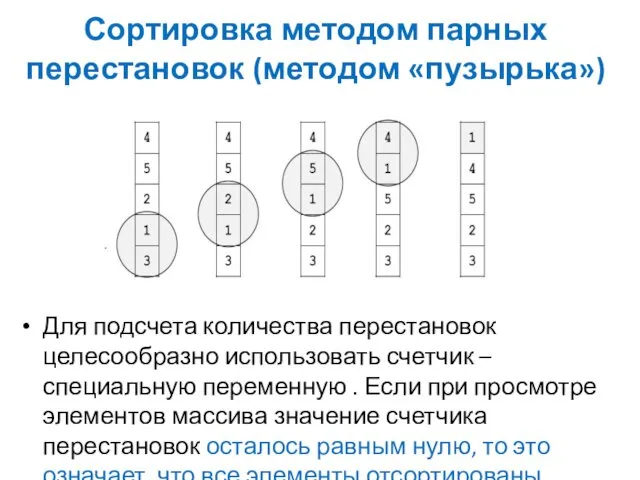
Сортировка методом парных перестановок (методом «пузырька»)
Для подсчета количества перестановок целесообразно использовать
Сортировка методом парных перестановок (методом «пузырька»)
Для подсчета количества перестановок целесообразно использовать

Сортировка методом парных перестановок (методом «пузырька»)
Пример кода программы
Сортировка методом парных перестановок (методом «пузырька»)
Пример кода программы

Сортировка методом парных перестановок (методом «пузырька»)
Результат работы программы
Этот алгоритм всегда будет
Сортировка методом парных перестановок (методом «пузырька»)
Результат работы программы
Этот алгоритм всегда будет

Сортировка методом парных перестановок (методом «пузырька»)
Пузырьковая сортировка имеет такую особенность: неупорядоченные
Сортировка методом парных перестановок (методом «пузырька»)
Пузырьковая сортировка имеет такую особенность: неупорядоченные

Сортировка модифицированным методом простого выбора
Этот метод основывается на алгоритме поиска минимального
Сортировка модифицированным методом простого выбора
Этот метод основывается на алгоритме поиска минимального

Сортировка модифицированным методом простого выбора
Рассмотрим алгоритмическое решение задачи на примере сортировки
Сортировка модифицированным методом простого выбора
Рассмотрим алгоритмическое решение задачи на примере сортировки
Схема метода
Через i обозначен счетчик (номер) просмотров элементов массива.
Схема метода
Через i обозначен счетчик (номер) просмотров элементов массива.

Схема метода
Рассмотрим выполнение сортировки данным методом на конкретном примере. Пусть исходный
Схема метода
Рассмотрим выполнение сортировки данным методом на конкретном примере. Пусть исходный
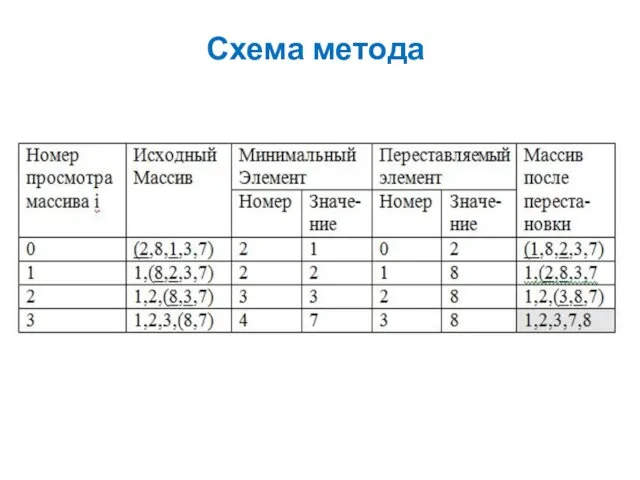
Схема метода
Схема метода

Код программы
Код программы

Результат работы программы
Результат работы программы

Результат работы программы
Как и в пузырьковой сортировке, внешний цикл выполняется n-1
Результат работы программы
Как и в пузырьковой сортировке, внешний цикл выполняется n-1

Результат работы программы
Покажем, почему данная реализация является неустойчивой.
Рассмотрим следующий массив из
Результат работы программы
Покажем, почему данная реализация является неустойчивой. Рассмотрим следующий массив из

Результат работы программы
Существует также двунаправленный вариант сортировки методом выбора, в котором
Результат работы программы
Существует также двунаправленный вариант сортировки методом выбора, в котором

Сортировка методом простого включения (вставками)
В этом методе задача формулируется так: есть
Сортировка методом простого включения (вставками)
В этом методе задача формулируется так: есть

Сортировка методом простого включения (вставками)
Метод выбора очередного элемента из исходного массива
Сортировка методом простого включения (вставками)
Метод выбора очередного элемента из исходного массива

Сортировка методом простого включения (вставками)
Максимальное количество инверсий содержится в массиве, элементы
Сортировка методом простого включения (вставками)
Максимальное количество инверсий содержится в массиве, элементы

Сортировка методом простого включения (вставками)
Рассмотрим на примере числовой последовательности процесс сортировки
Сортировка методом простого включения (вставками)
Рассмотрим на примере числовой последовательности процесс сортировки

Код программы
Код программы

Результат работы
Результат работы

Сортировка вставками
Это устойчивый алгоритм сортировки (не меняет порядок элементов, которые уже
Сортировка вставками
Это устойчивый алгоритм сортировки (не меняет порядок элементов, которые уже

Сортировка вставками
Это устойчивый алгоритм сортировки (не меняет порядок элементов, которые уже
Сортировка вставками
Это устойчивый алгоритм сортировки (не меняет порядок элементов, которые уже

Быстрая сортировка (quick-sort)
Быстрая сортировка является улучшенным вариантом алгоритма сортировки с
Быстрая сортировка (quick-sort)
Быстрая сортировка является улучшенным вариантом алгоритма сортировки с

Быстрая сортировка (quick-sort)
Общая схема алгоритма:
из массива выбирается некоторый
Быстрая сортировка (quick-sort)
Общая схема алгоритма:
из массива выбирается некоторый

Быстрая сортировка (quick-sort)
для обоих подмассивов: если в подмассиве более двух
Быстрая сортировка (quick-sort)
для обоих подмассивов: если в подмассиве более двух
![Быстрая сортировка (quick-sort) Рассмотрим алгоритм подробнее. На входе массив a[0]...a[N]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/107905/slide-31.jpg)
Быстрая сортировка (quick-sort)
Рассмотрим алгоритм подробнее.
На входе массив a[0]...a[N] и опорный
Быстрая сортировка (quick-sort)
Рассмотрим алгоритм подробнее.
На входе массив a[0]...a[N] и опорный
![Быстрая сортировка (quick-sort) Рассмотрим работу процедуры для массива a[0]...a[6] и](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/107905/slide-32.jpg)
Быстрая сортировка (quick-sort)
Рассмотрим работу процедуры для массива a[0]...a[6] и опорного
Быстрая сортировка (quick-sort)
Рассмотрим работу процедуры для массива a[0]...a[6] и опорного

Быстрая сортировка. Оценка сложности алгоритма
Операция разделения массива на две части относительно
Быстрая сортировка. Оценка сложности алгоритма
Операция разделения массива на две части относительно

Быстрая сортировка. Оценка сложности алгоритма
Лучший случай. В наиболее сбалансированном варианте при
Быстрая сортировка. Оценка сложности алгоритма
Лучший случай. В наиболее сбалансированном варианте при

Быстрая сортировка. Оценка сложности алгоритма
Худший случай. Реализуется если каждый раз в
Быстрая сортировка. Оценка сложности алгоритма
Худший случай. Реализуется если каждый раз в

Быстрая сортировка.
Метод неустойчив. Поведение довольно естественно, если учесть, что при
Быстрая сортировка.
Метод неустойчив. Поведение довольно естественно, если учесть, что при

Рекурсия
В языке Си функции могут вызывать сами себя непосредственно или косвенно,
Рекурсия
В языке Си функции могут вызывать сами себя непосредственно или косвенно,

Рекурсия
Каждая цепочка рекурсивных вызовов должна на каком-то шаге завершиться. Условие полного
Рекурсия
Каждая цепочка рекурсивных вызовов должна на каком-то шаге завершиться. Условие полного

Рекурсия
Применять рекурсивные методы программирования стоит в тех задачах, где рекурсия использована
Рекурсия
Применять рекурсивные методы программирования стоит в тех задачах, где рекурсия использована

Рекурсия
Пример программы вычисляющей факториал числа
Рекурсия
Пример программы вычисляющей факториал числа

Рекурсия
При первом вызове f(5) функция возвращает выражение 5*f(4), т.е. функция f()
Рекурсия
При первом вызове f(5) функция возвращает выражение 5*f(4), т.е. функция f()

Код алгоритма quick-sort
Код алгоритма quick-sort
 Использование мобильного телефона во время занятий
Использование мобильного телефона во время занятий Составление запросов для поисковых систем с использованием логических выражений
Составление запросов для поисковых систем с использованием логических выражений Введение в поисковое продвижение
Введение в поисковое продвижение Базовая линия. Повороты. Дополнения
Базовая линия. Повороты. Дополнения Проектирование баз данных
Проектирование баз данных Интеллектуальные информационные системы. Искусственный интеллект
Интеллектуальные информационные системы. Искусственный интеллект Обработка текстовой информации
Обработка текстовой информации Циклы while и for, работа со шрифтами в pygame.Занятие 5
Циклы while и for, работа со шрифтами в pygame.Занятие 5 Информационные технологии в менеджменте (для подготовки к контрольной)
Информационные технологии в менеджменте (для подготовки к контрольной) Типографика в рекламе и упаковке
Типографика в рекламе и упаковке Создание документов в WORD
Создание документов в WORD Извлечение данных из таблиц. Семинар 2
Извлечение данных из таблиц. Семинар 2 Машинная графика
Машинная графика Основы алгоритмизации
Основы алгоритмизации Базы данных Информационные системы
Базы данных Информационные системы Глобальная компьютерная сеть Интернет
Глобальная компьютерная сеть Интернет Веб-сервис по анализу цен интернет-магазинов
Веб-сервис по анализу цен интернет-магазинов Проект и основные этапы его разработки
Проект и основные этапы его разработки Введение в алгоритмизацию. Лекция 1
Введение в алгоритмизацию. Лекция 1 Презентация Классификация понятий
Презентация Классификация понятий Visual Basic
Visual Basic Застосування комп'ютерів Комп'ютерна система
Застосування комп'ютерів Комп'ютерна система Эталонная модель взаимодействия открытых систем. Основы сетевых технологий. Лекция 2
Эталонная модель взаимодействия открытых систем. Основы сетевых технологий. Лекция 2 Моделирование динамических отношений на UML
Моделирование динамических отношений на UML Web Application Penetration Testing
Web Application Penetration Testing Befree. Cons of social networks
Befree. Cons of social networks Обработка информации
Обработка информации Оформление списка литературы в алфавитном порядке
Оформление списка литературы в алфавитном порядке