- Сортировки. Внешние сортировки

Содержание
- 2. Понятие Внешняя сортировка – это упорядочивание данных, которые хранятся на внешнем устройстве с медленным доступом (диск
- 3. Понятие При внешней сортировке прежде всего требуется уменьшить число обращений к этому устройству, т. е. число
- 4. Эффективность алгоритма Для выяснения эффективности алгоритмов внутренней сортировки подсчитывалось число выполняемых ими сравнений. Объем работы по
- 5. Эффективность алгоритма При другом подходе можно воспользоваться файлами с прямым доступом и заменить непосредственные обращения к
- 6. Понятие серии Серией длины K является последовательность записей Ai, Ai+1,…,Ai+k-1 такая, что в ней все записи
- 7. Деление на серии Пусть в некотором файле A хранится одномерный массив: 12 35 65 0 24
- 8. Алгоритмы внешней сортировки Идея большинства методов заключается в расчленении данных на ряд последовательностей, помещающихся в оперативную
- 9. Алгоритмы внешней сортировки Естественная сортировка (метод естественного слияния) Сортировка методом двухпутевого сбалансированного слияния Сортировка методом n-путевого
- 10. Естественная сортировка Исходный файл: F: 20 50 7 30 80 40 60 50 35 25 70
- 11. Естественная сортировка Первый проход: Фаза распределения: F1: 20 50 | 40 60 | 35 F2: 7
- 12. Естественная сортировка Второй проход: Фаза распределения: F1: 7 20 30 50 80 | 25 35 70
- 13. Естественная сортировка Третий проход: Фаза распределения: F1: 7 20 30 40 50 50 60 80 F2:
- 14. Двухпутевое слияние Сортировка методом двухпутевого сбалансированного слияния без использования оперативной памяти Сбалансированная внешняя сортировка слиянием с
- 15. Двухпутевое слияние без использования оперативной памяти Вся сортируемая последовательность данных разбивается на два файла f1 и
- 16. Двухпутевое слияние без использования оперативной памяти После выполнения i проходов получатся два файла, состоящие из участков
- 17. Пример Исходные файлы: f1: 28 3 93 10 54 65 30 90 f2: 31 5 96
- 18. Пример Участки длинной 4: f1: 3 5 28 31 | 9 54 65 85 f2: 10
- 19. Двухпутевое слияние c использованием оперативной памяти Пусть у нас есть четыре файла и инструмент их слияния.
- 20. Двухпутевое слияние c использованием оперативной памяти I этап сортировки – распределение На первом шаге прочитаем S
- 21. Двухпутевое слияние c использованием оперативной памяти II этап сортировки – слияние отсортированных отрезков Начинаем с чтения
- 22. Двухпутевое слияние c использованием оперативной памяти Далее описанный процесс повторяется, при этом отрезки длины S/2 читаются
- 23. Анализ сортировки Если в исходном файле N записей, и в память помещается одновременно S записей, то
- 24. Сортировка методом многопутевого слияния При использовании метода многопутевой внешней сортировки на каждом шаге примерно половина вспомогательных
- 25. Способы слияния Просмотреть первые записи каждой серии и выбрать из них ту, которая имеет минимальный ключ;
- 26. Пример (N=3) Исходный файл: F: 21 72 19 45 44 40 8 57 77 63 18
- 27. Пример (N=3) Второй проход: F4: 19 21 72| 18 39 63 F5: 40 44 45 |
- 28. Многофазная сортировка (Фибоначчиевая) Идея многофазной сортировки состоит в том, что из имеющихся m вспомогательных файлов (m-1)
- 29. Многофазная сортировка (Фибоначчиевая) Первый шаг. Серии исходного файла распределяются по m-1 вспомогательному файлу. Второй шаг. Выполняется
- 30. Пример Пусть используются три файла B1, B2 и B3.
- 31. Многофазная сортировка (Фибоначчиевая) Вопрос: Каким должно быть распределение?
- 32. Многофазная сортировка (Фибоначчиевая) Метод трехфазной внешней сортировки дает желаемый результат и работает максимально эффективно (на каждом
- 33. Многофазная сортировка (Фибоначчиевая) Последовательность чисел Фибоначчи начинается с 0, 1, а каждое следующее число образуется как
- 34. Многофазная сортировка (Фибоначчиевая) В общем случае при использовании m вспомогательных файлов аналогичным условием успешного завершения и
- 35. Многофазная сортировка (Фибоначчиевая) Числа Фибоначчи p-го порядка определяются правилами: F(n) = F(n-1)+F(n-2)+ … +F(n-p) при n≥p
- 36. Многофазная сортировка (Фибоначчиевая) Поскольку число серий в исходном файле может не обеспечивать возможность такого распределения серий,
- 37. Пример (p=2) Исходный файл: F: 31 72 19 45 44 40 8 57 77 63 13
- 38. Пример (p=2) Начальное распределение: F1: ø| ø | 31 | 72 | 19 | 45 |
- 39. Пример (p=2) Второй проход: F1: F2: 8 45 | 44 57 | 31 40 77 F3:
- 40. Пример (p=2) Четвертый проход: F1: 13 19 44 57 F2: F3: 8 31 40 45 63
- 41. Каскадное слияние Каскадное слияние начинается с точного распределения серий по файлам, хотя правила точного распределения отличны
- 42. Оптимальное количество уровней для N=4
- 43. Каскадное слияние Числа an, bn, cn, dn имеют интересное свойство – их относительные величины являются также
- 44. Каскадное слияние - этапы 1. Распределение. Распределяем элементы по N файлам, согласно оптимальному приведенному выше алгоритму.
- 45. Каскадное слияние - этапы 2. Слияние - прямое На первом шаге сливаем файлы F1, F2, …,
- 46. Каскадное слияние - этапы 3. Слияние – обратное Повторяем процедуру прямого слияния, только в обратном порядке
- 47. Каскадное слияние - этапы 4. Цикл Повторяем этапы 2 и 3 до тех пор, пока все
- 48. Пример (N=4)
- 50. Скачать презентацию

Понятие
Внешняя сортировка – это упорядочивание данных, которые хранятся на внешнем устройстве
Понятие
Внешняя сортировка – это упорядочивание данных, которые хранятся на внешнем устройстве

Понятие
При внешней сортировке прежде всего требуется уменьшить число обращений к этому
Понятие
При внешней сортировке прежде всего требуется уменьшить число обращений к этому

Эффективность алгоритма
Для выяснения эффективности алгоритмов внутренней сортировки подсчитывалось число выполняемых ими
Эффективность алгоритма
Для выяснения эффективности алгоритмов внутренней сортировки подсчитывалось число выполняемых ими

Эффективность алгоритма
При другом подходе можно воспользоваться файлами с прямым доступом и
Эффективность алгоритма
При другом подходе можно воспользоваться файлами с прямым доступом и

Понятие серии
Серией длины K является последовательность записей Ai, Ai+1,…,Ai+k-1 такая, что
Понятие серии
Серией длины K является последовательность записей Ai, Ai+1,…,Ai+k-1 такая, что

Деление на серии
Пусть в некотором файле A хранится одномерный массив:
12 35
Деление на серии
Пусть в некотором файле A хранится одномерный массив: 12 35

Алгоритмы внешней сортировки
Идея большинства методов заключается в расчленении данных на ряд
Алгоритмы внешней сортировки
Идея большинства методов заключается в расчленении данных на ряд

Алгоритмы внешней сортировки
Естественная сортировка (метод естественного слияния)
Сортировка методом двухпутевого сбалансированного слияния
Сортировка
Алгоритмы внешней сортировки
Естественная сортировка (метод естественного слияния)
Сортировка методом двухпутевого сбалансированного слияния
Сортировка

Естественная сортировка
Исходный файл:
F: 20 50 7 30 80 40 60 50
Естественная сортировка
Исходный файл: F: 20 50 7 30 80 40 60 50

Естественная сортировка
Первый проход:
Фаза распределения:
F1: 20 50 | 40 60 | 35
F2:
Естественная сортировка
Первый проход:
Фаза распределения:
F1: 20 50 | 40 60 | 35
F2:

Естественная сортировка
Второй проход:
Фаза распределения:
F1: 7 20 30 50 80 | 25
Естественная сортировка
Второй проход:
Фаза распределения:
F1: 7 20 30 50 80 | 25

Естественная сортировка
Третий проход:
Фаза распределения:
F1: 7 20 30 40 50 50 60
Естественная сортировка
Третий проход:
Фаза распределения:
F1: 7 20 30 40 50 50 60

Двухпутевое слияние
Сортировка методом двухпутевого сбалансированного слияния без использования оперативной памяти
Сбалансированная внешняя
Двухпутевое слияние
Сортировка методом двухпутевого сбалансированного слияния без использования оперативной памяти
Сбалансированная внешняя

Двухпутевое слияние без использования оперативной памяти
Вся сортируемая последовательность данных разбивается на
Двухпутевое слияние без использования оперативной памяти
Вся сортируемая последовательность данных разбивается на

Двухпутевое слияние без использования оперативной памяти
После выполнения i проходов получатся два
Двухпутевое слияние без использования оперативной памяти
После выполнения i проходов получатся два

Пример
Исходные файлы:
f1: 28 3 93 10 54 65 30 90
f2: 31
Пример
Исходные файлы:
f1: 28 3 93 10 54 65 30 90
f2: 31

Пример
Участки длинной 4:
f1: 3 5 28 31 | 9 54 65
Пример
Участки длинной 4:
f1: 3 5 28 31 | 9 54 65

Двухпутевое слияние c использованием оперативной памяти
Пусть у нас есть четыре файла
Двухпутевое слияние c использованием оперативной памяти
Пусть у нас есть четыре файла

Двухпутевое слияние c использованием оперативной памяти
I этап сортировки – распределение
На первом
Двухпутевое слияние c использованием оперативной памяти
I этап сортировки – распределение
На первом

Двухпутевое слияние c использованием оперативной памяти
II этап сортировки – слияние отсортированных
Двухпутевое слияние c использованием оперативной памяти
II этап сортировки – слияние отсортированных

Двухпутевое слияние c использованием оперативной памяти
Далее описанный процесс повторяется, при этом
Двухпутевое слияние c использованием оперативной памяти
Далее описанный процесс повторяется, при этом

Анализ сортировки
Если в исходном файле N записей, и в память помещается
одновременно
Анализ сортировки
Если в исходном файле N записей, и в память помещается одновременно

Сортировка методом многопутевого слияния
При использовании метода многопутевой внешней сортировки на каждом
Сортировка методом многопутевого слияния
При использовании метода многопутевой внешней сортировки на каждом

Способы слияния
Просмотреть первые записи каждой серии и выбрать из них ту,
Способы слияния
Просмотреть первые записи каждой серии и выбрать из них ту,

Пример (N=3)
Исходный файл:
F: 21 72 19 45 44 40 8 57
Пример (N=3)
Исходный файл: F: 21 72 19 45 44 40 8 57

Пример (N=3)
Второй проход:
F4: 19 21 72| 18 39 63
F5: 40 44
Пример (N=3)
Второй проход:
F4: 19 21 72| 18 39 63
F5: 40 44

Многофазная сортировка
(Фибоначчиевая)
Идея многофазной сортировки состоит в том, что из имеющихся m
Многофазная сортировка
(Фибоначчиевая)
Идея многофазной сортировки состоит в том, что из имеющихся m

Многофазная сортировка
(Фибоначчиевая)
Первый шаг. Серии исходного файла распределяются по m-1
вспомогательному файлу.
Второй шаг.
Многофазная сортировка
(Фибоначчиевая)
Первый шаг. Серии исходного файла распределяются по m-1 вспомогательному файлу. Второй шаг.
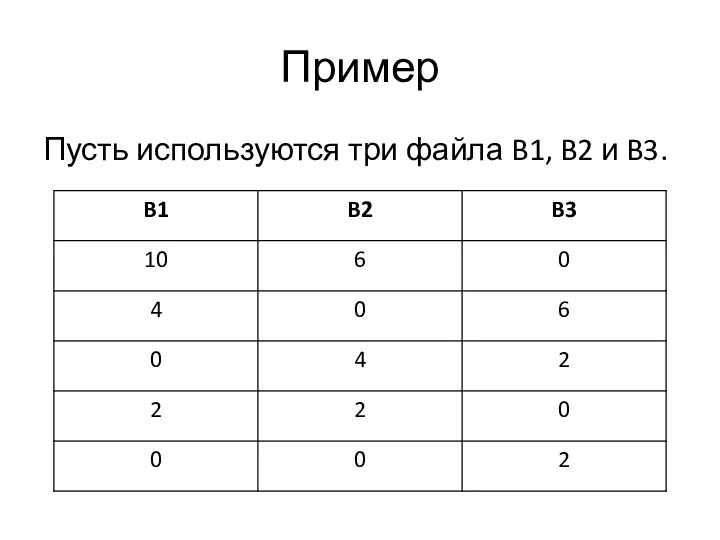
Пример
Пусть используются три файла B1, B2 и B3.
Пример
Пусть используются три файла B1, B2 и B3.
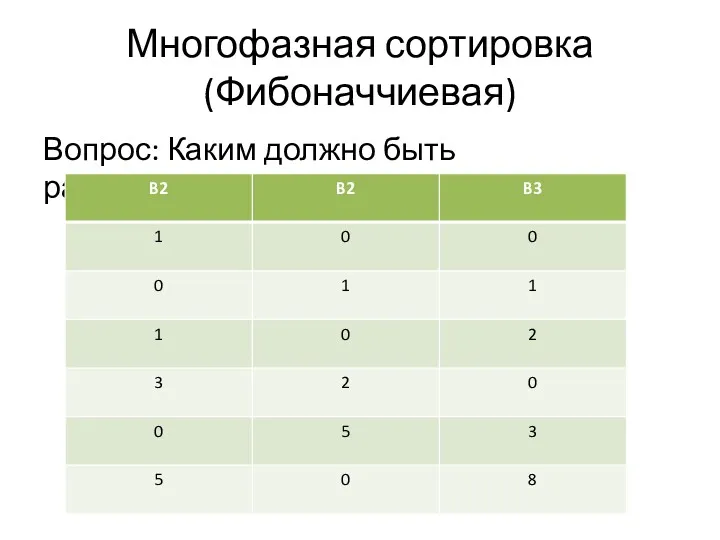
Многофазная сортировка
(Фибоначчиевая)
Вопрос: Каким должно быть распределение?
Многофазная сортировка
(Фибоначчиевая)
Вопрос: Каким должно быть распределение?

Многофазная сортировка
(Фибоначчиевая)
Метод трехфазной внешней сортировки дает желаемый результат и работает максимально
Многофазная сортировка
(Фибоначчиевая)
Метод трехфазной внешней сортировки дает желаемый результат и работает максимально

Многофазная сортировка
(Фибоначчиевая)
Последовательность чисел Фибоначчи начинается с 0, 1, а каждое следующее
Многофазная сортировка
(Фибоначчиевая)
Последовательность чисел Фибоначчи начинается с 0, 1, а каждое следующее

Многофазная сортировка
(Фибоначчиевая)
В общем случае при использовании m вспомогательных файлов аналогичным условием
Многофазная сортировка
(Фибоначчиевая)
В общем случае при использовании m вспомогательных файлов аналогичным условием

Многофазная сортировка
(Фибоначчиевая)
Числа Фибоначчи p-го порядка определяются правилами:
F(n) = F(n-1)+F(n-2)+ … +F(n-p)
Многофазная сортировка
(Фибоначчиевая)
Числа Фибоначчи p-го порядка определяются правилами:
F(n) = F(n-1)+F(n-2)+ … +F(n-p)

Многофазная сортировка
(Фибоначчиевая)
Поскольку число серий в исходном файле может не обеспечивать возможность
Многофазная сортировка
(Фибоначчиевая)
Поскольку число серий в исходном файле может не обеспечивать возможность

Пример (p=2)
Исходный файл:
F: 31 72 19 45 44 40 8 57
Пример (p=2)
Исходный файл: F: 31 72 19 45 44 40 8 57

Пример (p=2)
Начальное распределение:
F1: ø| ø | 31 | 72 | 19
Пример (p=2)
Начальное распределение: F1: ø| ø | 31 | 72 | 19

Пример (p=2)
Второй проход:
F1:
F2: 8 45 | 44 57 | 31 40
Пример (p=2)
Второй проход: F1: F2: 8 45 | 44 57 | 31 40

Пример (p=2)
Четвертый проход:
F1: 13 19 44 57
F2:
F3: 8 31 40
Пример (p=2)
Четвертый проход: F1: 13 19 44 57 F2: F3: 8 31 40

Каскадное слияние
Каскадное слияние начинается с точного распределения серий по файлам, хотя
Каскадное слияние
Каскадное слияние начинается с точного распределения серий по файлам, хотя
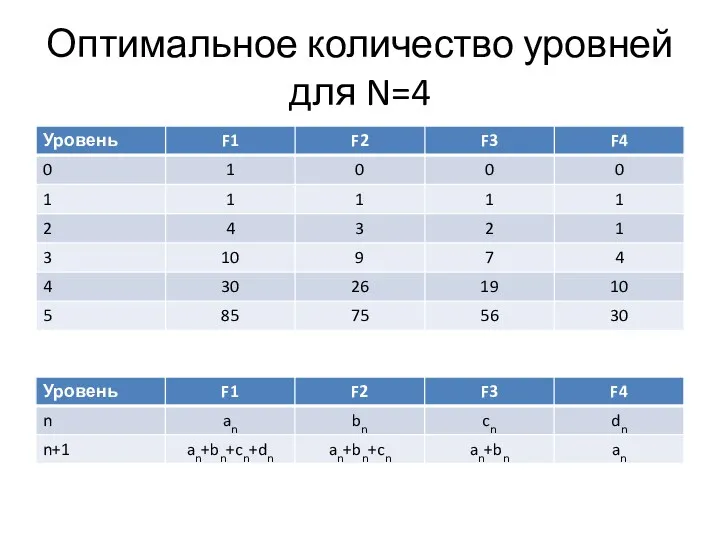
Оптимальное количество уровней для N=4
Оптимальное количество уровней для N=4

Каскадное слияние
Числа an, bn, cn, dn имеют интересное свойство – их
относительные
Каскадное слияние
Числа an, bn, cn, dn имеют интересное свойство – их относительные

Каскадное слияние - этапы
1. Распределение.
Распределяем элементы по N файлам, согласно оптимальному
Каскадное слияние - этапы
1. Распределение. Распределяем элементы по N файлам, согласно оптимальному

Каскадное слияние - этапы
2. Слияние - прямое
На первом шаге сливаем файлы
Каскадное слияние - этапы
2. Слияние - прямое
На первом шаге сливаем файлы

Каскадное слияние - этапы
3. Слияние – обратное
Повторяем процедуру прямого слияния, только
Каскадное слияние - этапы
3. Слияние – обратное
Повторяем процедуру прямого слияния, только

Каскадное слияние - этапы
4. Цикл
Повторяем этапы 2 и 3 до тех
Каскадное слияние - этапы
4. Цикл
Повторяем этапы 2 и 3 до тех
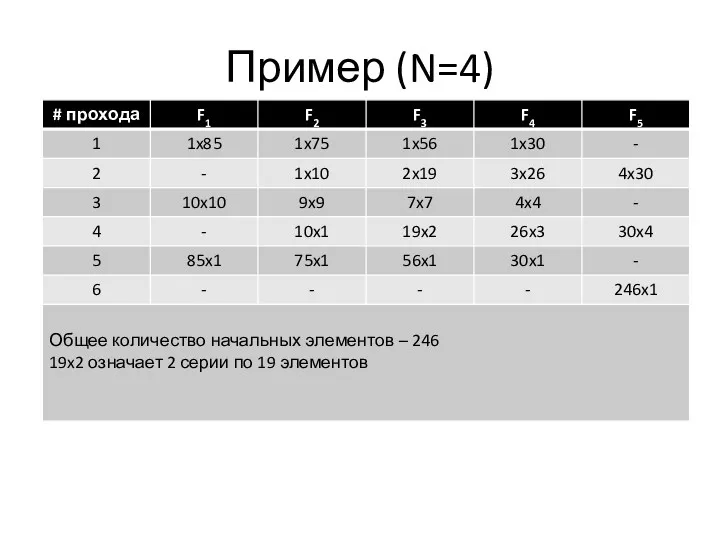
Пример (N=4)
Пример (N=4)
 Государственная система научно-технической информации
Государственная система научно-технической информации Управление освещением витрины
Управление освещением витрины Контент. SEO текст
Контент. SEO текст Anatomy Lesson for Middle School Internal Organs of the Human Body
Anatomy Lesson for Middle School Internal Organs of the Human Body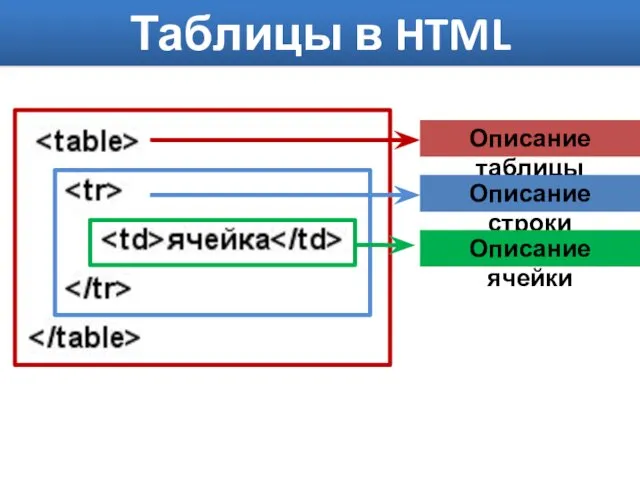 Таблицы в HTML
Таблицы в HTML Помехоустойчивое кодирование в системах телекоммуникаций (ПКСТ)
Помехоустойчивое кодирование в системах телекоммуникаций (ПКСТ) Решение задания ОГЭ по информатике
Решение задания ОГЭ по информатике Программирование (Python). Введение
Программирование (Python). Введение Кодирование, как изменение формы представления информации
Кодирование, как изменение формы представления информации Понятие информация. Виды информации. Основные информационные процессы
Понятие информация. Виды информации. Основные информационные процессы использование игр на уроке информатики в начальной школе
использование игр на уроке информатики в начальной школе Представление числовой информации в таблицах. Повторение
Представление числовой информации в таблицах. Повторение Каналы. Неименованные каналы
Каналы. Неименованные каналы Файловая система и ввод вывод информации
Файловая система и ввод вывод информации Overview software development methodology Аgile.Вusiness approach
Overview software development methodology Аgile.Вusiness approach Решение задач на компьютере. Алгоритмизация и программирование. 9 класс
Решение задач на компьютере. Алгоритмизация и программирование. 9 класс Интервью (событийное) как жанр журналистики (лекция № 6)
Интервью (событийное) как жанр журналистики (лекция № 6) Программирование. Оператор Mod в Visual Basic
Программирование. Оператор Mod в Visual Basic Перевод чисел из 10СС в 2СС
Перевод чисел из 10СС в 2СС Python NumPy. Установка. Массивы
Python NumPy. Установка. Массивы Декодирование. Построение префиксного кода по набору длин элементарных кодов
Декодирование. Построение префиксного кода по набору длин элементарных кодов Язык программирования C++
Язык программирования C++ Способы передачи данных. (Тема 4)
Способы передачи данных. (Тема 4) Графический дизайн для непрофессионалов
Графический дизайн для непрофессионалов Сущность и значение комплектования государственных архивов. Технотронные документы
Сущность и значение комплектования государственных архивов. Технотронные документы Автоматизированная информационная система Молодежь России. Регистрация в АИС
Автоматизированная информационная система Молодежь России. Регистрация в АИС Персональные данные (для детей 9-11 лет)
Персональные данные (для детей 9-11 лет) Создание комплексной системы непрерывного информационного обеспечения для повышение производительности качества сельхозпродукции
Создание комплексной системы непрерывного информационного обеспечения для повышение производительности качества сельхозпродукции