- Современные сети

Содержание
- 2. ML => DL Классика Машинного Обучения = Выделение признаков + модель для обучения Classic Machine Learning
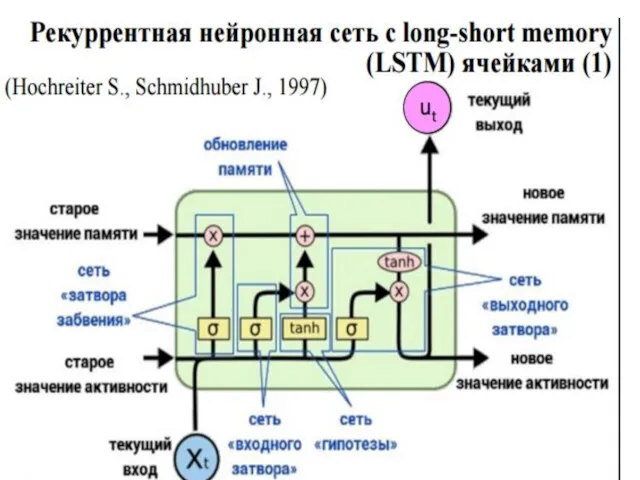
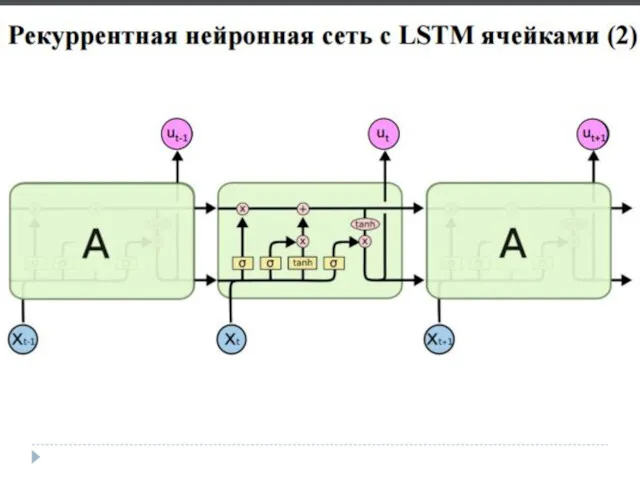
- 3. LSTM Юрген Шмидхубер 1997
- 7. AlexNet DropOut (RIP), Data Augmentation и ReLu.
- 8. AlexNet DropOut (RIP), Data Augmentation и ReLu. 1 неделя обучения на 2 GPUs
- 9. VGG16 16 слоев Вход: изображение размером 224х224 пиксела, 3 канала цвета 2 раза : свертка-свертка-подвыборка, 3
- 10. VGG16
- 11. VGG16 Очень медленная скорость обучения. Cеть слишком большая (появляются проблемы с диском и пропускной способностью)
- 12. VGG19 19 слоев Вход: изображение размером 224х224 пиксела, 3 канала цвета 2 раза : свертка-свертка-подвыборка, 3
- 13. VGG19 Не обучается целиком (затухает градиент) Несколько стадий обучения разной глубины Обучение 4 Titan Black GPUs
- 14. VGG16- VGG16 Задача(https://www.kaggle.com/c/imagenet-object-localization-challenge/data) ImageNet (1000 классов) ≈ 7 % K. Simonyan, A. Zisserman Very Deep Convolutional
- 15. GoogleNet - Inception 144 миллионa параметров Стек сверток (nхn по 3х3) Cascade Cross Chanel Parametric Pooling
- 16. GoogleNet - Inception
- 17. Rethinking the Inception Architecture for Computer Vision (11 Dec 2015) // https://arxiv.org/pdf/1512.00567v3.pdf GoogleNet - Inception
- 18. Макс. глубина: 22 слоя с параметрами Нет полносвязных слоев В 12 раз меньше параметров чем в
- 19. GoogleNet GoogleNet — первая известная сеть с ациклической архитектурой
- 20. ResNet
- 21. residual-функция остаточная функция: Можно обучить на эту функцию
- 22. ResNet
- 23. ResNet - задача ImageNet 3.57% - top5 на Imagenet. 2014 152 слоя
- 24. ResNet+Inception: Inception 4v
- 25. ResNet+Inception Очень глубокая сеть(более 550 слоев) , целиком не обучается (55M параметров) Один и тот же
- 26. DenseNet https://arxiv.org/pdf/1608.06993.pdf
- 27. SqueezeNet convolution layer (conv1), 8 Fire modules (fire2-9), conv layer (conv10)
- 28. SSD
- 29. YOLO Вход: 448x448х3 Почти GoogleNet
- 30. Сиамская сеть
- 31. Сегментация и рисование
- 32. U-net - сегментация
- 33. R-CNN (region CNN)
- 34. принципы построения DCNN для CV Избегайте representational bottlenecks: не стоит резко снижать размерность представления данных, это
- 35. YOLOv2 для генерации изображений Сснижающих качество распознавания
- 37. Резюме https://keras.io/applications/
- 39. Скачать презентацию
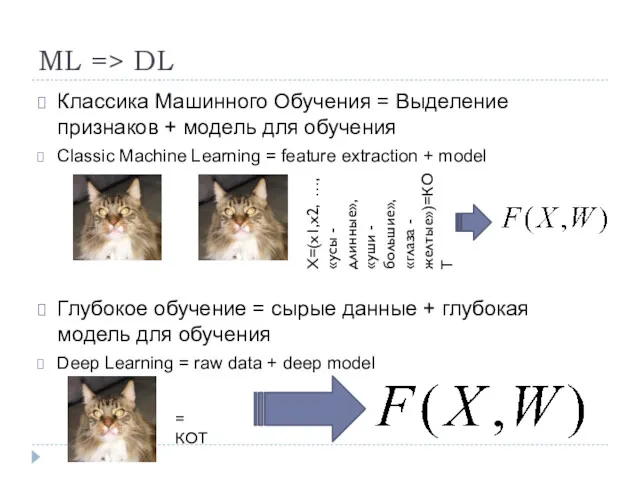
ML => DL
Классика Машинного Обучения = Выделение признаков + модель для
ML => DL
Классика Машинного Обучения = Выделение признаков + модель для

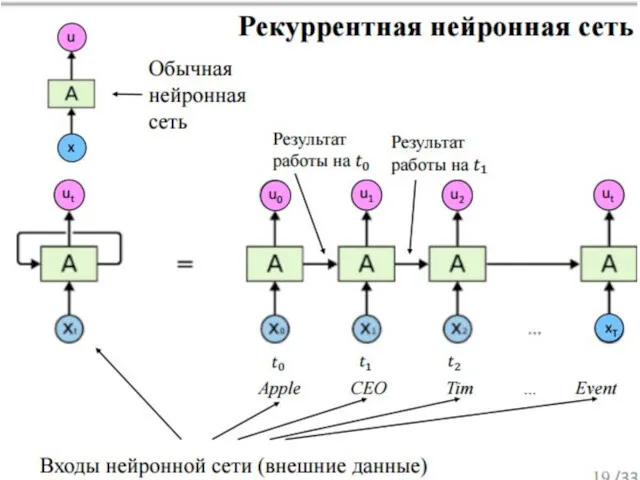
LSTM
Юрген Шмидхубер 1997
LSTM
Юрген Шмидхубер 1997
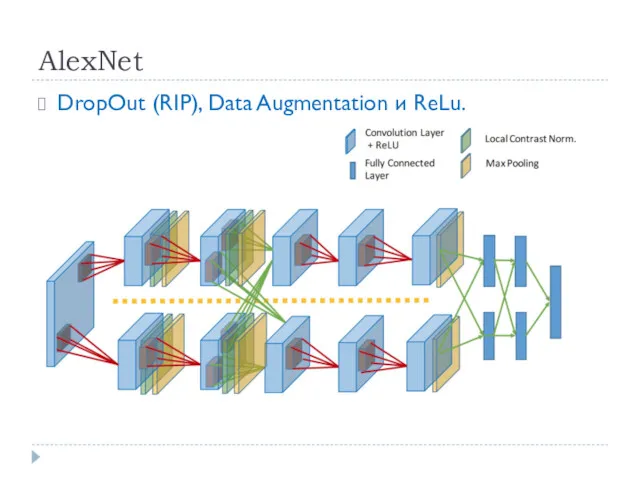
AlexNet
DropOut (RIP), Data Augmentation и ReLu.
AlexNet
DropOut (RIP), Data Augmentation и ReLu.

AlexNet
DropOut (RIP), Data Augmentation и ReLu.
1 неделя обучения на 2 GPUs
AlexNet
DropOut (RIP), Data Augmentation и ReLu.
1 неделя обучения на 2 GPUs

VGG16
16 слоев
Вход: изображение размером 224х224 пиксела, 3 канала цвета
2 раза :
VGG16
16 слоев
Вход: изображение размером 224х224 пиксела, 3 канала цвета
2 раза :
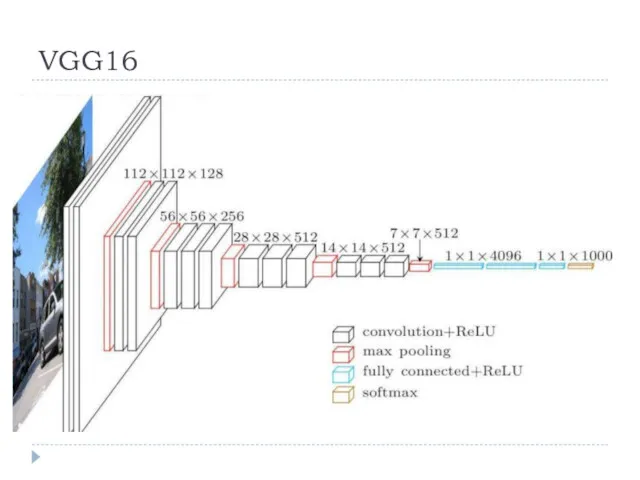
VGG16
VGG16

VGG16
Очень медленная скорость обучения.
Cеть слишком большая (появляются проблемы с диском и
VGG16
Очень медленная скорость обучения.
Cеть слишком большая (появляются проблемы с диском и

VGG19
19 слоев
Вход: изображение размером 224х224 пиксела, 3 канала цвета
2 раза :
VGG19
19 слоев
Вход: изображение размером 224х224 пиксела, 3 канала цвета
2 раза :

VGG19
Не обучается целиком (затухает градиент)
Несколько стадий обучения разной глубины
Обучение 4
VGG19
Не обучается целиком (затухает градиент)
Несколько стадий обучения разной глубины
Обучение 4

VGG16- VGG16
Задача(https://www.kaggle.com/c/imagenet-object-localization-challenge/data)
ImageNet (1000 классов) ≈ 7 %
K. Simonyan, A. Zisserman
Very Deep
VGG16- VGG16
Задача(https://www.kaggle.com/c/imagenet-object-localization-challenge/data)
ImageNet (1000 классов) ≈ 7 %
K. Simonyan, A. Zisserman
Very Deep
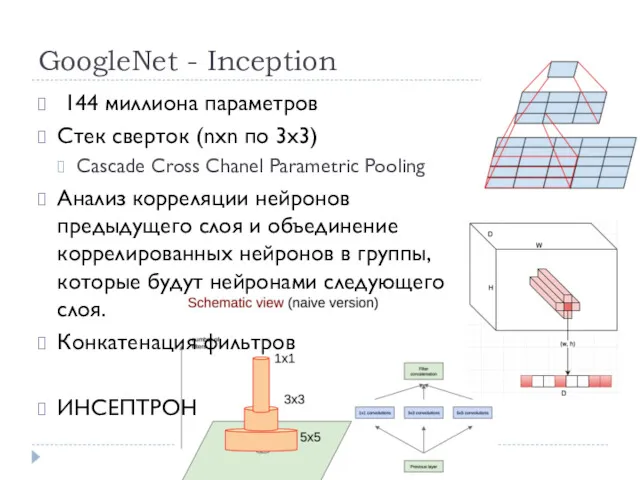
GoogleNet - Inception
144 миллионa параметров
Стек сверток (nхn по 3х3)
Cascade Cross Chanel
GoogleNet - Inception
144 миллионa параметров
Стек сверток (nхn по 3х3)
Cascade Cross Chanel
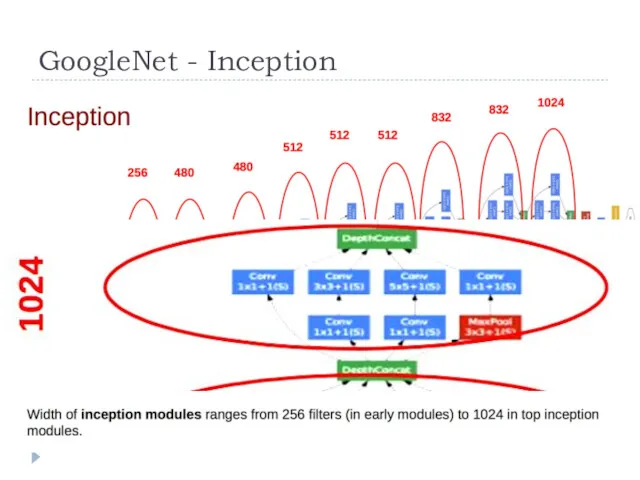
GoogleNet - Inception
GoogleNet - Inception
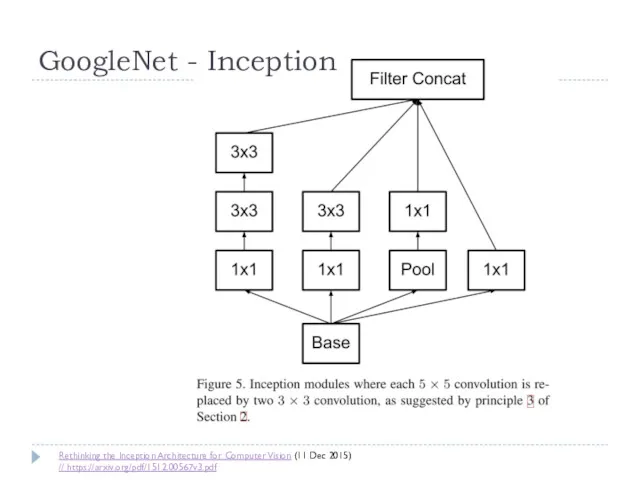
Rethinking the Inception Architecture for Computer Vision (11 Dec 2015)
// https://arxiv.org/pdf/1512.00567v3.pdf
GoogleNet -
Rethinking the Inception Architecture for Computer Vision (11 Dec 2015)
// https://arxiv.org/pdf/1512.00567v3.pdf
GoogleNet -
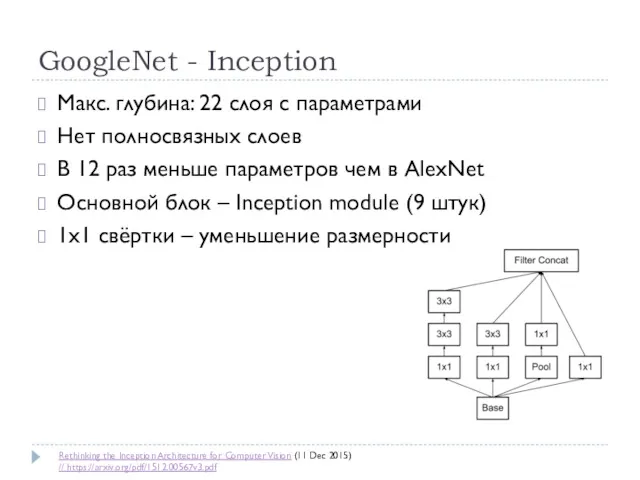
Макс. глубина: 22 слоя с параметрами
Нет полносвязных слоев
В 12 раз меньше
Макс. глубина: 22 слоя с параметрами
Нет полносвязных слоев
В 12 раз меньше

GoogleNet
GoogleNet — первая известная сеть с ациклической архитектурой
GoogleNet
GoogleNet — первая известная сеть с ациклической архитектурой
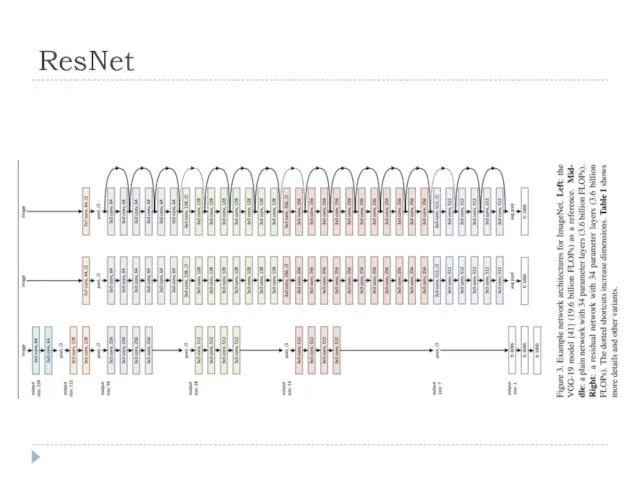
ResNet
ResNet

residual-функция
остаточная функция:
Можно обучить на эту функцию
residual-функция
остаточная функция:
Можно обучить на эту функцию
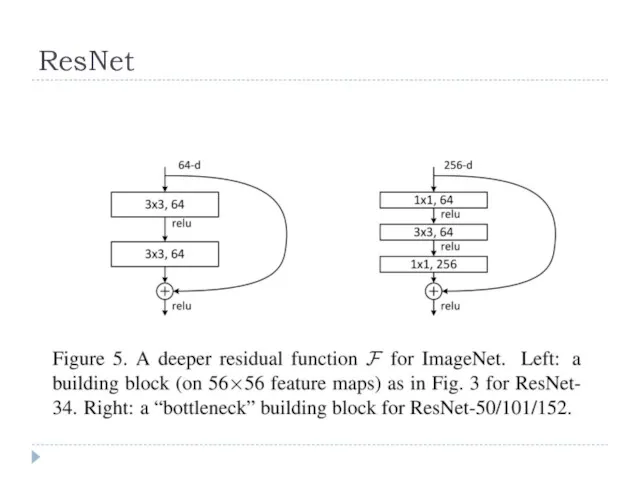
ResNet
ResNet

ResNet - задача
ImageNet
3.57% - top5 на Imagenet. 2014
152 слоя
ResNet - задача
ImageNet
3.57% - top5 на Imagenet. 2014
152 слоя
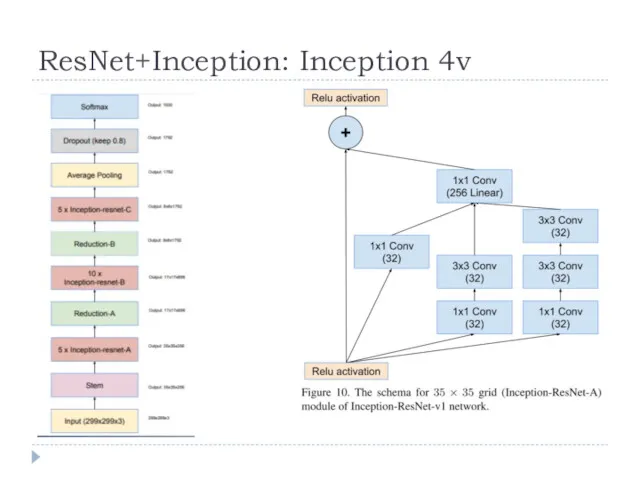
ResNet+Inception: Inception 4v
ResNet+Inception: Inception 4v

ResNet+Inception
Очень глубокая сеть(более 550 слоев) , целиком не обучается (55M параметров)
Один
ResNet+Inception
Очень глубокая сеть(более 550 слоев) , целиком не обучается (55M параметров)
Один

DenseNet
https://arxiv.org/pdf/1608.06993.pdf
DenseNet
https://arxiv.org/pdf/1608.06993.pdf

SqueezeNet
convolution layer (conv1),
8 Fire modules (fire2-9),
conv layer (conv10)
SqueezeNet
convolution layer (conv1),
8 Fire modules (fire2-9),
conv layer (conv10)
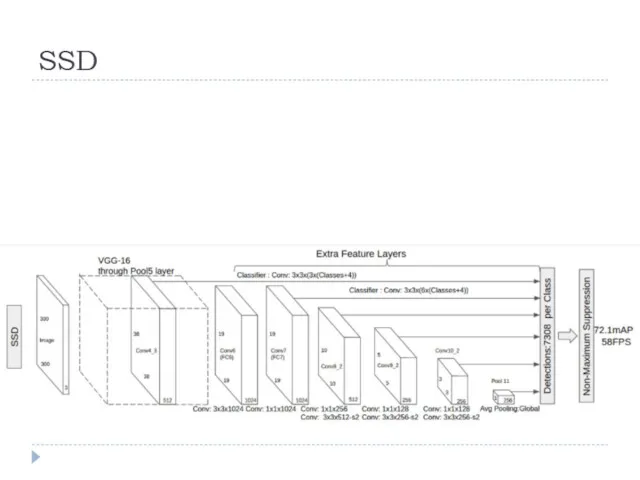
SSD
SSD
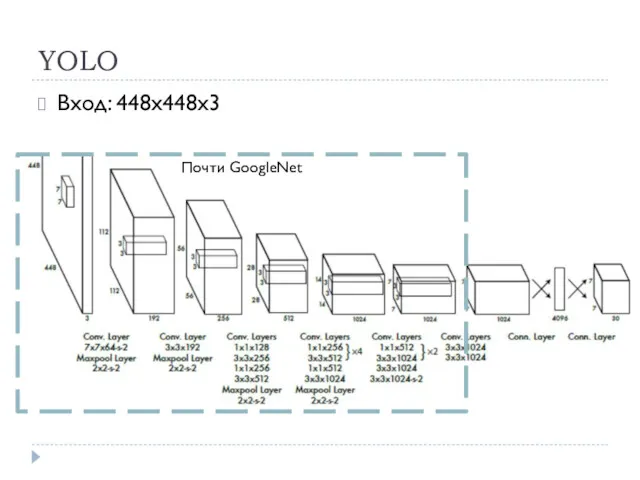
YOLO
Вход: 448x448х3
Почти GoogleNet
YOLO
Вход: 448x448х3
Почти GoogleNet
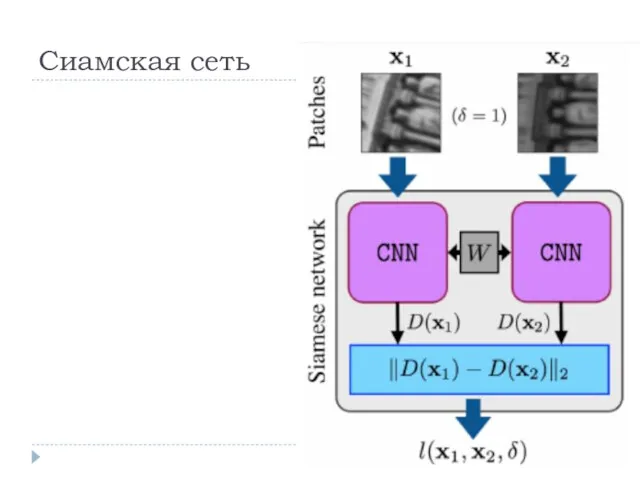
Сиамская сеть
Сиамская сеть
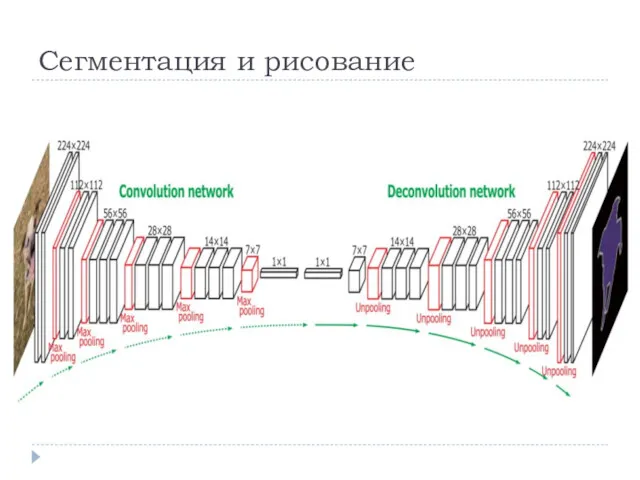
Сегментация и рисование
Сегментация и рисование
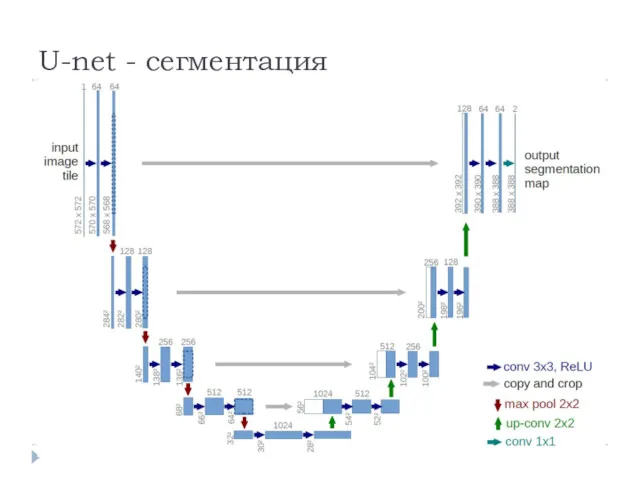
U-net - сегментация
U-net - сегментация
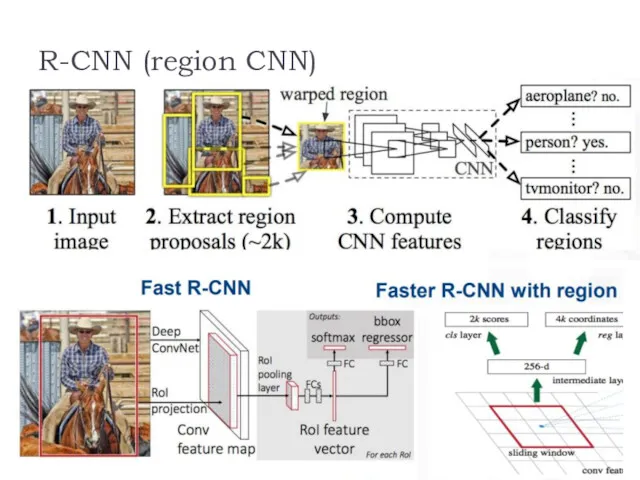
R-CNN (region CNN)
R-CNN (region CNN)

принципы построения DCNN для CV
Избегайте representational bottlenecks: не стоит резко снижать
принципы построения DCNN для CV
Избегайте representational bottlenecks: не стоит резко снижать

YOLOv2 для генерации изображений
Сснижающих качество распознавания
YOLOv2 для генерации изображений
Сснижающих качество распознавания
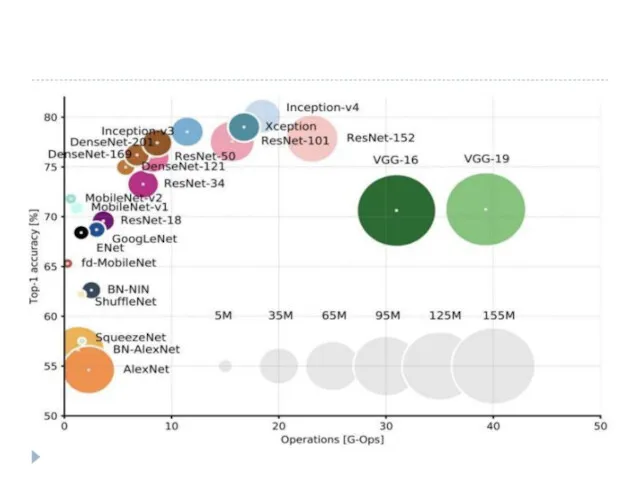
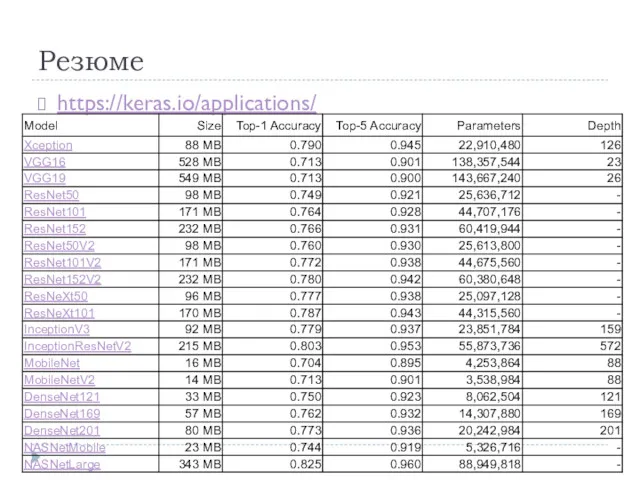
Резюме
https://keras.io/applications/
Резюме
https://keras.io/applications/
 2. Java Spring Core 2. Maven
2. Java Spring Core 2. Maven Методы, технология и инструменты программирования
Методы, технология и инструменты программирования Корпусная лингвистика
Корпусная лингвистика Просмотр достопримечательностей через веб-камеру
Просмотр достопримечательностей через веб-камеру Классические методы шифрования. Лекция 4 (ч.2)
Классические методы шифрования. Лекция 4 (ч.2) Вставка рисунка и гиперссылки Рисунки в таблице Фотогалерея
Вставка рисунка и гиперссылки Рисунки в таблице Фотогалерея Servlets and WebServices. Integration and Frameworks
Servlets and WebServices. Integration and Frameworks Управление в автоматизированном производстве (01)
Управление в автоматизированном производстве (01) Основы программирования (АлгЯзык)
Основы программирования (АлгЯзык) Разработка автоматизированной системы билетной кассы театра
Разработка автоматизированной системы билетной кассы театра Проект администрируемой сети на базе сервера
Проект администрируемой сети на базе сервера Орта мектепте химия пәнінен типтік есептер шығаруда ақпараттық технологияны қолдану әдістері
Орта мектепте химия пәнінен типтік есептер шығаруда ақпараттық технологияны қолдану әдістері Облачные хранилища данных
Облачные хранилища данных JavaScript. Занятие №18
JavaScript. Занятие №18 Вас вітає Жденіївська селищна бібліотека
Вас вітає Жденіївська селищна бібліотека Онлайн меню для ресторанов
Онлайн меню для ресторанов Установка и программирование. Позиционирование систем NEC
Установка и программирование. Позиционирование систем NEC Глобальна комп’ютерна мережа. Урок 9. Інформатика. 5 класс
Глобальна комп’ютерна мережа. Урок 9. Інформатика. 5 класс Программирование графических объектов в среде Pascal ABC
Программирование графических объектов в среде Pascal ABC Текстовая информация. Текст как форма представления информации. Текстовые документы
Текстовая информация. Текст как форма представления информации. Текстовые документы Алгоритмы с ветвлениями, 6 класс
Алгоритмы с ветвлениями, 6 класс Социальные сети в деятельности библиотек
Социальные сети в деятельности библиотек Инструкция по использованию программы GSFS для отчитывания ремонтов
Инструкция по использованию программы GSFS для отчитывания ремонтов Основные блоки ПК
Основные блоки ПК Презентация Вечер информатики в Шипунихинской школе
Презентация Вечер информатики в Шипунихинской школе Java OOP/OOD concepts
Java OOP/OOD concepts Создание мультфильма в программе powerpoint. (5 класс)
Создание мультфильма в программе powerpoint. (5 класс) Telegram. Характеристика
Telegram. Характеристика