- Среда параллельного программирования MPI (Message Passing Interface)

Содержание
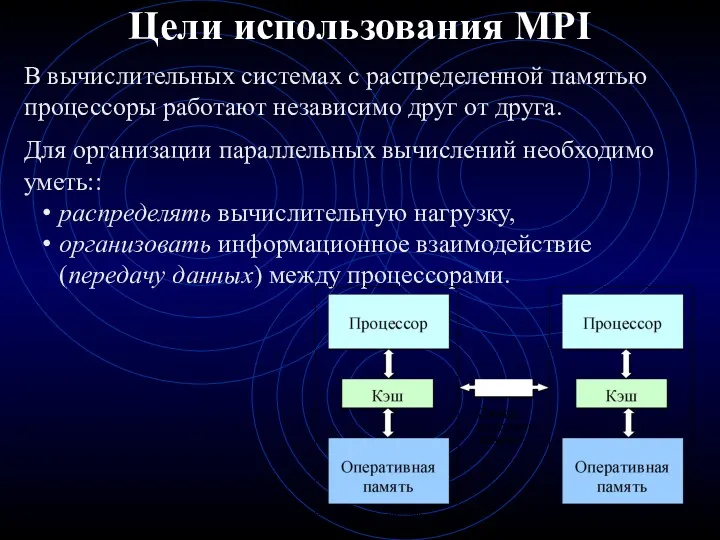
- 2. Цели использования MPI В вычислительных системах с распределенной памятью процессоры работают независимо друг от друга. Для
- 3. Работа с MPI «одна программа – много процессов» В рамках MPI для решения задачи разрабатывается одна
- 4. Работа с MPI - организация различия в вычислениях Для организации различных вычислений на разных процессорах можно
- 5. Преимущества MPI MPI позволяет существенно снизить остроту проблемы переносимости параллельных программ между разными компьютерными системами. MPI
- 6. Работа с MPI MPI подключается как обычная библиотека. После установки и настройки реализации MPI в проект
- 7. путь для include файлов
- 8. прописать путь к .lib файлам
- 9. Добавить msmpi.lib к подключаемым библиотекам:
- 10. Запуск Под параллельной программой в рамках MPI понимается множество одновременно выполняемых процессов: Процессы могут выполняться на
- 11. Запуск Вариант : mpiexec из C:\Program Files\Microsoft HPC Pack 2008 SDK\Bin Параметры mpiexec –n
- 12. Основные термины MPI Коммуникатор – контекст взаимодействия процессов с помощью функций MPI. За коммуникатором закрепляется некоторая
- 13. Основные термины MPI В программе коммуникатор - специально создаваемый служебный объект, объединяющий в своем составе группу
- 14. Основные термины MPI MPI_COMM_WORLD – предопределенная в библиотеке MPI константа, представляющая коммуникатор, включающий все процессы запущенной
- 15. Основные термины MPI Все функции начинаются с префикса MPI_ int MPI_Init(int *argc, char **argv); int MPI_Finalize(void);
- 16. Структура MPI-программы Запуск (MPI_Init) Инициализация среды выполнения MPI Вычисления Завершение среды выполнения MPI (MPI_Finalize(); ) Выгрузка
- 17. MPI-Init() - Инициализация среды выполнения MPI-программы MPI_Init(argc, argv) [INOUT] argc – количество параметров командной строки запуска
- 18. завершение среды выполнения MPI-программы MPI_Finalize() Функция MPI_Finalize освобождает ресурсы, занятые средой выполнения MPI.
- 19. пример #include #include // Подключаемый файл библиотеки MPI int main(int argc, char* argv[]) { int ierr;
- 20. Общая организация MPI MPI-программа представляет собой набор независимых процессов, каждый из которых выполняет свою собственную программу.
- 21. Общая организация MPI - Группы процессов :MPI_COMM_WORLD - все процессы приложения MPI_Comm_Split( … ) - разбить
- 22. Общая организация MPI - Функции функции инициализации и закрытия MPI процессов; функции, реализующие коммуникационные операции типа
- 23. Функции MPI Возвращают : MPI_SUCCESS - успешное завершение Код ошибки Типы: Блокирующие (MPI_Send(…), MPI_Recv(…), MPI_WaitAll()… )
- 24. Способ выполнения функций MPI Локальная функция - выполняется внутри вызывающего процесса. Ее завершение не требует коммуникаций.
- 25. Способ выполнения функций MPI Блокирующая функция - возврат управления из процедуры гарантирует возможность повторного использования параметров,
- 26. Сообщения Сообщения - данные, передаваемые между процессами, вместе с дополнительной информацией - их описанием Сообщения помечаются
- 27. Оболочка сообщения Оболочка сообщения содержит: Ранг процесса-источника сообщения Ранг процесса-получателя сообщения Количество передаваемых в сообщении данных
- 28. Соответствие между MPI-типами и типами языка C Тип MPI Тип языка C++ MPI_CHAR signed char MPI_SHORT
- 29. MPI-типы данных: производные типы Во всех функциях передачи данных сообщения представляют собой некоторый непрерывный вектор элементов
- 30. MPI-типы данных: производные типы Что делать, если пересылаемые данные могут располагаться не рядом и состоять из
- 31. Способы создания производных типов Непрерывный способ конструирования (кол-во элементов одного типа) MPI_Type_contiguous (2, oldtype, &newtype); Векторный
- 32. MPI производные типы данных: карта типа и сигнатура типа Задание типа в MPI принято осуществлять при
- 33. Пример карты типа и сигнатуры типа Функция int MPI_Type_contiguous(int count,MPI_Data_type oldtype, MPI_Datatype *newtype); Пусть исходный тип
- 34. MPI производные типы данных: структура Структурный способ конструирования нового типа данных Int MPI_Type_struct(count, blockLength, offset, oldTypes,
- 35. MPI производные типы данных перед использованием созданный тип должен быть объявлен При завершении использования производный тип
- 36. Базовые функции Инициализация и завершение int MPI_Init(int *argc, char ***argv) процессу при инициализации передаются аргументы функции
- 37. Функция определения числа процессов int MPI_Comm_size(MPI_Comm comm, int *size); IN comm - коммуникатор; OUT size -
- 38. Функция определения номера процесса MPI_Comm_rank int MPI_Comm_rank(MPI_Comm comm, int *rank) Функция возвращает номер процесса, вызвавшего эту
- 39. Функции передачи сообщения с блокировкой int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag,
- 40. Функции приема сообщения с блокировкой int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int dest, int tag,
- 41. Пример – вычисление числа π Значение числа π может быть получено при помощи интеграла Для численного
- 42. Пример (1) – вычисление числа π #include "mpi.h" #include double f(double a) { // подынтегральная функция
- 43. Пример (2) – вычисление числа π # while (!done ) { // основной цикл вычислений if
- 44. Пример (3) – вычисление числа π if (n > 0) { // вычисление локальных сумм h
- 45. Пример (4) – вычисление числа π if ( ProcRank == 0 ) { // вывод результатов
- 46. Функции MPI - продолжение
- 47. Функция MPI_Probe(…) MPI_Status status; int dataSize; // узнали статус сообщения: MPI_Probe(MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COM_WORLD, & status) ;
- 48. Функция MPI_Probe(…) для получения данных разных типов MPI_Status status; int dataSize; // узнали статус сообщения: MPI_Probe(MPI_ANY_SOURCE,
- 49. Джокеры MPI_ANY_SOURCE – любой номер задачи MPI_ANY_TAG -- любой идентификатор сообщения MPI_COMM_WORLD -- любая область связи
- 50. Блокировка приема сообщения Функция MPI_Recv является блокирующей для процесса-получателя, т.е. его выполнение приостанавливается до завершения работы
- 51. Объединенная конструкция приема-передачи - проблемы Процесс 1: (БЛОКИРОВКА!!!) Recv( …2 …); Send(…2…); Процесс 2: Recv( …1
- 52. Объединенная конструкция приема-передачи MPI_Sendrecv() MPI_Sendrecv( … ); 12 параметров = 5 (send) + 7 (recv) Свойства:
- 53. Объединенная конструкция приема-передачи MPI_Sendrecv_replace() MPI_Sendrecv_replace( … ); 12 параметров = 5 (send) + 7 (recv) -1
- 54. Замеры времени выполнения для оценки достигаемого ускорения за счет использования параллелизма необходимо определять время выполнения вычислений.
- 55. Функция отсчета времени double MPI_Wtime(void) Функция возвращает астрономическое время в секундах, прошедшее с некоторого момента в
- 56. Синхронизация вычислений Функция MPI_Barrier(commuicator) определяет коллективную операцию, при использовании должна вызываться всеми процессами коммуникатора. Продолжение вычислений
- 57. Схема простейшего алгоритма
- 58. Пример шаблона кода int res = MPI_Init(int *argc, char ***argv) ; MPI_Comm_rank( …&myNum…. ); MPI_Comm_size( …
- 59. Коллективные функции - рассылка Функция MPI_Scatter разбивает сообщение из буфера посылки процесса root на равные части
- 60. Коллективные функции - рассылка Пример использования функции MPI_Scatter MPI_Comm comm; int rbuf[100], gsize; int root, *array;
- 61. Коллективные функции - прием Функция MPI_Gather производит сборку блоков данных, посылаемых всеми процессами группы, в один
- 62. Коллективные функции - прием Пример программы с использованием функции MPI_Gather: MPI_Comm comm; int array[100]; int root,
- 63. Коллективные функции - векторный вариант int MPI_Scatterv(void* sendbuf, int *sendcounts, int *displs, MPI_Datatype sendtype, void* recvbuf,
- 64. Пример шаблона кода с коллективными функциями int res = MPI_Init(int *argc, char ***argv) ; int myNum
- 65. Дополнительные функции MPI_Alltoall(…) Обобщенная передача данных от всех процессов всем процессам Вызов функции MPI_Alltoall при выполнении
- 67. Скачать презентацию
Цели использования MPI
В вычислительных системах с распределенной памятью процессоры работают независимо
Цели использования MPI
В вычислительных системах с распределенной памятью процессоры работают независимо

Работа с MPI
«одна программа – много процессов»
В рамках MPI для решения
Работа с MPI
«одна программа – много процессов»
В рамках MPI для решения

Работа с MPI -
организация различия в вычислениях
Для организации различных вычислений
Работа с MPI -
организация различия в вычислениях
Для организации различных вычислений

Преимущества MPI
MPI позволяет существенно снизить остроту проблемы переносимости параллельных программ между
Преимущества MPI
MPI позволяет существенно снизить остроту проблемы переносимости параллельных программ между

Работа с MPI
MPI подключается как обычная библиотека. После установки и настройки
Работа с MPI
MPI подключается как обычная библиотека. После установки и настройки
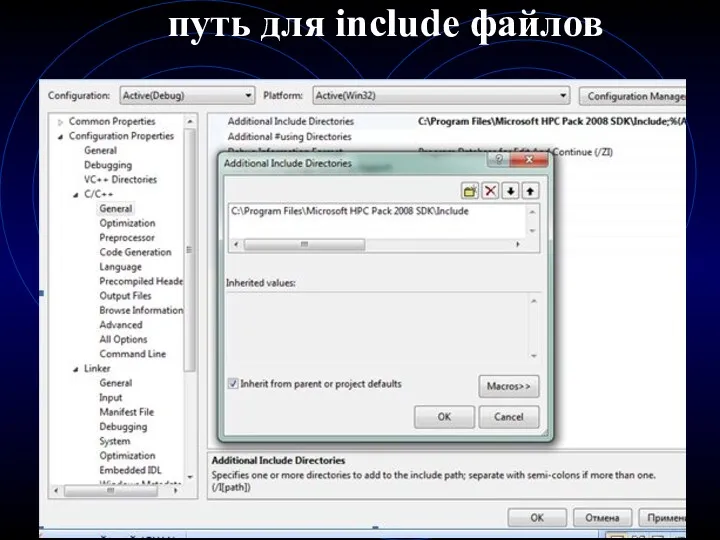
путь для include файлов
путь для include файлов
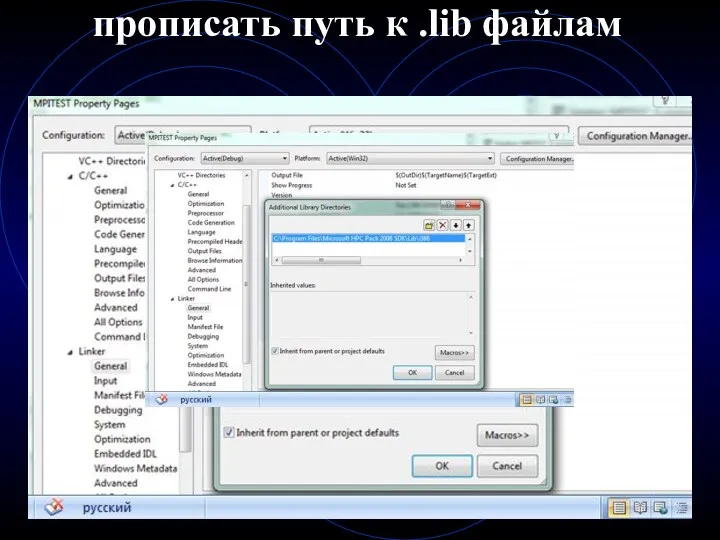
прописать путь к .lib файлам
прописать путь к .lib файлам
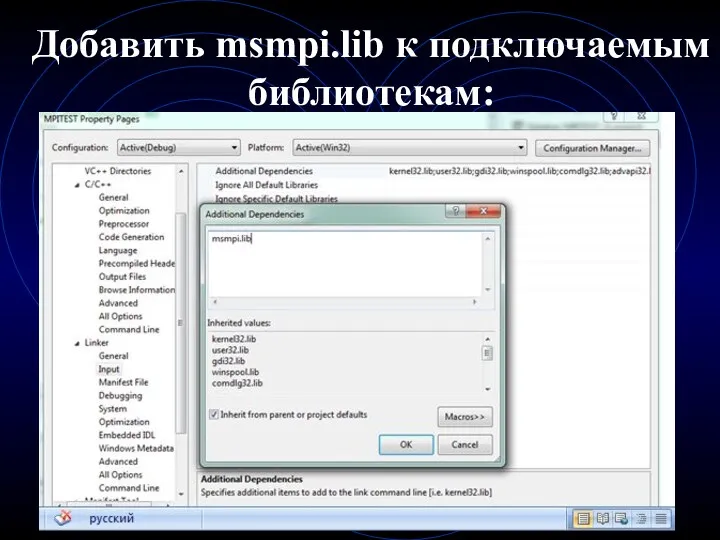
Добавить msmpi.lib к подключаемым библиотекам:
Добавить msmpi.lib к подключаемым библиотекам:

Запуск
Под параллельной программой в рамках MPI понимается множество одновременно выполняемых
Запуск
Под параллельной программой в рамках MPI понимается множество одновременно выполняемых

Запуск
Вариант : mpiexec из
C:\Program Files\Microsoft HPC Pack 2008 SDK\Bin
Параметры
mpiexec
Запуск
Вариант : mpiexec из
C:\Program Files\Microsoft HPC Pack 2008 SDK\Bin
Параметры
mpiexec

Основные термины MPI
Коммуникатор – контекст взаимодействия процессов с помощью функций
Основные термины MPI
Коммуникатор – контекст взаимодействия процессов с помощью функций

Основные термины MPI
В программе коммуникатор - специально создаваемый служебный объект,
Основные термины MPI
В программе коммуникатор - специально создаваемый служебный объект,

Основные термины MPI
MPI_COMM_WORLD – предопределенная в библиотеке MPI константа, представляющая
Основные термины MPI
MPI_COMM_WORLD – предопределенная в библиотеке MPI константа, представляющая

Основные термины MPI
Все функции начинаются с префикса MPI_
int MPI_Init(int *argc,
Основные термины MPI
Все функции начинаются с префикса MPI_
int MPI_Init(int *argc,

Структура MPI-программы
Запуск (MPI_Init)
Инициализация среды выполнения MPI
Вычисления
Завершение среды выполнения
Структура MPI-программы
Запуск (MPI_Init)
Инициализация среды выполнения MPI
Вычисления
Завершение среды выполнения
![MPI-Init() - Инициализация среды выполнения MPI-программы MPI_Init(argc, argv) [INOUT] argc](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/290218/slide-16.jpg)
MPI-Init() - Инициализация среды выполнения MPI-программы
MPI_Init(argc, argv)
[INOUT] argc –
MPI-Init() - Инициализация среды выполнения MPI-программы
MPI_Init(argc, argv)
[INOUT] argc –

завершение среды выполнения
MPI-программы
MPI_Finalize()
Функция MPI_Finalize освобождает ресурсы, занятые средой
завершение среды выполнения
MPI-программы
MPI_Finalize()
Функция MPI_Finalize освобождает ресурсы, занятые средой

пример
#include
#include
// Подключаемый файл библиотеки MPI
int
пример
#include
#include
// Подключаемый файл библиотеки MPI
int

Общая организация MPI
MPI-программа представляет собой набор независимых процессов, каждый из которых
Общая организация MPI
MPI-программа представляет собой набор независимых процессов, каждый из которых

Общая организация MPI - Группы процессов
:MPI_COMM_WORLD - все процессы приложения
MPI_Comm_Split( …
Общая организация MPI - Группы процессов
:MPI_COMM_WORLD - все процессы приложения
MPI_Comm_Split( …

Общая организация MPI - Функции
функции инициализации и закрытия MPI процессов;
Общая организация MPI - Функции
функции инициализации и закрытия MPI процессов;

Функции MPI
Возвращают :
MPI_SUCCESS - успешное завершение
Код ошибки
Типы:
Блокирующие (MPI_Send(…), MPI_Recv(…), MPI_WaitAll()…
Функции MPI
Возвращают :
MPI_SUCCESS - успешное завершение
Код ошибки
Типы:
Блокирующие (MPI_Send(…), MPI_Recv(…), MPI_WaitAll()…

Способ выполнения функций MPI
Локальная функция - выполняется внутри вызывающего процесса. Ее
Способ выполнения функций MPI
Локальная функция - выполняется внутри вызывающего процесса. Ее

Способ выполнения функций MPI
Блокирующая функция - возврат управления из процедуры гарантирует
Способ выполнения функций MPI
Блокирующая функция - возврат управления из процедуры гарантирует

Сообщения
Сообщения - данные, передаваемые между процессами, вместе с дополнительной информацией -
Сообщения
Сообщения - данные, передаваемые между процессами, вместе с дополнительной информацией -
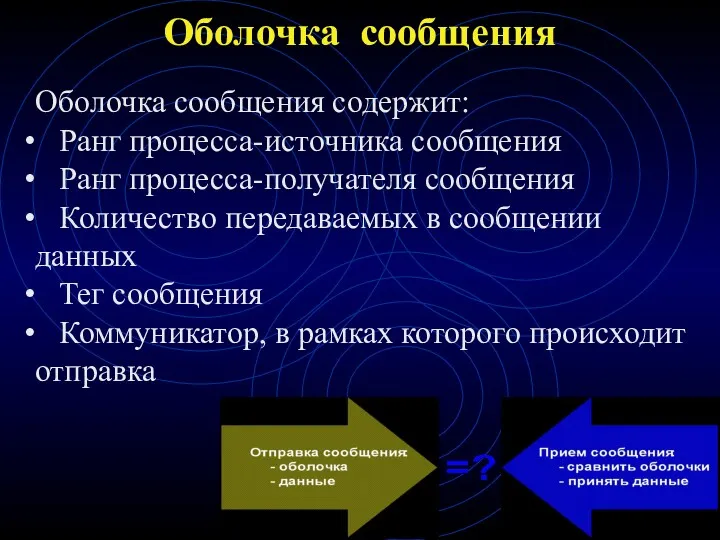
Оболочка сообщения
Оболочка сообщения содержит:
Ранг процесса-источника сообщения
Ранг процесса-получателя сообщения
Количество
Оболочка сообщения
Оболочка сообщения содержит:
Ранг процесса-источника сообщения
Ранг процесса-получателя сообщения
Количество

Соответствие между MPI-типами и типами языка C
Тип MPI Тип языка
Соответствие между MPI-типами и типами языка C
Тип MPI Тип языка

MPI-типы данных: производные типы
Во всех функциях передачи данных сообщения представляют
MPI-типы данных: производные типы
Во всех функциях передачи данных сообщения представляют

MPI-типы данных: производные типы
Что делать, если пересылаемые данные могут располагаться
MPI-типы данных: производные типы
Что делать, если пересылаемые данные могут располагаться

Способы создания производных типов
Непрерывный способ конструирования (кол-во элементов одного типа)
MPI_Type_contiguous
Способы создания производных типов
Непрерывный способ конструирования (кол-во элементов одного типа)
MPI_Type_contiguous

MPI производные типы данных: карта типа и сигнатура типа
Задание типа
MPI производные типы данных: карта типа и сигнатура типа
Задание типа

Пример карты типа и сигнатуры типа
Функция
int MPI_Type_contiguous(int count,MPI_Data_type oldtype, MPI_Datatype *newtype);
Пример карты типа и сигнатуры типа Функция int MPI_Type_contiguous(int count,MPI_Data_type oldtype, MPI_Datatype *newtype);

MPI производные типы данных:
структура
Структурный способ конструирования нового типа данных
Int MPI_Type_struct(count,
MPI производные типы данных:
структура
Структурный способ конструирования нового типа данных
Int MPI_Type_struct(count,

MPI производные типы данных
перед использованием созданный тип должен быть объявлен
При
MPI производные типы данных
перед использованием созданный тип должен быть объявлен
При

Базовые функции
Инициализация и завершение
int MPI_Init(int *argc, char ***argv)
процессу при
Базовые функции
Инициализация и завершение
int MPI_Init(int *argc, char ***argv)
процессу при

Функция определения числа процессов
int MPI_Comm_size(MPI_Comm comm, int *size);
IN comm
Функция определения числа процессов
int MPI_Comm_size(MPI_Comm comm, int *size);
IN comm

Функция определения номера процесса MPI_Comm_rank
int MPI_Comm_rank(MPI_Comm comm, int *rank)
Функция
Функция определения номера процесса MPI_Comm_rank
int MPI_Comm_rank(MPI_Comm comm, int *rank)
Функция

Функции передачи сообщения с блокировкой
int MPI_Send(void* buf, int count, MPI_Datatype datatype,
Функции передачи сообщения с блокировкой
int MPI_Send(void* buf, int count, MPI_Datatype datatype,

Функции приема сообщения с блокировкой
int MPI_Recv(void* buf, int count, MPI_Datatype datatype,
Функции приема сообщения с блокировкой
int MPI_Recv(void* buf, int count, MPI_Datatype datatype,
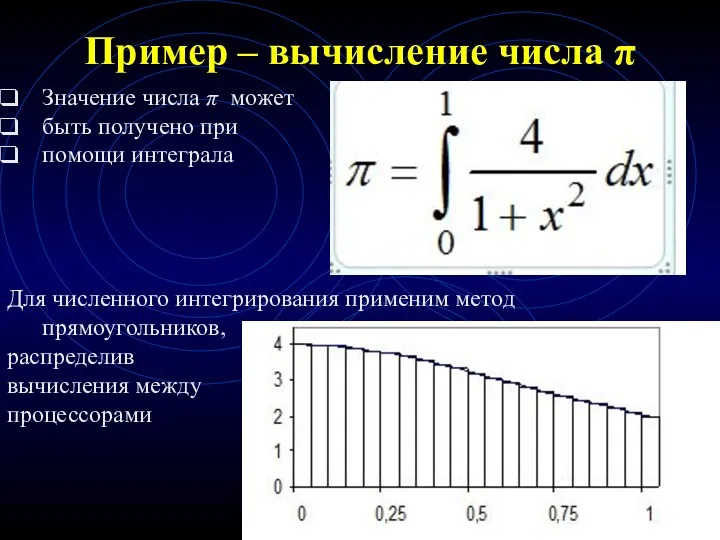
Пример – вычисление числа π
Значение числа π может
быть получено при
Пример – вычисление числа π
Значение числа π может
быть получено при

Пример (1) – вычисление числа π
#include "mpi.h"
#include
double
Пример (1) – вычисление числа π
#include "mpi.h"
#include
double

Пример (2) – вычисление числа π
# while (!done ) {
Пример (2) – вычисление числа π
# while (!done ) {

Пример (3) – вычисление числа π
if (n > 0) { //
Пример (3) – вычисление числа π
if (n > 0) { //

Пример (4) – вычисление числа π
if ( ProcRank == 0
Пример (4) – вычисление числа π
if ( ProcRank == 0

Функции MPI - продолжение
Функции MPI - продолжение

Функция MPI_Probe(…)
MPI_Status status;
int dataSize;
// узнали статус сообщения:
MPI_Probe(MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COM_WORLD,
Функция MPI_Probe(…)
MPI_Status status;
int dataSize;
// узнали статус сообщения:
MPI_Probe(MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COM_WORLD,

Функция MPI_Probe(…) для получения данных разных типов
MPI_Status status;
int dataSize;
// узнали
Функция MPI_Probe(…) для получения данных разных типов
MPI_Status status;
int dataSize;
// узнали

Джокеры
MPI_ANY_SOURCE – любой номер задачи
MPI_ANY_TAG -- любой идентификатор сообщения
MPI_COMM_WORLD -- любая
Джокеры
MPI_ANY_SOURCE – любой номер задачи
MPI_ANY_TAG -- любой идентификатор сообщения
MPI_COMM_WORLD -- любая

Блокировка приема сообщения
Функция MPI_Recv является блокирующей для процесса-получателя, т.е. его
Блокировка приема сообщения
Функция MPI_Recv является блокирующей для процесса-получателя, т.е. его

Объединенная конструкция приема-передачи - проблемы
Процесс 1: (БЛОКИРОВКА!!!)
Recv( …2 …); Send(…2…);
Процесс 2:
Recv(
Объединенная конструкция приема-передачи - проблемы
Процесс 1: (БЛОКИРОВКА!!!)
Recv( …2 …); Send(…2…);
Процесс 2:
Recv(

Объединенная конструкция приема-передачи MPI_Sendrecv()
MPI_Sendrecv( … );
12 параметров = 5 (send) +
Объединенная конструкция приема-передачи MPI_Sendrecv()
MPI_Sendrecv( … );
12 параметров = 5 (send) +

Объединенная конструкция приема-передачи MPI_Sendrecv_replace()
MPI_Sendrecv_replace( … );
12 параметров = 5 (send) +
Объединенная конструкция приема-передачи MPI_Sendrecv_replace()
MPI_Sendrecv_replace( … );
12 параметров = 5 (send) +

Замеры времени выполнения
для оценки достигаемого ускорения за счет использования параллелизма необходимо
Замеры времени выполнения
для оценки достигаемого ускорения за счет использования параллелизма необходимо

Функция отсчета времени
double MPI_Wtime(void)
Функция возвращает астрономическое время в секундах, прошедшее
Функция отсчета времени
double MPI_Wtime(void)
Функция возвращает астрономическое время в секундах, прошедшее

Синхронизация вычислений
Функция MPI_Barrier(commuicator) определяет коллективную операцию, при использовании должна вызываться всеми
Синхронизация вычислений
Функция MPI_Barrier(commuicator) определяет коллективную операцию, при использовании должна вызываться всеми
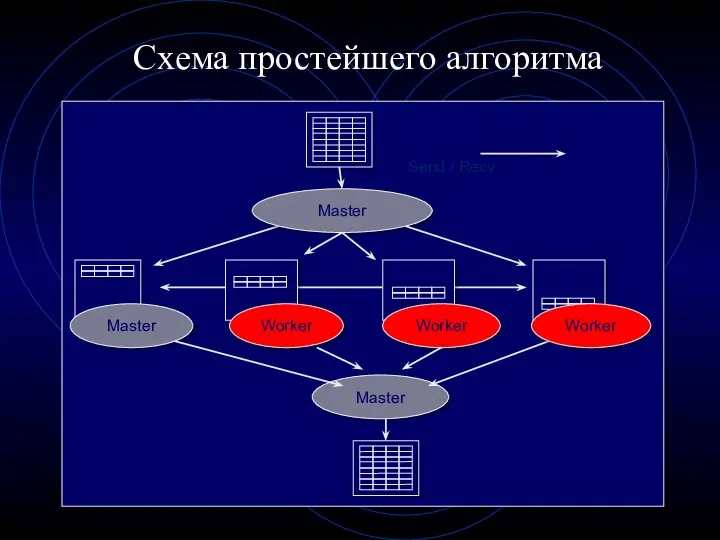
Схема простейшего алгоритма
Схема простейшего алгоритма

Пример шаблона кода
int res = MPI_Init(int *argc, char ***argv) ;
MPI_Comm_rank(
Пример шаблона кода
int res = MPI_Init(int *argc, char ***argv) ; MPI_Comm_rank(

Коллективные функции - рассылка
Функция MPI_Scatter разбивает сообщение из буфера посылки
Коллективные функции - рассылка
Функция MPI_Scatter разбивает сообщение из буфера посылки

Коллективные функции - рассылка
Пример использования функции MPI_Scatter
MPI_Comm comm;
int
Коллективные функции - рассылка
Пример использования функции MPI_Scatter
MPI_Comm comm;
int

Коллективные функции - прием
Функция MPI_Gather производит сборку блоков данных, посылаемых всеми
Коллективные функции - прием
Функция MPI_Gather производит сборку блоков данных, посылаемых всеми

Коллективные функции - прием
Пример программы с использованием функции MPI_Gather:
MPI_Comm comm;
Коллективные функции - прием
Пример программы с использованием функции MPI_Gather:
MPI_Comm comm;

Коллективные функции - векторный вариант
int MPI_Scatterv(void* sendbuf, int *sendcounts, int
Коллективные функции - векторный вариант
int MPI_Scatterv(void* sendbuf, int *sendcounts, int

Пример шаблона кода с коллективными функциями
int res = MPI_Init(int *argc, char
Пример шаблона кода с коллективными функциями
int res = MPI_Init(int *argc, char

Дополнительные функции
MPI_Alltoall(…)
Обобщенная передача данных от всех процессов всем процессам
Вызов функции
Дополнительные функции
MPI_Alltoall(…)
Обобщенная передача данных от всех процессов всем процессам
Вызов функции
 Створення веб-сайту бібліотеки
Створення веб-сайту бібліотеки Теория и практика информационно-аналитической работы. Семинар 2
Теория и практика информационно-аналитической работы. Семинар 2 Программирование на языке С++. Лекция 3. Основные типы данных, идентификаторы и их внутреннее представление
Программирование на языке С++. Лекция 3. Основные типы данных, идентификаторы и их внутреннее представление АО ТАСКОМ. Личный Кабинет. Инструкция по оформлению заявок
АО ТАСКОМ. Личный Кабинет. Инструкция по оформлению заявок Қазіргі қолданыстағы жады
Қазіргі қолданыстағы жады Безопасность детей в интернете
Безопасность детей в интернете Занятие по информатике Диск
Занятие по информатике Диск Обзор функциональных возможностей ERP–решения фирмы 1С
Обзор функциональных возможностей ERP–решения фирмы 1С 自动扫口和自动识别下载口. MediaTekI
自动扫口和自动识别下载口. MediaTekI Курсы международной школы программирования Алгоритмика 2019–2020
Курсы международной школы программирования Алгоритмика 2019–2020 Поняття графічного редактора, його призначення
Поняття графічного редактора, його призначення CSS. Модель відображення
CSS. Модель відображення Программист и тестолог: как создаются сложные программы
Программист и тестолог: как создаются сложные программы Прикладные программные средства
Прикладные программные средства Cerberus Mouse FW update SOP
Cerberus Mouse FW update SOP Основные понятия и принципы объектно-ориентированного программирования. Язык программирования Java
Основные понятия и принципы объектно-ориентированного программирования. Язык программирования Java Калькулятор уравнений. Создание приложения для решения уравнений на языке программирования Visual Basic
Калькулятор уравнений. Создание приложения для решения уравнений на языке программирования Visual Basic Типы алгоритмов
Типы алгоритмов Системное программное обеспечение ПК
Системное программное обеспечение ПК Поисковые системы
Поисковые системы Персональные данные (для детей 9-11 лет)
Персональные данные (для детей 9-11 лет) Особенности изучения английского языка с помощью компьютера и интернета
Особенности изучения английского языка с помощью компьютера и интернета Математичний калькулятор
Математичний калькулятор Об оказании АО Корпорация МСП услуг по регистрации на Портале Бизнес-навигатора МСП через МФЦ
Об оказании АО Корпорация МСП услуг по регистрации на Портале Бизнес-навигатора МСП через МФЦ Технология создания информационно-познавательной мультимедийной платформы
Технология создания информационно-познавательной мультимедийной платформы Риски и угрозы современной интернет-среды и их профилактика среди несовершеннолетних
Риски и угрозы современной интернет-среды и их профилактика среди несовершеннолетних Типы связей и виды управления. Естественные и искусственные системы
Типы связей и виды управления. Естественные и искусственные системы Проект Дом Историй
Проект Дом Историй