- Средства программирования для компьютеров с распределённой памятью

Содержание
- 2. Часть 3: Распараллеливание на компьютерах с распределенной памятью Средства программирования для компьютеров с распределённой памятью (MPI)
- 3. Средства программирования для компьютеров с распределённой памятью (MPI) Message Passing Interface (MPI) – набор программ, разработанный
- 4. Средства программирования для компьютеров с распределённой памятью (MPI) MPICH – бесплатная реализация для UNIX и Windows.
- 5. Средства программирования для компьютеров с распределённой памятью (MPI) OpenMP – директивы компилятора, MPI – вызовы функций
- 6. Понятие процесса в вычислениях на компьютерах с распределённой памятью Как сделать параллельную программу из последовательной? error=MPI_Init();
- 7. Понятие процесса в вычислениях на компьютерах с распределённой памятью Отличие MPI_Init() от $OMP PARALLEL: При вызове
- 8. MPI процесс – это отдельный набор команд с данными (программа), исполняемый независимо на (вирутально) независимом компьютере,
- 9. Основные инструменты MPI Основные функции: int MPI_Init (int *argc, char **argv) инициализирует окружение MPI int MPI_Finalize()
- 10. Коммуникации one-to-one, блокирующие и неблокирующие передачи Базовые функции пересылки: int MPI_Send (void *buf, int count, MPI_Datatype
- 11. Коммуникации one-to-one, блокирующие и неблокирующие передачи MPI_Datatype - типы данных в MPI: Так же MPI позволяет
- 12. Коммуникации one-to-one, блокирующие и неблокирующие передачи Пример простейшей программы: ... #include "mpi.h" int main(int argc, char
- 13. Коммуникации one-to-one, блокирующие и неблокирующие передачи Основные неблокирующие функции пересылки: int MPI_Isend( void *buf, int count,
- 14. Коммуникации one-to-one, блокирующие и неблокирующие передачи Основные неблокирующие функции пересылки: int MPI_Wait ( MPI_Request *request, MPI_Status
- 15. Коммуникации one-to-one, блокирующие и неблокирующие передачи Тот же пример, более корректный: ... #include "mpi.h" int main(int
- 16. Примеры элементарных ошибок Та же самая программа, но на фортране: ... include ‘mpif.h’ program main char
- 17. Примеры элементарных ошибок Другая популярная ошибка на примере этой же программы: ... #include "mpi.h" int main(int
- 18. Примеры элементарных ошибок Другая популярная ошибка на примере этой же программы: ... #include "mpi.h" int main(int
- 19. Задания на понимание Нарисуйте блок схему, реализующую параллельное умножение матрицы на вектор, где матрица распределена по
- 20. НЕУДОБНО!!! Коллективные коммуникации Задача: Напишите блок-схему, реализующую параллельное вычисление числа π. Псевдокод: #include "mpi.h" int main(int
- 21. Коллективные коммуникации int MPI_Reduce(void *sendbuf, void *recvbuf, int count, MPI_Datatype type, MPI_Op op, int root, MPI_Comm
- 22. Задача: Напишите блок-схему, реализующую параллельное вычисление числа π. Псевдокод с помощью MPI_REDUCE: #include "mpi.h" int main(int
- 23. MPI_Reduce: Коллективные коммуникации MPI_Bcast(void *buf, int count, MPI_Datatype type, int root, MPI_Comm comm): buf – адрес
- 24. int MPI_Scatter(void *sbuf, int scount, MPI_Datatype stype, void *rbuf, int rcount, MPI_Datatype rtype, int root, MPI_Comm
- 25. int MPI_Gather(void *sbuf, int scount, MPI_Datatype stype, void *rbuf, int rcount, MPI_Datatype rtype, int root, MPI_Comm
- 26. MPI_Gather и MPI_Scatter расссылают посылки одинакового объема, что бывает неудобно. Для рассылки разного веса используются такие
- 27. int MPI_Alltoall(void *sbuf, int scount, MPI_Datatype stype, void *rbuf, int rcount, MPI_Datatype rtype, MPI_Comm comm) Коллективные
- 28. Полезные мелочи: int MPI_Barrier(MPI_Comm comm) – останавливает MPI процессы в comm до того момента, пока они
- 29. MPI_Comm*comm – коммуникатор Что это такое? Структура, хранящая информацию о процессах, используемых в работе. Есть три
- 30. Можно ли присвоить один коммуникатор другому, например, Comm = MPI_COMM_WORLD;? НЕТ! Правильно: MPI_Comm new_comm; MPI_Comm_dup( MPI_COMM_WORLD,
- 31. int MPI_Group_size ( MPI_Group *group, int *size ) – считает размер группы int MPI_Group_rank ( MPI_Group
- 32. Пример: построить коммуникатор, который содержит только процессы той же четности, что и вызывающий (результат: должно получится
- 33. Другой способ построить новый коммуникатор без использования групп: int MPI_Comm_split(MPI_Comm comm, int color, int key, MPI_Comm
- 34. Тот же пример, но уже с помощью MPI_Comm_split: построить коммуникатор, который содержит только процессоры той же
- 35. Резюме MPI распараллеливание основано на вызове подпрограмм в отличие от OpenMP MPI процессы знают, что они
- 37. Скачать презентацию

Часть 3: Распараллеливание на компьютерах с распределенной памятью
Средства программирования для компьютеров
Часть 3: Распараллеливание на компьютерах с распределенной памятью
Средства программирования для компьютеров

Средства программирования для компьютеров с распределённой памятью (MPI)
Message Passing Interface (MPI) –
Средства программирования для компьютеров с распределённой памятью (MPI)
Message Passing Interface (MPI) –

Средства программирования для компьютеров с распределённой памятью (MPI)
MPICH – бесплатная реализация
Средства программирования для компьютеров с распределённой памятью (MPI)
MPICH – бесплатная реализация

Средства программирования для компьютеров с распределённой памятью (MPI)
OpenMP – директивы компилятора,
Средства программирования для компьютеров с распределённой памятью (MPI)
OpenMP – директивы компилятора,

Понятие процесса в вычислениях на компьютерах с распределённой памятью
Как сделать параллельную
Понятие процесса в вычислениях на компьютерах с распределённой памятью
Как сделать параллельную
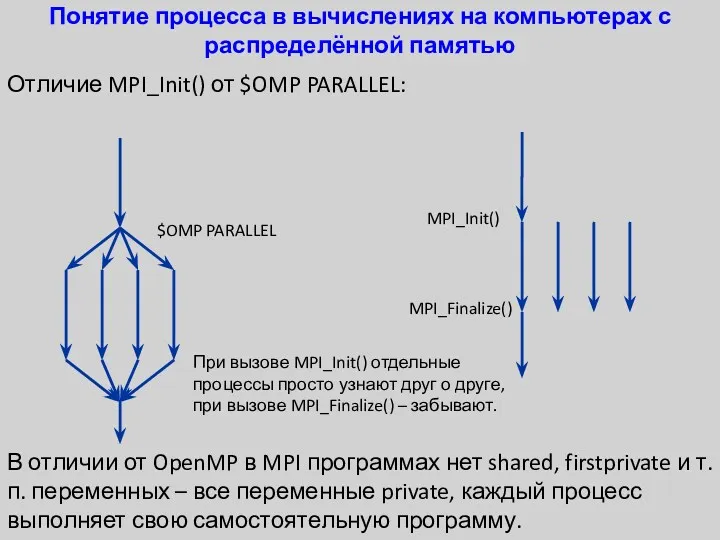
Понятие процесса в вычислениях на компьютерах с распределённой памятью
Отличие MPI_Init() от
Понятие процесса в вычислениях на компьютерах с распределённой памятью
Отличие MPI_Init() от

MPI процесс – это отдельный набор команд с данными (программа),
исполняемый
MPI процесс – это отдельный набор команд с данными (программа),
исполняемый

Основные инструменты MPI
Основные функции:
int MPI_Init (int *argc, char **argv) инициализирует окружение
Основные инструменты MPI
Основные функции:
int MPI_Init (int *argc, char **argv) инициализирует окружение

Коммуникации one-to-one, блокирующие и неблокирующие передачи
Базовые функции пересылки:
int MPI_Send (void *buf,
Коммуникации one-to-one, блокирующие и неблокирующие передачи
Базовые функции пересылки:
int MPI_Send (void *buf,
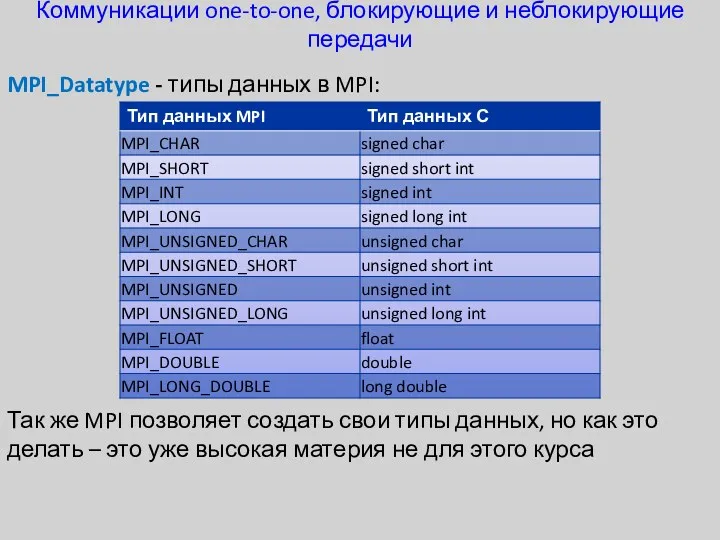
Коммуникации one-to-one, блокирующие и неблокирующие передачи
MPI_Datatype - типы данных в MPI:
Так
Коммуникации one-to-one, блокирующие и неблокирующие передачи
MPI_Datatype - типы данных в MPI:
Так
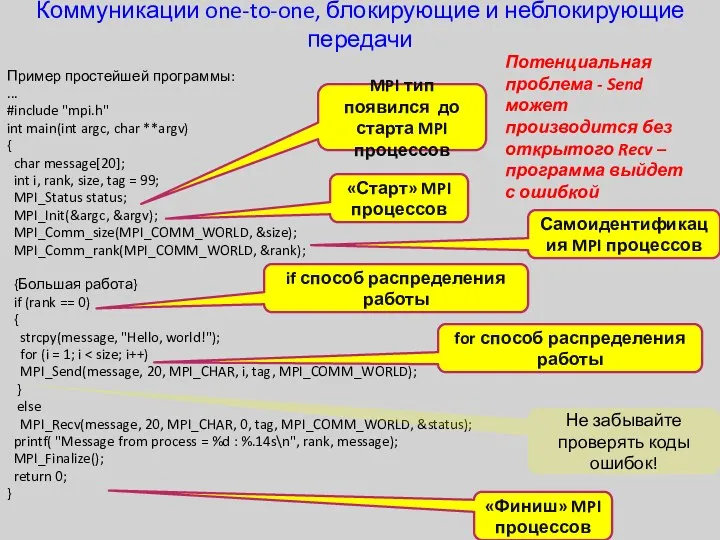
Коммуникации one-to-one, блокирующие и неблокирующие передачи
Пример простейшей программы:
...
#include "mpi.h"
int main(int
Коммуникации one-to-one, блокирующие и неблокирующие передачи
Пример простейшей программы:
...
#include "mpi.h"
int main(int

Коммуникации one-to-one, блокирующие и неблокирующие передачи
Основные неблокирующие функции пересылки:
int MPI_Isend( void
Коммуникации one-to-one, блокирующие и неблокирующие передачи
Основные неблокирующие функции пересылки:
int MPI_Isend( void

Коммуникации one-to-one, блокирующие и неблокирующие передачи
Основные неблокирующие функции пересылки:
int MPI_Wait (
Коммуникации one-to-one, блокирующие и неблокирующие передачи
Основные неблокирующие функции пересылки:
int MPI_Wait (

Коммуникации one-to-one, блокирующие и неблокирующие передачи
Тот же пример, более корректный:
...
#include "mpi.h"
Коммуникации one-to-one, блокирующие и неблокирующие передачи
Тот же пример, более корректный:
...
#include "mpi.h"

Примеры элементарных ошибок
Та же самая программа, но на фортране:
...
include ‘mpif.h’
program
Примеры элементарных ошибок
Та же самая программа, но на фортране:
...
include ‘mpif.h’
program

Примеры элементарных ошибок
Другая популярная ошибка на примере этой же программы:
...
#include "mpi.h"
Примеры элементарных ошибок
Другая популярная ошибка на примере этой же программы:
...
#include "mpi.h"

Примеры элементарных ошибок
Другая популярная ошибка на примере этой же программы:
...
#include "mpi.h"
Примеры элементарных ошибок
Другая популярная ошибка на примере этой же программы:
...
#include "mpi.h"

Задания на понимание
Нарисуйте блок схему, реализующую параллельное умножение матрицы на вектор,
Задания на понимание
Нарисуйте блок схему, реализующую параллельное умножение матрицы на вектор,

НЕУДОБНО!!!
Коллективные коммуникации
Задача: Напишите блок-схему, реализующую параллельное вычисление числа π. Псевдокод:
#include "mpi.h"
НЕУДОБНО!!!
Коллективные коммуникации
Задача: Напишите блок-схему, реализующую параллельное вычисление числа π. Псевдокод:
#include "mpi.h"
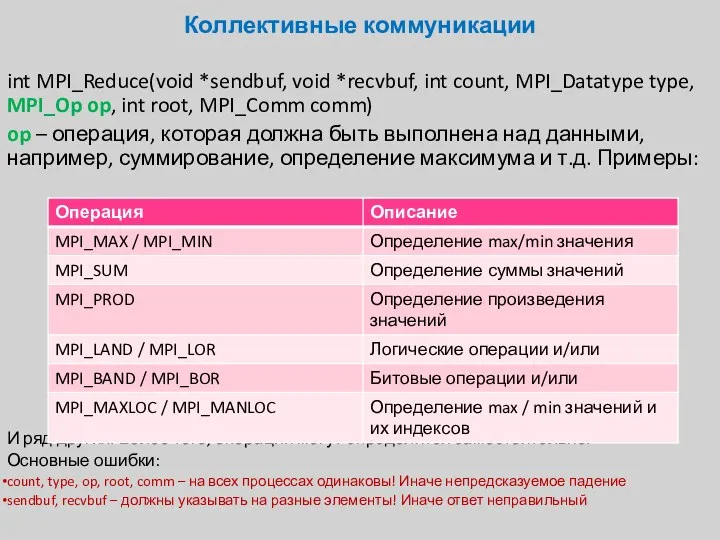
Коллективные коммуникации
int MPI_Reduce(void *sendbuf, void *recvbuf, int count, MPI_Datatype type, MPI_Op
Коллективные коммуникации
int MPI_Reduce(void *sendbuf, void *recvbuf, int count, MPI_Datatype type, MPI_Op

Задача: Напишите блок-схему, реализующую параллельное вычисление числа π. Псевдокод с помощью
Задача: Напишите блок-схему, реализующую параллельное вычисление числа π. Псевдокод с помощью
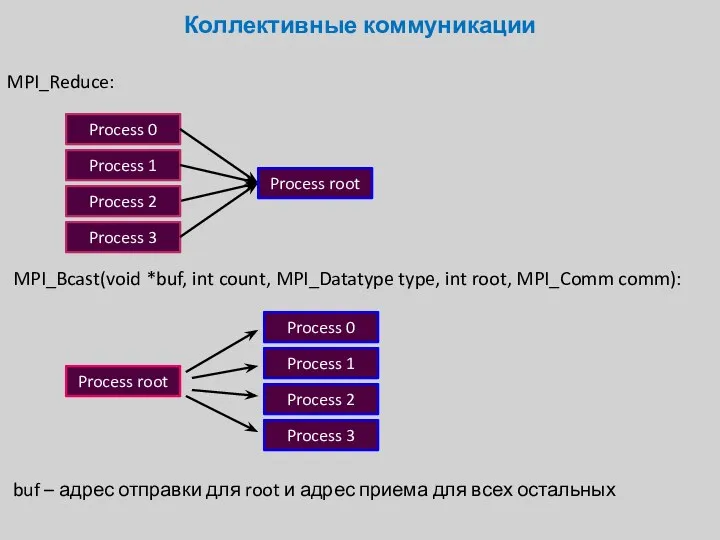
MPI_Reduce:
Коллективные коммуникации
MPI_Bcast(void *buf, int count, MPI_Datatype type, int root, MPI_Comm comm):
buf
MPI_Reduce:
Коллективные коммуникации
MPI_Bcast(void *buf, int count, MPI_Datatype type, int root, MPI_Comm comm):
buf
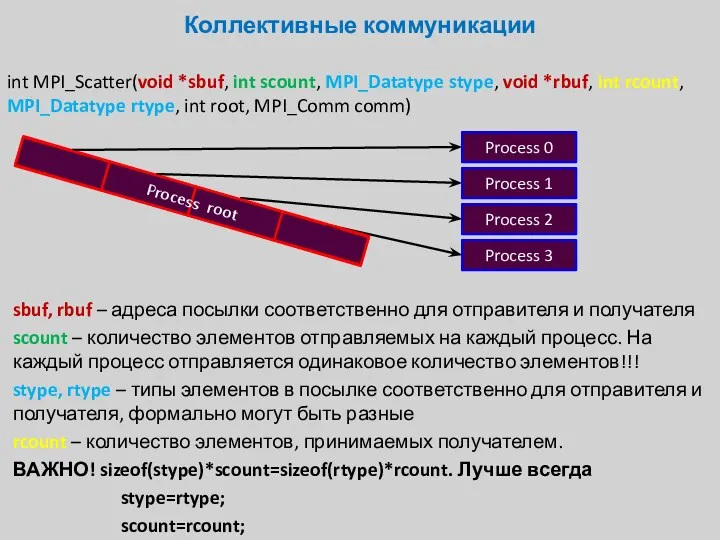
int MPI_Scatter(void *sbuf, int scount, MPI_Datatype stype, void *rbuf, int rcount,
int MPI_Scatter(void *sbuf, int scount, MPI_Datatype stype, void *rbuf, int rcount,
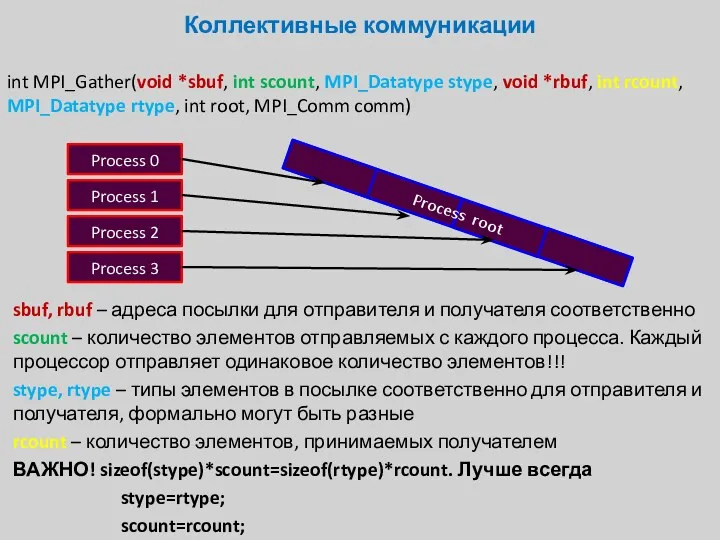
int MPI_Gather(void *sbuf, int scount, MPI_Datatype stype, void *rbuf, int rcount,
int MPI_Gather(void *sbuf, int scount, MPI_Datatype stype, void *rbuf, int rcount,
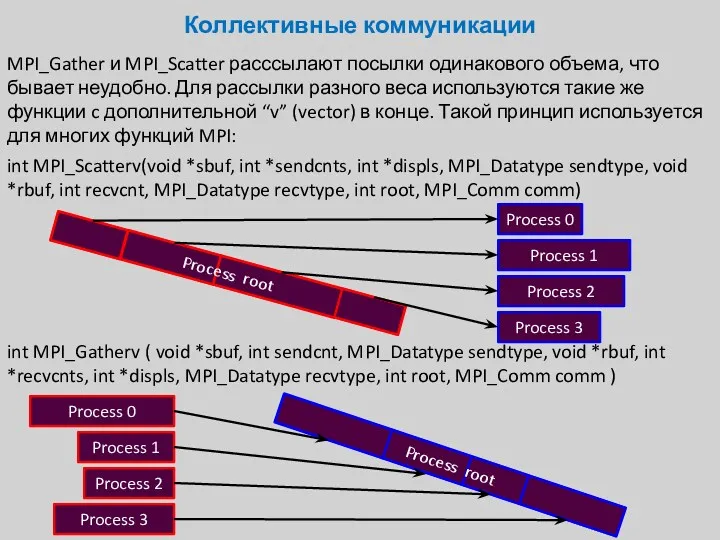
MPI_Gather и MPI_Scatter расссылают посылки одинакового объема, что бывает неудобно. Для
MPI_Gather и MPI_Scatter расссылают посылки одинакового объема, что бывает неудобно. Для

int MPI_Alltoall(void *sbuf, int scount, MPI_Datatype stype, void *rbuf, int rcount,
int MPI_Alltoall(void *sbuf, int scount, MPI_Datatype stype, void *rbuf, int rcount,

Полезные мелочи:
int MPI_Barrier(MPI_Comm comm) – останавливает MPI процессы в comm до
Полезные мелочи:
int MPI_Barrier(MPI_Comm comm) – останавливает MPI процессы в comm до

MPI_Comm*comm – коммуникатор
Что это такое? Структура, хранящая информацию о процессах, используемых
MPI_Comm*comm – коммуникатор
Что это такое? Структура, хранящая информацию о процессах, используемых

Можно ли присвоить один коммуникатор другому, например,
Comm = MPI_COMM_WORLD;?
НЕТ! Правильно:
MPI_Comm
Можно ли присвоить один коммуникатор другому, например,
Comm = MPI_COMM_WORLD;?
НЕТ! Правильно:
MPI_Comm

int MPI_Group_size ( MPI_Group *group, int *size ) – считает размер
int MPI_Group_size ( MPI_Group *group, int *size ) – считает размер

Пример: построить коммуникатор, который содержит только процессы той же четности, что
Пример: построить коммуникатор, который содержит только процессы той же четности, что

Другой способ построить новый коммуникатор без использования групп:
int MPI_Comm_split(MPI_Comm comm, int
Другой способ построить новый коммуникатор без использования групп:
int MPI_Comm_split(MPI_Comm comm, int

Тот же пример, но уже с помощью MPI_Comm_split: построить коммуникатор, который
Тот же пример, но уже с помощью MPI_Comm_split: построить коммуникатор, который

Резюме
MPI распараллеливание основано на вызове подпрограмм в отличие от OpenMP
MPI процессы
Резюме
MPI распараллеливание основано на вызове подпрограмм в отличие от OpenMP
MPI процессы
 Идентификация. Штриховое кодирование
Идентификация. Штриховое кодирование Java. Циклы
Java. Циклы Телекоммуникационные технологии
Телекоммуникационные технологии Microsoft Visual Studio. Лекция 2
Microsoft Visual Studio. Лекция 2 Адаптер. Патерни проектування
Адаптер. Патерни проектування Абстрактные классы и интерфейсы. (Занятие 4)
Абстрактные классы и интерфейсы. (Занятие 4) Введение в конфигурирование в системе 1С Предприятие 8. Основные объекты. Версия 8.3
Введение в конфигурирование в системе 1С Предприятие 8. Основные объекты. Версия 8.3 Действия со строками (столбцами). Транспонирование
Действия со строками (столбцами). Транспонирование Урок по информатике для 2 класса Множества. Элементы множества
Урок по информатике для 2 класса Множества. Элементы множества Хранение и выборка данных
Хранение и выборка данных Архитектура ПК
Архитектура ПК Алгоритмы кластеризации в машинном обучении
Алгоритмы кластеризации в машинном обучении Геоинформационны системы
Геоинформационны системы История развития и разновидности операционных систем
История развития и разновидности операционных систем Режимы и способы обработки данных
Режимы и способы обработки данных Объекты в Blender. Создание 3D-модели Молекула воды. Практическая работа №6
Объекты в Blender. Создание 3D-модели Молекула воды. Практическая работа №6 Интернет-зависимость
Интернет-зависимость Линейные списки. Стеки, очереди, деки. (Лекция 3)
Линейные списки. Стеки, очереди, деки. (Лекция 3) Системы управления контентом CMS (08)
Системы управления контентом CMS (08) Анонимность в интернете
Анонимность в интернете Анализ перспективы развития игровой индустрии и ее использование в сфере образования
Анализ перспективы развития игровой индустрии и ее использование в сфере образования Информационная культура
Информационная культура Типология интернет-СМИ
Типология интернет-СМИ Презентация к уроку Файлы и файловая система
Презентация к уроку Файлы и файловая система Руководство по турниру Realms OF Combat: The Ultimate Clash
Руководство по турниру Realms OF Combat: The Ultimate Clash Управляющие операторы языка высокого уровня. Лекция 3
Управляющие операторы языка высокого уровня. Лекция 3 Структура IR сайта. Главная страница
Структура IR сайта. Главная страница Программное обеспечение ЭВМ
Программное обеспечение ЭВМ