- Структурная организация данных

Содержание
- 2. Основные понятия структур данных Информация – любые сведения о каком-либо объекте, событии, процессе или явлении, являющиеся
- 3. Самое простое разделение информации на виды — по органам человека, которые ее воспринимают или воспроизводят. Можно
- 4. Несколько иначе информация подразделяется в современной вычислительной технике. Условно приняты следующие основные виды информации (типы данных):
- 5. Под структурой данных в общем случае понимают множество элементов данных и множество связей между ними. Такое
- 6. Отображение логической в соответствующую физическую структуру будет зависеть от самой структуры и особенностей физической среды, в
- 7. С практической точки зрения используют трехуровневую модель представления данных
- 8. Предметная область - часть реального мира, подлежащая изучению с целью организации управления и, в конечном итоге,
- 9. Объект характеризуется совокупностью свойств – атрибутов. Атрибут - это наименьшая поименованная единица данных, имеющая смысловое значение
- 10. Второй уровень представления данных относится к их логическому описанию (логический уровень). Каждый объект представлен здесь отдельной
- 11. Третий уровень представления данных связан с проблемой хранения данных в памяти компьютера. Физические структуры хранения должны
- 13. Над всеми структурами данных могут выполняться четыре операции: создание; уничтожение; выбор (доступ); обновление.
- 14. Операция создания заключается в выделении памяти для структуры данных. Память может выделяться в процессе выполнения программы
- 15. Операция уничтожения структур данных противоположна по своему действию операции создания. Операция уничтожения помогает эффективно использовать память
- 16. Операция выбора (доступа) используется для доступа к данным внутри самой структуры и зависит от типа структуры
- 17. Операция обновления позволяет изменить значения данных в структуре данных. Примером операции обновления является операция присваивания, или,
- 18. 2. Структуры хранения данных в оперативной памяти Для размещения логических записей в оперативной памяти используются линейные
- 19. К линейным структурам относятся массив, множество, стек, очередь, таблица.
- 20. Массив — структура данных с фиксированным числом элементов одного и того же типа, идентифицируемых по индексу.
- 21. Одномерный массив называется вектором, двухмерный - матрицей (каждый элемент в матрице определяется двумя индексами). Под массив
- 22. Множество — структура, представляющая собой набор неповторяющихся данных одного и того же типа. Допускает добавление и
- 23. Стек - линейная структура переменного размера. Объем данных в нем может изменяться (расти и сокращаться) во
- 24. Очередь, как и стек, является линейной структурой переменного размера. Включение элементов производится только с ее конца,
- 25. Таблица представляет собой линейную структуру переменного размера. Элементами таблицы являются строки (записи), включающие фиксированный набор атрибутов
- 26. Отношения между объектами предметной области часто носят нелинейный характер. Это могут быть отношения, определяемые логическими условиями,
- 27. Дерево – это структура данных, представляющая собой совокупность элементов и отношений, образующих иерархическую структуру. Т.е. древовидные
- 28. Каждое дерево обладает следующими свойствами: существует узел, в который не входит ни одной дуги (корень); в
- 29. Высота (глубина) дерева определяется номером уровня, на котором располагаются его листья. Степенью вершины в дереве называется
- 30. Обход дерева – это упорядоченная последовательность вершин дерева, в которой каждая вершина встречается только один раз.
- 32. Бинарное (двоичное) дерево – это структура данных, представляющее собой дерево, в котором каждая вершина имеет не
- 33. Отношения «многие ко многим» носят более универсальный характер и описываются структурой графа. Граф общего вида состоит
- 34. Списки представляют собой способ организации структуры данных, при которой элементы некоторого типа образуют связанную цепочку. Список,
- 35. Каждый список имеет особый элемент, называемый указателем начала списка, который обычно по содержанию отличен от остальных
- 36. Вставка и удаление элемента списка
- 37. 3. Хранение данных на внешних носителях При размещении информации на внешних носителях (физическом уровне ее хранения)
- 38. Чтение данных – это передача данных из внешней памяти (файла) в оперативную память. Запись данных –
- 39. Для размещения данных на внешних носителях используют следующие типы файловых структур: последовательные; прямые; индексно-последовательные; библиотечные.
- 40. При формировании последовательного файла записи располагаются на носителе в порядке их поступления. Каждая очередная запись размещается
- 41. К записям последовательного файла возможен только последовательный доступ, осуществляемый через указатель текущей записи, указывающий на ту
- 42. Прямые файлы (файлы прямого доступа) хранят информацию в структурированном (для поиска и обращения) виде. Дисковое пространство,
- 43. Файл, преобразованный (отсортированный) по какому-либо ключевому полю файл называется инвертированным. При обработке файла по нескольким ключам
- 44. Для рационализации обработки данных стали использовать индексно-последовательные файлы - совокупность файла данных и одного или нескольких
- 46. Операция добавления осуществляет запись в конец файла данных. Индексный файл при этом перестраивается (создается заново), чтобы
- 47. Файл с библиотечной организацией (с разделами) состоит из последовательно организованных разделов, каждый из которых имеет имя
- 49. Скачать презентацию

Основные понятия структур данных
Информация – любые сведения о каком-либо объекте, событии,
Основные понятия структур данных
Информация – любые сведения о каком-либо объекте, событии,

Самое простое разделение информации на виды — по органам человека, которые
Самое простое разделение информации на виды — по органам человека, которые

Несколько иначе информация подразделяется в современной вычислительной технике.
Условно приняты следующие
Несколько иначе информация подразделяется в современной вычислительной технике.
Условно приняты следующие

Под структурой данных в общем случае понимают множество элементов данных и
Под структурой данных в общем случае понимают множество элементов данных и

Отображение логической в соответствующую физическую структуру будет зависеть от самой структуры
Отображение логической в соответствующую физическую структуру будет зависеть от самой структуры
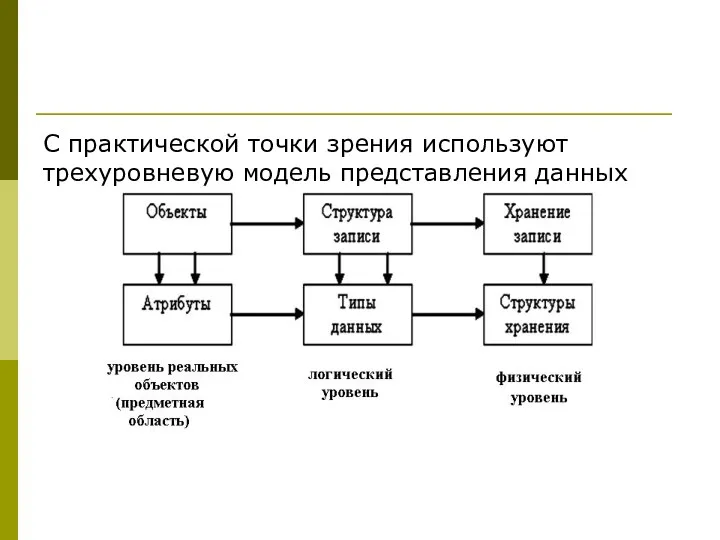
С практической точки зрения используют трехуровневую модель представления данных
С практической точки зрения используют трехуровневую модель представления данных

Предметная область - часть реального мира, подлежащая изучению с целью организации
Предметная область - часть реального мира, подлежащая изучению с целью организации

Объект характеризуется совокупностью свойств – атрибутов.
Атрибут - это наименьшая поименованная единица
Объект характеризуется совокупностью свойств – атрибутов.
Атрибут - это наименьшая поименованная единица

Второй уровень представления данных относится к их логическому описанию (логический уровень).
Второй уровень представления данных относится к их логическому описанию (логический уровень).

Третий уровень представления данных связан с проблемой хранения данных в памяти
Третий уровень представления данных связан с проблемой хранения данных в памяти

Над всеми структурами данных могут выполняться четыре операции:
создание;
уничтожение;
выбор
Над всеми структурами данных могут выполняться четыре операции:
создание;
уничтожение;
выбор

Операция создания заключается в выделении памяти для структуры данных.
Память может
Операция создания заключается в выделении памяти для структуры данных.
Память может

Операция уничтожения структур данных противоположна по своему действию операции создания.
Операция
Операция уничтожения структур данных противоположна по своему действию операции создания.
Операция

Операция выбора (доступа) используется для доступа к данным внутри самой структуры
Операция выбора (доступа) используется для доступа к данным внутри самой структуры

Операция обновления позволяет изменить значения данных в структуре данных.
Примером операции
Операция обновления позволяет изменить значения данных в структуре данных.
Примером операции

2. Структуры хранения данных в оперативной памяти
Для размещения логических записей в
2. Структуры хранения данных в оперативной памяти
Для размещения логических записей в

К линейным структурам относятся
массив,
множество,
стек,
очередь,
таблица.
К линейным структурам относятся
массив,
множество,
стек,
очередь,
таблица.

Массив — структура данных с фиксированным числом элементов одного и того
Массив — структура данных с фиксированным числом элементов одного и того
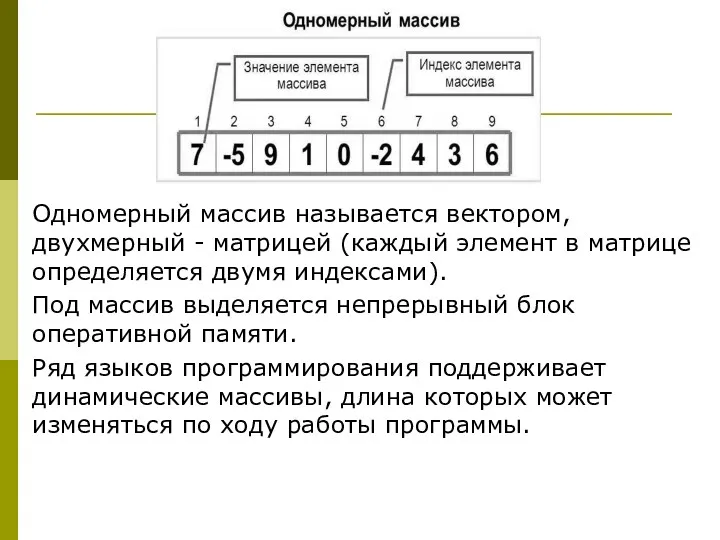
Одномерный массив называется вектором, двухмерный - матрицей (каждый элемент в матрице
Одномерный массив называется вектором, двухмерный - матрицей (каждый элемент в матрице

Множество — структура, представляющая собой набор неповторяющихся данных одного и того
Множество — структура, представляющая собой набор неповторяющихся данных одного и того
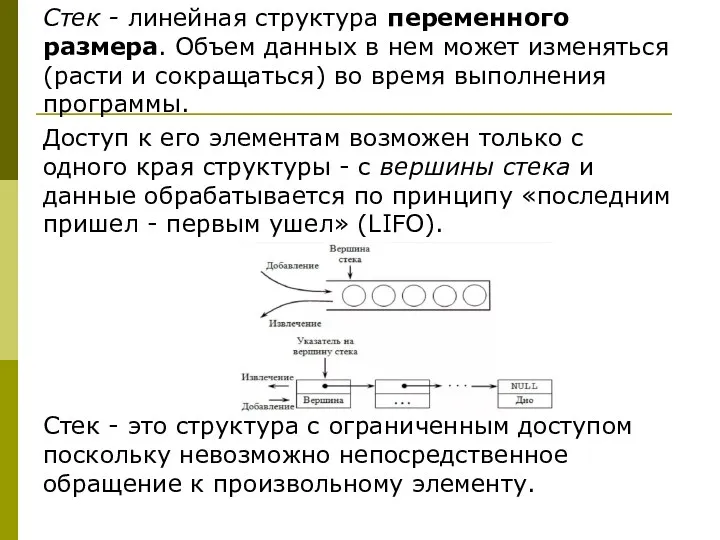
Стек - линейная структура переменного размера. Объем данных в нем может
Стек - линейная структура переменного размера. Объем данных в нем может
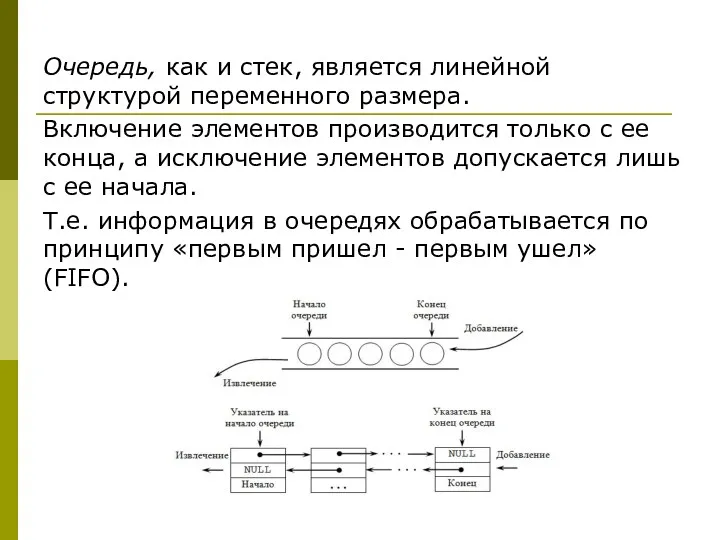
Очередь, как и стек, является линейной структурой переменного размера.
Включение элементов производится
Очередь, как и стек, является линейной структурой переменного размера.
Включение элементов производится

Таблица представляет собой линейную структуру переменного размера.
Элементами таблицы являются строки
Таблица представляет собой линейную структуру переменного размера.
Элементами таблицы являются строки

Отношения между объектами предметной области часто носят нелинейный характер.
Это могут
Отношения между объектами предметной области часто носят нелинейный характер.
Это могут
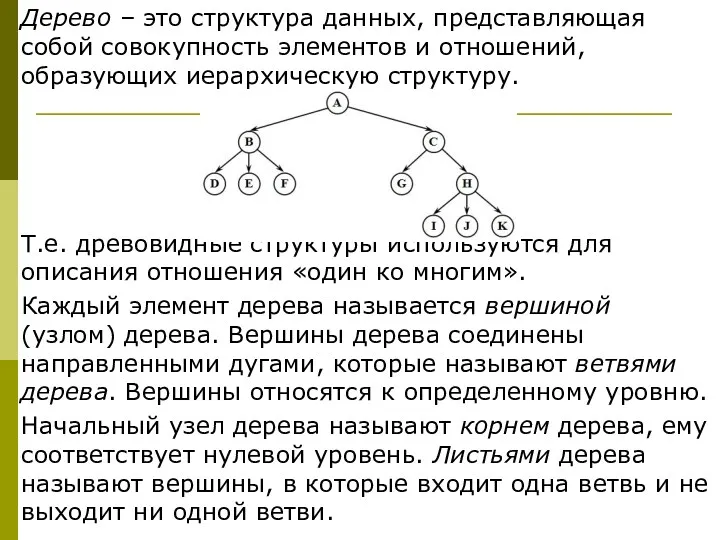
Дерево – это структура данных, представляющая собой совокупность элементов и отношений,
Дерево – это структура данных, представляющая собой совокупность элементов и отношений,

Каждое дерево обладает следующими свойствами:
существует узел, в который не входит ни
Каждое дерево обладает следующими свойствами:
существует узел, в который не входит ни

Высота (глубина) дерева определяется номером уровня, на котором располагаются его листья.
Высота (глубина) дерева определяется номером уровня, на котором располагаются его листья.

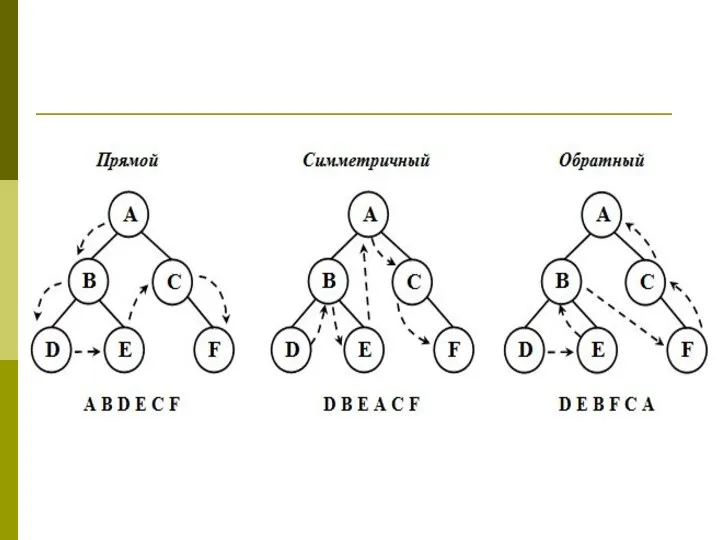
Обход дерева – это упорядоченная последовательность вершин дерева, в которой каждая
Обход дерева – это упорядоченная последовательность вершин дерева, в которой каждая
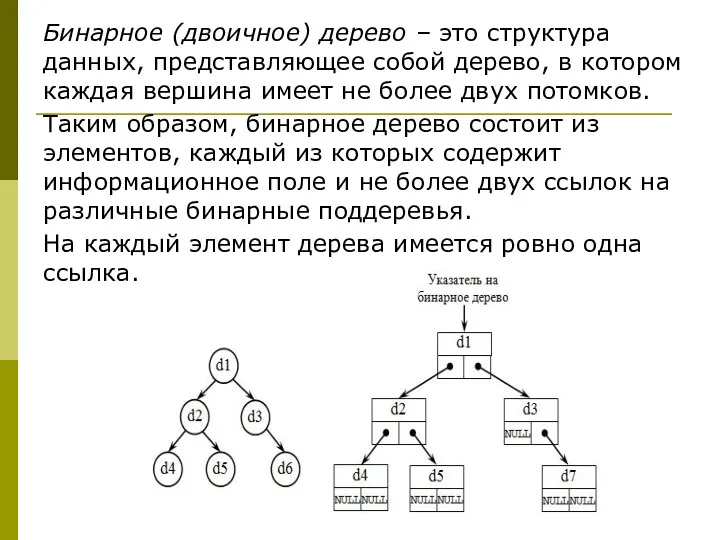
Бинарное (двоичное) дерево – это структура данных, представляющее собой дерево, в
Бинарное (двоичное) дерево – это структура данных, представляющее собой дерево, в
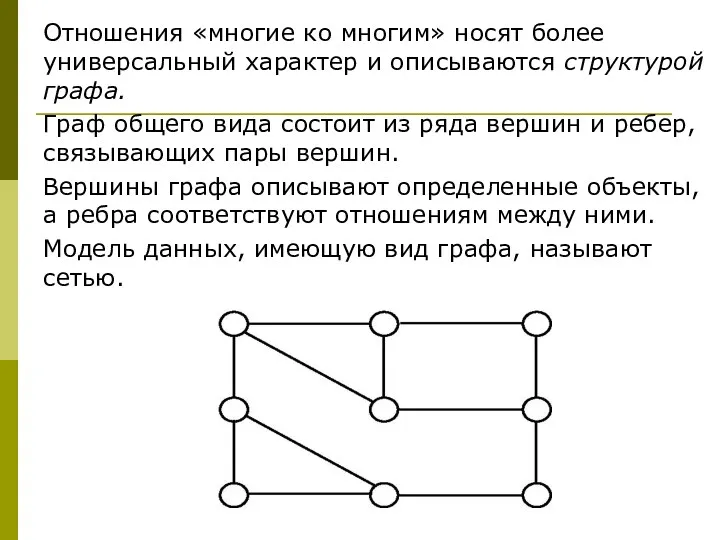
Отношения «многие ко многим» носят более универсальный характер и описываются структурой
Отношения «многие ко многим» носят более универсальный характер и описываются структурой
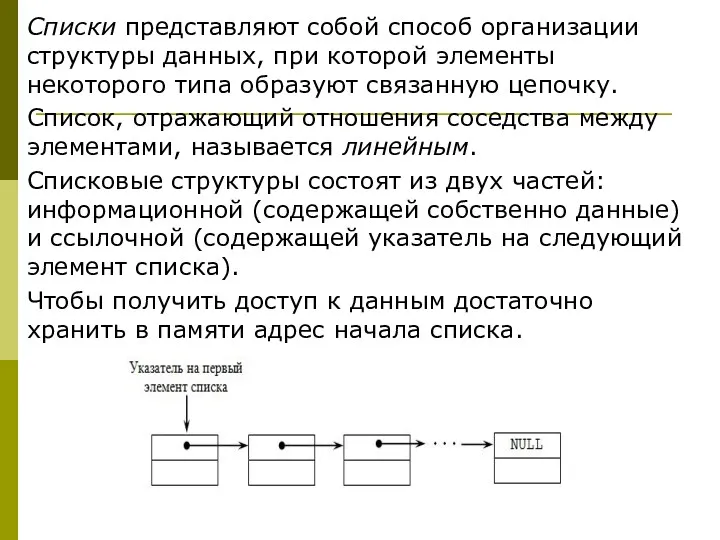
Списки представляют собой способ организации структуры данных, при которой элементы некоторого
Списки представляют собой способ организации структуры данных, при которой элементы некоторого

Каждый список имеет особый элемент, называемый указателем начала списка, который обычно
Каждый список имеет особый элемент, называемый указателем начала списка, который обычно
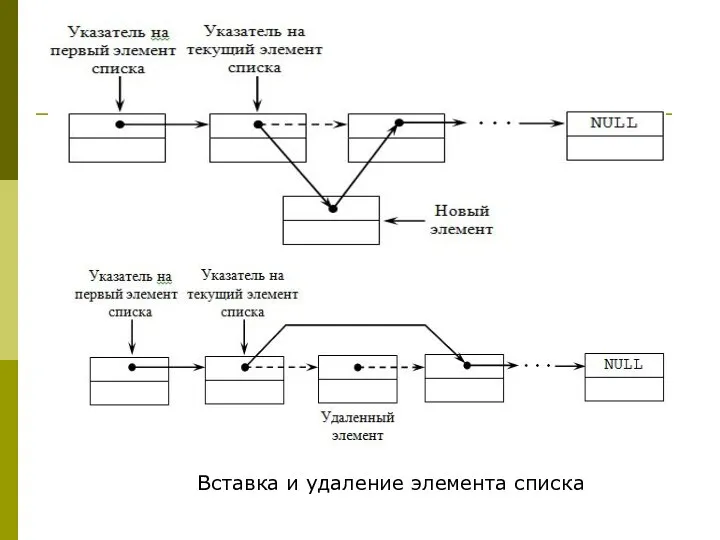
Вставка и удаление элемента списка
Вставка и удаление элемента списка

3. Хранение данных на внешних носителях
При размещении информации на внешних носителях
3. Хранение данных на внешних носителях
При размещении информации на внешних носителях

Чтение данных – это передача данных из внешней памяти (файла) в
Чтение данных – это передача данных из внешней памяти (файла) в

Для размещения данных на внешних носителях используют следующие типы файловых структур:
последовательные;
прямые;
индексно-последовательные;
библиотечные.
Для размещения данных на внешних носителях используют следующие типы файловых структур:
последовательные;
прямые;
индексно-последовательные;
библиотечные.

При формировании последовательного файла записи располагаются на носителе в порядке их
При формировании последовательного файла записи располагаются на носителе в порядке их

К записям последовательного файла возможен только последовательный доступ, осуществляемый через указатель
К записям последовательного файла возможен только последовательный доступ, осуществляемый через указатель

Прямые файлы (файлы прямого доступа) хранят информацию в структурированном (для поиска
Прямые файлы (файлы прямого доступа) хранят информацию в структурированном (для поиска

Файл, преобразованный (отсортированный) по какому-либо ключевому полю файл называется инвертированным.
При
Файл, преобразованный (отсортированный) по какому-либо ключевому полю файл называется инвертированным.
При

Для рационализации обработки данных стали использовать индексно-последовательные файлы - совокупность файла
Для рационализации обработки данных стали использовать индексно-последовательные файлы - совокупность файла
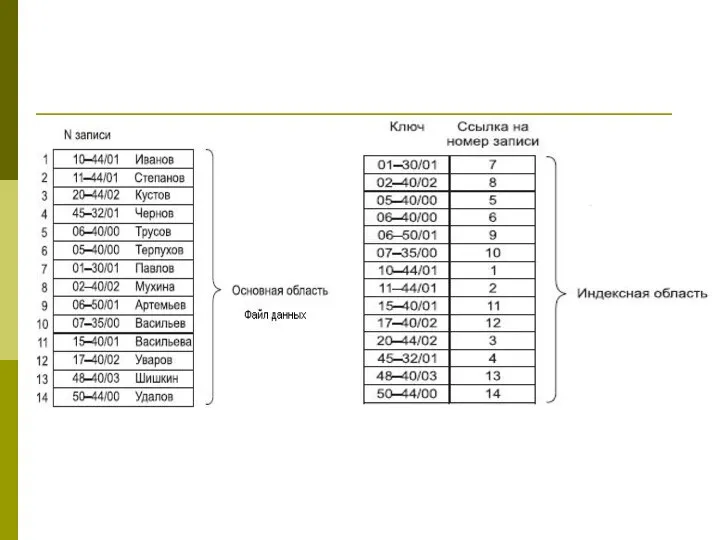

Операция добавления осуществляет запись в конец файла данных.
Индексный файл при
Операция добавления осуществляет запись в конец файла данных.
Индексный файл при

Файл с библиотечной организацией (с разделами) состоит из последовательно организованных разделов,
Файл с библиотечной организацией (с разделами) состоит из последовательно организованных разделов,
 Информация, информационные системы и технологии. Информатика в современном мире. Основы информационной культуры
Информация, информационные системы и технологии. Информатика в современном мире. Основы информационной культуры Локальные и глобальные компьютерные сети. Коммуникационные технологии
Локальные и глобальные компьютерные сети. Коммуникационные технологии Администрирование 1С
Администрирование 1С Шаблоны слайдов от McKinsey
Шаблоны слайдов от McKinsey Hyper Text Markup Language - Язык разметки гипертекста
Hyper Text Markup Language - Язык разметки гипертекста Автоматизированное тестирование
Автоматизированное тестирование Informatyka. Sortowanie danych
Informatyka. Sortowanie danych Корпорация Microsoft и её подразделения
Корпорация Microsoft и её подразделения Машина Тьюринга
Машина Тьюринга Графика в Pascal ABC.NET
Графика в Pascal ABC.NET Защита информации, антивирусная защита информации
Защита информации, антивирусная защита информации UML Унифицированный язык моделирования. Самоучитель
UML Унифицированный язык моделирования. Самоучитель Язык программирования C#
Язык программирования C# Технологии обработки графических образов. Лекция 6
Технологии обработки графических образов. Лекция 6 Компьютерные технологии интеллектуальной поддержки управленческих решений
Компьютерные технологии интеллектуальной поддержки управленческих решений Сеть Ethernet. Базовые понятия
Сеть Ethernet. Базовые понятия Информационные технологии (ИТ)
Информационные технологии (ИТ) урок информатики Кодирование текстовой информации для 8 класса
урок информатики Кодирование текстовой информации для 8 класса Тезаурус. Безопасный интернет
Тезаурус. Безопасный интернет Глобальные и локальные сети
Глобальные и локальные сети Ошибки продвижения бизнеса в интернете
Ошибки продвижения бизнеса в интернете Java SE8 Основы программирования. Введение. История. IDE среды. Термины ООП
Java SE8 Основы программирования. Введение. История. IDE среды. Термины ООП Страницы. Следующий уровень
Страницы. Следующий уровень Многообразие схем
Многообразие схем Текстовий процесор (урок 18, 6 клас)
Текстовий процесор (урок 18, 6 клас) Медиа-карта. СМИ в сфере бизнеса и финансов
Медиа-карта. СМИ в сфере бизнеса и финансов Программный комплексАВС ООО НПП АВС-Н
Программный комплексАВС ООО НПП АВС-Н Структура персонального компьютера
Структура персонального компьютера