- Структуры данных

Содержание
- 2. Структурирование данных Структурирование данных — разработка структуры данных, состоящая в определении данных как объектов элементарного типа
- 3. Структура данных — множество элементов данных, объединенных и упорядоченных одним из принятых способов. При использовании данных
- 4. Любое представление структуры данных в памяти ЭВМ должно включать в себя как сами данные, так и
- 5. Основные структуры данных Массив Массив — представляет собой некоторое количество расположенных в определенном порядке элементов одного
- 6. Последовательности Последовательности — в отличие от массива, количество элементов (длина) последовательности конечно, но не фиксировано. Это
- 7. Операции последовательности Рассмотрим более подробно и формально эти операции. создание: T(l1, l2, ..., ln); при n
- 8. удаление: tail(x) — последовательность, в которой из x исключен начальный элемент. initial(x) — последовательность, в которой
- 9. Если x = T(l1, l2, ..., ln), то tail(x) = T(l2, ..., ln) initial(x) = T(l1,
- 10. Зависимости Между указанными функциями существуют следующие зависимости: first(appendl(x, l)) = l tail(appendl(x, l)) = x appendl(tail(x),
- 11. Определение пустой последовательности empty(x) = true, если x = T() { false, если x # T()
- 12. Очередь Очередью (aнгл. queue)) называется структура данных, в которой элементы кладутся в конец, а извлекаются из
- 13. Очередь — это последовательность, для которой определены следующие операции образование пустой очереди T(); last(x); initial(x); appendl(x,
- 14. Добавление элемента к очереди осуществляется с ее левого конца с помощью операции appendl, а извлечение элемента
- 15. Последовательный файл Последовательный файл, над которым определены следующие 5 операций: формирование пустой последовательности T() first(x) tail(x)
- 16. Это последовательность, в которой допускается выборка (доступ) начального элемента последовательности и добавление элемента в конец последовательности.
- 17. Стек Стек — последовательность, для которой определены следующие операторы: образование пустой последовательности T() first(x) — top
- 18. Стек является памятью типа последним вошел — первым вышел (last in first out, LIFO). Стек является
- 19. Дек?
- 20. Дек Деком (англ. deque – аббревиатура от double-ended queue, двухсторонняя очередь) называется структура данных, в которую
- 21. Структуры данных — это объекты определенного уровня абстракции, для представления которых в памяти ЭВМ можно использовать
- 22. Таким образом системы хранения и манипулирования данными взаимосвязаны и должны рассматриваться совместно. Другими словами, физическое представление
- 23. АТД Подобный аспект рассмотрения данных связывают с понятием абстрактных типов данных (АТД). (Б.Лисков, 1974) Если точно
- 24. Для описания АТД используется формат, который включает заголовок с именем АТД, описание типа данных и список
- 25. В описании формата АТД должны использоваться, понятия, объекты и переменные, использующиеся только на уровне интерфейса к
- 26. Операция обозначает обслуживание, которое объект предлагает своим клиентам. Возможны пять видов операций клиента над объектом: 1)
- 27. Типы данных впервые были описаны Д. Кнутом в его книге «Искусство программирования» [3]. В главе 2,
- 28. АТД СТЕК операции create: -> Stack[Elem] push: Stack[Elem] x Elem -> Stack[Elem] pop: Stack[Elem] -> Elem
- 29. АТД СТЕК аксиомы и предусловия top(push(s,x))=x pop(push(s,x))=x empty(create())=true not empty(push(s,x))=true pop(s) require not empty(s) top(s) require
- 30. Спецификация стеков как АТД (Б.Мейер) ТИПЫ (TYPES) STACK [G] ФУНКЦИИ (FUNCTIONS) put: STACK [G] x G
- 31. Типы данных впервые были описаны Д. Кнутом в его книге «Искусство программирования» [3]. В главе 2,
- 32. АТД имя. Общая характеристика типа данных ДАННЫЕ: Описание общих параметров. Описание структуры хранения данных. ОПЕРАЦИИ: Конструктор:
- 33. Структуры хранения данных
- 34. Одномерный массив Этот способ является обычным при вводе данных в последовательность адресов запоминающего устройства. В случае
- 35. Двумерный массив Этот способ организации данных широко применяется на практике. Если длина (m) строки или столбца
- 36. Динамические структуры данных Список (Линейный связанный) Предполагается, что данные записываются не в последовательные адреса памяти, как
- 37. Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком
- 38. Линейные связные списки являются простейшими динамическими структурами данных. Из всего многообразия связанных списков можно выделить следующие
- 39. Односвязный список (Однонаправленный связный список) Наиболее простой динамической структурой является однонаправленный список, элементами которого служат объекты
- 40. Однонаправленный (односвязный) список – это структура данных, представляющая собой последовательность элементов, в каждом из которых хранится
- 41. Описание простейшего элемента списка выглядит следующим образом: struct имя_типа { информационное поле; адресное поле; }; где
- 42. Особое внимание следует обратить на то, что при выполнении любых операций с линейным однонаправленным списком необходимо
- 43. Двунаправленные (двусвязные) списки Для ускорения многих операций целесообразно применять переходы между элементами списка в обоих направлениях.
- 44. Достоинство: каждый элемент списка доступен из каждого текущего элемента. Недостаток связан с необходимостью выделения места для
- 45. Описание простейшего элемента такого списка выглядит следующим образом: struct имя_типа { информационное поле; адресное поле 1;
- 46. Например: struct list { type elem ; list *next, *pred ; } list *headlist ; где
- 47. Особое внимание следует обратить на то, что в отличие от однонаправленного списка здесь нет необходимости обеспечивать
- 48. Циклические (кольцевые, замкнутые) списки Односвязный список, у которого конечный элемент ссылается на начальный элемент, называется циклическим
- 49. Списки, достоинства лёгкость добавления и удаления элементов размер ограничен только объёмом памяти компьютера и разрядностью указателей
- 50. Списки, недостатки сложность определения адреса элемента по его индексу (номеру) в списке на поля-указатели (указатели на
- 51. Стек Представляет собой один из возможных способов организации памяти. Ввод данных в стек осуществляется таким образом,
- 52. Такая организация памяти применяется при использовании структур данных с указателями. Пример: Чтобы в односвязном списке пройти
- 53. Реализация стека Стек как динамическую структуру данных легко организовать на основе линейного списка. Поскольку работа всегда
- 54. Реализация очереди Очередь как динамическую структуру данных легко организовать на основе линейного списка. Поскольку работа идет
- 55. Древовидные структуры Кроме линейных динамических структур данных часто используются нелинейные структуры. Разновидностью нелинейных структур являются деревья.
- 56. Дерево. Основные определения Структура типа «дерево» характеризуется следующим свойством: Каждый объект в этой структуре, за исключением
- 57. Считается, что корень дерева находится на уровне 0. Максимальный уровень какой-либо из вершин дерева называется его
- 58. В основном применяются деревья с большим количеством ветвей, но для обеспечения однородности структуры ячеек памяти деревья
- 59. Структура узла содержит информационную часть и указатели на порожденный узел и на подобный узел.
- 60. Рассмотренный ранее двумерный массив можно представить в виде древовидной структуры.
- 62. Скачать презентацию

Структурирование данных
Структурирование данных — разработка структуры данных, состоящая в определении данных
Структурирование данных
Структурирование данных — разработка структуры данных, состоящая в определении данных

Структура данных — множество элементов данных, объединенных и упорядоченных одним из
Структура данных — множество элементов данных, объединенных и упорядоченных одним из

Любое представление структуры данных в памяти ЭВМ должно включать в себя
Любое представление структуры данных в памяти ЭВМ должно включать в себя

Основные структуры данных
Массив
Массив — представляет собой некоторое количество расположенных в определенном порядке
Основные структуры данных
Массив
Массив — представляет собой некоторое количество расположенных в определенном порядке

Последовательности
Последовательности — в отличие от массива, количество элементов (длина) последовательности конечно, но
Последовательности
Последовательности — в отличие от массива, количество элементов (длина) последовательности конечно, но

Операции последовательности
Рассмотрим более подробно и формально эти операции.
создание: T(l1, l2,
Операции последовательности
Рассмотрим более подробно и формально эти операции.
создание: T(l1, l2,

удаление:
tail(x) — последовательность, в которой из x исключен начальный элемент.
initial(x)
удаление:
tail(x) — последовательность, в которой из x исключен начальный элемент.
initial(x)

Если x = T(l1, l2, ..., ln), то
tail(x) = T(l2, ..., ln)
initial(x) = T(l1, l2, ...,
Если x = T(l1, l2, ..., ln), то
tail(x) = T(l2, ..., ln)
initial(x) = T(l1, l2, ...,

Зависимости
Между указанными функциями существуют следующие зависимости:
first(appendl(x, l)) = l
tail(appendl(x, l)) = x
appendl(tail(x), first(x)) = x, если x # T()
last(appendr(x, l)) = l
initial(appendr(x, l)) = x
appendr(initial(x), last(x)) = x, если x # T()
Зависимости
Между указанными функциями существуют следующие зависимости:
first(appendl(x, l)) = l
tail(appendl(x, l)) = x
appendl(tail(x), first(x)) = x, если x # T()
last(appendr(x, l)) = l
initial(appendr(x, l)) = x
appendr(initial(x), last(x)) = x, если x # T()

Определение пустой последовательности
empty(x) =
true, если x = T()
{
false, если x # T()
Определение пустой последовательности
empty(x) =
true, если x = T()
{
false, если x # T()

Очередь
Очередью (aнгл. queue)) называется структура данных, в которой элементы кладутся в
Очередь
Очередью (aнгл. queue)) называется структура данных, в которой элементы кладутся в

Очередь — это последовательность, для которой определены следующие операции
образование пустой очереди T();
Очередь — это последовательность, для которой определены следующие операции
образование пустой очереди T();

Добавление элемента к очереди осуществляется с ее левого конца с помощью
Добавление элемента к очереди осуществляется с ее левого конца с помощью

Последовательный файл
Последовательный файл, над которым определены следующие 5 операций:
формирование пустой последовательности
Последовательный файл
Последовательный файл, над которым определены следующие 5 операций:
формирование пустой последовательности

Это последовательность, в которой допускается выборка (доступ) начального элемента последовательности и добавление
Это последовательность, в которой допускается выборка (доступ) начального элемента последовательности и добавление

Стек
Стек — последовательность, для которой определены следующие операторы:
образование пустой последовательности T()
first(x)
Стек
Стек — последовательность, для которой определены следующие операторы:
образование пустой последовательности T()
first(x)

Стек является памятью типа последним вошел — первым вышел (last in first
Стек является памятью типа последним вошел — первым вышел (last in first
Дек?
Дек?

Дек
Деком (англ. deque – аббревиатура от double-ended queue, двухсторонняя очередь) называется структура
Дек
Деком (англ. deque – аббревиатура от double-ended queue, двухсторонняя очередь) называется структура

Структуры данных — это объекты определенного уровня абстракции, для представления которых в
Структуры данных — это объекты определенного уровня абстракции, для представления которых в

Таким образом системы хранения и манипулирования данными взаимосвязаны и должны рассматриваться
Таким образом системы хранения и манипулирования данными взаимосвязаны и должны рассматриваться

АТД
Подобный аспект рассмотрения данных связывают с понятием абстрактных типов данных (АТД).
АТД
Подобный аспект рассмотрения данных связывают с понятием абстрактных типов данных (АТД).

Для описания АТД используется формат, который включает заголовок с именем АТД,
Для описания АТД используется формат, который включает заголовок с именем АТД,

В описании формата АТД должны использоваться, понятия, объекты и переменные, использующиеся
В описании формата АТД должны использоваться, понятия, объекты и переменные, использующиеся

Операция обозначает обслуживание, которое объект предлагает своим клиентам. Возможны пять видов
Операция обозначает обслуживание, которое объект предлагает своим клиентам. Возможны пять видов

Типы данных впервые были описаны Д. Кнутом в его книге «Искусство
Типы данных впервые были описаны Д. Кнутом в его книге «Искусство
![АТД СТЕК операции create: -> Stack[Elem] push: Stack[Elem] x Elem](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/597810/slide-27.jpg)
АТД СТЕК операции
create: -> Stack[Elem]
push: Stack[Elem] x Elem -> Stack[Elem]
АТД СТЕК операции
create: -> Stack[Elem]
push: Stack[Elem] x Elem -> Stack[Elem]

АТД СТЕК аксиомы и предусловия
top(push(s,x))=x
pop(push(s,x))=x
empty(create())=true
not empty(push(s,x))=true
pop(s) require
АТД СТЕК аксиомы и предусловия
top(push(s,x))=x
pop(push(s,x))=x
empty(create())=true
not empty(push(s,x))=true
pop(s) require
![Спецификация стеков как АТД (Б.Мейер) ТИПЫ (TYPES) STACK [G] ФУНКЦИИ](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/597810/slide-29.jpg)
Спецификация стеков как АТД (Б.Мейер)
ТИПЫ (TYPES)
STACK [G]
ФУНКЦИИ (FUNCTIONS)
put: STACK [G] x
Спецификация стеков как АТД (Б.Мейер)
ТИПЫ (TYPES)
STACK [G]
ФУНКЦИИ (FUNCTIONS)
put: STACK [G] x

Типы данных впервые были описаны Д. Кнутом в его книге «Искусство
Типы данных впервые были описаны Д. Кнутом в его книге «Искусство

АТД имя.
Общая характеристика типа данных
ДАННЫЕ:
Описание общих параметров.
Описание структуры хранения данных.
ОПЕРАЦИИ:
Конструктор:
Вход: данные
АТД имя.
Общая характеристика типа данных
ДАННЫЕ:
Описание общих параметров.
Описание структуры хранения данных.
ОПЕРАЦИИ:
Конструктор:
Вход: данные

Структуры хранения данных
Структуры хранения данных
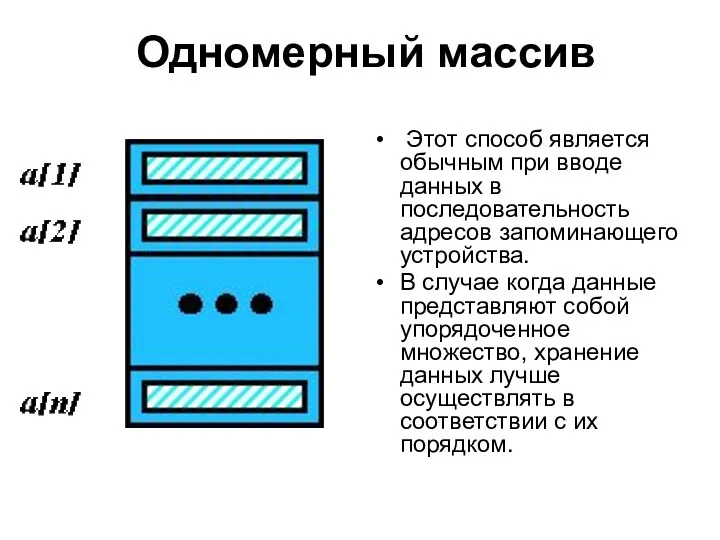
Одномерный массив
Этот способ является обычным при вводе данных в
Одномерный массив
Этот способ является обычным при вводе данных в
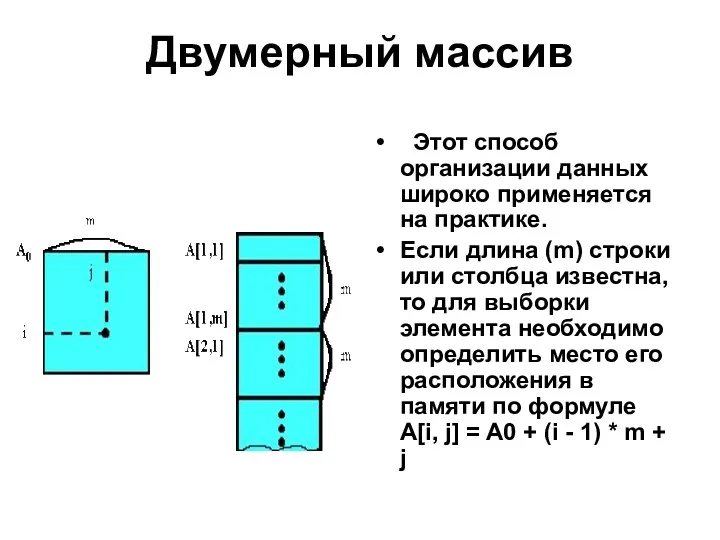
Двумерный массив
Этот способ организации данных широко применяется на практике.
Если
Двумерный массив
Этот способ организации данных широко применяется на практике.
Если

Динамические структуры данных
Список (Линейный связанный)
Предполагается, что данные записываются не в последовательные
Динамические структуры данных
Список (Линейный связанный)
Предполагается, что данные записываются не в последовательные

Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка
Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка

Линейные связные списки являются простейшими динамическими структурами данных. Из всего многообразия
Линейные связные списки являются простейшими динамическими структурами данных. Из всего многообразия
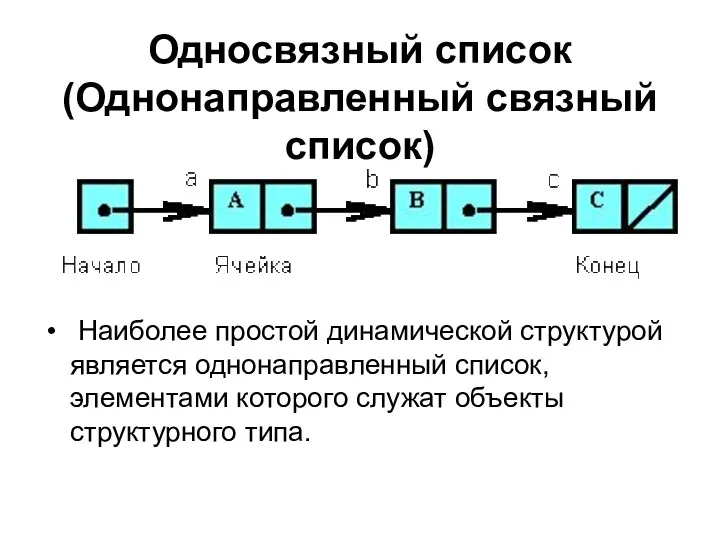
Односвязный список (Однонаправленный связный список)
Наиболее простой динамической структурой является однонаправленный
Односвязный список (Однонаправленный связный список)
Наиболее простой динамической структурой является однонаправленный

Однонаправленный (односвязный) список – это структура данных, представляющая собой последовательность элементов,
Однонаправленный (односвязный) список – это структура данных, представляющая собой последовательность элементов,

Описание простейшего элемента списка выглядит следующим образом:
struct имя_типа { информационное поле;
Описание простейшего элемента списка выглядит следующим образом:
struct имя_типа { информационное поле;

Особое внимание следует обратить на то, что при выполнении любых операций
Особое внимание следует обратить на то, что при выполнении любых операций

Двунаправленные (двусвязные) списки
Для ускорения многих операций целесообразно применять переходы между элементами
Двунаправленные (двусвязные) списки
Для ускорения многих операций целесообразно применять переходы между элементами
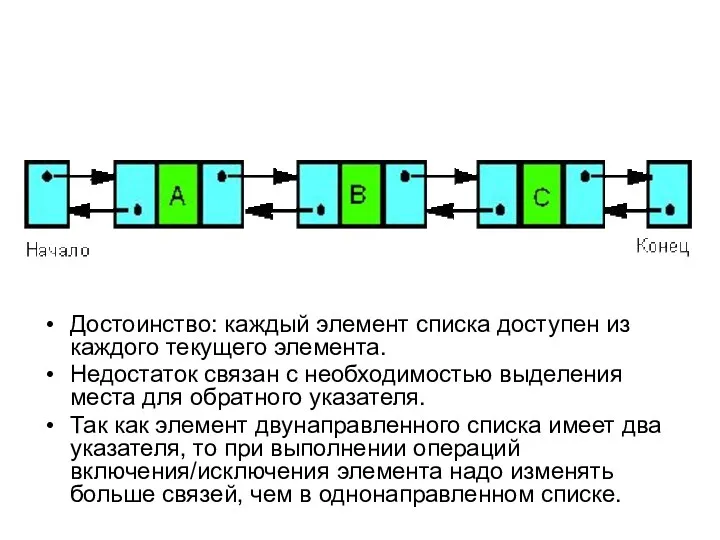
Достоинство: каждый элемент списка доступен из каждого текущего элемента.
Недостаток связан с
Достоинство: каждый элемент списка доступен из каждого текущего элемента.
Недостаток связан с

Описание простейшего элемента такого списка выглядит следующим образом:
struct имя_типа { информационное
Описание простейшего элемента такого списка выглядит следующим образом:
struct имя_типа { информационное

Например:
struct list {
type elem ;
list *next, *pred ;
Например:
struct list {
type elem ;
list *next, *pred ;

Особое внимание следует обратить на то, что в отличие от однонаправленного
Особое внимание следует обратить на то, что в отличие от однонаправленного
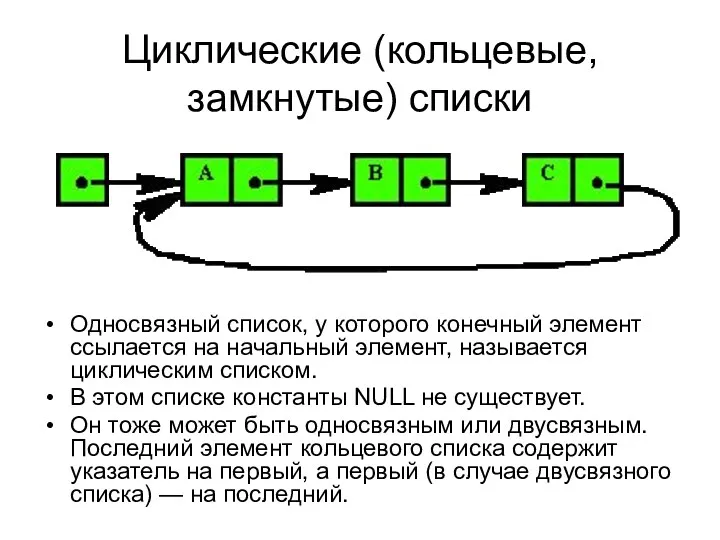
Циклические (кольцевые, замкнутые) списки
Односвязный список, у которого конечный элемент ссылается на
Циклические (кольцевые, замкнутые) списки
Односвязный список, у которого конечный элемент ссылается на

Списки, достоинства
лёгкость добавления и удаления элементов
размер ограничен только объёмом памяти
Списки, достоинства
лёгкость добавления и удаления элементов
размер ограничен только объёмом памяти

Списки, недостатки
сложность определения адреса элемента по его индексу (номеру) в списке
Списки, недостатки
сложность определения адреса элемента по его индексу (номеру) в списке
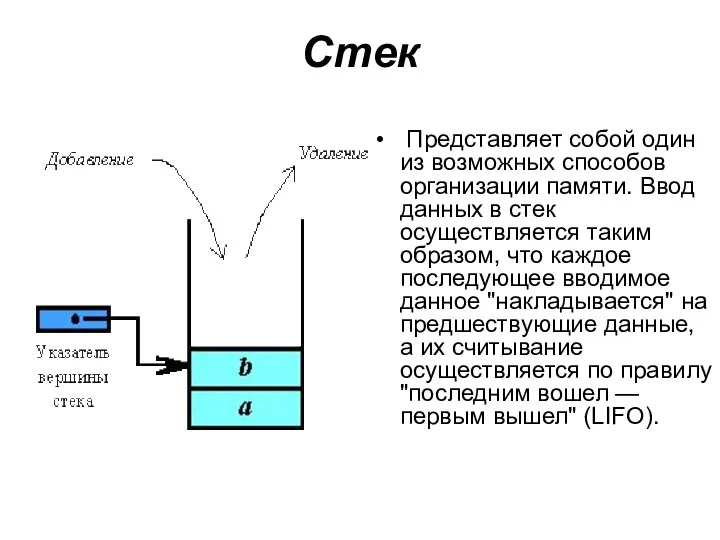
Стек
Представляет собой один из возможных способов организации памяти. Ввод данных
Стек
Представляет собой один из возможных способов организации памяти. Ввод данных

Такая организация памяти применяется при использовании структур данных с указателями.
Пример:
Такая организация памяти применяется при использовании структур данных с указателями.
Пример:

Реализация стека
Стек как динамическую структуру данных легко организовать на основе линейного
Реализация стека
Стек как динамическую структуру данных легко организовать на основе линейного

Реализация очереди
Очередь как динамическую структуру данных легко организовать на основе линейного
Реализация очереди
Очередь как динамическую структуру данных легко организовать на основе линейного
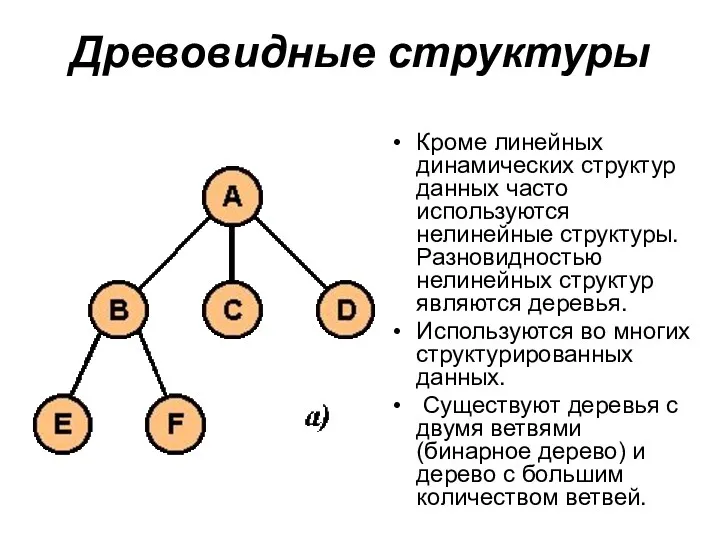
Древовидные структуры
Кроме линейных динамических структур данных часто используются нелинейные структуры.
Древовидные структуры
Кроме линейных динамических структур данных часто используются нелинейные структуры.

Дерево. Основные определения
Структура типа «дерево» характеризуется следующим свойством: Каждый объект в
Дерево. Основные определения
Структура типа «дерево» характеризуется следующим свойством: Каждый объект в

Считается, что корень дерева находится на уровне 0.
Максимальный уровень какой-либо
Считается, что корень дерева находится на уровне 0.
Максимальный уровень какой-либо
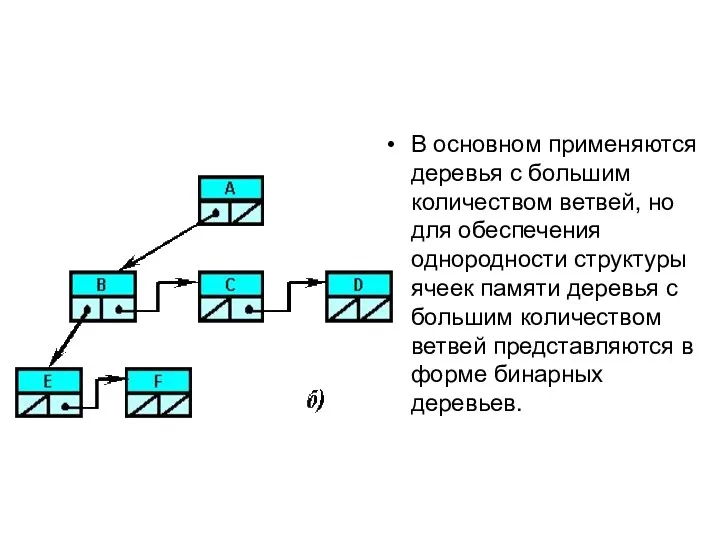
В основном применяются деревья с большим количеством ветвей, но для обеспечения
В основном применяются деревья с большим количеством ветвей, но для обеспечения
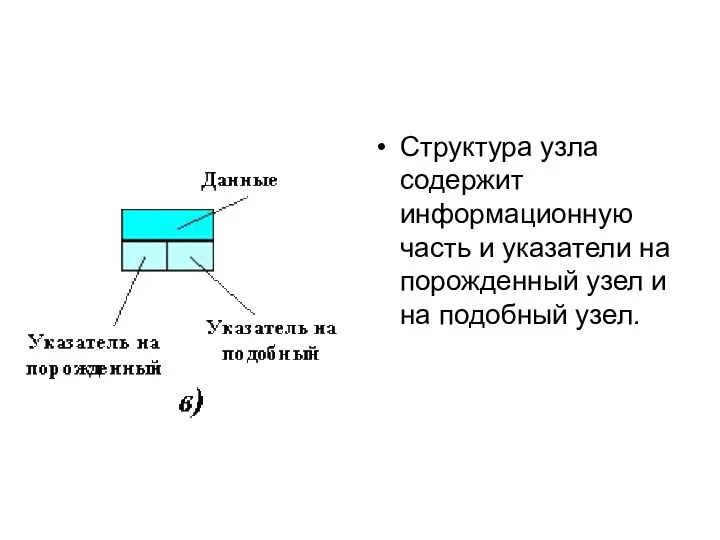
Структура узла содержит информационную часть и указатели на порожденный узел и
Структура узла содержит информационную часть и указатели на порожденный узел и
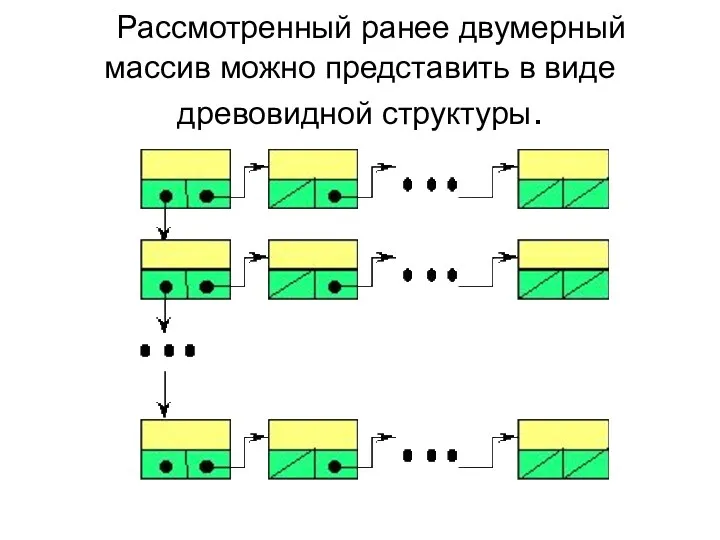
Рассмотренный ранее двумерный массив можно представить в виде древовидной структуры.
Рассмотренный ранее двумерный массив можно представить в виде древовидной структуры.
 Где искать научно-техническую информацию?
Где искать научно-техническую информацию? Графический дизайн и мультимедиа. Динамическая графика
Графический дизайн и мультимедиа. Динамическая графика Жизненный цикл программного обеспечения. Модели ЖЦ ПО
Жизненный цикл программного обеспечения. Модели ЖЦ ПО Урок решения задач по теме Файл и файловая система
Урок решения задач по теме Файл и файловая система Интенсив-курс по React JS. Занятие 1. Основы React
Интенсив-курс по React JS. Занятие 1. Основы React Проектирование баз данных. Введение
Проектирование баз данных. Введение Методика и практика создания Интернет-магазинов в системе CMS 1С-Битрикс: Управление сайтом - Бизнес
Методика и практика создания Интернет-магазинов в системе CMS 1С-Битрикс: Управление сайтом - Бизнес А что такое ОС?
А что такое ОС? Устройства и способы потребления новостей
Устройства и способы потребления новостей Проектирование информационных систем
Проектирование информационных систем Кодирование звуковой информации
Кодирование звуковой информации Основные понятия и определения. Основы программирования и баз данных www.specialist.ru
Основные понятия и определения. Основы программирования и баз данных www.specialist.ru Компьютерные технологии. Версия Matlab R2013b
Компьютерные технологии. Версия Matlab R2013b Создание презентаций в Microsoft Power Point
Создание презентаций в Microsoft Power Point Знакомство с OpenGL. Графические функции
Знакомство с OpenGL. Графические функции Помогаем экономить рабочее время при звонках
Помогаем экономить рабочее время при звонках Программирование на Python
Программирование на Python Python. Оператор присваивания
Python. Оператор присваивания Электронная почта. Сетевое коллективное взаимодействие и сетевой этикет
Электронная почта. Сетевое коллективное взаимодействие и сетевой этикет Архиваторы
Архиваторы Презантация по информатике Моделирование как метод познания
Презантация по информатике Моделирование как метод познания Графические возможности Pascal
Графические возможности Pascal Информация и энтропия
Информация и энтропия Интернет-воздействие и проблемы трезвости современной молодежи
Интернет-воздействие и проблемы трезвости современной молодежи მონაცემთა ბაზები
მონაცემთა ბაზები Оператор варианта
Оператор варианта Настройка маршрутизаторов DIR-300 и DIR-400 для работы в сети провайдера SKYNET* при помощи авторизатора
Настройка маршрутизаторов DIR-300 и DIR-400 для работы в сети провайдера SKYNET* при помощи авторизатора Introduction to the course. Managing the application life cycle
Introduction to the course. Managing the application life cycle