- Технологии обработки больших объемов данных (лекция № 8)

Содержание
- 2. Лекция 8. Технологии обработки больших объемов данных
- 3. Часть 1. Озёра данных
- 4. Data Lake (озеро данных) Data Lake — это репозиторий для хранения, который может вмещать большой объем
- 5. Data Lake (озеро данных)
- 6. Идея и варианты использования Идея, лежащая в основе Data Lake, — хранение всех данных в исходном
- 7. Преимущества Data Lake Данные никогда не отклоняются от загрузки в хранилище, так как хранятся в необработанном
- 8. Данные DataLake Данные потока кликов Логи сервера Социальные сети Координаты геолокаций Данные с датчиков и устройств
- 9. Data Lake Полное решение Data Lake состоит из компонентов хранения и обработки данных. Хранилище Data Lake
- 10. Когда следует использовать Data Lake К наиболее распространенным сферам применения Data Lake относятся исследования данных, анализ
- 11. Сравнение с DWH Нагрузка Схема Масштабирование Методы доступа Преимущества Кто пользователи? SQL Данные
- 12. Сравнение с хранилищем данных
- 13. Сравнение с хранилищем данных
- 14. Сложности Отсутствие схемы и описательных метаданных создает трудности при использовании данных и создании запросов. Отсутствие семантической
- 15. Инструменты
- 16. Подготовка данных к работе
- 17. Часть 2. Экосистема Hadoop. Файловая система HDFS. Обработка данных с применением MapReduce
- 18. Экосистема Hadoop
- 19. Элементы Hadoop Hadoop – программный комплекс для хранения и обработки больших объемов слабоструктурированной информации, состоящий из:
- 20. Система Hadoop Hadoop обслуживает распределенный кластер на программном уровне, эмулируя файловую систему Linux. Hadoop работает на
- 21. Распределенная файловая система Подсистема хранения HDFS разбивает файлы на блоки фиксированного размера. Размер блока при хранении
- 22. Система пакетной обработки данных MapReduce обрабатывает данные ключ:значение по принципу: Применения к значениям операций или функций
- 23. Spark для обработки в памяти Apache Spark – система пакетной обработки данных в памяти. В отличие
- 24. Система управления ресурсами кластера YARN – это система планирования заданий и управления кластером (Yet Another Resource
- 25. Система управления ресурсами кластера ResourceManager (RM) — менеджер ресурсов, которых отвечает за распределение ресурсов, необходимых для
- 26. Принцип работы Hadoop YARN
- 27. Организация работы Hadoop
- 28. Часть 3. Потоки данных. Обмен данными в системах BigData
- 29. Пакетная обработка данных Система пакетной обработки данных – конвейер обработки данных, состоящий из систем извлечения, обработки
- 30. Обработка и применение При пакетной обработке данных с данными в одном пакете может происходить: Применение операций.
- 31. Пакетная обработка данных
- 32. Пакетная обработка данных Примеры применения пакетной обработки данных: обработка данных с применением MapReduce стандартная аналитика данных
- 33. Потоковая обработка данных Потоковая обработка это однопроходная парадигма обработки данных, которая всегда поддерживает данные в движении
- 34. Потоковая обработка данных Плюсы потоковой обработки данных (streaming): результат в режиме реального времени равномерная нагрузка на
- 35. Элементы потоковой обработки Элементы системы потоковой обработки данных Загрузчик данных (средство доставки данных до хранилища); Apache
- 36. Лямбда архитектура Лямбда архитектура поддерживает параллельную обработку пакетных данных и потоковых данных на основе параллельного исполнения
- 37. Лямбда архитектура
- 38. Каппа архитектура Отличается от лямбда-архитектуры в слиянии направлений обработки данных: потоковой и пакетной. Данные хранятся в
- 39. Направленные ациклические графы Направленный ациклический граф (DAG ) представляет собой ориентированный граф без направленных циклов. То
- 40. Apache Airflow Apache Airflow — открытое программное обеспечение для создания, выполнения, мониторинга и оркестровки потоков операций
- 41. Apache Airflow
- 42. Apache Airflow
- 43. Apache Airflow
- 44. Apache Nifi Apache NiFi — это открытое программное обеспечение проекта Apache Software Foundation, предназначенное для автоматизации
- 45. Apache Nifi
- 46. Loginom Loginom — аналитическая платформа, позволяющая в единой среде выполнить все этапы бизнес-анализа от консолидации данных
- 47. Loginom
- 49. Скачать презентацию

Лекция 8. Технологии обработки больших объемов данных
Лекция 8. Технологии обработки больших объемов данных

Часть 1. Озёра данных
Часть 1. Озёра данных
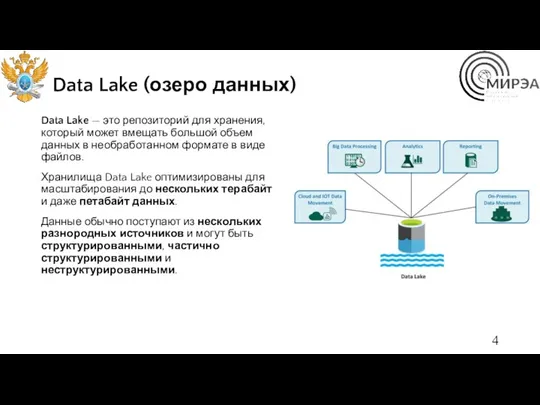
Data Lake (озеро данных)
Data Lake — это репозиторий для хранения, который
Data Lake (озеро данных)
Data Lake — это репозиторий для хранения, который

Data Lake (озеро данных)
Data Lake (озеро данных)

Идея и варианты использования
Идея, лежащая в основе Data Lake, — хранение
Идея и варианты использования
Идея, лежащая в основе Data Lake, — хранение

Преимущества Data Lake
Данные никогда не отклоняются от загрузки в хранилище,
Преимущества Data Lake
Данные никогда не отклоняются от загрузки в хранилище,
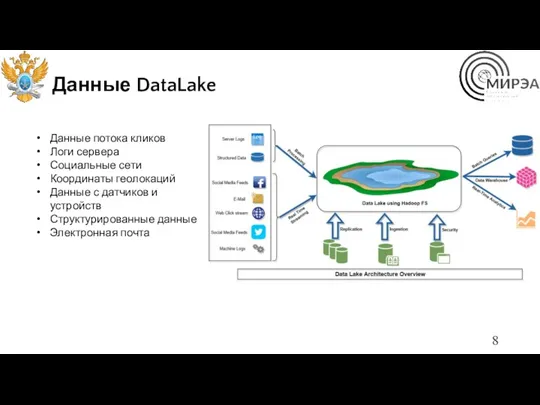
Данные DataLake
Данные потока кликов
Логи сервера
Социальные сети
Координаты геолокаций
Данные с
Данные DataLake
Данные потока кликов
Логи сервера
Социальные сети
Координаты геолокаций
Данные с
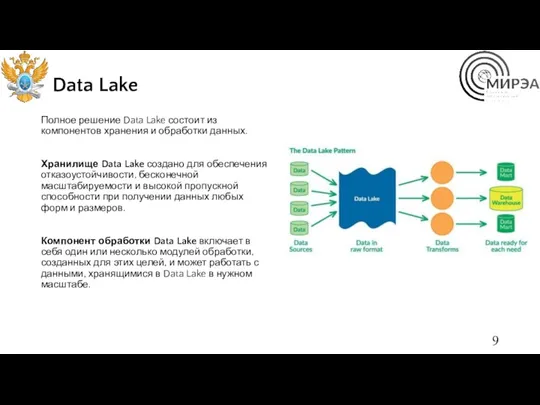
Data Lake
Полное решение Data Lake состоит из компонентов хранения и
Data Lake
Полное решение Data Lake состоит из компонентов хранения и

Когда следует использовать Data Lake
К наиболее распространенным сферам применения Data Lake
Когда следует использовать Data Lake
К наиболее распространенным сферам применения Data Lake

Сравнение с DWH
Нагрузка
Схема
Масштабирование
Методы доступа
Преимущества
Кто пользователи?
SQL
Данные
Сравнение с DWH
Нагрузка
Схема
Масштабирование
Методы доступа
Преимущества
Кто пользователи?
SQL
Данные

Сравнение с хранилищем данных
Сравнение с хранилищем данных

Сравнение с хранилищем данных
Сравнение с хранилищем данных

Сложности
Отсутствие схемы и описательных метаданных создает трудности при использовании данных и
Сложности
Отсутствие схемы и описательных метаданных создает трудности при использовании данных и

Инструменты
Инструменты
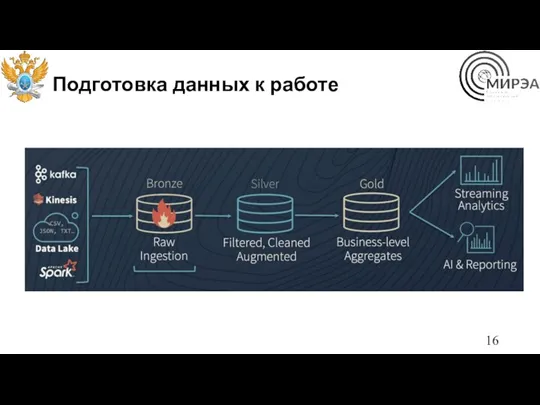
Подготовка данных к работе
Подготовка данных к работе

Часть 2. Экосистема Hadoop. Файловая система HDFS. Обработка данных с применением
Часть 2. Экосистема Hadoop. Файловая система HDFS. Обработка данных с применением
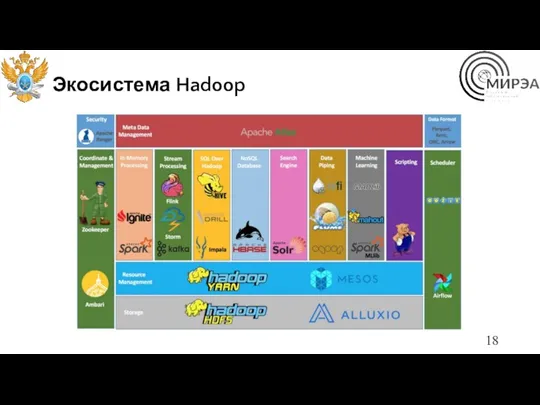
Экосистема Hadoop
Экосистема Hadoop

Элементы Hadoop
Hadoop – программный комплекс для хранения и обработки больших объемов
Элементы Hadoop
Hadoop – программный комплекс для хранения и обработки больших объемов

Система Hadoop
Hadoop обслуживает распределенный кластер на программном уровне, эмулируя файловую систему
Система Hadoop
Hadoop обслуживает распределенный кластер на программном уровне, эмулируя файловую систему

Распределенная файловая система
Подсистема хранения HDFS разбивает файлы на блоки фиксированного размера.
Распределенная файловая система
Подсистема хранения HDFS разбивает файлы на блоки фиксированного размера.
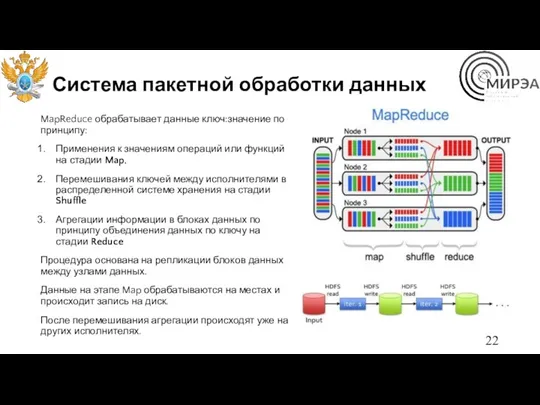
Система пакетной обработки данных
MapReduce обрабатывает данные ключ:значение по принципу:
Применения к
Система пакетной обработки данных
MapReduce обрабатывает данные ключ:значение по принципу:
Применения к
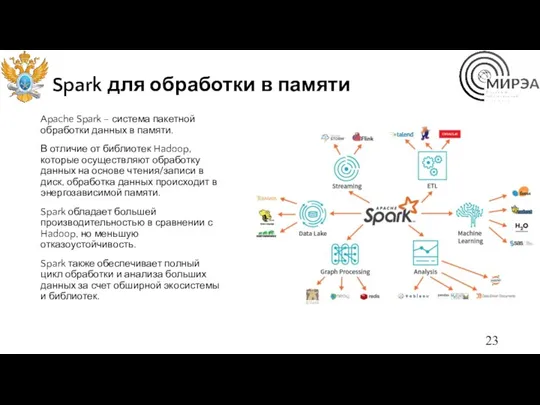
Spark для обработки в памяти
Apache Spark – система пакетной обработки данных
Spark для обработки в памяти
Apache Spark – система пакетной обработки данных
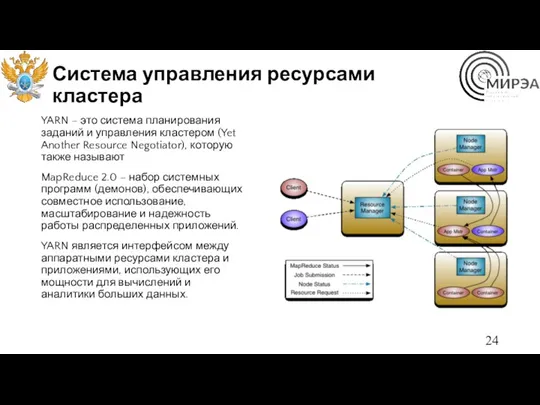
Система управления ресурсами кластера
YARN – это система планирования заданий и управления
Система управления ресурсами кластера
YARN – это система планирования заданий и управления

Система управления ресурсами кластера
ResourceManager (RM) — менеджер ресурсов, которых отвечает за распределение
Система управления ресурсами кластера
ResourceManager (RM) — менеджер ресурсов, которых отвечает за распределение
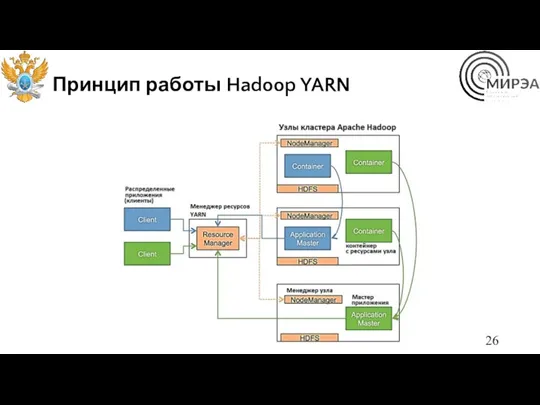
Принцип работы Hadoop YARN
Принцип работы Hadoop YARN
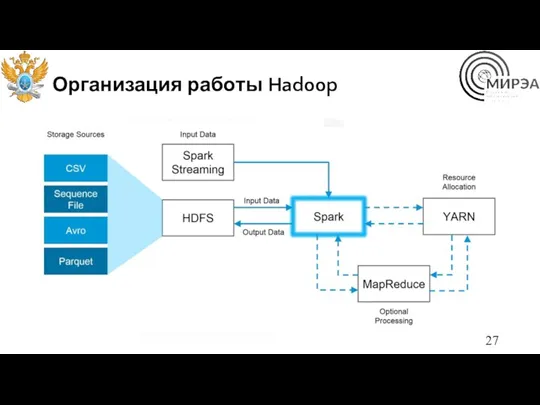
Организация работы Hadoop
Организация работы Hadoop

Часть 3. Потоки данных. Обмен данными в системах BigData
Часть 3. Потоки данных. Обмен данными в системах BigData

Пакетная обработка данных
Система пакетной обработки данных – конвейер обработки данных, состоящий
Пакетная обработка данных
Система пакетной обработки данных – конвейер обработки данных, состоящий

Обработка и применение
При пакетной обработке данных с данными в одном пакете
Обработка и применение
При пакетной обработке данных с данными в одном пакете
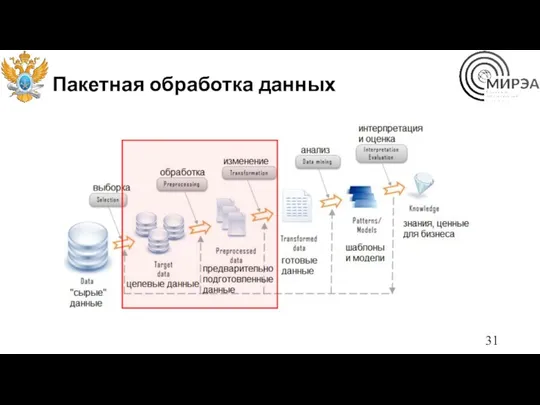
Пакетная обработка данных
Пакетная обработка данных

Пакетная обработка данных
Примеры применения пакетной обработки данных:
обработка данных с применением MapReduce
стандартная
Пакетная обработка данных
Примеры применения пакетной обработки данных:
обработка данных с применением MapReduce
стандартная

Потоковая обработка данных
Потоковая обработка это однопроходная парадигма обработки данных, которая всегда
Потоковая обработка данных
Потоковая обработка это однопроходная парадигма обработки данных, которая всегда
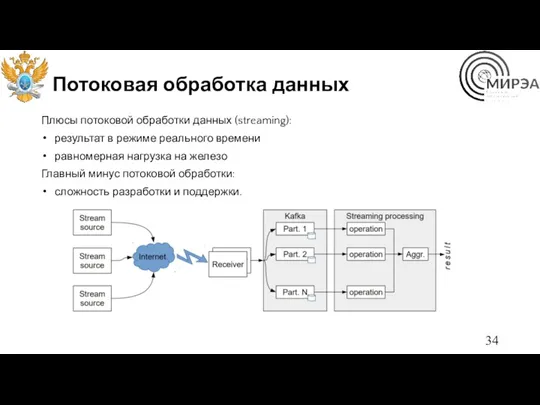
Потоковая обработка данных
Плюсы потоковой обработки данных (streaming):
результат в режиме реального времени
равномерная
Потоковая обработка данных
Плюсы потоковой обработки данных (streaming):
результат в режиме реального времени
равномерная

Элементы потоковой обработки
Элементы системы потоковой обработки данных
Загрузчик данных (средство доставки данных
Элементы потоковой обработки
Элементы системы потоковой обработки данных
Загрузчик данных (средство доставки данных
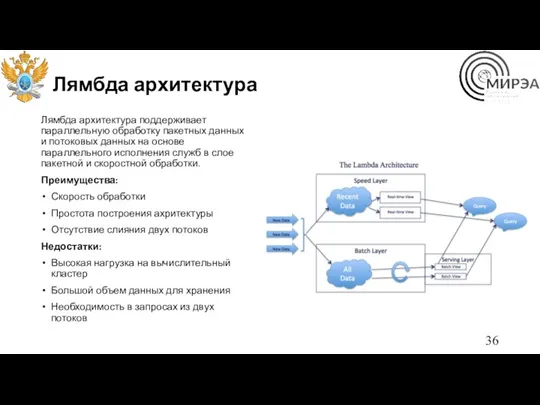
Лямбда архитектура
Лямбда архитектура поддерживает параллельную обработку пакетных данных и потоковых данных
Лямбда архитектура
Лямбда архитектура поддерживает параллельную обработку пакетных данных и потоковых данных
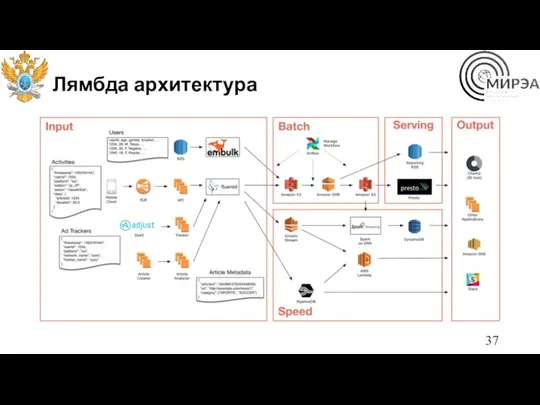
Лямбда архитектура
Лямбда архитектура
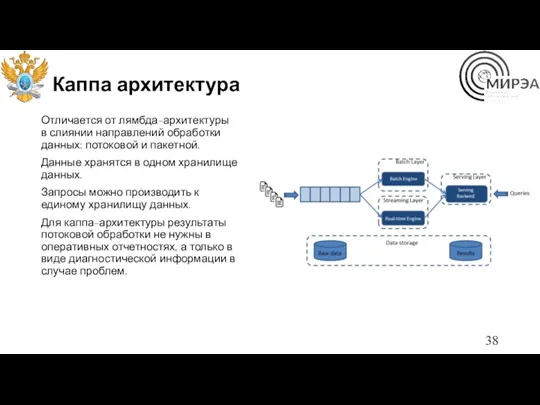
Каппа архитектура
Отличается от лямбда-архитектуры в слиянии направлений обработки данных: потоковой и
Каппа архитектура
Отличается от лямбда-архитектуры в слиянии направлений обработки данных: потоковой и
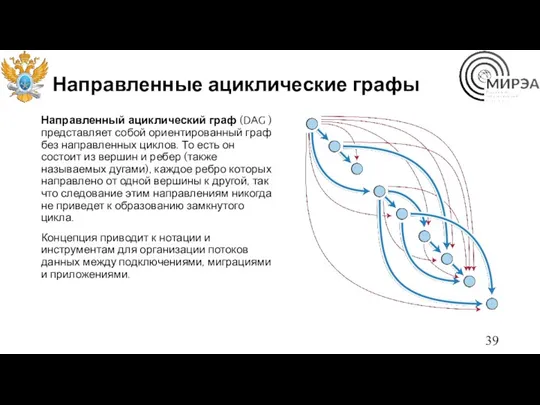
Направленные ациклические графы
Направленный ациклический граф (DAG ) представляет собой ориентированный граф
Направленные ациклические графы
Направленный ациклический граф (DAG ) представляет собой ориентированный граф

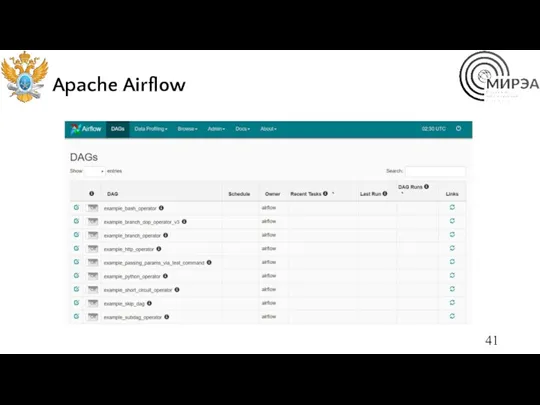
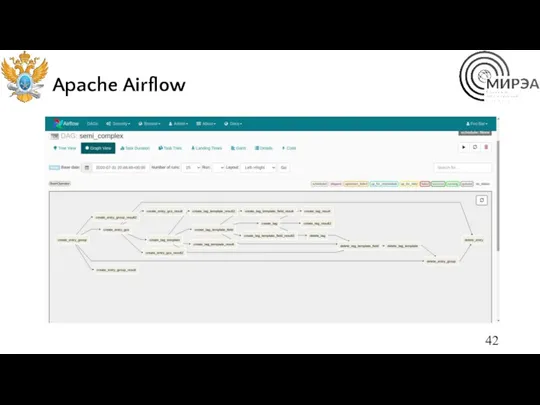
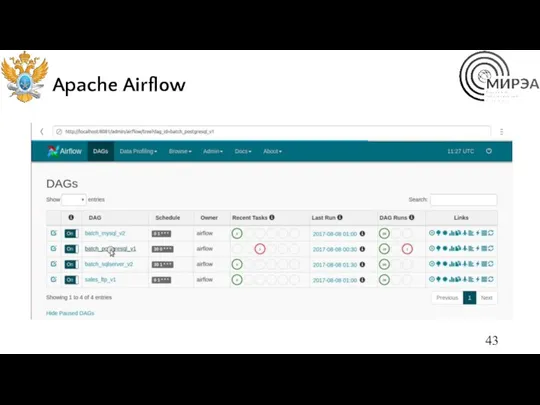
Apache Airflow
Apache Airflow — открытое программное обеспечение для создания, выполнения, мониторинга
Apache Airflow
Apache Airflow — открытое программное обеспечение для создания, выполнения, мониторинга
Apache Airflow
Apache Airflow
Apache Airflow
Apache Airflow
Apache Airflow
Apache Airflow

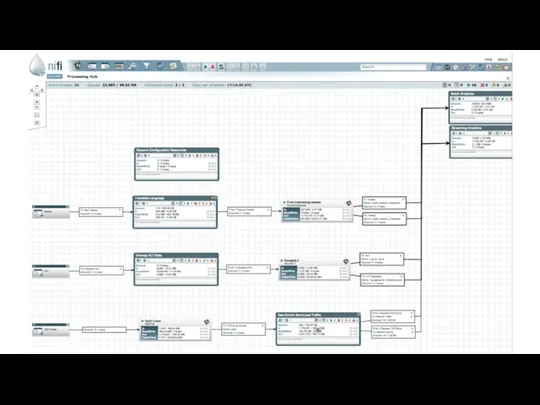
Apache Nifi
Apache NiFi — это открытое программное обеспечение проекта Apache Software
Apache Nifi
Apache NiFi — это открытое программное обеспечение проекта Apache Software
Apache Nifi
Apache Nifi

Loginom
Loginom — аналитическая платформа, позволяющая в единой среде выполнить все этапы
Loginom
Loginom — аналитическая платформа, позволяющая в единой среде выполнить все этапы
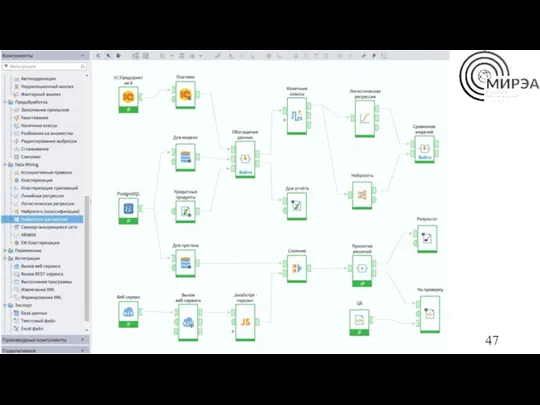
Loginom
Loginom
 Основы облачных вычислений
Основы облачных вычислений Пиши код правильно
Пиши код правильно Параллельное и распределенное программирование. Технология программирования гетерогенных систем
Параллельное и распределенное программирование. Технология программирования гетерогенных систем Языки программирования. Язык Паскаль
Языки программирования. Язык Паскаль Операції над об’єктами файлової системи
Операції над об’єктами файлової системи Формирование списков на Web-странице
Формирование списков на Web-странице Государственная информационная система жилищно-коммунального хозяйства
Государственная информационная система жилищно-коммунального хозяйства Правовые нормы, относящиеся к информации, правонарушения в информационной сфере, меры их предупреждения
Правовые нормы, относящиеся к информации, правонарушения в информационной сфере, меры их предупреждения Приложение TapTable
Приложение TapTable Техника безопасности в кабинете информатики
Техника безопасности в кабинете информатики Загальні відомості про електронну комерцію
Загальні відомості про електронну комерцію Принципы работы в сети интернет
Принципы работы в сети интернет Пространственная фильтрация, обработка в частотной области и восстановление изображения (Matlab)
Пространственная фильтрация, обработка в частотной области и восстановление изображения (Matlab) Безопасный интернет
Безопасный интернет Основи растрової графіки. Використання фото та кліпартів. Растрова анімація
Основи растрової графіки. Використання фото та кліпартів. Растрова анімація Операционные системы
Операционные системы Кодирование и обработка звуковой информации
Кодирование и обработка звуковой информации Әлеуметтік желілердегі хаттар тілі:түрі,лексика-грамматикалық сипаты
Әлеуметтік желілердегі хаттар тілі:түрі,лексика-грамматикалық сипаты Создание простейшей веб-страницы. Работа в редакторе Блокнот
Создание простейшей веб-страницы. Работа в редакторе Блокнот Optical identification using imperfections in 2D materials
Optical identification using imperfections in 2D materials Носители информации
Носители информации Компьютерные вирусы и антивирусные программы
Компьютерные вирусы и антивирусные программы Как устроена книга
Как устроена книга Логика. Основные понятия
Логика. Основные понятия Операционные системы
Операционные системы Системы перевода и распознавания текстов
Системы перевода и распознавания текстов Operators & Expressions. Lecture 3
Operators & Expressions. Lecture 3 Подготовка к СОР. 9 класс
Подготовка к СОР. 9 класс