Параллельное и распределенное программирование. Технология программирования гетерогенных систем презентация
- Параллельное и распределенное программирование. Технология программирования гетерогенных систем

Содержание
- 2. Архитектура GPU
- 3. Традиционная архитектура CPU CPU оптимизированы для минимизации задержки одного потока Может эффективно обрабатывать рабочие нагрузки с
- 4. Современная архитектура GPGPU Массив независимых «ядер», называемых Compute Units (AMD) или потоковых мультипроцессоров (NVIDIA) Высокая пропускная
- 5. Современная архитектура GPGPU Вычислительные устройства основаны на оборудовании SIMD Как у AMD, так и у NVIDIA
- 6. Современная архитектура GPGPU Рабочие элементы автоматически группируются в аппаратные потоки, называемые «wavefronts» (AMD) или «warps» (NVIDIA)
- 7. SIMT и SIMD NVIDIA придумала «Single Instruction Multiple Threads» (SIMT) для обозначения нескольких (программных) потоков, совместно
- 8. AMD R9 290X Архитектура вычислений
- 9. AMD R9 290X Wavefronts связаны с модулем SIMD и подмножеством векторных регистров С каждым SIMD может
- 10. Модель памяти в OpenCL Глобальная память для кэширования Основная память GDDR5 Константная память Память скалярного блока
- 11. AMD GPU архитектура in OpenCL R9 290X в OpenCL
- 12. Идеальное ядро GPGPU Идеальное ядро для GPU Имеет тысячи самостоятельных вычислительные единицы Использует все доступные вычислительные
- 13. Буферы
- 14. План Создание объектов памяти (например, буферов) Параметры флага памяти Буферы записи и чтения Управление объектами памяти
- 15. Буферы Объекты памяти используются для передачи больших структур данных в ядра OpenCL Наиболее прямым объектом является
- 16. Флаги памяти Поле флага памяти в clCreateBuffer () позволяет нам определять атрибуты буферного объекта:
- 17. Буферы Следующий код создает буфер только для чтения и инициализирует его данными из массива хоста Предполагается,
- 18. Буферы для записи OpenCL предоставляет команды для чтения или записи данных из буфера Использование командной очереди
- 19. Буферы для записи Пример, показывающий создание и инициализацию буфера cl_int err; int a[16]; for (int i
- 20. Буферы для записи В следующем примере показано создание и инициализация буфера, использование его в ядре без
- 21. Буферы для записи В качестве альтернативы среда выполнения может решить создать буфер непосредственно в памяти устройства
- 22. Буферы для чтения Бесплатный вызов для записи буфера (буфер считывается обратно в память хоста) Следующая диаграмма
- 23. Перенос (миграция) объектов памяти OpenCL предоставляет вызов API для переноса объектов памяти между устройствами В отличие
- 24. Память, доступная с хоста При создании объекта памяти флаги могут указывать, что объект должен быть создан
- 25. Память, доступная с хоста Специальная обработка флагов (AMD) CL_MEM_ALLOC_HOST_PTR и CL_MEM_USE_HOST_PTR Если устройства поддерживают виртуальную память,
- 26. Отображение данных в память хоста OpenCL предоставляет API-вызовы для отображения и распаковки объектов памяти из пространства
- 27. Отображение данных в память хоста В приведенном ниже примере показан один возможный сценарий для функций map
- 28. Выводы Объекты памяти создаются и управляются хостом с помощью вызовов OpenCL API Параметры, предоставленные во время
- 29. Изображения и каналы Images и Pipes в OpenCL 2.0
- 30. План Объекты памяти, введенные в спецификации OpenCL 2.0 Изображения Каналы (pipes) Объекты памяти специального назначения и
- 31. Изображения Массивы C / C ++ и объекты буфера OpenCL (cl_mem) обеспечивают 1D локальность Графические процессоры
- 32. Изображения Изображения специально разработаны для управления объектами графических данных Элементы изображений не могут быть доступны непосредственно
- 33. Преимущества изображений Интерполяция Доступ к изображениям осуществляется с помощью координат с плавающей запятой Возвращается любой ближайший
- 34. Преимущества изображений Обработка исключений Поведение доступа за пределами границ обрабатывается аппаратными средствами Флаги, указанные при создании
- 35. Преимущества изображений Каналы в изображениях OpenCL относятся к основным цветам, которые составляют изображение Каждый пиксель в
- 36. Создание изображений Декларации изображений состоят из дескрипторов и форматов Использование изображений в ядрах требует объявления объекта
- 37. Дескрипторы и форматы изображений Свойства изображения, указанные в структуре cl_image_desc, включая Тип изображения - 1D, 2D
- 38. Сэмплер изображения (Image sampler ) Image sampler описывает, как получить доступ к объекту изображения Сэмплеры указывают:
- 39. Использование изображений в ядре Форматы изображений не такие, как базовые типы OpenCL (int, float, char и
- 40. Использование изображений в ядре __kernel void rotation( __read_only image2d_t inputImage, __write_only image2d_t outputImage, int imageWidth, int
- 41. Каналы (Pipes) Новый объект памяти, введенный в спецификации OpenCL 2.0 Данные организованы как пакеты в структуре
- 42. Каналы (Pipes) Данные в канале организованы как пакеты Пакет может иметь тип, поддерживаемый OpenCL C Глубина
- 43. Каналы (Pipes) В ядре каналы должны быть объявлены с использованием ключевого слова pipe, квалификатора доступа (read_only
- 44. Каналы (Pipes) Подобно изображениям, каналы представляют собой непрозрачные объекты Доступ к каналу в ядре выполняется с
- 45. Pipes – идентификатор резервирования Существуют функции OpenCL для резервирования места в канале заранее Доступ гарантируется Эти
- 46. Pipes – идентификатор резервирования Идентификаторы резервирования передаются в перегруженные версии read_pipe () и write_pipe () дополнительно
- 47. Каналы (Pipes) Дополнительные версии вызовов резервирования и фиксации каналов существуют в детализации рабочей группы work_group_reserve_read_pipe ()
- 49. Скачать презентацию

Архитектура GPU
Архитектура GPU
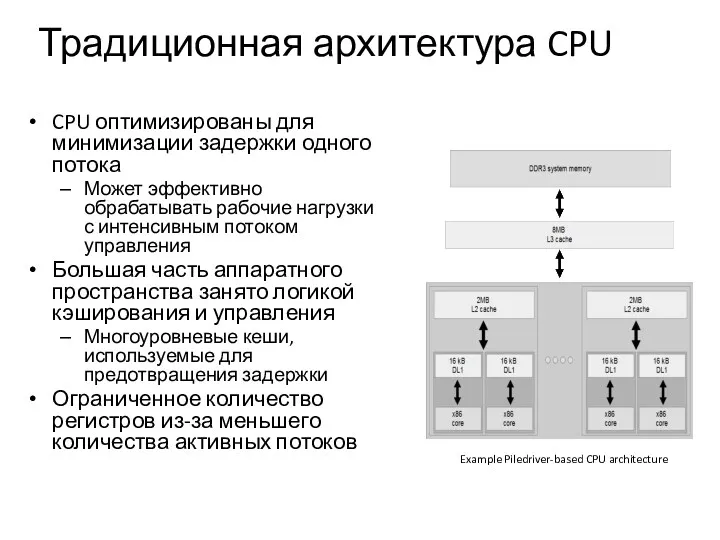
Традиционная архитектура CPU
CPU оптимизированы для минимизации задержки одного потока
Может эффективно обрабатывать
Традиционная архитектура CPU
CPU оптимизированы для минимизации задержки одного потока
Может эффективно обрабатывать

Современная архитектура GPGPU
Массив независимых «ядер», называемых Compute Units (AMD) или
Современная архитектура GPGPU
Массив независимых «ядер», называемых Compute Units (AMD) или

Современная архитектура GPGPU
Вычислительные устройства основаны на оборудовании SIMD
Как у AMD,
Современная архитектура GPGPU
Вычислительные устройства основаны на оборудовании SIMD
Как у AMD,

Современная архитектура GPGPU
Рабочие элементы автоматически группируются в аппаратные потоки, называемые
Современная архитектура GPGPU
Рабочие элементы автоматически группируются в аппаратные потоки, называемые

SIMT и SIMD
NVIDIA придумала «Single Instruction Multiple Threads» (SIMT) для обозначения
SIMT и SIMD
NVIDIA придумала «Single Instruction Multiple Threads» (SIMT) для обозначения
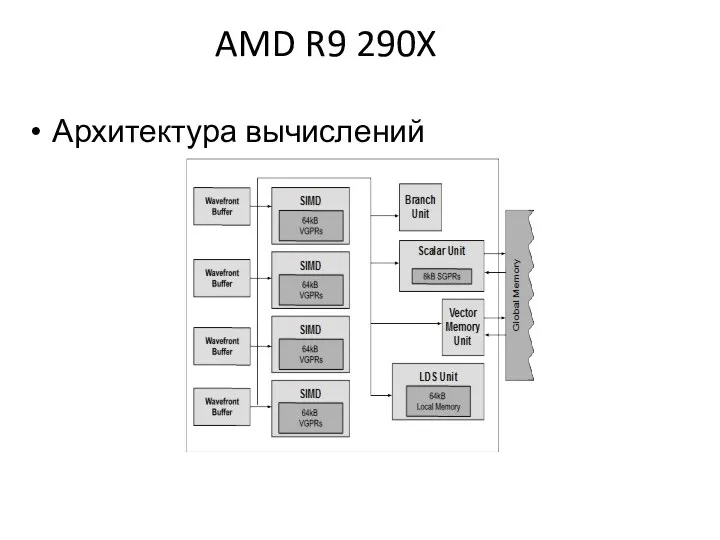
AMD R9 290X
Архитектура вычислений
AMD R9 290X
Архитектура вычислений

AMD R9 290X
Wavefronts связаны с модулем SIMD и подмножеством векторных регистров
С
AMD R9 290X
Wavefronts связаны с модулем SIMD и подмножеством векторных регистров
С
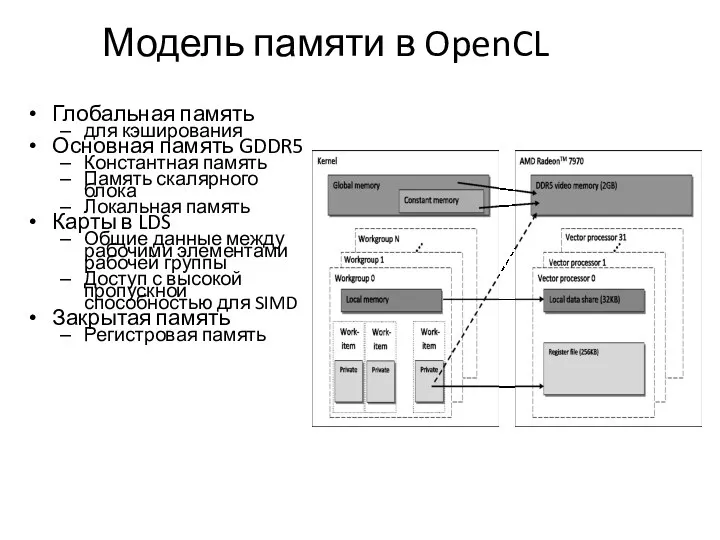
Модель памяти в OpenCL
Глобальная память
для кэширования
Основная память GDDR5
Константная память
Память скалярного
Модель памяти в OpenCL
Глобальная память
для кэширования
Основная память GDDR5
Константная память
Память скалярного
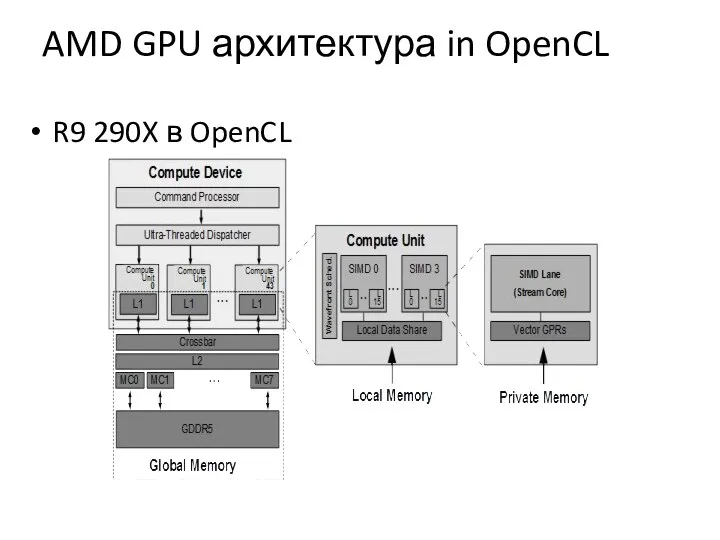
AMD GPU архитектура in OpenCL
R9 290X в OpenCL
AMD GPU архитектура in OpenCL
R9 290X в OpenCL

Идеальное ядро GPGPU
Идеальное ядро для GPU
Имеет тысячи самостоятельных вычислительные единицы
Использует все
Идеальное ядро GPGPU
Идеальное ядро для GPU
Имеет тысячи самостоятельных вычислительные единицы
Использует все

Буферы
Буферы

План
Создание объектов памяти (например, буферов)
Параметры флага памяти
Буферы записи и чтения
Управление объектами
План
Создание объектов памяти (например, буферов)
Параметры флага памяти
Буферы записи и чтения
Управление объектами

Буферы
Объекты памяти используются для передачи больших структур данных в ядра OpenCL
Наиболее
Буферы
Объекты памяти используются для передачи больших структур данных в ядра OpenCL
Наиболее
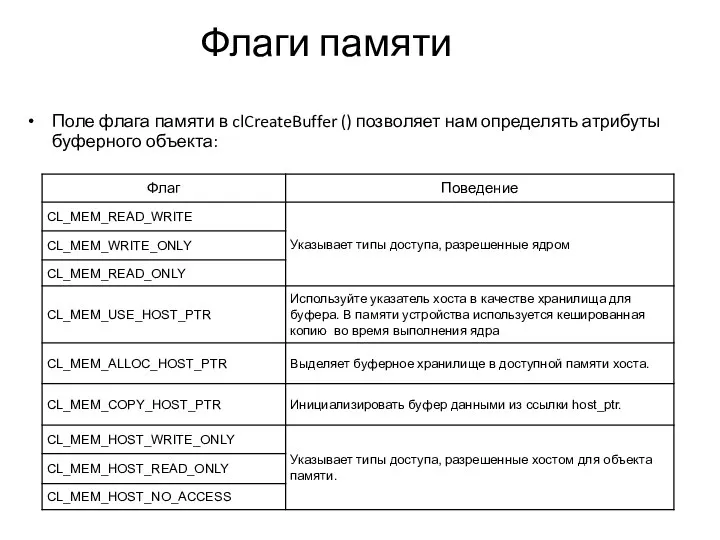
Флаги памяти
Поле флага памяти в clCreateBuffer () позволяет нам определять атрибуты
Флаги памяти
Поле флага памяти в clCreateBuffer () позволяет нам определять атрибуты

Буферы
Следующий код создает буфер только для чтения и инициализирует его данными
Буферы
Следующий код создает буфер только для чтения и инициализирует его данными

Буферы для записи
OpenCL предоставляет команды для чтения или записи данных из
Буферы для записи
OpenCL предоставляет команды для чтения или записи данных из

Буферы для записи
Пример, показывающий создание и инициализацию буфера
cl_int err;
int a[16];
for (int
Буферы для записи
Пример, показывающий создание и инициализацию буфера
cl_int err;
int a[16];
for (int
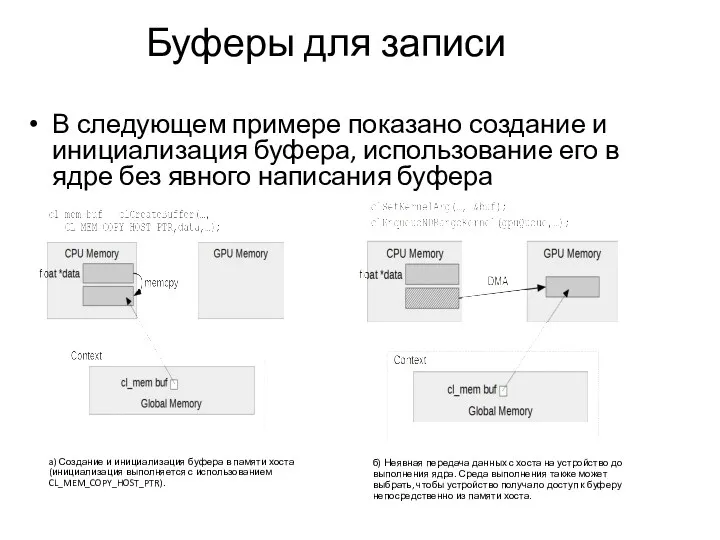
Буферы для записи
В следующем примере показано создание и инициализация буфера, использование
Буферы для записи
В следующем примере показано создание и инициализация буфера, использование
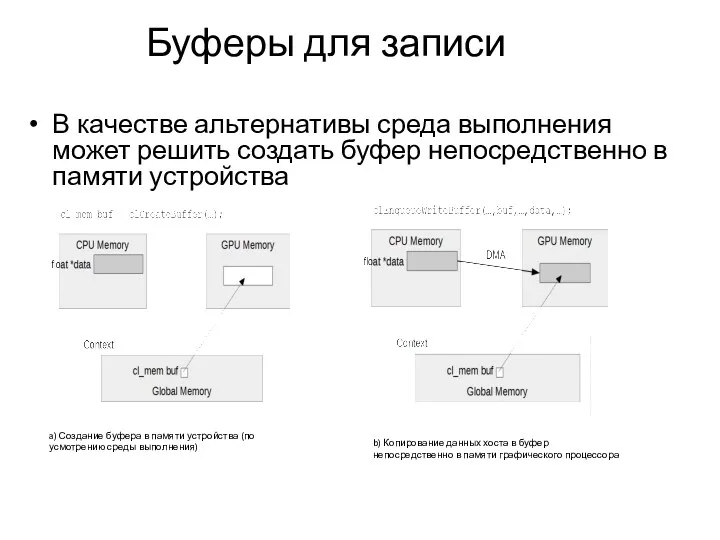
Буферы для записи
В качестве альтернативы среда выполнения может решить создать буфер
Буферы для записи
В качестве альтернативы среда выполнения может решить создать буфер

Буферы для чтения
Бесплатный вызов для записи буфера (буфер считывается обратно в
Буферы для чтения
Бесплатный вызов для записи буфера (буфер считывается обратно в

Перенос (миграция) объектов памяти
OpenCL предоставляет вызов API для переноса объектов памяти
Перенос (миграция) объектов памяти
OpenCL предоставляет вызов API для переноса объектов памяти

Память, доступная с хоста
При создании объекта памяти флаги могут указывать, что
Память, доступная с хоста
При создании объекта памяти флаги могут указывать, что

Память, доступная с хоста
Специальная обработка флагов (AMD)
CL_MEM_ALLOC_HOST_PTR и CL_MEM_USE_HOST_PTR
Если устройства поддерживают
Память, доступная с хоста
Специальная обработка флагов (AMD)
CL_MEM_ALLOC_HOST_PTR и CL_MEM_USE_HOST_PTR
Если устройства поддерживают

Отображение данных в память хоста
OpenCL предоставляет API-вызовы для отображения и распаковки
Отображение данных в память хоста
OpenCL предоставляет API-вызовы для отображения и распаковки
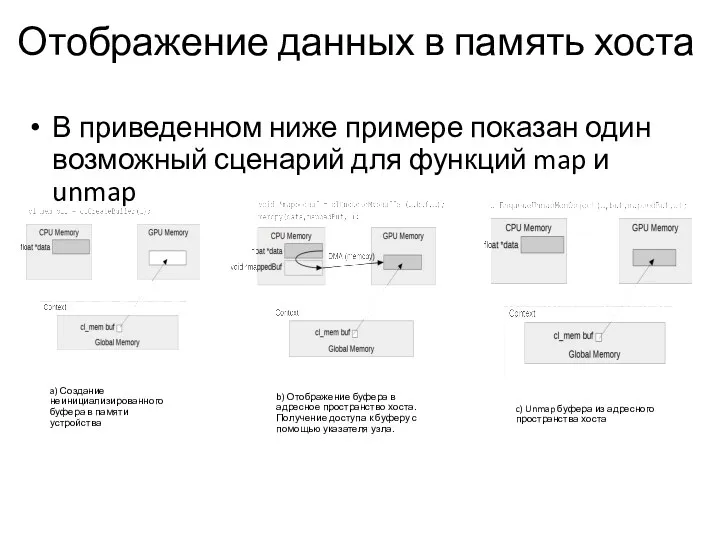
Отображение данных в память хоста
В приведенном ниже примере показан один возможный
Отображение данных в память хоста
В приведенном ниже примере показан один возможный

Выводы
Объекты памяти создаются и управляются хостом с помощью вызовов OpenCL API
Параметры,
Выводы
Объекты памяти создаются и управляются хостом с помощью вызовов OpenCL API
Параметры,

Изображения и каналы
Images и Pipes
в OpenCL 2.0
Изображения и каналы
Images и Pipes
в OpenCL 2.0

План
Объекты памяти, введенные в спецификации OpenCL 2.0
Изображения
Каналы (pipes)
Объекты памяти специального назначения
План
Объекты памяти, введенные в спецификации OpenCL 2.0
Изображения
Каналы (pipes)
Объекты памяти специального назначения

Изображения
Массивы C / C ++ и объекты буфера OpenCL (cl_mem) обеспечивают
Изображения
Массивы C / C ++ и объекты буфера OpenCL (cl_mem) обеспечивают

Изображения
Изображения специально разработаны для управления объектами графических данных
Элементы изображений не могут
Изображения
Изображения специально разработаны для управления объектами графических данных
Элементы изображений не могут

Преимущества изображений
Интерполяция
Доступ к изображениям осуществляется с помощью координат с плавающей запятой
Возвращается
Преимущества изображений
Интерполяция
Доступ к изображениям осуществляется с помощью координат с плавающей запятой
Возвращается

Преимущества изображений
Обработка исключений
Поведение доступа за пределами границ обрабатывается аппаратными средствами
Флаги, указанные
Преимущества изображений
Обработка исключений
Поведение доступа за пределами границ обрабатывается аппаратными средствами
Флаги, указанные

Преимущества изображений
Каналы в изображениях OpenCL относятся к основным цветам, которые составляют
Преимущества изображений
Каналы в изображениях OpenCL относятся к основным цветам, которые составляют

Создание изображений
Декларации изображений состоят из дескрипторов и форматов
Использование изображений в ядрах
Создание изображений
Декларации изображений состоят из дескрипторов и форматов
Использование изображений в ядрах

Дескрипторы и форматы изображений
Свойства изображения, указанные в структуре cl_image_desc, включая
Тип изображения
Дескрипторы и форматы изображений
Свойства изображения, указанные в структуре cl_image_desc, включая
Тип изображения

Сэмплер изображения
(Image sampler )
Image sampler описывает, как получить доступ к
Сэмплер изображения
(Image sampler )
Image sampler описывает, как получить доступ к

Использование изображений в ядре
Форматы изображений не такие, как базовые типы OpenCL
Использование изображений в ядре
Форматы изображений не такие, как базовые типы OpenCL

Использование изображений в ядре
__kernel
void rotation(
__read_only image2d_t inputImage, __write_only image2d_t outputImage,
Использование изображений в ядре
__kernel
void rotation(
__read_only image2d_t inputImage, __write_only image2d_t outputImage,
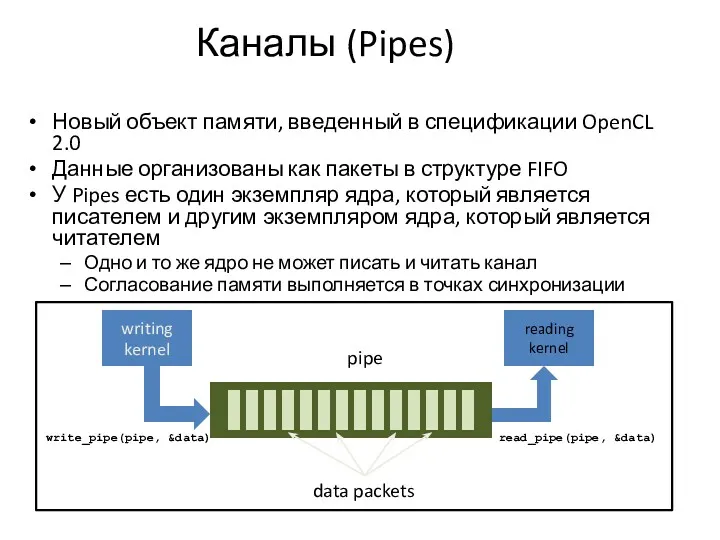
Каналы (Pipes)
Новый объект памяти, введенный в спецификации OpenCL 2.0
Данные организованы как
Каналы (Pipes)
Новый объект памяти, введенный в спецификации OpenCL 2.0
Данные организованы как

Каналы (Pipes)
Данные в канале организованы как пакеты
Пакет может иметь тип, поддерживаемый
Каналы (Pipes)
Данные в канале организованы как пакеты
Пакет может иметь тип, поддерживаемый

Каналы (Pipes)
В ядре каналы должны быть объявлены с использованием ключевого слова
Каналы (Pipes)
В ядре каналы должны быть объявлены с использованием ключевого слова

Каналы (Pipes)
Подобно изображениям, каналы представляют собой непрозрачные объекты
Доступ к каналу в
Каналы (Pipes)
Подобно изображениям, каналы представляют собой непрозрачные объекты
Доступ к каналу в

Pipes – идентификатор резервирования
Существуют функции OpenCL для резервирования места в канале
Pipes – идентификатор резервирования
Существуют функции OpenCL для резервирования места в канале

Pipes – идентификатор резервирования
Идентификаторы резервирования передаются в перегруженные версии read_pipe ()
Pipes – идентификатор резервирования
Идентификаторы резервирования передаются в перегруженные версии read_pipe ()

Каналы (Pipes)
Дополнительные версии вызовов резервирования и фиксации каналов существуют в детализации
Каналы (Pipes)
Дополнительные версии вызовов резервирования и фиксации каналов существуют в детализации
 Анимация, звук, цифровое фото и видео
Анимация, звук, цифровое фото и видео Электронная таблица Excel
Электронная таблица Excel Электронные библиотеки. Президентская библиотека им.Ельцина
Электронные библиотеки. Президентская библиотека им.Ельцина Назначение и принцип работы BIOS
Назначение и принцип работы BIOS Маршрутизация. Методы маршрутизации. Протоколы маршрутизации
Маршрутизация. Методы маршрутизации. Протоколы маршрутизации Информационные технологии в библиотеке
Информационные технологии в библиотеке Модель сетевого взаимодействия
Модель сетевого взаимодействия Типы данных в языке Паскаль
Типы данных в языке Паскаль Что такое биометрические данные?
Что такое биометрические данные? CAD/CAM services
CAD/CAM services Information and Communication Technologies
Information and Communication Technologies The Basics of Computer Networking
The Basics of Computer Networking Использование метода проектов в современной школе
Использование метода проектов в современной школе Базы данных в электронных таблицах
Базы данных в электронных таблицах Friar SlidesCarnival
Friar SlidesCarnival Основы информационно-библиографической культуры
Основы информационно-библиографической культуры Визуальные алгоритмы SLAM
Визуальные алгоритмы SLAM Основы системного анализа
Основы системного анализа Журнал №118. Газета гимназии №2 г. Железнодорожный. День учителя
Журнал №118. Газета гимназии №2 г. Железнодорожный. День учителя История развития социальных сетей
История развития социальных сетей Структура, цикл
Структура, цикл Партнерская программа интернет магазина
Партнерская программа интернет магазина Доменная система имён. Протоколы передачи данных
Доменная система имён. Протоколы передачи данных Программирование на языке Python. § 54. Введение в язык Python
Программирование на языке Python. § 54. Введение в язык Python VBA development technology. (Lecture 6)
VBA development technology. (Lecture 6) Системы счисления
Системы счисления Путешествие по стране Интернетии
Путешествие по стране Интернетии Курс С#. Программирование на языке высокого уровня. Лекция 1
Курс С#. Программирование на языке высокого уровня. Лекция 1