- Технологии параллельного программирования

Содержание
- 2. Развитые средства и технологии для разработки параллельных программ Автоматическое распараллеливание Библиотеки нитей (threads) Win32/64 API POSIX
- 3. Автоматическое распараллеливание Автоматическое (автоматизированное) распараллеливание (automatic parallelization) предполагает выполнение оптимизации программного кода компилятором путем преобразования в
- 4. #include #include #include #define NUM_THREADS 5 void *PrintHello(void *threadid) { long tid; tid = (long)threadid; printf("Hello
- 5. Пример - вычисление определенного интеграла
- 6. PROGRAM PI_SERIAL INTEGER I, N DOUBLE PRECISION X, STEP, PI, SUM /0.0/ PARAMETER (N=100000000) STEP =
- 7. PROGRAM PI_OPENMP INCLUDE 'omp_lib.h' INTEGER I, N, NTHREADS, TID, ISTART, IEND DOUBLE PRECISION X, STEP, PI,
- 8. Вариант программы с использованием MPI PROGRAM PI_MPI INCLUDE 'mpif.h' DOUBLE PRECISION PROC_SUM, PI, H, SUM, X,
- 9. #include #include #define NUM_THREADS 2 CRITICAL_SECTION hCriticalSection; double pi = 0.0; int n =100000; void main
- 10. OpenMP (Open Multi-Processing) - развитый высокоуровневый интерфейс прикладного программирования (Application Programming Interface, API), предназначенный для параллелизации
- 11. Версии спецификации OpenMP 2011 OpenMP F/C/C++ 3.1 2013 OpenMP F/C/C++ 4.0 http://www.openmp.org OpenMP F/C/C++ 4.1 2015
- 12. Коммерческие компиляторы: Intel C/C++ / Fortran Compilers (http://software.intel.com/en-us/intel-compilers/) Microsoft Visual Studio (https://www.visualstudio.com, нет компилятора Fortran) The
- 13. Основы OpenMP. Модель исполнения программ Модель исполнения программ в OpenMP основана на параллельной работе разделяющих общую
- 14. Основы OpenMP. Модель исполнения программ OpenMP базируется на высокоуровневой реализации механизмов многопоточности, поддерживаемых системой управления стандарта.
- 15. Основы OpenMP. Модель памяти Модель памяти, на которую опирается стандарт OpenMP, предполагает, что все нити имеют
- 16. Основы OpenMP. Модель памяти Одна из важнейших задач при разработке многопоточных приложений - обеспечение корректной и
- 17. За низкоуровневые детали реализации отвечает компилятор и управляющая система стандарта, а разработчик занимается выбором и указанием
- 18. Общие сведения о директивах OpenMP Термин директива (directive) закреплен в OpenMP за наиболее многочисленной конструкцией стандарта,
- 19. Общие сведения о директивах OpenMP: синтаксис директив Общие синтаксические правила включения директив и атрибутов OpenMP в
- 20. Общие сведения о директивах OpenMP: условная компиляция программ Организация условной компиляции программы позволяет развивать единый код
- 21. Общие сведения о библиотечных подпрограммах Библиотечные подпрограммы OpenMP позволяют задавать и осуществлять контроль над параметрами среды
- 22. Общие сведения о переменных окружения Переменные окружения OpenMP служат для создания переносимой среды запуска параллельных программ.
- 23. PROGRAM OPENMP_HELLO_WORLD INCLUDE 'omp_lib.h' INTEGER N, TID !$OMP PARALLEL PRIVATE(TID) TID = OMP_GET_THREAD_NUM() PRINT *, 'Hello,
- 24. PROGRAM OPENMP_PI INCLUDE 'omp_lib.h' INTEGER I, N, NTHREADS, TID, ISTART, IEND DOUBLE PRECISION X, STEP, PI,
- 25. Директивы и атрибуты OpenMP
- 26. Директивы и атрибуты OpenMP. Назначение параллельных областей программы Язык Fortran !$OMP PARALLEL [CLAUSE[[,] CLAUSE]...] STRUCTURED-BLOCK !$OMP
- 27. Многоуровневый (вложенный) параллелизм Стандарт OpenMP разрешает использовать в программах неограниченную вложенность параллельных областей друг в друга.
- 28. Переменные в параллельных областях OpenMP-программы (с позиций доступности для обращения к ним со стороны нитей) могут
- 29. Классы переменных в OpenMP FIRSTPRIVATE(LIST) LASTPRIVATE(LIST) Атрибут-оператор FIRSTPRIVATE позволяет выполнить автоматическую инициализацию создаваемых в нитях копий
- 30. Классы переменных в OpenMP Совместная обработка локальных переменных REDUCTION({OPERATOR |INTRINSIC_PROCEDURE_NAME}:LIST) Специальный тип переменных, задаваемый атрибутом-оператором REDUCTION,
- 31. Управление данными в OpenMP Назначение постоянно существующих в программе локальных переменных Описательная (декларативная) директива THREADPRIVATE позволяет
- 32. PROGRAM OPENMP_THREADPRIVATE INCLUDE 'omp_lib.h' INTEGER I, TID COMMON /BLOCK/ I !$OMP THREADPRIVATE(/BLOCK/) I=-1 CALL OMP_SET_DYNAMIC(.FALSE.) PRINT
- 33. Управление данными в OpenMP Атрибуты копирования значений локальных переменных COPYIN(LIST) COPYPRIVATE(LIST) Атрибуты копирования значений переменных реализуют
- 34. Распределение работы между нитями в параллельных областях Явное распределение работы между нитями Распределение выполняемых внутри параллельной
- 35. Явное распределение работы между нитями. Пример 1 PROGRAM OPENMP_PI_SPMD INCLUDE 'omp_lib.h' INTEGER I, N, NTHREADS, TID,
- 36. PROGRAM OPENMP_DAXPY_SPMD INCLUDE 'omp_lib.h' INTEGER I, ISTART, IEND, N, NTHREADS, TID PARAMETER (NTHREADS=2, N=100000000) DOUBLE PRECISION
- 37. Директивы параллелизации циклов !$OMP DO [CLAUSE[[,] CLAUSE] ... ] DO-LOOPS [!$OMP END DO [NOWAIT] ] Возможные
- 38. PROGRAM OPENMP_SCHEDULE INCLUDE 'omp_lib.h' INTEGER I, N, TID PARAMETER (N=9) !$OMP PARALLEL PRIVATE(TID) TID = OMP_GET_THREAD_NUM()
- 39. PROGRAM OPENMP_PI_DO INTEGER N, I DOUBLE PRECISION X, STEP, PI, SUM /0.0/ PARAMETER (N=100000000) STEP =
- 40. Параллелизация циклов: зависимость по данным и последовательное выполнение итераций Корректная параллелизация цикла возможна только при выполнении
- 41. Параллелизация циклов: отмена барьерной синхронизации ... !$OMP PARALLEL !$OMP DO DO I=2, N B(I) = (A(I)
- 42. Параллелизация многоуровневых циклов PROGRAM OPENMP_3D_ARRAY INCLUDE 'omp_lib.h' INTEGER I, J, K, N PARAMETER (N=600) DOUBLE PRECISION
- 43. Параллелизация многоуровневых циклов: объединение наборов итераций Атрибут COLLAPSE определяет особенности распараллеливания последовательных тесно вложенных циклов с
- 44. Неитеративное распределение работы между нитями !$OMP SECTIONS [CLAUSE[[,] CLAUSE] ...] [!$OMP SECTION] STRUCTURED-BLOCK [!$OMP SECTION STRUCTURED-BLOCK]
- 45. Выполнение части кода одной нитью: директива SINGLE !$OMP SINGLE [CLAUSE[[,] CLAUSE] ...] STRUCTURED-BLOCK !$OMP END SINGLE
- 46. Директива WORKSHARE Директива WORKSHARE применяется только в языке Fortran осуществляет разделение соответствующего структурного блока на независимые
- 47. Составные директивы параллелизации и распределения работы между нитями Составные (комбинированные) директивы OpenMP могут применяться в программе
- 48. Работа с явными задачами (1) В актуальных спецификациях OpenMP работа нитей представляется в терминах модели задач
- 49. Связанная (tied) задача – соответствующей задаче программный код целиком, от начала до конца выполняется одной и
- 50. Директива TASKYIELD указывает, что текущая задача может быть приостановлена с целью переключения соответствующей нити на выполнение
- 51. PROGRAM OPENMP_FIBONACCI INTEGER N, NUM, RES, FIB PARAMETER(N=40) !$OMP PARALLEL !$OMP SINGLE NUM = FIB(N) !$OMP
- 52. Атрибут DEPEND накладывает дополнительные ограничения на планирование задач и состоит из параметра DEPENDENCE-TYPE и одного или
- 53. Пример использования явных задач и атрибута DEPEND в подпрограмме блочного перемножения плотных квадратных матриц. SUBROUTINE MATMUL_DEPEND
- 54. Директивы синхронизации в OpenMP Принципиальнейшая задача при создании многопоточных приложений состоит в регулярно возникающей необходимости обеспечения
- 55. Директивы синхронизации в OpenMP Выполнение части кода главной нитью: директива MASTER Директива MASTER предназначена для выделения
- 56. Директивы синхронизации в OpenMP Критические секции: директива CRITICAL Директива CRITICAL реализует в OpenMP синхронизирующую операцию взаимного
- 57. PROGRAM OPENMP_PI_CRITICAL INTEGER I, N DOUBLE PRECISION X, STEP, PI /0.0/, THREAD_SUM /0.0/ N = 100000000
- 58. Директивы синхронизации в OpenMP Атомарное обновление общих переменных: директива ATOMIC Директива ATOMIC обеспечивает атомарное обновление заданной
- 59. Директивы синхронизации в OpenMP Директива FLUSH Модель работы с памятью, реализуемая в OpenMP, позволяет нитям иметь
- 60. Библиотечные подпрограммы и переменные окружения OpenMP
- 61. Библиотечные подпрограммы и переменные окружения Библиотечные подпрограммы OpenMP позволяют задавать и осуществлять контроль над параметрами среды
- 62. Подпрограммы для работы со временем Функция OMP_GET_WTIME Язык Fortran DOUBLE PRECISION FUNCTION OMP_GET_WTIME() Язык C/C++ double
- 63. Подпрограммы для контроля за выполнением параллельной программы (1) Установка количества нитей в параллельной области Язык Fortran
- 64. Подпрограммы для контроля за выполнением параллельной программы (2) Функция OMP_GET_NUM_PROCS Язык Fortran INTEGER FUNCTION OMP_GET_NUM_PROCS() Язык
- 65. Функция OMP_GET_MAX_THREADS Язык Fortran INTEGER FUNCTION OMP_GET_MAX_THREADS() Язык C/C++ int omp_get_max_threads(void); Функция возвращает максимальное число нитей,
- 66. Подпрограммы для контроля за выполнением параллельной программы (4) Динамический и статический режимы выполнения программы Язык Fortran
- 67. Подпрограммы для контроля за выполнением параллельной программы (5) Контроль режима вложенного параллелизма Язык Fortran SUBROUTINE OMP_SET_NESTED
- 68. Подпрограммы для контроля за выполнением параллельной программы (6) Функция OMP_GET_LEVEL Язык Fortran INTEGER FUNCTION OMP_GET_LEVEL() Язык
- 69. Подпрограммы для контроля за выполнением параллельной программы (7) Функция OMP_GET_TEAM_SIZE Язык Fortran INTEGER FUNCTION OMP_GET_TEAM_SIZE(LEVEL) INTEGER
- 70. Процедуры синхронизации на основе переменных-замков Представляемый далее набор библиотечных процедур OpenMP реализует операцию взаимного исключения нитей
- 71. PROGRAM OPENMP_PI_LOCK INCLUDE 'omp_lib.h' INTEGER I, N, TID INTEGER(OMP_LOCK_KIND) LOCK DOUBLE PRECISION X, STEP, PI /0.0/,
- 72. Переменные окружения OpenMP Переменная окружения OMP_STACKSIZE позволяет задать размер локального для каждой из нитей стека, создаваемого
- 73. Некоторые вопросы повышения эффективности параллельных программ Негативное влияние на показатели производительности могут оказывать следующие факторы: несбалансированность
- 74. Дополнительные примеры кодов программ (1) Вычисление скалярного произведения векторов PROGRAM OPENMP_DDOT_DO INTEGER I, N PARAMETER (N
- 75. Дополнительные примеры кодов программ (2) Умножение квадратных матриц PROGRAM OPENMP_DGEMM INTEGER I, J, K, N, CHUNK
- 76. Дополнительные примеры кодов программ (3) Распараллеливание операции LU-разложения матрицы PROGRAM OPENMP_DGETRF INTEGER I, J, K, N
- 77. Дополнительные примеры кодов программ (4) Численное решение двумерного уравнения Пуассона по методу Якоби Применим упрощенную постановку
- 78. Дополнительные примеры кодов программ (4) Численное решение двумерного уравнения Пуассона по методу Якоби: код программы PROGRAM
- 80. Скачать презентацию
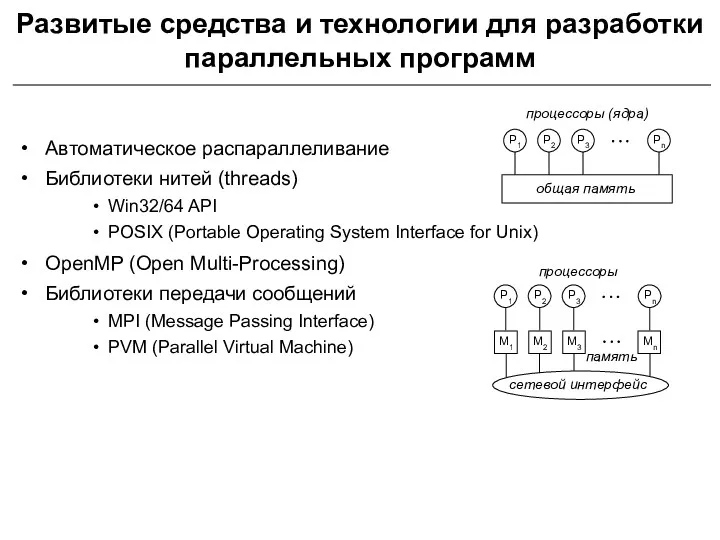
Развитые средства и технологии для разработки параллельных программ
Автоматическое распараллеливание
Библиотеки нитей (threads)
Win32/64
Развитые средства и технологии для разработки параллельных программ
Автоматическое распараллеливание
Библиотеки нитей (threads)
Win32/64

Автоматическое распараллеливание
Автоматическое (автоматизированное) распараллеливание (automatic parallelization) предполагает выполнение оптимизации программного кода
Автоматическое распараллеливание
Автоматическое (автоматизированное) распараллеливание (automatic parallelization) предполагает выполнение оптимизации программного кода

#include
#include
#include
#define NUM_THREADS 5
void *PrintHello(void *threadid)
{
long tid;
tid
#include
#include
#include
#define NUM_THREADS 5
void *PrintHello(void *threadid)
{
long tid;
tid
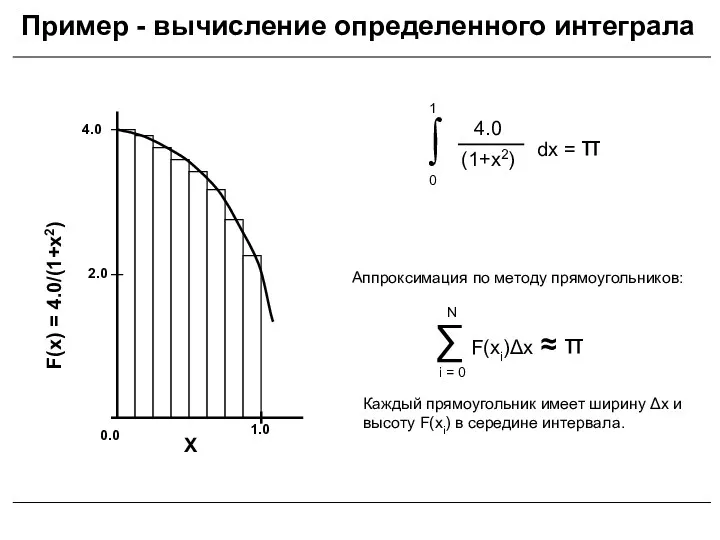
Пример - вычисление определенного интеграла
Пример - вычисление определенного интеграла
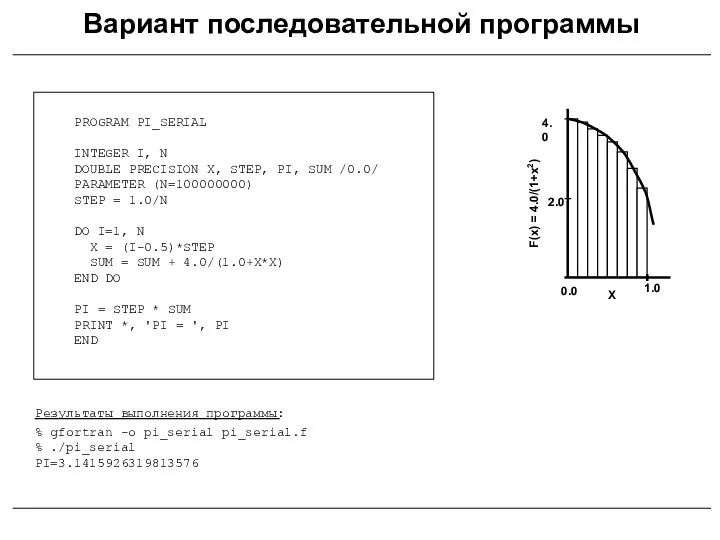
PROGRAM PI_SERIAL
INTEGER I, N
DOUBLE PRECISION X, STEP, PI, SUM
PROGRAM PI_SERIAL
INTEGER I, N
DOUBLE PRECISION X, STEP, PI, SUM

PROGRAM PI_OPENMP
INCLUDE 'omp_lib.h'
INTEGER I, N, NTHREADS, TID, ISTART,
PROGRAM PI_OPENMP
INCLUDE 'omp_lib.h'
INTEGER I, N, NTHREADS, TID, ISTART,

Вариант программы с использованием MPI
PROGRAM PI_MPI
INCLUDE 'mpif.h'
DOUBLE PRECISION
Вариант программы с использованием MPI
PROGRAM PI_MPI
INCLUDE 'mpif.h'
DOUBLE PRECISION

#include
#include
#define NUM_THREADS 2
CRITICAL_SECTION hCriticalSection;
double pi = 0.0;
int n =100000;
void
#include
#include
#define NUM_THREADS 2
CRITICAL_SECTION hCriticalSection;
double pi = 0.0;
int n =100000;
void

OpenMP (Open Multi-Processing) - развитый высокоуровневый интерфейс прикладного программирования (Application Programming
OpenMP (Open Multi-Processing) - развитый высокоуровневый интерфейс прикладного программирования (Application Programming
Версии спецификации OpenMP
2011
OpenMP
F/C/C++ 3.1
2013
OpenMP
F/C/C++ 4.0
http://www.openmp.org
OpenMP
F/C/C++ 4.1
2015
Версии спецификации OpenMP
2011
OpenMP
F/C/C++ 3.1
2013
OpenMP
F/C/C++ 4.0
http://www.openmp.org
OpenMP
F/C/C++ 4.1
2015

Коммерческие компиляторы:
Intel C/C++ / Fortran Compilers (http://software.intel.com/en-us/intel-compilers/)
Microsoft Visual Studio
Коммерческие компиляторы:
Intel C/C++ / Fortran Compilers (http://software.intel.com/en-us/intel-compilers/)
Microsoft Visual Studio

Основы OpenMP. Модель исполнения программ
Модель исполнения программ в OpenMP основана на
Основы OpenMP. Модель исполнения программ
Модель исполнения программ в OpenMP основана на

Основы OpenMP. Модель исполнения программ
OpenMP базируется на высокоуровневой реализации механизмов многопоточности,
Основы OpenMP. Модель исполнения программ
OpenMP базируется на высокоуровневой реализации механизмов многопоточности,

Основы OpenMP. Модель памяти
Модель памяти, на которую опирается стандарт OpenMP, предполагает,
Основы OpenMP. Модель памяти
Модель памяти, на которую опирается стандарт OpenMP, предполагает,

Основы OpenMP. Модель памяти
Одна из важнейших задач при разработке многопоточных приложений
Основы OpenMP. Модель памяти
Одна из важнейших задач при разработке многопоточных приложений
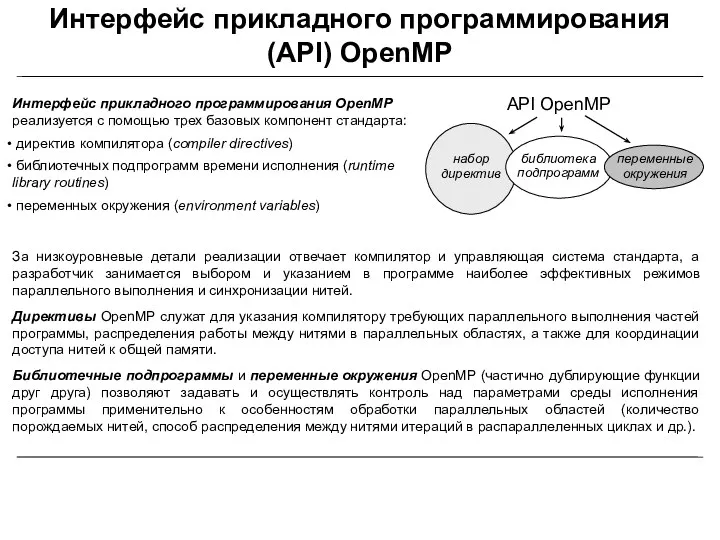
За низкоуровневые детали реализации отвечает компилятор и управляющая система стандарта, а
За низкоуровневые детали реализации отвечает компилятор и управляющая система стандарта, а

Общие сведения о директивах OpenMP
Термин директива (directive) закреплен в OpenMP за
Общие сведения о директивах OpenMP
Термин директива (directive) закреплен в OpenMP за

Общие сведения о директивах OpenMP:
синтаксис директив
Общие синтаксические правила включения директив и
Общие сведения о директивах OpenMP:
синтаксис директив
Общие синтаксические правила включения директив и

Общие сведения о директивах OpenMP:
условная компиляция программ
Организация условной компиляции программы позволяет
Общие сведения о директивах OpenMP:
условная компиляция программ
Организация условной компиляции программы позволяет

Общие сведения о библиотечных подпрограммах
Библиотечные подпрограммы OpenMP позволяют задавать и осуществлять
Общие сведения о библиотечных подпрограммах
Библиотечные подпрограммы OpenMP позволяют задавать и осуществлять

Общие сведения о переменных окружения
Переменные окружения OpenMP служат для создания переносимой
Общие сведения о переменных окружения
Переменные окружения OpenMP служат для создания переносимой
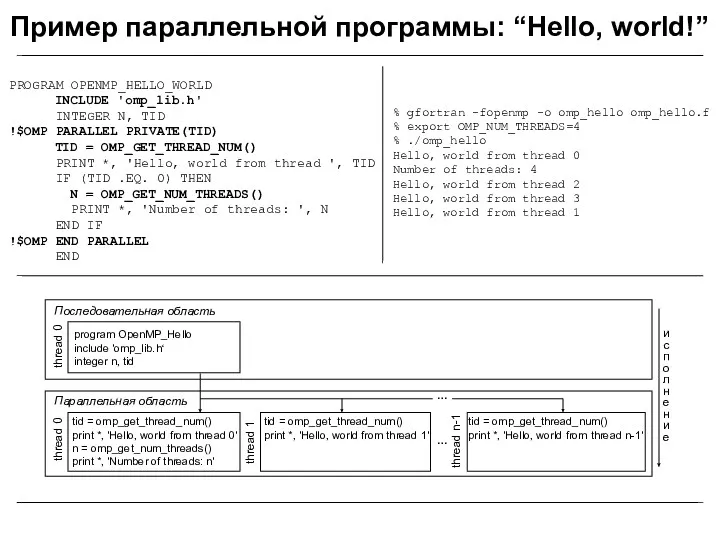
PROGRAM OPENMP_HELLO_WORLD
INCLUDE 'omp_lib.h'
INTEGER N, TID
!$OMP PARALLEL PRIVATE(TID)
TID
PROGRAM OPENMP_HELLO_WORLD
INCLUDE 'omp_lib.h'
INTEGER N, TID
!$OMP PARALLEL PRIVATE(TID)
TID

PROGRAM OPENMP_PI
INCLUDE 'omp_lib.h'
INTEGER I, N, NTHREADS, TID, ISTART,
PROGRAM OPENMP_PI
INCLUDE 'omp_lib.h'
INTEGER I, N, NTHREADS, TID, ISTART,

Директивы и атрибуты OpenMP
Директивы и атрибуты OpenMP

Директивы и атрибуты OpenMP.
Назначение параллельных областей программы
Язык Fortran
!$OMP PARALLEL [CLAUSE[[,] CLAUSE]...]
Директивы и атрибуты OpenMP.
Назначение параллельных областей программы
Язык Fortran
!$OMP PARALLEL [CLAUSE[[,] CLAUSE]...]

Многоуровневый (вложенный) параллелизм
Стандарт OpenMP разрешает использовать в программах неограниченную вложенность параллельных
Многоуровневый (вложенный) параллелизм
Стандарт OpenMP разрешает использовать в программах неограниченную вложенность параллельных

Переменные в параллельных областях OpenMP-программы (с позиций доступности для обращения к
Переменные в параллельных областях OpenMP-программы (с позиций доступности для обращения к

Классы переменных в OpenMP
FIRSTPRIVATE(LIST)
LASTPRIVATE(LIST)
Атрибут-оператор FIRSTPRIVATE позволяет выполнить автоматическую инициализацию создаваемых
Классы переменных в OpenMP
FIRSTPRIVATE(LIST)
LASTPRIVATE(LIST)
Атрибут-оператор FIRSTPRIVATE позволяет выполнить автоматическую инициализацию создаваемых

Классы переменных в OpenMP
Совместная обработка локальных переменных
REDUCTION({OPERATOR |INTRINSIC_PROCEDURE_NAME}:LIST)
Специальный тип переменных,
Классы переменных в OpenMP
Совместная обработка локальных переменных
REDUCTION({OPERATOR |INTRINSIC_PROCEDURE_NAME}:LIST)
Специальный тип переменных,

Управление данными в OpenMP
Назначение постоянно существующих в программе локальных переменных
Описательная (декларативная)
Управление данными в OpenMP
Назначение постоянно существующих в программе локальных переменных
Описательная (декларативная)

PROGRAM OPENMP_THREADPRIVATE
INCLUDE 'omp_lib.h'
INTEGER I, TID
COMMON /BLOCK/ I
!$OMP
PROGRAM OPENMP_THREADPRIVATE
INCLUDE 'omp_lib.h'
INTEGER I, TID
COMMON /BLOCK/ I
!$OMP

Управление данными в OpenMP
Атрибуты копирования значений локальных переменных
COPYIN(LIST)
COPYPRIVATE(LIST)
Атрибуты копирования значений переменных
Управление данными в OpenMP
Атрибуты копирования значений локальных переменных
COPYIN(LIST)
COPYPRIVATE(LIST)
Атрибуты копирования значений переменных

Распределение работы между нитями
в параллельных областях
Явное распределение работы между нитями
Распределение выполняемых
Распределение работы между нитями
в параллельных областях
Явное распределение работы между нитями
Распределение выполняемых

Явное распределение работы между нитями. Пример 1
PROGRAM OPENMP_PI_SPMD
INCLUDE 'omp_lib.h'
Явное распределение работы между нитями. Пример 1
PROGRAM OPENMP_PI_SPMD
INCLUDE 'omp_lib.h'
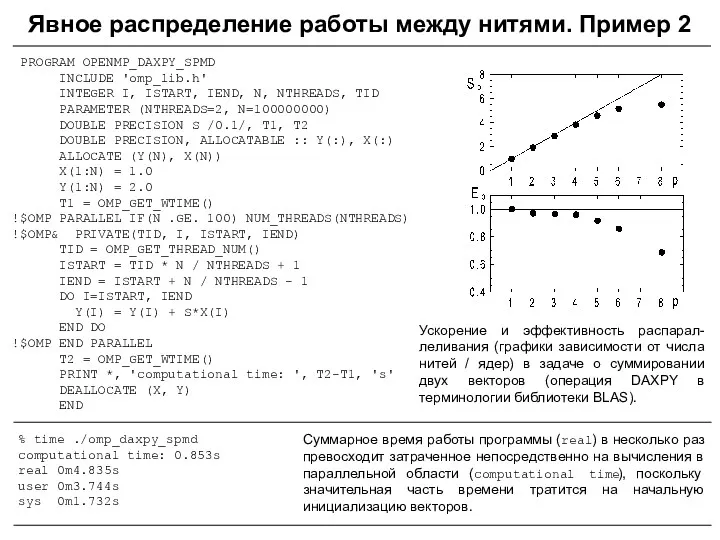
PROGRAM OPENMP_DAXPY_SPMD
INCLUDE 'omp_lib.h'
INTEGER I, ISTART, IEND, N, NTHREADS,
PROGRAM OPENMP_DAXPY_SPMD
INCLUDE 'omp_lib.h'
INTEGER I, ISTART, IEND, N, NTHREADS,
![Директивы параллелизации циклов !$OMP DO [CLAUSE[[,] CLAUSE] ... ] DO-LOOPS](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/590191/slide-36.jpg)
Директивы параллелизации циклов
!$OMP DO [CLAUSE[[,] CLAUSE] ... ]
DO-LOOPS
[!$OMP END DO
Директивы параллелизации циклов
!$OMP DO [CLAUSE[[,] CLAUSE] ... ]
DO-LOOPS
[!$OMP END DO
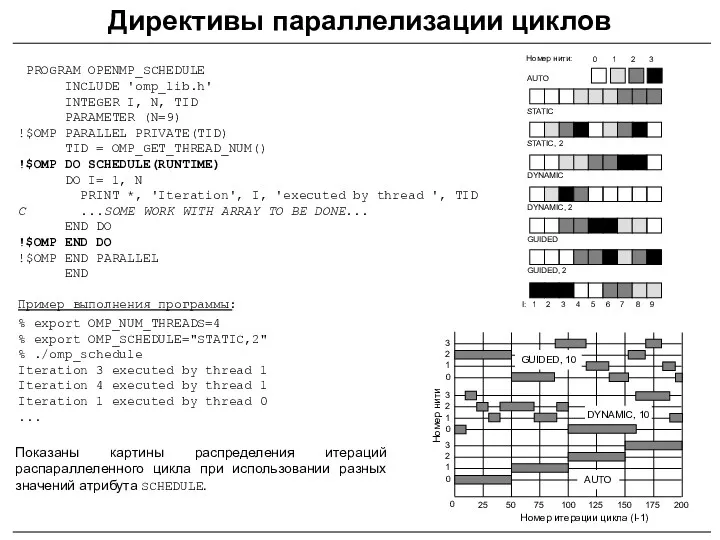
PROGRAM OPENMP_SCHEDULE
INCLUDE 'omp_lib.h'
INTEGER I, N, TID
PARAMETER (N=9)
!$OMP
PROGRAM OPENMP_SCHEDULE
INCLUDE 'omp_lib.h'
INTEGER I, N, TID
PARAMETER (N=9)
!$OMP
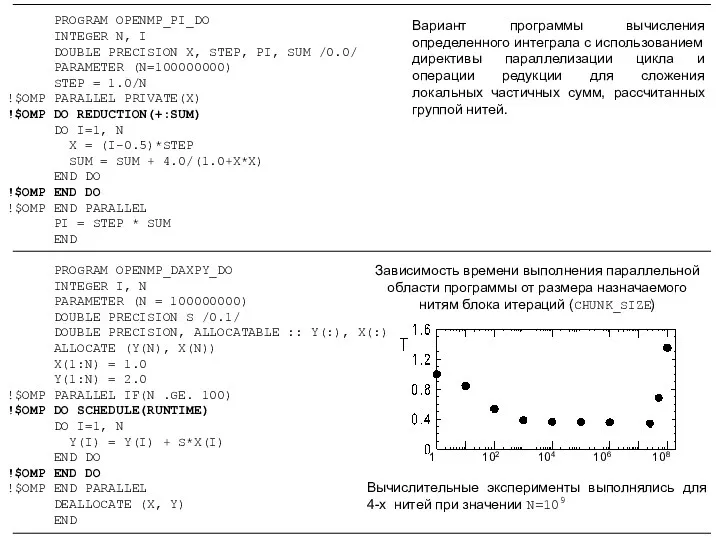
PROGRAM OPENMP_PI_DO
INTEGER N, I
DOUBLE PRECISION X, STEP, PI,
PROGRAM OPENMP_PI_DO
INTEGER N, I
DOUBLE PRECISION X, STEP, PI,

Параллелизация циклов: зависимость по данным и последовательное выполнение итераций
Корректная параллелизация цикла
Параллелизация циклов: зависимость по данным и последовательное выполнение итераций
Корректная параллелизация цикла

Параллелизация циклов:
отмена барьерной синхронизации
...
!$OMP PARALLEL
!$OMP DO
DO I=2, N
B(I) =
Параллелизация циклов:
отмена барьерной синхронизации
...
!$OMP PARALLEL
!$OMP DO
DO I=2, N
B(I) =
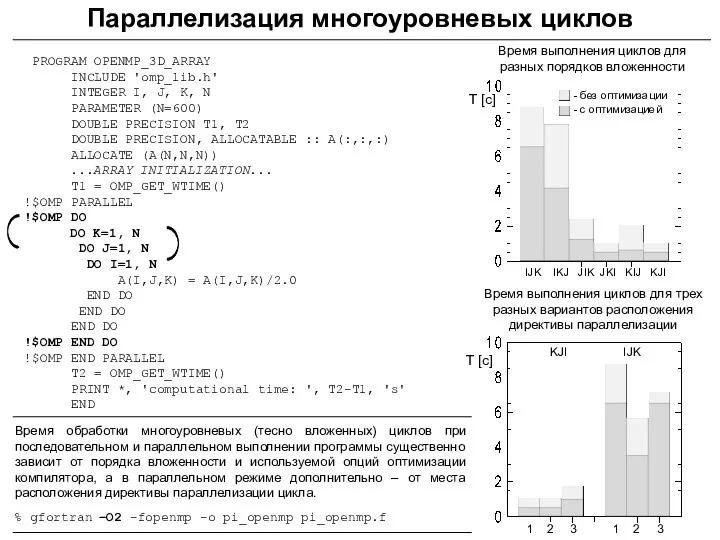
Параллелизация многоуровневых циклов
PROGRAM OPENMP_3D_ARRAY
INCLUDE 'omp_lib.h'
INTEGER I, J, K,
Параллелизация многоуровневых циклов
PROGRAM OPENMP_3D_ARRAY
INCLUDE 'omp_lib.h'
INTEGER I, J, K,

Параллелизация многоуровневых циклов: объединение наборов итераций
Атрибут COLLAPSE определяет особенности распараллеливания последовательных
Параллелизация многоуровневых циклов: объединение наборов итераций
Атрибут COLLAPSE определяет особенности распараллеливания последовательных
![Неитеративное распределение работы между нитями !$OMP SECTIONS [CLAUSE[[,] CLAUSE] ...]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/590191/slide-43.jpg)
Неитеративное распределение работы между нитями
!$OMP SECTIONS [CLAUSE[[,] CLAUSE] ...]
[!$OMP SECTION]
STRUCTURED-BLOCK
[!$OMP
Неитеративное распределение работы между нитями
!$OMP SECTIONS [CLAUSE[[,] CLAUSE] ...]
[!$OMP SECTION]
STRUCTURED-BLOCK
[!$OMP
![Выполнение части кода одной нитью: директива SINGLE !$OMP SINGLE [CLAUSE[[,]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/590191/slide-44.jpg)
Выполнение части кода одной нитью: директива SINGLE
!$OMP SINGLE [CLAUSE[[,] CLAUSE] ...]
Выполнение части кода одной нитью: директива SINGLE
!$OMP SINGLE [CLAUSE[[,] CLAUSE] ...]

Директива WORKSHARE
Директива WORKSHARE применяется только в языке Fortran осуществляет разделение соответствующего
Директива WORKSHARE
Директива WORKSHARE применяется только в языке Fortran осуществляет разделение соответствующего

Составные директивы параллелизации и распределения работы между нитями
Составные (комбинированные) директивы OpenMP
Составные директивы параллелизации и распределения работы между нитями
Составные (комбинированные) директивы OpenMP

Работа с явными задачами (1)
В актуальных спецификациях OpenMP работа нитей представляется
Работа с явными задачами (1)
В актуальных спецификациях OpenMP работа нитей представляется

Связанная (tied) задача – соответствующей задаче программный код целиком, от начала
Связанная (tied) задача – соответствующей задаче программный код целиком, от начала

Директива TASKYIELD указывает, что текущая задача может быть приостановлена с целью
Директива TASKYIELD указывает, что текущая задача может быть приостановлена с целью

PROGRAM OPENMP_FIBONACCI
INTEGER N, NUM, RES, FIB
PARAMETER(N=40)
!$OMP PARALLEL
!$OMP SINGLE
PROGRAM OPENMP_FIBONACCI
INTEGER N, NUM, RES, FIB
PARAMETER(N=40)
!$OMP PARALLEL
!$OMP SINGLE

Атрибут DEPEND накладывает дополнительные ограничения на планирование задач и состоит из
Атрибут DEPEND накладывает дополнительные ограничения на планирование задач и состоит из

Пример использования явных задач и атрибута DEPEND в подпрограмме блочного перемножения
Пример использования явных задач и атрибута DEPEND в подпрограмме блочного перемножения

Директивы синхронизации в OpenMP
Принципиальнейшая задача при создании многопоточных приложений состоит в
Директивы синхронизации в OpenMP
Принципиальнейшая задача при создании многопоточных приложений состоит в

Директивы синхронизации в OpenMP
Выполнение части кода главной нитью: директива MASTER
Директива MASTER
Директивы синхронизации в OpenMP
Выполнение части кода главной нитью: директива MASTER
Директива MASTER

Директивы синхронизации в OpenMP
Критические секции: директива CRITICAL
Директива CRITICAL реализует в OpenMP
Директивы синхронизации в OpenMP
Критические секции: директива CRITICAL
Директива CRITICAL реализует в OpenMP

PROGRAM OPENMP_PI_CRITICAL
INTEGER I, N
DOUBLE PRECISION X, STEP, PI
PROGRAM OPENMP_PI_CRITICAL
INTEGER I, N
DOUBLE PRECISION X, STEP, PI

Директивы синхронизации в OpenMP
Атомарное обновление общих переменных: директива ATOMIC
Директива ATOMIC обеспечивает
Директивы синхронизации в OpenMP
Атомарное обновление общих переменных: директива ATOMIC
Директива ATOMIC обеспечивает

Директивы синхронизации в OpenMP
Директива FLUSH
Модель работы с памятью, реализуемая в OpenMP,
Директивы синхронизации в OpenMP
Директива FLUSH
Модель работы с памятью, реализуемая в OpenMP,

Библиотечные подпрограммы и переменные окружения OpenMP
Библиотечные подпрограммы и переменные окружения OpenMP

Библиотечные подпрограммы и переменные окружения
Библиотечные подпрограммы OpenMP позволяют задавать и осуществлять
Библиотечные подпрограммы и переменные окружения
Библиотечные подпрограммы OpenMP позволяют задавать и осуществлять

Подпрограммы для работы со временем
Функция OMP_GET_WTIME
Язык Fortran
DOUBLE PRECISION FUNCTION OMP_GET_WTIME()
Язык C/C++
double
Подпрограммы для работы со временем
Функция OMP_GET_WTIME
Язык Fortran
DOUBLE PRECISION FUNCTION OMP_GET_WTIME()
Язык C/C++
double

Подпрограммы для контроля за выполнением параллельной программы (1)
Установка количества нитей в
Подпрограммы для контроля за выполнением параллельной программы (1)
Установка количества нитей в

Подпрограммы для контроля за выполнением параллельной программы (2)
Функция OMP_GET_NUM_PROCS
Язык Fortran
INTEGER FUNCTION
Подпрограммы для контроля за выполнением параллельной программы (2)
Функция OMP_GET_NUM_PROCS
Язык Fortran
INTEGER FUNCTION

Функция OMP_GET_MAX_THREADS
Язык Fortran
INTEGER FUNCTION OMP_GET_MAX_THREADS()
Язык C/C++
int omp_get_max_threads(void);
Функция возвращает максимальное число нитей,
Функция OMP_GET_MAX_THREADS
Язык Fortran
INTEGER FUNCTION OMP_GET_MAX_THREADS()
Язык C/C++
int omp_get_max_threads(void);
Функция возвращает максимальное число нитей,

Подпрограммы для контроля за выполнением параллельной программы (4)
Динамический и статический режимы
Подпрограммы для контроля за выполнением параллельной программы (4)
Динамический и статический режимы

Подпрограммы для контроля за выполнением параллельной программы (5)
Контроль режима вложенного параллелизма
Язык
Подпрограммы для контроля за выполнением параллельной программы (5)
Контроль режима вложенного параллелизма
Язык

Подпрограммы для контроля за выполнением параллельной программы (6)
Функция OMP_GET_LEVEL
Язык Fortran
INTEGER FUNCTION
Подпрограммы для контроля за выполнением параллельной программы (6)
Функция OMP_GET_LEVEL
Язык Fortran
INTEGER FUNCTION

Подпрограммы для контроля за выполнением параллельной программы (7)
Функция OMP_GET_TEAM_SIZE
Язык Fortran
INTEGER FUNCTION
Подпрограммы для контроля за выполнением параллельной программы (7)
Функция OMP_GET_TEAM_SIZE
Язык Fortran
INTEGER FUNCTION

Процедуры синхронизации на основе переменных-замков
Представляемый далее набор библиотечных процедур OpenMP реализует
Процедуры синхронизации на основе переменных-замков
Представляемый далее набор библиотечных процедур OpenMP реализует

PROGRAM OPENMP_PI_LOCK
INCLUDE 'omp_lib.h'
INTEGER I, N, TID
INTEGER(OMP_LOCK_KIND) LOCK
DOUBLE
PROGRAM OPENMP_PI_LOCK
INCLUDE 'omp_lib.h'
INTEGER I, N, TID
INTEGER(OMP_LOCK_KIND) LOCK
DOUBLE
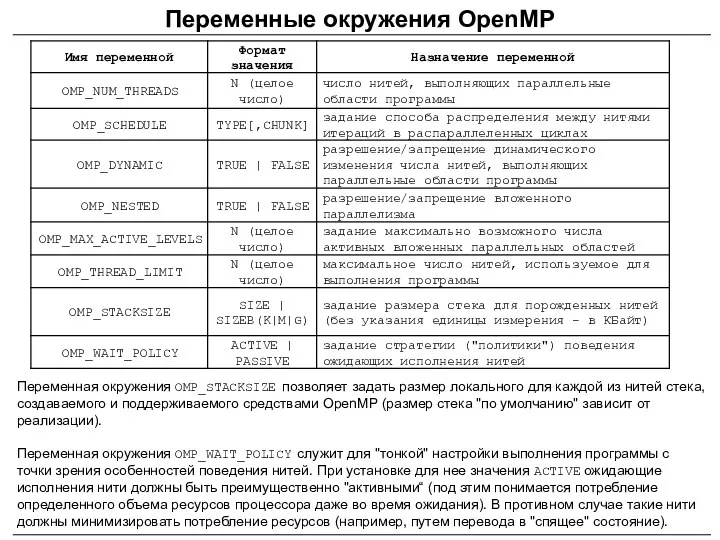
Переменные окружения OpenMP
Переменная окружения OMP_STACKSIZE позволяет задать размер локального для каждой
Переменные окружения OpenMP
Переменная окружения OMP_STACKSIZE позволяет задать размер локального для каждой

Некоторые вопросы повышения эффективности параллельных программ
Негативное влияние на показатели производительности могут
Некоторые вопросы повышения эффективности параллельных программ
Негативное влияние на показатели производительности могут

Дополнительные примеры кодов программ (1)
Вычисление скалярного произведения векторов
PROGRAM OPENMP_DDOT_DO
Дополнительные примеры кодов программ (1)
Вычисление скалярного произведения векторов
PROGRAM OPENMP_DDOT_DO

Дополнительные примеры кодов программ (2)
Умножение квадратных матриц
PROGRAM OPENMP_DGEMM
INTEGER I,
Дополнительные примеры кодов программ (2)
Умножение квадратных матриц
PROGRAM OPENMP_DGEMM
INTEGER I,

Дополнительные примеры кодов программ (3)
Распараллеливание операции LU-разложения матрицы
PROGRAM OPENMP_DGETRF
INTEGER
Дополнительные примеры кодов программ (3)
Распараллеливание операции LU-разложения матрицы
PROGRAM OPENMP_DGETRF
INTEGER

Дополнительные примеры кодов программ (4)
Численное решение двумерного уравнения Пуассона по методу
Дополнительные примеры кодов программ (4)
Численное решение двумерного уравнения Пуассона по методу

Дополнительные примеры кодов программ (4)
Численное решение двумерного уравнения Пуассона по методу
Дополнительные примеры кодов программ (4)
Численное решение двумерного уравнения Пуассона по методу
 Новые возможности в человекомашинном интерфейсе. (Лекция 1)
Новые возможности в человекомашинном интерфейсе. (Лекция 1) Функции в PHP
Функции в PHP Безопасность автоматизированных систем обработки информации (АСОИ). Курс лекций
Безопасность автоматизированных систем обработки информации (АСОИ). Курс лекций Dota 2 — компьютерная многопользовательская командная игра
Dota 2 — компьютерная многопользовательская командная игра Курс повышения квалификации SMM-специалист
Курс повышения квалификации SMM-специалист Сравнительный анализ дизайна сайтов
Сравнительный анализ дизайна сайтов Разветвляющиеся алгоритмы на языке Паскаль
Разветвляющиеся алгоритмы на языке Паскаль Презентация к уроку Словесное описание модели
Презентация к уроку Словесное описание модели апреля 8а Мат.тексты
апреля 8а Мат.тексты Оновлюємо комп'ютерний клас
Оновлюємо комп'ютерний клас Алгоритми з розгалуженням
Алгоритми з розгалуженням GYMNASIUM 47. Зачем изучать программирование
GYMNASIUM 47. Зачем изучать программирование Уроки по теме Одномерный массив
Уроки по теме Одномерный массив Разработка программы нахождения значения определенного интеграла с помощью метода Симпсона
Разработка программы нахождения значения определенного интеграла с помощью метода Симпсона Объектно-ориентированное программирование в Java. Лекция 2
Объектно-ориентированное программирование в Java. Лекция 2 Почтовые протоколы SMTP, POP, IMAP
Почтовые протоколы SMTP, POP, IMAP Базовая конфигурация компьютера
Базовая конфигурация компьютера Разработка урока для 6 класса Растровое кодирование графической информации
Разработка урока для 6 класса Растровое кодирование графической информации Cne6923 software update
Cne6923 software update Кодирование и обработка звуковой информации
Кодирование и обработка звуковой информации Внутрішній паралелізм. Лекція №8
Внутрішній паралелізм. Лекція №8 Операторы языка С++. Структура программы. Лекция 2
Операторы языка С++. Структура программы. Лекция 2 Системное программирование
Системное программирование Информационные технологии в деятельности правоохранительных органов
Информационные технологии в деятельности правоохранительных органов Моделирование физических процессов
Моделирование физических процессов Информатика. Введение и общие положения
Информатика. Введение и общие положения If и Switch. Вывод текста в графике. Обработка нажатий клавиш
If и Switch. Вывод текста в графике. Обработка нажатий клавиш iOS Developer
iOS Developer