- Text Mining. Анализ текстовой информации

Содержание
- 2. Text Mining- методы анализа неструктурированного текста Обнаружение знаний в тексте - это нетривиальный процесс обнаружения действительно
- 3. Этапы Text Mining
- 4. Предварительная обработка текста Удаление стоп-слов. Стоп- слов – вспомогательные слова, которые несут мало информации о содержании
- 5. Задачи Text Mining Классификация- определение для каждого документа одной и нескольких заранее заданных категорий, к которой
- 6. Извлечение ключевых понятий из текста Интерес представляют некоторые сущности, события, отношения. Извлечённые понятия анализируются и используются
- 7. Подходы к извлечению информации из текста Определение частых наборов слов и объединение их в ключевые понятия
- 8. Извлечение ключевых понятий с помощью шаблонов Анализ понятий Извлечение отдельных фактов Интеграция извлечённых фактов и/или вывод
- 9. Локальный анализ Лексический анализ. Текст делится на предложения и лексемы. Словарь должен включать специальные термины, имена
- 10. Локальный анализ Синтаксический анализ. Построение структур для групп имён существительных (имя сущ. + его модификации) и
- 11. Наборы образцов используют для укрупнения групп имён существительных. Образцы объединяют 2 группы имён существительных и промежуточные
- 12. Стадия интеграции и вывода понятий Для извлечения событий и отношений используются образцы, которые получаются за счёт
- 13. Анализ ссылок. Разрешение ссылок , представленных местоимениями и описываемыми группами имён сущ. «Его»(сущность е5).
- 15. Скачать презентацию

Text Mining- методы анализа неструктурированного текста
Обнаружение знаний в тексте - это
Text Mining- методы анализа неструктурированного текста
Обнаружение знаний в тексте - это
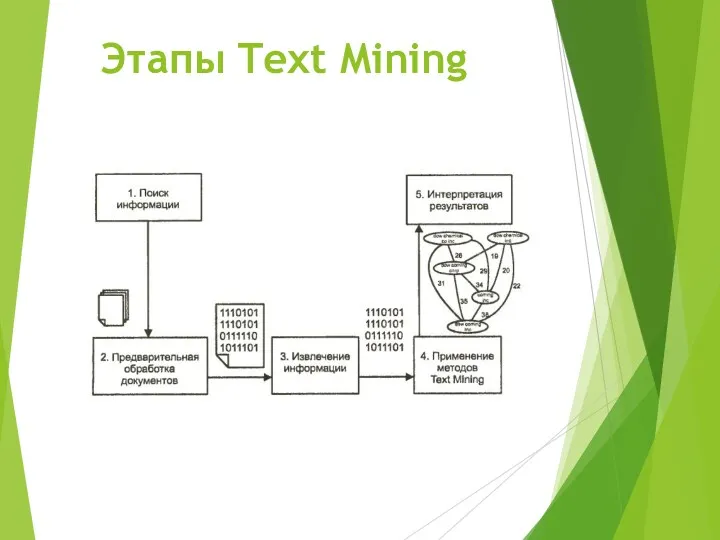
Этапы Text Mining
Этапы Text Mining
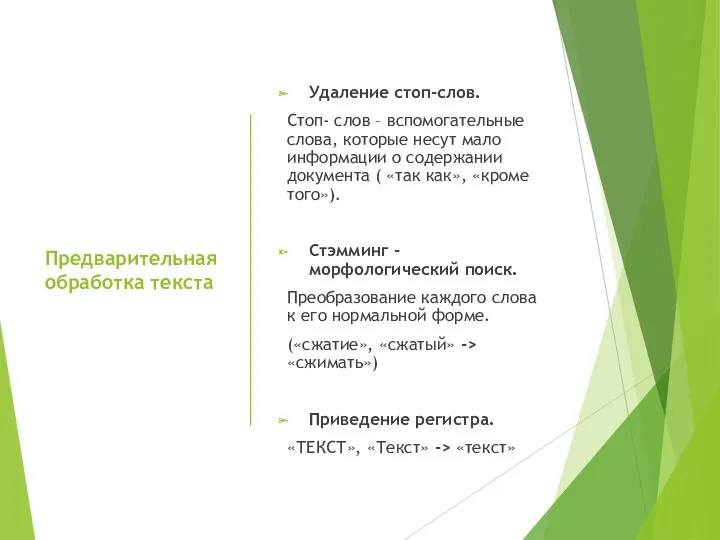
Предварительная обработка текста
Удаление стоп-слов.
Стоп- слов – вспомогательные слова, которые несут мало
Предварительная обработка текста
Удаление стоп-слов.
Стоп- слов – вспомогательные слова, которые несут мало

Задачи Text Mining
Классификация- определение для каждого документа одной и нескольких заранее
Задачи Text Mining
Классификация- определение для каждого документа одной и нескольких заранее

Извлечение ключевых понятий из текста
Интерес представляют некоторые сущности, события, отношения. Извлечённые
Извлечение ключевых понятий из текста
Интерес представляют некоторые сущности, события, отношения. Извлечённые

Подходы к извлечению информации из текста
Определение частых наборов слов и объединение
Подходы к извлечению информации из текста
Определение частых наборов слов и объединение
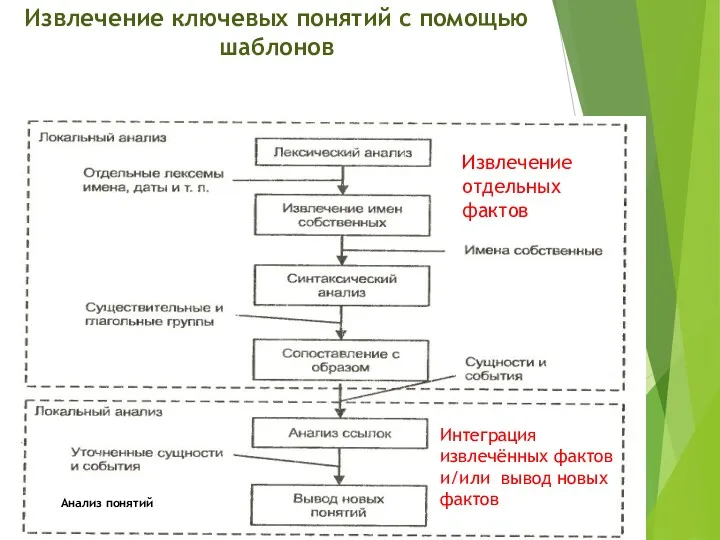
Извлечение ключевых понятий с помощью шаблонов
Анализ понятий
Извлечение отдельных фактов
Интеграция извлечённых фактов
Извлечение ключевых понятий с помощью шаблонов
Анализ понятий
Извлечение отдельных фактов
Интеграция извлечённых фактов

Локальный анализ
Лексический анализ. Текст делится на предложения и лексемы.
Словарь должен включать
Локальный анализ
Лексический анализ. Текст делится на предложения и лексемы.
Словарь должен включать

Локальный анализ
Синтаксический анализ. Построение структур для групп имён существительных (имя сущ.
Локальный анализ
Синтаксический анализ. Построение структур для групп имён существительных (имя сущ.

Наборы образцов используют для укрупнения групп имён существительных.
Образцы объединяют 2 группы
Наборы образцов используют для укрупнения групп имён существительных.
Образцы объединяют 2 группы

Стадия интеграции и вывода понятий
Для извлечения событий и отношений используются образцы,
Стадия интеграции и вывода понятий
Для извлечения событий и отношений используются образцы,

Анализ ссылок. Разрешение ссылок , представленных местоимениями и описываемыми группами имён
Анализ ссылок. Разрешение ссылок , представленных местоимениями и описываемыми группами имён
 Понятие алгоритма. 8 класс
Понятие алгоритма. 8 класс Принципы организации внутренней и внешней памяти компьютера
Принципы организации внутренней и внешней памяти компьютера Телекоммуникационные системы гостиниц
Телекоммуникационные системы гостиниц Визуализация информации в текстовых документах. 7 класс
Визуализация информации в текстовых документах. 7 класс Сервисы сети Интернет
Сервисы сети Интернет История развития вычислительной техники
История развития вычислительной техники тренировочные задания на английском языке (УМК Спотлайт 2 класс )
тренировочные задания на английском языке (УМК Спотлайт 2 класс ) Презентация к уроку Массивы
Презентация к уроку Массивы Програмне забезпечення комп’ютерних мереж
Програмне забезпечення комп’ютерних мереж Законы алгебры логики
Законы алгебры логики Разработка пособия по созданию графических изображений посредствами Adobe Photoshop для начинающих пользователей
Разработка пособия по созданию графических изображений посредствами Adobe Photoshop для начинающих пользователей Internet History
Internet History Электронная коммерция
Электронная коммерция Размеры. Нанесение размеров (часть 2)
Размеры. Нанесение размеров (часть 2) Добавляем эффект свечения для изображения в Фотошоп
Добавляем эффект свечения для изображения в Фотошоп Социальные сети. Инструменты продвижения SMM и SMO
Социальные сети. Инструменты продвижения SMM и SMO Устройство персонального компьютера
Устройство персонального компьютера Приложения по информатике
Приложения по информатике Искусственный интеллект. Межуниверситетский проект
Искусственный интеллект. Межуниверситетский проект Фейковые манипуляции в массовых медиа: как их распознать и убедить друзей в недостоверности информации?
Фейковые манипуляции в массовых медиа: как их распознать и убедить друзей в недостоверности информации?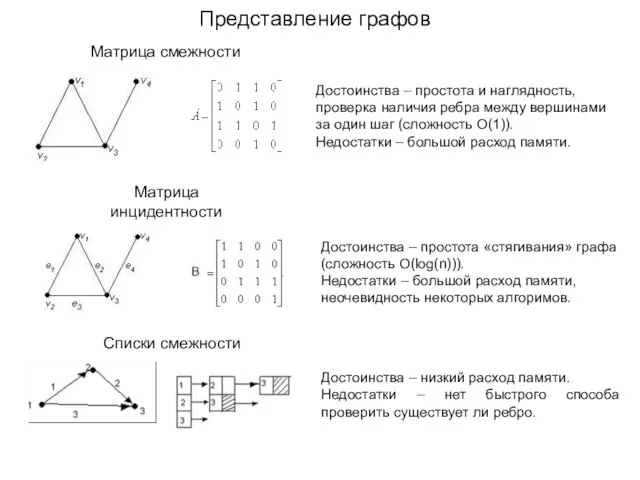 Представление графов
Представление графов Зачем нам телефон и телевизор
Зачем нам телефон и телевизор Презентация. Виды компьютерных презентаций
Презентация. Виды компьютерных презентаций Занятие по информатике в рамках организации внеурочной занятости Редактирование текста
Занятие по информатике в рамках организации внеурочной занятости Редактирование текста Таблиця. Діаграма по даних таблиці
Таблиця. Діаграма по даних таблиці ТЖ ақпаратты жинау және өңдеу жүйесі
ТЖ ақпаратты жинау және өңдеу жүйесі Готовимся в проектной работе
Готовимся в проектной работе Екі өлшемді массив
Екі өлшемді массив