- Типы моделей данных

Содержание
- 2. Основные типы моделей данных Ядром любой базы данных есть модель данных. Модель данных представляет собой великое
- 3. Иерархическая модель данных Иерархическая модель данных — это модель данных, где используется представление базы данных в
- 4. Пример иерархической модели данных
- 5. Иерархическая модель БД: основные понятия и специфика построения В стандартном виде иерархическая модель данных состоит из
- 6. Управляющая часть Иерархическая бд имеет структуру, включающую управляющую и структурную части. В составе управляющей части входит
- 7. Структурная часть В качестве ключевых функциональных единиц в этом случае используются «Поле» и «Сегмент». «Поле» («Атрибут»)
- 8. Трансформация концептуальной модели БД в иерархическую Процесс трансформации концептуальной модели БД в древовидную осуществляется аналогично преобразованию
- 9. Специфика управления иерархиями В процессе управления иерархической БД используются две группы языковых средств, в частности: средства
- 10. Какие операции можно выполнять с помощью иерархических БД Иерархические модели БД имеют широкую сферу применения. С
- 11. Пример:с
- 12. Где используются иерархические структуры данных? Иерархическая структура базы данных – это основа функционирования семейства ОС Windows.
- 13. Преимущества иерархической модели БД Иерархическая модель базы данных обладает широким спектром безоговорочных преимуществ, в числе прочих
- 14. Сетевая модель данных Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая
- 15. Сетевая модель данных Управление сетевыми данными. Операции с сетевыми данными можно разделить на две группы: навигационные
- 16. Сетевая модель данных Операции модификации данных Операций модификации сетевых баз данных осуществляют добавление новых записей данных,
- 17. Пример сетевой модели данных
- 18. Реляционные базы данных Прежде чем определять понятие реляционных баз данных, нужно разобраться с понятием самих данных.
- 19. Реляционная модель Реляционную модель предложил британский математик Эдгар Кодд на рубеже шестидесятых и семидесятых годов XX
- 20. Реляционная модель Транзакция — это комплекс последовательных операций с применением операторов SQL, имеющих определенную цель. Все
- 21. Структура реляционной базы данных Индексы позволяют эффективно реализовать поиск и обработку данных, формируя дополнительные индексные файлы.
- 22. Реляционная модель данных Данные в реляционной базе данных формируют отношения — двумерные таблицы с информацией о
- 23. 3 популярных реляционных базы данных для веб-разработки MySQL Данную открытую систему управления базами данных американская корпорация
- 24. 3 популярных реляционных базы данных для веб-разработки PostgreSQL Это наиболее продвинутая система управления реляционными базами данных.
- 26. Скачать презентацию

Основные типы моделей данных
Ядром любой базы данных есть модель данных.
Модель данных представляет
Основные типы моделей данных
Ядром любой базы данных есть модель данных.
Модель данных представляет

Иерархическая модель данных
Иерархическая модель данных — это модель данных, где используется представление базы данных в
Иерархическая модель данных
Иерархическая модель данных — это модель данных, где используется представление базы данных в
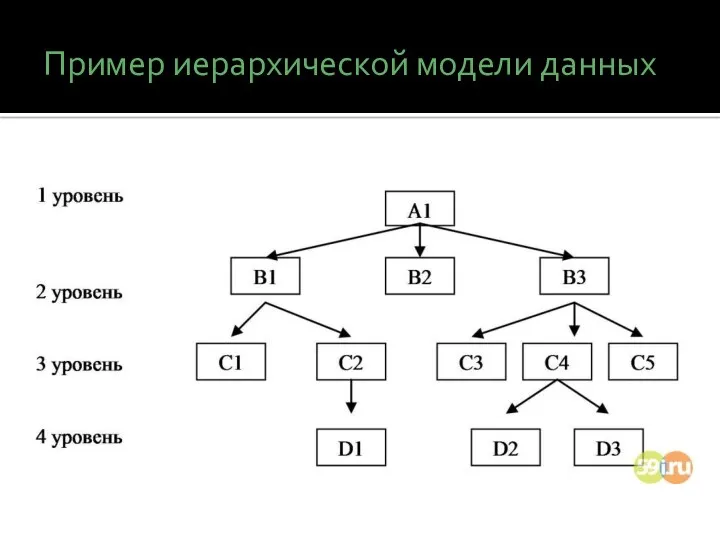
Пример иерархической модели данных
Пример иерархической модели данных

Иерархическая модель БД: основные понятия и специфика построения
В стандартном виде иерархическая
Иерархическая модель БД: основные понятия и специфика построения
В стандартном виде иерархическая

Управляющая часть
Иерархическая бд имеет структуру, включающую управляющую и структурную части. В
Управляющая часть
Иерархическая бд имеет структуру, включающую управляющую и структурную части. В

Структурная часть
В качестве ключевых функциональных единиц в этом случае используются «Поле»
Структурная часть
В качестве ключевых функциональных единиц в этом случае используются «Поле»

Трансформация концептуальной модели БД в иерархическую
Процесс трансформации концептуальной модели БД в
Трансформация концептуальной модели БД в иерархическую
Процесс трансформации концептуальной модели БД в

Специфика управления иерархиями
В процессе управления иерархической БД используются две группы языковых
Специфика управления иерархиями
В процессе управления иерархической БД используются две группы языковых

Какие операции можно выполнять с помощью иерархических БД
Иерархические модели БД имеют
Какие операции можно выполнять с помощью иерархических БД
Иерархические модели БД имеют
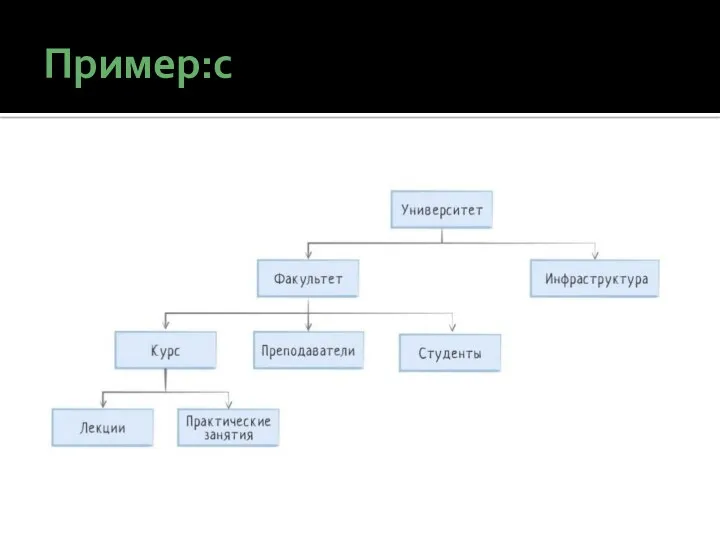
Пример:с
Пример:с

Где используются иерархические структуры данных?
Иерархическая структура базы данных – это основа
Где используются иерархические структуры данных?
Иерархическая структура базы данных – это основа

Преимущества иерархической модели
БД Иерархическая модель базы данных обладает широким спектром
Преимущества иерархической модели
БД Иерархическая модель базы данных обладает широким спектром

Сетевая модель данных
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического
Сетевая модель данных
Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического

Сетевая модель данных
Управление сетевыми данными.
Операции с сетевыми данными можно разделить на
Сетевая модель данных
Управление сетевыми данными.
Операции с сетевыми данными можно разделить на

Сетевая модель данных
Операции модификации данных
Операций модификации сетевых баз данных осуществляют добавление
Сетевая модель данных
Операции модификации данных
Операций модификации сетевых баз данных осуществляют добавление
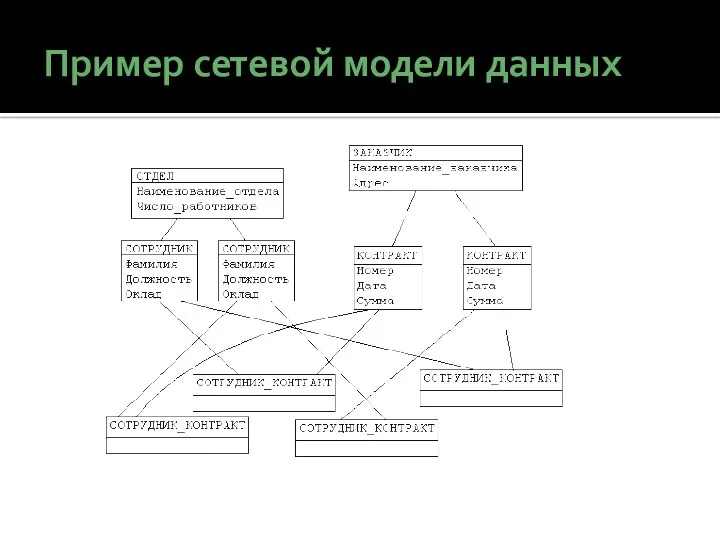
Пример сетевой модели данных
Пример сетевой модели данных

Реляционные базы данных
Прежде чем определять понятие реляционных баз данных, нужно разобраться
Реляционные базы данных
Прежде чем определять понятие реляционных баз данных, нужно разобраться

Реляционная модель
Реляционную модель предложил британский математик Эдгар Кодд на рубеже шестидесятых и семидесятых
Реляционная модель
Реляционную модель предложил британский математик Эдгар Кодд на рубеже шестидесятых и семидесятых

Реляционная модель
Транзакция — это комплекс последовательных операций с применением операторов SQL, имеющих
Реляционная модель
Транзакция — это комплекс последовательных операций с применением операторов SQL, имеющих

Структура реляционной базы данных
Индексы позволяют эффективно реализовать поиск и обработку данных,
Структура реляционной базы данных
Индексы позволяют эффективно реализовать поиск и обработку данных,

Реляционная модель данных
Данные в реляционной базе данных формируют отношения — двумерные
Реляционная модель данных
Данные в реляционной базе данных формируют отношения — двумерные

3 популярных реляционных базы данных для веб-разработки
MySQL
Данную открытую систему управления базами
3 популярных реляционных базы данных для веб-разработки
MySQL
Данную открытую систему управления базами

3 популярных реляционных базы данных для веб-разработки
PostgreSQL
Это наиболее продвинутая система управления
3 популярных реляционных базы данных для веб-разработки
PostgreSQL
Это наиболее продвинутая система управления
 Что такое система
Что такое система Тестовые артефакты, документация. Risk-Based Testing
Тестовые артефакты, документация. Risk-Based Testing Evolution media
Evolution media презентация по информатике по учебнику А. Г.Гейна 8 класс
презентация по информатике по учебнику А. Г.Гейна 8 класс Программирование на языке Python. 9 класс
Программирование на языке Python. 9 класс Разработка программы для шифрования и дешифрования текста особой важности
Разработка программы для шифрования и дешифрования текста особой важности Локальные компьютерные сети
Локальные компьютерные сети Архитектура операционных систем. Введение. (Лекция 1)
Архитектура операционных систем. Введение. (Лекция 1) Технология защищенного документооборота. Лекция 2. Криптография
Технология защищенного документооборота. Лекция 2. Криптография Информатизация – важное условие организации образовательного процесса в МБОУ СОШ №19
Информатизация – важное условие организации образовательного процесса в МБОУ СОШ №19 Количественные характеристики информации
Количественные характеристики информации Диагностирование непрерывных динамических систем с использованием смены позиции входного сигнала
Диагностирование непрерывных динамических систем с использованием смены позиции входного сигнала Установка образа на АРМ-П
Установка образа на АРМ-П Технология разработки и защиты баз данных
Технология разработки и защиты баз данных Lecture 6 Routing
Lecture 6 Routing Правильное место для торговли бинарными опционами
Правильное место для торговли бинарными опционами Задача 20.1
Задача 20.1 Использование логических функций Microsoft Excel
Использование логических функций Microsoft Excel Системы реального времени. Основные понятия систем реального времени
Системы реального времени. Основные понятия систем реального времени Основы программирования
Основы программирования Командная разработка. Разработки игр на Unity
Командная разработка. Разработки игр на Unity Итоговый тест по теме Компьютерная графика 5 класс Диск
Итоговый тест по теме Компьютерная графика 5 класс Диск Remy MF1/P1. Objectives
Remy MF1/P1. Objectives Інформація про наукову діяльність за січень – грудень 2016 року кафедри документознавства та інформаційної діяльності
Інформація про наукову діяльність за січень – грудень 2016 року кафедри документознавства та інформаційної діяльності Компьютерный сленг в речи современной молодёжи
Компьютерный сленг в речи современной молодёжи Импульсные измерения кубитов
Импульсные измерения кубитов Использование голосового помощника Маруся в образовании
Использование голосового помощника Маруся в образовании Программирование на алгоритмическом языке БЕЙСИК
Программирование на алгоритмическом языке БЕЙСИК