Цифровая схемотехника и архитектура компьютера. Иеархия памяти и подсистема ввода-вывода. (Глава 8) презентация
- Цифровая схемотехника и архитектура компьютера. Иеархия памяти и подсистема ввода-вывода. (Глава 8)

Содержание
- 2. Цифровая схемотехника и архитектура компьютера Эти слайды предназначены для преподавателей, которые читают лекции на основе учебника
- 3. Благодарности Перевод данных слайдов на русский язык был выполнен командой сотрудников университетов и компаний из России,
- 4. Глава 8 :: Темы Введение Анализ производительности систем памяти Кэш-память Виртуальная память Ввод-вывод, отображённый в память
- 5. Производительность компьютера зависит от: Производительности процессора Производительности подсистемы памяти Интерфейс памяти Введение
- 6. В предыдущих главах, предполагалось, что доступ к памяти осуществляется за 1 такт, но это не было
- 7. Сделать подсистему памяти такой же быстрой, как процессор Использовать иерархию памяти Идеальная память: Быстрая Дешёвая (недорогая)
- 8. Иерархия памяти
- 9. Используйте локальность для того, чтобы сделать доступ к памяти более быстрым Временная локальность: Локальность во времени
- 10. Попадания: данные найдены на этом уровне иерархии памяти Промахи: данные не найдены на этом уровне иерархии
- 11. Программа имеет 2000 операций загрузки и сохранения 1250 из них нашли данные в кэш-памяти Остальные данные
- 12. Программа имеет 2000 операций загрузки и сохранения 1250 из них нашли данные в кэш-памяти Остальные данные
- 13. Предположим, что процессор имеет 2 уровня иерархии: кэш-память и оперативную память tcache = 1 цикл, tMM
- 14. Предположим, что процессор имеет 2 уровня иерархии: кэш-память и оперативную память tcache = 1 цикл, tMM
- 15. Закон Амдала: усилия, потраченные на улучшение производительности подсистемы, оправдываются только тогда, когда она оказывает значительное влияние
- 16. Наивысший уровень в иерархии памяти Быстрая (обычно время доступа ≈ 1 такт) В идеале предоставляет бόльшую
- 17. Какие данные хранятся в кэш-памяти? Как найти данные? Какие данные заместить? Сосредоточьтесь на загрузке данных, а
- 18. В идеале, процессор предугадывает какие данные потребуются и помещает их в кэш Но невозможно предсказать будущее
- 19. Ёмкость (C): количество байт данных, которое может поместиться в кэш-памяти Размер строк (b): количество байт данных,
- 20. Кэш-память состоит из S наборов Каждый адрес памяти отображается только в один набор кэша По количеству
- 21. C = 8 слов (ёмкость) b = 1 слово (размер строки) Тогда, B = 8 (количество
- 22. Кэш прямого отображения
- 23. Аппаратная реализация кэша прямого отображения
- 24. # MIPS код addi $t0, $0, 5 loop: beq $t0, $0, done lw $t1, 0x4($0) lw
- 25. # MIPS код addi $t0, $0, 5 loop: beq $t0, $0, done lw $t1, 0x4($0) lw
- 26. # MIPS код addi $t0, $0, 5 loop: beq $t0, $0, done lw $t1, 0x4($0) lw
- 27. # MIPS код addi $t0, $0, 5 loop: beq $t0, $0, done lw $t1, 0x4($0) lw
- 28. Наборно-ассоциативный кэш с N секциями
- 29. # MIPS код addi $t0, $0, 5 loop: beq $t0, $0, done lw $t1, 0x4($0) lw
- 30. # MIPS код addi $t0, $0, 5 loop: beq $t0, $0, done lw $t1, 0x4($0) lw
- 31. Уменьшает количество конфликтов из-за промахов Построение крайне затратное Полностью ассоциативный кэш
- 32. Увеличение размера строки: Размер строки, b = 4 слова C = 8 слов Прямое отображение (1
- 33. Кэш с бόльшим размером строки
- 34. addi $t0, $0, 5 loop: beq $t0, $0, done lw $t1, 0x4($0) lw $t2, 0xC($0) lw
- 35. addi $t0, $0, 5 loop: beq $t0, $0, done lw $t1, 0x4($0) lw $t2, 0xC($0) lw
- 36. Ёмкость: C Размер строки: b Количество строк в кэш-памяти: B = C/b Количество строк в наборе:
- 37. Кэш слишком мал, чтобы вместить сразу все данные, представляющие интерес Если кэш заполнен: программа получает доступ
- 38. Неизбежные: при первом доступе к данным Из-за недостаточной ёмкости: кэш слишком мал, чтобы вместить сразу все
- 39. # MIPS код lw $t0, 0x04($0) lw $t1, 0x24($0) lw $t2, 0x54($0) Замещение LRU
- 40. # MIPS код lw $t0, 0x04($0) lw $t1, 0x24($0) lw $t2, 0x54($0) Замещение LRU
- 41. Какие данные хранить в кэш-памяти? Недавно использованные данные (временная локальность) Рядом лежащие данные (пространственная локальность) Как
- 42. Больший размер кэша уменьшает количество промахов из-за недостаточной ёмкости Бόльшая ассоциативность уменьшает количество промахов из-за конфликтов
- 43. Бόльшие размеры строк уменьшают количество обязательных промахов Бόльшие размеры строк увеличивают количество промахов из-за конфликтов Динамика
- 44. Кэши большего размера имеют меньший процент промахов, но более длительное время доступа Спроецируйте идею иерархии памяти
- 45. Intel Pentium III
- 46. Даёт иллюзию большего размера памяти Оперативная память (DRAM) выступает в качестве кэша для жесткого диска Виртуальная
- 47. Физическая память: DRAM (оперативная память) Виртуальная память: жёсткий диск медленная, большая, дешёвая Иерархия памяти
- 48. Поиск правильного положения занимает миллисекунды Жёсткий диск
- 49. Виртуальные адреса Программы используют виртуальные адреса Всё виртуальное адресное пространство хранится на жёстком диске Подмножество виртуальных
- 50. Физическая память выступает в качестве кэша виртуальной памяти Аналогия между виртуальной памятью и кэшем
- 51. Размер страницы: количество памяти, переносимое с жесткого диска в DRAM одновременно Трансляция адреса: определение физического адреса
- 52. Большинство доступов осуществляется в физическую память Но программы имеют большую ёмкость виртуальной памяти Виртуальные и физические
- 53. Трансляция адреса
- 54. Система: Размер виртуальной памяти: 2 ГБ = 231 байт Размер физической памяти: 128 МБ = 227
- 55. Система: Размер виртуальной памяти: 2 ГБ = 231 байт Размер физической памяти: 128 МБ = 227
- 56. 19-битный номер виртуальной страницы 15-битный номер физической страницы Пример виртуальной памяти
- 57. Пример виртуальной памяти Каков физический адрес виртуального адреса 0x247C?
- 58. Пример виртуальной памяти Каков физический адрес виртуального адреса 0x247C? VPN = 0x2 VPN 0x2 отображается в
- 59. Таблица страниц Содержит запись для каждой виртуальной страницы Запись содержит: Бит достоверности: 1 если страница находится
- 60. VPN является индексом в таблице страниц Пример таблицы страниц
- 61. Каков физический адрес виртуального адреса 0x5F20? Первый пример таблицы страниц
- 62. Каков физический адрес виртуального адреса 0x5F20? VPN = 5 Запись с № 5 в таблице страниц
- 63. Каков физический адрес виртуального адреса 0x73E0? Второй пример таблицы страниц
- 64. Каков физический адрес виртуального адреса 0x73E0? VPN = 7 Запись 7 является недостоверной Виртуальная страница должна
- 65. Таблица страниц большая как правило, находится в физической памяти Загрузка/сохранение требуют два доступа к оперативной памяти:
- 66. Небольшой кэш самых последних трансляций Снижение количества доступов к памяти для большинства загрузок/сохранений с 2 до
- 67. Доступ к таблице страниц: большая пространственная локальность Большой размер страницы: идущие друг за другом загрузки/сохранения имеют
- 68. Пример 2 – запись TLB
- 69. Множество процессов (программ) работают одновременно Каждый процесс имеет свою собственную таблицу страниц Каждый процесс может использовать
- 70. Виртуальная память увеличивает пропускную способность Подмножество виртуальных страниц хранится в физической памяти Таблица страниц отображает виртуальные
- 71. Процессор получает доступ к устройствам ввода-вывода так же, как и к памяти (например к клавиатурам, мониторам,
- 72. Дешифратор адреса: Смотрит на адрес для того, чтобы определить – какое устройство или память связывается с
- 73. Интерфейс памяти
- 74. Аппаратная реализация ввода-вывода, отображённого в память
- 75. Предположим, что устройству ввода‑вывода 1 присваивается адрес 0xFFFFFFF4 Запишите значение 42 в устройство ввода‑вывода 1 Прочтите
- 76. Запишите значение 42 в устройство ввода-вывода 1 (0xFFFFFFF4) addi $t0, $0, 42 sw $t0, 0xFFF4($0) Код
- 77. Прочтите значение из устройства ввода-вывода 1 и поместите его в $t3 lw $t3, 0xFFF4($0) Код ввода-вывода,
- 78. Встроенные подсистемы ввода-вывода Тостеры, светодиоды и т. д. Подсистемы ввода-вывода персональных компьютеров Подсистема ввода-вывода
- 79. Пример микроконтроллера: PIC32 микроконтроллер 32-битный MIPS процессор низкоуровневая периферия включает: последовательные порты таймеры аналого-цифровые преобразователи Встроенные
- 80. // C код #include int main(void) { int switches; TRISD = 0xFF00; // RD[7:0] outputs //
- 81. Пример последовательных протоколов последовательный периферийный интерфейс (англ. Serial Peripheral Interface, SPI) универсальный асинхронный приемопередатчик (англ. Universal
- 82. SPI: последовательный периферийный интерфейс Ведущее устройство (master) инициирует установку связи с ведомым устройством (slave) посредством генерации
- 83. UART: универсальный асинхронный приемопередатчик Параметры: Стартовый бит (0), 7-8 бит данных, бит чётности (опционален), 1 и
- 84. // Create specified ms/us of delay using built-in timer #include void delaymicros(int micros) { if (micros
- 85. Необходим для взаимодействия с внешним миром Аналоговый ввод: аналого-цифровое преобразование Часто включено в микроконтроллер N битовое:
- 86. Широтно-импульсная модуляция (ШИМ) Среднее значение пропорционально коэффициенту заполнения Добавить фильтр верхних частот на выходе для установки
- 87. Другие внешние устройства микроконтроллера Примеры Символьный ЖК-дисплей VGA монитор Беспроводная связь Bluetooth Двигатели
- 88. Подсистема ввода-вывода персональных компьютеров Универсальная последовательная шина (англ. Universal Serial Bus, USB) USB 1.0 был выпущен
- 90. Скачать презентацию

Цифровая схемотехника и архитектура компьютера
Эти слайды предназначены для преподавателей, которые читают
Цифровая схемотехника и архитектура компьютера
Эти слайды предназначены для преподавателей, которые читают

Благодарности
Перевод данных слайдов на русский язык был выполнен командой сотрудников университетов
Благодарности
Перевод данных слайдов на русский язык был выполнен командой сотрудников университетов

Глава 8 :: Темы
Введение
Анализ производительности
систем памяти
Кэш-память
Виртуальная память
Ввод-вывод, отображённый
в память
Резюме
Глава 8 :: Темы
Введение
Анализ производительности
систем памяти
Кэш-память
Виртуальная память
Ввод-вывод, отображённый
в память
Резюме
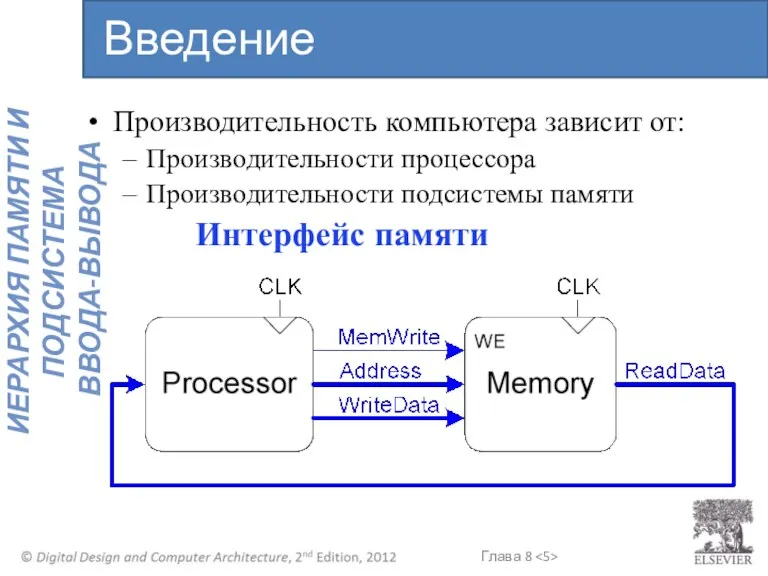
Производительность компьютера зависит от:
Производительности процессора
Производительности подсистемы памяти
Интерфейс памяти
Введение
Производительность компьютера зависит от:
Производительности процессора
Производительности подсистемы памяти
Интерфейс памяти
Введение
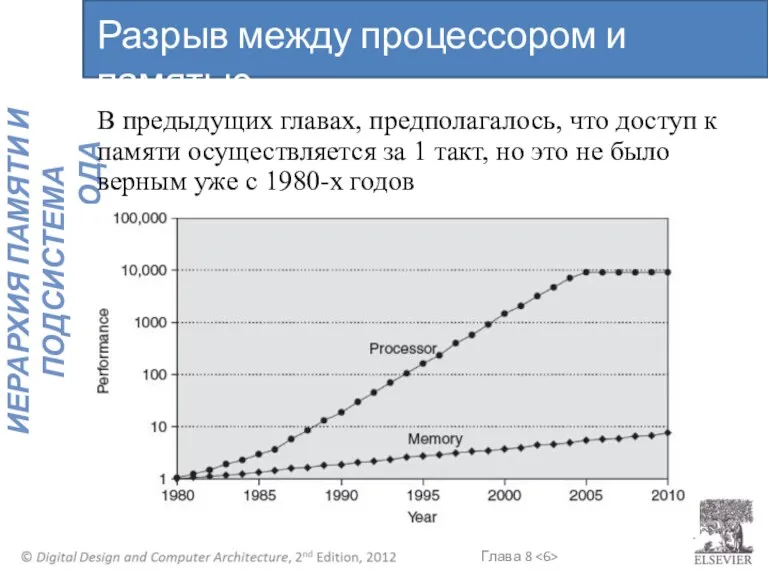
В предыдущих главах, предполагалось, что доступ к памяти осуществляется за 1
В предыдущих главах, предполагалось, что доступ к памяти осуществляется за 1

Сделать подсистему памяти такой же быстрой, как процессор
Использовать иерархию
памяти
Идеальная память:
Быстрая
Дешёвая
Сделать подсистему памяти такой же быстрой, как процессор
Использовать иерархию
памяти
Идеальная память:
Быстрая
Дешёвая
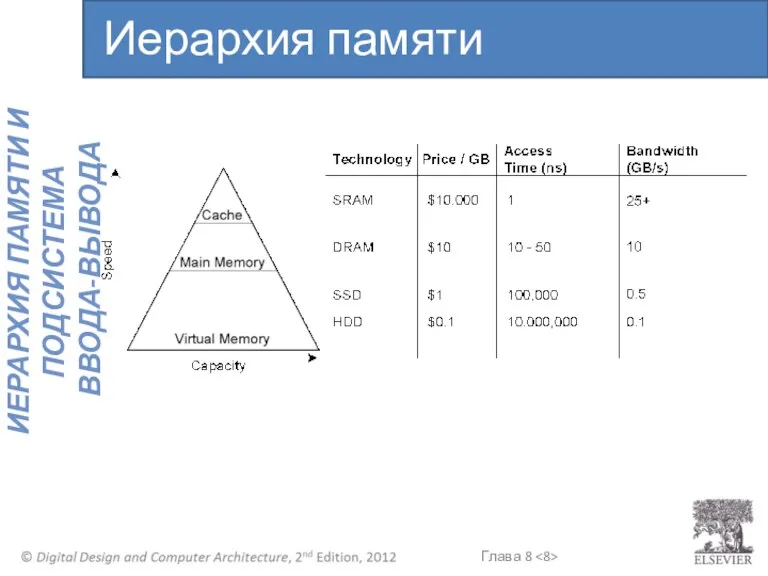
Иерархия памяти
Иерархия памяти

Используйте локальность для того, чтобы сделать доступ к памяти более быстрым
Временная
Используйте локальность для того, чтобы сделать доступ к памяти более быстрым
Временная

Попадания: данные найдены на этом уровне иерархии памяти
Промахи: данные не найдены
Попадания: данные найдены на этом уровне иерархии памяти
Промахи: данные не найдены

Программа имеет 2000 операций загрузки и сохранения
1250 из них нашли данные
Программа имеет 2000 операций загрузки и сохранения
1250 из них нашли данные

Программа имеет 2000 операций загрузки и сохранения
1250 из них нашли данные
Программа имеет 2000 операций загрузки и сохранения
1250 из них нашли данные

Предположим, что процессор имеет 2 уровня иерархии: кэш-память и оперативную память
tcache
Предположим, что процессор имеет 2 уровня иерархии: кэш-память и оперативную память
tcache

Предположим, что процессор имеет 2 уровня иерархии: кэш-память и оперативную память
tcache
Предположим, что процессор имеет 2 уровня иерархии: кэш-память и оперативную память
tcache

Закон Амдала: усилия, потраченные на улучшение производительности подсистемы, оправдываются только тогда,
Закон Амдала: усилия, потраченные на улучшение производительности подсистемы, оправдываются только тогда,

Наивысший уровень в иерархии памяти
Быстрая (обычно время доступа ≈ 1 такт)
В
Наивысший уровень в иерархии памяти
Быстрая (обычно время доступа ≈ 1 такт)
В

Какие данные хранятся в кэш-памяти?
Как найти данные?
Какие данные заместить?
Сосредоточьтесь на загрузке
Какие данные хранятся в кэш-памяти?
Как найти данные?
Какие данные заместить?
Сосредоточьтесь на загрузке

В идеале, процессор предугадывает какие данные потребуются и помещает их в
В идеале, процессор предугадывает какие данные потребуются и помещает их в

Ёмкость (C):
количество байт данных, которое может поместиться в кэш-памяти
Размер строк
Ёмкость (C):
количество байт данных, которое может поместиться в кэш-памяти
Размер строк

Кэш-память состоит из S наборов
Каждый адрес памяти отображается только в один
Кэш-память состоит из S наборов
Каждый адрес памяти отображается только в один

C = 8 слов (ёмкость)
b = 1 слово (размер строки)
Тогда, B
C = 8 слов (ёмкость)
b = 1 слово (размер строки)
Тогда, B
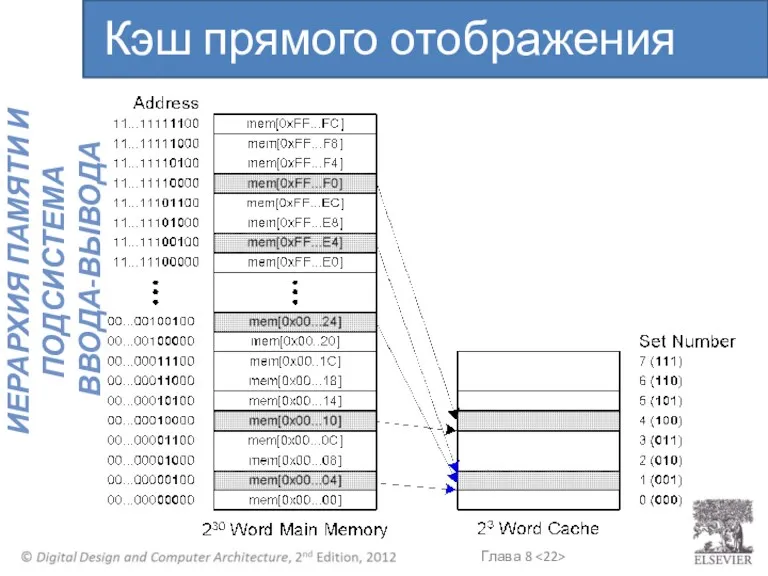
Кэш прямого отображения
Кэш прямого отображения
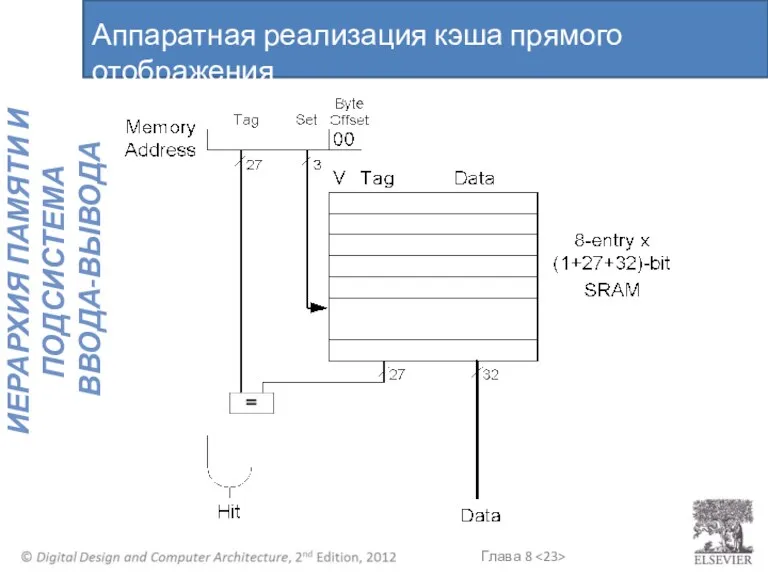
Аппаратная реализация кэша прямого отображения
Аппаратная реализация кэша прямого отображения

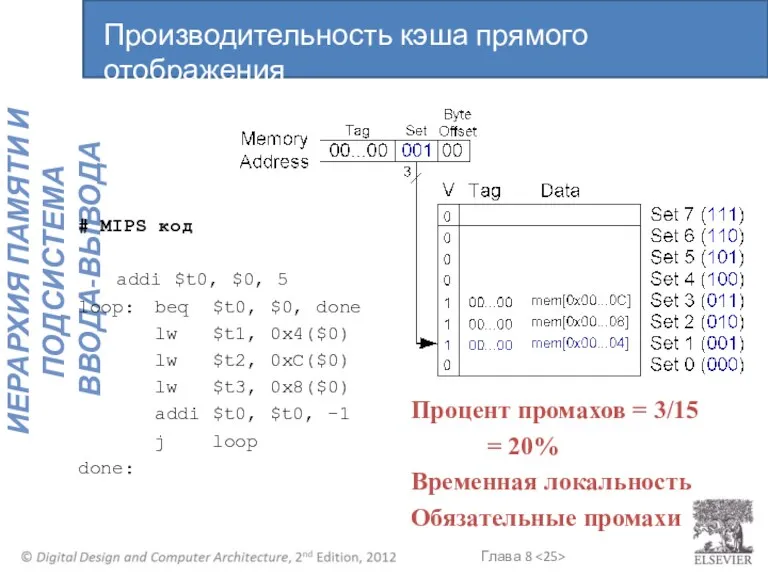
# MIPS код
addi $t0, $0, 5
loop: beq $t0, $0, done
# MIPS код
addi $t0, $0, 5
loop: beq $t0, $0, done
# MIPS код
addi $t0, $0, 5
loop: beq $t0, $0, done
# MIPS код
addi $t0, $0, 5
loop: beq $t0, $0, done

# MIPS код
addi $t0, $0, 5
loop: beq $t0, $0, done
# MIPS код
addi $t0, $0, 5
loop: beq $t0, $0, done

# MIPS код
addi $t0, $0, 5
loop: beq $t0, $0, done
# MIPS код
addi $t0, $0, 5
loop: beq $t0, $0, done
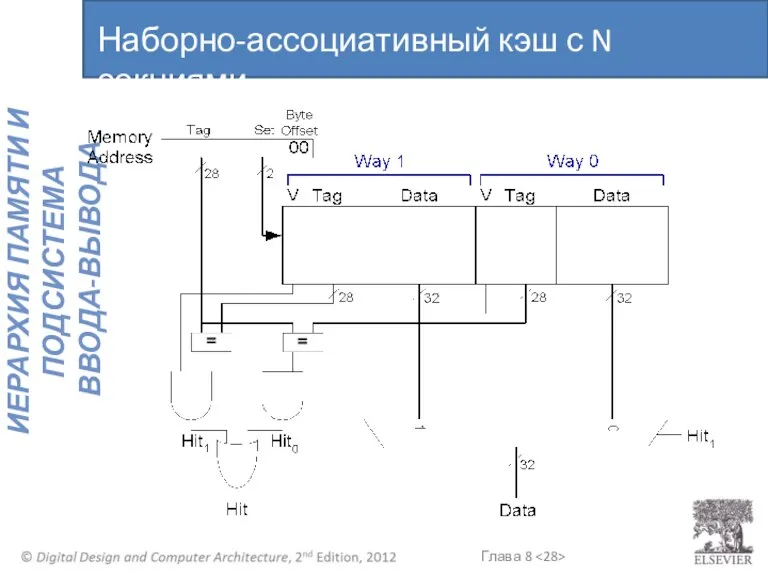
Наборно-ассоциативный кэш с N секциями
Наборно-ассоциативный кэш с N секциями
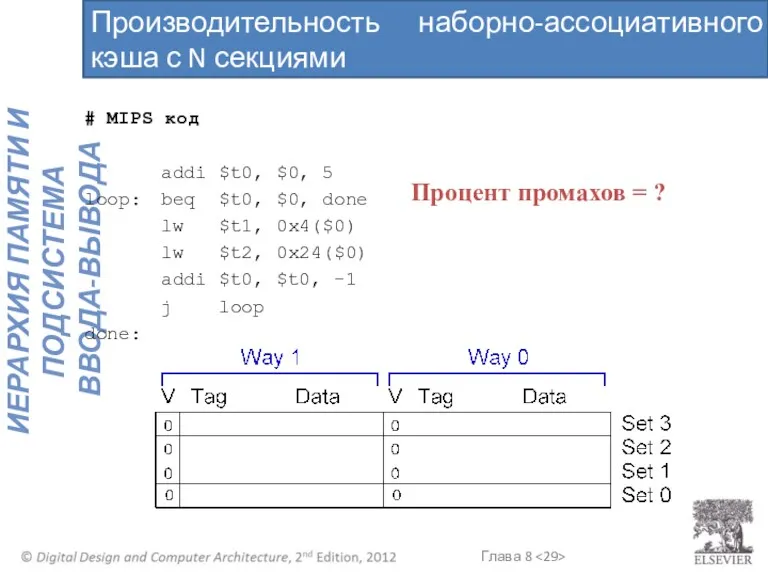
# MIPS код
addi $t0, $0, 5
loop: beq $t0, $0, done
# MIPS код
addi $t0, $0, 5
loop: beq $t0, $0, done

# MIPS код
addi $t0, $0, 5
loop: beq $t0, $0, done
# MIPS код
addi $t0, $0, 5
loop: beq $t0, $0, done

Уменьшает количество конфликтов из-за промахов
Построение крайне затратное
Полностью ассоциативный кэш
Уменьшает количество конфликтов из-за промахов
Построение крайне затратное
Полностью ассоциативный кэш

Увеличение размера строки:
Размер строки, b = 4 слова
C = 8 слов
Прямое
Увеличение размера строки:
Размер строки, b = 4 слова
C = 8 слов
Прямое
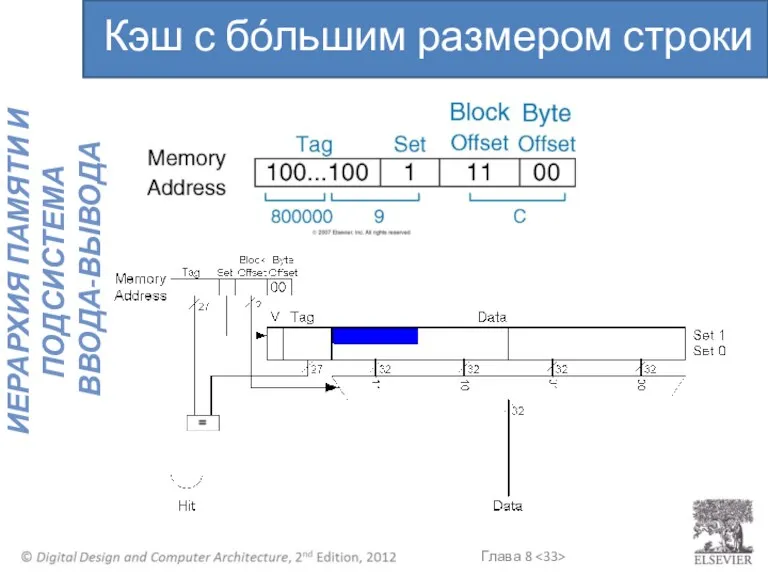
Кэш с бόльшим размером строки
Кэш с бόльшим размером строки

addi $t0, $0, 5
loop: beq $t0, $0, done
lw $t1, 0x4($0)
lw
addi $t0, $0, 5
loop: beq $t0, $0, done
lw $t1, 0x4($0)
lw
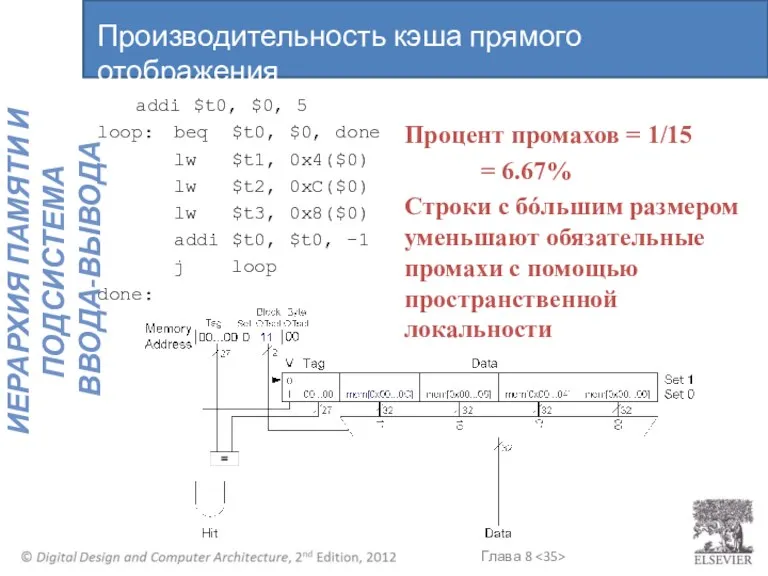
addi $t0, $0, 5
loop: beq $t0, $0, done
lw $t1, 0x4($0)
lw
addi $t0, $0, 5
loop: beq $t0, $0, done
lw $t1, 0x4($0)
lw
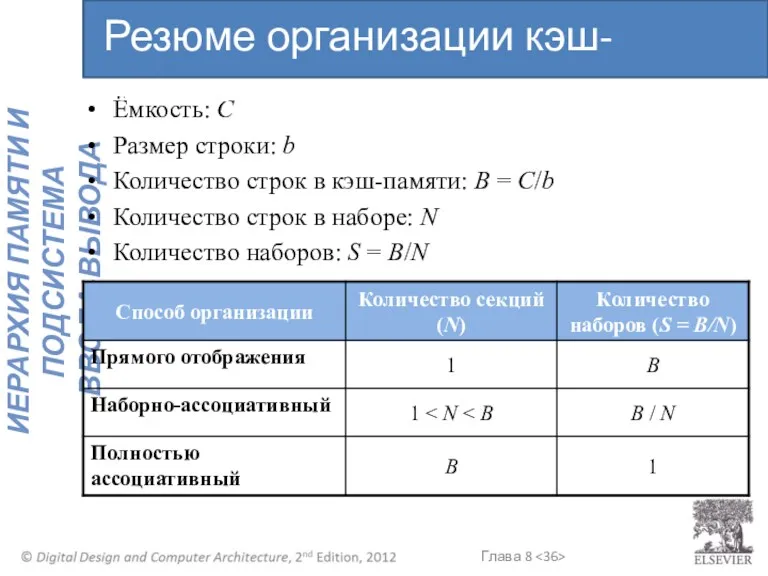
Ёмкость: C
Размер строки: b
Количество строк в кэш-памяти: B = C/b
Количество
Ёмкость: C
Размер строки: b
Количество строк в кэш-памяти: B = C/b
Количество

Кэш слишком мал, чтобы вместить сразу все данные, представляющие интерес
Если кэш
Кэш слишком мал, чтобы вместить сразу все данные, представляющие интерес
Если кэш

Неизбежные: при первом доступе к данным
Из-за недостаточной ёмкости: кэш слишком мал,
Неизбежные: при первом доступе к данным
Из-за недостаточной ёмкости: кэш слишком мал,

# MIPS код
lw $t0, 0x04($0)
lw $t1, 0x24($0)
lw $t2, 0x54($0)
Замещение LRU
# MIPS код
lw $t0, 0x04($0)
lw $t1, 0x24($0)
lw $t2, 0x54($0)
Замещение LRU
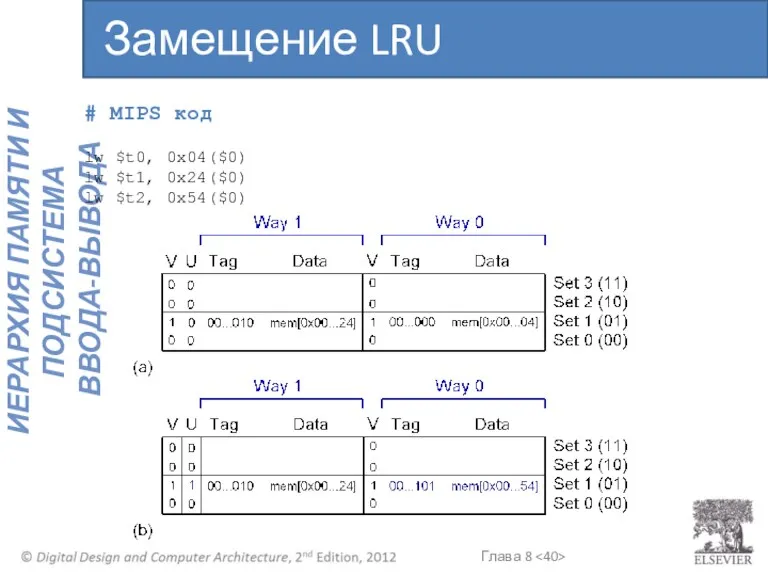
# MIPS код
lw $t0, 0x04($0)
lw $t1, 0x24($0)
lw $t2, 0x54($0)
Замещение LRU
# MIPS код
lw $t0, 0x04($0)
lw $t1, 0x24($0)
lw $t2, 0x54($0)
Замещение LRU

Какие данные хранить в кэш-памяти?
Недавно использованные данные (временная локальность)
Рядом лежащие данные
Какие данные хранить в кэш-памяти?
Недавно использованные данные (временная локальность)
Рядом лежащие данные
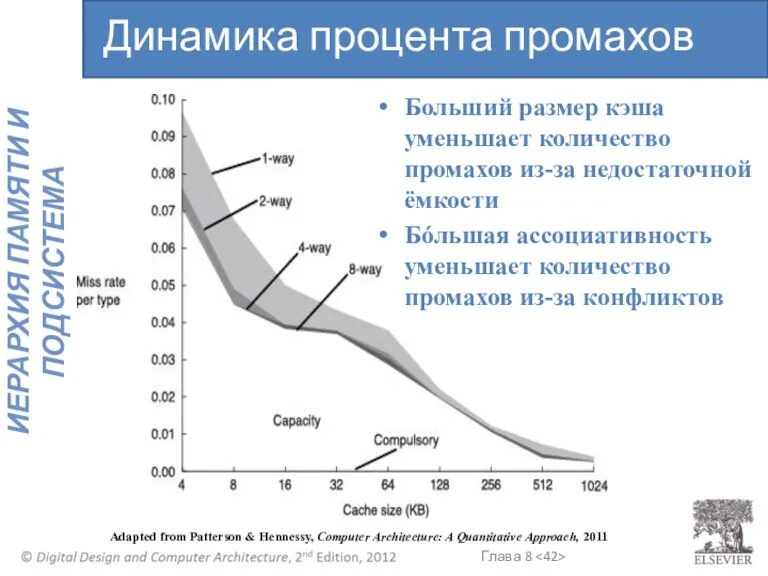
Больший размер кэша уменьшает количество промахов из-за недостаточной ёмкости
Бόльшая ассоциативность уменьшает
Больший размер кэша уменьшает количество промахов из-за недостаточной ёмкости
Бόльшая ассоциативность уменьшает
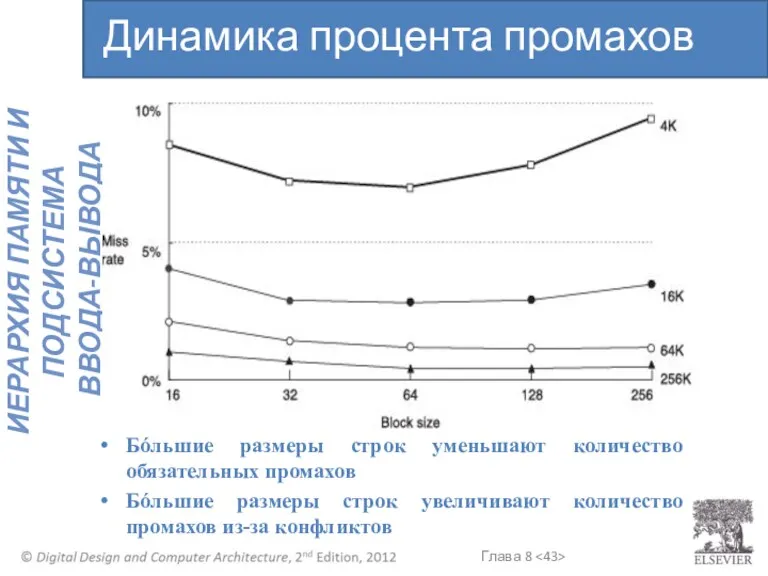
Бόльшие размеры строк уменьшают количество обязательных промахов
Бόльшие размеры строк увеличивают количество
Бόльшие размеры строк уменьшают количество обязательных промахов
Бόльшие размеры строк увеличивают количество

Кэши большего размера имеют меньший процент промахов, но более длительное время
Кэши большего размера имеют меньший процент промахов, но более длительное время

Intel Pentium III
Intel Pentium III

Даёт иллюзию большего размера памяти
Оперативная память (DRAM) выступает в качестве кэша
Даёт иллюзию большего размера памяти
Оперативная память (DRAM) выступает в качестве кэша

Физическая память: DRAM (оперативная память)
Виртуальная память: жёсткий диск
медленная, большая, дешёвая
Иерархия памяти
Физическая память: DRAM (оперативная память)
Виртуальная память: жёсткий диск
медленная, большая, дешёвая
Иерархия памяти

Поиск правильного положения занимает миллисекунды
Жёсткий диск
Поиск правильного положения занимает миллисекунды
Жёсткий диск

Виртуальные адреса
Программы используют виртуальные адреса
Всё виртуальное адресное пространство хранится на жёстком
Виртуальные адреса
Программы используют виртуальные адреса
Всё виртуальное адресное пространство хранится на жёстком
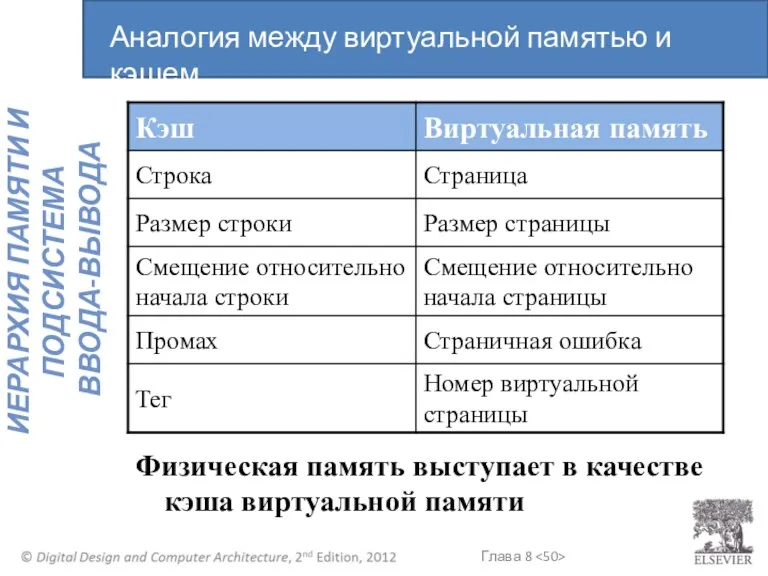
Физическая память выступает в качестве кэша виртуальной памяти
Аналогия между виртуальной памятью
Физическая память выступает в качестве кэша виртуальной памяти
Аналогия между виртуальной памятью

Размер страницы: количество памяти, переносимое с жесткого диска в DRAM одновременно
Трансляция
Размер страницы: количество памяти, переносимое с жесткого диска в DRAM одновременно
Трансляция
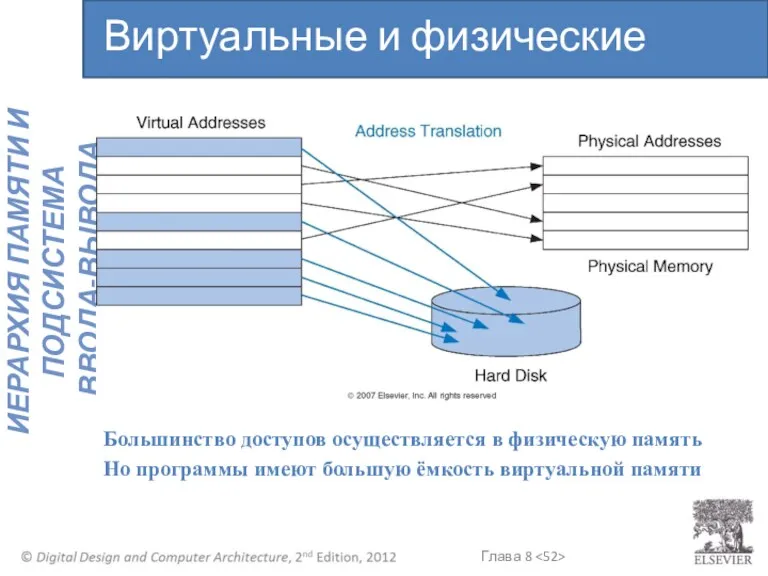
Большинство доступов осуществляется в физическую память
Но программы имеют большую ёмкость виртуальной
Большинство доступов осуществляется в физическую память
Но программы имеют большую ёмкость виртуальной
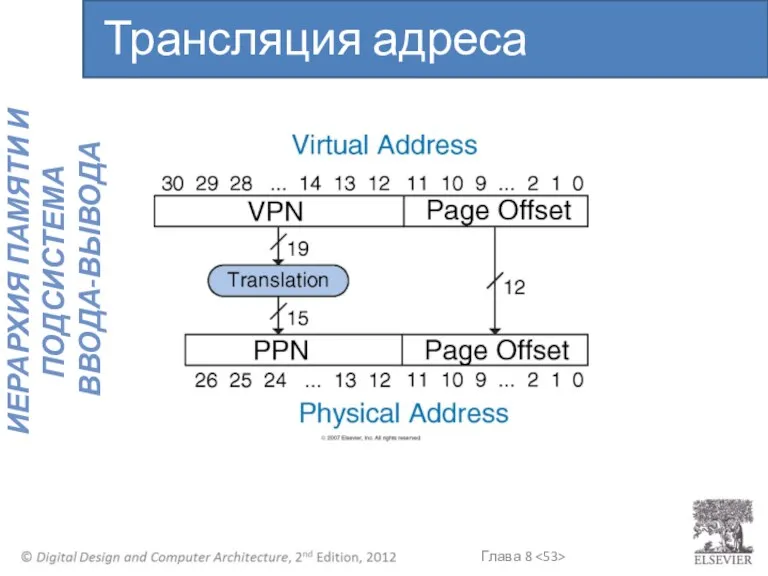
Трансляция адреса
Трансляция адреса

Система:
Размер виртуальной памяти: 2 ГБ = 231 байт
Размер физической памяти: 128
Система:
Размер виртуальной памяти: 2 ГБ = 231 байт
Размер физической памяти: 128

Система:
Размер виртуальной памяти: 2 ГБ = 231 байт
Размер физической памяти: 128
Система:
Размер виртуальной памяти: 2 ГБ = 231 байт
Размер физической памяти: 128
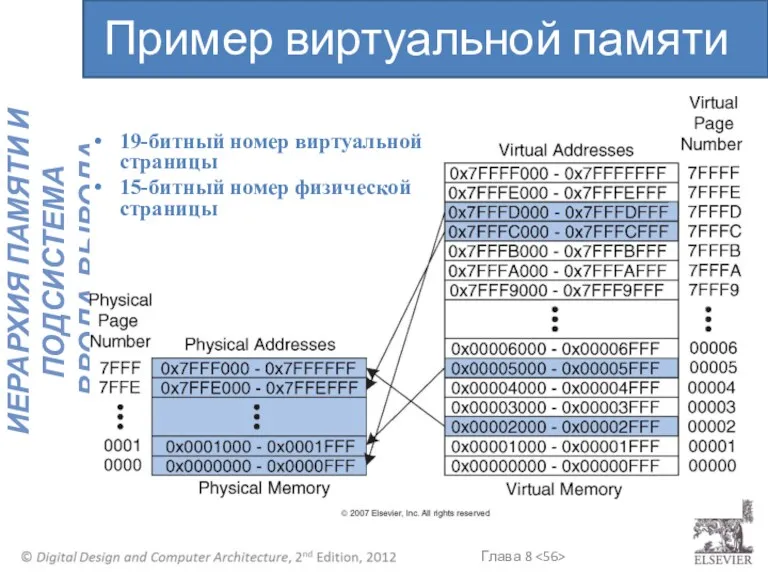
19-битный номер виртуальной страницы
15-битный номер физической страницы
Пример виртуальной памяти
19-битный номер виртуальной страницы
15-битный номер физической страницы
Пример виртуальной памяти
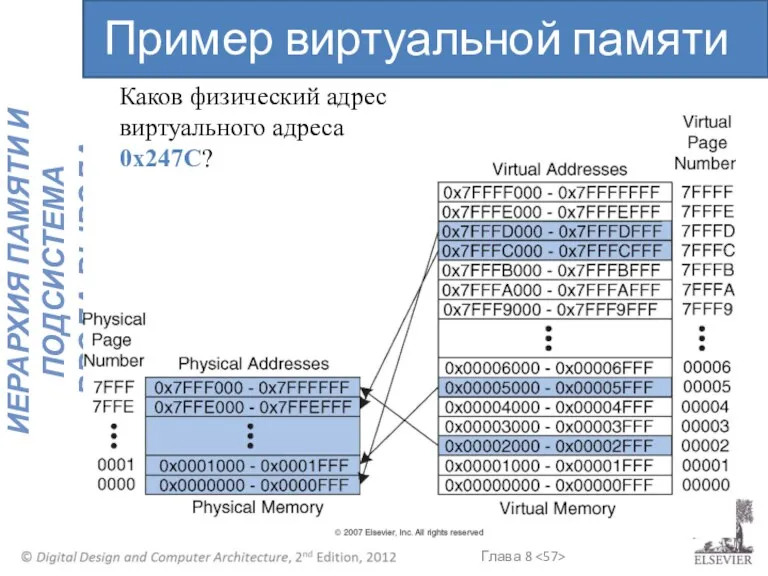
Пример виртуальной памяти
Каков физический адрес виртуального адреса 0x247C?
Пример виртуальной памяти
Каков физический адрес виртуального адреса 0x247C?
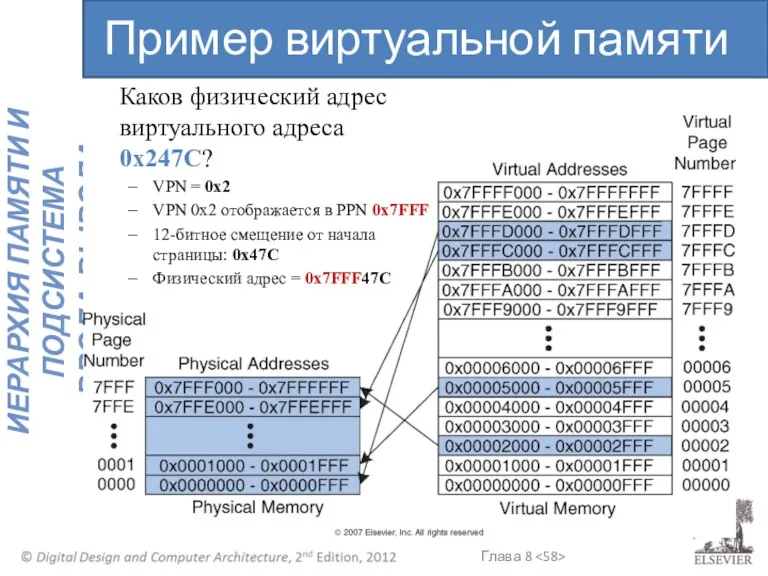
Пример виртуальной памяти
Каков физический адрес виртуального адреса 0x247C?
VPN = 0x2
VPN 0x2
Пример виртуальной памяти
Каков физический адрес виртуального адреса 0x247C?
VPN = 0x2
VPN 0x2

Таблица страниц
Содержит запись для каждой виртуальной страницы
Запись содержит:
Бит достоверности: 1 если
Таблица страниц
Содержит запись для каждой виртуальной страницы
Запись содержит:
Бит достоверности: 1 если
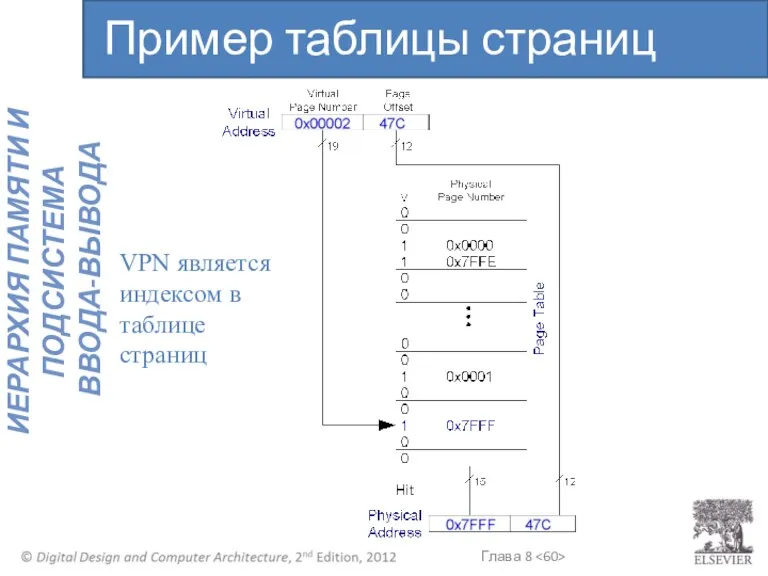
VPN является индексом в таблице страниц
Пример таблицы страниц
VPN является индексом в таблице страниц
Пример таблицы страниц

Каков физический адрес виртуального адреса 0x5F20?
Первый пример таблицы страниц
Каков физический адрес виртуального адреса 0x5F20?
Первый пример таблицы страниц
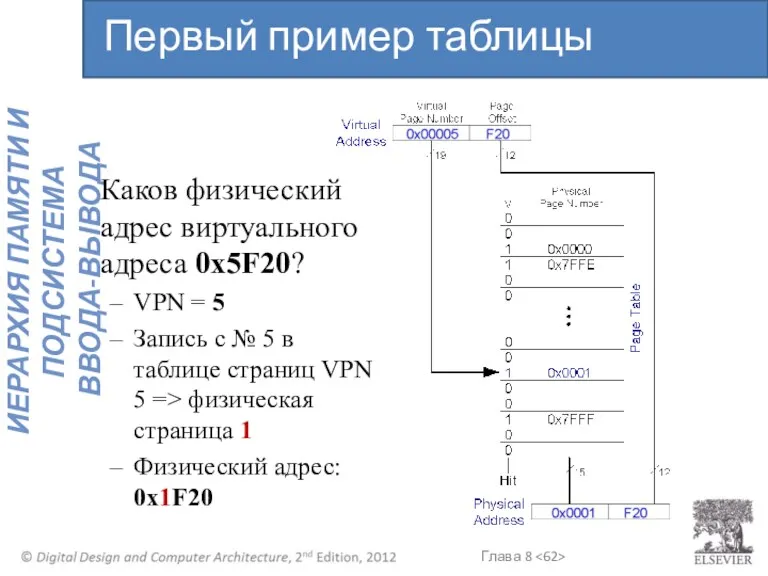
Каков физический адрес виртуального адреса 0x5F20?
VPN = 5
Запись с №
Каков физический адрес виртуального адреса 0x5F20?
VPN = 5
Запись с №

Каков физический адрес виртуального адреса 0x73E0?
Второй пример таблицы страниц
Каков физический адрес виртуального адреса 0x73E0?
Второй пример таблицы страниц

Каков физический адрес виртуального адреса 0x73E0?
VPN = 7
Запись 7 является
Каков физический адрес виртуального адреса 0x73E0?
VPN = 7
Запись 7 является

Таблица страниц большая
как правило, находится в физической памяти
Загрузка/сохранение требуют два доступа
Таблица страниц большая
как правило, находится в физической памяти
Загрузка/сохранение требуют два доступа

Небольшой кэш самых последних трансляций
Снижение количества доступов к памяти для большинства
Небольшой кэш самых последних трансляций
Снижение количества доступов к памяти для большинства

Доступ к таблице страниц: большая пространственная локальность
Большой размер страницы: идущие друг
Доступ к таблице страниц: большая пространственная локальность
Большой размер страницы: идущие друг
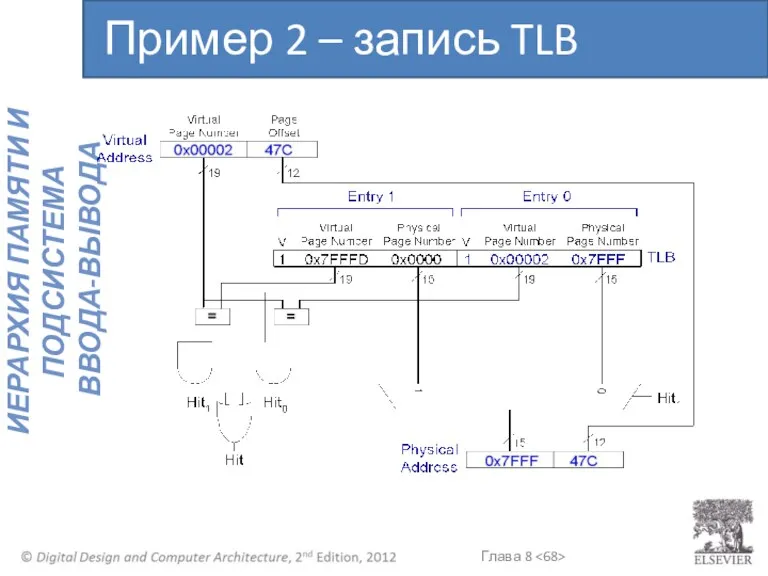
Пример 2 – запись TLB
Пример 2 – запись TLB

Множество процессов (программ) работают одновременно
Каждый процесс имеет свою собственную таблицу страниц
Каждый
Множество процессов (программ) работают одновременно
Каждый процесс имеет свою собственную таблицу страниц
Каждый

Виртуальная память увеличивает пропускную способность
Подмножество виртуальных страниц хранится в физической памяти
Таблица
Виртуальная память увеличивает пропускную способность
Подмножество виртуальных страниц хранится в физической памяти
Таблица

Процессор получает доступ к устройствам ввода-вывода так же, как и к
Процессор получает доступ к устройствам ввода-вывода так же, как и к

Дешифратор адреса:
Смотрит на адрес для того, чтобы определить – какое устройство
Дешифратор адреса:
Смотрит на адрес для того, чтобы определить – какое устройство
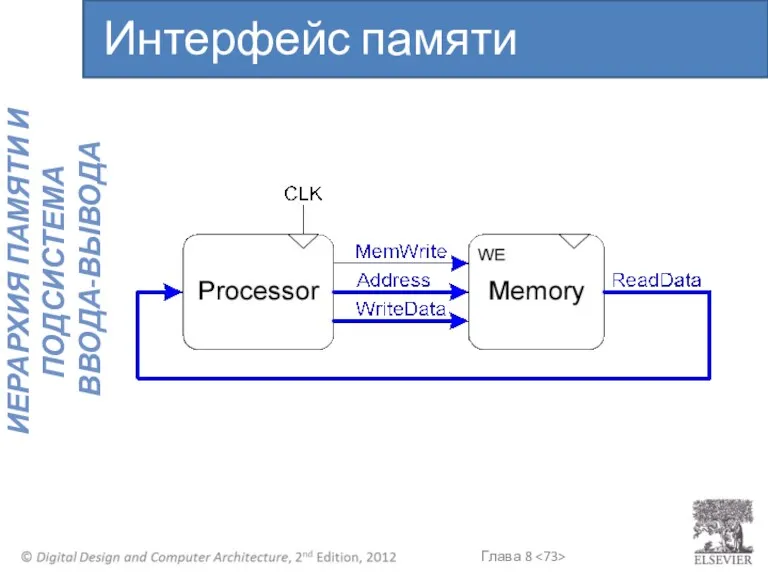
Интерфейс памяти
Интерфейс памяти
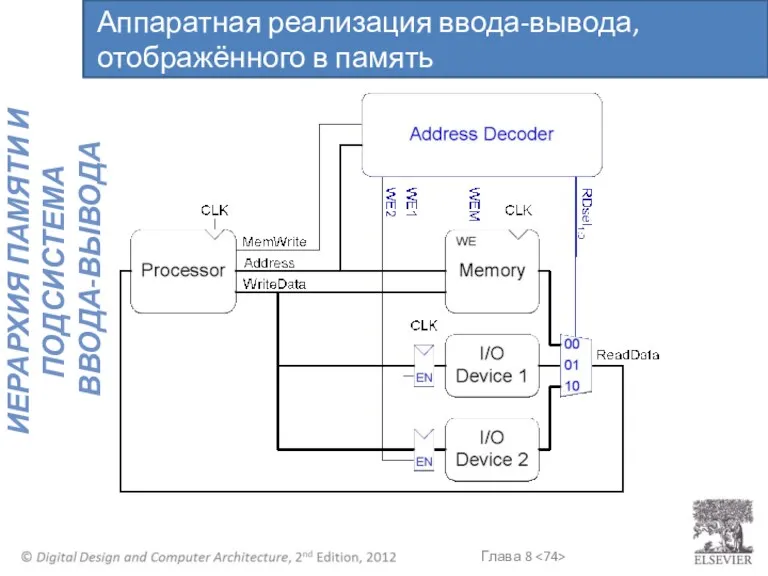
Аппаратная реализация ввода-вывода, отображённого в память
Аппаратная реализация ввода-вывода, отображённого в память

Предположим, что устройству ввода‑вывода 1 присваивается адрес 0xFFFFFFF4
Запишите значение 42 в
Предположим, что устройству ввода‑вывода 1 присваивается адрес 0xFFFFFFF4
Запишите значение 42 в
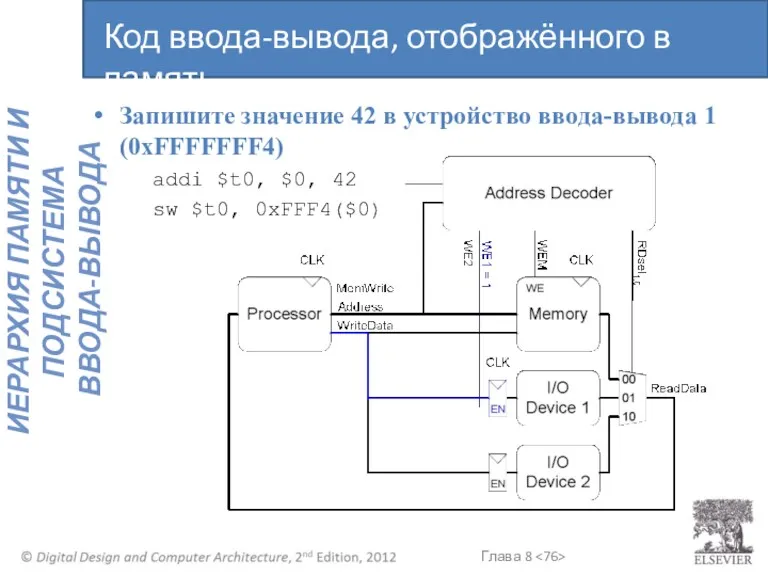
Запишите значение 42 в устройство ввода-вывода 1 (0xFFFFFFF4)
addi $t0, $0, 42
sw
Запишите значение 42 в устройство ввода-вывода 1 (0xFFFFFFF4)
addi $t0, $0, 42
sw
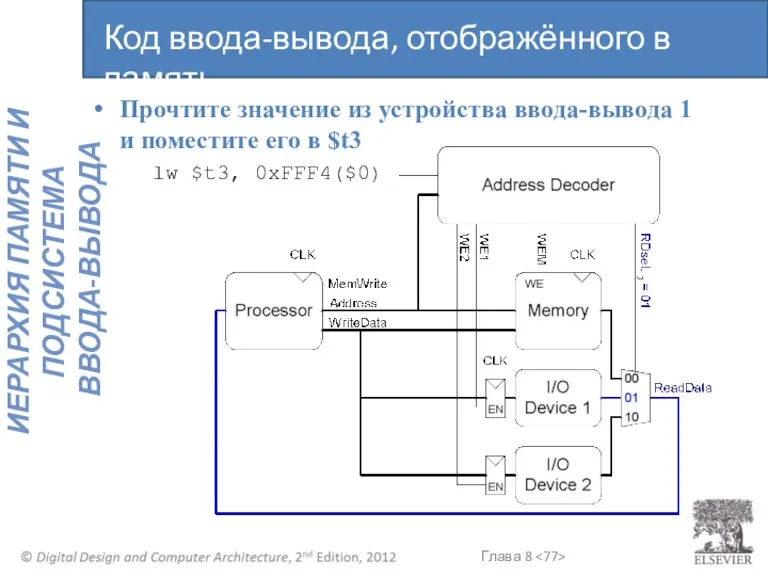
Прочтите значение из устройства ввода-вывода 1 и поместите его в $t3
lw
Прочтите значение из устройства ввода-вывода 1 и поместите его в $t3
lw

Встроенные подсистемы ввода-вывода
Тостеры, светодиоды и т. д.
Подсистемы ввода-вывода персональных компьютеров
Подсистема ввода-вывода
Встроенные подсистемы ввода-вывода
Тостеры, светодиоды и т. д.
Подсистемы ввода-вывода персональных компьютеров
Подсистема ввода-вывода

Пример микроконтроллера: PIC32
микроконтроллер
32-битный MIPS процессор
низкоуровневая периферия включает:
последовательные порты
таймеры
аналого-цифровые преобразователи
Встроенные подсистемы ввода-вывода
Пример микроконтроллера: PIC32
микроконтроллер
32-битный MIPS процессор
низкоуровневая периферия включает:
последовательные порты
таймеры
аналого-цифровые преобразователи
Встроенные подсистемы ввода-вывода

// C код
#include
int main(void) {
int switches;
TRISD = 0xFF00;
// C код
#include
int main(void) {
int switches;
TRISD = 0xFF00;

Пример последовательных протоколов
последовательный периферийный интерфейс (англ. Serial Peripheral Interface, SPI)
универсальный
Пример последовательных протоколов
последовательный периферийный интерфейс (англ. Serial Peripheral Interface, SPI)
универсальный
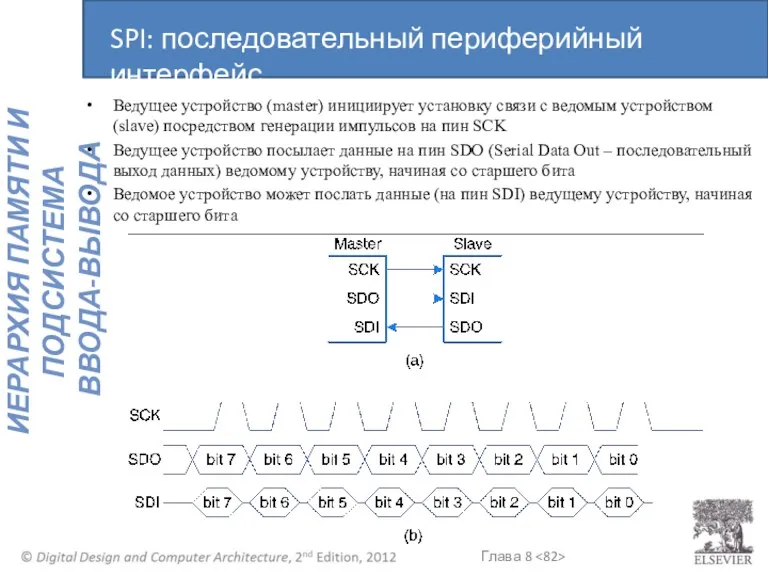
SPI: последовательный периферийный интерфейс
Ведущее устройство (master) инициирует установку связи с
SPI: последовательный периферийный интерфейс
Ведущее устройство (master) инициирует установку связи с

UART: универсальный асинхронный приемопередатчик
Параметры:
Стартовый бит (0), 7-8 бит данных, бит
UART: универсальный асинхронный приемопередатчик
Параметры:
Стартовый бит (0), 7-8 бит данных, бит

// Create specified ms/us of delay using built-in timer
#include
void delaymicros(int
// Create specified ms/us of delay using built-in timer
#include
void delaymicros(int

Необходим для взаимодействия с внешним миром
Аналоговый ввод: аналого-цифровое преобразование
Часто включено в
Необходим для взаимодействия с внешним миром
Аналоговый ввод: аналого-цифровое преобразование
Часто включено в
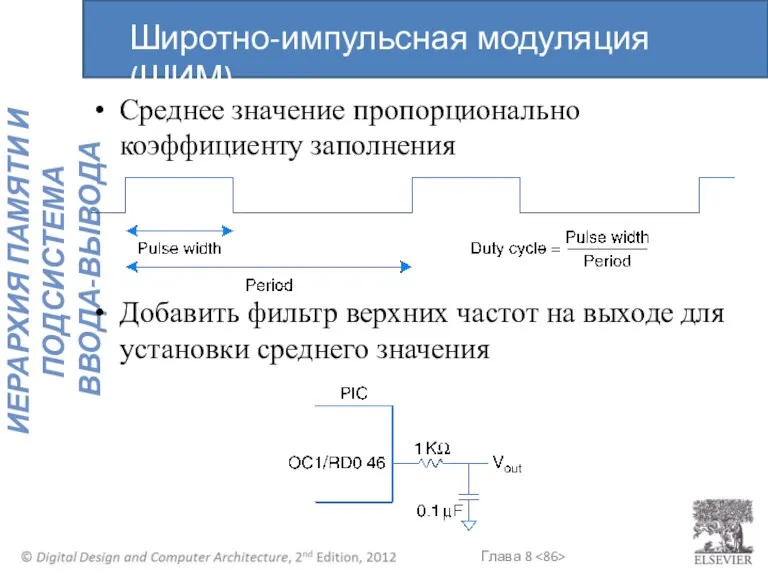
Широтно-импульсная модуляция (ШИМ)
Среднее значение пропорционально коэффициенту заполнения
Добавить фильтр верхних частот на
Широтно-импульсная модуляция (ШИМ)
Среднее значение пропорционально коэффициенту заполнения
Добавить фильтр верхних частот на

Другие внешние устройства микроконтроллера
Примеры
Символьный ЖК-дисплей
VGA монитор
Беспроводная связь Bluetooth
Двигатели
Другие внешние устройства микроконтроллера
Примеры
Символьный ЖК-дисплей
VGA монитор
Беспроводная связь Bluetooth
Двигатели

Подсистема ввода-вывода персональных компьютеров
Универсальная последовательная шина (англ. Universal Serial Bus, USB)
Подсистема ввода-вывода персональных компьютеров
Универсальная последовательная шина (англ. Universal Serial Bus, USB)
 Файлы и папки. 6 класс
Файлы и папки. 6 класс Дербес компьютер шығу тарихы
Дербес компьютер шығу тарихы Клас ScrollPane
Клас ScrollPane Основные положения информационных технологий
Основные положения информационных технологий Динамические структуры данных. Деревья
Динамические структуры данных. Деревья Разработка информационной системы на базе высокоскоростной компьютерной сети мясоперерабатывающий завода Кампамос
Разработка информационной системы на базе высокоскоростной компьютерной сети мясоперерабатывающий завода Кампамос Информационная модель лечебно-диагностического процесса
Информационная модель лечебно-диагностического процесса Яка небезпека очікує дітей в інтернеті
Яка небезпека очікує дітей в інтернеті Медиабезопасность в образовании
Медиабезопасность в образовании Передача информации. Схема передачи информации. Электронная почта
Передача информации. Схема передачи информации. Электронная почта Древо компьютерных наук
Древо компьютерных наук What’s the Internet
What’s the Internet Работа в текстовом редакторе Microsoft Word 2010. Редактирование текста
Работа в текстовом редакторе Microsoft Word 2010. Редактирование текста Процедуры и функции. Lambda function. *args, **kwargs в Python
Процедуры и функции. Lambda function. *args, **kwargs в Python Геймінг – це гра у відеоігри на колективних турнірах
Геймінг – це гра у відеоігри на колективних турнірах C++. Основные достоинства языка
C++. Основные достоинства языка Стратегии тестирования
Стратегии тестирования Мультимедийная презентация на тему: Алгоритм и исполнители
Мультимедийная презентация на тему: Алгоритм и исполнители Функциональное и доменное тестирование
Функциональное и доменное тестирование Тест. Экстремальное программирование
Тест. Экстремальное программирование Внеклассное мероприятия Компьютер –мой друг. 2 класс
Внеклассное мероприятия Компьютер –мой друг. 2 класс Защита информации
Защита информации Требования к разработке ПО
Требования к разработке ПО Рефлексия типов и программирование с использованием атрибутов. Лекция #6
Рефлексия типов и программирование с использованием атрибутов. Лекция #6 PR и работа со СМИ. Благотворительные гастроли
PR и работа со СМИ. Благотворительные гастроли Создание web-сайта. Коммуникационные технологии
Создание web-сайта. Коммуникационные технологии Сети передачи данных (урок 4)
Сети передачи данных (урок 4) Пособие по плаванию в сети Интернет (родителям)
Пособие по плаванию в сети Интернет (родителям)