- ТВ растр с чересстрочной разверткой. Система передачи данных

Содержание
- 2. Система передачи данных
- 5. Статистическое кодирование Сокращение избыточности информации без потерь
- 6. Типы избыточности статистическая избыточность, связанная с корреляцией и предсказуемостью данных; эта избыточность может быть устранена без
- 7. Меры избыточности Коэффициент сжатия CR = N2/N1 Среднее число бит на информационный символ При статистическом кодировании
- 8. Статистическая избыточность дискретных данных
- 9. Классификация методов статистического кодирования Три задачи статистического кодирования: построение информационной модели генерация кода хранение описания способа
- 10. Коды переменной длины Код переменной длины C отображает каждый символ ai алфавита X = {a1, …,
- 11. Коды переменной длины По определению, код C является однозначно декодируемым, если для любой последовательности символов источника
- 12. Методы представления целых чисел кодами переменной длины
- 13. Гамма- и дельта-коды Элиаса Для диапазона значений [2k, 2k+1-1] числа n коды формируются: - гамма-код: унарное
- 14. Коды Голомба и Райса Для кодирования символа с номером n необходимо представить этот номер в виде:
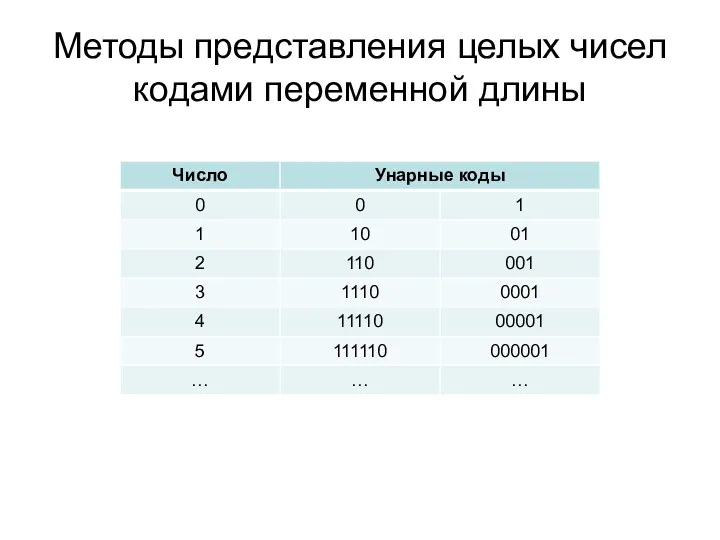
- 15. Омега-коды Элиаса и коды Ивен-Роде Коды состоят из последовательности групп длинной L1, L2, L3, …, Lm
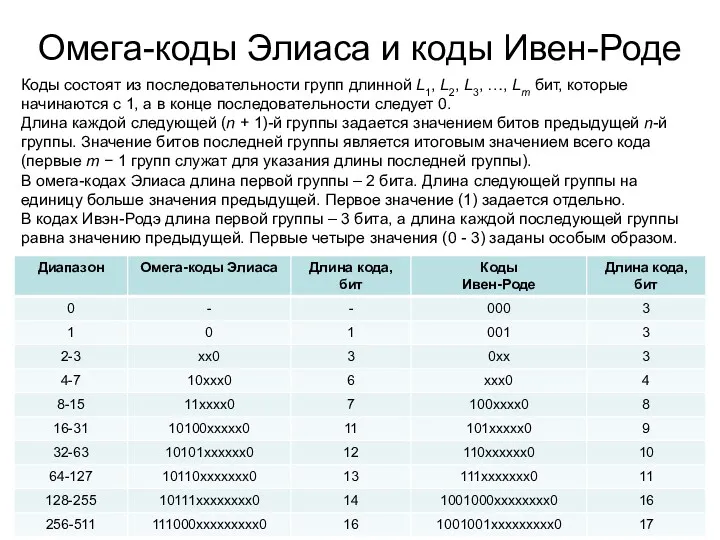
- 16. Коды Фибоначчи
- 17. Уникально-префиксные (безпрефиксные) коды если существует набор однозначно-декодируемых кодов с определенным множеством длин кодовых слов, то можно
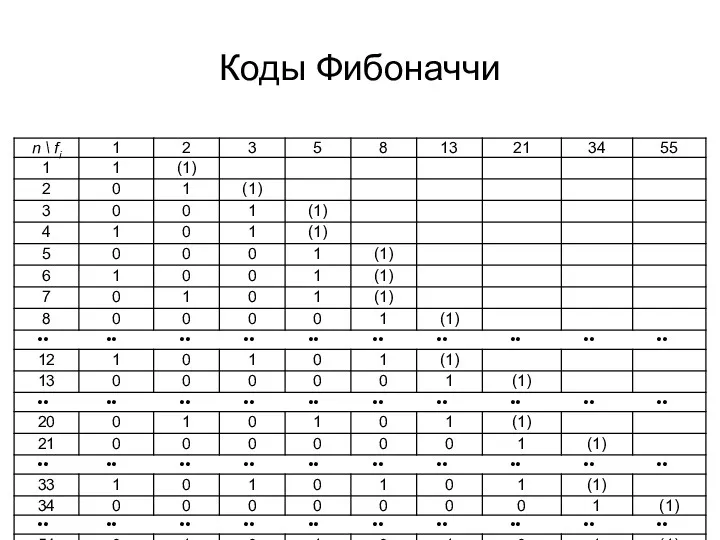
- 18. Двоичное кодовое дерево Уникально-префиксные коды однозначно декодируемы, но однозначно декодируемые коды не обязательно обладают уникальными префиксами.
- 19. Синхронизация кодов переменной длины При передаче кодов переменной длины в канале с ошибками декодер может потерять
- 20. Неравенство Крафта Неравенство Крафта описывает условия, определяющие возможность построения уникально-префиксных кодов для заданного алфавита X =
- 21. Неравенство Крафта Можно представить кодовые слова в виде двоичных дробей в двоичной системе счисления. Двоичная дробь
- 22. Коды Шеннона-Фано Зная вероятности символов, строят таблицу кодов, обладающую следующими свойствами: - различные коды имеют различное
- 23. Алгоритм Хаффмана
- 24. Блочное и условное кодирование
- 25. Арифметическое кодирование
- 26. Словарные методы кодирования Словарные методы энтропийного кодирования вместо вероятностного используют следующий подход: кодовые схемы используют коды
- 27. Словарное кодирование: LZ77 В скользящем окне помещается N символов, причем часть из них M = N
- 28. Словарное кодирование: LZ78
- 29. Словарное кодирование: LZW
- 30. Ассоциативное кодирование Буяновского Предположим, что уже закодирована последовательность ..111101011100001010010001010100101110 и предстоит закодировать строку 0100010111.., обозначенную далее
- 31. Ассоциативное кодирование Буяновского ..11110|1011100001010010001010100101110 ..1111010|11100001010010001010100101110 ..11110101110|0001010010001010100101110 ..111101011100|001010010001010100101110 ..1111010111000|01010010001010100101110 ..11110101110000|1010010001010100101110 ..1111010111000010|10010001010100101110 ..111101011100001010|010001010100101110 ..1111010111000010100|10001010100101110 ..111101011100001010010|001010100101110 ..1111010111000010100100|01010100101110 ..11110101110000101001000|1010100101110 ..1111010111000010100100010|10100101110
- 32. Ассоциативное кодирование Буяновского Полученные последовательности упорядочиваются по возрастанию лексикографического порядка предыстории. При этом анализируется последовательность символов
- 33. Ассоциативное кодирование Буяновского 15 ..11110101110000|1010010001010100101110 14 ..11110101110000101001000|1010100101110 13 ..1111010111000|01010010001010100101110 12 ..1111010111000010100100|01010100101110 11 ..1111010111000010100|10001010100101110 10 11101011100001010010001010100|101110 9
- 34. Ассоциативное кодирование Буяновского Затем этот список переупорядочивается в лексикографическом порядке постистории (в противоположном направлении - слева
- 35. Ассоциативное кодирование Буяновского В дальнейшем используются только две строки, примыкающие к пакуемой строке: 4 ..111101011100001010|010001010100101110 0
- 36. Ассоциативное кодирование Буяновского 3. Длина «вытяжки» (в терминологии автора алгоритма) – количество нулей или единиц в
- 38. Скачать презентацию
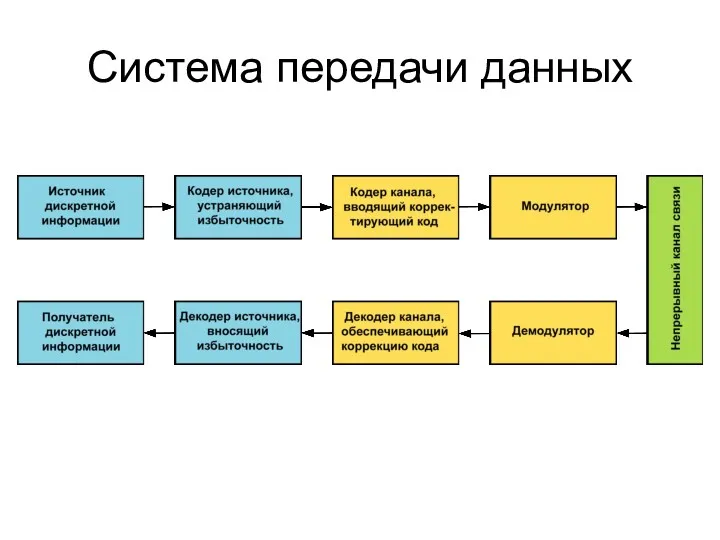
Система передачи данных
Система передачи данных

Статистическое кодирование
Сокращение избыточности информации без потерь
Статистическое кодирование
Сокращение избыточности информации без потерь

Типы избыточности
статистическая избыточность, связанная с корреляцией и предсказуемостью данных; эта избыточность
Типы избыточности
статистическая избыточность, связанная с корреляцией и предсказуемостью данных; эта избыточность

Меры избыточности
Коэффициент сжатия CR = N2/N1
Среднее число бит на информационный символ
При
Меры избыточности
Коэффициент сжатия CR = N2/N1
Среднее число бит на информационный символ
При

Статистическая избыточность дискретных данных
Статистическая избыточность дискретных данных
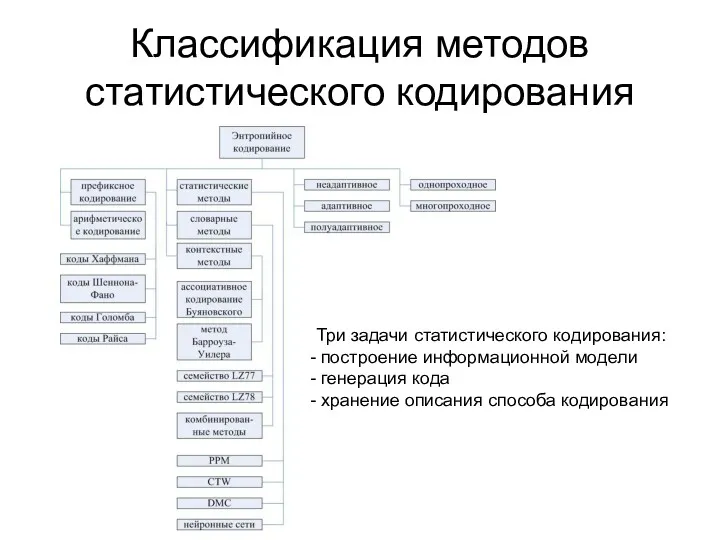
Классификация методов статистического кодирования
Три задачи статистического кодирования:
построение информационной модели
генерация
Классификация методов статистического кодирования
Три задачи статистического кодирования:
построение информационной модели
генерация

Коды переменной длины
Код переменной длины C отображает каждый символ ai алфавита
Коды переменной длины
Код переменной длины C отображает каждый символ ai алфавита

Коды переменной длины
По определению, код C является однозначно декодируемым, если для
Коды переменной длины
По определению, код C является однозначно декодируемым, если для
Методы представления целых чисел
кодами переменной длины
Методы представления целых чисел
кодами переменной длины
![Гамма- и дельта-коды Элиаса Для диапазона значений [2k, 2k+1-1] числа](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/276950/slide-12.jpg)
Гамма- и дельта-коды Элиаса
Для диапазона значений [2k, 2k+1-1] числа n коды
Гамма- и дельта-коды Элиаса
Для диапазона значений [2k, 2k+1-1] числа n коды

Коды Голомба и Райса
Для кодирования символа с номером n необходимо представить
Коды Голомба и Райса
Для кодирования символа с номером n необходимо представить
Омега-коды Элиаса и коды Ивен-Роде
Коды состоят из последовательности групп длинной L1,
Омега-коды Элиаса и коды Ивен-Роде
Коды состоят из последовательности групп длинной L1,
Коды Фибоначчи
Коды Фибоначчи

Уникально-префиксные (безпрефиксные) коды
если существует набор однозначно-декодируемых кодов с определенным множеством длин
Уникально-префиксные (безпрефиксные) коды
если существует набор однозначно-декодируемых кодов с определенным множеством длин
Двоичное кодовое дерево
Уникально-префиксные коды однозначно декодируемы, но однозначно декодируемые коды не
Двоичное кодовое дерево
Уникально-префиксные коды однозначно декодируемы, но однозначно декодируемые коды не

Синхронизация кодов переменной длины
При передаче кодов переменной длины в канале с
Синхронизация кодов переменной длины
При передаче кодов переменной длины в канале с

Неравенство Крафта
Неравенство Крафта описывает условия, определяющие возможность построения уникально-префиксных кодов для
Неравенство Крафта
Неравенство Крафта описывает условия, определяющие возможность построения уникально-префиксных кодов для

Неравенство Крафта
Можно представить кодовые слова в виде двоичных дробей в двоичной
Неравенство Крафта
Можно представить кодовые слова в виде двоичных дробей в двоичной

Коды Шеннона-Фано
Зная вероятности символов, строят таблицу кодов, обладающую
следующими свойствами:
- различные коды
Коды Шеннона-Фано
Зная вероятности символов, строят таблицу кодов, обладающую
следующими свойствами:
- различные коды

Алгоритм Хаффмана
Алгоритм Хаффмана

Блочное и условное кодирование
Блочное и условное кодирование
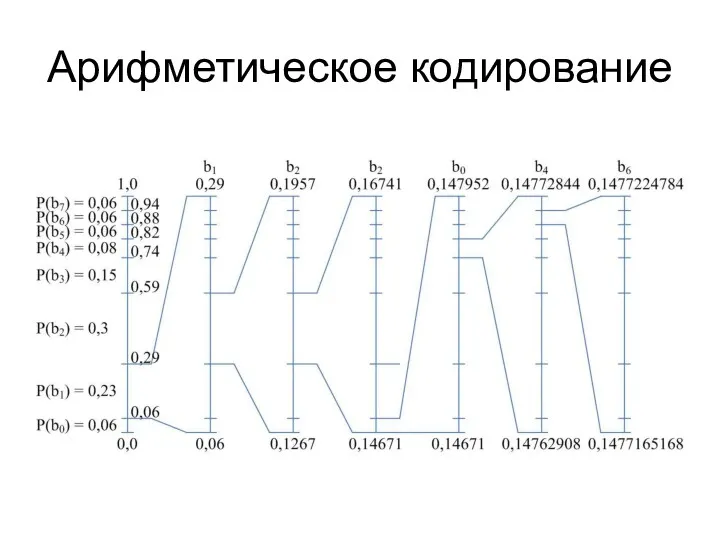
Арифметическое кодирование
Арифметическое кодирование

Словарные методы кодирования
Словарные методы энтропийного кодирования вместо вероятностного используют следующий подход:
Словарные методы кодирования
Словарные методы энтропийного кодирования вместо вероятностного используют следующий подход:
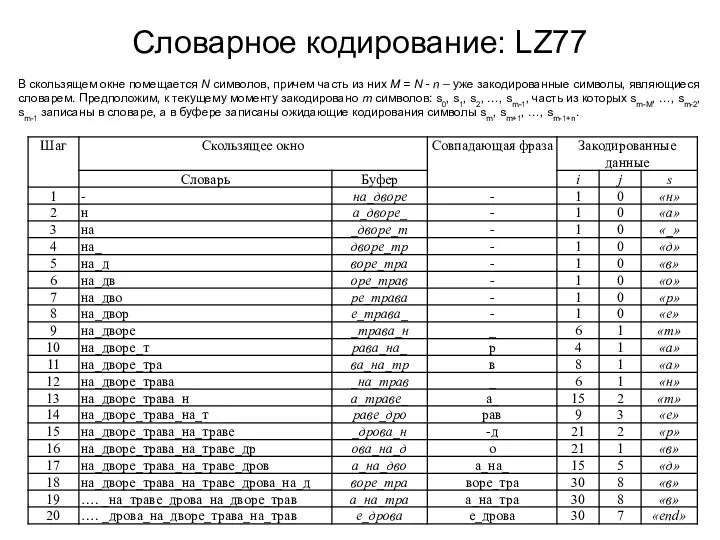
Словарное кодирование: LZ77
В скользящем окне помещается N символов, причем часть из
Словарное кодирование: LZ77
В скользящем окне помещается N символов, причем часть из
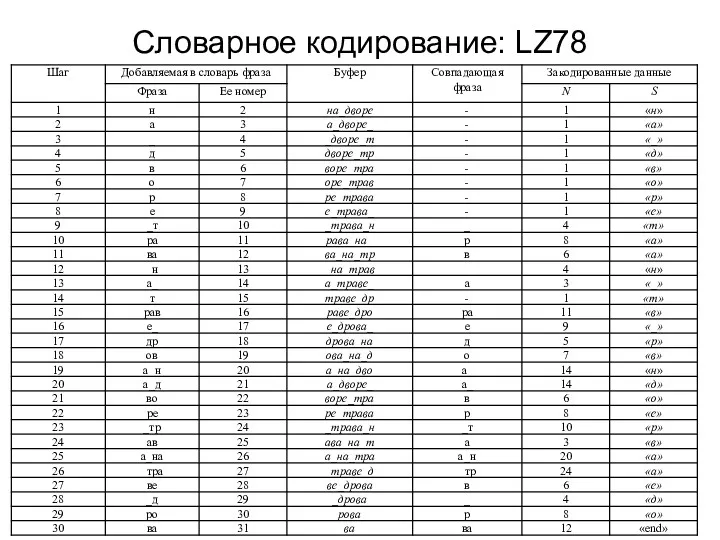
Словарное кодирование: LZ78
Словарное кодирование: LZ78
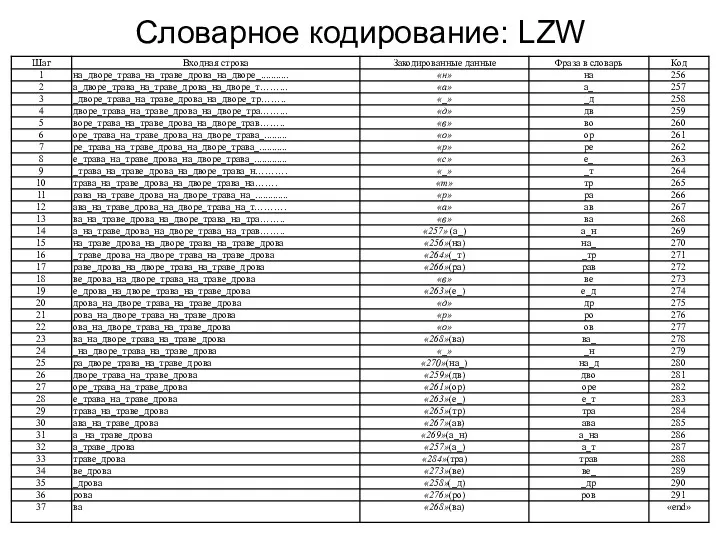
Словарное кодирование: LZW
Словарное кодирование: LZW

Ассоциативное кодирование Буяновского
Предположим, что уже закодирована последовательность
..111101011100001010010001010100101110
и предстоит закодировать строку
0100010111.., обозначенную
Ассоциативное кодирование Буяновского
Предположим, что уже закодирована последовательность
..111101011100001010010001010100101110
и предстоит закодировать строку
0100010111.., обозначенную

Ассоциативное кодирование Буяновского
..11110|1011100001010010001010100101110
..1111010|11100001010010001010100101110
..11110101110|0001010010001010100101110
..111101011100|001010010001010100101110
..1111010111000|01010010001010100101110
..11110101110000|1010010001010100101110
..1111010111000010|10010001010100101110
..111101011100001010|010001010100101110
..1111010111000010100|10001010100101110
..111101011100001010010|001010100101110
..1111010111000010100100|01010100101110
..11110101110000101001000|1010100101110
..1111010111000010100100010|10100101110
..111101011100001010010001010|100101110
..11110101110000101001000101010|0101110
..111101011100001010010001010100|101110
..11110101110000101001000101010010|1110
..111101011100001010010001010100101110|0100010111..
Максимальная длина предыстории ограничивается некоторым числом N.
Ассоциативное кодирование Буяновского
..11110|1011100001010010001010100101110
..1111010|11100001010010001010100101110
..11110101110|0001010010001010100101110
..111101011100|001010010001010100101110
..1111010111000|01010010001010100101110
..11110101110000|1010010001010100101110
..1111010111000010|10010001010100101110
..111101011100001010|010001010100101110
..1111010111000010100|10001010100101110
..111101011100001010010|001010100101110
..1111010111000010100100|01010100101110
..11110101110000101001000|1010100101110
..1111010111000010100100010|10100101110
..111101011100001010010001010|100101110
..11110101110000101001000101010|0101110
..111101011100001010010001010100|101110
..11110101110000101001000101010010|1110
..111101011100001010010001010100101110|0100010111..
Максимальная длина предыстории ограничивается некоторым числом N.

Ассоциативное кодирование Буяновского
Полученные последовательности упорядочиваются по возрастанию лексикографического порядка предыстории. При
Ассоциативное кодирование Буяновского
Полученные последовательности упорядочиваются по возрастанию лексикографического порядка предыстории. При

Ассоциативное кодирование Буяновского
15 ..11110101110000|1010010001010100101110
14 ..11110101110000101001000|1010100101110
13 ..1111010111000|01010010001010100101110
12 ..1111010111000010100100|01010100101110
11 ..1111010111000010100|10001010100101110
10 11101011100001010010001010100|101110
9 ..111101011100|001010010001010100101110
Ассоциативное кодирование Буяновского
15 ..11110101110000|1010010001010100101110
14 ..11110101110000101001000|1010100101110
13 ..1111010111000|01010010001010100101110
12 ..1111010111000010100100|01010100101110
11 ..1111010111000010100|10001010100101110
10 11101011100001010010001010100|101110
9 ..111101011100|001010010001010100101110

Ассоциативное кодирование Буяновского
Затем этот список переупорядочивается в лексикографическом порядке постистории (в
Ассоциативное кодирование Буяновского
Затем этот список переупорядочивается в лексикографическом порядке постистории (в

Ассоциативное кодирование Буяновского
В дальнейшем используются только две строки, примыкающие к пакуемой
Ассоциативное кодирование Буяновского
В дальнейшем используются только две строки, примыкающие к пакуемой

Ассоциативное кодирование Буяновского
3. Длина «вытяжки» (в терминологии автора алгоритма) – количество
Ассоциативное кодирование Буяновского
3. Длина «вытяжки» (в терминологии автора алгоритма) – количество
 Организация файлового сервера в сети предприятия АО САЗ и его администрирование
Организация файлового сервера в сети предприятия АО САЗ и его администрирование Информационные технологии. Лекция 1. Введение
Информационные технологии. Лекция 1. Введение Информационные технологии в юридической деятельности
Информационные технологии в юридической деятельности Браузеры. Наиболее популярные браузеры
Браузеры. Наиболее популярные браузеры Упрощенный приём отправлений (инструкция v.1)
Упрощенный приём отправлений (инструкция v.1) Positive and negative effects of computers
Positive and negative effects of computers Социальные сети и их возможности
Социальные сети и их возможности Поколение - Z. Школа Блогеров
Поколение - Z. Школа Блогеров Разработка информационной системы многоуровневой поддержки отделом информационных технологий
Разработка информационной системы многоуровневой поддержки отделом информационных технологий Строковые алгоритмы
Строковые алгоритмы Файлы и файловая система
Файлы и файловая система Лекция 1. Основы компьютерных сетей. История развития
Лекция 1. Основы компьютерных сетей. История развития Компьютерные технологии интеллектуальной поддержки управленческих решений
Компьютерные технологии интеллектуальной поддержки управленческих решений Управление доступом к ресурсам. Лекция 4
Управление доступом к ресурсам. Лекция 4 Основы трехмерного моделирования в Компас 3D
Основы трехмерного моделирования в Компас 3D How to Update Norton Antivirus
How to Update Norton Antivirus Проблемы с реализацией ФГИС
Проблемы с реализацией ФГИС Глобальная сеть - Интернет
Глобальная сеть - Интернет Автоматизация рабочего места секретаря директора школы
Автоматизация рабочего места секретаря директора школы Информационная картина мира.
Информационная картина мира. Технология поиска информации в сети Интернет
Технология поиска информации в сети Интернет Занимательные задачки
Занимательные задачки Основы SQL. Практическое применение
Основы SQL. Практическое применение Носители информации (5 класс)
Носители информации (5 класс) Основи інформаційної безпеки. Основи захисту даних в комп’ютерних системах. 9 клас
Основи інформаційної безпеки. Основи захисту даних в комп’ютерних системах. 9 клас ВКР: Процесс миграции виртуальных машин в облачных центрах обработки данных с использованием методов машинного обучения
ВКР: Процесс миграции виртуальных машин в облачных центрах обработки данных с использованием методов машинного обучения C# Collections. Generic Collections
C# Collections. Generic Collections Поставки - продаж непродовольчих товарів. База даних
Поставки - продаж непродовольчих товарів. База даних