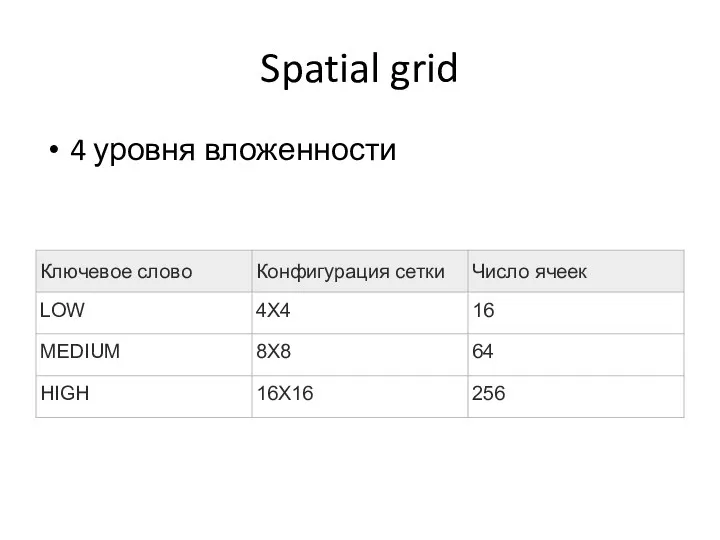
- Виды индексов:

Содержание
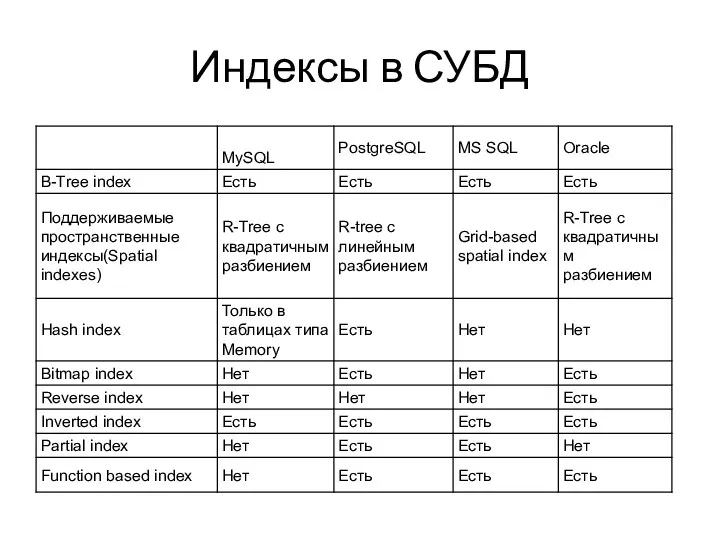
- 2. Индексы в СУБД
- 3. Поиск с использованием индекса SELECT * FROM customers WHERE email_address='vassya@spbu.ru' + SELECT * FROM customers WHERE
- 4. Reverse index SELECT email_address FROM customers WHERE email_address LIKE '%@yahoo.com'. CREATE INDEX test_indexi ON customers (email_address)
- 5. Reverse index Reverse index – это тоже B-tree индекс но с реверсированным ключом, используемый в основном
- 6. Reverse index
- 7. Поиск документов по содержащимся в них словам WHERE Field1 like ‘алгоритм%’ Использует индекс WHERE Field1 like
- 8. Inverted index Документ (текстовое поле) – это последовательность слов D1: w1 w2 w3 w1 w4 w2
- 9. Поиск документов по содержащимся в них словам W1: d1 d2 d3 W2: d1 d3 W3: d1
- 10. Для FULL TEXT индекса Выбрать столбцы таблицы или индексированного представления Построить для таблицы индекс по одному
- 11. Полнотекстовый индекс FULLTEXT В полнотекстовый индекс включается один или несколько символьных столбцов в таблице. Эти столбцы
- 12. Процесс индексирования Создание полнотекстового каталога Создание полнотекстового индекса Заполнение полнотекстового индекса
- 13. Создание каталога CREATE FULLTEXT CATALOG catalog_name Полнотекстовый каталог — это логическое понятие, обозначающее группу полнотекстовых индексов.
- 14. Создание полнотекстового каталога Полнотекстовый каталог — это логическое понятие, обозначающее группу полнотекстовых индексов. CREATE FULLTEXT CATALOG
- 15. Создание полнотекстового индекса CREATE FULLTEXT INDEX ON customers (email_address) KEY INDEX ui_1 ON test_catalog
- 16. Создание FULL TEXT индекса CREATE FULLTEXT INDEX ON table_name [ ( { column_name [ TYPE COLUMN
- 17. Создание полнотекстового индекса CREATE FULLTEXT INDEX ON customers ( email_address language 1033 , cust_name language 1049)
- 18. Полнотекстовый индекс
- 19. Процесс полнотекстового индексирования Фильтрацию, разбиение по словам Удаление стоп-слов и нормализация токенов Преобразует конвертированные данные в
- 20. Заполнение индекса значениями (обновление) MANUAL – вручную ALTER FULLTEXT INDEX ON customers START FULL POPULATION AUTO
- 21. Список стоп-слов По умолчанию индекс сопоставляется с системным стоп-листом “system”, по этому стоп-листу не будут находиться
- 22. Список стоп-слов CREATE FULLTEXT STOPLIST myStoplist [FROM SYSTEM STOPLIST]; ALTER FULLTEXT STOPLIST MyStoplist ADD 'en' LANGUAGE
- 23. Обработка полнотекстовых запросов разбиение по словам расширение тезауруса морфологический поиск обработка стоп-слов поиск в индексе ранжирование
- 24. Поиск в полнотекстовом индексе В полнотекстовых запросах не учитывается регистр букв. Все полнотекстовые запросы используют предикаты
- 25. Запросы с полнотекстовым индексом: Самый простой способ – это использование freetext и CONTAINS select * from
- 26. CONTAINS Предикат, используемый в предложении WHERE для и проверки точного или нечеткого совпадения с отдельными словами,
- 27. FREETEXT Этот предикат используется в предложении WHERE для поиска значений, которые соответствуют условию поиска по смыслу,
- 28. Виды запросов Простое выражение. Префиксные выражения. Производное выражение. Выражения с учетом расположения. Синонимы. Взвешенное выражение.
- 29. Простое выражение Одно или несколько конкретных слов или фраз в одном или нескольких столбцах. { AND
- 30. Префиксные выражения Слова, начинающиеся заданным текстом, или фразы с такими словами. … CONTAINS(Comments, ' ужасн*'); …
- 31. Префиксные выражения Если параметр является фразой, то каждое содержащееся во фразе слово считается отдельным префиксом. "local
- 32. Выражения с учетом расположения Слова или фразы, находящиеся рядом с другими словами или фразами. CONTAINS(*,‘NEAR (значение,
- 33. Выражения с учетом расположения NEAR ( { search_term [ ,…n ] |(search_term [ ,…n ] )
- 34. FREETEXT Разбивает строку на отдельные слова согласно границам слов (пословное разбиение). Формирует словоформы (а также производит
- 35. FREETEXT Словоформы конкретного слова. Синонимические формы конкретного слова. SELECT * FROM t3 WHERE freetext(s,'рама')
- 36. Взвешенное выражение Слова или фразы со взвешенными значениями () SELECT * from CONTAINSTABLE ( table3 –имя
- 37. Полнотекстовый индекс FULLTEXT Загрузка данных в таблицу, уже имеющую индекс FULLTEXT, будет более медленной.
- 38. Индексы на основе битовых карт Подходят для столбцов с низкой избирательностью. Создаются быстро. Занимают мало места.
- 39. Индексы на основе битовых карт create bitmap index ind_4 on table_1(field1) В индекс входят: Для каждого
- 40. Индексы на основе битовых карт
- 41. create bitmap index ind_4 on table_1(рост): Высокий 0010001000 Средний 1101110100 Ниже среднего 0000000011
- 42. create bitmap index ind_5 on table_1(Цвет волос): Блондинка 1100010000 Шатенка 0010000100 Брюнетка 0000101001 Рыжая 0001000010
- 43. Блондинка среднего роста: Блондинка 1100010000 Средний 1101110100 Побитовое умножение 1100010000
- 44. Появилась Мальвина: Блондинка 1100010000 Шатенка 0010000100 Брюнетка 0000101001 Рыжая 0001000010 Голубые волосы 00000000001
- 45. Индексы на основе битовых карт Индексы на основе битовых карт обычно выбираются стоимостным оптимизатором, если для
- 46. Hash-индекс Выбираем количество участков, в которых будем размещать записи. Подбираем функцию перемешивания, которая от ключевого столбца
- 47. Создание hash-индекса CREATE INDEX имя_индекса USING HASH ON имя_таблицы (имя_столбца)
- 49. Hash-индекс Для размещения таблицы отводится заданное количество участков Есть функция hash(key)=n, где n – номер участка
- 50. Недостатки hash-индексов Таблица адресов участков может быть слишком велика Если в один участок попало слишком много
- 51. Коллизии
- 52. Функции Hash Деление Мультипликативный метод
- 53. Функции Hash деление Размер таблицы hashTableSize - простое число. Хеширующее значение hashValue, изменяющееся от 0 до
- 54. Функции Hash мультипликативный метод Размер таблицы hashTableSize есть степень 2n. Значение key умножается на константу, затем
- 55. Функции Hash для строк переменной длины Аддитивный метод – преобразовываем слова в числа, складываем и берем
- 58. Пространственные типы данных geometry используется для планарных или евклидовых данных geography, который используется для хранения эллиптических
- 59. Пространственные типы данных geometry используется для планарных или евклидовых данных geography, который используется для хранения эллиптических
- 60. Пространственные типы данных Point MultiPoint LineString MultiLineString Polygon
- 61. R-дерево Избавляемся от формы – окружаем фигуру min ограничивающим прямоугольником (oid, Rectangle), oid – ссылка на
- 62. Иерархия R-дерева Окружаем фигуры ограничивающими прямоугольниками (cp, Rectangle) При переполнении делим пополам
- 63. R-дерево
- 64. R-дерево - недостатки Не удается избежать перекрытий – необходим просмотр нескольких веток
- 65. Критерии разделения узла Минимальная площадь Минимальное перекрытие Минимальные границы
- 66. Минимальная площадь
- 67. Минимальное перекрытие
- 68. Минимальные границы
- 69. Spatial grid
- 70. Spatial grid CREATE SPATIAL INDEX GEOMETRY_GRID | GEOGRAPHY_GRID BOUNDING_BOX (для GEOMETRY_GRID) xmin, ymin, xmax, ymax GRIDS
- 71. Spatial grid 4 уровня вложенности
- 72. Spatial grid CREATE SPATIAL INDEX SIndx ON SpatialTable(geometry_col) WITH ( BOUNDING_BOX = ( 0, 0, 500,
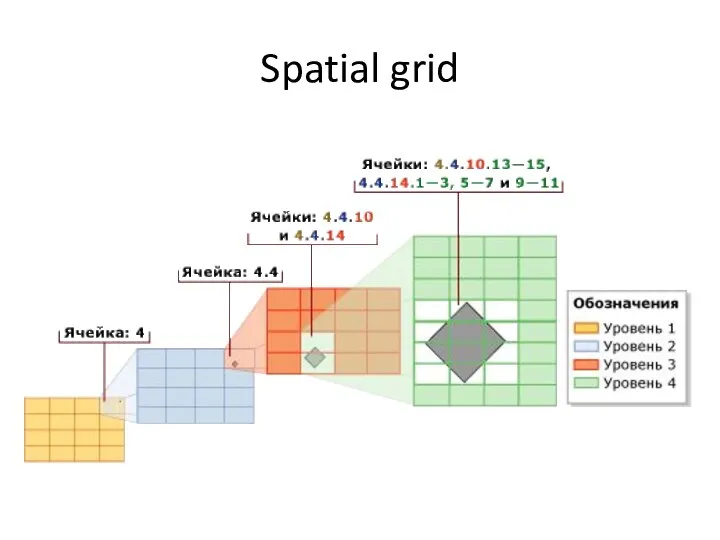
- 73. Spatial grid
- 74. Тесселяция Декомпозиция индексированного пространства в cеточную иерархию Считывание данных для пространственного объекта по строкам Вставка объекта
- 76. Скачать презентацию
Индексы в СУБД
Индексы в СУБД

Поиск с использованием индекса
SELECT * FROM customers WHERE email_address='vassya@spbu.ru' +
SELECT *
Поиск с использованием индекса
SELECT * FROM customers WHERE email_address='vassya@spbu.ru' +
SELECT *

Reverse index
SELECT email_address FROM customers WHERE email_address LIKE '%@yahoo.com'.
CREATE INDEX test_indexi
Reverse index
SELECT email_address FROM customers WHERE email_address LIKE '%@yahoo.com'.
CREATE INDEX test_indexi

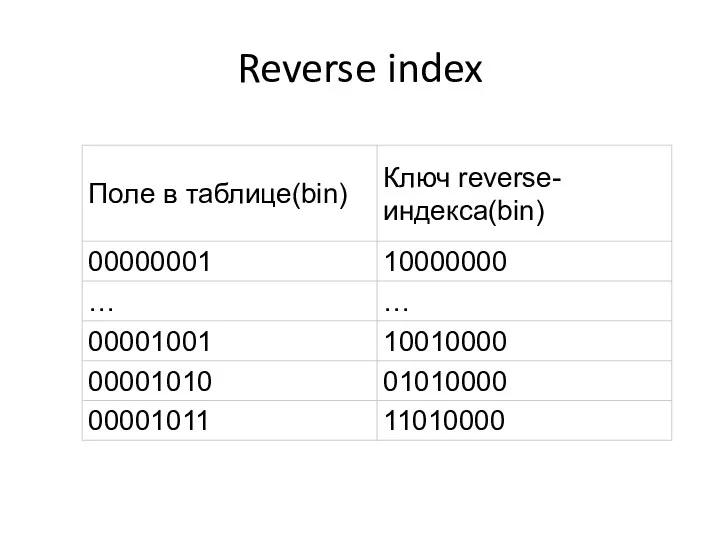
Reverse index
Reverse index – это тоже B-tree индекс но с реверсированным
Reverse index
Reverse index – это тоже B-tree индекс но с реверсированным
Reverse index
Reverse index

Поиск документов по содержащимся в них словам
WHERE Field1 like ‘алгоритм%’
Использует индекс
WHERE
Поиск документов по содержащимся в них словам
WHERE Field1 like ‘алгоритм%’
Использует индекс
WHERE

Inverted index
Документ (текстовое поле) – это последовательность слов
D1: w1 w2 w3
Inverted index
Документ (текстовое поле) – это последовательность слов
D1: w1 w2 w3

Поиск документов по содержащимся в них словам
W1: d1 d2 d3
W2: d1
Поиск документов по содержащимся в них словам
W1: d1 d2 d3
W2: d1

Для FULL TEXT индекса
Выбрать столбцы таблицы или индексированного представления
Построить для таблицы
Для FULL TEXT индекса
Выбрать столбцы таблицы или индексированного представления
Построить для таблицы

Полнотекстовый индекс FULLTEXT
В полнотекстовый индекс включается один или несколько символьных столбцов
Полнотекстовый индекс FULLTEXT
В полнотекстовый индекс включается один или несколько символьных столбцов

Процесс индексирования
Создание полнотекстового каталога
Создание полнотекстового индекса
Заполнение полнотекстового индекса
Процесс индексирования
Создание полнотекстового каталога
Создание полнотекстового индекса
Заполнение полнотекстового индекса

Создание каталога
CREATE FULLTEXT CATALOG catalog_name
Полнотекстовый каталог — это логическое понятие, обозначающее
Создание каталога
CREATE FULLTEXT CATALOG catalog_name
Полнотекстовый каталог — это логическое понятие, обозначающее

Создание полнотекстового каталога
Полнотекстовый каталог — это логическое понятие, обозначающее группу полнотекстовых
Создание полнотекстового каталога
Полнотекстовый каталог — это логическое понятие, обозначающее группу полнотекстовых

Создание полнотекстового индекса
CREATE FULLTEXT INDEX ON
customers (email_address)
KEY INDEX ui_1 ON
Создание полнотекстового индекса
CREATE FULLTEXT INDEX ON customers (email_address) KEY INDEX ui_1 ON

Создание FULL TEXT индекса
CREATE FULLTEXT INDEX ON table_name
[ ( {
Создание FULL TEXT индекса
CREATE FULLTEXT INDEX ON table_name
[ ( {

Создание полнотекстового индекса
CREATE FULLTEXT INDEX ON
customers (
email_address language 1033
, cust_name
Создание полнотекстового индекса
CREATE FULLTEXT INDEX ON customers ( email_address language 1033 , cust_name

Полнотекстовый индекс
Полнотекстовый индекс

Процесс полнотекстового индексирования
Фильтрацию, разбиение по словам
Удаление стоп-слов и нормализация токенов
Преобразует
Процесс полнотекстового индексирования
Фильтрацию, разбиение по словам
Удаление стоп-слов и нормализация токенов
Преобразует

Заполнение индекса значениями (обновление)
MANUAL – вручную
ALTER FULLTEXT INDEX ON customers
START FULL POPULATION
AUTO
автоматически, но
Заполнение индекса значениями (обновление)
MANUAL – вручную
ALTER FULLTEXT INDEX ON customers
START FULL POPULATION
AUTO
автоматически, но

Список стоп-слов
По умолчанию индекс сопоставляется с системным стоп-листом “system”, по этому
Список стоп-слов
По умолчанию индекс сопоставляется с системным стоп-листом “system”, по этому
![Список стоп-слов CREATE FULLTEXT STOPLIST myStoplist [FROM SYSTEM STOPLIST]; ALTER](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/326311/slide-21.jpg)
Список стоп-слов
CREATE FULLTEXT STOPLIST myStoplist
[FROM SYSTEM STOPLIST];
ALTER FULLTEXT STOPLIST MyStoplist
Список стоп-слов
CREATE FULLTEXT STOPLIST myStoplist
[FROM SYSTEM STOPLIST];
ALTER FULLTEXT STOPLIST MyStoplist

Обработка полнотекстовых запросов
разбиение по словам
расширение тезауруса
морфологический поиск
обработка стоп-слов
поиск в индексе
ранжирование
Обработка полнотекстовых запросов
разбиение по словам
расширение тезауруса
морфологический поиск
обработка стоп-слов
поиск в индексе
ранжирование

Поиск в полнотекстовом индексе
В полнотекстовых запросах не учитывается регистр букв.
Все
Поиск в полнотекстовом индексе
В полнотекстовых запросах не учитывается регистр букв.
Все

Запросы с полнотекстовым индексом:
Самый простой способ – это использование freetext и
Запросы с полнотекстовым индексом:
Самый простой способ – это использование freetext и

CONTAINS
Предикат, используемый в предложении WHERE для и проверки точного или нечеткого
CONTAINS
Предикат, используемый в предложении WHERE для и проверки точного или нечеткого

FREETEXT
Этот предикат используется в предложении WHERE для поиска значений, которые соответствуют
FREETEXT
Этот предикат используется в предложении WHERE для поиска значений, которые соответствуют

Виды запросов
Простое выражение.
Префиксные выражения.
Производное выражение.
Выражения с учетом расположения.
Синонимы.
Взвешенное выражение.
Виды запросов
Простое выражение.
Префиксные выражения.
Производное выражение.
Выражения с учетом расположения.
Синонимы.
Взвешенное выражение.

Простое выражение
Одно или несколько конкретных слов или фраз в одном или
Простое выражение
Одно или несколько конкретных слов или фраз в одном или

Префиксные выражения
Слова, начинающиеся заданным текстом, или фразы с такими словами.
… CONTAINS(Comments,
Префиксные выражения
Слова, начинающиеся заданным текстом, или фразы с такими словами.
… CONTAINS(Comments,

Префиксные выражения
Если параметр является фразой, то каждое содержащееся во фразе слово
Префиксные выражения
Если параметр является фразой, то каждое содержащееся во фразе слово

Выражения с учетом расположения
Слова или фразы, находящиеся рядом с другими словами
Выражения с учетом расположения
Слова или фразы, находящиеся рядом с другими словами

Выражения с учетом расположения
NEAR ( { search_term [ ,…n ] |(search_term [ ,…n ] ) [, [, ] ]
CONTAINS(column_name, 'NEAR
Выражения с учетом расположения
NEAR ( { search_term [ ,…n ] |(search_term [ ,…n ] ) [,
CONTAINS(column_name, 'NEAR

FREETEXT
Разбивает строку на отдельные слова согласно границам слов (пословное разбиение).
Формирует словоформы
FREETEXT
Разбивает строку на отдельные слова согласно границам слов (пословное разбиение).
Формирует словоформы

FREETEXT
Словоформы конкретного слова.
Синонимические формы конкретного слова.
SELECT * FROM t3 WHERE freetext(s,'рама')
FREETEXT
Словоформы конкретного слова.
Синонимические формы конкретного слова.
SELECT * FROM t3 WHERE freetext(s,'рама')

Взвешенное выражение
Слова или фразы со взвешенными значениями ()
SELECT * from CONTAINSTABLE
Взвешенное выражение
Слова или фразы со взвешенными значениями ()
SELECT * from CONTAINSTABLE

Полнотекстовый индекс FULLTEXT
Загрузка данных в таблицу, уже имеющую индекс FULLTEXT,
Полнотекстовый индекс FULLTEXT
Загрузка данных в таблицу, уже имеющую индекс FULLTEXT,

Индексы на основе битовых карт
Подходят для столбцов с низкой избирательностью.
Создаются быстро.
Занимают
Индексы на основе битовых карт
Подходят для столбцов с низкой избирательностью.
Создаются быстро.
Занимают

Индексы на основе битовых карт
create bitmap index ind_4 on table_1(field1)
В индекс
Индексы на основе битовых карт
create bitmap index ind_4 on table_1(field1)
В индекс
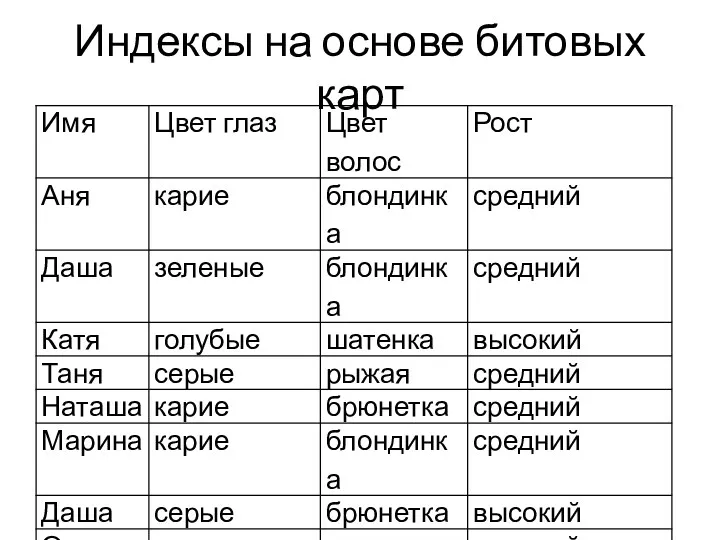
Индексы на основе битовых карт
Индексы на основе битовых карт

create bitmap index ind_4 on table_1(рост):
Высокий 0010001000
Средний 1101110100
Ниже среднего 0000000011
create bitmap index ind_4 on table_1(рост):
Высокий 0010001000
Средний 1101110100
Ниже среднего 0000000011

create bitmap index ind_5 on table_1(Цвет волос):
Блондинка 1100010000
Шатенка 0010000100
Брюнетка 0000101001
Рыжая 0001000010
create bitmap index ind_5 on table_1(Цвет волос):
Блондинка 1100010000
Шатенка 0010000100
Брюнетка 0000101001
Рыжая 0001000010

Блондинка среднего роста:
Блондинка 1100010000
Средний 1101110100
Побитовое умножение 1100010000
Блондинка среднего роста:
Блондинка 1100010000
Средний 1101110100
Побитовое умножение 1100010000

Появилась Мальвина:
Блондинка 1100010000
Шатенка 0010000100
Брюнетка 0000101001
Рыжая 0001000010
Голубые волосы 00000000001
Появилась Мальвина:
Блондинка 1100010000
Шатенка 0010000100
Брюнетка 0000101001
Рыжая 0001000010
Голубые волосы 00000000001

Индексы на основе битовых карт
Индексы на основе битовых карт обычно выбираются
Индексы на основе битовых карт
Индексы на основе битовых карт обычно выбираются

Hash-индекс
Выбираем количество участков, в которых будем размещать записи.
Подбираем функцию перемешивания, которая
Hash-индекс
Выбираем количество участков, в которых будем размещать записи.
Подбираем функцию перемешивания, которая

Создание hash-индекса
CREATE INDEX имя_индекса USING HASH
ON имя_таблицы (имя_столбца)
Создание hash-индекса
CREATE INDEX имя_индекса USING HASH
ON имя_таблицы (имя_столбца)
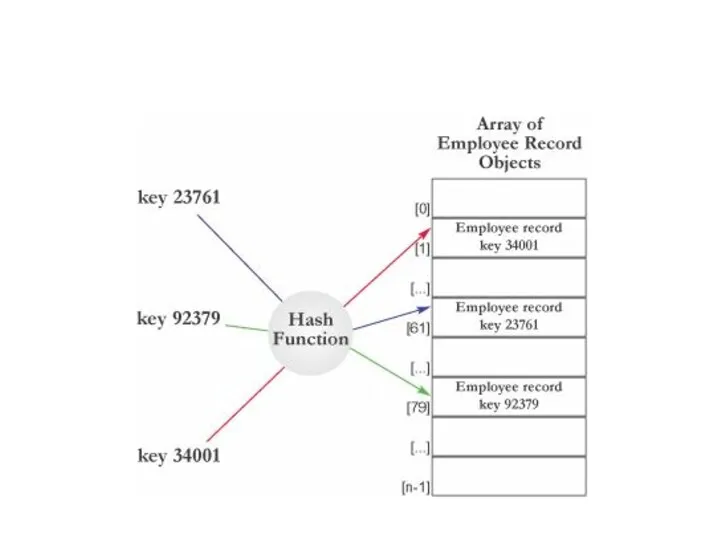

Hash-индекс
Для размещения таблицы отводится заданное количество участков
Есть функция hash(key)=n, где
Hash-индекс
Для размещения таблицы отводится заданное количество участков
Есть функция hash(key)=n, где

Недостатки hash-индексов
Таблица адресов участков может быть слишком велика
Если в один участок
Недостатки hash-индексов
Таблица адресов участков может быть слишком велика
Если в один участок
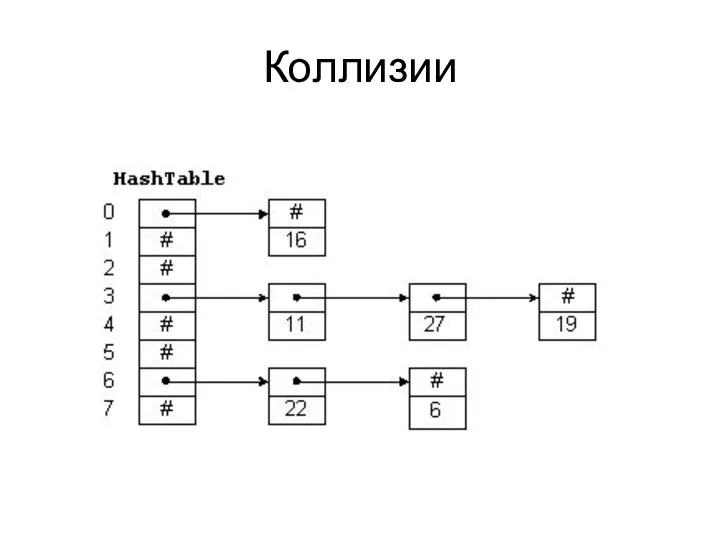
Коллизии
Коллизии

Функции Hash
Деление
Мультипликативный метод
Функции Hash
Деление
Мультипликативный метод

Функции Hash деление
Размер таблицы hashTableSize - простое число.
Хеширующее значение hashValue,
Функции Hash деление
Размер таблицы hashTableSize - простое число.
Хеширующее значение hashValue,

Функции Hash мультипликативный метод
Размер таблицы hashTableSize есть степень 2n.
Значение
Функции Hash мультипликативный метод
Размер таблицы hashTableSize есть степень 2n.
Значение

Функции Hash
для строк переменной длины
Аддитивный метод – преобразовываем слова в
Функции Hash
для строк переменной длины
Аддитивный метод – преобразовываем слова в

Пространственные типы данных
geometry используется для планарных или евклидовых данных
geography, который используется
Пространственные типы данных
geometry используется для планарных или евклидовых данных
geography, который используется

Пространственные типы данных
geometry используется для планарных или евклидовых данных
geography, который используется
Пространственные типы данных
geometry используется для планарных или евклидовых данных
geography, который используется
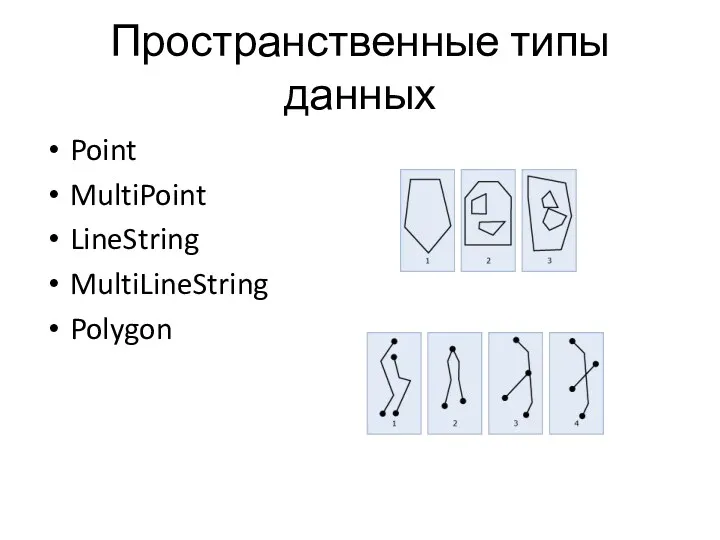
Пространственные типы данных
Point
MultiPoint
LineString
MultiLineString
Polygon
Пространственные типы данных
Point
MultiPoint
LineString
MultiLineString
Polygon
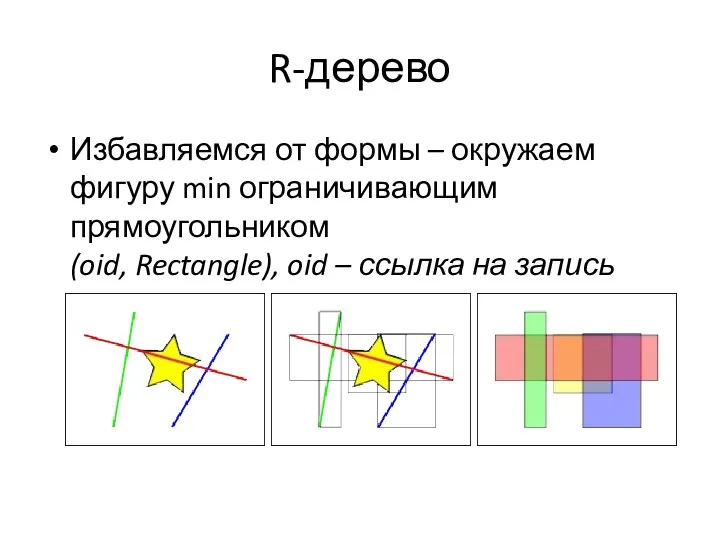
R-дерево
Избавляемся от формы – окружаем фигуру min ограничивающим прямоугольником
(oid, Rectangle), oid
R-дерево
Избавляемся от формы – окружаем фигуру min ограничивающим прямоугольником (oid, Rectangle), oid
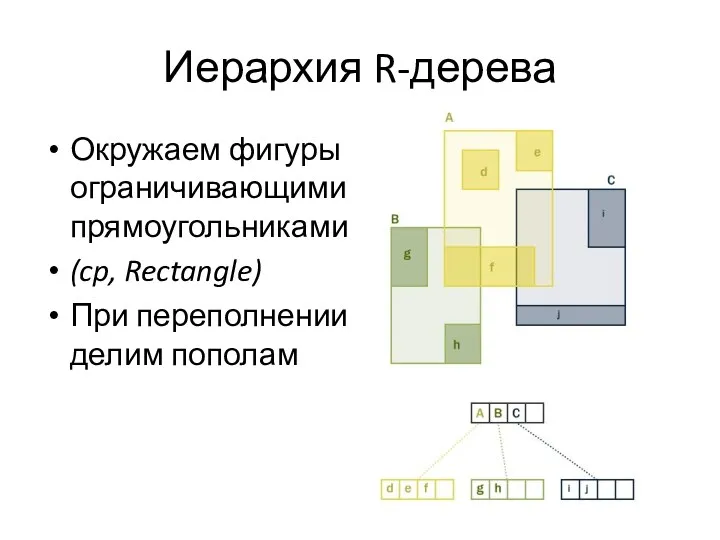
Иерархия R-дерева
Окружаем фигуры
ограничивающими
прямоугольниками
(cp, Rectangle)
При переполнении
делим пополам
Иерархия R-дерева
Окружаем фигуры
ограничивающими
прямоугольниками
(cp, Rectangle)
При переполнении
делим пополам
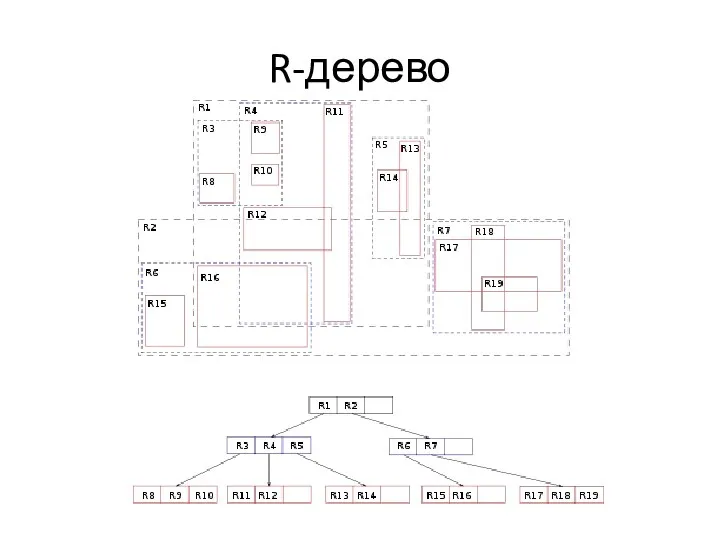
R-дерево
R-дерево

R-дерево - недостатки
Не удается избежать перекрытий – необходим просмотр нескольких веток
R-дерево - недостатки
Не удается избежать перекрытий – необходим просмотр нескольких веток
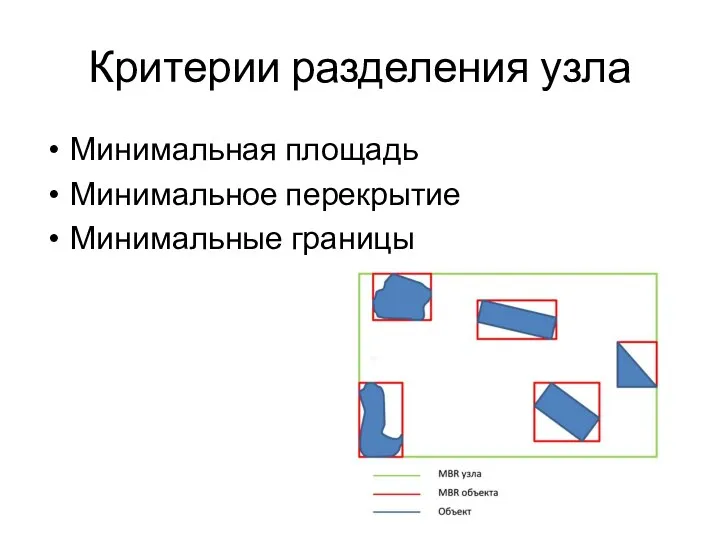
Критерии разделения узла
Минимальная площадь
Минимальное перекрытие
Минимальные границы
Критерии разделения узла
Минимальная площадь
Минимальное перекрытие
Минимальные границы
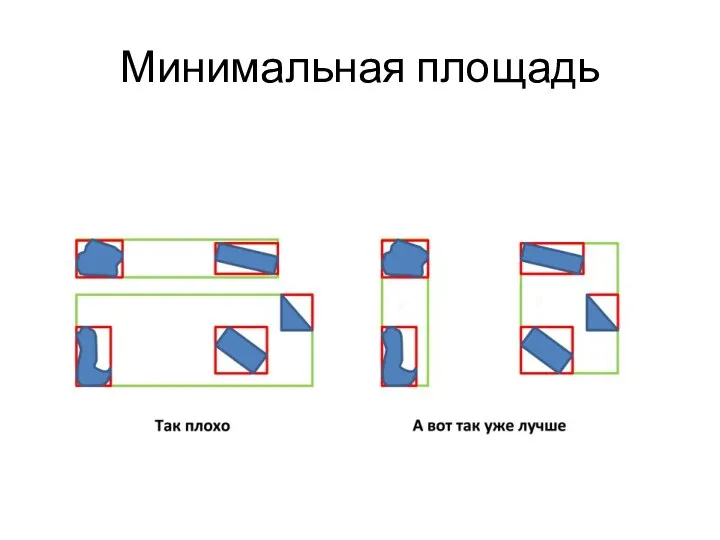
Минимальная площадь
Минимальная площадь
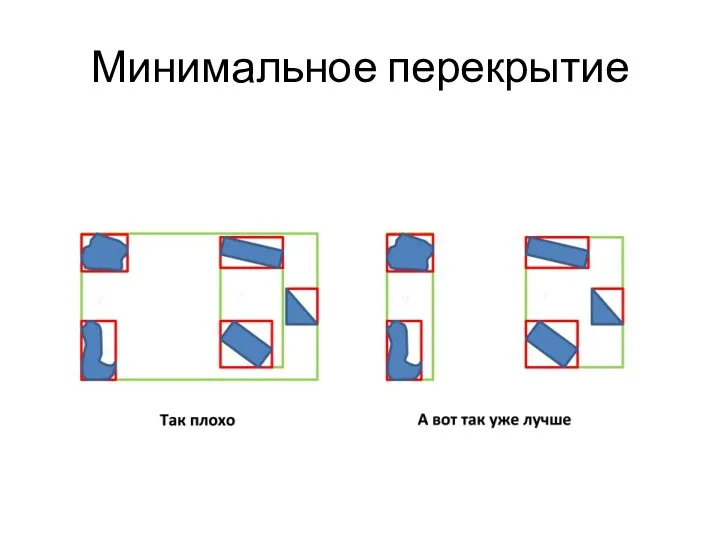
Минимальное перекрытие
Минимальное перекрытие
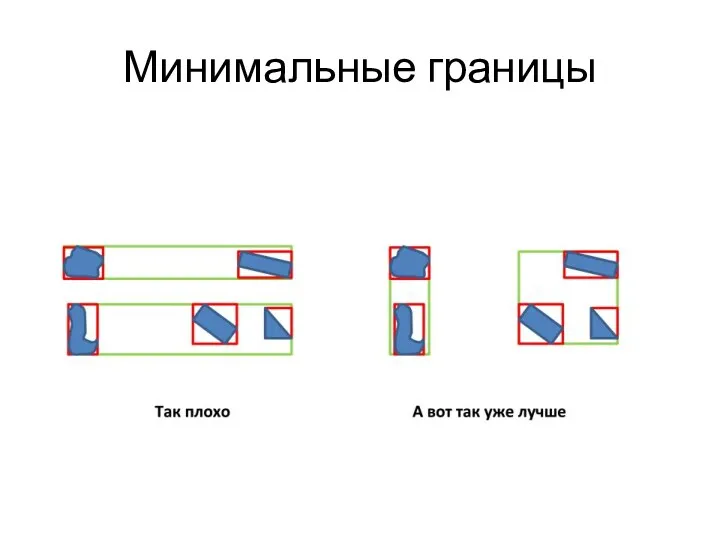
Минимальные границы
Минимальные границы
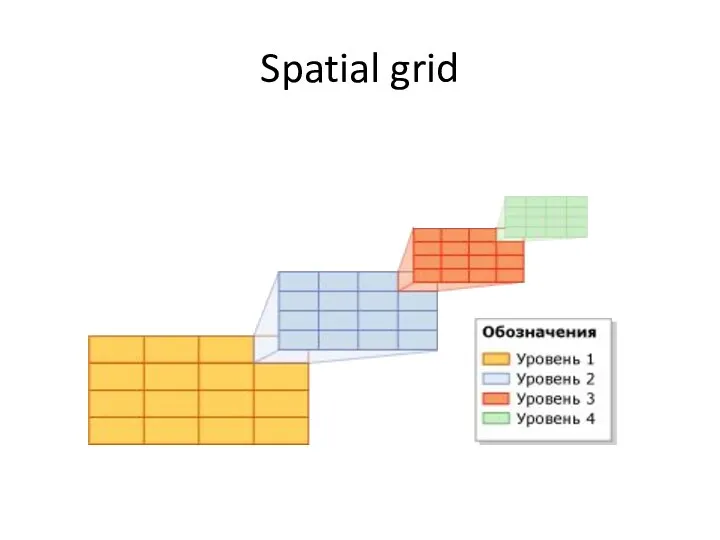
Spatial grid
Spatial grid

Spatial grid
CREATE SPATIAL INDEX
GEOMETRY_GRID | GEOGRAPHY_GRID
BOUNDING_BOX (для GEOMETRY_GRID)
xmin, ymin, xmax, ymax
GRIDS
Spatial grid
CREATE SPATIAL INDEX
GEOMETRY_GRID | GEOGRAPHY_GRID
BOUNDING_BOX (для GEOMETRY_GRID)
xmin, ymin, xmax, ymax
GRIDS
Spatial grid
4 уровня вложенности
Spatial grid
4 уровня вложенности

Spatial grid
CREATE SPATIAL INDEX SIndx
ON SpatialTable(geometry_col)
WITH (
BOUNDING_BOX =
Spatial grid
CREATE SPATIAL INDEX SIndx
ON SpatialTable(geometry_col)
WITH (
BOUNDING_BOX =
Spatial grid
Spatial grid

Тесселяция
Декомпозиция индексированного пространства в cеточную иерархию
Считывание данных для пространственного объекта по
Тесселяция
Декомпозиция индексированного пространства в cеточную иерархию
Считывание данных для пространственного объекта по
 Mobile SMARTS для ЕГАИС
Mobile SMARTS для ЕГАИС Дипломный проект. Разработка web–дизайна сайта кафе Шафран
Дипломный проект. Разработка web–дизайна сайта кафе Шафран Статика в Java
Статика в Java Основы разработки управляющих программ для станков с ЧПУ (ручное программирование, среда Siemens NX)
Основы разработки управляющих программ для станков с ЧПУ (ручное программирование, среда Siemens NX) Текстовый процессор MS Word
Текстовый процессор MS Word DTU – Data Transfer Untility Training
DTU – Data Transfer Untility Training Міст. Патерни проектування
Міст. Патерни проектування Мир библиографии
Мир библиографии Принципы разработки тестов
Принципы разработки тестов Персональный компьютер
Персональный компьютер Создание игры на движке Unity
Создание игры на движке Unity Программирование на языке высокого уровня C++. Лекция 7. Модульное программирование
Программирование на языке высокого уровня C++. Лекция 7. Модульное программирование Social Networks
Social Networks Арифметические основы ЭВМ
Арифметические основы ЭВМ Урок по теме: Операции над множествами
Урок по теме: Операции над множествами Git A distributed version control system Oct 4, 2016
Git A distributed version control system Oct 4, 2016 Нормативное и правовое обеспечение дополнительного образования детей и молодежи
Нормативное и правовое обеспечение дополнительного образования детей и молодежи STL Algorithm
STL Algorithm Исключения. Занятие 5
Исключения. Занятие 5 Виджеты и их свойства
Виджеты и их свойства Drvr product deck
Drvr product deck Символьные и строковые величины. Команды ввода и вывода
Символьные и строковые величины. Команды ввода и вывода Работа с дефектами в IT. Описание и структура дефектов
Работа с дефектами в IT. Описание и структура дефектов История Интернета. События Internet
История Интернета. События Internet Training Module Overview
Training Module Overview Назначение клавиш
Назначение клавиш Чат бот для улучшения оценок
Чат бот для улучшения оценок Электронные таблицы (ЭТ). Основные типы данных в ЭТ
Электронные таблицы (ЭТ). Основные типы данных в ЭТ