Интеллектуальный анализ данных Online Analytical Processing – аналитическая обработка данных в реальном времени презентация
- Интеллектуальный анализ данных Online Analytical Processing – аналитическая обработка данных в реальном времени

Содержание
- 2. Практическое применение Data Mining. Интернет-торговля: В системах электронного бизнеса, где особую важность имеют вопросы привлечения и
- 3. Телекоммуникации Телекоммуникационный бизнес является одной из наиболее динамически развивающихся областей современной экономики. Возможно, поэтому традиционные проблемы,
- 4. Медицина В медицинских и биологических исследованиях, равно как и в практической медицине, спектр решаемых задач настолько
- 5. Банковское дело Классическим примером использования Data Mining на практике является решение проблемы о возможной некредитоспособности клиентов
- 6. Процесс обнаружения знаний Основные этапы анализа Весь процесс можно разбить на следующие этапы: понимание и формулировка
- 7. На первом этапе выполняется осмысление поставленной задачи и уточнение целей, которые должны быть достигнуты методами Data
- 8. Текущее состояние дел Точно знаем надо Примерно знаем почему Плохо знаем как Данные Собираются не для
- 9. Примеры (реальные случаи) ошибки при вводе марки автомобиля: 14 (!)вариантов написания марки “Mercedes”. DEU указано вместо
- 10. Клиенты приходят в разное время и их качественный состав меняется Измерения производятся точно, результаты тщательно регистрируются
- 11. Продажа стиральных машин
- 12. Продажа майонеза
- 13. Классификация задач Data Mining Методы DM помогают решить многие задачи, с которыми сталкивается аналитик. Из них
- 14. Перечисленные задачи по назначению делятся на описательные и предсказательные. Описательные (descriptive) задачи уделяют внимание улучшению понимания
- 15. Кластеризация Задача кластеризации состоит в разделении исследуемого множества объектов на группы «похожих» объектов, называемых кластерами. Часто
- 16. Постановка задачи кластеризации Кластеризация отличается от классификации тем, что для проведения анализа не требуется иметь выделенную
- 17. Формальная постановка задачи Дано — набор данных со следующими свойствами: каждый экземпляр данных выражается четким числовым
- 18. Формально задача кластеризации описывается следующим образом. Дано множество объектов данных I, каждый из которых представлен набором
- 19. Меры близости, основанные на расстояниях, используемые в алгоритмах кластеризации Расстояния между объектами предполагают их представление в
- 20. Евклидово расстояние. Иногда может возникнуть желание возвести в квадрат стандартное евклидово расстояние, чтобы придать большие веса
- 21. Расстояние Чебышева. Это расстояние может оказаться полезным, когда желают определить два объекта как «различные», если они
- 22. Пиковое расстояние предполагает независимость между случайными переменными, что говорит о расстоянии в ортогональном пространстве. Но в
- 23. Представление результатов Результатом кластерного анализа является набор кластеров, содержащих элементы исходного множества. Кластерная модель должна описывать
- 24. Задача классификации и регрессии При анализе часто требуется определить, к какому из известных классов относятся исследуемые
- 25. Задача поиска ассоциативных правил предполагает отыскание частых наборов в большом числе наборов данных. В контексте анализы
- 26. Отличие поиска ассоциативных правил от секвенциального анализа (анализа последовательностей) в том, что в первом случае ищется
- 27. Введём некоторые обозначения и определения. D - множество всех транзакций T, где каждая транзакция характеризуется уникальным
- 28. Поддержка последовательности - это отношение числа покупателей, в чьих транзакциях присутствует указанная последовательность к общему числу
- 29. Алгоритм AprioriALL Существует большое число разновидностей алгоритма Apriori, который изначально не учитывал временную составляющую в наборах
- 31. Фаза отбора кандидатов - в исходном наборе данных производится поиск последовательностей в соответствии со значением минимальной
- 32. Фаза трансформации. В ходе работы алгоритма нам многократно придётся вычислять, присутствует ли последовательность в транзакциях покупателя.
- 34. Фаза генерации последовательностей - из полученных на предыдущих шагах последовательностей строятся более длинные шаблоны последовательностей. Фаза
- 35. Значение минимальной поддержки выберем 40% (последовательность должна наблюдаться как минимум у двоих покупателей из пяти). После
- 36. В фазе генерации последовательностей из исходных одно-элементных последовательностей сгенерируем двух-элементные и посчитаем для них поддержку. Оставим
- 38. Последовательность , например, не проходит отбор, поскольку последовательность , входящая в неё, не присутствует в L3.
- 39. Ограничения AprioriAll Рассмотренный алгоритм AprioriAll позволяет находить взаимосвязи в последовательностях данных. Это стало возможно после введения
- 40. Например, если книжный клуб установит значение окна равным одной неделе, то клиент, заказавший "Основание" в понедельник,
- 41. Классификация методов Различают две группы методов: статистические методы, основанные на использовании усредненного накопленного опыта, который отражен
- 42. Статистические методы Data mining В эти методы представляют собой четыре взаимосвязанных раздела: предварительный анализ природы статистических
- 43. Арсенал статистических методов Data Mining классифицирован на четыре группы методов: Дескриптивный анализ и описание исходных данных.
- 44. Кибернетические методы Data Mining Второе направление Data Mining - это множество подходов, объединенных идеей компьютерной математики
- 45. http://www.kdnuggets.com/
- 46. Дескриптивные (или описательные) статистики являются базовым и наиболее общим методом анализа данных. Представьте, что вы проводите
- 47. Давайте рассмотрим на примере: Потенциальный спрос на товар
- 48. Абсолютная частота показывает, сколько раз тот или иной ответ повторяется в выборке. Например, 23 человека купили
- 49. Наряду с частотами, дескриптивный анализ предполагает расчет различных описательных статистик. Соответствуя своему названию, они предоставляют основную
- 50. четыре уровня измерения: номинальный, порядковый, интервальный и отношений Номинальная шкала Шкала, содержащая только категории; данные в
- 51. Порядковая шкала Шкала, в которой числа присваивают объектам для обозначения относительной позиции объектов, но не величины
- 52. Интервальная шкала Шкала, разности, между значениями которой могут быть вычислены, однако их отношения не имеют смысла.
- 53. Относительная шкала Шкала, в которой есть определенная точка отсчета и возможны отношения между значениями шкалы. Относительные
- 55. Дескриптивные (описательные) методы для всех уровней измерения Данные на любом из уровней измерения можно описывать в
- 56. Категория ответа Количество ответов Не женат (не замужем) и никогда не был (а) женат (замужем) 5
- 57. Нынешнее семейное положение Количество ответов Состоят в браке 22 Не состоят в браке 28 ВСЕГО 50
- 58. Доли, проценты, пропорции Построив распределение частот, вы должны выбрать один из трех типов анализа, который способствовал
- 59. Нынешнее семейное положение Частота Доля Не женат (не замужем) и никогда не был (а) женат (замужем)
- 60. Вы только что увидели три рекламных ролика. Каждому из роликов было дано название до того, как
- 62. Анализ данных по столбцам (сверху вниз) указывает на то, что большая часть участников присвоила: Рекламному ролику
- 63. Пропорции. Третий путь суммирования данных на всех уровнях измерения – использование пропорции. Пропорция одного числа Х
- 64. Анализ данных интервального и относительного уровня измерений Интервальные и относительные шкалы обладают всеми характерными особенностями, присущими
- 65. Дискретные данные Рассмотрим следующий вопрос для оценки. Пожалуйста, дайте оценку рекламному ролику, который вы только что
- 66. Непрерывные данные Непрерывные данные предоставляют такую возможность для ответа, при которой значения, по крайней мере, теоретически,
- 68. Определение количества и ширины интервалов и категорий. Следующий шаг предполагает определение числа и ширины интервалов категорий.
- 71. Среднее является очень мощной статистикой. Оно дает возможность представить одним числом множество ответов на вопрос анкеты.
- 73. Значения средних намерения купить, сложившегося после просмотра ка- ждого рекламного ролика, совпадают, несмотря на то, что
- 74. Несмотря на то, что среднее намерения купить товар равняется 3,0 для всех трех роликов, это значение
- 77. Медиана. Среднее является часто используемой мерой центральной тенденции ряда данных. Дисперсия и стандартное отклонение указывают на
- 78. Что использовать – среднее или медиану? Определение среднего и медианы ряда значений важно и полезно для
- 79. Второй ситуацией, когда следует отдать предпочтение медиане, является наличие открытых категорий в группировке данных. Группировка по
- 80. Мода. Еще одной мерой центральной тенденции служит мода. Она определяется как наиболее часто встречающееся значение в
- 81. Соотношение среднего, моды и медианы. Среднее, мода и медиана дают различное видение характеристик ряда. Распределение будет
- 82. Многие распределения не являются симметричными. Распределение, в котором мода меньше медианы, а медиана в свою очередь,
- 83. Распределение, в котором мода больше медианы, а медиана больше среднего, скошено вправо.
- 84. Упрощенное представление нескольких дескриптивных мер Номинальный уровень данных: организация представления и вычисление «совокупного» процента. Вы только
- 87. Закономерность ответов на этот вопрос можно сделать более ясной, если придерживаться следующих действий: Во-первых, определите о
- 89. Когда данные организованы так, как показано в таблице, сразу становятся очевидными следующие выводы: Почти всем респондентам
- 90. Интервальные и относительные данные: объединение связанных по смыслу шкал. Очень часто для оценки индивидуального отношения и
- 91. 1. Товар, рекламируемый как «легкий» и «обезжиренный», действи- тельно полезнее для здоровья. 2. Реклама, которая настойчиво
- 94. Важные результаты лучше всего представить, сперва организовав утверждения, а затем осуществив дополнительные вычисления. Сначала, как и
- 96. Далее надо иметь ввиду, что усреднение ответов на логически взаимосвязанные шкалы – интуитивно обоснованный метод обобщения
- 98. Скачать презентацию

Практическое применение Data Mining.
Интернет-торговля:
В системах электронного бизнеса, где особую важность
Практическое применение Data Mining.
Интернет-торговля:
В системах электронного бизнеса, где особую важность

Телекоммуникации
Телекоммуникационный бизнес является одной из наиболее динамически развивающихся областей современной экономики.
Телекоммуникации
Телекоммуникационный бизнес является одной из наиболее динамически развивающихся областей современной экономики.

Медицина
В медицинских и биологических исследованиях, равно как и в практической медицине,
Медицина
В медицинских и биологических исследованиях, равно как и в практической медицине,

Банковское дело
Классическим примером использования Data Mining на практике является решение проблемы
Банковское дело
Классическим примером использования Data Mining на практике является решение проблемы

Процесс обнаружения знаний
Основные этапы анализа
Весь процесс можно разбить на следующие
Процесс обнаружения знаний
Основные этапы анализа
Весь процесс можно разбить на следующие

На первом этапе выполняется осмысление поставленной задачи и уточнение целей, которые
На первом этапе выполняется осмысление поставленной задачи и уточнение целей, которые
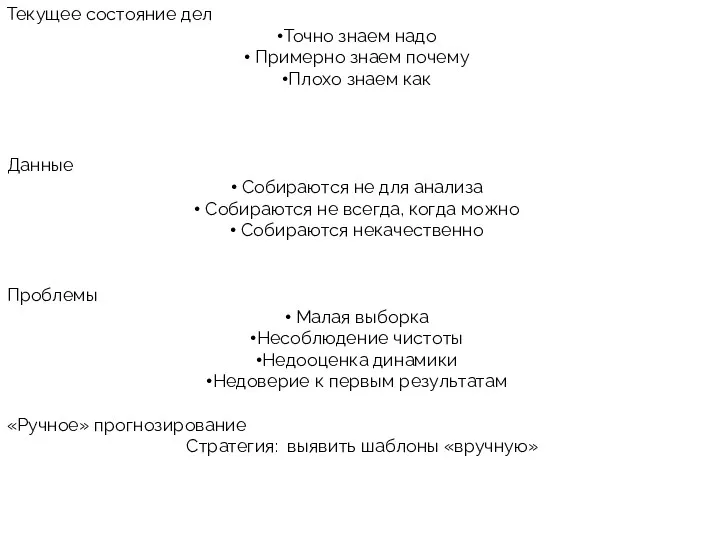
Текущее состояние дел
Точно знаем надо
Примерно знаем почему
Плохо знаем как
Данные
Текущее состояние дел
Точно знаем надо
Примерно знаем почему
Плохо знаем как
Данные

Примеры (реальные случаи)
ошибки при вводе марки автомобиля:
14 (!)вариантов написания
Примеры (реальные случаи)
ошибки при вводе марки автомобиля:
14 (!)вариантов написания

Клиенты приходят в разное время и их качественный состав меняется
Измерения
Клиенты приходят в разное время и их качественный состав меняется
Измерения

Продажа стиральных машин
Продажа стиральных машин

Продажа майонеза
Продажа майонеза

Классификация задач Data Mining
Методы DM помогают решить многие задачи, с которыми
Классификация задач Data Mining
Методы DM помогают решить многие задачи, с которыми

Перечисленные задачи по назначению делятся на описательные и предсказательные.
Описательные (descriptive) задачи
Перечисленные задачи по назначению делятся на описательные и предсказательные.
Описательные (descriptive) задачи

Кластеризация
Задача кластеризации состоит в разделении исследуемого множества объектов на группы «похожих»
Кластеризация
Задача кластеризации состоит в разделении исследуемого множества объектов на группы «похожих»

Постановка задачи кластеризации
Кластеризация отличается от классификации тем, что для проведения анализа
Постановка задачи кластеризации
Кластеризация отличается от классификации тем, что для проведения анализа

Формальная постановка задачи
Дано — набор данных со следующими свойствами:
каждый экземпляр данных
Формальная постановка задачи
Дано — набор данных со следующими свойствами:
каждый экземпляр данных

Формально задача кластеризации описывается следующим образом.
Дано множество объектов данных I, каждый
Формально задача кластеризации описывается следующим образом.
Дано множество объектов данных I, каждый

Меры близости, основанные на расстояниях, используемые в алгоритмах кластеризации
Расстояния между объектами
Меры близости, основанные на расстояниях, используемые в алгоритмах кластеризации
Расстояния между объектами

Евклидово расстояние. Иногда может возникнуть желание возвести в квадрат стандартное евклидово
Евклидово расстояние. Иногда может возникнуть желание возвести в квадрат стандартное евклидово

Расстояние Чебышева. Это расстояние может оказаться полезным, когда желают определить два
Расстояние Чебышева. Это расстояние может оказаться полезным, когда желают определить два

Пиковое расстояние предполагает независимость между случайными переменными, что говорит о расстоянии
Пиковое расстояние предполагает независимость между случайными переменными, что говорит о расстоянии

Представление результатов
Результатом кластерного анализа является набор кластеров, содержащих элементы исходного множества.
Представление результатов
Результатом кластерного анализа является набор кластеров, содержащих элементы исходного множества.

Задача классификации и регрессии
При анализе часто требуется определить, к какому из
Задача классификации и регрессии
При анализе часто требуется определить, к какому из

Задача поиска ассоциативных правил предполагает отыскание частых наборов в большом числе
Задача поиска ассоциативных правил предполагает отыскание частых наборов в большом числе

Отличие поиска ассоциативных правил от секвенциального анализа (анализа последовательностей) в том,
Отличие поиска ассоциативных правил от секвенциального анализа (анализа последовательностей) в том,

Введём некоторые обозначения и определения.
D - множество всех транзакций T, где
Введём некоторые обозначения и определения.
D - множество всех транзакций T, где

Поддержка последовательности - это отношение числа покупателей, в чьих транзакциях присутствует указанная
Поддержка последовательности - это отношение числа покупателей, в чьих транзакциях присутствует указанная

Алгоритм AprioriALL
Существует большое число разновидностей алгоритма Apriori, который изначально не учитывал
Алгоритм AprioriALL
Существует большое число разновидностей алгоритма Apriori, который изначально не учитывал


Фаза отбора кандидатов - в исходном наборе данных производится поиск последовательностей в
Фаза отбора кандидатов - в исходном наборе данных производится поиск последовательностей в

Фаза трансформации. В ходе работы алгоритма нам многократно придётся вычислять, присутствует
Фаза трансформации. В ходе работы алгоритма нам многократно придётся вычислять, присутствует


Фаза генерации последовательностей - из полученных на предыдущих шагах последовательностей строятся более
Фаза генерации последовательностей - из полученных на предыдущих шагах последовательностей строятся более

Значение минимальной поддержки выберем 40% (последовательность должна наблюдаться как минимум у
Значение минимальной поддержки выберем 40% (последовательность должна наблюдаться как минимум у

В фазе генерации последовательностей из исходных одно-элементных последовательностей сгенерируем двух-элементные и
В фазе генерации последовательностей из исходных одно-элементных последовательностей сгенерируем двух-элементные и


Последовательность <1 2 4 3>, например, не проходит отбор, поскольку последовательность
Последовательность <1 2 4 3>, например, не проходит отбор, поскольку последовательность

Ограничения AprioriAll
Рассмотренный алгоритм AprioriAll позволяет находить взаимосвязи в последовательностях данных. Это
Ограничения AprioriAll Рассмотренный алгоритм AprioriAll позволяет находить взаимосвязи в последовательностях данных. Это

Например, если книжный клуб установит значение окна равным одной неделе, то
Например, если книжный клуб установит значение окна равным одной неделе, то

Классификация методов
Различают две группы методов:
статистические методы, основанные на использовании усредненного накопленного опыта, который
Классификация методов
Различают две группы методов:
статистические методы, основанные на использовании усредненного накопленного опыта, который

Статистические методы Data mining
В эти методы представляют собой четыре взаимосвязанных раздела:
предварительный анализ природы
Статистические методы Data mining
В эти методы представляют собой четыре взаимосвязанных раздела:
предварительный анализ природы

Арсенал статистических методов Data Mining классифицирован на четыре группы методов:
Дескриптивный анализ и описание исходных
Арсенал статистических методов Data Mining классифицирован на четыре группы методов:
Дескриптивный анализ и описание исходных

Кибернетические методы Data Mining
Второе направление Data Mining - это множество подходов,
Кибернетические методы Data Mining
Второе направление Data Mining - это множество подходов,

http://www.kdnuggets.com/
http://www.kdnuggets.com/

Дескриптивные (или описательные) статистики являются базовым и наиболее общим методом анализа
Дескриптивные (или описательные) статистики являются базовым и наиболее общим методом анализа

Давайте рассмотрим на примере: Потенциальный спрос на товар
Давайте рассмотрим на примере: Потенциальный спрос на товар

Абсолютная частота показывает, сколько раз тот или иной ответ повторяется в
Абсолютная частота показывает, сколько раз тот или иной ответ повторяется в

Наряду с частотами, дескриптивный анализ предполагает расчет различных описательных статистик. Соответствуя
Наряду с частотами, дескриптивный анализ предполагает расчет различных описательных статистик. Соответствуя

четыре уровня измерения: номинальный, порядковый, интервальный и отношений
Номинальная шкала
Шкала, содержащая только категории;
четыре уровня измерения: номинальный, порядковый, интервальный и отношений
Номинальная шкала
Шкала, содержащая только категории;

Порядковая шкала
Шкала, в которой числа присваивают объектам для обозначения относительной позиции объектов, но
Порядковая шкала
Шкала, в которой числа присваивают объектам для обозначения относительной позиции объектов, но

Интервальная шкала
Шкала, разности, между значениями которой могут быть вычислены, однако их
Интервальная шкала
Шкала, разности, между значениями которой могут быть вычислены, однако их

Относительная шкала
Шкала, в которой есть определенная точка отсчета и возможны отношения между значениями шкалы. Относительные
Относительная шкала
Шкала, в которой есть определенная точка отсчета и возможны отношения между значениями шкалы. Относительные
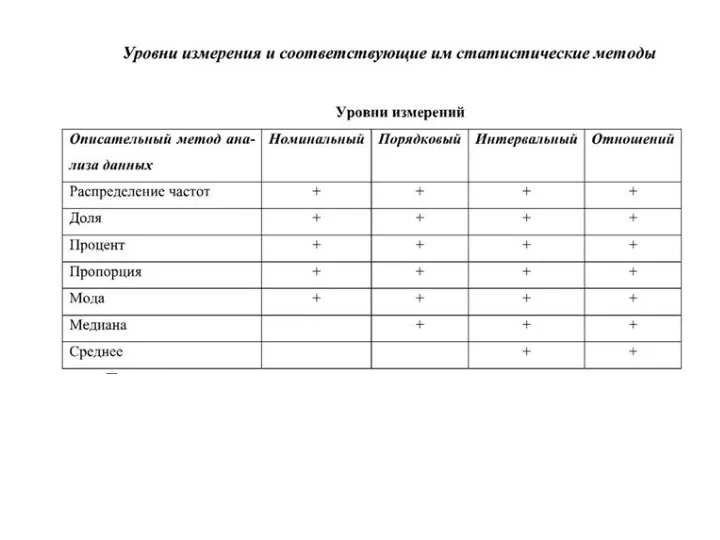

Дескриптивные (описательные) методы для всех уровней измерения
Данные на любом из
Дескриптивные (описательные) методы для всех уровней измерения
Данные на любом из

Категория ответа Количество ответов
Не женат (не замужем) и никогда не
Категория ответа Количество ответов
Не женат (не замужем) и никогда не

Нынешнее семейное положение Количество ответов
Состоят в браке 22
Не состоят
Нынешнее семейное положение Количество ответов
Состоят в браке 22
Не состоят

Доли, проценты, пропорции
Построив распределение частот, вы должны выбрать один из
Доли, проценты, пропорции
Построив распределение частот, вы должны выбрать один из

Нынешнее семейное положение Частота Доля
Не женат (не замужем) и никогда
Нынешнее семейное положение Частота Доля
Не женат (не замужем) и никогда

Вы только что увидели три рекламных ролика. Каждому из роликов было
Вы только что увидели три рекламных ролика. Каждому из роликов было


Анализ данных по столбцам (сверху вниз) указывает на то, что большая
Анализ данных по столбцам (сверху вниз) указывает на то, что большая

Пропорции.
Третий путь суммирования данных на всех уровнях измерения – использование
Пропорции.
Третий путь суммирования данных на всех уровнях измерения – использование

Анализ данных интервального и относительного уровня измерений
Интервальные и относительные шкалы
Анализ данных интервального и относительного уровня измерений
Интервальные и относительные шкалы

Дискретные данные Рассмотрим следующий вопрос для оценки. Пожалуйста, дайте оценку рекламному
Дискретные данные Рассмотрим следующий вопрос для оценки. Пожалуйста, дайте оценку рекламному

Непрерывные данные
Непрерывные данные предоставляют такую возможность для ответа, при которой
Непрерывные данные
Непрерывные данные предоставляют такую возможность для ответа, при которой


Определение количества и ширины интервалов и категорий. Следующий шаг предполагает определение
Определение количества и ширины интервалов и категорий. Следующий шаг предполагает определение



Среднее является очень мощной статистикой. Оно дает возможность представить одним числом
Среднее является очень мощной статистикой. Оно дает возможность представить одним числом


Значения средних намерения купить, сложившегося после просмотра ка-
ждого рекламного ролика, совпадают,
Значения средних намерения купить, сложившегося после просмотра ка-
ждого рекламного ролика, совпадают,

Несмотря на то, что среднее намерения купить товар равняется 3,0 для
Несмотря на то, что среднее намерения купить товар равняется 3,0 для
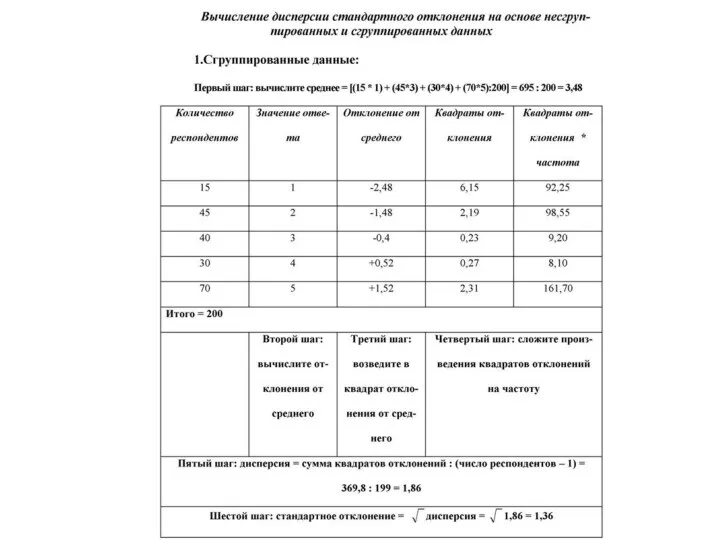


Медиана.
Среднее является часто используемой мерой центральной тенденции ряда данных. Дисперсия и
Медиана.
Среднее является часто используемой мерой центральной тенденции ряда данных. Дисперсия и
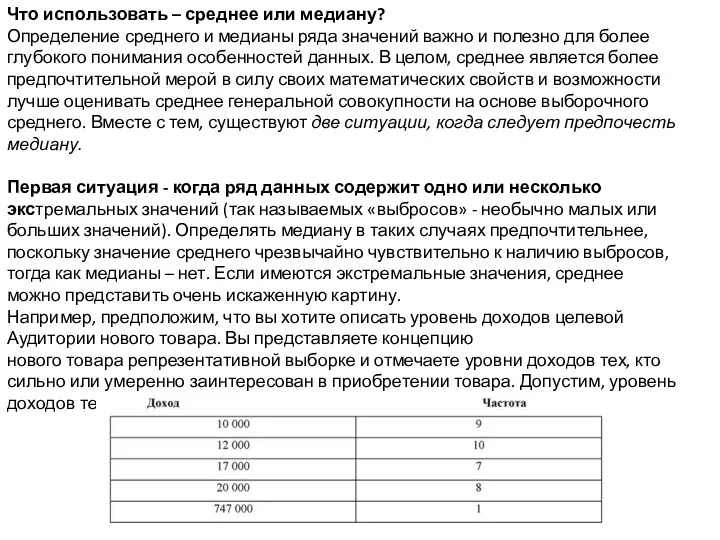
Что использовать – среднее или медиану?
Определение среднего и медианы ряда
Что использовать – среднее или медиану?
Определение среднего и медианы ряда

Второй ситуацией, когда следует отдать предпочтение медиане, является
наличие открытых категорий в
Второй ситуацией, когда следует отдать предпочтение медиане, является
наличие открытых категорий в

Мода. Еще одной мерой центральной тенденции служит мода. Она определяется как
Мода. Еще одной мерой центральной тенденции служит мода. Она определяется как
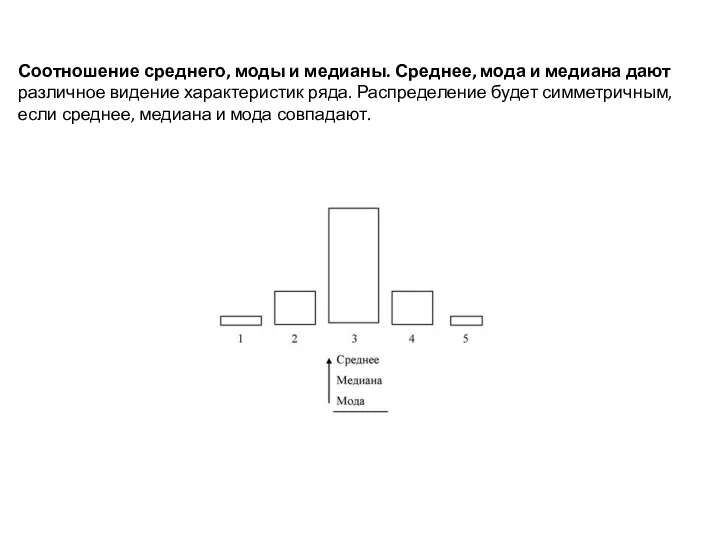
Соотношение среднего, моды и медианы. Среднее, мода и медиана дают
различное видение
Соотношение среднего, моды и медианы. Среднее, мода и медиана дают
различное видение

Многие распределения не являются симметричными. Распределение, в
котором мода меньше медианы, а
Многие распределения не являются симметричными. Распределение, в
котором мода меньше медианы, а
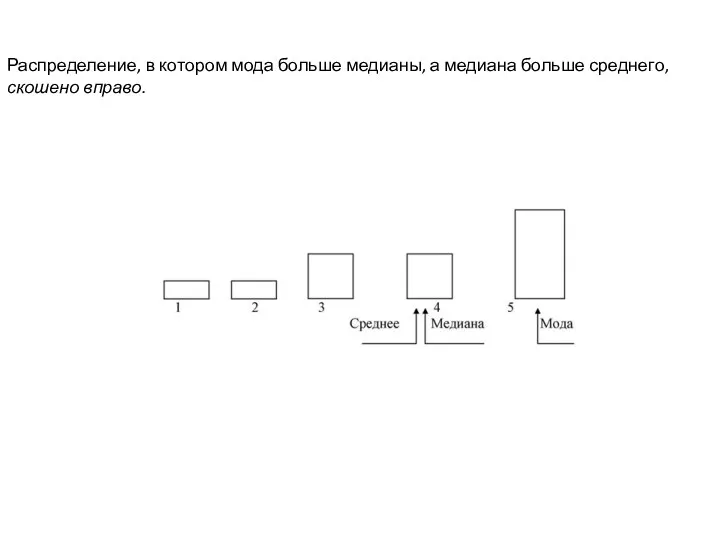
Распределение, в котором мода больше медианы, а медиана больше среднего, скошено
Распределение, в котором мода больше медианы, а медиана больше среднего, скошено

Упрощенное представление нескольких дескриптивных мер
Номинальный уровень данных: организация представления и вычисление
Упрощенное представление нескольких дескриптивных мер
Номинальный уровень данных: организация представления и вычисление



Закономерность ответов на этот вопрос можно сделать более ясной, если
придерживаться следующих
Закономерность ответов на этот вопрос можно сделать более ясной, если
придерживаться следующих


Когда данные организованы так, как показано в таблице, сразу становятся очевидными
Когда данные организованы так, как показано в таблице, сразу становятся очевидными

Интервальные и относительные данные: объединение связанных по смыслу шкал.
Очень часто для
Интервальные и относительные данные: объединение связанных по смыслу шкал.
Очень часто для

1. Товар, рекламируемый как «легкий» и «обезжиренный», действи-
тельно полезнее для здоровья.
2.
1. Товар, рекламируемый как «легкий» и «обезжиренный», действи-
тельно полезнее для здоровья.
2.
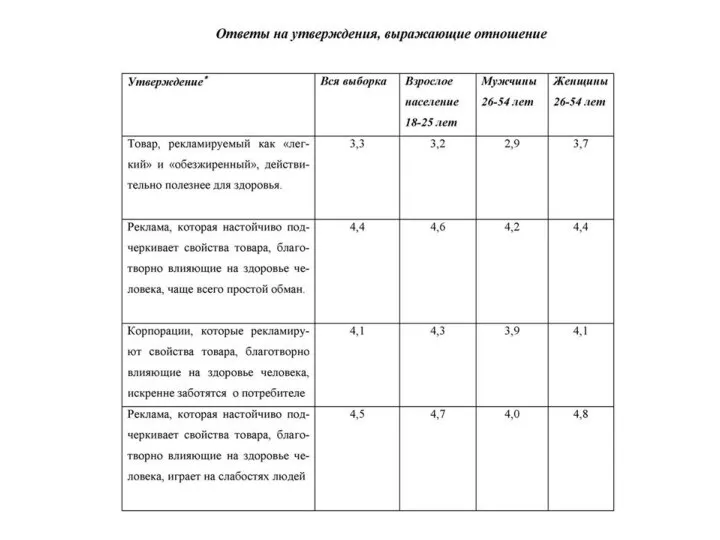


Важные результаты лучше всего представить, сперва организовав утверждения, а затем осуществив
Важные результаты лучше всего представить, сперва организовав утверждения, а затем осуществив


Далее надо иметь ввиду, что усреднение ответов на логически взаимосвязанные шкалы
Далее надо иметь ввиду, что усреднение ответов на логически взаимосвязанные шкалы
 Подробная информация по туру Нормандия
Подробная информация по туру Нормандия Эффективность предпринимательской деятельности. Тема 8
Эффективность предпринимательской деятельности. Тема 8 Диспенсеры Ibis
Диспенсеры Ibis Вывеска как элемент наружного оформления фасадов зданий
Вывеска как элемент наружного оформления фасадов зданий Журнал Inspiramus Magazine
Журнал Inspiramus Magazine Компания Мицеллайн
Компания Мицеллайн История бренда Lipton. Новый Lipton Yellow Label
История бренда Lipton. Новый Lipton Yellow Label Портфолио ведущей мероприятий
Портфолио ведущей мероприятий Автоматизация приемки поставок в Х5 (по DESADV)
Автоматизация приемки поставок в Х5 (по DESADV) Сервис Mango Office. Анализ конкурентов
Сервис Mango Office. Анализ конкурентов Пресс-ланч, брифинг, пресс-тур и пресс-клуб
Пресс-ланч, брифинг, пресс-тур и пресс-клуб О компании Новогодофф. Сладкие новогодние подарки
О компании Новогодофф. Сладкие новогодние подарки The CCK 11 MBps Modulation for IEEE 802.11 2.4 GHz WLANs
The CCK 11 MBps Modulation for IEEE 802.11 2.4 GHz WLANs Global Social Media Plan September Topic: Golf R 1 Subline: Focus on the Golf R brake pads Format: Image Date: Flexible Content
Global Social Media Plan September Topic: Golf R 1 Subline: Focus on the Golf R brake pads Format: Image Date: Flexible Content Железо в питании человека. БАД компании NSP, содержащие железо
Железо в питании человека. БАД компании NSP, содержащие железо Технология разработки бренда
Технология разработки бренда Жарнаманың тарихы
Жарнаманың тарихы PFC CSKA vs Hyundai Stadium activations
PFC CSKA vs Hyundai Stadium activations Сбытовая функция маркетинга. (Лекция 9)
Сбытовая функция маркетинга. (Лекция 9) Анализ рынка молочной продукции АО ГК Российское Молоко
Анализ рынка молочной продукции АО ГК Российское Молоко Стратегии маркетинга территорий на примере разных стран и регионов
Стратегии маркетинга территорий на примере разных стран и регионов Humor in Ads FInal
Humor in Ads FInal Компания парфюмерии ESSENS
Компания парфюмерии ESSENS Brand Identity and Style Guide
Brand Identity and Style Guide Регламент работы с КПК и Мерч Онлайн отчетностью
Регламент работы с КПК и Мерч Онлайн отчетностью Складской комплекс Terra-2000. Сдача помещений в аренду
Складской комплекс Terra-2000. Сдача помещений в аренду Сутність і завдання страхового маркетингу
Сутність і завдання страхового маркетингу CrocoNut. Грильяж от Рошен
CrocoNut. Грильяж от Рошен