Эконометрика. Методы и модели анализа временных рядов. Прогнозирование экономических процессов с использованием временных рядов презентация
- Эконометрика. Методы и модели анализа временных рядов. Прогнозирование экономических процессов с использованием временных рядов

Содержание
- 2. Вопросы Структура временных рядов экономических показателей. Требования, предъявляемые к исходной информации. Основные этапы построения моделей экономического
- 3. Структура и особенности временных рядов экономических показателей Динамика финансово-экономических показателей обычно отражается динамическими и временными рядами.
- 4. Графическая форма представления ВР
- 5. Всякий временной ряд состоит из отдельных уровней. Уровни ряда - отдельные значения временного ряда, характеризующие изменение
- 6. Среди временных рядов выделяют два вида: моментные ВР – последовательные наблюдения характеризуют показатель на некоторый момент
- 7. Экономические процессы могут быть представлены в виде различных моделей: одной из названных составляющих компонент: yt= ft
- 8. Этапы построения прогнозов экономических показателей, представленных временными рядами Предварительный анализ временных рядов. Построение моделей. Оценка качества
- 9. Предварительный анализ временных рядов 1. Выявление аномальных наблюдений Метод Ирвина. 2. Сглаживание временных рядов. Метод простой
- 10. Проверка требований, предъявляемых к исходной информации и ее анализ На этапе предварительного анализа уровни ВР должны
- 11. Сопоставимость означает, что урони ряда должны отвечать ряду требований: 1) выражаться в одних и тех же
- 12. Однородность предполагает отсутствие нетипичных и аномальных наблюдений и изломов тенденций. Устойчивость характеризует преобладание законо-мерности над случайностью
- 13. Расчет динамических характеристик ВР включает в себя: Расчет абсолютных приростов: цепных ∆yцепн = yt - yt-1
- 14. Расчет темпов роста: Цепных Тцепн = yt / yt-1 , Базисных Тбазисн= yt / y1 ,
- 16. Коррелограмма автокорреляционной функции ВВП
- 17. Выявление аномальных наблюдений включает: Определение аномальных наблюдений (по критерию Ирвина): для каждого наблюдения начиная со второго,
- 18. Предварительный анализ данных. Влияние аномальных наблюдений на результаты моделирования
- 19. Предварительный анализ данных. Влияние аномальных наблюдений на результаты моделирования
- 20. Установление причин возникновения аномальных наблюдений АН могут быть вызваны двумя причинами: техническими - из-за ошибок в
- 21. Пример. Проверить ВР на наличие АН. Здесь ∑yt = 240, ytср=24, ∑(yt-ytср) 2 = 574, σy
- 22. Сглаживание ВР Сглаживание ВР позволяет более четко выявить тренд и подготовить ряд для построения модели прогнозирования.
- 23. 2) Рассчитывается параметр: p=(m-1)/2 . 3) Вычисляется среднее арифметическое значение уровней в интервале сглаживания: . 4)
- 24. Особенности весовых коэффициентов: - симметричны относительно центрального члена; - сумма весов с учетом общего члена равна
- 25. Выявление тренда Тренд – долговременная устойчивая тенденция изменения показателя во времени. Различают 3 вида: ↑ ,
- 26. Метод обнаружения тренда - сравнение средних уровней ряда. Временной ряд разбивают на две примерно равные по
- 28. Метод обнаружения тренда - сравнение средних уровней ряда.
- 29. Построение моделей временных рядов. Формирование уровней ряда определяется закономерностями трех основных типов: инерцией тенденции, инерцией взаимосвязи
- 30. Модели кривых роста Плавную кривую (гладкую функцию), аппроксимирующую временной ряд принято называть кривой роста. Аналитические методы
- 31. Виды аппроксимирующих функций В качестве кривых роста для описания тренда могут выбираться различные функции: Полиномиальные (полином
- 32. Расчет параметров модели МНК Параметры большинства "кривых роста", как правило, оцениваются по методу наименьших квадратов, т.е.
- 33. Построим график у = f(t) t y yt yp εt Yp=a0+a1t εt=yt-yp или ∑ ε2t= ∑(yt-
- 34. Далее минимизируется сумма квадратов отклонений εt2, для чего вычисляются частные производные по a1, a0 и приравниваются
- 35. Оценка качества модели Проверка адекватности 1.Проверка независимости (отсутствие автокорреляции). 2. Проверка случайности. 3. Соответствие ряда остатков
- 36. Оценка качества модели прогнозирования Модель считается хорошей со статистической точки зрения, если она адекватна и достаточно
- 37. 1) Проверка равенства математического ожидания нулю ( Равенство нулю средней ошибки). Если случайная компонента имеет нормальное
- 38. 2) Проверка условия случайности возникновения отдельных отклонений от тренда Для проверки случайности уровней ряда могут быть
- 39. Проверка случайности. Критерий поворотных точек (p – критерий) Данный критерий служит для проверки свойства случайности колебаний
- 40. 3) Проверка независимости (отсутствие автокорреляции) Критерий Дарбина-Уотсона или d – критерий (свойство независимости остатков т.е. отсутствие
- 41. Проверка независимости (отсутствие автокорреляции)
- 42. Рассчитанное значение r (1) сопоставляется с r (1)табл табличным, и если r (1) Если d2 Если
- 43. 4) Соответствие ряда остатков нормальному закону распределения R/S – критерий (нормальность распределения εt) Критерий рассчитывается как
- 44. Критерии точности модели В качестве статистических показателей точности модели применяются: среднее квадратическое отклонение Sε = ,
- 45. Выбор лучшей модели производится по критериям адекватности и точности. Лучшей считается та модель, которая имеет лучшие
- 47. Скачать презентацию

Вопросы
Структура временных рядов экономических показателей.
Требования, предъявляемые к исходной информации.
Основные этапы
Вопросы
Структура временных рядов экономических показателей.
Требования, предъявляемые к исходной информации.
Основные этапы

Структура и особенности временных рядов экономических показателей
Динамика финансово-экономических показателей обычно
Структура и особенности временных рядов экономических показателей
Динамика финансово-экономических показателей обычно
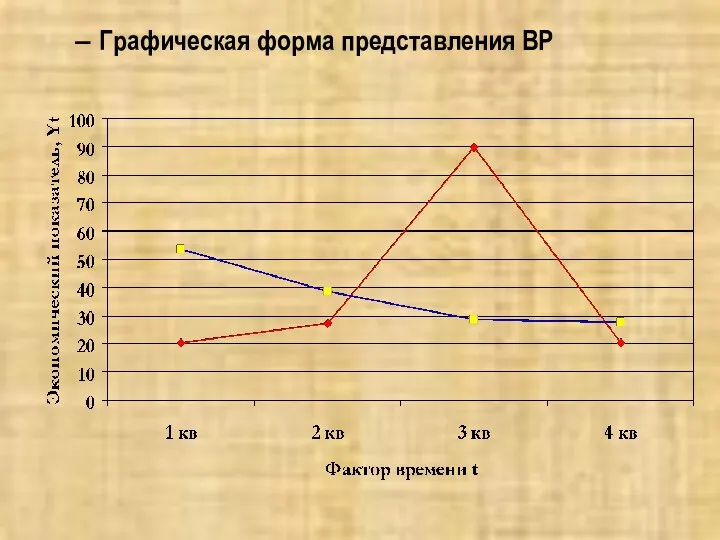
Графическая форма представления ВР
Графическая форма представления ВР

Всякий временной ряд состоит из отдельных уровней.
Уровни ряда - отдельные
Всякий временной ряд состоит из отдельных уровней.
Уровни ряда - отдельные

Среди временных рядов выделяют два вида:
моментные ВР – последовательные
Среди временных рядов выделяют два вида: моментные ВР – последовательные

Экономические процессы могут быть представлены в виде различных моделей:
одной из названных
Экономические процессы могут быть представлены в виде различных моделей:
одной из названных

Этапы построения прогнозов экономических показателей, представленных временными рядами
Предварительный анализ временных рядов.
Построение
Этапы построения прогнозов экономических показателей, представленных временными рядами
Предварительный анализ временных рядов.
Построение
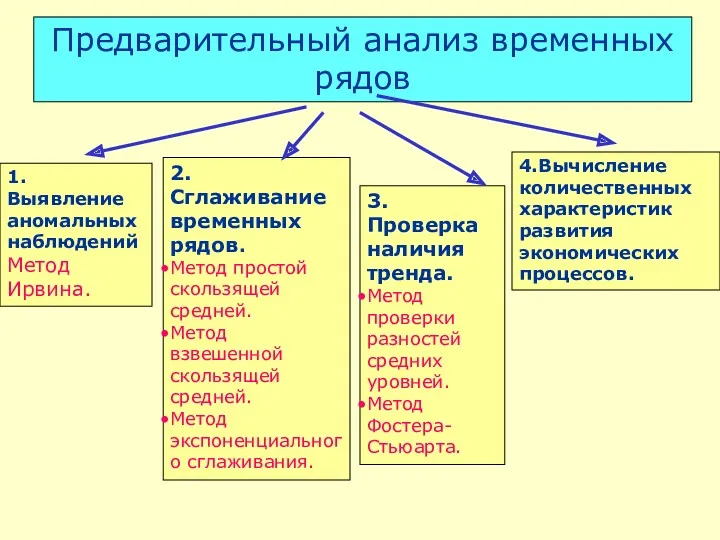
Предварительный анализ временных рядов
1. Выявление аномальных наблюдений
Метод Ирвина.
2. Сглаживание временных рядов.
Метод
Предварительный анализ временных рядов
1. Выявление аномальных наблюдений
Метод Ирвина.
2. Сглаживание временных рядов.
Метод

Проверка требований, предъявляемых к исходной информации и ее анализ
На этапе
Проверка требований, предъявляемых к исходной информации и ее анализ
На этапе

Сопоставимость означает, что урони ряда должны отвечать ряду требований:
1) выражаться в
Сопоставимость означает, что урони ряда должны отвечать ряду требований:
1) выражаться в
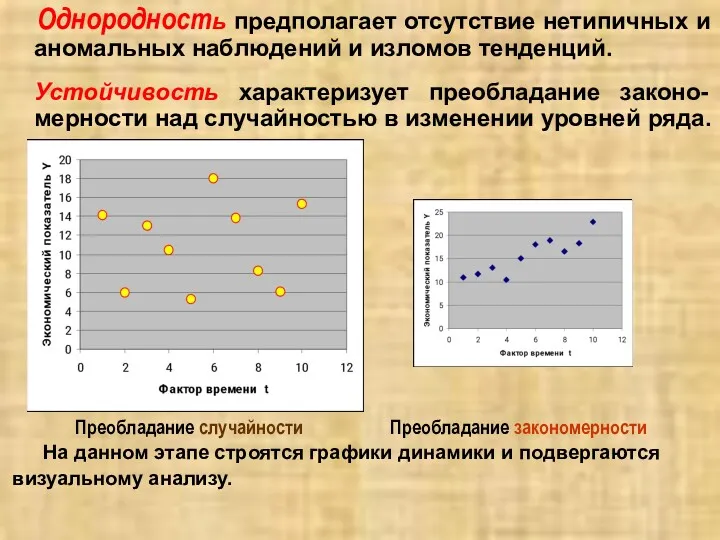
Однородность предполагает отсутствие нетипичных и аномальных наблюдений и изломов тенденций.
Однородность предполагает отсутствие нетипичных и аномальных наблюдений и изломов тенденций.

Расчет динамических характеристик ВР включает в себя:
Расчет абсолютных приростов:
цепных ∆yцепн =
Расчет динамических характеристик ВР включает в себя:
Расчет абсолютных приростов:
цепных ∆yцепн =

Расчет темпов роста:
Цепных Тцепн = yt / yt-1 ,
Базисных Тбазисн= yt
Расчет темпов роста:
Цепных Тцепн = yt / yt-1 ,
Базисных Тбазисн= yt

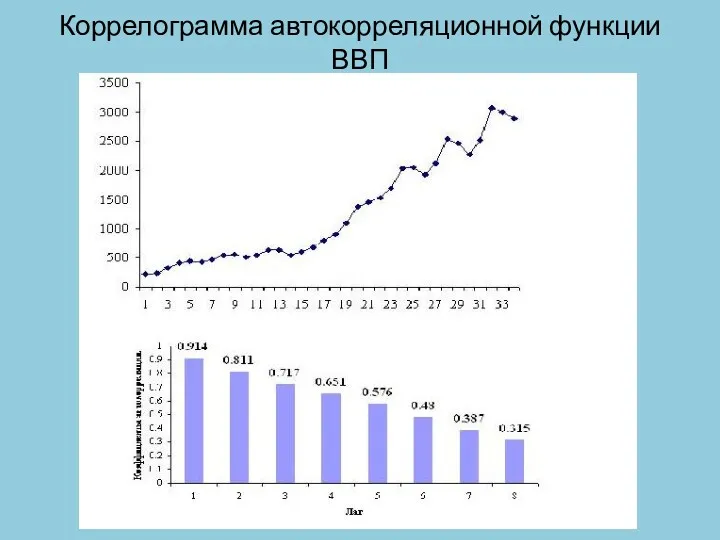
Коррелограмма автокорреляционной функции ВВП
Коррелограмма автокорреляционной функции ВВП

Выявление аномальных наблюдений включает:
Определение аномальных наблюдений (по критерию Ирвина):
для каждого
Выявление аномальных наблюдений включает:
Определение аномальных наблюдений (по критерию Ирвина):
для каждого
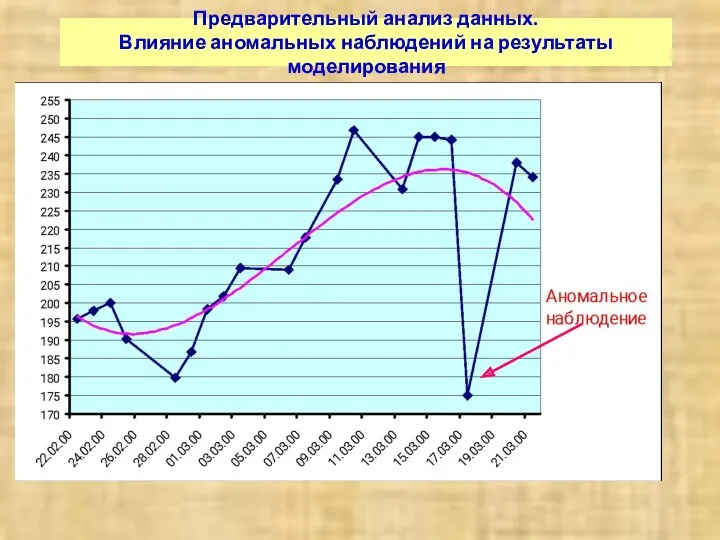
Предварительный анализ данных.
Влияние аномальных наблюдений на результаты моделирования
Предварительный анализ данных.
Влияние аномальных наблюдений на результаты моделирования
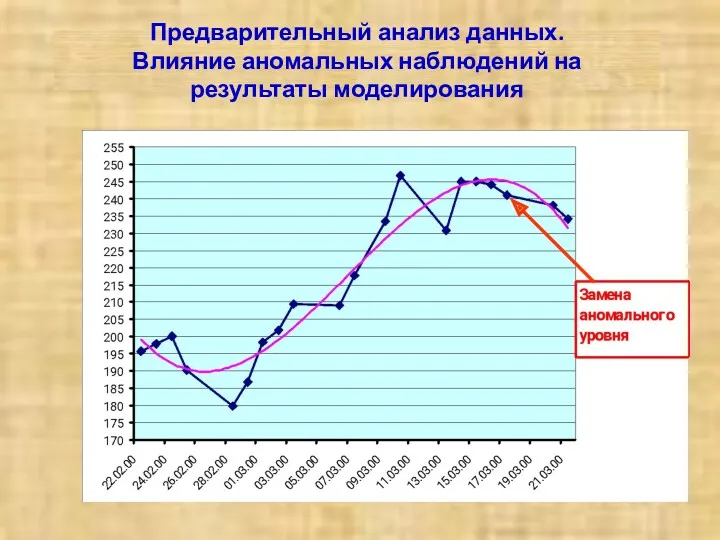
Предварительный анализ данных.
Влияние аномальных наблюдений на результаты моделирования
Предварительный анализ данных.
Влияние аномальных наблюдений на результаты моделирования

Установление причин возникновения аномальных наблюдений
АН могут быть вызваны двумя причинами:
техническими -
Установление причин возникновения аномальных наблюдений
АН могут быть вызваны двумя причинами:
техническими -

Пример. Проверить ВР на наличие АН.
Здесь ∑yt = 240, ytср=24, ∑(yt-ytср)
Пример. Проверить ВР на наличие АН.
Здесь ∑yt = 240, ytср=24, ∑(yt-ytср)

Сглаживание ВР
Сглаживание ВР позволяет более четко выявить тренд и подготовить
Сглаживание ВР
Сглаживание ВР позволяет более четко выявить тренд и подготовить

2) Рассчитывается параметр: p=(m-1)/2 .
3) Вычисляется среднее арифметическое значение уровней в
2) Рассчитывается параметр: p=(m-1)/2 .
3) Вычисляется среднее арифметическое значение уровней в
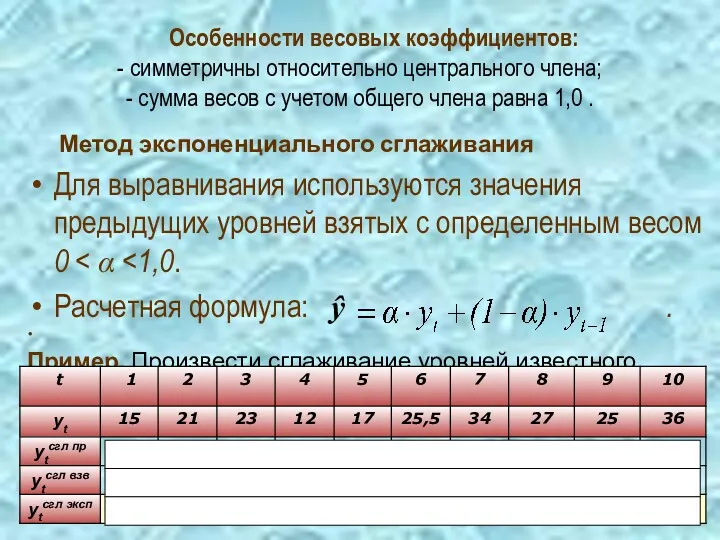
Особенности весовых коэффициентов:
- симметричны относительно центрального члена;
- сумма весов с
Особенности весовых коэффициентов: - симметричны относительно центрального члена; - сумма весов с

Выявление тренда
Тренд – долговременная устойчивая тенденция изменения показателя во времени. Различают
Выявление тренда Тренд – долговременная устойчивая тенденция изменения показателя во времени. Различают

Метод обнаружения тренда - сравнение средних уровней ряда.
Временной ряд разбивают
Метод обнаружения тренда - сравнение средних уровней ряда.
Временной ряд разбивают

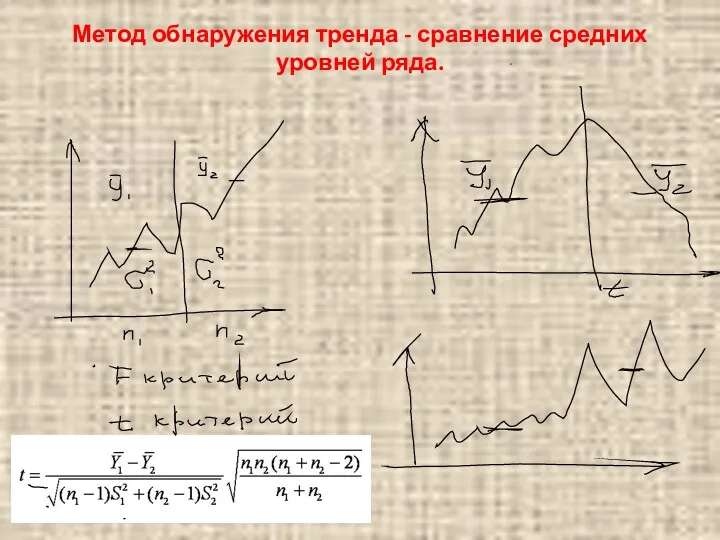
Метод обнаружения тренда - сравнение средних уровней ряда.
Метод обнаружения тренда - сравнение средних уровней ряда.

Построение моделей временных рядов.
Формирование уровней ряда определяется закономерностями трех основных типов:
Построение моделей временных рядов.
Формирование уровней ряда определяется закономерностями трех основных типов:

Модели кривых роста
Плавную кривую (гладкую функцию), аппроксимирующую временной ряд принято называть
Модели кривых роста
Плавную кривую (гладкую функцию), аппроксимирующую временной ряд принято называть

Виды аппроксимирующих функций
В качестве кривых роста для описания тренда могут
Виды аппроксимирующих функций
В качестве кривых роста для описания тренда могут

Расчет параметров модели МНК
Параметры большинства "кривых роста", как правило, оцениваются по
Расчет параметров модели МНК
Параметры большинства "кривых роста", как правило, оцениваются по
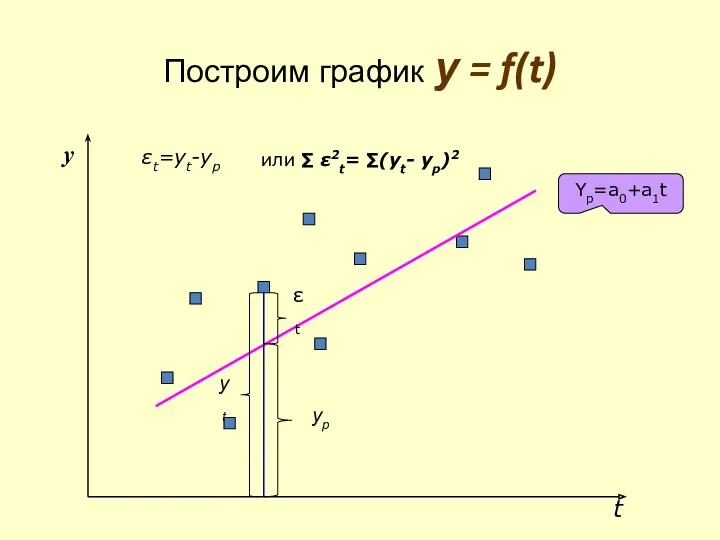
Построим график у = f(t)
t
y
yt
yp
εt
Yp=a0+a1t
εt=yt-yp
или ∑ ε2t= ∑(yt- yp)2
Построим график у = f(t)
t
y
yt
yp
εt
Yp=a0+a1t
εt=yt-yp
или ∑ ε2t= ∑(yt- yp)2

Далее минимизируется сумма квадратов отклонений εt2, для чего вычисляются частные производные
Далее минимизируется сумма квадратов отклонений εt2, для чего вычисляются частные производные

Оценка качества модели
Проверка адекватности
1.Проверка независимости (отсутствие автокорреляции).
2. Проверка случайности.
3. Соответствие ряда
Оценка качества модели
Проверка адекватности
1.Проверка независимости (отсутствие автокорреляции).
2. Проверка случайности.
3. Соответствие ряда

Оценка качества модели прогнозирования
Модель считается хорошей со статистической точки зрения,
Оценка качества модели прогнозирования
Модель считается хорошей со статистической точки зрения,

1) Проверка равенства математического ожидания нулю ( Равенство нулю средней ошибки).
1) Проверка равенства математического ожидания нулю ( Равенство нулю средней ошибки).

2) Проверка условия случайности возникновения отдельных отклонений от тренда
Для проверки случайности
2) Проверка условия случайности возникновения отдельных отклонений от тренда
Для проверки случайности

Проверка случайности.
Критерий поворотных точек (p – критерий)
Данный критерий служит
Проверка случайности.
Критерий поворотных точек (p – критерий)
Данный критерий служит

3) Проверка независимости (отсутствие автокорреляции)
Критерий Дарбина-Уотсона или d – критерий
3) Проверка независимости (отсутствие автокорреляции)
Критерий Дарбина-Уотсона или d – критерий

Проверка независимости (отсутствие автокорреляции)
Проверка независимости (отсутствие автокорреляции)

Рассчитанное значение r (1) сопоставляется с r (1)табл табличным, и если
Рассчитанное значение r (1) сопоставляется с r (1)табл табличным, и если

4) Соответствие ряда остатков нормальному закону распределения
R/S – критерий (нормальность распределения
4) Соответствие ряда остатков нормальному закону распределения R/S – критерий (нормальность распределения

Критерии точности модели
В качестве статистических показателей точности модели применяются:
среднее квадратическое
Критерии точности модели
В качестве статистических показателей точности модели применяются:
среднее квадратическое

Выбор лучшей модели
производится по критериям адекватности и точности.
Лучшей считается та
Выбор лучшей модели
производится по критериям адекватности и точности.
Лучшей считается та
 презентация Сложение
презентация Сложение Натуральные числа и нуль. Множество натуральных чисел и его свойства
Натуральные числа и нуль. Множество натуральных чисел и его свойства Параллелограмм. Свойства параллелограмма
Параллелограмм. Свойства параллелограмма Повторение курса алгебры
Повторение курса алгебры Формирование познавательной учебной деятельности на уроках математики с применением технологии развития критического мышления
Формирование познавательной учебной деятельности на уроках математики с применением технологии развития критического мышления Сложения и вычитания десятичных дробей
Сложения и вычитания десятичных дробей Средняя линия треугольника
Средняя линия треугольника Третий признак равенства треугольников
Третий признак равенства треугольников Презентация непосредственно образовательной деятельности по ФЭМП детей старшего дошкольного возраста. Тема: В поисках сокровищ.
Презентация непосредственно образовательной деятельности по ФЭМП детей старшего дошкольного возраста. Тема: В поисках сокровищ. Проценты в современной жизни
Проценты в современной жизни Вписанная окружность треугольника
Вписанная окружность треугольника Основы образования чертежа. Проецирование плоскости. Метрические задачи. (Лекция 2)
Основы образования чертежа. Проецирование плоскости. Метрические задачи. (Лекция 2) Решение систем рациональных неравенств. 9 класс
Решение систем рациональных неравенств. 9 класс Пирамида
Пирамида Симметрия в пространстве
Симметрия в пространстве Множества точек на координатной прямой. Алгебра 7 класс
Множества точек на координатной прямой. Алгебра 7 класс Сложение и вычитание обыкновенных дробей
Сложение и вычитание обыкновенных дробей Тренажёр по математике 1 класс
Тренажёр по математике 1 класс Прямая и обратная пропорциональные зависимости
Прямая и обратная пропорциональные зависимости Стандартизация в различных сферах
Стандартизация в различных сферах Симетрія відносно точки
Симетрія відносно точки Своя игра математическая
Своя игра математическая Статистические показатели в форме средних величин
Статистические показатели в форме средних величин Координатный угол. 4 класс
Координатный угол. 4 класс 20231114_reshenie_zadach_na_nahozhdeniedrobi_ot_chisla
20231114_reshenie_zadach_na_nahozhdeniedrobi_ot_chisla Решение основных видов неравенств
Решение основных видов неравенств Признаки делимости на 3 и 9
Признаки делимости на 3 и 9 Лекция 7. Постановка задачи нелинейного программирования. Теорема Куна-Таккера
Лекция 7. Постановка задачи нелинейного программирования. Теорема Куна-Таккера