- Кластерный анализ экспериментальных данных

Содержание
- 2. 5.1. Кластерный анализ: цели и задачи Исходные данные для кластерного анализа Цель кластеризации: разбиение всего множества
- 3. 5.2. Меры сходства признаков в общем наборе данных Сходство между факторами Сходство между наблюдениями Матрица сходства
- 4. 5.2. Меры сходства признаков в общем наборе данных Рис. Схема классификации мер сходства для кластеризации признаков
- 5. Порядок вычисления: 1. Подготовить матрицу исходных данных. 2. Перевести значения наблюдаемых признаков в бинарный вид. 3.
- 6. 5.2. Меры сходства признаков в общем наборе данных Положение коэффициента в матрице k l Для каждого
- 7. 5.2. Меры сходства признаков в общем наборе данных Линейный коэффициент корреляции является количественной оценкой линейной взаимосвязи
- 8. 5.2. Меры сходства признаков в общем наборе данных Обозначения: 1 – область сильной линейной зависимости; 2
- 9. 5.2. Меры сходства признаков в общем наборе данных Алгоритм проверки: 1) выдвигается гипотеза H0 о том,
- 10. 5.2. Меры сходства признаков в общем наборе данных Под ранговой корреляцией понимается статистическая связь между ранжировками.
- 11. 5.2. Меры сходства признаков в общем наборе данных Расстояние Евклида между объектами обычно оценивается метрикой: Максимальное
- 12. 5.2. Меры сходства признаков в общем наборе данных Рис. 1. Настройка уровня значимости Рис. 2. Цветовые
- 13. 5.2. Меры сходства признаков в общем наборе данных Рис. 1. Настройка объектов и метода для расчета
- 14. 5.3. Процедуры кластерного анализа данных Рис. 2. Схема неиерархической процедуры кластеризации Рис. 1. Схема классификации процедур
- 15. 5.3. Процедуры кластерного анализа данных Рис. Схемы иерархических процедур кластеризации а б в Агломеративная Дивизимная Комбинированная
- 16. 5.3.2. Агломеративная процедура кластеризации по расстоянию а) в исходной матрице сходства (расстояния) находят два различных, но
- 17. 5.3.2. Агломеративная процедура кластеризации по расстоянию Пусть по результатам наблюдений построена матрица расстояний Требуется выполнить кластеризацию
- 18. 5.3.3. Метод вроцлавской таксономии Дендрит – это такая ломаная, которая может разветвляться, но не может содержать
- 19. 5.3.3. Метод вроцлавской таксономии Пусть по результатам наблюдений построена матрица расстояний Требуется выполнить кластеризацию методом вроцлавской
- 20. 5.3.3. Метод вроцлавской таксономии Упорядочивание связей: i2 Количество кластеров: 3. Количество разрываемых связей: 2. 1 2
- 21. 5.3.4. Метода корреляционных плеяд Алгоритм метода корреляционных плеяд: 1. В матрице коэффициентов межфакторной корреляции находится наибольший
- 22. 5.3.4. Метода корреляционных плеяд Матрица межфакторной корреляции – Итерация 1 x1 x5 0,8 Матрица межфакторной корреляции
- 23. x1 x5 0,8 x4 0,7 x6 0,54 x3 0,75 5.3.4. Метода корреляционных плеяд x2 0,6 Матрица
- 24. 5.3.5. Метода k-средних или алгоритм Лойда 1. Из исходного множества данных случайным образом выбираются k записей,
- 25. 5. Шаги 2, 3, 4 повторяются, пока не будет найдена стабильная конфигурация (то есть кластеры перестанут
- 26. 5.3.5. Метода k-средних или алгоритм Лойда а б в Рис. Диалоговые окна для настройки параметров кластеризации:
- 27. 5.3.5. Метода k-средних или алгоритм Лойда а б в г Рис. Результаты кластеризации: а – расстояние
- 28. 5.3.5. Метода k-средних или алгоритм Лойда а б в г Рис. Результаты кластеризации: а – средние
- 29. Задания к практическому занятию Задание 1 Для исходных данных выполнить расчет матрицы коэффициентов сопоставимости по факторам
- 31. Скачать презентацию
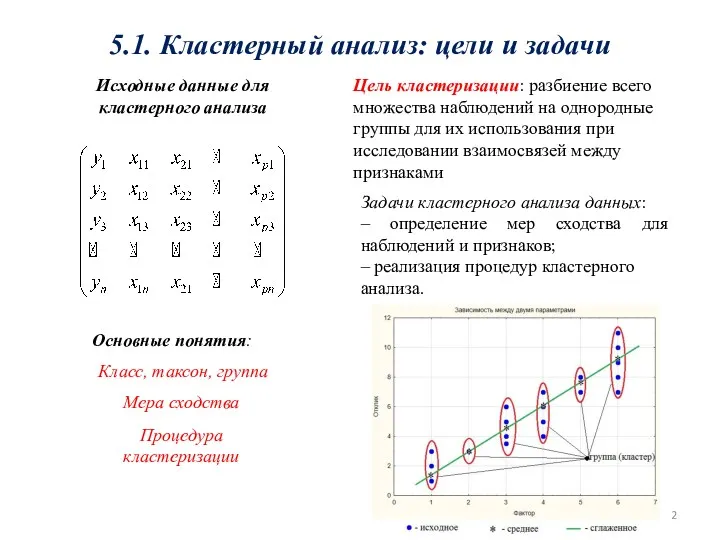
5.1. Кластерный анализ: цели и задачи
Исходные данные для
кластерного анализа
Цель кластеризации:
5.1. Кластерный анализ: цели и задачи
Исходные данные для
кластерного анализа
Цель кластеризации:
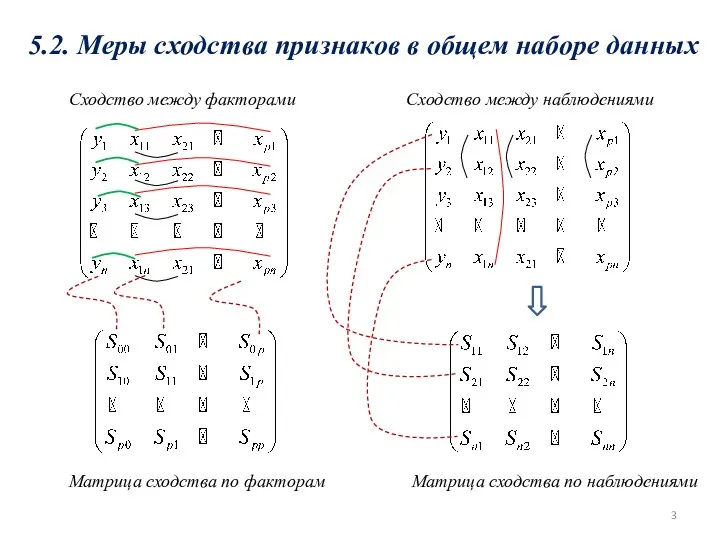
5.2. Меры сходства признаков в общем наборе данных
Сходство между факторами
Сходство между
5.2. Меры сходства признаков в общем наборе данных
Сходство между факторами
Сходство между
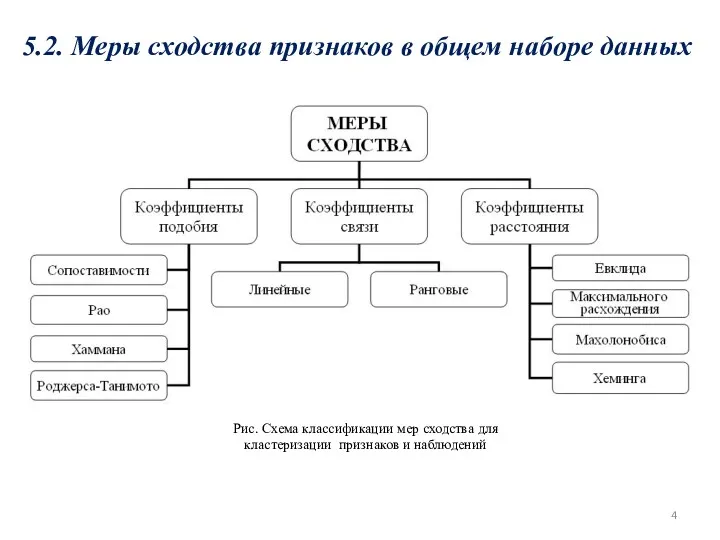
5.2. Меры сходства признаков в общем наборе данных
Рис. Схема классификации мер
5.2. Меры сходства признаков в общем наборе данных
Рис. Схема классификации мер

Порядок вычисления:
1. Подготовить матрицу исходных данных.
2. Перевести значения наблюдаемых
признаков в бинарный
Порядок вычисления:
1. Подготовить матрицу исходных данных.
2. Перевести значения наблюдаемых
признаков в бинарный

5.2. Меры сходства признаков в общем наборе данных
Положение
коэффициента
в матрице
k
l
Для
5.2. Меры сходства признаков в общем наборе данных
Положение
коэффициента
в матрице
k
l
Для

5.2. Меры сходства признаков в общем наборе данных
Линейный коэффициент корреляции является
5.2. Меры сходства признаков в общем наборе данных
Линейный коэффициент корреляции является
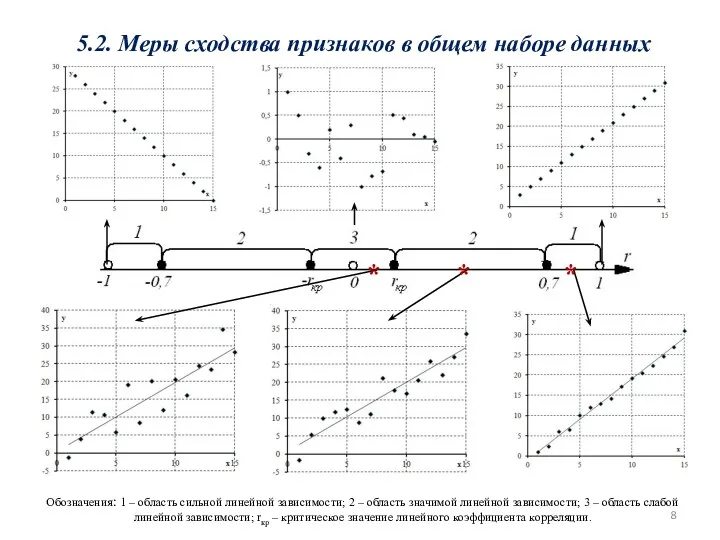
5.2. Меры сходства признаков в общем наборе данных
Обозначения: 1 – область
5.2. Меры сходства признаков в общем наборе данных
Обозначения: 1 – область

5.2. Меры сходства признаков в общем наборе данных
Алгоритм проверки:
1) выдвигается гипотеза
5.2. Меры сходства признаков в общем наборе данных
Алгоритм проверки:
1) выдвигается гипотеза

5.2. Меры сходства признаков в общем наборе данных
Под ранговой корреляцией понимается
5.2. Меры сходства признаков в общем наборе данных
Под ранговой корреляцией понимается

5.2. Меры сходства признаков в общем наборе данных
Расстояние Евклида между объектами
5.2. Меры сходства признаков в общем наборе данных
Расстояние Евклида между объектами
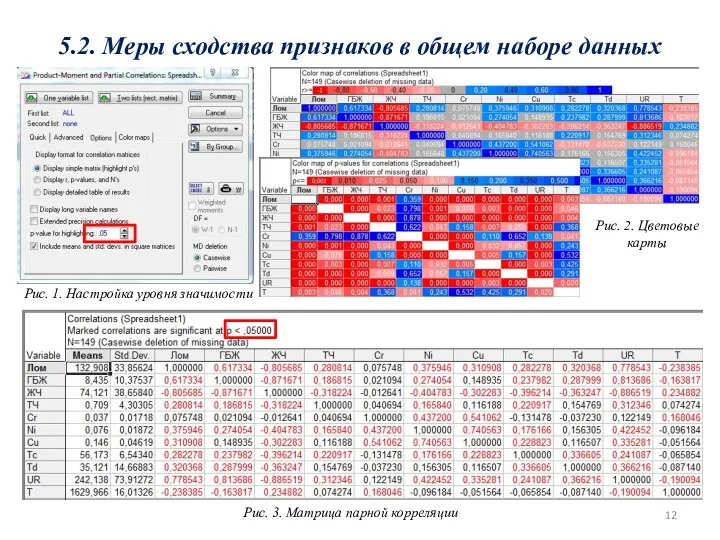
5.2. Меры сходства признаков в общем наборе данных
Рис. 1. Настройка
5.2. Меры сходства признаков в общем наборе данных
Рис. 1. Настройка
5.2. Меры сходства признаков в общем наборе данных
Рис. 1. Настройка
5.2. Меры сходства признаков в общем наборе данных
Рис. 1. Настройка
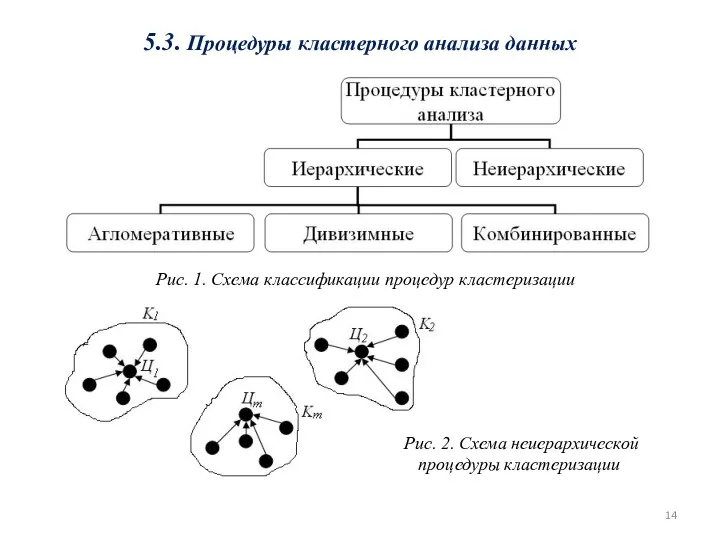
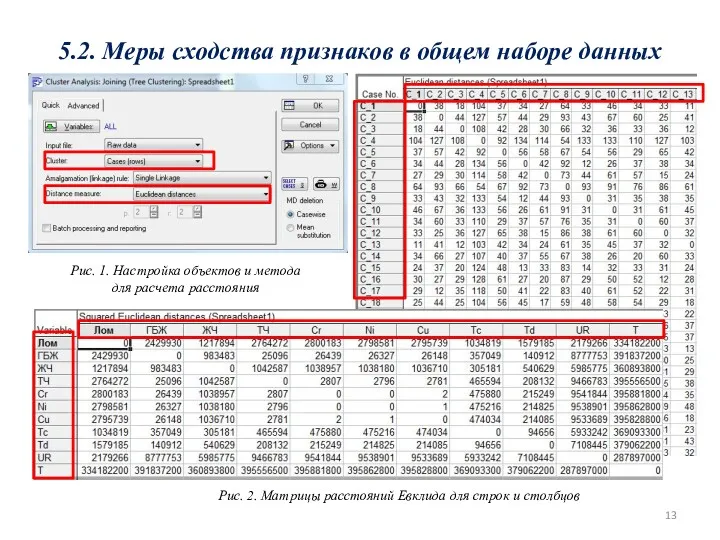
5.3. Процедуры кластерного анализа данных
Рис. 2. Схема неиерархической процедуры кластеризации
Рис. 1.
5.3. Процедуры кластерного анализа данных
Рис. 2. Схема неиерархической процедуры кластеризации
Рис. 1.
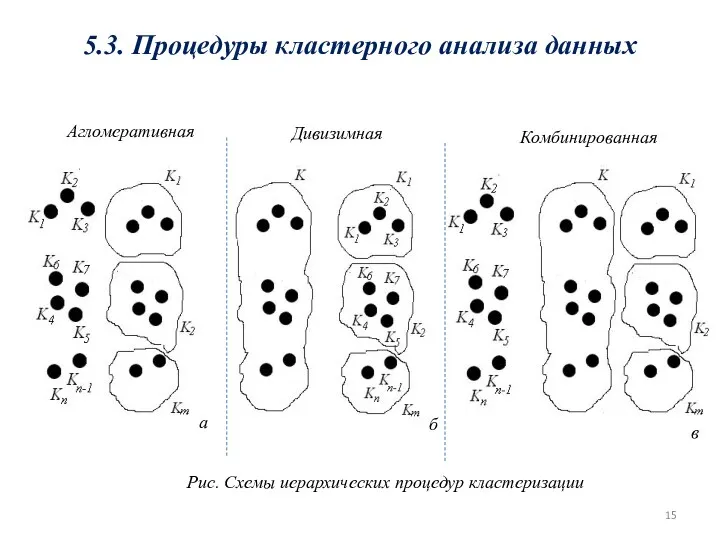
5.3. Процедуры кластерного анализа данных
Рис. Схемы иерархических процедур кластеризации
а
б
в
Агломеративная
Дивизимная
Комбинированная
5.3. Процедуры кластерного анализа данных
Рис. Схемы иерархических процедур кластеризации
а
б
в
Агломеративная
Дивизимная
Комбинированная

5.3.2. Агломеративная процедура кластеризации по расстоянию
а) в исходной матрице сходства (расстояния)
5.3.2. Агломеративная процедура кластеризации по расстоянию
а) в исходной матрице сходства (расстояния)

5.3.2. Агломеративная процедура кластеризации по расстоянию
Пусть по результатам наблюдений построена матрица
5.3.2. Агломеративная процедура кластеризации по расстоянию
Пусть по результатам наблюдений построена матрица

5.3.3. Метод вроцлавской таксономии
Дендрит – это такая ломаная, которая может разветвляться,
5.3.3. Метод вроцлавской таксономии
Дендрит – это такая ломаная, которая может разветвляться,
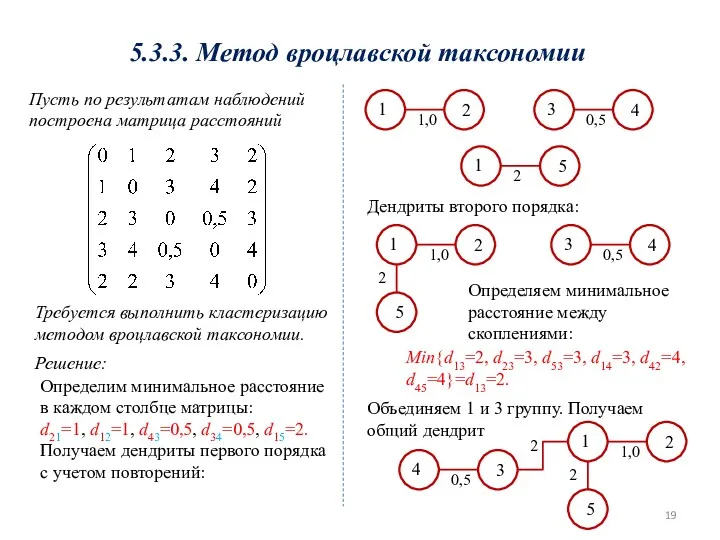
5.3.3. Метод вроцлавской таксономии
Пусть по результатам наблюдений построена матрица расстояний
Требуется выполнить
5.3.3. Метод вроцлавской таксономии
Пусть по результатам наблюдений построена матрица расстояний
Требуется выполнить
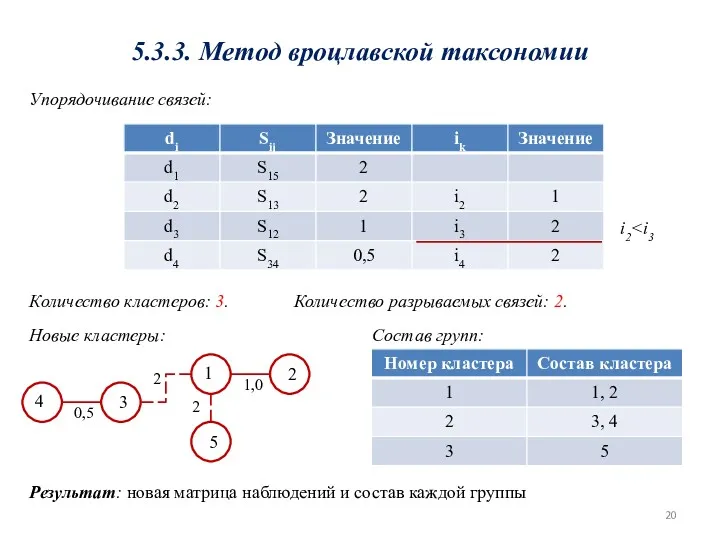
5.3.3. Метод вроцлавской таксономии
Упорядочивание связей:
i2Количество кластеров: 3.
Количество разрываемых связей: 2.
1
2
1,0
5
2
4
3
0,5
2
Новые
5.3.3. Метод вроцлавской таксономии
Упорядочивание связей:
i2 Количество кластеров: 3. Количество разрываемых связей: 2. 1 2 1,0 5 2 4 3 0,5 2 Новые

5.3.4. Метода корреляционных плеяд
Алгоритм метода
корреляционных плеяд:
1. В матрице коэффициентов межфакторной
5.3.4. Метода корреляционных плеяд
Алгоритм метода
корреляционных плеяд:
1. В матрице коэффициентов межфакторной

5.3.4. Метода корреляционных плеяд
Матрица межфакторной корреляции – Итерация 1
x1
x5
0,8
Матрица межфакторной корреляции
5.3.4. Метода корреляционных плеяд
Матрица межфакторной корреляции – Итерация 1
x1
x5
0,8
Матрица межфакторной корреляции

x1
x5
0,8
x4
0,7
x6
0,54
x3
0,75
5.3.4. Метода корреляционных плеяд
x2
0,6
Матрица межфакторной корреляции – Итерация 4
Критическое значение t-статистики:
t(5%,
x1
x5
0,8
x4
0,7
x6
0,54
x3
0,75
5.3.4. Метода корреляционных плеяд
x2
0,6
Матрица межфакторной корреляции – Итерация 4
Критическое значение t-статистики:
t(5%,
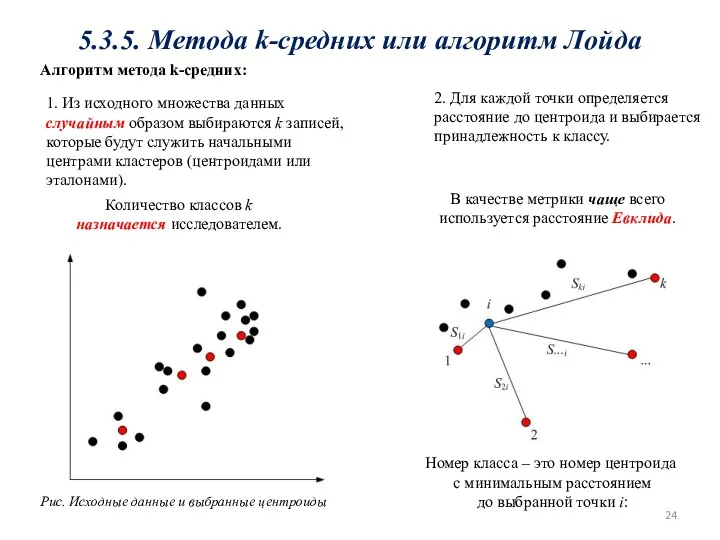
5.3.5. Метода k-средних или алгоритм Лойда
1. Из исходного множества данных случайным
5.3.5. Метода k-средних или алгоритм Лойда
1. Из исходного множества данных случайным

5. Шаги 2, 3, 4 повторяются, пока не будет найдена стабильная
5. Шаги 2, 3, 4 повторяются, пока не будет найдена стабильная
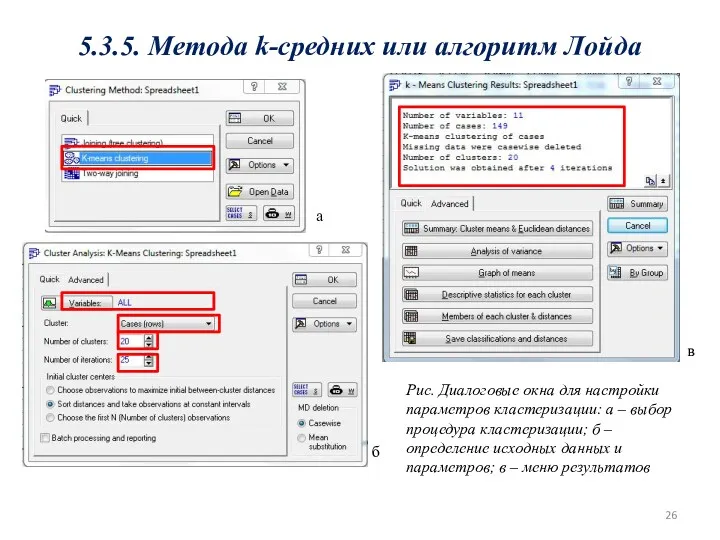
5.3.5. Метода k-средних или алгоритм Лойда
а
б
в
Рис. Диалоговые окна для настройки параметров
5.3.5. Метода k-средних или алгоритм Лойда
а
б
в
Рис. Диалоговые окна для настройки параметров
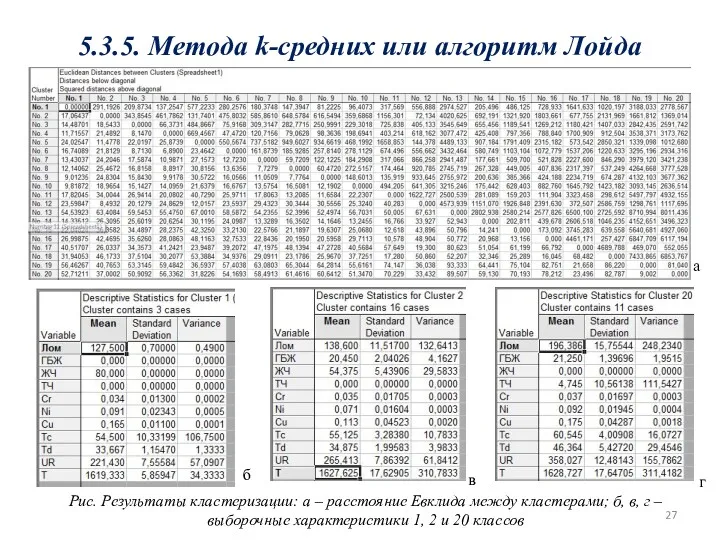
5.3.5. Метода k-средних или алгоритм Лойда
а
б
в
г
Рис. Результаты кластеризации: а – расстояние
5.3.5. Метода k-средних или алгоритм Лойда
а
б
в
г
Рис. Результаты кластеризации: а – расстояние
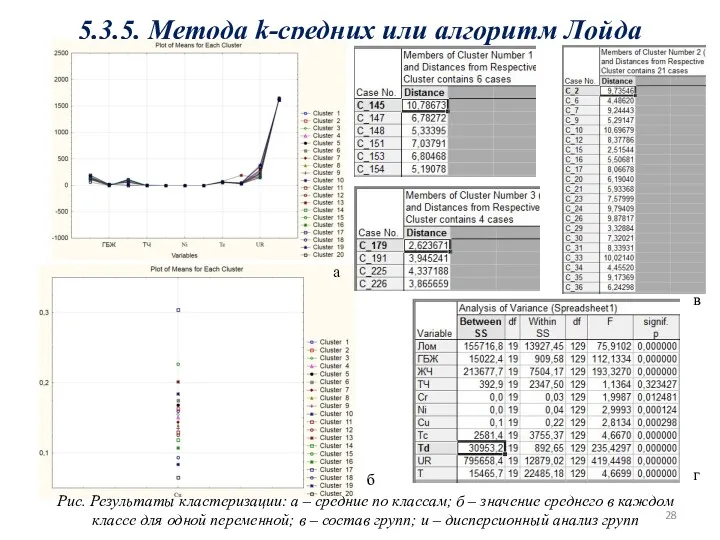
5.3.5. Метода k-средних или алгоритм Лойда
а
б
в
г
Рис. Результаты кластеризации: а – средние
5.3.5. Метода k-средних или алгоритм Лойда
а
б
в
г
Рис. Результаты кластеризации: а – средние

Задания к практическому занятию
Задание 1
Для исходных данных выполнить расчет матрицы коэффициентов
Задания к практическому занятию
Задание 1
Для исходных данных выполнить расчет матрицы коэффициентов
 Объем прямоугольного параллелепипеда, призмы и цилиндра
Объем прямоугольного параллелепипеда, призмы и цилиндра Временные ряды в эконометрических исследованиях
Временные ряды в эконометрических исследованиях Образование чисел из одного десятка и нескольких единиц. 1 класс
Образование чисел из одного десятка и нескольких единиц. 1 класс Центральная симметрия
Центральная симметрия Решение комбинаторных задач. Приложение к уроку № 3
Решение комбинаторных задач. Приложение к уроку № 3 конспект и презентация урока по математике 3 класс Квадратный метр
конспект и презентация урока по математике 3 класс Квадратный метр Решение типовых задач алгебры и анализа
Решение типовых задач алгебры и анализа Квадратный трехчлен
Квадратный трехчлен Интегральные исчисления
Интегральные исчисления Математик на фабрике обоев или алгоритмическое рисование узоров
Математик на фабрике обоев или алгоритмическое рисование узоров Геометрична прогресія
Геометрична прогресія Координатная плоскость
Координатная плоскость Конспект урока математики в 3 классе на тему Закрепление таблицы умножения с использованием ИКТ. По УМК Школа России в рамках ФГОС НОО с нововведениями сингапурской системы.
Конспект урока математики в 3 классе на тему Закрепление таблицы умножения с использованием ИКТ. По УМК Школа России в рамках ФГОС НОО с нововведениями сингапурской системы. Математическое описание САР в статистике и динамике
Математическое описание САР в статистике и динамике Параллельный перенос
Параллельный перенос Компьютерный практикум по алгебре в среде Matlab. Практическое занятие 7
Компьютерный практикум по алгебре в среде Matlab. Практическое занятие 7 Использование счётных палочек Кюизенера для обучения детей математике в ДОУ.
Использование счётных палочек Кюизенера для обучения детей математике в ДОУ. Интерактивное пособие для подготовки к ОГЭ. Окружность
Интерактивное пособие для подготовки к ОГЭ. Окружность Сложение и вычитание многочленов. 7 класс
Сложение и вычитание многочленов. 7 класс Единица длины – дециметр
Единица длины – дециметр Плоскость. Прямая. Луч
Плоскость. Прямая. Луч Приближенное решение нелинейных уравнений. Метод хорд
Приближенное решение нелинейных уравнений. Метод хорд Логиканың негізі. Логикалық ойларды айту. Логикалық байланыстар
Логиканың негізі. Логикалық ойларды айту. Логикалық байланыстар Точность и погрешность измерений
Точность и погрешность измерений Рациональные числа. Иррациональные числа
Рациональные числа. Иррациональные числа Умножение на 1 и на 0
Умножение на 1 и на 0 График линейного уравнения с двумя переменными
График линейного уравнения с двумя переменными Линейная алгебра и аналитическая геометрия. Матрицы
Линейная алгебра и аналитическая геометрия. Матрицы