- Параметрические и непараметрические методы статистики

Содержание
- 2. ВВЕДЕНИЕ Вектор состояния P (P1,P2,P3…Pn) – набор функциональных параметров организма, который позволяет описать его состояние в
- 3. Cреднее и доверительный интервал. Вероятно, большинство из вас использовало такую важную описательную статистику, как среднее. Среднее
- 4. Форма распределения; нормальность. Важным способом "описания" переменной является форма ее распределения, которая показывает, с какой частотой
- 5. 1. Определение вектора состояния в норме
- 6. 1. Определение вектора состояния в норме
- 7. 1. Определение вектора состояния в норме
- 8. 1. Определение вектора состояния при заболевании Отличия: 3. РАСПРЕДЕЛЕНИЯ НЕ СИММЕТРИЧНЫ 1. 2.
- 9. Объем выборки. Другим фактором, часто ограничивающим применимость критериев, основанных на предположении нормальности, является объем или размер
- 10. Две основные задачи статистики 1.Нахождение различий выборок 2. Нахождение связи между выборками Для нахождения различий между
- 11. Большие массивы данных и непараметрические методы. Непараметрические методы наиболее приемлемы, когда объем выборок мал. Если данных
- 12. Параметрический Т- критерий Стьюдента. то с вероятностью w выборки, а следовательно и состояния различны.
- 13. Критические значения коэффициентов Стьюдента t для выборки объема n и заданной доверительной вероятности ω
- 14. основан на подсчете однонаправленных эффектов в парных сравнениях; применяется для связанных (парных) выборок. Критерий знаков (КЗ)
- 15. Максимальное число знаков (менее часто встречающихся), при которых различия в парных сравнениях можно считать существенными Из
- 16. Основан на сравнении двух рядов наблюдений в общем упорядоченном ряду. Применяется для независимых выборок. Критерий Q
- 17. Критерий Q Розенбаума Пример: Сравнить max артериальное давление в мм. рт.ст. у детей с разными по
- 18. Критические значения Q-критерия Розенбаума. Минимальные значения Q, при которых различия между двумя выборками можно считать значимыми
- 19. Корреляционный и регрессионный анализ связь как синхронность (согласованность) – корреляционный анализ. связь как зависимость (влияние) –
- 20. Выявление наличия связи между параметрами Пример положительной функциональной связи между параметрами X и Y. Чем больше
- 21. Пример положительной статистической связи между параметрами X и Y.
- 22. Пример отрицательной функциональной связи между параметрами X и Y. Чем больше значения одного параметра, тем меньше
- 23. Пример отрицательной статистической связи между параметрами X и Y.
- 24. Определение силы (тесноты) связи Коэффициент парной корреляции показывает, насколько тесно две переменные связаны между собой. Коэффициент
- 25. Коэффициент корреляции Мера тесноты линейной связи Если r = 1, то между двумя переменными существует функциональная
- 26. Коэффициент корреляции Мера тесноты линейной связи Если r = -1, то между двумя переменными существует функциональная
- 27. Коэффициент корреляции Мера тесноты линейной связи Если r = 0, то рассматриваемые переменные линейно независимы, т.е.
- 28. Коэффициент корреляции вычисляется для количественных признаков; симметричен; величина безразмерная; не изменяется при изменении единиц измерения параметров
- 29. Коэффициент корреляции и детерминации если две переменные линейно независимы (метод наименьших квадратов дает горизонтальную прямую), то
- 30. 2. Подбор формы связи Линейная и нелинейная связь Отсутствие связи между параметрами
- 31. 2. Подбор формы связи МЕТОД НАИМЕНЬШИХ КВАДРАТОВ ЛИНИЯ РЕГРЕССИИ. Сумма квадратов расстояний от точек на диаграмме
- 32. Коэффициенты аппроксимирующих формул Если связь есть, то ее можно описать с помощью аппроксимирующей формулы. Вводим данные
- 33. Если распределение не является нормальным, то можно перейти к непараметрическим коэффициентам корреляции, одинаково пригодным при любом
- 35. Формула для расчета коэффициента ранговой корреляции Спирмена
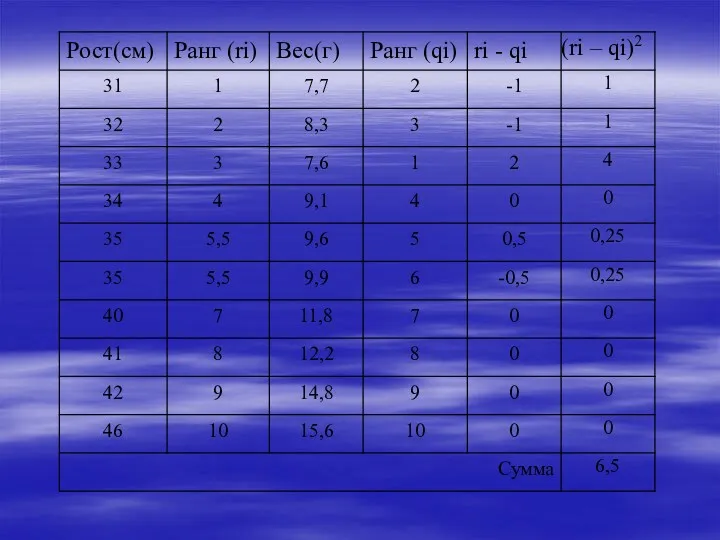
- 36. Обратимся к таблице критических значений коэффициента ранговой корреляции Спирмена Критическое значение для уровня значимости 0,01 и
- 37. Пакеты программ для статистической обработки медицинской и биологической информации
- 38. О современных системах статистического анализа на персональных компьютерах STATISTICA SPSS S-плюс SAS MStat
- 39. Реализован графически-ориентированный подход к анализу данных Система STATISTICA StatSoft
- 40. Система STATISTICA состоит из отдельных модулей, покрывающих весь спектр современных методов анализа данных.
- 41. Гибкий интерфейс, отвечающий всем стандартам Windows, позволяет настроить систему под конкретный проект, связанный с анализом медицинских
- 42. Основные этапы анализа данных Подготовка данных: заполнение таблиц, импорт, проверка и сортировка. Разведочный анализ: основные статистики
- 43. Типы медицинской информации Массовые обследования (десятки тысяч наблюдений и сотни показателей). Результаты клинических исследований (наблюдения за
- 44. Подготовка информации Импорт из баз данных, текстовых файлов или электронных таблиц. Динамический обмен данными (DDE) с
- 45. Исследуется прибор для неинвазивного измерения содержания билирубина в крови. Измерения в разных точках тела коррелируют с
- 46. www.statsoft.ru Учебник содержит разделы по методам статистического анализа данных и предназначен в первую очередь для тех,
- 47. СПАСИБО ЗА ВНИМАНИЕ!!
- 49. Скачать презентацию

ВВЕДЕНИЕ
Вектор состояния P (P1,P2,P3…Pn) – набор функциональных параметров организма, который позволяет
ВВЕДЕНИЕ
Вектор состояния P (P1,P2,P3…Pn) – набор функциональных параметров организма, который позволяет

Cреднее и доверительный интервал. Вероятно, большинство из вас использовало такую важную
Cреднее и доверительный интервал. Вероятно, большинство из вас использовало такую важную

Форма распределения; нормальность.
Важным способом "описания" переменной является форма ее распределения,
Форма распределения; нормальность.
Важным способом "описания" переменной является форма ее распределения,
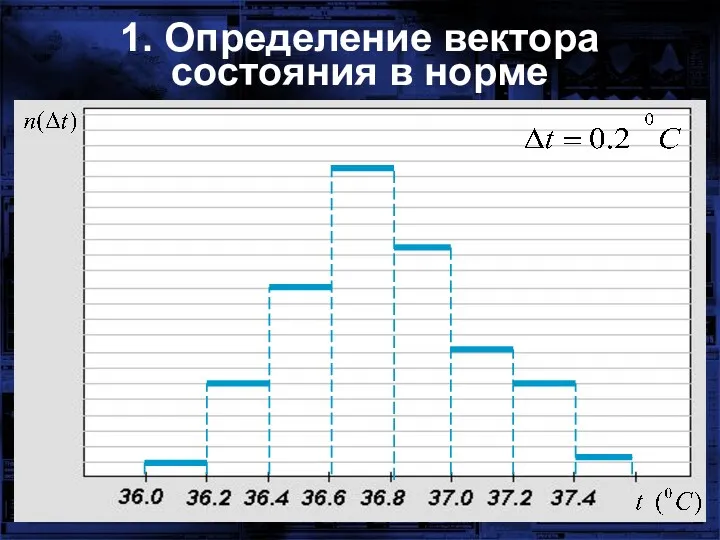
1. Определение вектора состояния в норме
1. Определение вектора состояния в норме
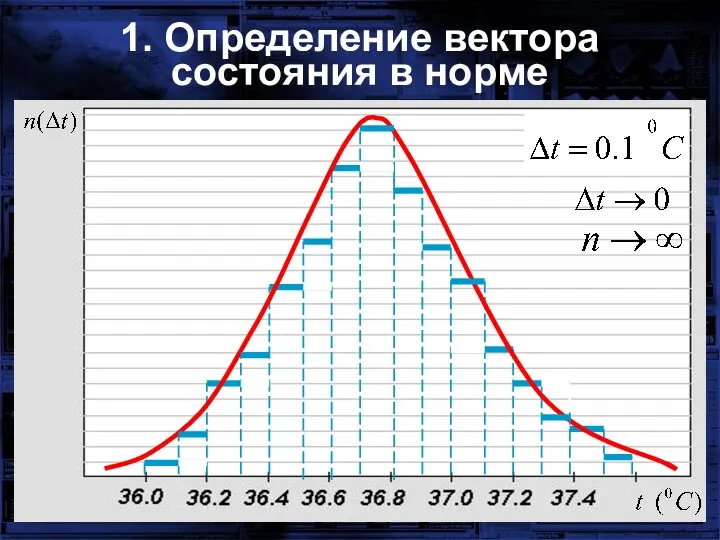
1. Определение вектора состояния в норме
1. Определение вектора состояния в норме
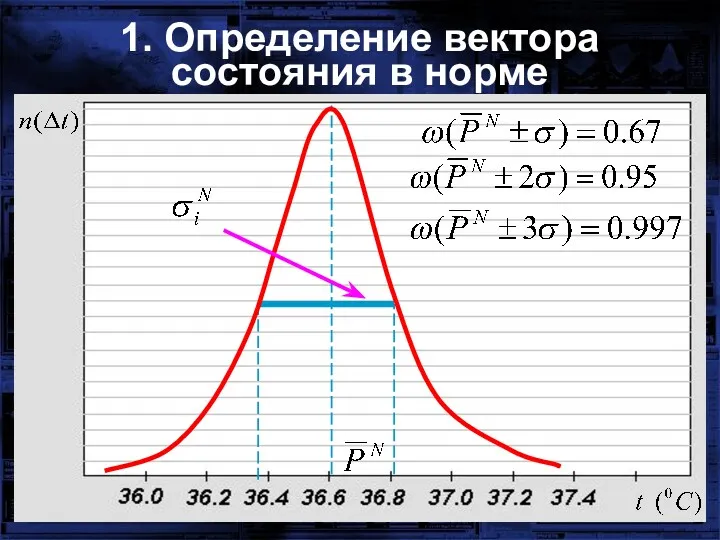
1. Определение вектора состояния в норме
1. Определение вектора состояния в норме
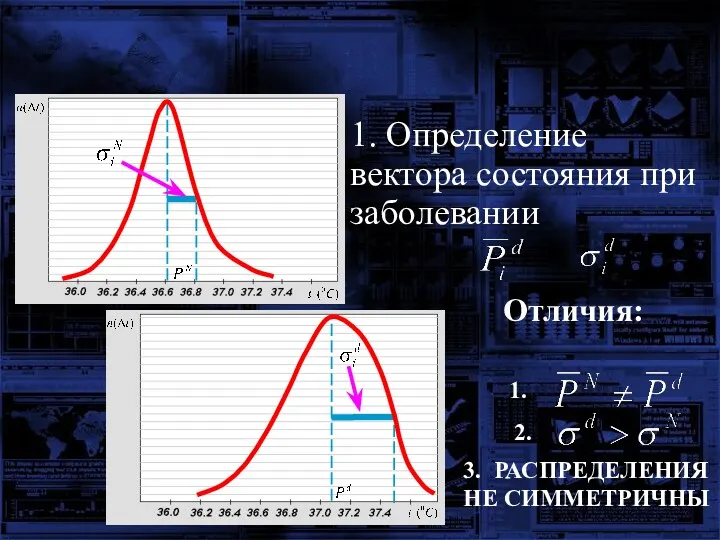
1. Определение вектора состояния при заболевании
Отличия:
3. РАСПРЕДЕЛЕНИЯ НЕ СИММЕТРИЧНЫ
1.
2.
1. Определение вектора состояния при заболевании
Отличия:
3. РАСПРЕДЕЛЕНИЯ НЕ СИММЕТРИЧНЫ
1.
2.

Объем выборки.
Другим фактором, часто ограничивающим применимость критериев, основанных на
Объем выборки.
Другим фактором, часто ограничивающим применимость критериев, основанных на

Две основные задачи статистики
1.Нахождение различий выборок
2. Нахождение связи между выборками
Для нахождения
Две основные задачи статистики
1.Нахождение различий выборок
2. Нахождение связи между выборками
Для нахождения

Большие массивы данных и непараметрические методы.
Непараметрические методы наиболее приемлемы, когда
Большие массивы данных и непараметрические методы.
Непараметрические методы наиболее приемлемы, когда

Параметрический Т- критерий Стьюдента.
то с вероятностью w выборки, а следовательно и
Параметрический Т- критерий Стьюдента.
то с вероятностью w выборки, а следовательно и
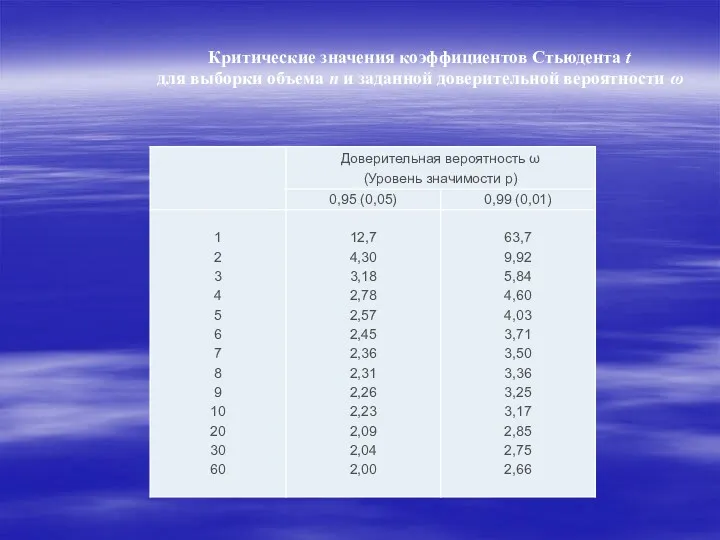
Критические значения коэффициентов Стьюдента t
для выборки объема n и заданной доверительной
Критические значения коэффициентов Стьюдента t
для выборки объема n и заданной доверительной

основан на подсчете однонаправленных эффектов в парных сравнениях;
применяется для связанных (парных)
основан на подсчете однонаправленных эффектов в парных сравнениях;
применяется для связанных (парных)
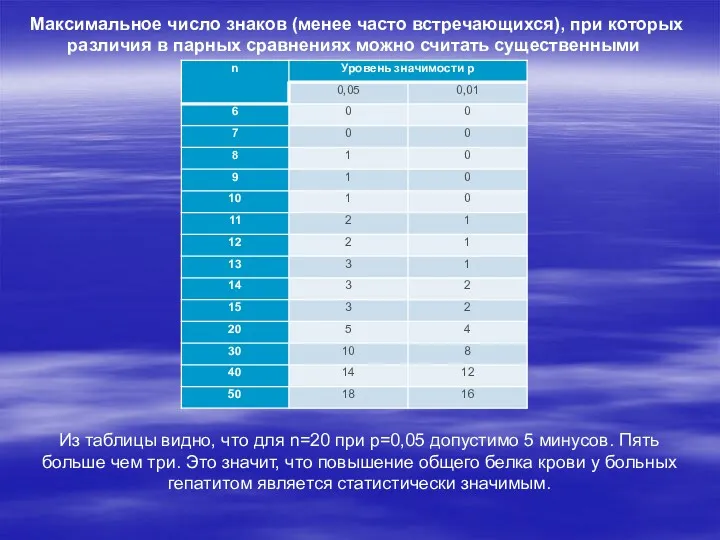
Максимальное число знаков (менее часто встречающихся), при которых различия в парных
Максимальное число знаков (менее часто встречающихся), при которых различия в парных

Основан на сравнении двух рядов наблюдений в общем упорядоченном ряду. Применяется
Основан на сравнении двух рядов наблюдений в общем упорядоченном ряду. Применяется

Критерий Q Розенбаума
Пример:
Сравнить max артериальное давление в мм. рт.ст. у детей
Критерий Q Розенбаума
Пример:
Сравнить max артериальное давление в мм. рт.ст. у детей

Критические значения Q-критерия Розенбаума.
Минимальные значения Q, при которых различия между
Критические значения Q-критерия Розенбаума. Минимальные значения Q, при которых различия между

Корреляционный и регрессионный анализ
связь как синхронность (согласованность) – корреляционный анализ.
связь как
Корреляционный и регрессионный анализ
связь как синхронность (согласованность) – корреляционный анализ.
связь как
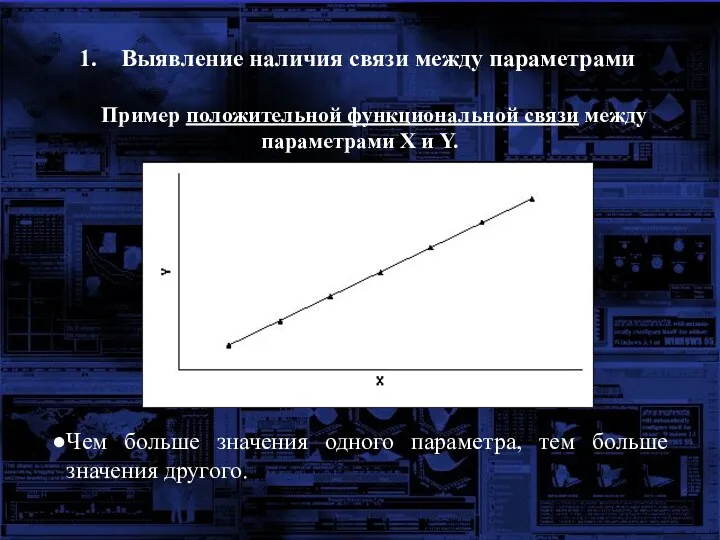
Выявление наличия связи между параметрами
Пример положительной функциональной связи между параметрами X
Выявление наличия связи между параметрами
Пример положительной функциональной связи между параметрами X
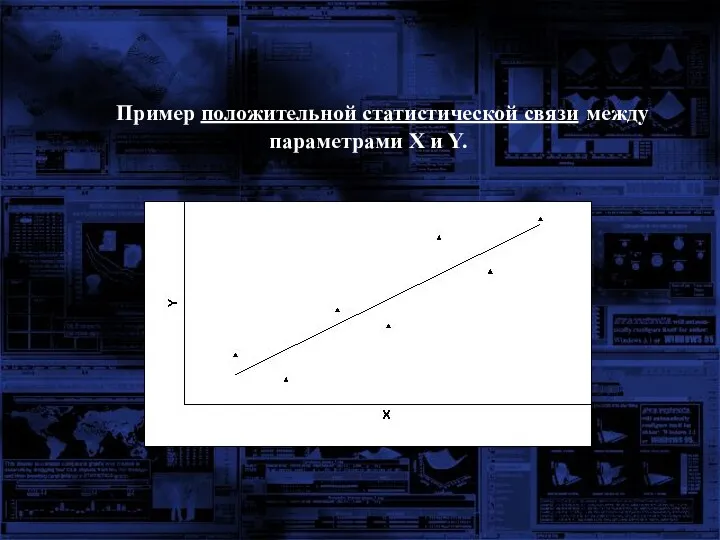
Пример положительной статистической связи между параметрами X и Y.
Пример положительной статистической связи между параметрами X и Y.
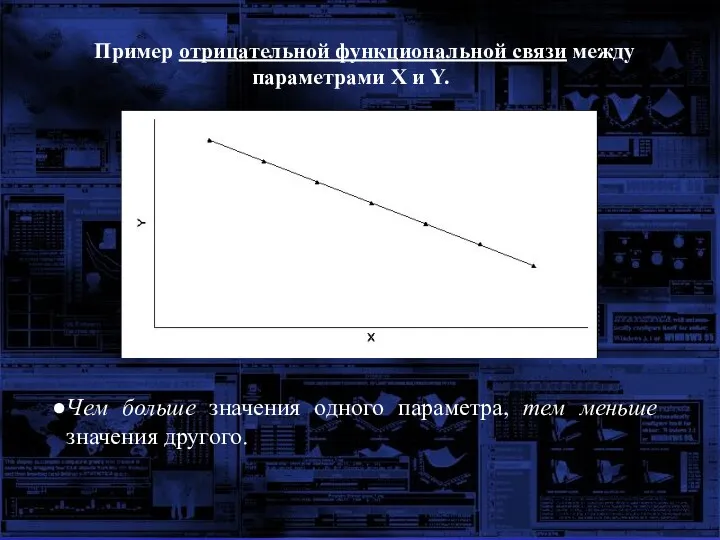
Пример отрицательной функциональной связи между параметрами X и Y.
Чем больше
Пример отрицательной функциональной связи между параметрами X и Y.
Чем больше
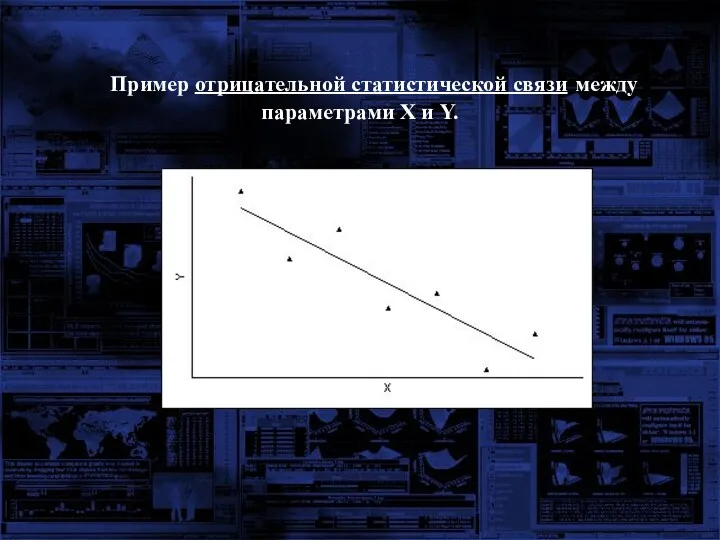
Пример отрицательной статистической связи между параметрами X и Y.
Пример отрицательной статистической связи между параметрами X и Y.
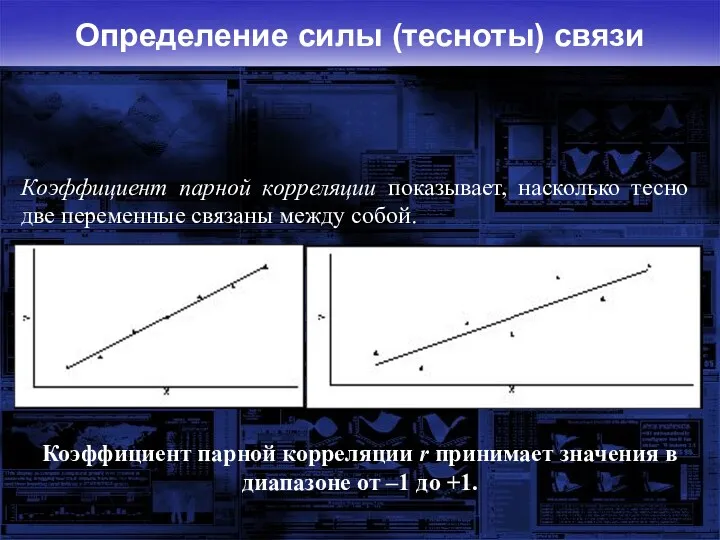
Определение силы (тесноты) связи
Коэффициент парной корреляции показывает, насколько тесно две переменные
Определение силы (тесноты) связи
Коэффициент парной корреляции показывает, насколько тесно две переменные
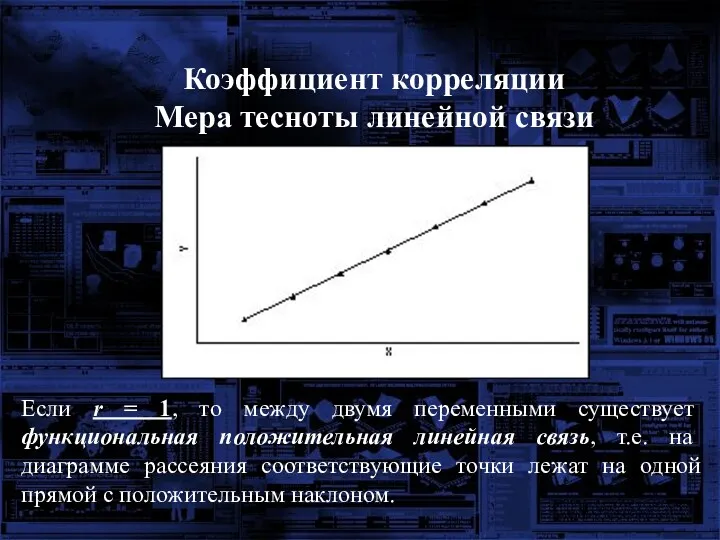
Коэффициент корреляции
Мера тесноты линейной связи
Если r = 1, то между двумя
Коэффициент корреляции
Мера тесноты линейной связи
Если r = 1, то между двумя
Коэффициент корреляции
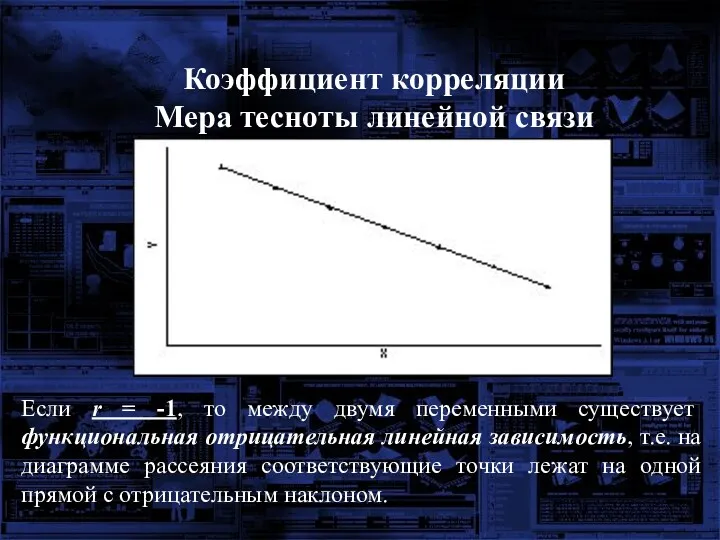
Мера тесноты линейной связи
Если r = -1, то между двумя
Коэффициент корреляции
Мера тесноты линейной связи
Если r = -1, то между двумя

Коэффициент корреляции
Мера тесноты линейной связи
Если r = 0, то рассматриваемые переменные
Коэффициент корреляции
Мера тесноты линейной связи
Если r = 0, то рассматриваемые переменные

Коэффициент корреляции
вычисляется для количественных признаков;
симметричен;
величина безразмерная;
не изменяется при изменении единиц измерения
Коэффициент корреляции
вычисляется для количественных признаков;
симметричен;
величина безразмерная;
не изменяется при изменении единиц измерения

Коэффициент корреляции и детерминации
если две переменные линейно независимы (метод
Коэффициент корреляции и детерминации
если две переменные линейно независимы (метод
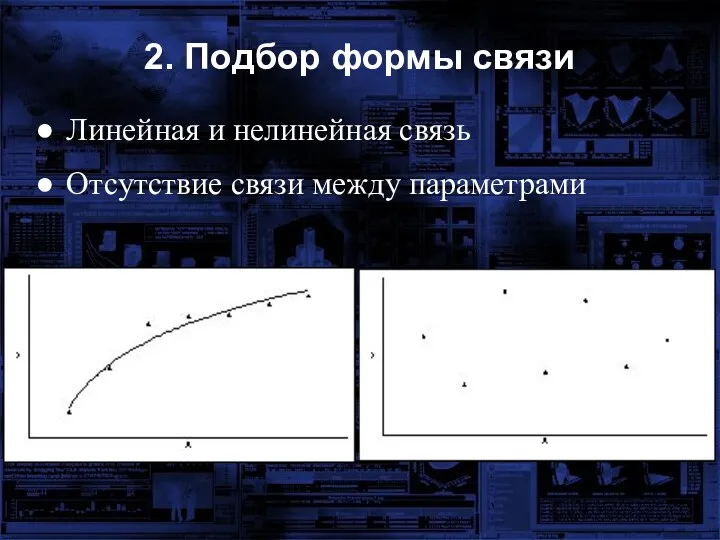
2. Подбор формы связи
Линейная и нелинейная связь
Отсутствие связи между параметрами
2. Подбор формы связи
Линейная и нелинейная связь
Отсутствие связи между параметрами
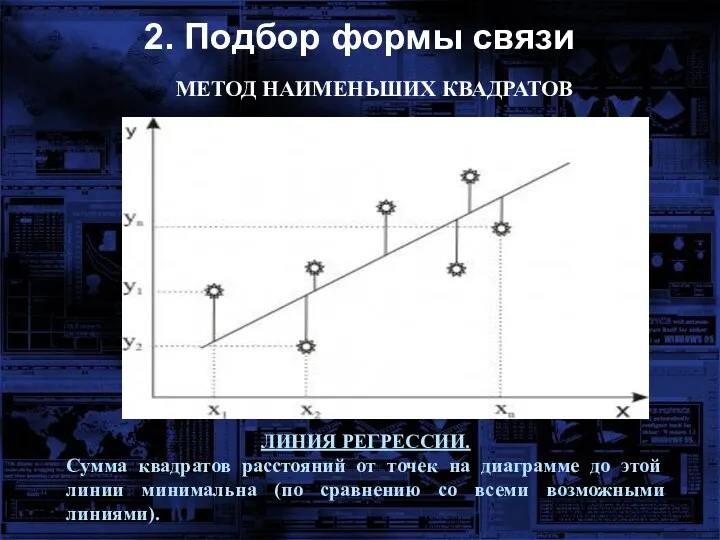
2. Подбор формы связи
МЕТОД НАИМЕНЬШИХ КВАДРАТОВ
ЛИНИЯ РЕГРЕССИИ.
Сумма квадратов расстояний от точек
2. Подбор формы связи
МЕТОД НАИМЕНЬШИХ КВАДРАТОВ
ЛИНИЯ РЕГРЕССИИ.
Сумма квадратов расстояний от точек

Коэффициенты аппроксимирующих формул
Если связь есть, то ее можно описать с помощью
Коэффициенты аппроксимирующих формул
Если связь есть, то ее можно описать с помощью
Если распределение не является нормальным, то можно перейти к непараметрическим коэффициентам
Если распределение не является нормальным, то можно перейти к непараметрическим коэффициентам

Формула для расчета коэффициента ранговой корреляции Спирмена
Формула для расчета коэффициента ранговой корреляции Спирмена
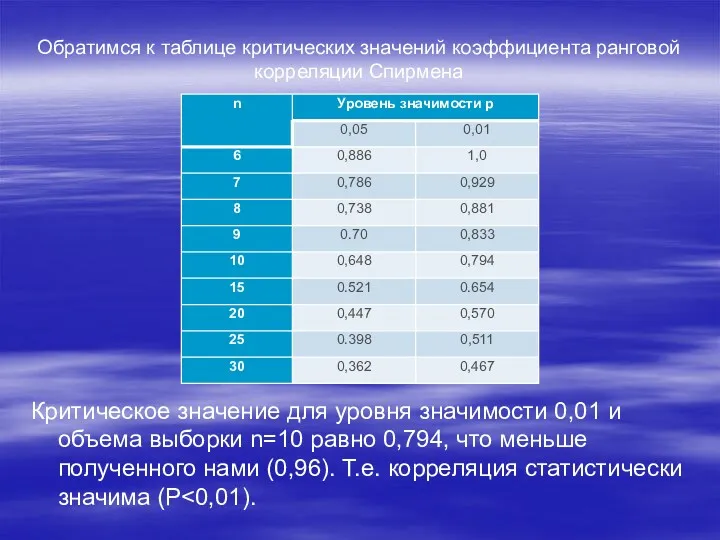
Обратимся к таблице критических значений коэффициента ранговой корреляции Спирмена
Критическое значение для
Обратимся к таблице критических значений коэффициента ранговой корреляции Спирмена
Критическое значение для

Пакеты программ для статистической обработки медицинской и биологической информации
Пакеты программ для статистической обработки медицинской и биологической информации

О современных системах статистического анализа на персональных компьютерах
STATISTICA
SPSS
S-плюс
SAS
MStat
О современных системах статистического анализа на персональных компьютерах
STATISTICA
SPSS
S-плюс
SAS
MStat
Реализован графически-ориентированный подход к анализу данных
Система STATISTICA
StatSoft
Реализован графически-ориентированный подход к анализу данных
Система STATISTICA
StatSoft
Система STATISTICA состоит из отдельных модулей, покрывающих весь спектр современных методов
Система STATISTICA состоит из отдельных модулей, покрывающих весь спектр современных методов

Гибкий интерфейс, отвечающий всем стандартам Windows, позволяет настроить систему под конкретный
Гибкий интерфейс, отвечающий всем стандартам Windows, позволяет настроить систему под конкретный

Основные этапы анализа данных
Подготовка данных: заполнение таблиц, импорт, проверка и сортировка.
Разведочный
Основные этапы анализа данных
Подготовка данных: заполнение таблиц, импорт, проверка и сортировка.
Разведочный
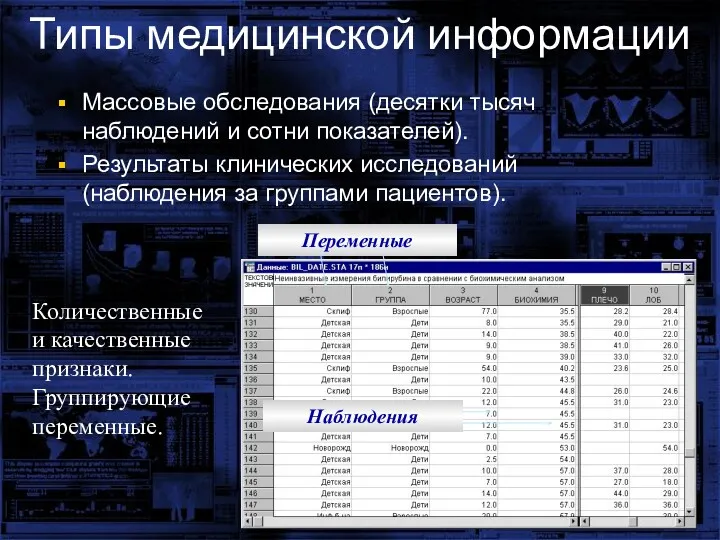
Типы медицинской информации
Массовые обследования (десятки тысяч наблюдений и сотни показателей).
Результаты клинических
Типы медицинской информации
Массовые обследования (десятки тысяч наблюдений и сотни показателей).
Результаты клинических
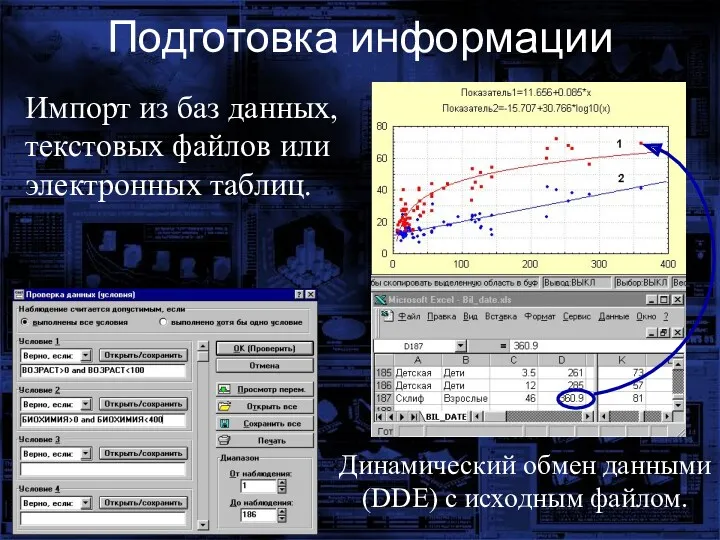
Подготовка информации
Импорт из баз данных, текстовых файлов или электронных таблиц.
Динамический обмен
Подготовка информации
Импорт из баз данных, текстовых файлов или электронных таблиц.
Динамический обмен

Исследуется прибор для неинвазивного измерения содержания билирубина в крови. Измерения в
Исследуется прибор для неинвазивного измерения содержания билирубина в крови. Измерения в

www.statsoft.ru
Учебник содержит разделы по методам статистического анализа данных и предназначен в
www.statsoft.ru
Учебник содержит разделы по методам статистического анализа данных и предназначен в

СПАСИБО ЗА ВНИМАНИЕ!!
СПАСИБО ЗА ВНИМАНИЕ!!
 Действия с дробями. Нахождение целого по его части
Действия с дробями. Нахождение целого по его части Методическая разработка к уроку математики для 2 класса. Тема: Сложение однозначных чисел с переходом через разряд
Методическая разработка к уроку математики для 2 класса. Тема: Сложение однозначных чисел с переходом через разряд Занимательная математика. Танграм
Занимательная математика. Танграм Математика. 2 класс
Математика. 2 класс История космонавтики в цифрах
История космонавтики в цифрах Викторина для 5 - 6 классов
Викторина для 5 - 6 классов Четыре замечательные точки треугольника
Четыре замечательные точки треугольника Сложение и вычитание чисел, запись которых оканчивается нулями. Устные приёмы
Сложение и вычитание чисел, запись которых оканчивается нулями. Устные приёмы Компоненты сложения и вычитания
Компоненты сложения и вычитания Статистика. Абсолютные и относительные показатели
Статистика. Абсолютные и относительные показатели Двугранные углы
Двугранные углы Линейные и нелинейные критерии. Нормализация и свертка критериев. Масштабирование
Линейные и нелинейные критерии. Нормализация и свертка критериев. Масштабирование Степень числа. Квадрат и куб числа
Степень числа. Квадрат и куб числа Задачи, раскрывающие смысл действия деления
Задачи, раскрывающие смысл действия деления Описательная статистика. Показатели формы распределения. (Лекция 3)
Описательная статистика. Показатели формы распределения. (Лекция 3) Квадратичная функция. Построение графика квадратичной функции
Квадратичная функция. Построение графика квадратичной функции Относительная частота и закон больших чисел (9 класс)
Относительная частота и закон больших чисел (9 класс) Тест Координатная плоскость. Математика. 6 класс
Тест Координатная плоскость. Математика. 6 класс Первообразная. Правило нахождения первообразной. Неопределенный интеграл
Первообразная. Правило нахождения первообразной. Неопределенный интеграл Лас су желісі
Лас су желісі Умножение числа 2 и на 2
Умножение числа 2 и на 2 Понятие корня n-ой степени из действительного числа
Понятие корня n-ой степени из действительного числа Проценты. Как найти число по его проценту
Проценты. Как найти число по его проценту Понятие алгоритма и способы записи алгоритмов. (урок 1)
Понятие алгоритма и способы записи алгоритмов. (урок 1) Приём сложения однозначных чисел с переходом через десяток
Приём сложения однозначных чисел с переходом через десяток Подобные треугольники
Подобные треугольники Примеры сокращения дробей (для быстрого рационального счёта)
Примеры сокращения дробей (для быстрого рационального счёта) Экономическая задача в ЕГЭ по математике
Экономическая задача в ЕГЭ по математике