- Проверка качества уравнения регрессии

Содержание
- 2. Цели лекции Выполнимость теоретических предпосылок Анализ расчетных статистических показателей качества Интерпретация регрессии
- 3. Случайные составляющие коэффициентов регрессии После определения оценок b0 и b1 возникают вопросы: насколько точно эмпирическое уравнение
- 4. Свойства оценок коэффициентов регрессии Оценки b0 и b1 представляют собой случайные величины, зависящие от случайного члена
- 5. Свойства оценок коэффициентов регрессии Представим выборочную ковариацию Sxy в виде: Sxy = Cov(X,β0+β1X+ε) = Cov(X,β0) +
- 6. Свойства оценок коэффициентов регрессии Свойства оценок коэффициентов регрессии, а следовательно, и качество построенного уравнения регрессии существенно
- 7. Свойства оценок коэффициентов регрессии Доказано, что для получения по МНК наилучших результатов (при этом оценки bi
- 8. Предпосылки использования МНК (условия Гаусса – Маркова) 10. Случайное отклонение имеет нулевое математическое ожидание. 20. Дисперсия
- 9. Предпосылки использования МНК (условия Гаусса – Маркова) 10. Случайное отклонение имеет нулевое математическое ожидание. Данное условие
- 10. Предпосылки использования МНК (условия Гаусса – Маркова) 20. Дисперсия случайного отклонения постоянна. Из данного условия следует,
- 11. Предпосылки использования МНК (условия Гаусса – Маркова) 30. Наблюдаемые значения случайных отклонений независимы друг от друга.
- 12. Предпосылки использования МНК (условия Гаусса – Маркова) 40. Случайное отклонение д.б. независимо от объясняющей переменной. Это
- 13. Предпосылки использования МНК (условия Гаусса – Маркова) 50. Регрессионная модель является линейной относительно параметров, корректно специфицирована
- 14. Предпосылки использования МНК (условия Гаусса – Маркова) 60. Наряду с выполнимостью указанных предпосылок при построении линейных
- 15. Теорема Гаусса - Маркова Теорема. Если предпосылки 10 – 50 выполнены, то оценки, полученные по МНК,
- 16. Типичная картина выполнения условий Гаусса – Маркова
- 17. Типичная картина нарушения условий 20 и 40: D[ε] = const, Cov(εi,Xi) = 0
- 18. Типичная картина нарушения условия 30: Cov(εi,εj) = 0, i ≠ j
- 19. Система показателей качества парной регрессии 1. Показатели качества коэффициентов регрессии 2. Показатели качества уравнения регрессии в
- 20. Показатели качества коэффициентов регрессии 1. Стандартные ошибки оценок (анализ точности определения оценок). 2. Значения t-статистик (проверка
- 21. Стандартные ошибки оценок Оценки b0 и b1 являются случайными величинами. Отсюда следует, что стандартные ошибки коэффициентов
- 22. Свойства дисперсий оценок 1. Дисперсии D[b0] и D[b1] прямо пропорциональны дисперсии случайного отклонения σε2. Следовательно, чем
- 23. Расчет стандартных ошибок Заменив σε2 на ее несмещенную оценку получим:
- 24. Формулы расчета стандартных ошибок оценок Стандартные ошибки коэффициентов регрессии: Стандартная ошибка является оценкой среднего квадратического отклонения
- 25. Использование стандартных ошибок Сравнивая значение коэффициента с его стандартной ошибкой, можно судить о значимости коэффициента Коэффициент
- 26. Проверка значимости на основе t-статистик Проверка значимости на основе t-статистик заключается в установлении наличия линейной зависимости
- 27. Проверка значимости на основе t-статистик Если принимается гипотеза H0, то считают, что величина Y не зависит
- 28. Значимость свободного члена Аналогично проверяется значимость коэффициента b0. Однако мы должны быть осторожны в сильном выделении
- 29. t-статистики для проверки значимости коэффициентов регрессии t-статистика соизмеряет значение коэффициента с его стандартной ошибкой:
- 30. t-статистики для проверки значимости коэффициентов регрессии t-статистики в парной регрессии по n наблюдениям при справедливости гипотезы
- 31. Порядок работы при проверке значимости коэффициента по t-статистике 1. Выбираем уровень значимости α (1% или 5%).
- 32. Использование односторонних гипотез для проверки значимости коэффициентов Использование односторонних гипотез иногда позволяет «спасти» значимость коэффициентов регрессии
- 33. Пример (A). Проверка значимости Критическое значение при уровне значимости α = 0,05:
- 34. Пример (A). Проверка значимости Поэтому нулевая гипотеза H0: {β1 = 0} отвергается в пользу альтернативной при
- 35. Пример (A). Проверка значимости Гипотеза о статистической незначимости b0 не отклоняется. Это означает, что свободным членом
- 36. Правило оценки значимости коэффициентов регрессии без использования таблиц 1. Если , то коэффициент bi не м.б.
- 37. Интервальные оценки коэффициентов линейного уравнения регрессии Построение доверительных интервалов для коэффициентов линейной регрессии при заданном уровне
- 38. Порядок работы при проверке значимости коэффициента по доверительному интервалу 1. Выбираем уровень значимости α (1% или
- 39. Доверительные области для зависимой переменной Одной из центральных задач эконометрики является прогнозирование значений зависимой переменной при
- 40. Предсказание среднего значения зависимой переменной Пусть построено уравнение регрессии На его основе необходимо предсказать условное м.
- 41. Предсказание среднего значения зависимой переменной Доверительная область для условного м. о. M[Y/X = xp]: При она
- 42. Предсказание индивидуальных значений зависимой переменной Построенная доверительная область для Mx[Y] определяет местоположение модельной линии регрессии (условного
- 43. Предсказание индивидуальных значений зависимой переменной Доверительная область для прогнозов индивидуальных значений имеет вид: Доверительная область для
- 44. Графики доверительных областей для зависимой переменной
- 45. Выводы по доверительным областям для зависимой переменной 1. Прогноз значений зависимой переменной Y по уравнению регрессии
- 46. Пример (А). Доверительные области для зависимой переменной 1. Рассчитаем 95%-й доверительный интервал для условного м.о. при
- 47. Пример (А). Доверительные области для зависимой переменной 2. Границы 95%-го доверительного интервала для индивидуальных объемов потребления
- 48. Показатели качества уравнения регрессии в целом Суть проверки общего качества уравнения регрессии – оценить насколько хорошо
- 49. Коэффициент детерминации R2 Коэффициент R2 показывает долю объясненной вариации зависимой переменной: Используется для предварительной оценки качества
- 50. Основные свойства коэффициента детерминации 0 ≤ R2 ≤ 1. Чем ближе R2 к 1, тем лучше
- 51. Пример (А). Расчет коэффициента детерминации
- 52. F-тест на качество оценивания уравнения регрессии Основан на основном тождестве дисперсионного анализа TSS – общая сумма
- 53. F-статистика для проверки качества уравнения регрессии F-статистика представляет собой отношение объясненной суммы квадратов (в расчете на
- 54. F-статистика для проверки качества уравнения регрессии При отсутствии линейной зависимости между зависимой и объясняющими(ей) переменными F-статистика
- 55. F-статистика для проверки качества парного уравнения регрессии В парной (m = 1) регрессии F-статистика является отношением
- 56. Порядок работы при проверке значимости парного уравнения по F-статистике 1. Выбираем уровень значимости α (1% или
- 57. Связь между значимостью коэффициента регрессии и уравнения в целом В парной регрессии F-статистика равна квадрату t-статистики;
- 58. Коэффициент корреляции rxy Коэффициент корреляции указывает на наличие (или отсутствие) линейной связи между зависимой и объясняющей
- 59. Взаимосвязь критериев в парном регрессионном анализе Коэффициент корреляции по абсолютной величине совпадает с квадратным корнем из
- 60. Проверка значимости коэффициента детерминации Критическое значение R2 связано с критическим значением F-статистики Проверка значимости коэффициента детерминации
- 61. Сумма квадратов остатков RSS Является оценкой необъясненной части вариации зависимой переменной Используется как основная минимизируемая величина
- 62. Стандартная ошибка регрессии Se Является оценкой величины квадрата ошибки, приходящейся на одну степень свободы модели Используется
- 63. Средняя ошибка аппроксимации A Оценку качества модели дает также средняя ошибка аппроксимации – среднее отклонение расчетных
- 64. Типичные ошибки в использовании показателей качества регрессии Величина коэффициентов регрессии не указывает на силу связи или
- 65. Ограниченность простой регрессии 1. Никакая единственная переменная за редкими исключениями не в состоянии хорошо «объяснить» изменения
- 67. Скачать презентацию

Цели лекции
Выполнимость теоретических предпосылок
Анализ расчетных статистических показателей качества
Интерпретация регрессии
Цели лекции
Выполнимость теоретических предпосылок
Анализ расчетных статистических показателей качества
Интерпретация регрессии

Случайные составляющие коэффициентов регрессии
После определения оценок b0 и b1 возникают
Случайные составляющие коэффициентов регрессии
После определения оценок b0 и b1 возникают

Свойства оценок коэффициентов регрессии
Оценки b0 и b1 представляют собой случайные
величины, зависящие
Свойства оценок коэффициентов регрессии
Оценки b0 и b1 представляют собой случайные
величины, зависящие

Свойства оценок коэффициентов регрессии
Представим выборочную ковариацию Sxy в виде:
Sxy = Cov(X,β0+β1X+ε)
Свойства оценок коэффициентов регрессии
Представим выборочную ковариацию Sxy в виде:
Sxy = Cov(X,β0+β1X+ε)

Свойства оценок коэффициентов регрессии
Свойства оценок коэффициентов регрессии, а
следовательно, и качество построенного
уравнения
Свойства оценок коэффициентов регрессии
Свойства оценок коэффициентов регрессии, а
следовательно, и качество построенного
уравнения

Свойства оценок коэффициентов регрессии
Доказано, что для получения по МНК наилучших результатов
Свойства оценок коэффициентов регрессии
Доказано, что для получения по МНК наилучших результатов

Предпосылки использования МНК (условия Гаусса – Маркова)
10. Случайное отклонение имеет нулевое
Предпосылки использования МНК (условия Гаусса – Маркова)
10. Случайное отклонение имеет нулевое

Предпосылки использования МНК (условия Гаусса – Маркова)
10. Случайное отклонение имеет нулевое
Предпосылки использования МНК (условия Гаусса – Маркова)
10. Случайное отклонение имеет нулевое

Предпосылки использования МНК (условия Гаусса – Маркова)
20. Дисперсия случайного отклонения постоянна.
Из
Предпосылки использования МНК (условия Гаусса – Маркова)
20. Дисперсия случайного отклонения постоянна.
Из

Предпосылки использования МНК (условия Гаусса – Маркова)
30. Наблюдаемые значения случайных отклонений
Предпосылки использования МНК (условия Гаусса – Маркова)
30. Наблюдаемые значения случайных отклонений

Предпосылки использования МНК (условия Гаусса – Маркова)
40. Случайное отклонение д.б. независимо
Предпосылки использования МНК (условия Гаусса – Маркова)
40. Случайное отклонение д.б. независимо

Предпосылки использования МНК (условия Гаусса – Маркова)
50. Регрессионная модель является линейной
Предпосылки использования МНК (условия Гаусса – Маркова)
50. Регрессионная модель является линейной

Предпосылки использования МНК (условия Гаусса – Маркова)
60. Наряду с выполнимостью указанных
Предпосылки использования МНК (условия Гаусса – Маркова)
60. Наряду с выполнимостью указанных

Теорема Гаусса - Маркова
Теорема. Если предпосылки 10 – 50 выполнены, то
Теорема Гаусса - Маркова
Теорема. Если предпосылки 10 – 50 выполнены, то
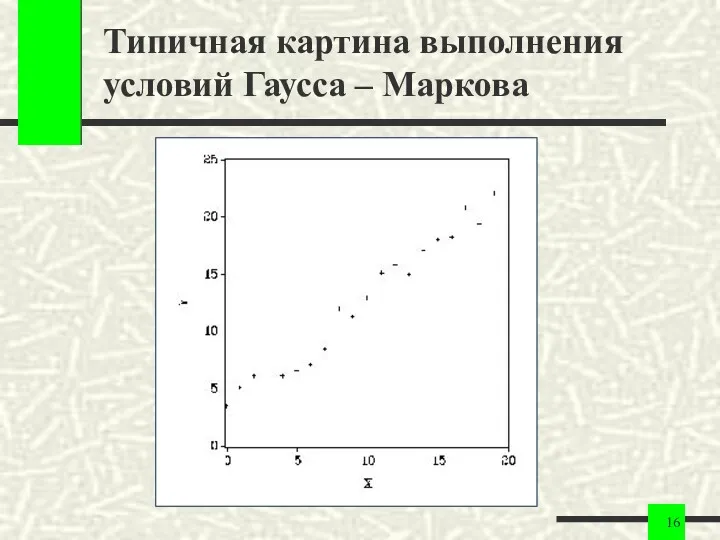
Типичная картина выполнения условий Гаусса – Маркова
Типичная картина выполнения условий Гаусса – Маркова
![Типичная картина нарушения условий 20 и 40: D[ε] = const, Cov(εi,Xi) = 0](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/210807/slide-16.jpg)
Типичная картина нарушения условий 20 и 40: D[ε] = const, Cov(εi,Xi)
Типичная картина нарушения условий 20 и 40: D[ε] = const, Cov(εi,Xi)
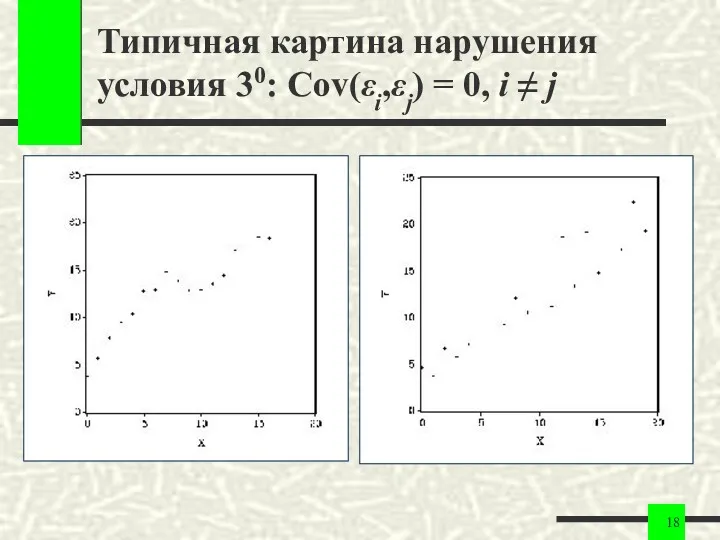
Типичная картина нарушения условия 30: Cov(εi,εj) = 0, i ≠ j
Типичная картина нарушения условия 30: Cov(εi,εj) = 0, i ≠ j

Система показателей качества парной регрессии
1. Показатели качества коэффициентов регрессии
2. Показатели качества
Система показателей качества парной регрессии
1. Показатели качества коэффициентов регрессии
2. Показатели качества

Показатели качества коэффициентов регрессии
1. Стандартные ошибки оценок (анализ точности определения оценок).
2.
Показатели качества коэффициентов регрессии
1. Стандартные ошибки оценок (анализ точности определения оценок).
2.

Стандартные ошибки оценок
Оценки b0 и b1 являются случайными величинами. Отсюда
следует, что
Стандартные ошибки оценок
Оценки b0 и b1 являются случайными величинами. Отсюда
следует, что
![Свойства дисперсий оценок 1. Дисперсии D[b0] и D[b1] прямо пропорциональны](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/210807/slide-21.jpg)
Свойства дисперсий оценок
1. Дисперсии D[b0] и D[b1] прямо пропорциональны дисперсии случайного
Свойства дисперсий оценок
1. Дисперсии D[b0] и D[b1] прямо пропорциональны дисперсии случайного

Расчет стандартных ошибок
Заменив σε2 на ее несмещенную оценку
получим:
Расчет стандартных ошибок
Заменив σε2 на ее несмещенную оценку
получим:

Формулы расчета стандартных ошибок оценок
Стандартные ошибки коэффициентов регрессии:
Стандартная ошибка является оценкой
Формулы расчета стандартных ошибок оценок
Стандартные ошибки коэффициентов регрессии:
Стандартная ошибка является оценкой

Использование стандартных ошибок
Сравнивая значение коэффициента с его
стандартной ошибкой, можно судить о
значимости
Использование стандартных ошибок
Сравнивая значение коэффициента с его
стандартной ошибкой, можно судить о
значимости

Проверка значимости на основе t-статистик
Проверка значимости на основе t-статистик
заключается в установлении
Проверка значимости на основе t-статистик
Проверка значимости на основе t-статистик
заключается в установлении

Проверка значимости на основе t-статистик
Если принимается гипотеза H0, то считают, что
Проверка значимости на основе t-статистик
Если принимается гипотеза H0, то считают, что

Значимость свободного члена
Аналогично проверяется значимость коэффициента b0.
Однако мы должны быть осторожны
Значимость свободного члена
Аналогично проверяется значимость коэффициента b0.
Однако мы должны быть осторожны

t-статистики для проверки значимости коэффициентов регрессии
t-статистика соизмеряет значение коэффициента
с его стандартной
t-статистики для проверки значимости коэффициентов регрессии
t-статистика соизмеряет значение коэффициента
с его стандартной
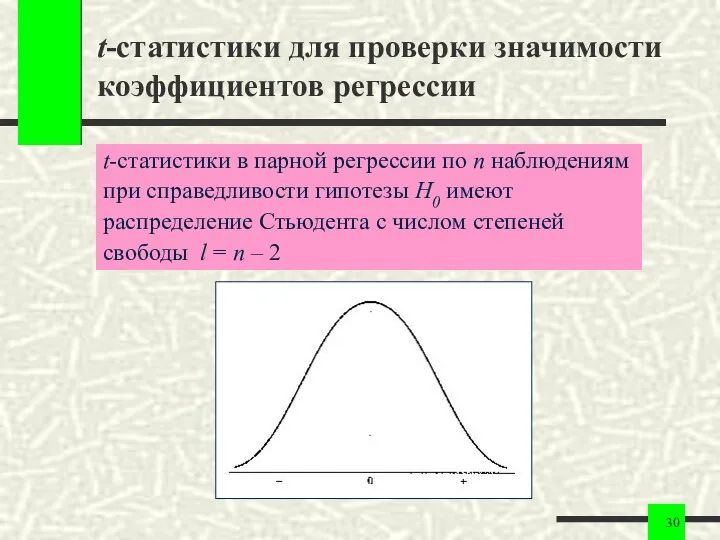
t-статистики для проверки значимости коэффициентов регрессии
t-статистики в парной регрессии по n
t-статистики для проверки значимости коэффициентов регрессии
t-статистики в парной регрессии по n

Порядок работы при проверке значимости коэффициента по t-статистике
1. Выбираем уровень значимости
Порядок работы при проверке значимости коэффициента по t-статистике
1. Выбираем уровень значимости
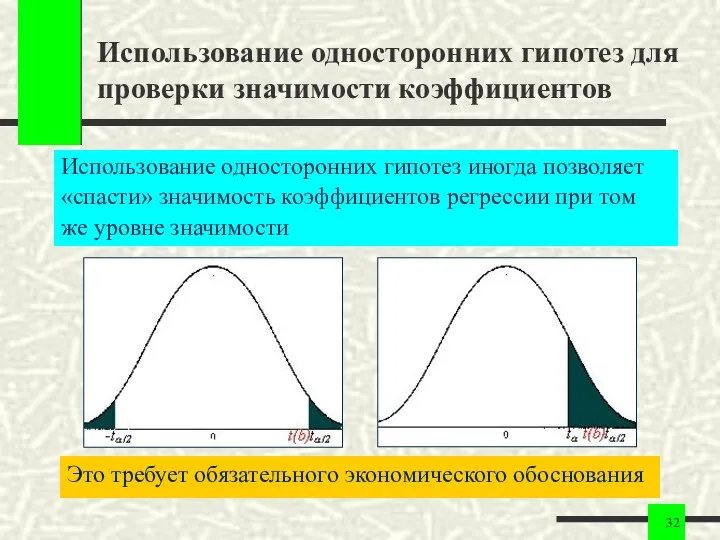
Использование односторонних гипотез для проверки значимости коэффициентов
Использование односторонних гипотез иногда позволяет
«спасти»
Использование односторонних гипотез для проверки значимости коэффициентов
Использование односторонних гипотез иногда позволяет
«спасти»

Пример (A). Проверка значимости
Критическое значение при уровне значимости α = 0,05:
Пример (A). Проверка значимости
Критическое значение при уровне значимости α = 0,05:

Пример (A). Проверка значимости
Поэтому нулевая гипотеза H0: {β1 = 0} отвергается
Пример (A). Проверка значимости
Поэтому нулевая гипотеза H0: {β1 = 0} отвергается

Пример (A). Проверка значимости
Гипотеза о статистической незначимости b0 не отклоняется.
Это означает,
Пример (A). Проверка значимости
Гипотеза о статистической незначимости b0 не отклоняется.
Это означает,

Правило оценки значимости коэффициентов регрессии без использования таблиц
1. Если , то
Правило оценки значимости коэффициентов регрессии без использования таблиц
1. Если , то

Интервальные оценки коэффициентов линейного уравнения регрессии
Построение доверительных интервалов для коэффициентов
линейной регрессии
Интервальные оценки коэффициентов линейного уравнения регрессии
Построение доверительных интервалов для коэффициентов
линейной регрессии

Порядок работы при проверке значимости коэффициента по доверительному интервалу
1. Выбираем уровень
Порядок работы при проверке значимости коэффициента по доверительному интервалу
1. Выбираем уровень

Доверительные области для зависимой переменной
Одной из центральных задач эконометрики является
прогнозирование значений
Доверительные области для зависимой переменной
Одной из центральных задач эконометрики является
прогнозирование значений

Предсказание среднего значения зависимой переменной
Пусть построено уравнение регрессии
На его основе
Предсказание среднего значения зависимой переменной
Пусть построено уравнение регрессии
На его основе

Предсказание среднего значения зависимой переменной
Доверительная область для условного м. о. M[Y/X
Предсказание среднего значения зависимой переменной
Доверительная область для условного м. о. M[Y/X
![Предсказание индивидуальных значений зависимой переменной Построенная доверительная область для Mx[Y]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/210807/slide-41.jpg)
Предсказание индивидуальных значений зависимой переменной
Построенная доверительная область для Mx[Y] определяет
местоположение модельной
Предсказание индивидуальных значений зависимой переменной
Построенная доверительная область для Mx[Y] определяет
местоположение модельной

Предсказание индивидуальных значений зависимой переменной
Доверительная область для прогнозов индивидуальных
значений имеет вид:
Доверительная
Предсказание индивидуальных значений зависимой переменной
Доверительная область для прогнозов индивидуальных
значений имеет вид:
Доверительная
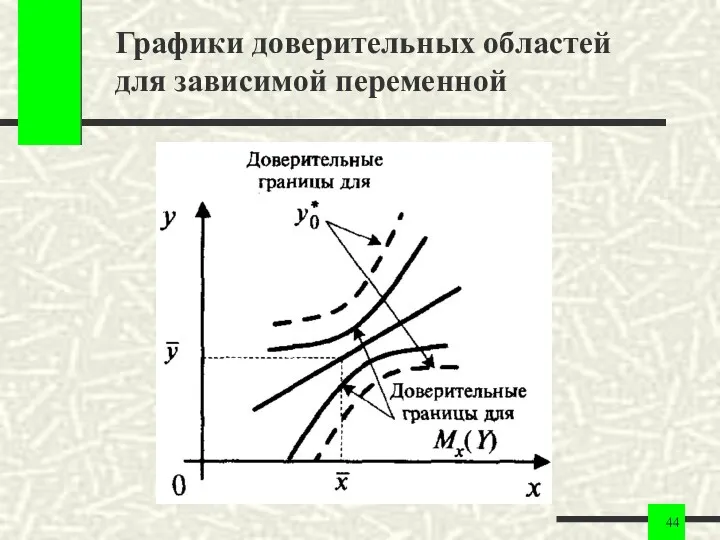
Графики доверительных областей для зависимой переменной
Графики доверительных областей для зависимой переменной

Выводы по доверительным областям для зависимой переменной
1. Прогноз значений зависимой переменной
Выводы по доверительным областям для зависимой переменной
1. Прогноз значений зависимой переменной

Пример (А). Доверительные области для зависимой переменной
1. Рассчитаем 95%-й доверительный интервал
Пример (А). Доверительные области для зависимой переменной
1. Рассчитаем 95%-й доверительный интервал

Пример (А). Доверительные области для зависимой переменной
2. Границы 95%-го доверительного интервала
Пример (А). Доверительные области для зависимой переменной
2. Границы 95%-го доверительного интервала

Показатели качества уравнения регрессии в целом
Суть проверки общего качества уравнения регрессии
Показатели качества уравнения регрессии в целом
Суть проверки общего качества уравнения регрессии

Коэффициент детерминации R2
Коэффициент R2 показывает долю объясненной вариации зависимой переменной:
Используется для
Коэффициент детерминации R2
Коэффициент R2 показывает долю объясненной вариации зависимой переменной:
Используется для

Основные свойства коэффициента детерминации
0 ≤ R2 ≤ 1.
Чем ближе R2 к
Основные свойства коэффициента детерминации
0 ≤ R2 ≤ 1.
Чем ближе R2 к

Пример (А). Расчет коэффициента детерминации
Пример (А). Расчет коэффициента детерминации
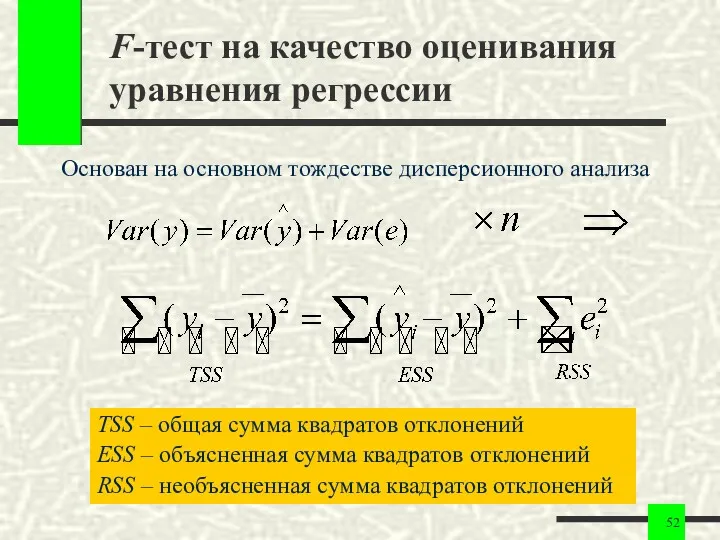
F-тест на качество оценивания уравнения регрессии
Основан на основном тождестве дисперсионного анализа
F-тест на качество оценивания уравнения регрессии
Основан на основном тождестве дисперсионного анализа

F-статистика для проверки качества уравнения регрессии
F-статистика представляет собой отношение объясненной
суммы квадратов
F-статистика для проверки качества уравнения регрессии
F-статистика представляет собой отношение объясненной
суммы квадратов

F-статистика для проверки качества уравнения регрессии
При отсутствии линейной зависимости между зависимой
и
F-статистика для проверки качества уравнения регрессии
При отсутствии линейной зависимости между зависимой
и

F-статистика для проверки качества парного уравнения регрессии
В парной (m = 1)
F-статистика для проверки качества парного уравнения регрессии
В парной (m = 1)

Порядок работы при проверке значимости парного уравнения по F-статистике
1. Выбираем уровень
Порядок работы при проверке значимости парного уравнения по F-статистике
1. Выбираем уровень

Связь между значимостью коэффициента регрессии и уравнения в целом
В парной регрессии
Связь между значимостью коэффициента регрессии и уравнения в целом
В парной регрессии

Коэффициент корреляции rxy
Коэффициент корреляции указывает на наличие
(или отсутствие) линейной связи между
Коэффициент корреляции rxy
Коэффициент корреляции указывает на наличие
(или отсутствие) линейной связи между

Взаимосвязь критериев в парном регрессионном анализе
Коэффициент корреляции по абсолютной величине
совпадает с
Взаимосвязь критериев в парном регрессионном анализе
Коэффициент корреляции по абсолютной величине
совпадает с

Проверка значимости коэффициента детерминации
Критическое значение R2 связано с
критическим значением F-статистики
Проверка значимости
Проверка значимости коэффициента детерминации
Критическое значение R2 связано с
критическим значением F-статистики
Проверка значимости

Сумма квадратов остатков RSS
Является оценкой необъясненной части
вариации зависимой переменной
Используется как основная
Сумма квадратов остатков RSS
Является оценкой необъясненной части
вариации зависимой переменной
Используется как основная

Стандартная ошибка регрессии Se
Является оценкой величины квадрата ошибки,
приходящейся на одну степень
Стандартная ошибка регрессии Se
Является оценкой величины квадрата ошибки,
приходящейся на одну степень

Средняя ошибка аппроксимации A
Оценку качества модели дает также средняя ошибка
аппроксимации –
Средняя ошибка аппроксимации A
Оценку качества модели дает также средняя ошибка
аппроксимации –

Типичные ошибки в использовании показателей качества регрессии
Величина коэффициентов регрессии не указывает
Типичные ошибки в использовании показателей качества регрессии
Величина коэффициентов регрессии не указывает

Ограниченность простой регрессии
1. Никакая единственная переменная за редкими
исключениями не в состоянии
Ограниченность простой регрессии
1. Никакая единственная переменная за редкими
исключениями не в состоянии
 Відстані в просторі
Відстані в просторі Компьютерная презентация методической разработки раздела учебной программы по алгебре в 8 классе Квадратные уравнения
Компьютерная презентация методической разработки раздела учебной программы по алгебре в 8 классе Квадратные уравнения Конспект урока с презентацией. Математика 1 класс Число и цифра 8
Конспект урока с презентацией. Математика 1 класс Число и цифра 8 Сумма углов треугольника. Внешние углы
Сумма углов треугольника. Внешние углы Проверка статистической гипотезы
Проверка статистической гипотезы Одномерные временные ряды
Одномерные временные ряды Задачи на кратное сравнение
Задачи на кратное сравнение Теорема Фалеса (1)
Теорема Фалеса (1) Mathematics for еconomists. (Week 1-12)
Mathematics for еconomists. (Week 1-12) Итоговое повторение. 1 класс
Итоговое повторение. 1 класс Показательные неравенства
Показательные неравенства Проецирование геометрических тел. Анализ геометрической формы
Проецирование геометрических тел. Анализ геометрической формы конкурс по математике Эврика
конкурс по математике Эврика Модуль геометрия. Подготовка к ОГЭ
Модуль геометрия. Подготовка к ОГЭ Виды прямоугольников
Виды прямоугольников Деление рациональных дробей. Урок алгебры в 8 классе
Деление рациональных дробей. Урок алгебры в 8 классе Сложение вида +8, +9
Сложение вида +8, +9 Лекция 7. Постановка задачи нелинейного программирования. Теорема Куна-Таккера
Лекция 7. Постановка задачи нелинейного программирования. Теорема Куна-Таккера Интегрированный урок математики и географии 6 класс
Интегрированный урок математики и географии 6 класс Математика Тема урока: Число и цифра 2.
Математика Тема урока: Число и цифра 2. Логарифмические неравенства
Логарифмические неравенства Представление данных в виде таблиц
Представление данных в виде таблиц Числовые последовательности. Предел числовой последовательности и её сходимость
Числовые последовательности. Предел числовой последовательности и её сходимость Гауссово моделирование. Алгоритмы в Petrel
Гауссово моделирование. Алгоритмы в Petrel Алгебраические действия с вероятностями событий
Алгебраические действия с вероятностями событий Приёмы письменного деления на однозначное число
Приёмы письменного деления на однозначное число Целое уравнение и его корни. Урок алгебры в 9 классе
Целое уравнение и его корни. Урок алгебры в 9 классе Корреляциялық талдау
Корреляциялық талдау