- Статистические ряды распределения

Содержание
- 2. Статистический ряд распределения – это упорядоченное распределение единиц совокупности на группы по определенному варьирующемуся признаку (стаж
- 3. Характеризуют состав (структуру), изучаемого явления Рассматривают вопрос об однородности совокупности Рассматривают вопрос о границах варьирования единиц
- 4. Виды статистических рядов распределения и их элементы Атрибутивный ряд Вариационный ряд Дискретный ряд Интервальный ряд В
- 5. Ряд построенный по атрибутивному признаку (пол, занятость, национальность, профессия и пр.) Распределение студентов I курса экономического
- 6. Вариационный ряд – это ранжированный в порядке возрастания или убывания ряд вариантов с соответствующими им весами.
- 7. 1. Варианты – это числовые значения количественного признака в вариационном ряду распределения (положительные, отрицательные, относительные, абсолютные)
- 8. 3. Частости – это частоты, выраженные в виде относительных величин (долях или процентах) Сумма частостей равна
- 9. В основе этого ряда лежит дискретный (прерывный) признак, т.е. значения признака отличаются друг от друга не
- 10. В основе этого ряда лежит непрерывный признак, который может принимать любые значения (температура воздуха, объем выручки)
- 11. Ранжирование – расположение всех вариантов в возрастающем или убывающем порядке Например стаж работы рабочих бригады: 2,
- 12. Строим дискретный ряд
- 13. Вычисляем количество интервалов по формуле Стерджесса Вычисляем величину интервала Строим таблицу: n=1+3,322lg25=5,6 примерно 5 h=(15-1)/5=2,8 примерно
- 14. Полигон – графическое изображение вариационных дискретных рядов: Ось абсцисс – ранжированные значения вариационного признака Ось ординат
- 15. Полигон распределения работников по стажу работы
- 16. Гистограмма - графическое изображение вариационных интервальных рядов Ось абсцисс – отображение величин интервалов Частоты описываются прямоугольниками,
- 17. Гистограмма распределения торговых предприятий города по среднесписочной численности работающих
- 18. Распределение называется симметричным если веса любых вариантов, равноотстоящих от среднего, равны между собой. Умеренно ассиметричные –
- 19. Крайне ассиметричными называются распределения, у которых частоты или все время возрастают, или все время убывают При
- 20. Эмпирической функцией распределения (функция распределения выборки) называетсяF*(x), определяющую для каждого значения x относительную частоту события X
- 21. значения F*(x) [0;1] F*(x) – функция неубывающая: F*(x2)> F*(x1), если x2> x1 если x1 – наименьшая
- 22. Кумулята – для изображения ряда накопленных частот Огива – это кумулята, в которой оси поменяны местами
- 23. Пример кумуляты
- 24. Пример огивы
- 25. Наиболее употребительными в статистических исследованиях являются три вида средних: средняя арифметическая, мода и медиана. средняя арифметическая:
- 26. Медианой (обозначим Mе) называется такое значение варьирующего признака, которое приходится на середину вариационного ряда. При нахождении
- 27. Модой (обозначим Мо) называется варианта, наиболее часто встречающаяся в данном вариационном ряду Меры уровня
- 28. Размах вариации показывает разность между наибольшим и наименьшим значениями признака (R=xmax-xmin). Достоинством этого показателя является простота
- 29. Дисперсия, или средний квадрат отклонения (обозначим σ2) есть средняя арифметическая из квадратов отклонений вариант от их
- 30. Показатели вариации Часто для исследования удобно представлять меру рассеяния в тех же единицах измерения, что и
- 31. Вся подлежащая изучению совокупность объектов называется генеральной совокупностью Та часть объектов которая попала на проверку или
- 32. Собственно-случайная Механическая выборка (члены из генеральной совокупности отбираются через определенный интервал) Типическая (генеральная совокупность разбита на
- 33. Средняя арифметическая распределения признака генеральной совокупности называется генеральной средней, а дисперсия этого распределения – генеральной дисперсией
- 34. Средняя арифметическая распределения признака в выборочной совокупности называется выборочной средней, а дисперсия этого распределения – выборочной
- 35. Генеральной долей p признака А называется отношение числа M членов генеральной совокупности с признаком А к
- 36. Случайные величины Случайной называют величину, которая в результате испытания примет одно и только одно возможное значение,
- 37. Поскольку в одном испытании случайная величина принимает одно и только одно возможное значение, заключаем, что события
- 38. Числовые характеристики дискретных случайных величин Математическое ожидание дискретной случайной величины Математическим ожиданием дискретной случайной величины Х
- 39. Вероятностный смысл математического ожидания Пусть проведено n испытаний, в которых случайная величина Х приняла m1 раз
- 40. Свойства математического ожидания 1. Математическое ожидание постоянной величины С равно самой постоянной: М(С) = С. Доказательство.
- 41. 4. Математическое ожидание суммы двух случайных величин равно сумме математических ожиданий слагаемых: М(Х + Y) =
- 42. Дисперсия дискретной случайной величины Пусть Х — случайная величина и М(Х) — ее математическое ожидание. Отклонением
- 43. Теорема. Дисперсия равна разности между математическим ожиданием квадрата случайной величины Х и квадратом ее математического ожидания:
- 44. Дисперсия постоянной величины С равна нулю: D(С) = 0. 2. Постоянный множитель можно выносить за знак
- 45. Среднее квадратическое отклонение Дисперсия имеет размерность квадрата случайной величины. Для того чтобы иметь показатель рассеяния случайной
- 46. Начальные и центральные теоретические моменты Начальным моментом порядка k случайной величины Х называют математическое ожидание величины
- 47. Функция распределения Функцией распределения называют функцию F(x), определяющую вероятность того, что случайная величина Х в результате
- 48. Итак, каждая функция распределения является неубывающей, непрерывной слева и удовлетворяющей условиям F(-∞) = 0, F(+∞) =
- 49. Случайная величина называется непрерывной, если существует неотрицательная функция р(х), удовлетворяющая при любых х равенству Функция р(х)
- 50. Свойства функции распределения непрерывной случайной величины 1. Вероятность того, что непрерывная случайная величина Х примет одно
- 51. Вероятность попадания непрерывной случайной величины в заданный интервал Теорема. Вероятность того, что непрерывная случайная величина Х
- 52. Числовые характеристики непрерывных случайных величин Математическим ожиданием непрерывной случайной величины Х, возможные значения которой принадлежат интервалу
- 53. Медианой непрерывной случайной величины называется такое ее значение m, при котором F(m)=0,5;другими словами, Квантилью порядка р
- 54. Равномерное распределение вероятностей Распределение вероятностей называется равномерным, если на интервале, которому принадлежат все возможные значения случайной
- 55. Нормальное распределение Нормальным называется распределение вероятностей непрерывной случайной величины, которое описывается плотностью Нормальное распределение определяется двумя
- 56. Общим называется нормальное распределение с произвольными параметрами а и σ. Нормированным называется нормальное распределение с параметрами
- 57. 1. Функция F0(x) общего нормального распределения и функция F(х) нормированного распределения связаны соотношением 2. Вероятность попадания
- 58. Вероятность попадания в заданный интервал нормальной случайной величины
- 59. Вероятность заданного отклонения σ1 σ2 при а = 0
- 60. Правило «трех сигм» Вероятность того, что отклонение по абсолютной величине будет меньше утроенного среднего квадратического отклонения,
- 61. При изучении распределений, отличных от нормального, возникает необходимость качественно оценить это различие. С этой целью вводят
- 62. Асимметрия и эксцесс E>0 E
- 63. Показательное распределение Показательным (экспоненциальным) называют распределение вероятностей непрерывной случайной величины Х, которое описывается плотностью Функция распределения
- 64. Вероятность попадания в заданный интервал показательно распределенной случайной величины Учитывая, что при х ≥ 0 Воспользуемся
- 66. Система двух случайных величин Закон распределения двумерной случайной величины Кроме одномерных случайных величин изучают случайные величины,
- 67. Закон распределения двумерной случайной величины Законом распределения дискретной двумерной случайной величины называют перечень возможных значений этой
- 68. Функция распределения двумерной случайной величины Рассмотрим двумерную случайную величину (X, Y) (дискретную или непрерывную). Функцией распределения
- 69. Вероятность попадания случайной точки в полуполосу P(x1 Поскольку
- 70. Вероятность попадания случайной точки в прямоугольник
- 71. Плотность совместного распределения вероятностей двумерной случайной величины Будем предполагать, что функция распределения F(x, y) непрерывна и
- 72. Вероятность попадания случайной точки в двумерную область
- 73. Свойства двумерной плотности вероятности Двумерная плотность вероятности неотрицательна: p(x, y) ≥ 0. 2. Отыскание плотностей вероятности
- 74. Условные законы распределения составляющих системы дискретных случайных величин Для того чтобы охарактеризовать зависимость между составляющими случайной
- 75. Пример. Дискретная двумерная случайная величина задана следующим законом распределения 0,60 0,40 P(Y = yj) Найти условные
- 76. Условные законы распределения составляющих системы непрерывных случайных величин Пусть (X, Y) — непрерывная случайная величина. Условной
- 77. Пример. Двумерная случайная величина (X, Y) задана плотностью совместного распределения Найти условные законы распределения составляющих. Решение.
- 78. Условное математическое ожидание Условным математическим ожиданием дискретной случайной величины Y при X = x (x —
- 79. Пример. Задана двумерная случайная величина: Найти условное математическое ожидание составляющей Y при х1 = 1. Решение.
- 80. Зависимые и независимые случайные величины. Две случайные величины X и Y называются независимыми, если закон распределения
- 81. Корреляционный момент. Коэффициент корреляции. Корреляционным моментом μxy случайных величин X и Y называют математическое ожидание произведения
- 82. Коррелированность и зависимость случайных величин Две случайные величины X и Y называют коррелированными, если их коэффициент
- 83. Нормальный закон распределения на плоскости Нормальным законом распределения на плоскости называют распределение вероятностей двумерной случайной величины,
- 84. Линейная регрессия. Прямые линии среднеквадратической регрессии. Рассмотрим двумерную случайную величину (X, Y), где X, Y —
- 86. Скачать презентацию

Статистический ряд распределения – это упорядоченное распределение единиц совокупности на группы
Статистический ряд распределения – это упорядоченное распределение единиц совокупности на группы

Характеризуют состав (структуру), изучаемого явления
Рассматривают вопрос об однородности совокупности
Рассматривают вопрос о
Характеризуют состав (структуру), изучаемого явления
Рассматривают вопрос об однородности совокупности
Рассматривают вопрос о
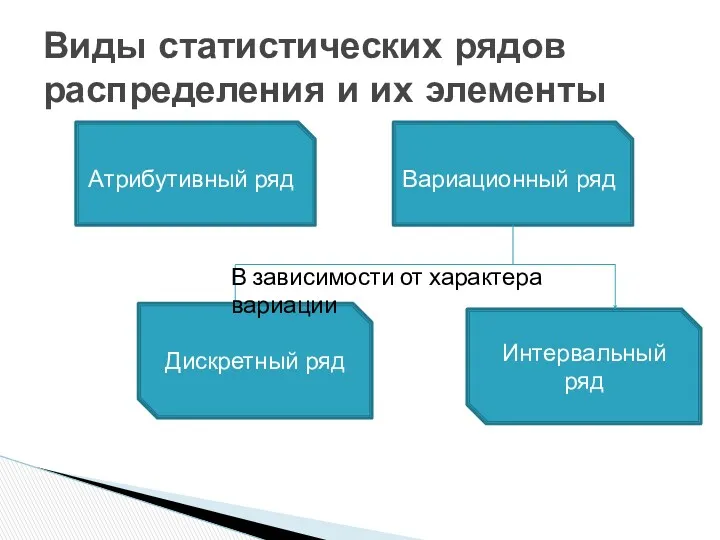
Виды статистических рядов распределения и их элементы
Атрибутивный ряд
Вариационный ряд
Дискретный ряд
Интервальный ряд
В
Виды статистических рядов распределения и их элементы
Атрибутивный ряд
Вариационный ряд
Дискретный ряд
Интервальный ряд
В

Ряд построенный по атрибутивному признаку (пол, занятость, национальность, профессия и пр.)
Распределение
Ряд построенный по атрибутивному признаку (пол, занятость, национальность, профессия и пр.)
Распределение
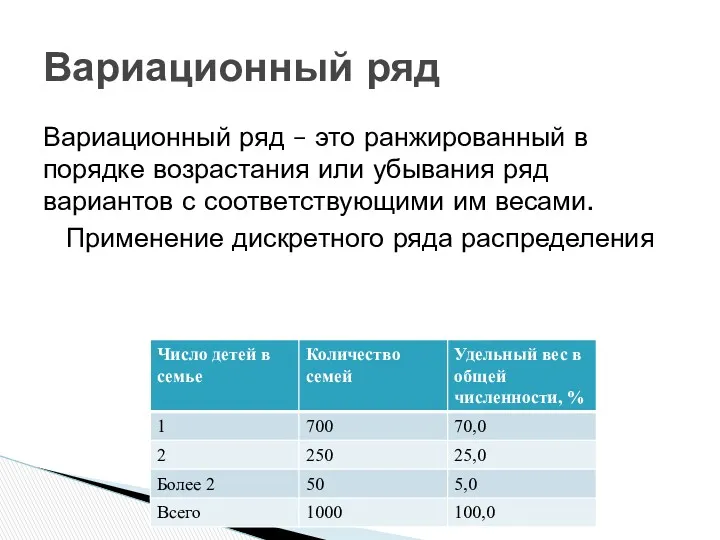
Вариационный ряд – это ранжированный в порядке возрастания или убывания ряд
Вариационный ряд – это ранжированный в порядке возрастания или убывания ряд

1. Варианты – это числовые значения количественного признака в вариационном ряду
1. Варианты – это числовые значения количественного признака в вариационном ряду

3. Частости – это частоты, выраженные в виде относительных величин (долях
3. Частости – это частоты, выраженные в виде относительных величин (долях
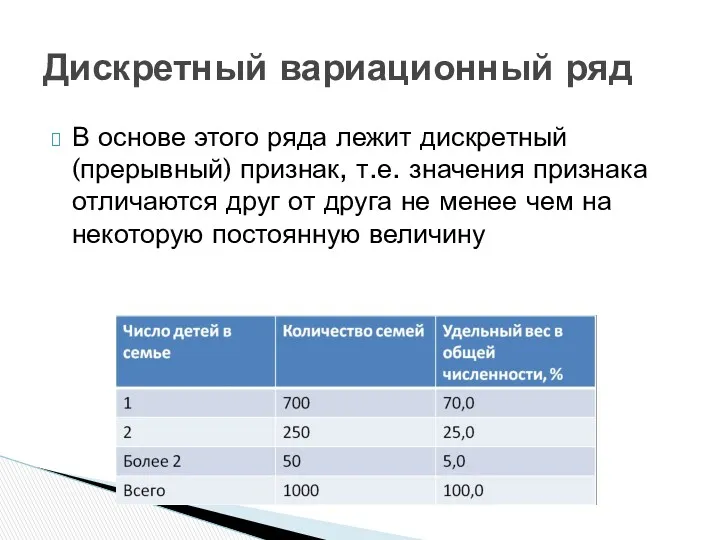
В основе этого ряда лежит дискретный (прерывный) признак, т.е. значения признака
В основе этого ряда лежит дискретный (прерывный) признак, т.е. значения признака

В основе этого ряда лежит непрерывный признак, который может принимать любые
В основе этого ряда лежит непрерывный признак, который может принимать любые

Ранжирование – расположение всех вариантов в возрастающем или убывающем порядке
Например стаж
Ранжирование – расположение всех вариантов в возрастающем или убывающем порядке
Например стаж
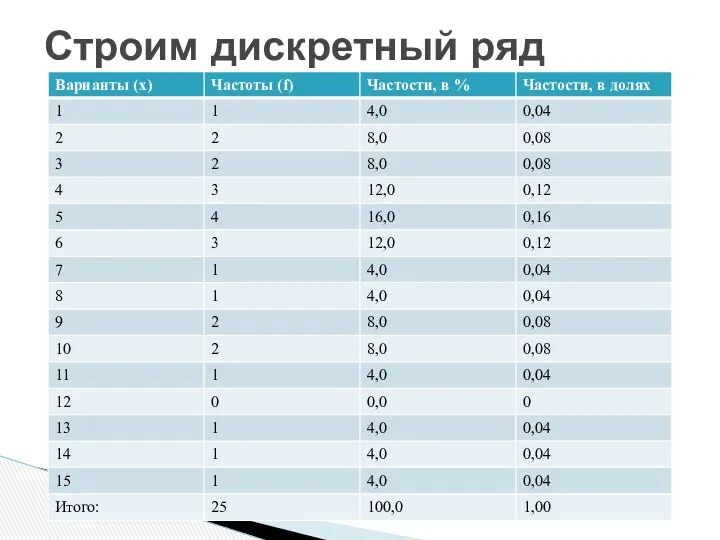
Строим дискретный ряд
Строим дискретный ряд

Вычисляем количество интервалов по формуле Стерджесса
Вычисляем величину интервала
Строим таблицу:
n=1+3,322lg25=5,6 примерно
Вычисляем количество интервалов по формуле Стерджесса
Вычисляем величину интервала
Строим таблицу:
n=1+3,322lg25=5,6 примерно

Полигон – графическое изображение вариационных дискретных рядов:
Ось абсцисс – ранжированные значения
Полигон – графическое изображение вариационных дискретных рядов:
Ось абсцисс – ранжированные значения
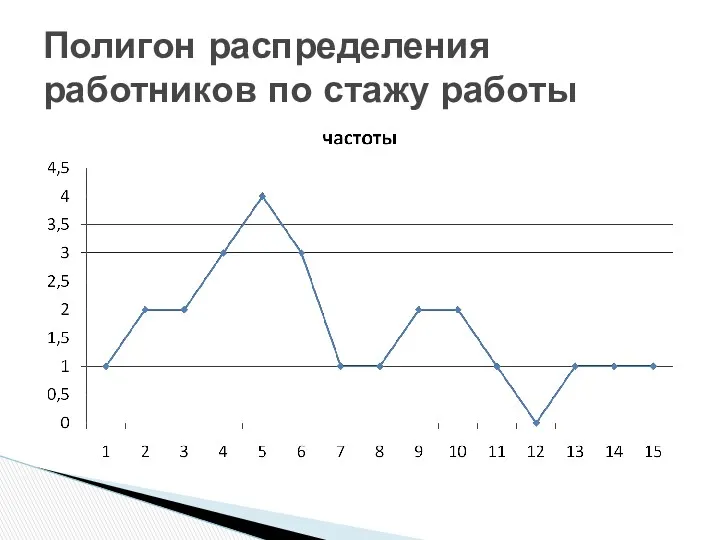
Полигон распределения работников по стажу работы
Полигон распределения работников по стажу работы

Гистограмма - графическое изображение вариационных интервальных рядов
Ось абсцисс – отображение
Гистограмма - графическое изображение вариационных интервальных рядов
Ось абсцисс – отображение
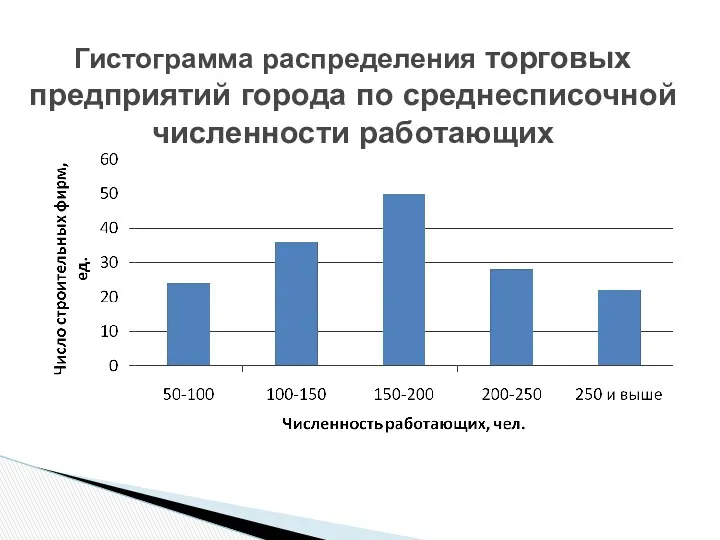
Гистограмма распределения торговых предприятий города по среднесписочной численности работающих
Гистограмма распределения торговых предприятий города по среднесписочной численности работающих

Распределение называется симметричным если веса любых вариантов, равноотстоящих от среднего, равны
Распределение называется симметричным если веса любых вариантов, равноотстоящих от среднего, равны

Крайне ассиметричными называются распределения, у которых частоты или все время возрастают,
Крайне ассиметричными называются распределения, у которых частоты или все время возрастают,

Эмпирической функцией распределения (функция распределения выборки) называетсяF*(x), определяющую для каждого
Эмпирической функцией распределения (функция распределения выборки) называетсяF*(x), определяющую для каждого
![значения F*(x) [0;1] F*(x) – функция неубывающая: F*(x2)> F*(x1), если](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/220776/slide-20.jpg)
значения F*(x) [0;1]
F*(x) – функция неубывающая: F*(x2)> F*(x1), если x2> x1
если
значения F*(x) [0;1]
F*(x) – функция неубывающая: F*(x2)> F*(x1), если x2> x1
если

Кумулята – для изображения ряда накопленных частот
Огива – это кумулята, в
Кумулята – для изображения ряда накопленных частот
Огива – это кумулята, в
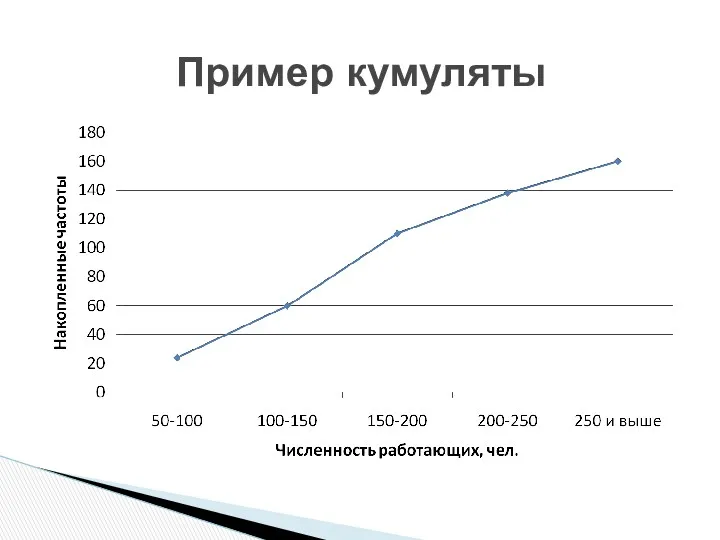
Пример кумуляты
Пример кумуляты
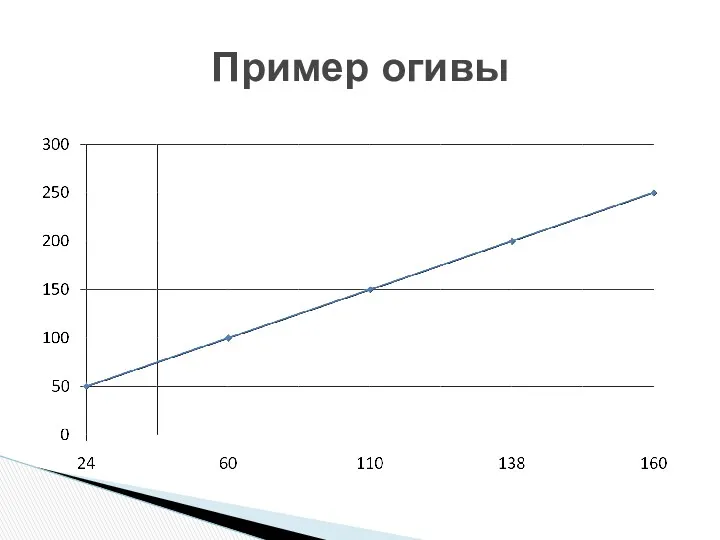
Пример огивы
Пример огивы

Наиболее употребительными в статистических исследованиях являются три вида средних: средняя арифметическая,
Наиболее употребительными в статистических исследованиях являются три вида средних: средняя арифметическая,

Медианой (обозначим Mе) называется такое значение варьирующего признака, которое приходится на
Медианой (обозначим Mе) называется такое значение варьирующего признака, которое приходится на

Модой (обозначим Мо) называется варианта, наиболее часто встречающаяся в данном вариационном
Модой (обозначим Мо) называется варианта, наиболее часто встречающаяся в данном вариационном

Размах вариации показывает разность между наибольшим и наименьшим значениями признака (R=xmax-xmin).
Размах вариации показывает разность между наибольшим и наименьшим значениями признака (R=xmax-xmin).

Дисперсия, или средний квадрат отклонения (обозначим σ2) есть средняя арифметическая из
Дисперсия, или средний квадрат отклонения (обозначим σ2) есть средняя арифметическая из

Показатели вариации
Часто для исследования удобно представлять меру рассеяния в тех же
Показатели вариации
Часто для исследования удобно представлять меру рассеяния в тех же

Вся подлежащая изучению совокупность объектов называется генеральной совокупностью
Та часть объектов которая
Вся подлежащая изучению совокупность объектов называется генеральной совокупностью
Та часть объектов которая

Собственно-случайная
Механическая выборка (члены из генеральной совокупности отбираются через определенный интервал)
Типическая (генеральная
Собственно-случайная
Механическая выборка (члены из генеральной совокупности отбираются через определенный интервал)
Типическая (генеральная

Средняя арифметическая распределения признака генеральной совокупности называется генеральной средней, а дисперсия
Средняя арифметическая распределения признака генеральной совокупности называется генеральной средней, а дисперсия

Средняя арифметическая распределения признака в выборочной совокупности называется выборочной средней, а
Средняя арифметическая распределения признака в выборочной совокупности называется выборочной средней, а

Генеральной долей p признака А называется отношение числа M членов генеральной
Генеральной долей p признака А называется отношение числа M членов генеральной

Случайные величины
Случайной называют величину, которая в результате испытания примет одно и
Случайные величины
Случайной называют величину, которая в результате испытания примет одно и

Поскольку в одном испытании случайная величина принимает одно и только одно
Поскольку в одном испытании случайная величина принимает одно и только одно

Числовые характеристики дискретных случайных величин
Математическое ожидание дискретной случайной величины
Математическим ожиданием дискретной
Числовые характеристики дискретных случайных величин
Математическое ожидание дискретной случайной величины
Математическим ожиданием дискретной

Вероятностный смысл математического ожидания
Пусть проведено n испытаний, в которых случайная величина
Вероятностный смысл математического ожидания
Пусть проведено n испытаний, в которых случайная величина

Свойства математического ожидания
1. Математическое ожидание постоянной величины С равно самой постоянной:
Свойства математического ожидания
1. Математическое ожидание постоянной величины С равно самой постоянной:

4. Математическое ожидание суммы двух случайных величин равно
сумме математических ожиданий слагаемых:
4. Математическое ожидание суммы двух случайных величин равно
сумме математических ожиданий слагаемых:

Дисперсия дискретной случайной величины
Пусть Х — случайная величина и М(Х) —
Дисперсия дискретной случайной величины
Пусть Х — случайная величина и М(Х) —

Теорема. Дисперсия равна разности между математическим ожиданием квадрата случайной величины Х
Теорема. Дисперсия равна разности между математическим ожиданием квадрата случайной величины Х

Дисперсия постоянной величины С равна нулю: D(С) = 0.
2. Постоянный множитель
Дисперсия постоянной величины С равна нулю: D(С) = 0.
2. Постоянный множитель

Среднее квадратическое отклонение
Дисперсия имеет размерность квадрата случайной величины. Для того чтобы
Среднее квадратическое отклонение
Дисперсия имеет размерность квадрата случайной величины. Для того чтобы

Начальные и центральные теоретические
моменты
Начальным моментом порядка k случайной величины Х
Начальные и центральные теоретические
моменты
Начальным моментом порядка k случайной величины Х

Функция распределения
Функцией распределения называют функцию F(x), определяющую вероятность того, что случайная
Функция распределения
Функцией распределения называют функцию F(x), определяющую вероятность того, что случайная

Итак, каждая функция распределения является неубывающей, непрерывной слева и удовлетворяющей условиям
Итак, каждая функция распределения является неубывающей, непрерывной слева и удовлетворяющей условиям

Случайная величина называется непрерывной, если существует неотрицательная функция р(х), удовлетворяющая при
Случайная величина называется непрерывной, если существует неотрицательная функция р(х), удовлетворяющая при

Свойства функции распределения непрерывной случайной величины
1. Вероятность того, что непрерывная случайная
Свойства функции распределения непрерывной случайной величины
1. Вероятность того, что непрерывная случайная

Вероятность попадания непрерывной
случайной величины в заданный интервал
Теорема. Вероятность того, что
Вероятность попадания непрерывной
случайной величины в заданный интервал
Теорема. Вероятность того, что

Числовые характеристики непрерывных случайных величин
Математическим ожиданием непрерывной случайной величины Х,
возможные
Числовые характеристики непрерывных случайных величин
Математическим ожиданием непрерывной случайной величины Х,
возможные

Медианой непрерывной случайной величины называется такое ее значение m, при котором
Медианой непрерывной случайной величины называется такое ее значение m, при котором

Равномерное распределение вероятностей
Распределение вероятностей называется равномерным, если на интервале,
которому принадлежат все
Равномерное распределение вероятностей
Распределение вероятностей называется равномерным, если на интервале,
которому принадлежат все

Нормальное распределение
Нормальным называется распределение вероятностей непрерывной случайной величины, которое описывается плотностью
Нормальное
Нормальное распределение
Нормальным называется распределение вероятностей непрерывной случайной величины, которое описывается плотностью
Нормальное
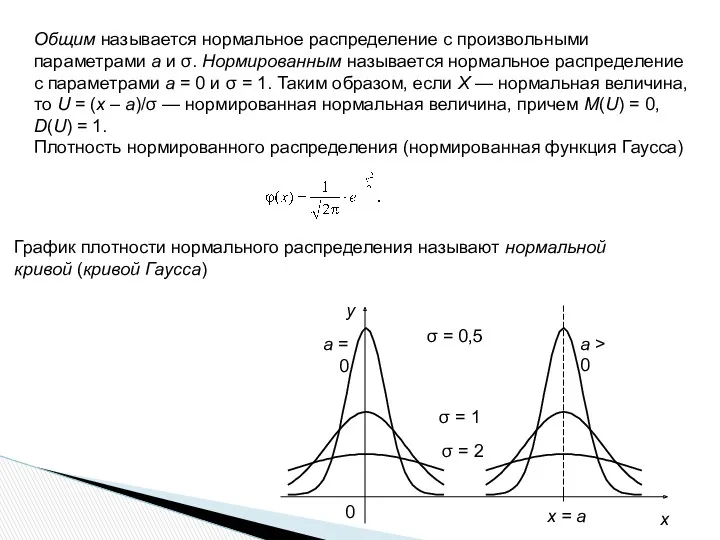
Общим называется нормальное распределение с произвольными параметрами а и σ. Нормированным
Общим называется нормальное распределение с произвольными параметрами а и σ. Нормированным

1. Функция F0(x) общего нормального распределения
и функция F(х) нормированного распределения
связаны
1. Функция F0(x) общего нормального распределения
и функция F(х) нормированного распределения
связаны

Вероятность попадания в заданный интервал нормальной
случайной величины
Вероятность попадания в заданный интервал нормальной
случайной величины
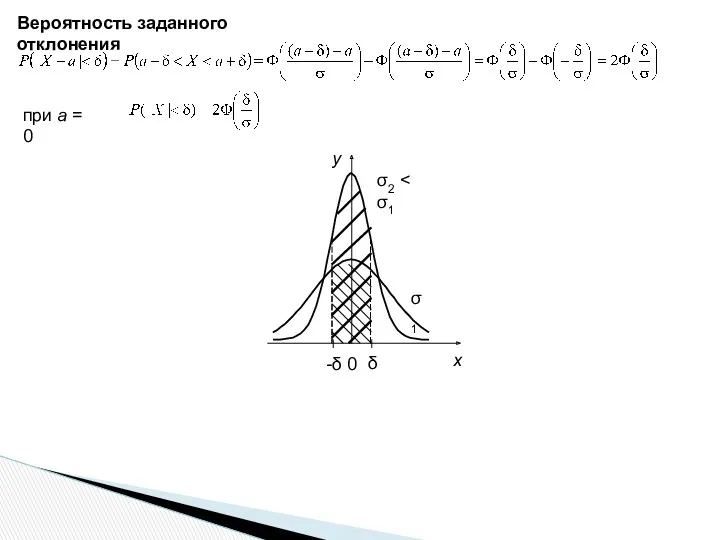
Вероятность заданного отклонения
σ1
σ2 < σ1
при а = 0
Вероятность заданного отклонения
σ1
σ2 < σ1
при а = 0

Правило «трех сигм»
Вероятность того, что отклонение по абсолютной величине будет
меньше
Правило «трех сигм»
Вероятность того, что отклонение по абсолютной величине будет
меньше

При изучении распределений, отличных от нормального, возникает необходимость качественно оценить это
При изучении распределений, отличных от нормального, возникает необходимость качественно оценить это
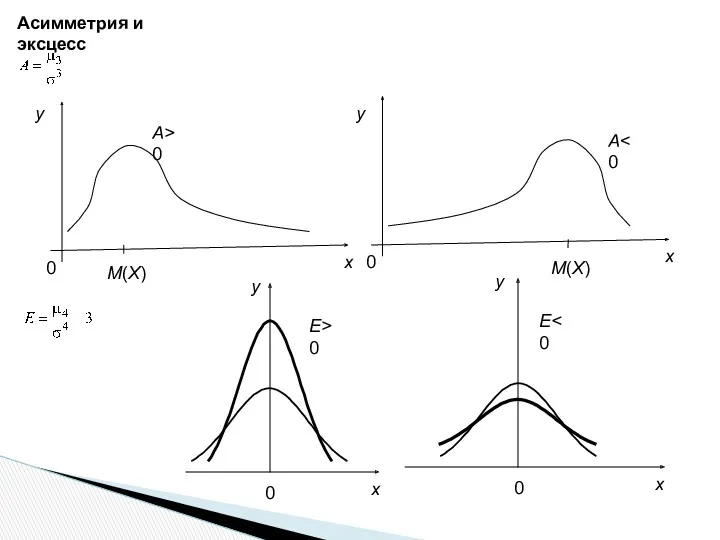
Асимметрия и эксцесс
E>0
E<0
Асимметрия и эксцесс
E>0
E<0
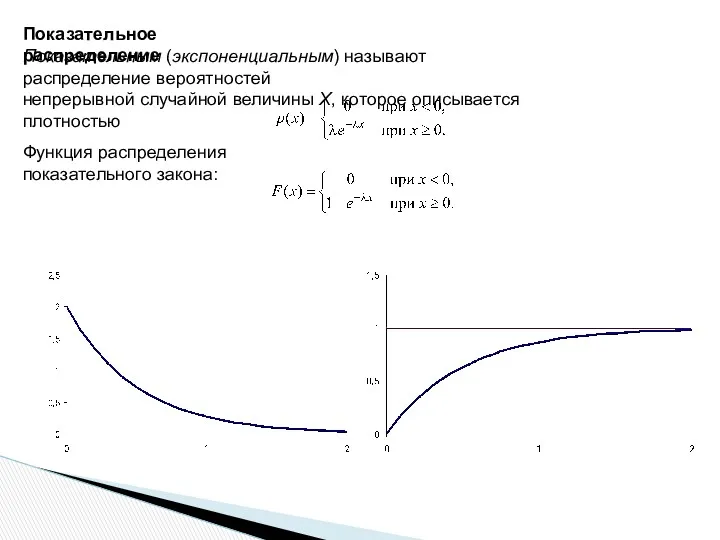
Показательное распределение
Показательным (экспоненциальным) называют распределение вероятностей
непрерывной случайной величины Х, которое
Показательное распределение
Показательным (экспоненциальным) называют распределение вероятностей
непрерывной случайной величины Х, которое

Вероятность попадания в заданный интервал
показательно распределенной случайной величины
Учитывая, что при
Вероятность попадания в заданный интервал
показательно распределенной случайной величины
Учитывая, что при


Система двух случайных величин
Закон распределения двумерной случайной величины
Кроме одномерных случайных величин
Система двух случайных величин
Закон распределения двумерной случайной величины
Кроме одномерных случайных величин
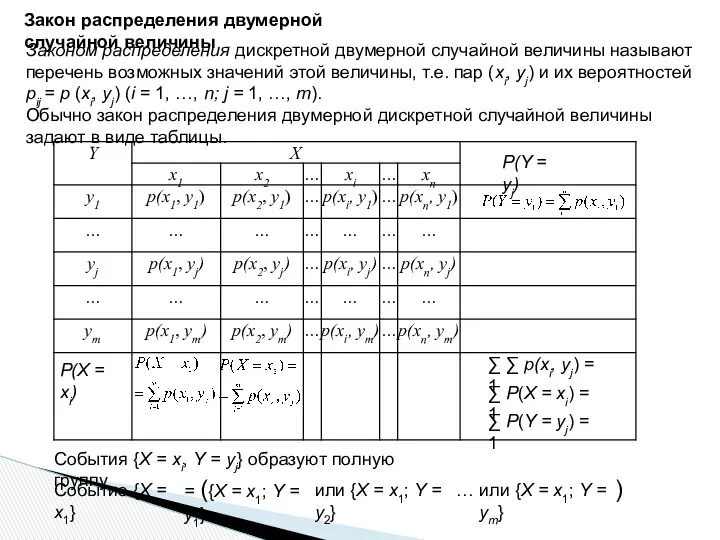
Закон распределения двумерной случайной величины
Законом распределения дискретной двумерной случайной величины называют
Закон распределения двумерной случайной величины
Законом распределения дискретной двумерной случайной величины называют

Функция распределения двумерной случайной величины
Рассмотрим двумерную случайную величину (X, Y) (дискретную
Функция распределения двумерной случайной величины
Рассмотрим двумерную случайную величину (X, Y) (дискретную

Вероятность попадания случайной точки в полуполосу
P(x1 < X < x2, Y
Вероятность попадания случайной точки в полуполосу
P(x1 < X < x2, Y

Вероятность попадания случайной точки в прямоугольник
Вероятность попадания случайной точки в прямоугольник

Плотность совместного распределения вероятностей двумерной случайной величины
Будем предполагать, что функция распределения
Плотность совместного распределения вероятностей двумерной случайной величины
Будем предполагать, что функция распределения
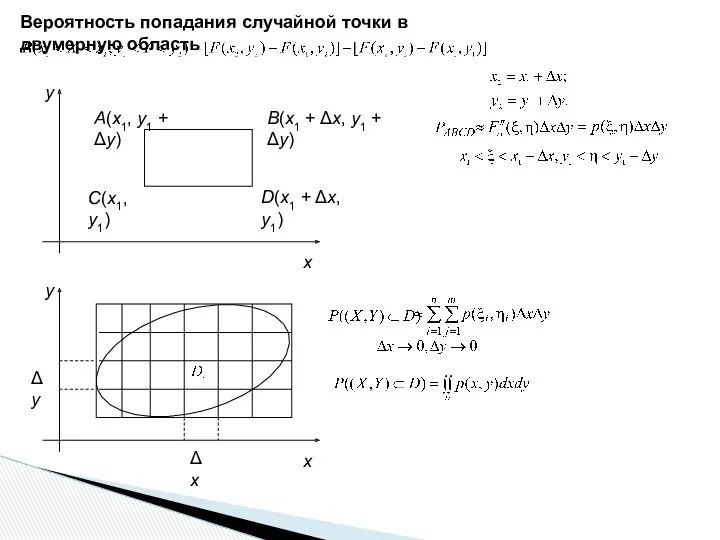
Вероятность попадания случайной точки в двумерную область
Вероятность попадания случайной точки в двумерную область

Свойства двумерной плотности вероятности
Двумерная плотность вероятности неотрицательна: p(x, y) ≥
Свойства двумерной плотности вероятности
Двумерная плотность вероятности неотрицательна: p(x, y) ≥

Условные законы распределения составляющих системы дискретных случайных величин
Для того чтобы охарактеризовать
Условные законы распределения составляющих системы дискретных случайных величин
Для того чтобы охарактеризовать

Пример. Дискретная двумерная случайная величина задана следующим законом распределения
0,60
0,40
P(Y = yj)
Найти
Пример. Дискретная двумерная случайная величина задана следующим законом распределения
0,60
0,40
P(Y = yj)
Найти

Условные законы распределения составляющих системы непрерывных случайных величин
Пусть (X, Y) —
Условные законы распределения составляющих системы непрерывных случайных величин
Пусть (X, Y) —

Пример. Двумерная случайная величина (X, Y) задана плотностью совместного распределения
Найти условные
Пример. Двумерная случайная величина (X, Y) задана плотностью совместного распределения
Найти условные

Условное математическое ожидание
Условным математическим ожиданием дискретной случайной величины Y при X
Условное математическое ожидание
Условным математическим ожиданием дискретной случайной величины Y при X

Пример. Задана двумерная случайная величина:
Найти условное математическое ожидание составляющей Y при
Пример. Задана двумерная случайная величина:
Найти условное математическое ожидание составляющей Y при

Зависимые и независимые случайные величины.
Две случайные величины X и Y называются
Зависимые и независимые случайные величины.
Две случайные величины X и Y называются

Корреляционный момент. Коэффициент корреляции.
Корреляционным моментом μxy случайных величин X и Y
Корреляционный момент. Коэффициент корреляции.
Корреляционным моментом μxy случайных величин X и Y

Коррелированность и зависимость случайных величин
Две случайные величины X и Y называют
Коррелированность и зависимость случайных величин
Две случайные величины X и Y называют

Нормальный закон распределения на плоскости
Нормальным законом распределения на плоскости называют распределение
Нормальный закон распределения на плоскости
Нормальным законом распределения на плоскости называют распределение
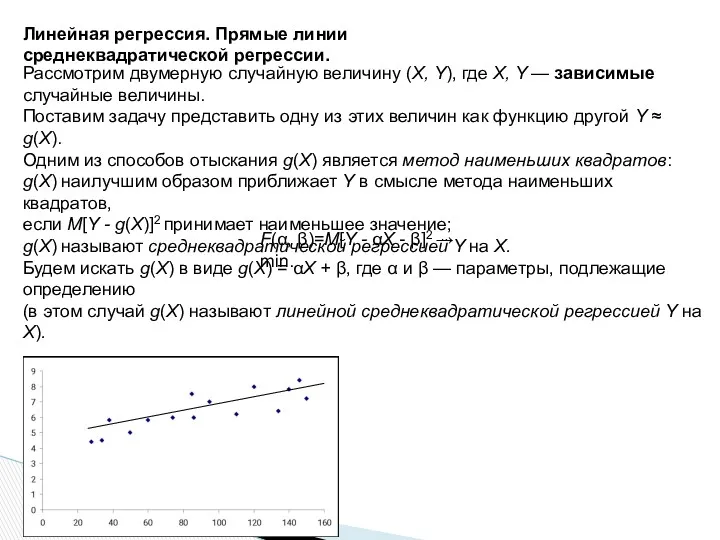
Линейная регрессия. Прямые линии среднеквадратической регрессии.
Рассмотрим двумерную случайную величину (X, Y),
Линейная регрессия. Прямые линии среднеквадратической регрессии.
Рассмотрим двумерную случайную величину (X, Y),
 20231226_494-obem-konusa
20231226_494-obem-konusa Из каких фигур состоит поверхность прямоугольного параллелепипеда?
Из каких фигур состоит поверхность прямоугольного параллелепипеда? Розв’язання систем лінійних алгебраїчних рівнянь
Розв’язання систем лінійних алгебраїчних рівнянь Приём письменного деления многозначных чисел на однозначное число
Приём письменного деления многозначных чисел на однозначное число Тетраэдр. Параллелепипед. Задачи на построение сечений
Тетраэдр. Параллелепипед. Задачи на построение сечений Открытый урок математика 3 класс.
Открытый урок математика 3 класс. Математический диктант
Математический диктант Решение задач на части. 5 класс
Решение задач на части. 5 класс Линейная функция и ее график
Линейная функция и ее график Соотношения между сторонами и углами треугольника
Соотношения между сторонами и углами треугольника Площадь трапеции
Площадь трапеции Презентация ЗАДАЧА
Презентация ЗАДАЧА Устные приемы умножения и деления чисел от 1 до 1000; 3 класс. Технологический приём Универсальный тренажёр
Устные приемы умножения и деления чисел от 1 до 1000; 3 класс. Технологический приём Универсальный тренажёр Пирамида. Задачи ЕГЭ
Пирамида. Задачи ЕГЭ Урок математики. 1 класс. Система Л.В.Занкова.
Урок математики. 1 класс. Система Л.В.Занкова. Презентация к уроку математики в 1 классе по теме Величины.Сантиметр
Презентация к уроку математики в 1 классе по теме Величины.Сантиметр Решение задач
Решение задач Игра Веселые соревнования
Игра Веселые соревнования Масса
Масса Математика и космос. Первый человек в космосе
Математика и космос. Первый человек в космосе Игра Крестики-нолики. Тема: Треугольники
Игра Крестики-нолики. Тема: Треугольники Квадратичные объясняющие переменные
Квадратичные объясняющие переменные Найди пару
Найди пару Площади частей круга
Площади частей круга Симетрія
Симетрія Свойства геометрических фигур на плоскости
Свойства геометрических фигур на плоскости Вовка в математическом царстве. Часть 1
Вовка в математическом царстве. Часть 1 Работа в программе Excel на уроках математики. Составление таблиц и диаграмм, анализ статистических данных
Работа в программе Excel на уроках математики. Составление таблиц и диаграмм, анализ статистических данных