- Взвешенный и обобщенный МНК. Неоднородность. Дамми-переменные

Содержание
- 2. Обобщенная линейная модель множественной регрессии (ОЛММР) 2 Второе условие классической модели может не выполняться: σ 2
- 3. Обобщенный метод наименьших квадратов 3 МНК-оценки – состоятельные и несмещенные, но не эффективные. – обладают всеми
- 4. Модель с гетероскедастичными остатками. Взвешенный метод наименьших квадратов 4 Остатки взаимно некоррелированы: Остатки не обладают постоянной
- 5. Проверка гетероскедастичности 5 Для проверки типично строится регрессия абсолютной величины остат-ков по некоторой функции от X:
- 6. Практическое оценивание модели с гетероскедастичными остатками 6 Проверка гипотезы о наличии гетероскедастичности. Переход от исходной модели
- 7. Модель с автокоррелированными остатками. Обобщенный метод наименьших квадратов 7 Данные регистрируются во времени. |ρ | ∈
- 8. Проверка автокорреляции. Критерий Дарбина-Уотсона 8 Выбираем уровень значимости α. Находим эмпирическое значение критерия Случай d В
- 9. Практическое оценивание модели с автокоррелированными остатками 9 Проверка гипотезы о наличии автокорреляции. Переход от исходной модели
- 10. Итеративная процедура Кохрейна-Оркатта 10 1. Вычисляем МНК-оценки 1-итерации 2. Подсчитываем остатки 1-итерации 3. С помощью МНК
- 11. Точечный прогноз в моделях линейной регрессии 11 Наиболее распространенная задача: предсказывать y по известным X. –
- 12. Интервальный прогноз в моделях линейной регрессии 12 Для построения доверительного интервала необходима оценка точности точечного прогноза:
- 13. Неоднородность данных 13 Результирующий показатель y зависит не только от регрессоров X, но и от уровня
- 14. Метод дамми-переменных 14 Если категоризованная переменная z(j) имеет kj градаций, вводим (kj – 1) бинарных дамми-переменных,
- 15. Модификации метода. Варианты зависимостей 15 Пример. Продажи мороженого в зависимости от цены, сезона и при-надлежности к
- 16. Несколько замечаний 16 Замечание 1. Статистическая надежность: Точность модели зависит от соотношения n / (p+1) –
- 17. Ловушка, связанная с введением дамми-переменных 17 Если у переменной z(j) есть k градаций, то есть риск
- 18. Численный пример на использование дамми-переменных 18 Собраны данные по продажам мо-роженого (y, млн шт.) за 5
- 19. Учет эффекта взаимодействия сопутствующих факторов 19 До сих пор сопутствующие переменные влияли на результирующий показатель независимо,
- 20. Проверка регрессионной однородности двух групп наблюдений 20 Случай 1. Большая выборка В1 + большая выборка В2
- 21. Проверка регрессионной однородности двух групп наблюдений 21 Случай 3. Большая выборка В1 + сверхмалая выборка В2
- 22. Численный пример на проверку однородности выборок 22 Зависимость зарплаты от стажа и образования (пример из практики
- 23. Пример неоднородности данных при неизвестных сопутствующих факторах 23 Исследование проблемы «утечки мозгов» в 1990-е. Регрессионный анализ
- 25. Скачать презентацию

Обобщенная линейная модель
множественной регрессии (ОЛММР)
2
Второе условие классической модели может не выполняться:
σ
Обобщенная линейная модель
множественной регрессии (ОЛММР)
2
Второе условие классической модели может не выполняться:
σ

Обобщенный метод
наименьших квадратов
3
МНК-оценки – состоятельные и несмещенные, но не эффективные.
– обладают
Обобщенный метод
наименьших квадратов
3
МНК-оценки – состоятельные и несмещенные, но не эффективные.
– обладают

Модель с
гетероскедастичными остатками.
Взвешенный метод наименьших квадратов
4
Остатки взаимно некоррелированы:
Остатки не обладают
Модель с
гетероскедастичными остатками.
Взвешенный метод наименьших квадратов
4
Остатки взаимно некоррелированы:
Остатки не обладают

Проверка гетероскедастичности
5
Для проверки типично строится регрессия абсолютной величины остат-ков по некоторой
Проверка гетероскедастичности
5
Для проверки типично строится регрессия абсолютной величины остат-ков по некоторой

Практическое оценивание модели
с гетероскедастичными остатками
6
Проверка гипотезы о наличии гетероскедастичности.
Переход от исходной
Практическое оценивание модели
с гетероскедастичными остатками
6
Проверка гипотезы о наличии гетероскедастичности.
Переход от исходной

Модель с
автокоррелированными остатками.
Обобщенный метод наименьших квадратов
7
Данные регистрируются во времени.
|ρ | ∈
Модель с
автокоррелированными остатками.
Обобщенный метод наименьших квадратов
7
Данные регистрируются во времени.
|ρ | ∈

Проверка автокорреляции.
Критерий Дарбина-Уотсона
8
Выбираем уровень значимости α.
Находим эмпирическое значение критерия
Случай d <
Проверка автокорреляции.
Критерий Дарбина-Уотсона
8
Выбираем уровень значимости α.
Находим эмпирическое значение критерия
Случай d <

Практическое оценивание модели
с автокоррелированными остатками
9
Проверка гипотезы о наличии автокорреляции.
Переход от исходной
Практическое оценивание модели
с автокоррелированными остатками
9
Проверка гипотезы о наличии автокорреляции.
Переход от исходной

Итеративная процедура
Кохрейна-Оркатта
10
1. Вычисляем МНК-оценки 1-итерации
2. Подсчитываем остатки 1-итерации
3. С помощью МНК
Итеративная процедура
Кохрейна-Оркатта
10
1. Вычисляем МНК-оценки 1-итерации
2. Подсчитываем остатки 1-итерации
3. С помощью МНК

Точечный прогноз
в моделях линейной регрессии
11
Наиболее распространенная задача: предсказывать y по известным
Точечный прогноз
в моделях линейной регрессии
11
Наиболее распространенная задача: предсказывать y по известным

Интервальный прогноз
в моделях линейной регрессии
12
Для построения доверительного интервала необходима оценка точности
Интервальный прогноз
в моделях линейной регрессии
12
Для построения доверительного интервала необходима оценка точности

Неоднородность данных
13
Результирующий показатель y зависит не только от регрессоров X, но
Неоднородность данных
13
Результирующий показатель y зависит не только от регрессоров X, но

Метод дамми-переменных
14
Если категоризованная переменная z(j) имеет kj градаций, вводим (kj –
Метод дамми-переменных
14
Если категоризованная переменная z(j) имеет kj градаций, вводим (kj –

Модификации метода.
Варианты зависимостей
15
Пример. Продажи мороженого в зависимости от цены, сезона и
Модификации метода.
Варианты зависимостей
15
Пример. Продажи мороженого в зависимости от цены, сезона и

Несколько замечаний
16
Замечание 1. Статистическая надежность:
Точность модели зависит от соотношения n /
Несколько замечаний
16
Замечание 1. Статистическая надежность:
Точность модели зависит от соотношения n /

Ловушка, связанная
с введением дамми-переменных
17
Если у переменной z(j) есть k градаций, то
Ловушка, связанная
с введением дамми-переменных
17
Если у переменной z(j) есть k градаций, то

Численный пример
на использование дамми-переменных
18
Собраны данные по продажам мо-роженого (y, млн шт.)
Численный пример
на использование дамми-переменных
18
Собраны данные по продажам мо-роженого (y, млн шт.)
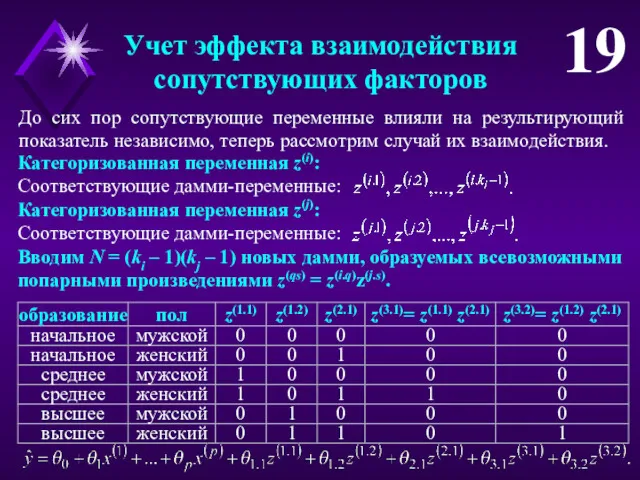
Учет эффекта взаимодействия
сопутствующих факторов
19
До сих пор сопутствующие переменные влияли на результирующий
Учет эффекта взаимодействия
сопутствующих факторов
19
До сих пор сопутствующие переменные влияли на результирующий

Проверка регрессионной
однородности двух групп наблюдений
20
Случай 1. Большая выборка В1 + большая
Проверка регрессионной
однородности двух групп наблюдений
20
Случай 1. Большая выборка В1 + большая

Проверка регрессионной
однородности двух групп наблюдений
21
Случай 3. Большая выборка В1 + сверхмалая
Проверка регрессионной
однородности двух групп наблюдений
21
Случай 3. Большая выборка В1 + сверхмалая

Численный пример
на проверку однородности выборок
22
Зависимость зарплаты от стажа и образования (пример
Численный пример
на проверку однородности выборок
22
Зависимость зарплаты от стажа и образования (пример

Пример неоднородности данных
при неизвестных сопутствующих факторах
23
Исследование проблемы «утечки мозгов» в 1990-е.
Регрессионный
Пример неоднородности данных
при неизвестных сопутствующих факторах
23
Исследование проблемы «утечки мозгов» в 1990-е.
Регрессионный
 Старинные меры длины
Старинные меры длины Математические методы (Исследование операций, Методы оптимизации). Задача о максимальном потоке
Математические методы (Исследование операций, Методы оптимизации). Задача о максимальном потоке Математика в быту и в повседневной жизни
Математика в быту и в повседневной жизни Эконометрика. Модель парной и множественной линейной регрессии
Эконометрика. Модель парной и множественной линейной регрессии презентация Новогодние игры
презентация Новогодние игры Презентация к уроку математики 1 класс Таблица сложения
Презентация к уроку математики 1 класс Таблица сложения Параллелограмм Вариньона
Параллелограмм Вариньона Объёмы тел. Общие свойства объемов тел
Объёмы тел. Общие свойства объемов тел Сыбайлас және вертикаль бұрыштар
Сыбайлас және вертикаль бұрыштар Письменное деление многозначных чисел на трехзначное число
Письменное деление многозначных чисел на трехзначное число Счет в пределах 10, 1 класс Зимние забавы
Счет в пределах 10, 1 класс Зимние забавы Математика. 1 класс. Урок 41. Переместительное свойство сложения - Презентация
Математика. 1 класс. Урок 41. Переместительное свойство сложения - Презентация Введение в геометрию. 7 класс
Введение в геометрию. 7 класс Алгоритм построения проекции прямой на плоскость
Алгоритм построения проекции прямой на плоскость Проверка статистических гипотез
Проверка статистических гипотез Площадь прямоугольника. Свойства площадей
Площадь прямоугольника. Свойства площадей Логарифмы вокруг нас
Логарифмы вокруг нас Математика Древней Греции
Математика Древней Греции Задачи на проценты
Задачи на проценты Аналитическая геометрия на плоскости
Аналитическая геометрия на плоскости Параллельные прямые. Урок геометрии в 7 классе
Параллельные прямые. Урок геометрии в 7 классе Пирамида
Пирамида Использование матриц при решении экономических задач
Использование матриц при решении экономических задач Обозначение натуральных чисел
Обозначение натуральных чисел Круговые диаграммы
Круговые диаграммы Капельки
Капельки Математика. 1 класс. Урок 69. Уравнение - Презентация
Математика. 1 класс. Урок 69. Уравнение - Презентация Вычисление площади с помощью итеграла
Вычисление площади с помощью итеграла