- Менеджер транзакций

Содержание
- 2. Компоненты менеджера транзакций Менеджер блокировок для конкурентного доступа. Менеджер восстановления. Буферный пул для хранения промежуточных состояний
- 3. Менеджер блокировок Две стратегии: Блокировка Восстановление
- 4. Механизмы управления согласованием в многопользовательской среде Multi-Granular Locking scheme (сокращённо MGL, также известна как LSCC) -
- 5. LSCC - схема гранулированных синхронизационных захватов Одна строка – одна запись => эксклюзивная блокировка (W-lock) для
- 7. READ UNCOMMITTED Уровень изолированности READ UNCOMMITTED не требует R-блокировки для защиты от чтения, но в случае
- 8. Снятие блокировок В случае уровня изолированности Read Committed, R-блокировка строки будет снята сразу после считывания строки
- 9. Блокировка таблиц В некоторых продуктах СУБД диалект SQL включает явные команды LOCK TABLE, но снимаются эти
- 10. Гранулярность блокировок
- 11. Уровни блокировок Table (TAB): Это самая грубая логическая блокировка, которую может использовать SQL Server. Extent (EXT):
- 12. Уровни блокировок Высокая конкурентность означает, что множество пользователей может работать одновременно. По возможности это достигается путем
- 13. Иерархия объектов
- 14. Эскалация блокировок Эскалация блокировок – это процесс, при котором множество блокировок с маленькой гранулярностью, конвертируются в
- 15. Проблемы маленьких блокировок Locking overhead. иногда выгоднее наложить одну блокировку с большей гранулярностью, чем несколько (или
- 16. Подсказки оптимизатору По умолчанию сервер старается наложить блокировку min гранулярности. Если сервер посчитает, что блокировать на
- 17. Бесконечное ожидание Протокол блокировки уладит проблему потерянных обновлений, но если конкурирующие транзакции используют уровень изолированности, который
- 19. Важно помнить, что никакая СУБД не может автоматически перезапустить прерванную взаимной блокировкой «жертву», за это несёт
- 20. MVCC - многоверсионное управление параллелизмом В MVCC техника такова, что сервер сохраняет цепь истории в некоторых
- 21. MVCC - многоверсионное управление параллелизмом Любая транзакция с уровнем изолированности READ COMMITTED получит последние зафиксированные версии
- 23. В MVCC Oracle первой транзакции для записи строки (то есть для выполнения вставки, обновления или удаления)
- 24. Технику управления параллелизмом в Oracle можно назвать гибридным CC, так как в дополнение к MVCC с
- 25. Механизм управления параллелизмом в MySQL/InnoDB является реальным гибридным CC, обеспечивающим для чтения четыре уровня изолированности: READ
- 26. OCC - управление оптимистичным параллелизмом Begin: Пометка о времени начала транзакции. Modify: Чтение и запись изменение
- 27. Восстановление Индивидуальный откат транзакции. Восстановление после внезапной потери содержимого оперативной памяти. Восстановление после поломки основного внешнего
- 28. Отказы приложений завершение оператором ROLLBACK; аварийное завершение работы прикладной программы; принудительный откат транзакции в случае взаимной
- 29. Технические проблемы Мягкий сбой при аварийном выключении электрического питания; при возникновении неустранимого сбоя процессора и т.
- 30. Возобновление при отказах Отказы приложений/транзакции: транзакции обрываются Отказы системы: функционирование возобновляется после рестарта и восстановления согласованности
- 31. Восстановление оборванных транзакций: откат Обрывы транзакций могут быть вызваны ошибками при выполнении приложений или невозможностью выполнить
- 32. Восстановимость Восстановимость расписаний: транзакции должны фиксироваться до того, как их результаты используются другими транзакциями Пример невосстановимого
- 33. Откат По команде rollback система откатит транзакцию на начало (на неявную точку отката) По команде commit
- 34. Оптимистический и пессимистический подходы Для обеспечения целостности транзакции СУБД может откладывать запись изменений в БД до
- 35. Сегмент отката (rollback segment, RBS) Сегмент отката – это специальная область памяти на диске, в которую
- 36. Savepoint savepoint запоминает промежуточную "текущую копию" состояния базы данных для того, чтобы при необходимости можно было
- 37. Журнал транзакций Журнал транзакций – это часть БД, в которую поступают данные обо всех изменениях всех
- 38. Ведение журнала Журнал ведется последовательно Опережающая запись в журнал (WAL, write-ahead log) Регистрируются операции записи, начала
- 39. Фиксация транзакции Изменения, внесённые транзакцией, помечаются как постоянные. Уничтожаются все точки сохранения для данной транзакции. Если
- 40. Восстановление после системных отказов Необходим рестарт сервера БД Для того, чтобы восстановление было возможным, необходимо вести
- 41. Общие принципы восстановления результаты зафиксированных транзакций должны быть сохранены в восстановленном состоянии базы данных; результаты незафиксированных
- 42. Что нужно сделать при восстановлении Определить, какие транзакции были зафиксированы до отказа и какие были активными
- 43. Журнал транзакций сохранение промежуточных состояний, подтверждение транзакции, отката транзакции
- 44. Журнал транзакций поддерживает: восстановление отдельных транзакций; восстановление всех незавершенных транзакций при запуске SQL Server; откат восстановленной
- 45. Алгоритм восстановления при рестарте Фаза просмотра: найти все зафиксированные и активные транзакции (прямой просмотр журнала) Фаза
- 46. Завершение восстановления После завершения фазы отката необходимо Записать на диск все измененные блоки БД После записи
- 47. CREATE DATABASE Sales ON ( NAME = Sales_dat, FILENAME = 'C:\tmp\saledat.mdf', SIZE = 10, MAXSIZE =
- 48. Усечение журнала транзакций Процесс усечения журнала освобождает место в файле журнала для повторного использования журналом транзакций.
- 49. Сжатие журнала Усечение журнала не приводит к уменьшению размера физического файла журнала. Для уменьшения реального размера
- 50. Модель транзакций
- 52. Скачать презентацию

Компоненты менеджера транзакций
Менеджер блокировок для конкурентного доступа.
Менеджер восстановления.
Буферный пул для хранения
Компоненты менеджера транзакций
Менеджер блокировок для конкурентного доступа.
Менеджер восстановления.
Буферный пул для хранения

Менеджер блокировок
Две стратегии:
Блокировка
Восстановление
Менеджер блокировок
Две стратегии:
Блокировка
Восстановление

Механизмы управления согласованием в многопользовательской среде
Multi-Granular Locking scheme (сокращённо MGL, также
Механизмы управления согласованием в многопользовательской среде
Multi-Granular Locking scheme (сокращённо MGL, также

LSCC - схема гранулированных синхронизационных захватов
Одна строка – одна запись =>
эксклюзивная
LSCC - схема гранулированных синхронизационных захватов
Одна строка – одна запись => эксклюзивная
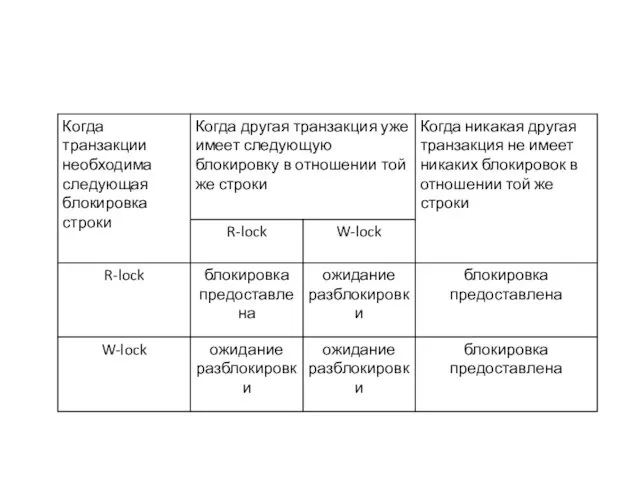

READ UNCOMMITTED
Уровень изолированности READ UNCOMMITTED не требует R-блокировки для защиты от
READ UNCOMMITTED
Уровень изолированности READ UNCOMMITTED не требует R-блокировки для защиты от

Снятие блокировок
В случае уровня изолированности Read Committed, R-блокировка строки будет снята
Снятие блокировок
В случае уровня изолированности Read Committed, R-блокировка строки будет снята

Блокировка таблиц
В некоторых продуктах СУБД диалект SQL включает явные команды LOCK
Блокировка таблиц
В некоторых продуктах СУБД диалект SQL включает явные команды LOCK
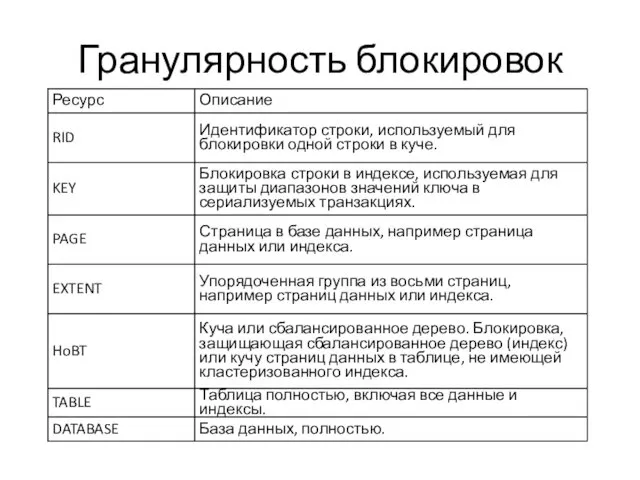
Гранулярность блокировок
Гранулярность блокировок

Уровни блокировок
Table (TAB): Это самая грубая логическая блокировка, которую может использовать
Уровни блокировок
Table (TAB): Это самая грубая логическая блокировка, которую может использовать

Уровни блокировок
Высокая конкурентность означает, что множество пользователей может работать одновременно. По
Уровни блокировок
Высокая конкурентность означает, что множество пользователей может работать одновременно. По
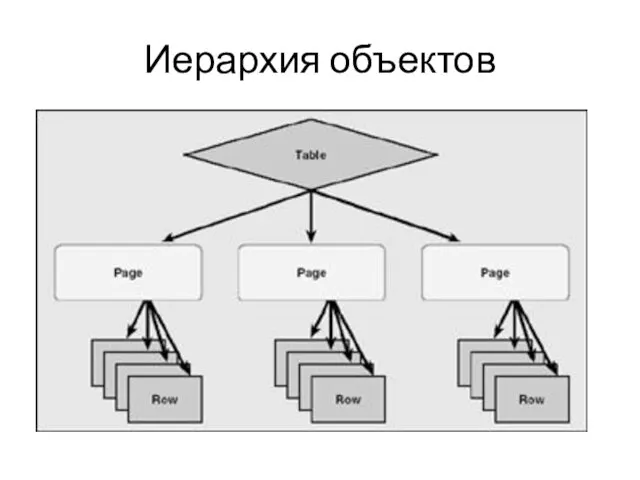
Иерархия объектов
Иерархия объектов

Эскалация блокировок
Эскалация блокировок – это процесс, при котором множество блокировок с
Эскалация блокировок
Эскалация блокировок – это процесс, при котором множество блокировок с

Проблемы маленьких блокировок
Locking overhead. иногда выгоднее наложить одну блокировку с большей
Проблемы маленьких блокировок
Locking overhead. иногда выгоднее наложить одну блокировку с большей

Подсказки оптимизатору
По умолчанию сервер старается наложить блокировку min гранулярности. Если сервер
Подсказки оптимизатору
По умолчанию сервер старается наложить блокировку min гранулярности. Если сервер

Бесконечное ожидание
Протокол блокировки уладит проблему потерянных обновлений, но если конкурирующие транзакции
Бесконечное ожидание
Протокол блокировки уладит проблему потерянных обновлений, но если конкурирующие транзакции
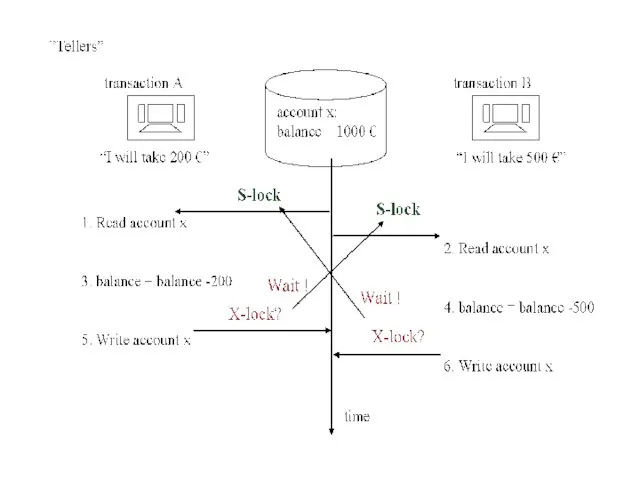

Важно помнить, что никакая СУБД не может автоматически перезапустить прерванную взаимной
Важно помнить, что никакая СУБД не может автоматически перезапустить прерванную взаимной

MVCC - многоверсионное управление параллелизмом
В MVCC техника такова, что сервер сохраняет
MVCC - многоверсионное управление параллелизмом
В MVCC техника такова, что сервер сохраняет

MVCC - многоверсионное управление параллелизмом
Любая транзакция с уровнем изолированности READ COMMITTED
MVCC - многоверсионное управление параллелизмом
Любая транзакция с уровнем изолированности READ COMMITTED
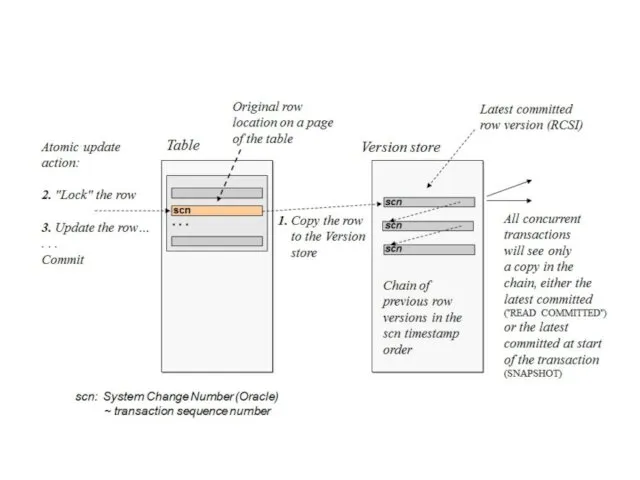

В MVCC Oracle первой транзакции для записи строки (то есть для
В MVCC Oracle первой транзакции для записи строки (то есть для

Технику управления параллелизмом в Oracle можно назвать гибридным CC, так как
Технику управления параллелизмом в Oracle можно назвать гибридным CC, так как

Механизм управления параллелизмом в MySQL/InnoDB является реальным гибридным CC, обеспечивающим для
Механизм управления параллелизмом в MySQL/InnoDB является реальным гибридным CC, обеспечивающим для

OCC - управление оптимистичным параллелизмом
Begin: Пометка о времени начала транзакции.
Modify: Чтение
OCC - управление оптимистичным параллелизмом
Begin: Пометка о времени начала транзакции.
Modify: Чтение

Восстановление
Индивидуальный откат транзакции.
Восстановление после внезапной потери содержимого оперативной памяти.
Восстановление
Восстановление
Индивидуальный откат транзакции.
Восстановление после внезапной потери содержимого оперативной памяти.
Восстановление

Отказы приложений
завершение оператором ROLLBACK;
аварийное завершение работы прикладной программы;
принудительный откат
Отказы приложений
завершение оператором ROLLBACK;
аварийное завершение работы прикладной программы;
принудительный откат

Технические проблемы
Мягкий сбой
при аварийном выключении электрического питания;
при возникновении неустранимого
Технические проблемы
Мягкий сбой
при аварийном выключении электрического питания;
при возникновении неустранимого

Возобновление при отказах
Отказы приложений/транзакции: транзакции обрываются
Отказы системы: функционирование возобновляется после рестарта
Возобновление при отказах
Отказы приложений/транзакции: транзакции обрываются
Отказы системы: функционирование возобновляется после рестарта

Восстановление оборванных транзакций: откат
Обрывы транзакций могут быть вызваны ошибками при выполнении
Восстановление оборванных транзакций: откат
Обрывы транзакций могут быть вызваны ошибками при выполнении

Восстановимость
Восстановимость расписаний: транзакции должны фиксироваться до того, как их результаты используются
Восстановимость
Восстановимость расписаний: транзакции должны фиксироваться до того, как их результаты используются

Откат
По команде rollback система откатит транзакцию на начало (на неявную точку
Откат
По команде rollback система откатит транзакцию на начало (на неявную точку

Оптимистический и пессимистический подходы
Для обеспечения целостности транзакции СУБД может откладывать запись
Оптимистический и пессимистический подходы
Для обеспечения целостности транзакции СУБД может откладывать запись

Сегмент отката
(rollback segment, RBS)
Сегмент отката – это специальная область памяти
Сегмент отката
(rollback segment, RBS)
Сегмент отката – это специальная область памяти

Savepoint
savepoint запоминает промежуточную "текущую копию" состояния базы данных для того, чтобы
Savepoint
savepoint запоминает промежуточную "текущую копию" состояния базы данных для того, чтобы

Журнал транзакций
Журнал транзакций – это часть БД, в которую поступают данные
Журнал транзакций
Журнал транзакций – это часть БД, в которую поступают данные

Ведение журнала
Журнал ведется последовательно
Опережающая запись в журнал (WAL, write-ahead log)
Регистрируются операции
Ведение журнала
Журнал ведется последовательно
Опережающая запись в журнал (WAL, write-ahead log)
Регистрируются операции

Фиксация транзакции
Изменения, внесённые транзакцией, помечаются как постоянные.
Уничтожаются все точки сохранения
Фиксация транзакции
Изменения, внесённые транзакцией, помечаются как постоянные.
Уничтожаются все точки сохранения

Восстановление
после системных отказов
Необходим рестарт сервера БД
Для того, чтобы восстановление было
Восстановление
после системных отказов
Необходим рестарт сервера БД
Для того, чтобы восстановление было

Общие принципы восстановления
результаты зафиксированных транзакций должны быть сохранены в восстановленном
Общие принципы восстановления
результаты зафиксированных транзакций должны быть сохранены в восстановленном

Что нужно сделать при восстановлении
Определить, какие транзакции были зафиксированы до отказа
Что нужно сделать при восстановлении
Определить, какие транзакции были зафиксированы до отказа

Журнал транзакций
сохранение промежуточных состояний,
подтверждение транзакции,
отката транзакции
Журнал транзакций
сохранение промежуточных состояний,
подтверждение транзакции,
отката транзакции

Журнал транзакций поддерживает:
восстановление отдельных транзакций;
восстановление всех незавершенных транзакций при запуске SQL
Журнал транзакций поддерживает:
восстановление отдельных транзакций;
восстановление всех незавершенных транзакций при запуске SQL

Алгоритм восстановления при рестарте
Фаза просмотра: найти все зафиксированные и активные транзакции
Алгоритм восстановления при рестарте
Фаза просмотра: найти все зафиксированные и активные транзакции

Завершение восстановления
После завершения фазы отката необходимо
Записать на диск все измененные блоки
Завершение восстановления
После завершения фазы отката необходимо
Записать на диск все измененные блоки

CREATE DATABASE Sales
ON ( NAME = Sales_dat, FILENAME = 'C:\tmp\saledat.mdf',
CREATE DATABASE Sales
ON ( NAME = Sales_dat, FILENAME = 'C:\tmp\saledat.mdf',

Усечение журнала транзакций
Процесс усечения журнала освобождает место в файле журнала для
Усечение журнала транзакций
Процесс усечения журнала освобождает место в файле журнала для

Сжатие журнала
Усечение журнала не приводит к уменьшению размера физического файла журнала.
Для
Сжатие журнала
Усечение журнала не приводит к уменьшению размера физического файла журнала.
Для
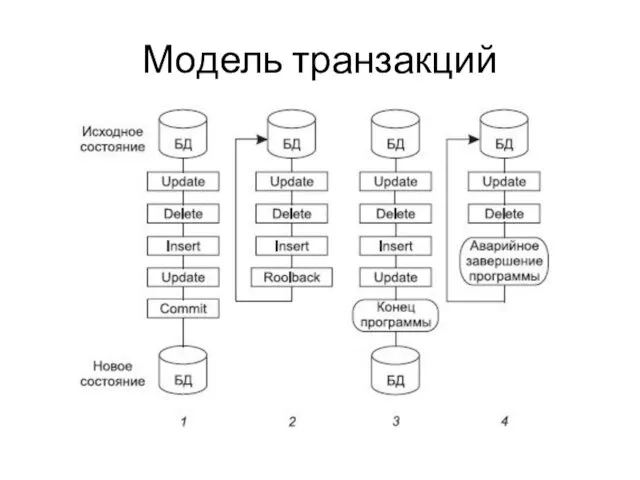
Модель транзакций
Модель транзакций
 Производство: затраты, выручка, прибыль
Производство: затраты, выручка, прибыль Школа светофора для малышей.
Школа светофора для малышей. Двенадцатипульсовые схемы выпрямления
Двенадцатипульсовые схемы выпрямления Радиационная безопасность
Радиационная безопасность МИНИ-МУЗЕЙ ИГРУШКИ-ЗАБАВЫ
МИНИ-МУЗЕЙ ИГРУШКИ-ЗАБАВЫ Урок-тренинг в двух частях Зимнее путешествие
Урок-тренинг в двух частях Зимнее путешествие Поточные системы шифрования. АПС 2-2-1. Тема № 2
Поточные системы шифрования. АПС 2-2-1. Тема № 2 Нормативный проект Сколько нужно мне игрушек?
Нормативный проект Сколько нужно мне игрушек? Совершенствование системы разрешения конфликтов в современной организации
Совершенствование системы разрешения конфликтов в современной организации Санитарные требования к проведению уборки. Выбор моющих средств
Санитарные требования к проведению уборки. Выбор моющих средств Конструирование урока по ФГОС
Конструирование урока по ФГОС Олександр Довженко
Олександр Довженко Основные параметры колодок
Основные параметры колодок Творчество Корнея Ивановича Чуковского. (1 класс)
Творчество Корнея Ивановича Чуковского. (1 класс) Лексикология и лексикография
Лексикология и лексикография Строение мышц
Строение мышц Химия. Лекция №1. Элементы химической термодинамики и биоэнергетики
Химия. Лекция №1. Элементы химической термодинамики и биоэнергетики Правила дорожного движения
Правила дорожного движения Папа, мама,я- спортивная семья!
Папа, мама,я- спортивная семья! Интеллектуальная игра для учащихся начальной школы Умники и умницы
Интеллектуальная игра для учащихся начальной школы Умники и умницы Явление тяготения. Сила тяжести
Явление тяготения. Сила тяжести Страны Северной Европы
Страны Северной Европы Структура рынка консалтинговых услуг
Структура рынка консалтинговых услуг Урок по теме Неорганические и органические кислоты
Урок по теме Неорганические и органические кислоты Загальна будова комп’ютера
Загальна будова комп’ютера Зороастризм (маздаїзм, авестизм)
Зороастризм (маздаїзм, авестизм) Транспорт на электромагнитной подвеске
Транспорт на электромагнитной подвеске Учимся читать с паровозиком - обучение плавному слоговому чтению.
Учимся читать с паровозиком - обучение плавному слоговому чтению.