- Методы повышения производительности микропроцессора. Лекция 11

Содержание
- 2. Повышение производительности вычислительно системы Основой для повышения производительности вычислительной системы является принцип "совмещения операций", при котором
- 3. Цикл выполнения команды Программа состоит из машинных команд. Программа загружается в память компьютера. Затем программа начинает
- 4. Выборка команды. Блок управления извлекает команду из памяти программ, копирует её во внутреннюю память процессора и
- 5. Совмещение операций во времени с использованием конвейерного регистра Конвейеризация Декомпозиция вычислительного устройства Рисунок 1 – Структура
- 6. Пока конвейерный регистр (КР) хранит текущую микрокоманду, под действием которой в операционном устройстве (ОУ) выполняется операция,
- 7. Рисунок 3 – Схема тактирования и выполнения команды в конвейере PIC Рисунок 4 – Последовательность выполнения
- 8. Очередь команд Очередь команд – позволяет выбирать (аккумулировать) несколько последующих команд, пока выполняется предыдущая. Физически очередь
- 9. Шинный интерфейс инициирует выборку из памяти следующего командного слова, когда в очереди оказываются два свободных (пустых)
- 10. Очередь команд характеризуется: Разрядностью регистров – nОК Длиной очереди (количество регистров) – QОК где λОК –
- 11. Пример. Работа очереди команд для микропроцессора i8086 1 – команды регистр-регистр 2 – равномерная смесь команд
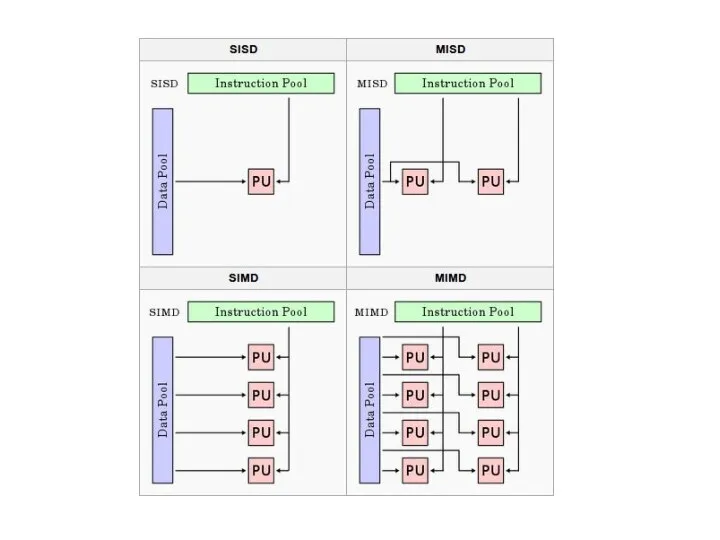
- 12. В 1966 году Майкл Флинн предложил следующую классификацию вычислительных систем, основанную на количестве потоков входных данных
- 13. Вычислительный процесс типа SISD (англ. Single Instruction Single Data) – одиночный поток команд и одиночный поток
- 14. Вычислительный процесс SIMD (англ. Single Instruction Multiple Data — последовательный поток команд и параллельный поток данных),
- 15. Вычислительный процесс MISD обеспечивает большую скорость обработки информации по сравнению с последовательным процессом типа SIMD, поскольку
- 16. Вычислительный процесс типа MIMD (англ. Multiple Instruction Multiple Data) – множественный поток команд и множественный поток
- 18. Память в SMP системе служит, в частности, для передачи сообщений между процессорами, при этом все вычислительные
- 19. Основные преимущества SMP-систем: — простота и универсальность для программирования. Архитектура SMP не накладывает ограничений на модель
- 20. Массивно-параллельная архитектура MPP (англ. Massive Parallel Processing,) — класс архитектур параллельных вычислительных систем. Особенность архитектуры состоит
- 21. Достоинства MРP: хорошая масштабируемость. Легко подобрать оптимальную конфигурацию вычислительной системы изменяя количество процессоров если заранее известна
- 22. NUMA архитектура NUMA (англ. nonuniform memory access) – система с неоднородным доступом к памяти это гибридная
- 23. Метакомпьютинг – способ решения трудоёмких вычислительных задач с использованием нескольких компьютеров с различной архитектурой и различной
- 25. Скачать презентацию

Повышение производительности вычислительно системы
Основой для повышения производительности вычислительной системы является принцип
Повышение производительности вычислительно системы
Основой для повышения производительности вычислительной системы является принцип

Цикл выполнения команды
Программа состоит из машинных команд. Программа загружается в память
Цикл выполнения команды
Программа состоит из машинных команд. Программа загружается в память

Выборка команды. Блок управления извлекает команду из памяти программ, копирует её
Выборка команды. Блок управления извлекает команду из памяти программ, копирует её
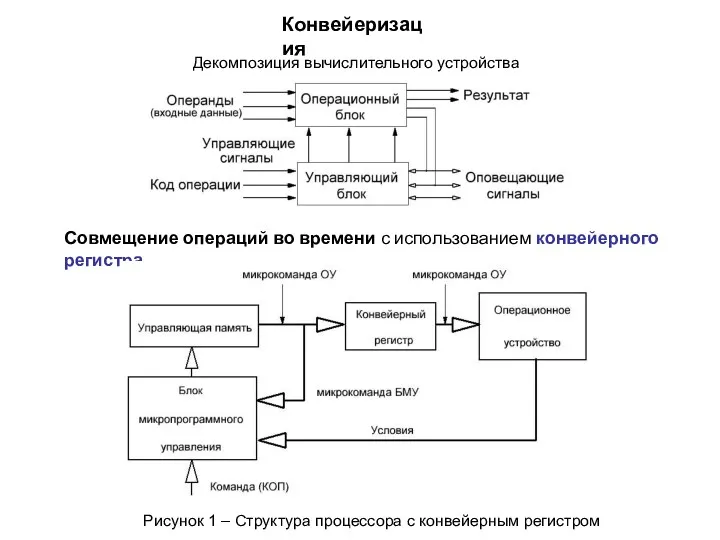
Совмещение операций во времени с использованием конвейерного регистра
Конвейеризация
Декомпозиция вычислительного устройства
Рисунок 1
Совмещение операций во времени с использованием конвейерного регистра
Конвейеризация
Декомпозиция вычислительного устройства
Рисунок 1
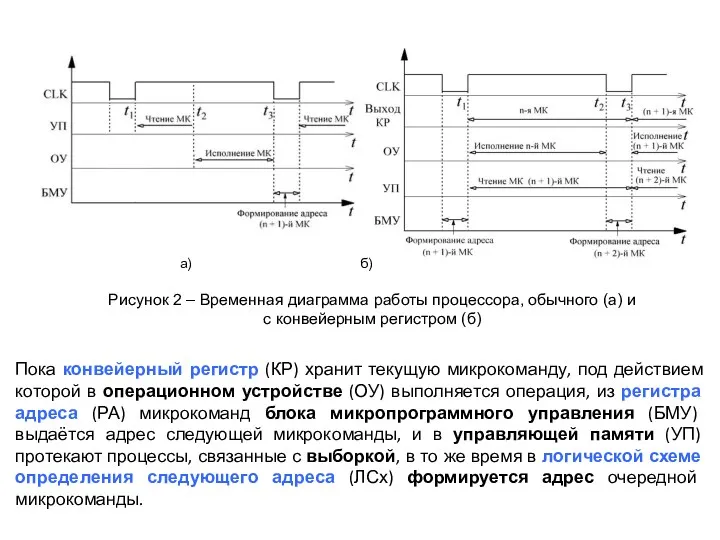
Пока конвейерный регистр (КР) хранит текущую микрокоманду, под действием которой в
Пока конвейерный регистр (КР) хранит текущую микрокоманду, под действием которой в
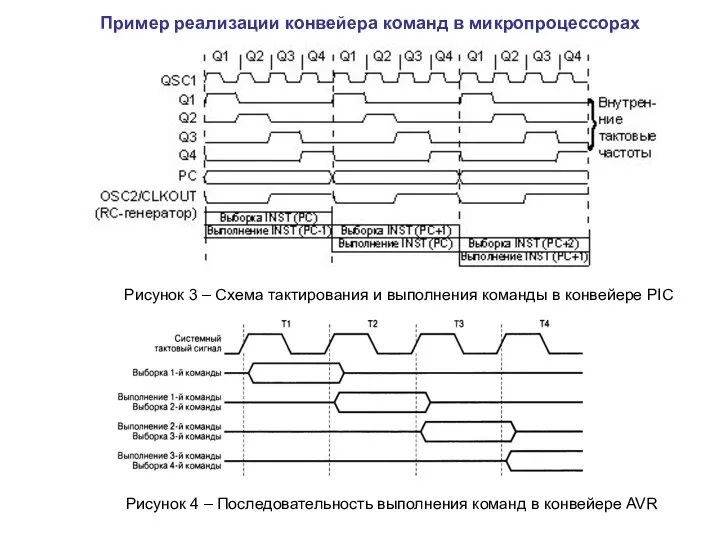
Рисунок 3 – Схема тактирования и выполнения команды в конвейере PIC
Рисунок 3 – Схема тактирования и выполнения команды в конвейере PIC
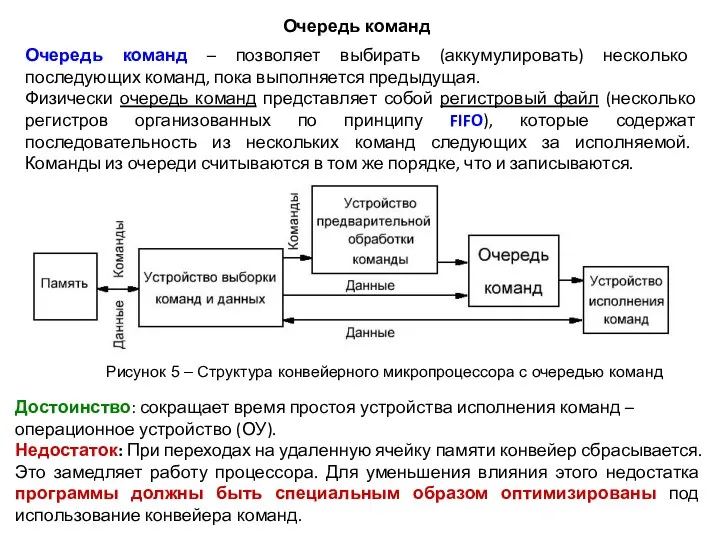
Очередь команд
Очередь команд – позволяет выбирать (аккумулировать) несколько последующих команд, пока
Очередь команд
Очередь команд – позволяет выбирать (аккумулировать) несколько последующих команд, пока

Шинный интерфейс инициирует выборку из памяти следующего командного слова, когда в
Шинный интерфейс инициирует выборку из памяти следующего командного слова, когда в

Очередь команд характеризуется:
Разрядностью регистров – nОК
Длиной очереди (количество регистров) – QОК
где
Очередь команд характеризуется:
Разрядностью регистров – nОК
Длиной очереди (количество регистров) – QОК
где

Пример. Работа очереди команд для микропроцессора i8086
1 – команды регистр-регистр
2 –
Пример. Работа очереди команд для микропроцессора i8086
1 – команды регистр-регистр
2 –

В 1966 году Майкл Флинн предложил следующую классификацию вычислительных систем, основанную
В 1966 году Майкл Флинн предложил следующую классификацию вычислительных систем, основанную
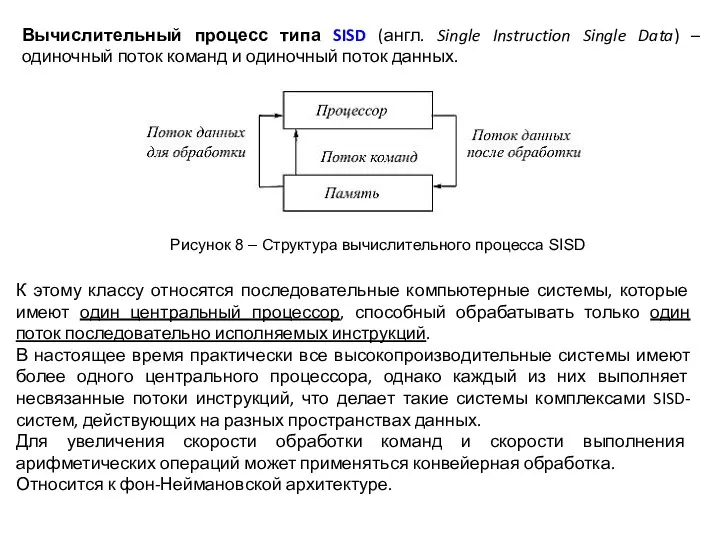
Вычислительный процесс типа SISD (англ. Single Instruction Single Data) – одиночный
Вычислительный процесс типа SISD (англ. Single Instruction Single Data) – одиночный
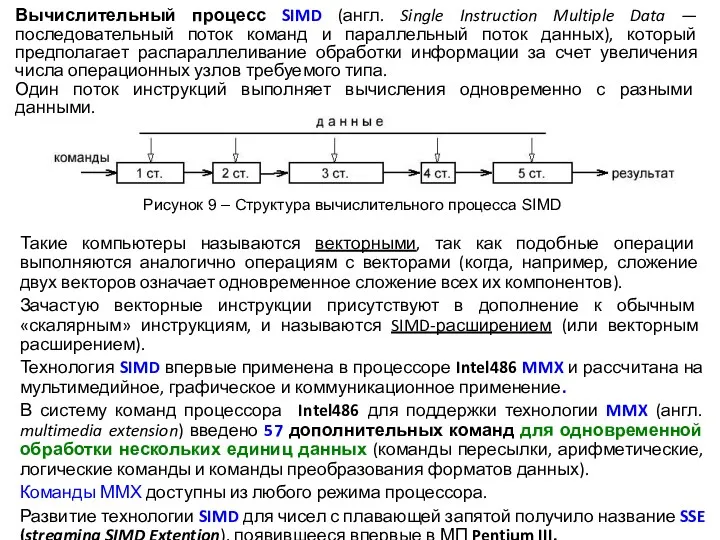
Вычислительный процесс SIMD (англ. Single Instruction Multiple Data — последовательный поток
Вычислительный процесс SIMD (англ. Single Instruction Multiple Data — последовательный поток
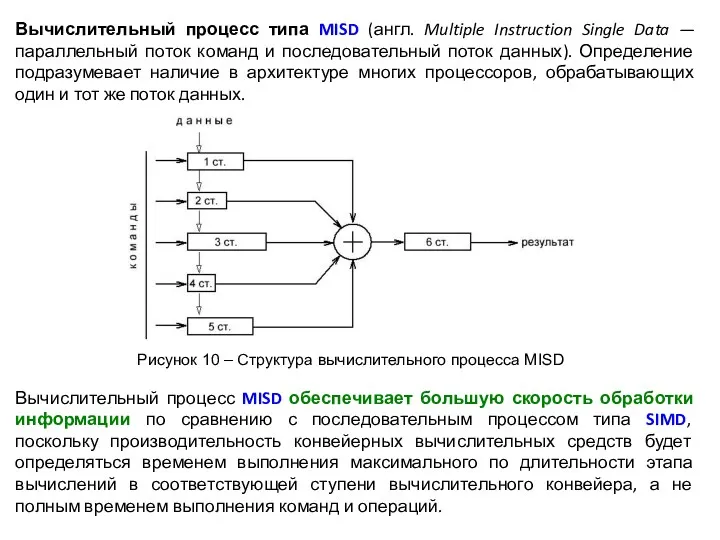
Вычислительный процесс MISD обеспечивает большую скорость обработки информации по сравнению с
Вычислительный процесс MISD обеспечивает большую скорость обработки информации по сравнению с

Вычислительный процесс типа MIMD (англ. Multiple Instruction Multiple Data) – множественный
Вычислительный процесс типа MIMD (англ. Multiple Instruction Multiple Data) – множественный
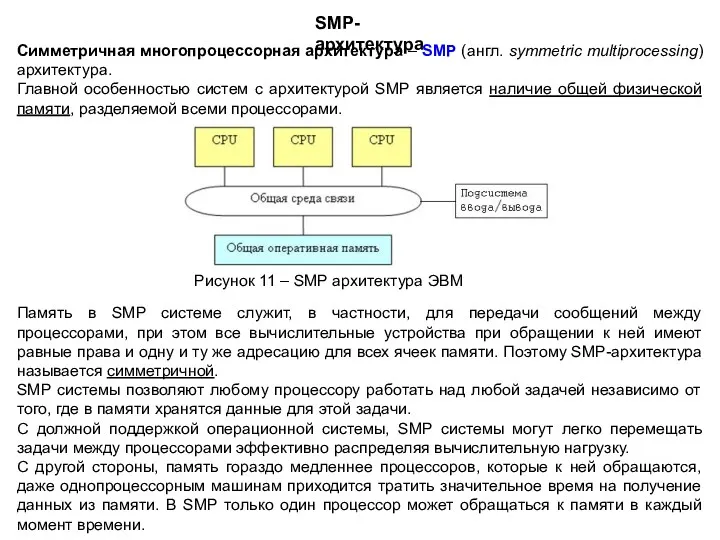
Память в SMP системе служит, в частности, для передачи сообщений между
Память в SMP системе служит, в частности, для передачи сообщений между

Основные преимущества SMP-систем:
— простота и универсальность для программирования.
Архитектура SMP не
Основные преимущества SMP-систем:
— простота и универсальность для программирования.
Архитектура SMP не
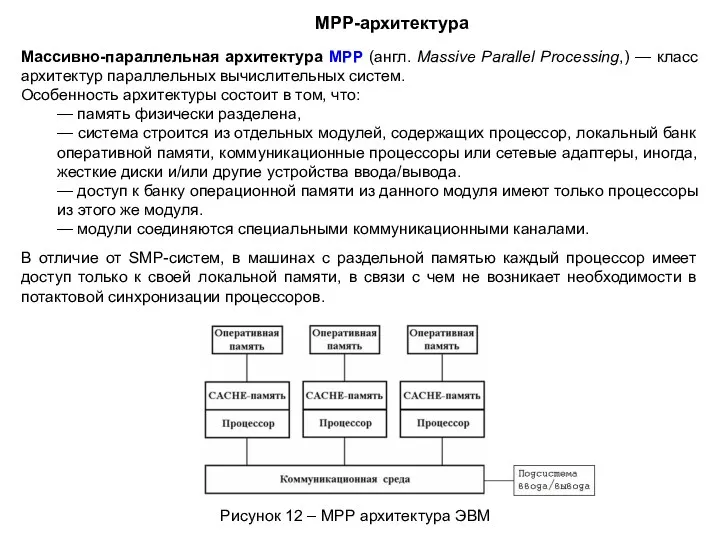
Массивно-параллельная архитектура MPP (англ. Massive Parallel Processing,) — класс архитектур параллельных
Массивно-параллельная архитектура MPP (англ. Massive Parallel Processing,) — класс архитектур параллельных

Достоинства MРP: хорошая масштабируемость.
Легко подобрать оптимальную конфигурацию вычислительной системы изменяя
Достоинства MРP: хорошая масштабируемость.
Легко подобрать оптимальную конфигурацию вычислительной системы изменяя
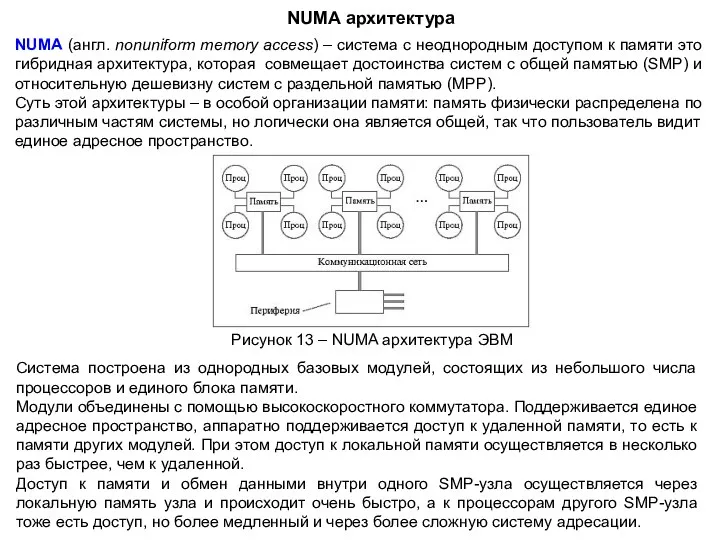
NUMA архитектура
NUMA (англ. nonuniform memory access) – система с неоднородным доступом
NUMA архитектура
NUMA (англ. nonuniform memory access) – система с неоднородным доступом
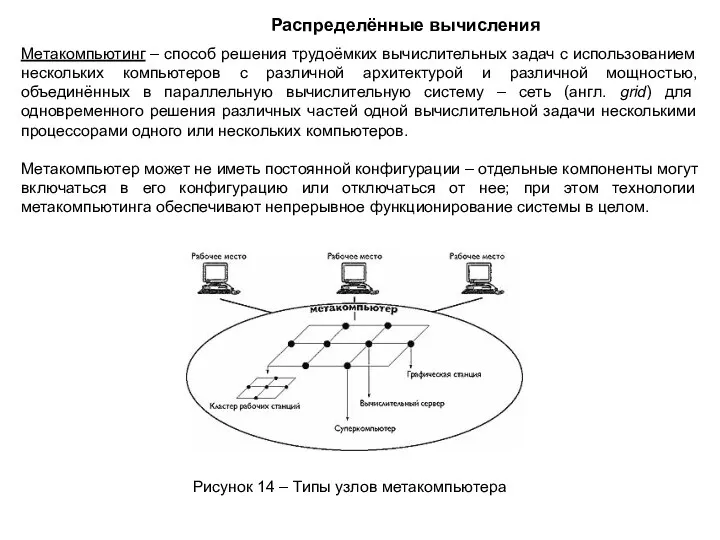
Метакомпьютинг – способ решения трудоёмких вычислительных задач с использованием нескольких компьютеров
Метакомпьютинг – способ решения трудоёмких вычислительных задач с использованием нескольких компьютеров
 Уроженцы Бабушкинского района - Герои Советского Союза
Уроженцы Бабушкинского района - Герои Советского Союза Парадоксы жизни
Парадоксы жизни Тест по теме Арктические пустыни, тундра, лесотундра
Тест по теме Арктические пустыни, тундра, лесотундра Образовательной программы дошкольной образовательной организации
Образовательной программы дошкольной образовательной организации ТРЕНАЖЕРНО- ИНФОРМАЦИОННАЯ СИСТЕМА ТИСА В ШКОЛЬНОЙ ПРОГРАММЕ НА УРОКАХ ЛФК
ТРЕНАЖЕРНО- ИНФОРМАЦИОННАЯ СИСТЕМА ТИСА В ШКОЛЬНОЙ ПРОГРАММЕ НА УРОКАХ ЛФК Dwayne Douglas Johnson
Dwayne Douglas Johnson Операционные усилители
Операционные усилители Бизнес-планирование. Модуль 6
Бизнес-планирование. Модуль 6 Похититель рассудка
Похититель рассудка Осложнения повреждений опорно-двигательного аппарата
Осложнения повреждений опорно-двигательного аппарата Past Simple
Past Simple speakout
speakout Жилища народов России в старину
Жилища народов России в старину Спектры и спектральный анализ
Спектры и спектральный анализ Заболевания сердечно-сосудистой системы
Заболевания сердечно-сосудистой системы Достижения педагога
Достижения педагога Эксперту: Структура и содержание устной части
Эксперту: Структура и содержание устной части дыхательная недостаточность
дыхательная недостаточность fb-5fa0bf70
fb-5fa0bf70 Презентация Развиваем мелкую моторику рук
Презентация Развиваем мелкую моторику рук Презентация Озера
Презентация Озера Массаж
Массаж Дополнительные авторские программы художественно - эстетической направленности: ХУДОЖЕСТВЕННЫЙ ЯЗЫК ИЗОБРАЗИТЕЛЬНОГО ИСКУССТВА, СМОТРЮ НА МИР ГЛАЗАМИ ХУДОЖНИКА, ВОЛШЕБНЫЕ СЕКРЕТЫ ХУДОЖНИКА, В МИРЕ ХУДОЖ
Дополнительные авторские программы художественно - эстетической направленности: ХУДОЖЕСТВЕННЫЙ ЯЗЫК ИЗОБРАЗИТЕЛЬНОГО ИСКУССТВА, СМОТРЮ НА МИР ГЛАЗАМИ ХУДОЖНИКА, ВОЛШЕБНЫЕ СЕКРЕТЫ ХУДОЖНИКА, В МИРЕ ХУДОЖ Tsesnabank
Tsesnabank Технология культурных практик (коллекционирование)
Технология культурных практик (коллекционирование) Военно-промышленный комплекс
Военно-промышленный комплекс Понятие об органах растений. Корень
Понятие об органах растений. Корень РАЗВИВАЮЩАЯ СРЕДА В КОРРЕКЦИОННОЙ ГРУППЕ ЗНАЙКИ ПО ФГОС
РАЗВИВАЮЩАЯ СРЕДА В КОРРЕКЦИОННОЙ ГРУППЕ ЗНАЙКИ ПО ФГОС