- Микропроцессоры. Логические основы ЭВМ, элементы и узлы

Содержание
- 2. Процессором называется устройство, осуществляющее обработку данных и программное управление этим процессом. Процессор занимает центральное место в
- 3. Логические основы ЭВМ, элементы и узлы Основа: алгебра логики Алгебра логики – это раздел математической логики,
- 4. Триггеры Простейшая электронная схема триггера состоит из двух усилительных каскадов. Выход каждого из каскадов подключен к
- 5. Пример работы процессора В качестве примера, иллюстрирующего работу микро ЭВМ, рассмотрим процедуру, для реализации которой нужно
- 6. Схема Команды уже загружены в первые шесть ячеек памяти. Хранимая программа содержит следующую цепочку команд: 1.
- 7. Схема На рисунке в памяти программ записано шесть команд. Это связано с тем, что команда обычно
- 8. История Первым общедоступным микропроцессором был 4-разрядный Intel 4004, созданный в 1971 году корпорацией Intel. Он содержал
- 9. 4004. Блок-схема
- 10. История Все эти функциональные узлы объединялись между собой 4 - разрядной ШД. Память команд достигала 4
- 11. История Модуль i4004 не имел возможности останова (команды HALT) и обработки прерываний. Цикл команды процессора состоял
- 12. История. 8080 Далее его сменили 8-разрядный Intel 8080 и 16-разрядный 8086, заложившие основы архитектуры всех современных
- 13. История В процессоре 80286 появился защищённый режим с 24-битной адресацией, до 16 Мб памяти. Процессор Intel
- 14. Микропроцессор 80486 Кристалл микропроцессора Intel 80486DX2 Расположение кристалла в корпусе микропроцессора
- 15. Планарная технология Планарная технология — совокупность технологических операций, используемых при изготовлении планарных (плоских, поверхностных) полупроводниковых приборов
- 16. Планарная технология ПЛАНА́РНАЯ ТЕХНОЛО́ГИЯ (от лат. planus – плоский, ровный), совокупность способов изготовления полупроводниковых приборов и
- 17. Планарная технология Области структур создаются локальным введением в подложку примесей (посредством диффузии или ионной имплантации), осуществляемым
- 18. Планарная технология Все области имеют выход на одну сторону подложки, что позволяет через окна в плёнке
- 19. Планарная технология
- 20. Планарная технология Основные технологические операции, используемые в планарной технологии, основаны на процессе литографии (фотолитографии). Применяются следующие
- 21. Планарная технология
- 22. Функции микропроцессора вычисление адресов операндов или команд; выборка и дешифрация команд из оперативной памяти (ОП); выборка
- 23. Основные параметры микропроцессоров разрядность - разрядностью внутренних регистров, над которыми одновременно могут выполняться операции; адресное пространство
- 24. Классификация команд микропроцессора
- 25. Набор команд В зависимости от набора и порядка выполнения команд процессоры делятся на четыре класса: CISC
- 26. МП типа CISC Характеризуется следующим набором свойств: нефиксированное значение длины команды; арифметические действия кодируются в одной
- 27. МП типа CISC При этом поздние х86, хотя и CISC-совместимы, но являются процессорами с RISC-ядром, и
- 28. МП типа RISC Вычисления с сокращённым набором команд – это процессоры по следующему принципу: более компактные
- 29. Характерные особенности RISC -процессоров 1. Одинаковая длина команд (упрощает выборку из памяти); 2. Использование большого количество
- 30. Достоинства и недостатки Достоинства: — высокая тактовая частота; — высокая скорость выполнения команд; —уменьшение площади кристалла
- 31. МП типа VLIW Архитектура МП с несколькими вычислительными устройствами. Одна инструкция процессора содержит несколько операций, которые
- 32. МП типа VLIW Подход VLIW сильно упрощает архитектуру процессора, перекладывая задачу распределения вычислительных устройств на компилятор.
- 33. МП типа MISC Процессор, работающий с минимальным набором длинных команд. Увеличение разрядности процессоров привело к идее
- 34. Классификация Флинна В 1966 г. Флинном был предложен подход к классификации архитектур вычислительных систем. В его
- 35. Одиночный поток команд и одиночный поток данных К этому классу относятся последовательные компьютерные системы, которые имеют
- 36. Множественный поток команд и одиночный поток данных Ни Флинн, ни другие специалисты в области архитектуры компьютеров
- 37. Одиночный поток команд и множественный поток данных В таких системах единое управляющее устройство контролирует множество процессорных
- 38. Множественный поток команд и множественный поток данных Эти машины параллельно выполняют несколько потоков инструкций над различными
- 40. Ядро процессора Каждое ядро процессора состоит из нескольких функциональных блоков: блока выборки инструкций; блоков декодирования инструкций;
- 41. Блоки выборки инструкций и предсказатель перехода Блок выборки инструкций осуществляет считывание инструкций по адресу, указанному в
- 42. Блоки декодирования Это блоки, которые занимаются декодированием инструкций, т.е. определяют, что надо сделать процессору, и какие
- 43. Блоки выборки данных и управляющий блок Блоки выборки данных осуществляют выборку данных из КЭШ-памяти или ОЗУ,
- 44. Блоки выполнения инструкций Включают в себя несколько разнотипных блоков: ALU – арифметическое логическое устройство; FPU –
- 45. Популярными расширениями наборов инструкция являются: MMX (Multimedia Extensions) – набор инструкций, разработанный компанией Intel, для ускорения
- 46. Блоки сохранения результатов и работы с прерываниями Блок сохранения результатов обеспечивает запись результата выполнения инструкции в
- 47. Блок работы с прерываниями Обработка прерываний происходит следующим образом. Процессор перед началом каждого цикла работы проверяет
- 48. Регистры Регистры – сверхбыстрая оперативная память (доступ к регистрам в несколько раз быстрее доступа к КЭШ-памяти)
- 49. Счетчик команд Счетчик команд – регистр, содержащий адрес команды, которую процессор начнет выполнять на следующем такте
- 50. Цикл работы ядра процессора 1. Блок выборки инструкций проверяет наличие прерываний. Если прерывание есть, то данные
- 51. Цикл работы ядра процессора 4. Блок выборки данных считывает из КЭШ-памяти или ОЗУ требуемые для выполнения
- 52. Технологии повышения производительности ядра процессора Увеличение производительности ядра процессора, за счет поднятия тактовый частоты, имеет жесткое
- 53. Конвейеризация Каждая инструкция, выполняемая процессором, последовательно проходит все блоки ядра, в каждом из которых совершается своя
- 54. Конвейеризация. Пример
- 55. Конвейеризация Как видно, для выполнения пяти инструкций процессору понадобилось 25 тактов. При этом в каждом такте
- 56. Конвейеризация. Пример Та же программа была выполнена за 9 тактов, что почти 2.8 раза быстрее. Максимальная
- 57. Конвейеризация Во-первых, реальный поток команд, обрабатываемый процессором – не последовательный. В нем часто встречаются переходы. При
- 58. Конвейеризация Если условный переход удалось предсказать, то выполнение инструкций по новому адресу начинается раньше, чем будет
- 59. Конвейеризация В большинстве современных процессорах задача анализа взаимосвязи инструкций и составления порядка их обработки ложится на
- 60. Суперскалярность Суперскалярность – архитектура вычислительного ядра, при которой наиболее нагруженные блоки могут входить в нескольких экземплярах.
- 61. Многоядерность Подавляющее большинство современных процессоров имеют два и более ядра. Мы практически получаем несколько процессоров, способных
- 62. Многоядерность Во-вторых, усложняется работа с памятью, так как ядер – много, и всем им требуется доступ
- 63. Технология Hyper-Threading Технология Intel Hyper-threading позволяет каждому ядру процессора выполнять две задачи одновременно, делая из одного
- 64. Технология Hyper-Threading Большинство программ не могут полностью нагрузить процессор, так как некоторые, в основном, используют несложные
- 65. Технология Hyper-Threading Естественно, прирост производительности будет меньше, чем от использования нескольких физических ядер, так как потоки
- 66. Технология Turbo Boost Производительность большинства современных процессоров в поднять, разогнать – заставить работать на частотах, превышающих
- 68. Скачать презентацию

Процессором называется устройство, осуществляющее обработку данных и программное управление этим процессом.
Процессором называется устройство, осуществляющее обработку данных и программное управление этим процессом.

Логические основы ЭВМ, элементы и узлы
Основа: алгебра логики
Алгебра логики – это
Логические основы ЭВМ, элементы и узлы
Основа: алгебра логики
Алгебра логики – это
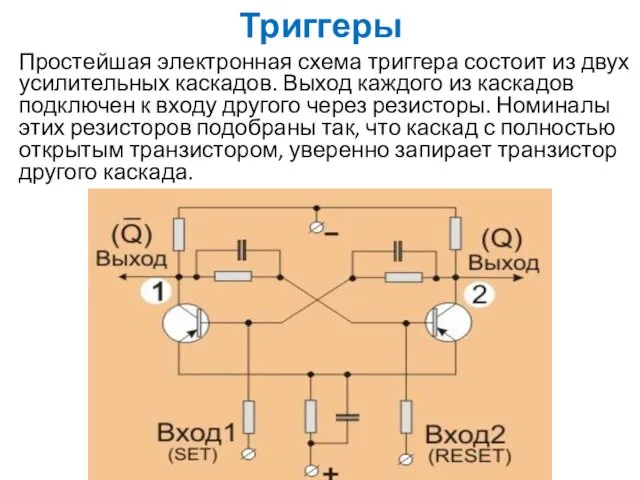
Триггеры
Простейшая электронная схема триггера состоит из двух усилительных каскадов. Выход каждого
Триггеры
Простейшая электронная схема триггера состоит из двух усилительных каскадов. Выход каждого

Пример работы процессора
В качестве примера, иллюстрирующего работу микро ЭВМ, рассмотрим процедуру,
Пример работы процессора
В качестве примера, иллюстрирующего работу микро ЭВМ, рассмотрим процедуру,
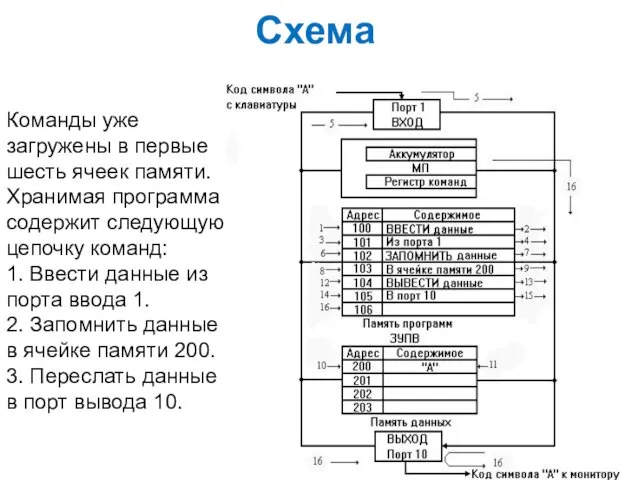
Схема
Команды уже загружены в первые шесть ячеек памяти. Хранимая программа содержит
Схема
Команды уже загружены в первые шесть ячеек памяти. Хранимая программа содержит

Схема
На рисунке в памяти программ записано шесть команд. Это связано с
Схема
На рисунке в памяти программ записано шесть команд. Это связано с

История
Первым общедоступным микропроцессором был 4-разрядный Intel 4004, созданный в 1971 году
История
Первым общедоступным микропроцессором был 4-разрядный Intel 4004, созданный в 1971 году
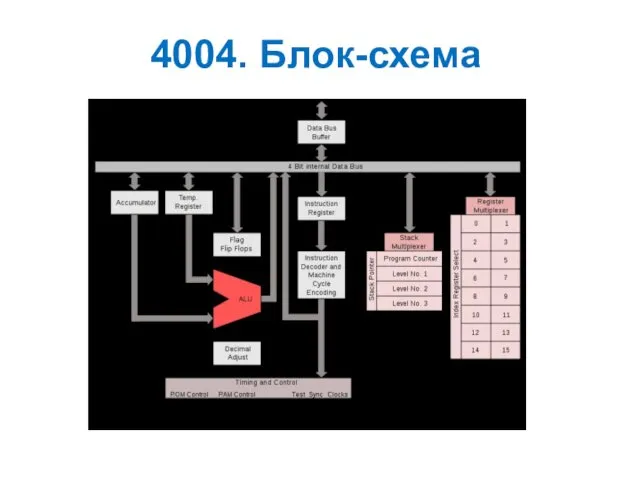
4004. Блок-схема
4004. Блок-схема

История
Все эти функциональные узлы объединялись между собой 4 - разрядной ШД.
История
Все эти функциональные узлы объединялись между собой 4 - разрядной ШД.

История
Модуль i4004 не имел возможности останова (команды HALT) и обработки прерываний.
История
Модуль i4004 не имел возможности останова (команды HALT) и обработки прерываний.

История. 8080
Далее его сменили 8-разрядный Intel 8080 и 16-разрядный 8086, заложившие
История. 8080
Далее его сменили 8-разрядный Intel 8080 и 16-разрядный 8086, заложившие

История
В процессоре 80286 появился защищённый режим с 24-битной адресацией, до 16
История
В процессоре 80286 появился защищённый режим с 24-битной адресацией, до 16

Микропроцессор 80486
Кристалл микропроцессора Intel 80486DX2
Расположение кристалла в корпусе микропроцессора
Микропроцессор 80486
Кристалл микропроцессора Intel 80486DX2
Расположение кристалла в корпусе микропроцессора

Планарная технология
Планарная технология — совокупность технологических операций, используемых при изготовлении планарных
Планарная технология
Планарная технология — совокупность технологических операций, используемых при изготовлении планарных

Планарная технология
ПЛАНА́РНАЯ ТЕХНОЛО́ГИЯ (от лат. planus – плоский, ровный), совокупность способов изготовления
Планарная технология
ПЛАНА́РНАЯ ТЕХНОЛО́ГИЯ (от лат. planus – плоский, ровный), совокупность способов изготовления

Планарная технология
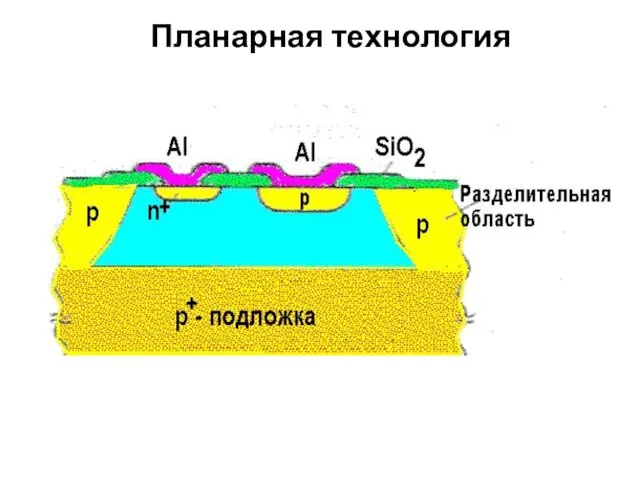
Области структур создаются локальным введением в подложку примесей (посредством диффузии
Планарная технология
Области структур создаются локальным введением в подложку примесей (посредством диффузии

Планарная технология
Все области имеют выход на одну сторону подложки, что позволяет
Планарная технология
Все области имеют выход на одну сторону подложки, что позволяет
Планарная технология
Планарная технология

Планарная технология
Основные технологические операции, используемые в планарной технологии, основаны на процессе
Планарная технология
Основные технологические операции, используемые в планарной технологии, основаны на процессе
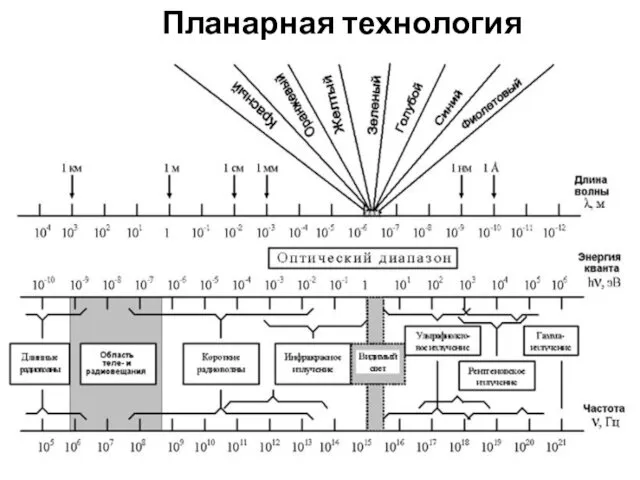
Планарная технология
Планарная технология

Функции микропроцессора
вычисление адресов операндов или команд;
выборка и дешифрация команд из оперативной
Функции микропроцессора
вычисление адресов операндов или команд;
выборка и дешифрация команд из оперативной

Основные параметры микропроцессоров
разрядность - разрядностью внутренних регистров, над которыми одновременно
Основные параметры микропроцессоров
разрядность - разрядностью внутренних регистров, над которыми одновременно
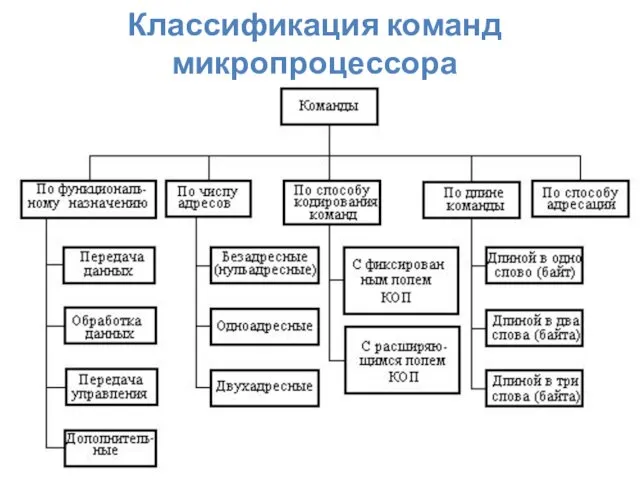
Классификация команд микропроцессора
Классификация команд микропроцессора

Набор команд
В зависимости от набора и порядка выполнения команд процессоры делятся
Набор команд
В зависимости от набора и порядка выполнения команд процессоры делятся

МП типа CISC
Характеризуется следующим набором свойств:
нефиксированное значение длины команды;
арифметические действия
МП типа CISC
Характеризуется следующим набором свойств:
нефиксированное значение длины команды;
арифметические действия

МП типа CISC
При этом поздние х86, хотя и CISC-совместимы, но
МП типа CISC
При этом поздние х86, хотя и CISC-совместимы, но

МП типа RISC
Вычисления с сокращённым набором команд – это процессоры
МП типа RISC
Вычисления с сокращённым набором команд – это процессоры

Характерные особенности RISC -процессоров
1. Одинаковая длина команд (упрощает выборку из памяти);
2.
Характерные особенности RISC -процессоров
1. Одинаковая длина команд (упрощает выборку из памяти);
2.

Достоинства и недостатки
Достоинства:
— высокая тактовая частота;
— высокая скорость выполнения команд;
—уменьшение площади
Достоинства и недостатки
Достоинства:
— высокая тактовая частота;
— высокая скорость выполнения команд;
—уменьшение площади

МП типа VLIW
Архитектура МП с несколькими вычислительными устройствами. Одна инструкция
МП типа VLIW
Архитектура МП с несколькими вычислительными устройствами. Одна инструкция

МП типа VLIW
Подход VLIW сильно упрощает архитектуру процессора, перекладывая задачу
МП типа VLIW
Подход VLIW сильно упрощает архитектуру процессора, перекладывая задачу

МП типа MISC
Процессор, работающий с минимальным набором длинных команд.
Увеличение
МП типа MISC
Процессор, работающий с минимальным набором длинных команд. Увеличение

Классификация Флинна
В 1966 г. Флинном был предложен подход к классификации архитектур
Классификация Флинна
В 1966 г. Флинном был предложен подход к классификации архитектур

Одиночный поток команд и одиночный поток данных
К этому классу относятся последовательные
Одиночный поток команд и одиночный поток данных
К этому классу относятся последовательные

Множественный поток команд и одиночный поток данных
Ни Флинн, ни другие специалисты
Множественный поток команд и одиночный поток данных
Ни Флинн, ни другие специалисты
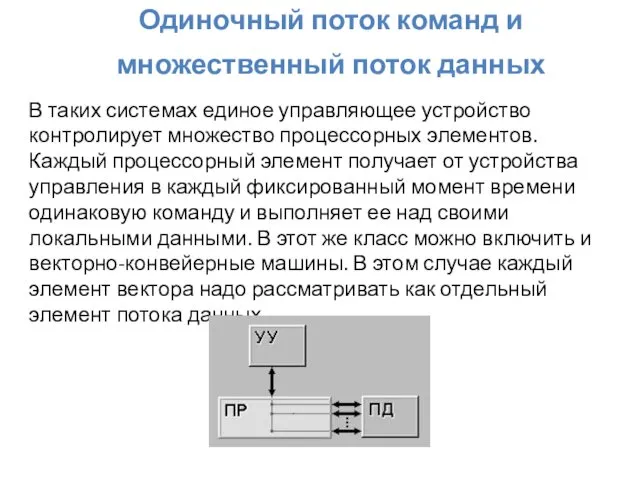
Одиночный поток команд и множественный поток данных
В таких системах единое
Одиночный поток команд и множественный поток данных
В таких системах единое

Множественный поток команд и множественный поток данных
Эти машины параллельно выполняют
Множественный поток команд и множественный поток данных
Эти машины параллельно выполняют
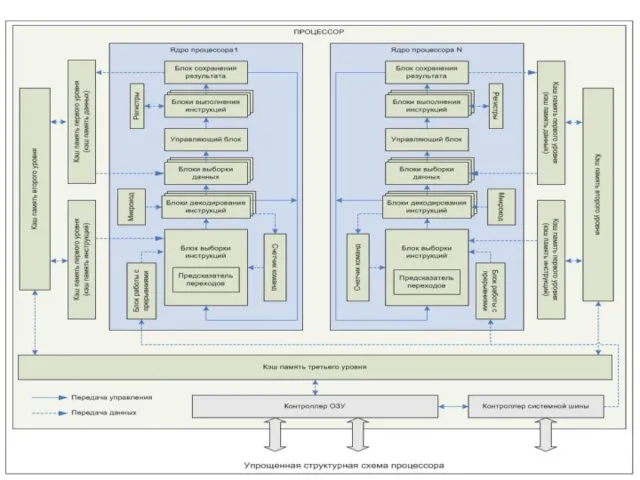

Ядро процессора
Каждое ядро процессора состоит из нескольких функциональных блоков:
блока выборки
Ядро процессора
Каждое ядро процессора состоит из нескольких функциональных блоков:
блока выборки

Блоки выборки инструкций и предсказатель перехода
Блок выборки инструкций осуществляет считывание инструкций
Блоки выборки инструкций и предсказатель перехода
Блок выборки инструкций осуществляет считывание инструкций

Блоки декодирования
Это блоки, которые занимаются декодированием инструкций, т.е. определяют, что надо
Блоки декодирования
Это блоки, которые занимаются декодированием инструкций, т.е. определяют, что надо

Блоки выборки данных и управляющий блок
Блоки выборки данных осуществляют выборку
Блоки выборки данных и управляющий блок
Блоки выборки данных осуществляют выборку

Блоки выполнения инструкций
Включают в себя несколько разнотипных блоков:
ALU – арифметическое
Блоки выполнения инструкций
Включают в себя несколько разнотипных блоков:
ALU – арифметическое

Популярными расширениями наборов инструкция являются:
MMX (Multimedia Extensions) – набор инструкций,
Популярными расширениями наборов инструкция являются:
MMX (Multimedia Extensions) – набор инструкций,

Блоки сохранения результатов и работы с прерываниями
Блок сохранения результатов обеспечивает запись
Блоки сохранения результатов и работы с прерываниями
Блок сохранения результатов обеспечивает запись

Блок работы с прерываниями
Обработка прерываний происходит следующим образом. Процессор перед началом
Блок работы с прерываниями
Обработка прерываний происходит следующим образом. Процессор перед началом

Регистры
Регистры – сверхбыстрая оперативная память (доступ к регистрам в несколько раз
Регистры
Регистры – сверхбыстрая оперативная память (доступ к регистрам в несколько раз

Счетчик команд
Счетчик команд – регистр, содержащий адрес команды, которую процессор начнет
Счетчик команд
Счетчик команд – регистр, содержащий адрес команды, которую процессор начнет

Цикл работы ядра процессора
1. Блок выборки инструкций проверяет наличие прерываний.
Цикл работы ядра процессора
1. Блок выборки инструкций проверяет наличие прерываний.

Цикл работы ядра процессора
4. Блок выборки данных считывает из КЭШ-памяти
Цикл работы ядра процессора
4. Блок выборки данных считывает из КЭШ-памяти

Технологии повышения производительности ядра процессора
Увеличение производительности ядра процессора, за счет поднятия
Технологии повышения производительности ядра процессора
Увеличение производительности ядра процессора, за счет поднятия

Конвейеризация
Каждая инструкция, выполняемая процессором, последовательно проходит все блоки ядра, в каждом
Конвейеризация
Каждая инструкция, выполняемая процессором, последовательно проходит все блоки ядра, в каждом
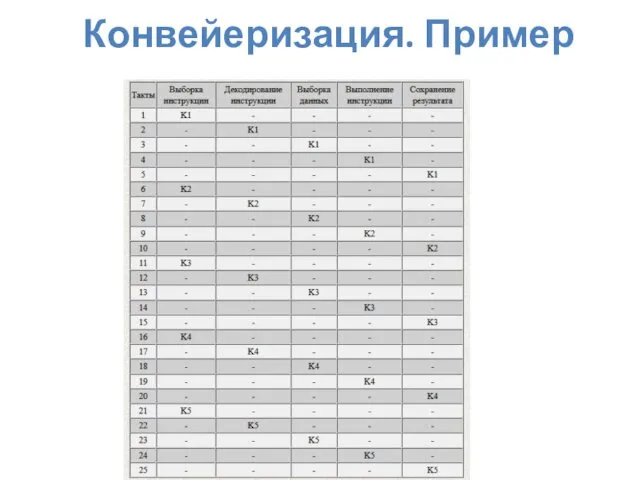
Конвейеризация. Пример
Конвейеризация. Пример

Конвейеризация
Как видно, для выполнения пяти инструкций процессору понадобилось 25 тактов. При
Конвейеризация
Как видно, для выполнения пяти инструкций процессору понадобилось 25 тактов. При
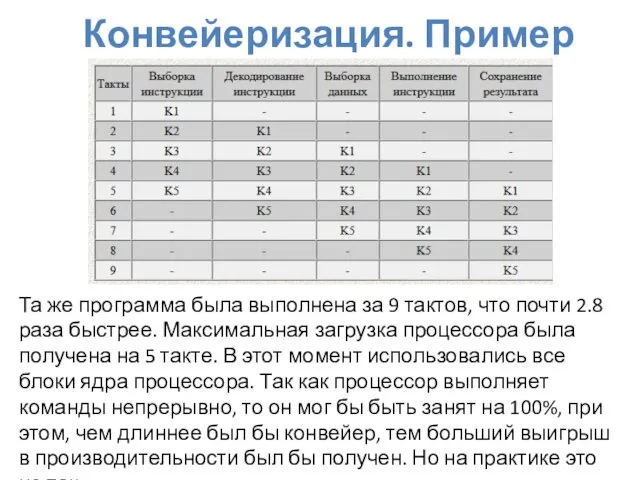
Конвейеризация. Пример
Та же программа была выполнена за 9 тактов, что почти
Конвейеризация. Пример
Та же программа была выполнена за 9 тактов, что почти

Конвейеризация
Во-первых, реальный поток команд, обрабатываемый процессором – не последовательный. В нем
Конвейеризация
Во-первых, реальный поток команд, обрабатываемый процессором – не последовательный. В нем

Конвейеризация
Если условный переход удалось предсказать, то выполнение инструкций по новому адресу
Конвейеризация
Если условный переход удалось предсказать, то выполнение инструкций по новому адресу

Конвейеризация
В большинстве современных процессорах задача анализа взаимосвязи инструкций и составления порядка
Конвейеризация
В большинстве современных процессорах задача анализа взаимосвязи инструкций и составления порядка

Суперскалярность
Суперскалярность – архитектура вычислительного ядра, при которой наиболее нагруженные блоки могут
Суперскалярность
Суперскалярность – архитектура вычислительного ядра, при которой наиболее нагруженные блоки могут

Многоядерность
Подавляющее большинство современных процессоров имеют два и более ядра. Мы практически
Многоядерность
Подавляющее большинство современных процессоров имеют два и более ядра. Мы практически

Многоядерность
Во-вторых, усложняется работа с памятью, так как ядер – много, и
Многоядерность
Во-вторых, усложняется работа с памятью, так как ядер – много, и

Технология Hyper-Threading
Технология Intel Hyper-threading позволяет каждому ядру процессора выполнять две задачи
Технология Hyper-Threading
Технология Intel Hyper-threading позволяет каждому ядру процессора выполнять две задачи

Технология Hyper-Threading
Большинство программ не могут полностью нагрузить процессор, так как некоторые,
Технология Hyper-Threading
Большинство программ не могут полностью нагрузить процессор, так как некоторые,

Технология Hyper-Threading
Естественно, прирост производительности будет меньше, чем от использования нескольких физических
Технология Hyper-Threading
Естественно, прирост производительности будет меньше, чем от использования нескольких физических

Технология Turbo Boost
Производительность большинства современных процессоров в поднять, разогнать – заставить
Технология Turbo Boost
Производительность большинства современных процессоров в поднять, разогнать – заставить
 Психолого-педагогические особенности обучения математике в 5-6 классах детей с ослабленным слухом
Психолого-педагогические особенности обучения математике в 5-6 классах детей с ослабленным слухом Глагол to have
Глагол to have Бактерии. Место бактерий в системе органического мира
Бактерии. Место бактерий в системе органического мира Великие Каппадокийцы. Свт. Григорий Назианзин, Богослов (ок. 330 года)
Великие Каппадокийцы. Свт. Григорий Назианзин, Богослов (ок. 330 года) Введение в комбинаторику
Введение в комбинаторику Действия с десятичными дробями
Действия с десятичными дробями Спрос на деньги. Равновесие на денежном рынке. Совокупный спрос. Фискальная и монетарная политика
Спрос на деньги. Равновесие на денежном рынке. Совокупный спрос. Фискальная и монетарная политика Цифровые системы передачи мультимедийной информации
Цифровые системы передачи мультимедийной информации Малярия:классификация, клиника, диагностика, лечение
Малярия:классификация, клиника, диагностика, лечение Викторина Вопрос на засыпку
Викторина Вопрос на засыпку презентация Сюжетно ролевая игра магазин сад-огород
презентация Сюжетно ролевая игра магазин сад-огород История фестивального движения
История фестивального движения Разновидности планирования ГПД
Разновидности планирования ГПД Вентиляция производственных зданий
Вентиляция производственных зданий Правила электробезопасности для детей
Правила электробезопасности для детей Музеи, театры, цирк
Музеи, театры, цирк Дидактические игры по экономике и финансам
Дидактические игры по экономике и финансам Социализация
Социализация Өнеге – отбасынан...
Өнеге – отбасынан... Мнемосказки в развитии связной речи у дошкольников
Мнемосказки в развитии связной речи у дошкольников Основы организации санитарно-гигиенического и противоэпидемического обеспечения войск в мирное и военное время
Основы организации санитарно-гигиенического и противоэпидемического обеспечения войск в мирное и военное время Компьютерная графика
Компьютерная графика Социальный проект Вместе в электронный век
Социальный проект Вместе в электронный век проект Животные в космосе
проект Животные в космосе Занимательные задания для автоматизации звуков С, З, Ц
Занимательные задания для автоматизации звуков С, З, Ц Võrdlusskeem magnitude comparator
Võrdlusskeem magnitude comparator Проектная деятельность Здравствуй, Осень, золотая
Проектная деятельность Здравствуй, Осень, золотая Магнитные цепи и электромагнитные устройства. Трансформатор
Магнитные цепи и электромагнитные устройства. Трансформатор