- Особливості формування машинних команд

Содержание
- 3. Механізм формумування фізичної адреси в реальному режимі
- 5. Розглянемо формат двооперандної команди. В першому байті записується код операції, в другому – режим адресації. Інші
- 6. Регістри кодуються таким чином:
- 7. Сегментні регістри кодуються так: Режим адресації другого операнда визначається кодами в полях MOD і R/M (register-memory).
- 8. Поле MOD визначає, що саме закодовано в полі слово R/M. Коли ж MOD = 11, це
- 9. Наприклад, для команди ADD (додати): Додати операнди в регістрах чи пам'яті Додати безпосередній операнд до регістру
- 10. Тобто, команда ADD має 3 варіанти коду і різні формати. Як видно, в форматі є лише
- 11. Поля із 6-ти бітів для кодування всіх команд не достатньо. Тому деякі команди об'єднуються в групу
- 12. Оператори Програма на асемблері складається з окремих рядків-операторів, які описують виконувані операції. Оператором може бути команда
- 13. COUNT: MOV AX,DI; переслати DI в акумулятор Наприклад:
- 14. Псевдооператори – керують роботою транслятора, а не мікропроцесора. З їх допомогою визначають сегменти і процедури (підпрограми),
- 15. Їх можна розділити на групи: Визначення ідентифікаторів; Визначення даних; Псевдооператори визначення сегменту і процедури. Псевдооператори даних
- 16. DBL_SPEED EQU 2*SPEED 1. Визначення ідентифікаторів Дозволяють присвоїти символічне ім'я виразу, константі, адресі, іншому символічному імені.
- 17. Шіснадцяткові константи – справа літера Н (2FH). Коли така константа починається з літери, то ліворуч треба
- 18. Коли комірка використовується для збереження даних, їй можна присвоїти ім'я за допомогою псевдооператорів DB, DW, DD
- 19. LAMBDA DW ? POLITE DB ‘Введіть дані знову $’ Коли значення змінних завчасно невідоме, але буде
- 20. BETA DW 15 DUP(0) или GAMA DW 3 DUP (4DUP(0)) ALPHA DW 20 DUP (?) THERE
- 21. Як зазначалося, програма може складатися з декількох сегментів: коду, даних, стеку, додаткового сегменту. Для поділу програми
- 22. В сегменті даних визначаються імена даних та резурвується пам'ять для результатів. У псевдооператора SEGMENT можуть бути
- 23. PARA — сегмент починається з адреси, що кратна 16, то остання шістнадцяткова цифра адреси повинна бути
- 24. Об'єднання визначає спосіб опрацювання сегменту при компонуванні. PRIVATE – за замовчуванням, сегмент повинен бути відділений від
- 25. STACK SEG SEGMENT PARA STACK ‘STACK’ MAS DW 20 DUP (?) STACK SEG ENDS. Клас –
- 26. Як зазначалося, процесор використовує регістр CS для адресації сегменту коду, SS – сегменту стеку, DS -
- 27. CALC PROC ....... RET CALC ENDP Сегмент коду може вміщати одну або кілька процедур. Окрема процедура
- 28. В програмі може бути кілька сегментів з однаковим іменем. Рахується, що це один сегмент, який з
- 29. A SEGMENT A1 DB 400h DUP(?) A2 DW 8 A ENDS ; B SEGMENT B1 DW
- 30. Сегменти, розміщені на межі параграфу, тобто, адреса кратна 16. Якщо А розміщено 1000h, то він займе
- 31. Значення імені сегменту являється номером, який відповідає сегменту пам'яті, тобто, перші 16 бітів початкової адреси заданого
- 32. Директива ASSUME відмічає, з якими сегметними регістрами пов'язувати сегменти. Регістри DS і ES потрібно завантажити початковими
- 33. Відносно сегменту стеку SS, навіть якщо програма і не використовує його, то створити такий сегмент в
- 34. Тому, програма на асемблері має таку структуру: Title EXAMPLE ;заголовок dat segment ; сегмент даних mas
- 35. В загальному випадку в сегменті даних можна розміщувати і команди, а в сегменті коду - дані.
- 36. MASM (Macro Assembler) - стандарт де-факто при програмуванні під Windows 9x/NT; TASM (Turbo Assembler) – стандарт
- 37. Є декілька види трансляторів асемблеру: MASM фірми Microsoft TASM фірми Borland, може працювати в режимі MASM
- 38. Наприклад: Спрощений опис сегментів Masm ; режим роботи транслятора TASM model small ; модель пам'яті .data
- 39. Спрощені директиви визначення сегменту
- 40. @ code – фізична адреса (зміщення) сегменту коду @ data – фізична адреса (зміщення) сегменту даних
- 41. Моделі пам'яті Модифікатор директиви model дозволяє визначити деякі особливості вибраної моделі пам'яті: Use 16 - 16-бітові
- 43. Скачать презентацию
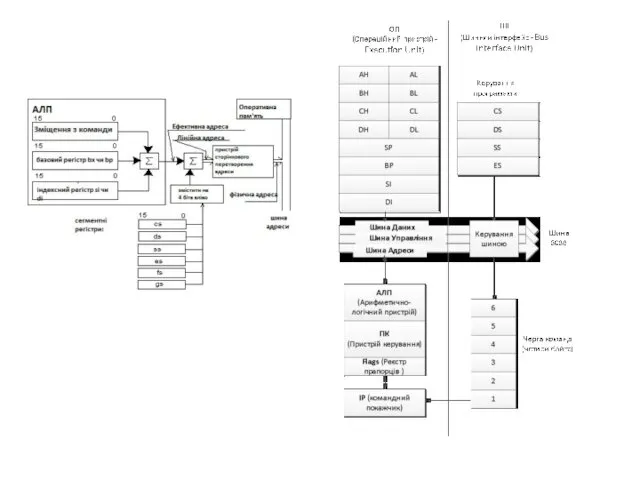
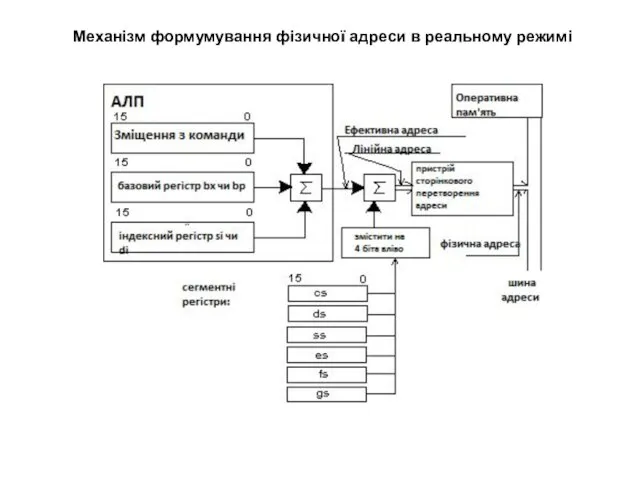
Механізм формумування фізичної адреси в реальному режимі
Механізм формумування фізичної адреси в реальному режимі
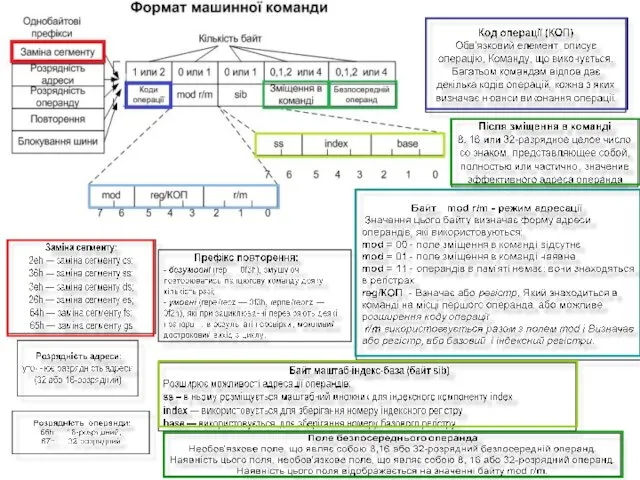

Розглянемо формат двооперандної команди. В першому байті записується код операції, в
Розглянемо формат двооперандної команди. В першому байті записується код операції, в
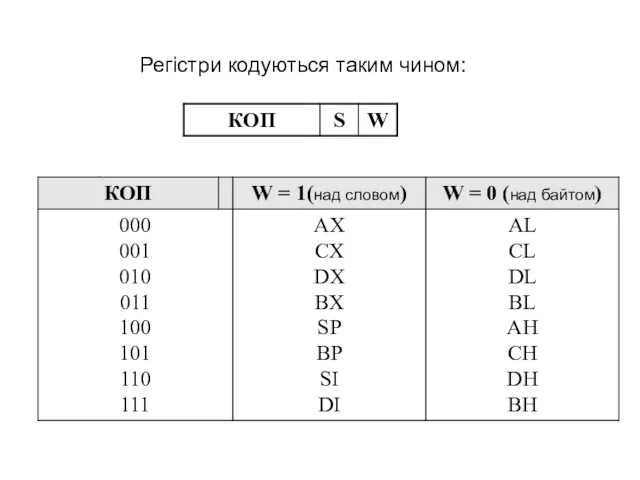
Регістри кодуються таким чином:
Регістри кодуються таким чином:
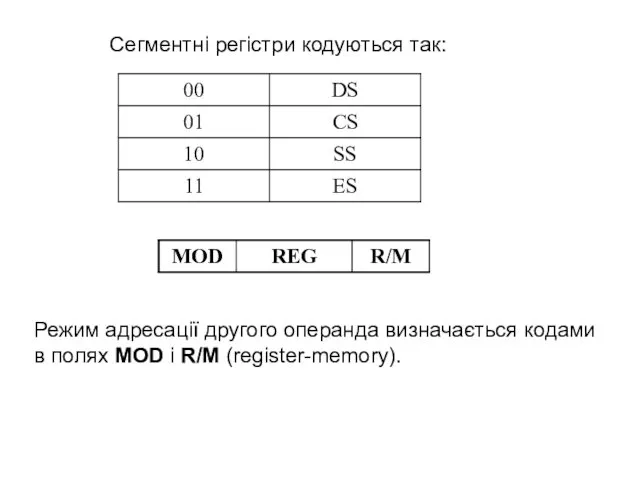
Сегментні регістри кодуються так:
Режим адресації другого операнда визначається кодами в полях
Сегментні регістри кодуються так:
Режим адресації другого операнда визначається кодами в полях
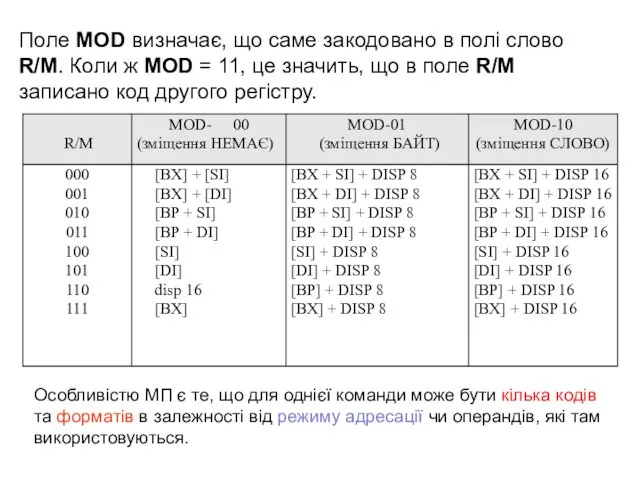
Поле MOD визначає, що саме закодовано в полі слово R/M. Коли
Поле MOD визначає, що саме закодовано в полі слово R/M. Коли
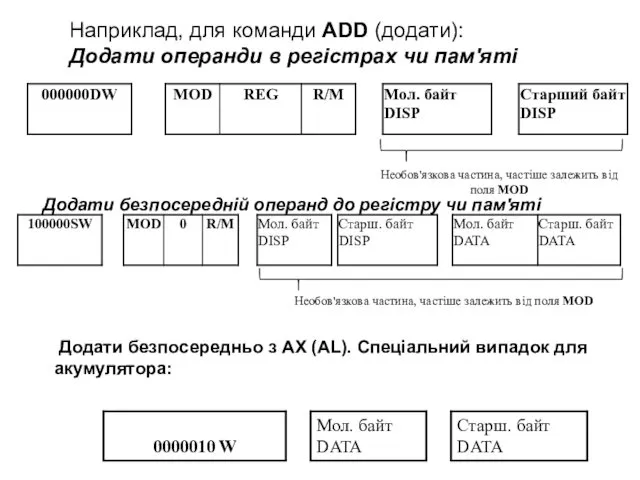
Наприклад, для команди ADD (додати):
Додати операнди в регістрах чи пам'яті
Додати безпосередній
Наприклад, для команди ADD (додати):
Додати операнди в регістрах чи пам'яті
Додати безпосередній

Тобто, команда ADD має 3 варіанти коду і різні формати. Як

Поля із 6-ти бітів для кодування всіх команд не достатньо. Тому
Поля із 6-ти бітів для кодування всіх команд не достатньо. Тому

Оператори
Програма на асемблері складається з окремих рядків-операторів, які описують виконувані операції.
Оператори
Програма на асемблері складається з окремих рядків-операторів, які описують виконувані операції.
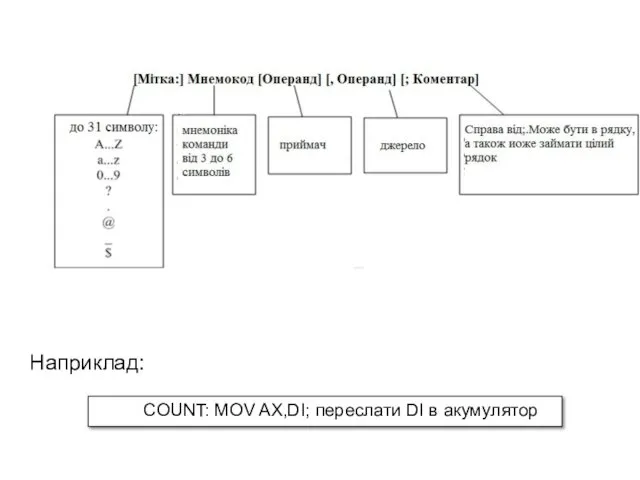
COUNT: MOV AX,DI; переслати DI в акумулятор
Наприклад:
COUNT: MOV AX,DI; переслати DI в акумулятор
Наприклад:

Псевдооператори – керують роботою транслятора, а не мікропроцесора. З їх допомогою
Псевдооператори – керують роботою транслятора, а не мікропроцесора. З їх допомогою

Їх можна розділити на групи:
Визначення ідентифікаторів;
Визначення даних;
Псевдооператори визначення сегменту і
Їх можна розділити на групи:
Визначення ідентифікаторів;
Визначення даних;
Псевдооператори визначення сегменту і

DBL_SPEED EQU 2*SPEED
1. Визначення ідентифікаторів
Дозволяють присвоїти символічне ім'я виразу, константі,
DBL_SPEED EQU 2*SPEED
1. Визначення ідентифікаторів
Дозволяють присвоїти символічне ім'я виразу, константі,

Шіснадцяткові константи – справа літера Н (2FH). Коли така константа починається
Шіснадцяткові константи – справа літера Н (2FH). Коли така константа починається

Коли комірка використовується для збереження даних, їй можна присвоїти ім'я за
Коли комірка використовується для збереження даних, їй можна присвоїти ім'я за

LAMBDA DW ?
POLITE DB ‘Введіть дані знову $’
Коли значення змінних
LAMBDA DW ?
POLITE DB ‘Введіть дані знову $’
Коли значення змінних

BETA DW 15 DUP(0) или GAMA DW 3 DUP (4DUP(0))
ALPHA DW
BETA DW 15 DUP(0) или GAMA DW 3 DUP (4DUP(0))
ALPHA DW

Як зазначалося, програма може складатися з декількох сегментів: коду, даних,
Як зазначалося, програма може складатися з декількох сегментів: коду, даних,

В сегменті даних визначаються імена даних та резурвується пам'ять для результатів.
У
В сегменті даних визначаються імена даних та резурвується пам'ять для результатів.
У

PARA — сегмент починається з адреси, що кратна 16, то остання
PARA — сегмент починається з адреси, що кратна 16, то остання

Об'єднання визначає спосіб опрацювання сегменту при компонуванні.
PRIVATE – за замовчуванням,
Об'єднання визначає спосіб опрацювання сегменту при компонуванні.
PRIVATE – за замовчуванням,

STACK SEG SEGMENT PARA STACK ‘STACK’
MAS DW 20 DUP (?)
STACK
STACK SEG SEGMENT PARA STACK ‘STACK’
MAS DW 20 DUP (?)
STACK

Як зазначалося, процесор використовує регістр CS для адресації сегменту коду, SS
Як зазначалося, процесор використовує регістр CS для адресації сегменту коду, SS

CALC PROC
.......
RET
CALC ENDP
Сегмент коду може вміщати одну або кілька процедур. Окрема
CALC PROC
.......
RET
CALC ENDP
Сегмент коду може вміщати одну або кілька процедур. Окрема

В програмі може бути кілька сегментів з однаковим іменем. Рахується, що
В програмі може бути кілька сегментів з однаковим іменем. Рахується, що

A SEGMENT
A1 DB 400h DUP(?)
A2 DW 8
A ENDS
;
B SEGMENT
A SEGMENT
A1 DB 400h DUP(?)
A2 DW 8
A ENDS
;
B SEGMENT

Сегменти, розміщені на межі параграфу, тобто, адреса кратна 16.
Якщо А
Сегменти, розміщені на межі параграфу, тобто, адреса кратна 16.
Якщо А

Значення імені сегменту являється номером, який відповідає сегменту пам'яті, тобто, перші

Директива ASSUME відмічає, з якими сегметними регістрами пов'язувати сегменти. Регістри DS
Директива ASSUME відмічає, з якими сегметними регістрами пов'язувати сегменти. Регістри DS

Відносно сегменту стеку SS, навіть якщо програма і не використовує його,
Відносно сегменту стеку SS, навіть якщо програма і не використовує його,

Тому, програма на асемблері має таку структуру:
Title EXAMPLE ;заголовок
dat segment ;
Тому, програма на асемблері має таку структуру:
Title EXAMPLE ;заголовок
dat segment ;

В загальному випадку в сегменті даних можна розміщувати і команди, а
В загальному випадку в сегменті даних можна розміщувати і команди, а

MASM (Macro Assembler) - стандарт де-факто при програмуванні під Windows 9x/NT;
TASM
MASM (Macro Assembler) - стандарт де-факто при програмуванні під Windows 9x/NT;
TASM

Є декілька види трансляторів асемблеру:
MASM фірми Microsoft
TASM фірми Borland,
Є декілька види трансляторів асемблеру:
MASM фірми Microsoft
TASM фірми Borland,

Наприклад:
Спрощений опис сегментів
Masm ; режим роботи транслятора TASM
model small ; модель
Наприклад:
Спрощений опис сегментів
Masm ; режим роботи транслятора TASM
model small ; модель
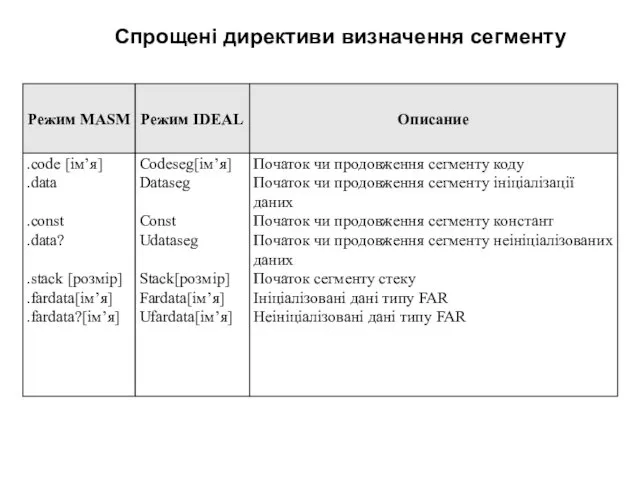
Спрощені директиви визначення сегменту
Спрощені директиви визначення сегменту

@ code – фізична адреса (зміщення) сегменту коду
@ data – фізична
@ code – фізична адреса (зміщення) сегменту коду
@ data – фізична
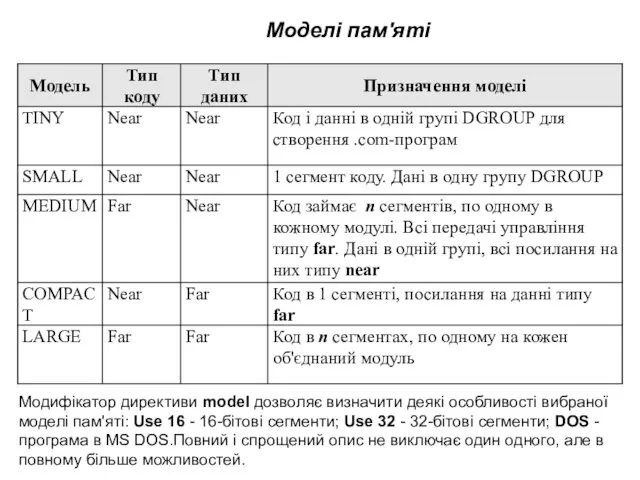
Моделі пам'яті
Модифікатор директиви model дозволяє визначити деякі особливості вибраної моделі пам'яті:
Моделі пам'яті
Модифікатор директиви model дозволяє визначити деякі особливості вибраної моделі пам'яті:
 Жылқының сүт өнімділігі
Жылқының сүт өнімділігі Реформы в 1900 – 1912 гг
Реформы в 1900 – 1912 гг Значение слова пассия
Значение слова пассия Таинство Крещения
Таинство Крещения Эпизоотология лейкоза и туберкулёза в Ордынском районе Новосибирской области
Эпизоотология лейкоза и туберкулёза в Ордынском районе Новосибирской области Техника и технология бурения скважин. Подводные инженерно-технических работы. Плавучие буровые установки и буровые суда
Техника и технология бурения скважин. Подводные инженерно-технических работы. Плавучие буровые установки и буровые суда Реальная математика. Практические расчеты по формулам
Реальная математика. Практические расчеты по формулам Понятие модели. Типы моделей
Понятие модели. Типы моделей Юридическая техника: понятие, виды, способы и приемы
Юридическая техника: понятие, виды, способы и приемы Презентация Огород на подоконнике
Презентация Огород на подоконнике Бюджетная система и бюджетное устройство. Особенности бюджетного процесса в РФ
Бюджетная система и бюджетное устройство. Особенности бюджетного процесса в РФ Использование мультимедийных технологй в целях повышения познавательной деятельности у младших школьников. Дифференциация звуков С-З
Использование мультимедийных технологй в целях повышения познавательной деятельности у младших школьников. Дифференциация звуков С-З Музеи в жизни города. 3 класс
Музеи в жизни города. 3 класс Покажи свое настроение. Обида
Покажи свое настроение. Обида Случайные события и их вероятности
Случайные события и их вероятности Господарство та економічна думка в період державно-монополістичного розвитку суспільств європейської цивілізації
Господарство та економічна думка в період державно-монополістичного розвитку суспільств європейської цивілізації Системы документальной электросвязи
Системы документальной электросвязи Аддитивное производство
Аддитивное производство Дорожные знаки
Дорожные знаки Олимпийское движение. Сочи - 2014 г
Олимпийское движение. Сочи - 2014 г История возникновения театрального искусства в Саратове.
История возникновения театрального искусства в Саратове. Что такое исследовательская работа. Автор : Буркаль Е.В.
Что такое исследовательская работа. Автор : Буркаль Е.В. Технология производства шампанского. Виды шампанских вин
Технология производства шампанского. Виды шампанских вин Культурно-зрелищные здания
Культурно-зрелищные здания Ведомственные строительные нормы. Оценка физического износа жилых зданий
Ведомственные строительные нормы. Оценка физического износа жилых зданий Производство гибких печатных плат без металлизированных отверстий
Производство гибких печатных плат без металлизированных отверстий Для пап и детей. Образ отца в литературе для детей. Часть 2
Для пап и детей. Образ отца в литературе для детей. Часть 2 Презентация Русская матрешка
Презентация Русская матрешка