- Введение в CUDA C

Содержание
- 2. CUDA C CUDA C – расширение языка С, включающее квалификаторы функций; квалификаторы типов памяти; встроенные переменные.
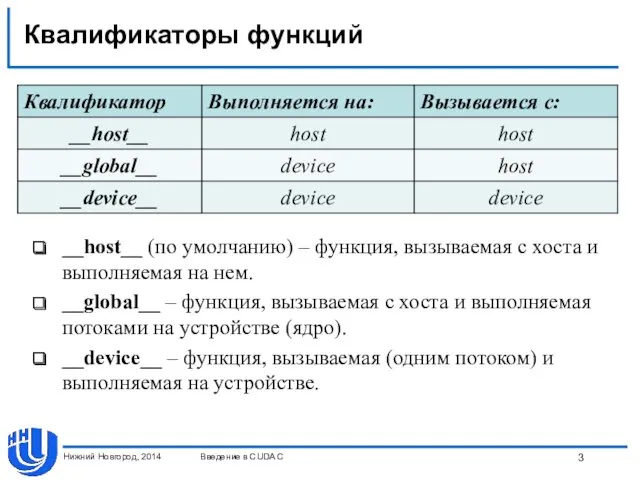
- 3. Квалификаторы функций __host__ (по умолчанию) – функция, вызываемая с хоста и выполняемая на нем. __global__ –
- 4. Пример синтаксиса __host__ float hostSquare(float a) { return a * a; } __device__ float deviceSquare(float a)
- 5. __global__ функции Тип возвращаемого результата всегда void. Аргументы передаются через разделяемую/константную память, размер не больше 256
- 6. __device__ функции __device__ может использоваться совместно с __host__, в этом случае функция компилируется в 2 видах.
- 7. Встроенные векторные типы [u]char[1..4], [u]int[1..4], [u]long[1..4], float[1..4], double2 – являются структурами, доступ через .x, .y, .z,
- 8. Встроенные переменные В коде на стороне GPU доступны следующие переменные: gridDim – размер решетки блоков; blockIdx
- 9. Вычисление уникального индекса потока threadIdx является «локальным» индексом потока внутри блока. Нет встроенной переменной для «глобального»
- 10. Пример: ядро для сложения векторов /* Считаем, что ядро будет вызываться столько раз, какова длина векторов,
- 11. Пример: ядро для сложения матриц // Матрицы хранятся по строкам и имеют размер m x n
- 12. Вызов ядер Функция ядра должна быть вызвана с указанием конфигурации исполнения. Конфигурация определяется использованием выражения специального
- 13. Вызов ядер Размер решетки блоков и размер блока потоков являются переменными типа dim3 (встроенный тип в
- 14. Пример: вызов ядра для сложения векторов Используем ядро из примера. Будем считать, что размер блока фиксирован
- 15. Пример: вызов ядра для сложения векторов void vecAdd(const float * a, const float * b, float
- 16. Правильное ядро для сложения векторов __global__ void vecAdd_kernel( const float * a, const float * b,
- 17. Способы борьбы с невыровненностью Брать число блоков с запасом и проверять, не выходим ли мы за
- 18. Квалификаторы переменных Нижний Новгород, 2014 Введение в CUDA C Использование __device__ опционально, если есть __local__, __shared__
- 19. Квалификаторы переменных Нижний Новгород, 2014 Введение в CUDA C
- 20. CUDA API Состав CUDA API: управление устройствами; управление памятью; управление процессом выполнения: Streams; Synchronization; Events; взаимодействие
- 21. CUDA API: обработка ошибок Все функции возвращают значение типа cudaError_t, cudaSuccess в случае успешного завершения функции.
- 22. Управление устройствами Перечисление устройств: cudaError_t cudaGetDeviceCount(int* count) – возвращает число доступных устройств; cudaError_t cudaGetDevice (int* dev)
- 23. Управление устройствами Выбор устройства: cudaError_t cudaSetDevice (int dev) – устанавливает устройство с заданным номером; cudaError_t cudaChooseDevice
- 24. Управление памятью Выделение и освобождение памяти на устройстве: cudaError_t cudaMalloc (void** devPtr, size_t count) – выделяет
- 25. Синхронизация void __syncthreads() – барьерная синхронизация в для потоков внутри одного блока (вызывается внутри ядра). Атомарные
- 26. CUDA “Hello, World!”… #include #include #include __global__ void vecAdd_kernel( const float * a, const float *
- 27. CUDA “Hello, World!” … int main() { int n = 1000; float * a = new
- 28. CUDA “Hello, World!” … for (int i = 0; i a[i] = b[i] = i; cudaMemcpy(a_gpu,
- 29. CUDA “Hello, World!” const int block_size = 256; int num_blocks = (n + block_size - 1)
- 30. Компиляция и сборка Компилятор nvcc. Build rules для Microsoft Visual Studio. В CUDA до 4.0 поддерживались
- 31. Компиляция и сборка Нижний Новгород, 2014 Введение в CUDA C
- 33. Скачать презентацию

CUDA C
CUDA C – расширение языка С, включающее
квалификаторы функций;
квалификаторы типов памяти;
встроенные
CUDA C
CUDA C – расширение языка С, включающее
квалификаторы функций;
квалификаторы типов памяти;
встроенные
Квалификаторы функций
__host__ (по умолчанию) – функция, вызываемая с хоста и выполняемая
Квалификаторы функций
__host__ (по умолчанию) – функция, вызываемая с хоста и выполняемая

Пример синтаксиса
__host__ float hostSquare(float a) {
return a * a;
}
__device__ float
Пример синтаксиса
__host__ float hostSquare(float a) {
return a * a;
}
__device__ float

__global__ функции
Тип возвращаемого результата всегда void.
Аргументы передаются через разделяемую/константную память, размер
__global__ функции
Тип возвращаемого результата всегда void.
Аргументы передаются через разделяемую/константную память, размер

__device__ функции
__device__ может использоваться совместно с __host__, в этом случае функция
__device__ функции
__device__ может использоваться совместно с __host__, в этом случае функция
![Встроенные векторные типы [u]char[1..4], [u]int[1..4], [u]long[1..4], float[1..4], double2 – являются](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/54530/slide-6.jpg)
Встроенные векторные типы
[u]char[1..4], [u]int[1..4], [u]long[1..4], float[1..4], double2 – являются структурами, доступ
Встроенные векторные типы
[u]char[1..4], [u]int[1..4], [u]long[1..4], float[1..4], double2 – являются структурами, доступ

Встроенные переменные
В коде на стороне GPU доступны следующие переменные:
gridDim – размер
Встроенные переменные
В коде на стороне GPU доступны следующие переменные:
gridDim – размер

Вычисление уникального индекса потока
threadIdx является «локальным» индексом потока внутри блока. Нет
Вычисление уникального индекса потока
threadIdx является «локальным» индексом потока внутри блока. Нет

Пример: ядро для сложения векторов
/* Считаем, что ядро будет вызываться столько
Пример: ядро для сложения векторов
/* Считаем, что ядро будет вызываться столько

Пример: ядро для сложения матриц
// Матрицы хранятся по строкам и имеют
Пример: ядро для сложения матриц
// Матрицы хранятся по строкам и имеют

Вызов ядер
Функция ядра должна быть вызвана с указанием конфигурации исполнения.
Конфигурация определяется
Вызов ядер
Функция ядра должна быть вызвана с указанием конфигурации исполнения.
Конфигурация определяется

Вызов ядер
Размер решетки блоков и размер блока потоков являются переменными типа
Вызов ядер
Размер решетки блоков и размер блока потоков являются переменными типа

Пример: вызов ядра для сложения векторов
Используем ядро из примера.
Будем считать, что
Пример: вызов ядра для сложения векторов
Используем ядро из примера.
Будем считать, что
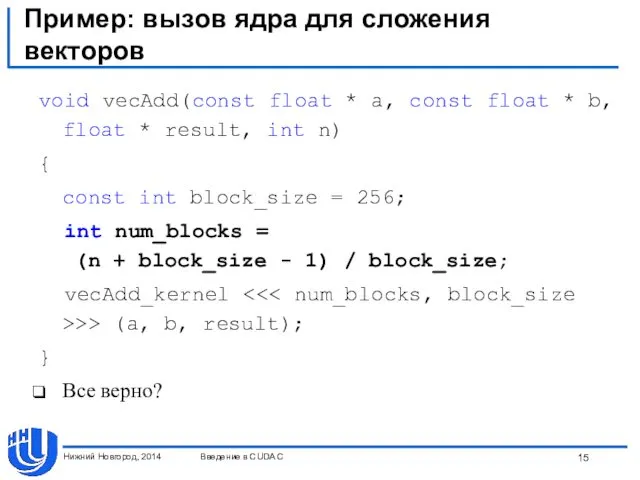
Пример: вызов ядра для сложения векторов
void vecAdd(const float * a, const
Пример: вызов ядра для сложения векторов
void vecAdd(const float * a, const

Правильное ядро для сложения векторов
__global__ void vecAdd_kernel(
const float * a, const
Правильное ядро для сложения векторов
__global__ void vecAdd_kernel( const float * a, const

Способы борьбы с невыровненностью
Брать число блоков с запасом и проверять, не
Способы борьбы с невыровненностью
Брать число блоков с запасом и проверять, не
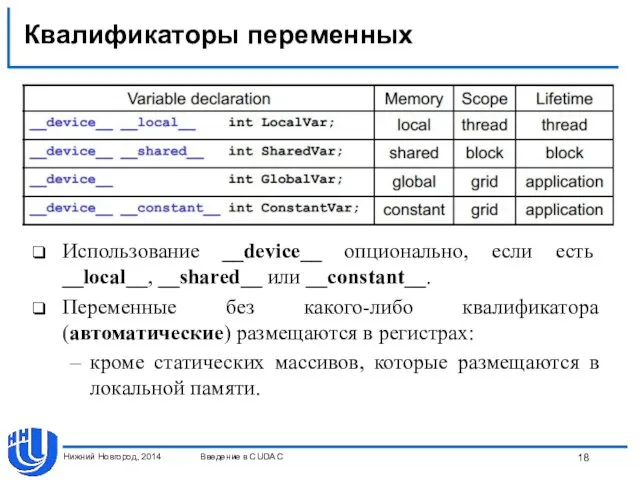
Квалификаторы переменных
Нижний Новгород, 2014
Введение в CUDA C
Использование __device__ опционально, если есть
Квалификаторы переменных
Нижний Новгород, 2014
Введение в CUDA C
Использование __device__ опционально, если есть
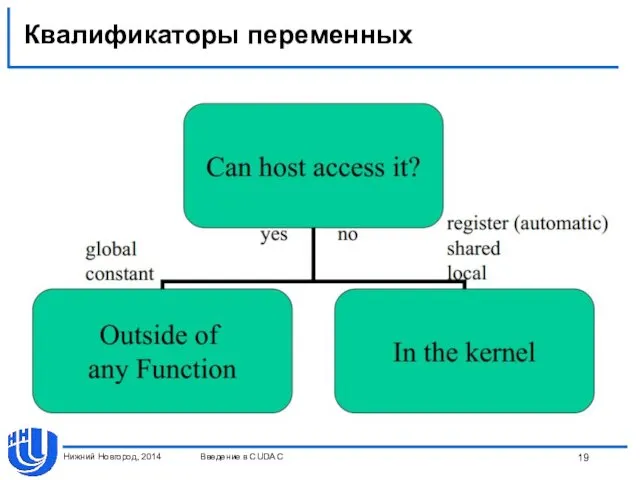
Квалификаторы переменных
Нижний Новгород, 2014
Введение в CUDA C
Квалификаторы переменных
Нижний Новгород, 2014
Введение в CUDA C

CUDA API
Состав CUDA API:
управление устройствами;
управление памятью;
управление процессом выполнения:
Streams;
Synchronization;
Events;
взаимодействие с графическими API;
обработка
CUDA API
Состав CUDA API:
управление устройствами;
управление памятью;
управление процессом выполнения:
Streams;
Synchronization;
Events;
взаимодействие с графическими API;
обработка

CUDA API: обработка ошибок
Все функции возвращают значение типа cudaError_t, cudaSuccess в
CUDA API: обработка ошибок
Все функции возвращают значение типа cudaError_t, cudaSuccess в

Управление устройствами
Перечисление устройств:
cudaError_t cudaGetDeviceCount(int* count) – возвращает число доступных устройств;
cudaError_t cudaGetDevice
Управление устройствами
Перечисление устройств:
cudaError_t cudaGetDeviceCount(int* count) – возвращает число доступных устройств;
cudaError_t cudaGetDevice

Управление устройствами
Выбор устройства:
cudaError_t cudaSetDevice (int dev) – устанавливает устройство с заданным
Управление устройствами
Выбор устройства:
cudaError_t cudaSetDevice (int dev) – устанавливает устройство с заданным

Управление памятью
Выделение и освобождение памяти на устройстве:
cudaError_t cudaMalloc (void** devPtr, size_t
Управление памятью
Выделение и освобождение памяти на устройстве:
cudaError_t cudaMalloc (void** devPtr, size_t

Синхронизация
void __syncthreads() – барьерная синхронизация в для потоков внутри одного блока
Синхронизация
void __syncthreads() – барьерная синхронизация в для потоков внутри одного блока

CUDA “Hello, World!”…
#include
#include
#include
__global__ void vecAdd_kernel(
const float * a,
CUDA “Hello, World!”…
#include
#include
#include
__global__ void vecAdd_kernel(
const float * a,
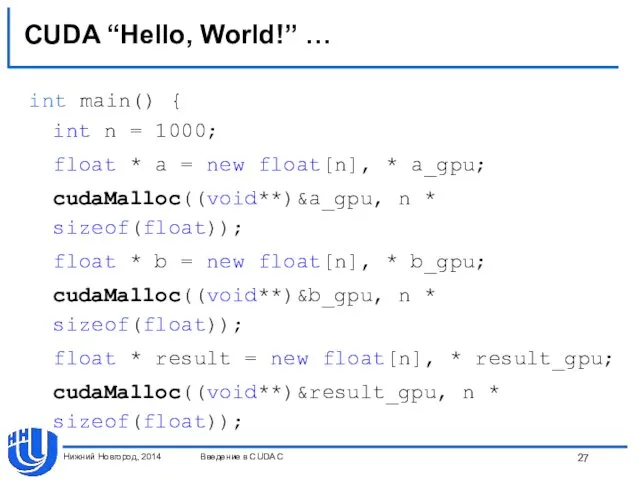
CUDA “Hello, World!” …
int main() {
int n = 1000;
float * a
CUDA “Hello, World!” …
int main() {
int n = 1000;
float * a

CUDA “Hello, World!” …
for (int i = 0; i < n;
CUDA “Hello, World!” …
for (int i = 0; i < n;

CUDA “Hello, World!”
const int block_size = 256;
int num_blocks =
(n +
CUDA “Hello, World!”
const int block_size = 256;
int num_blocks =
(n +

Компиляция и сборка
Компилятор nvcc.
Build rules для Microsoft Visual Studio.
В CUDA до
Компиляция и сборка
Компилятор nvcc.
Build rules для Microsoft Visual Studio.
В CUDA до
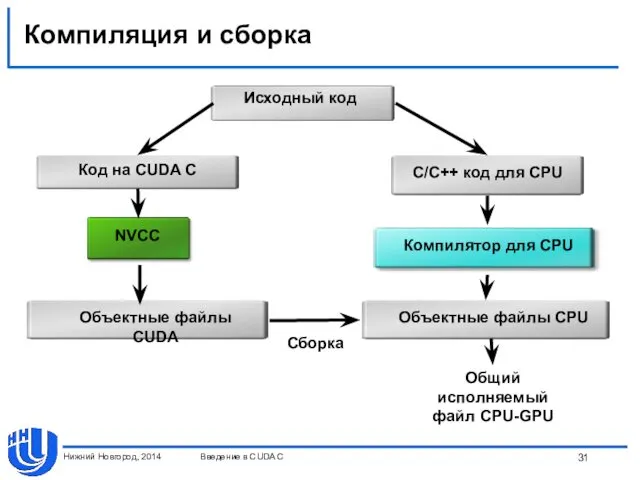
Компиляция и сборка
Нижний Новгород, 2014
Введение в CUDA C
Компиляция и сборка
Нижний Новгород, 2014
Введение в CUDA C
 Проблемы юридической техники в уголовном праве
Проблемы юридической техники в уголовном праве Автоматизация звука Р
Автоматизация звука Р Теоретические основы товароведения продовольственных товаров
Теоретические основы товароведения продовольственных товаров Технология изготовления и монтаж деревянных лестниц. Устройство деревянного перекрытия
Технология изготовления и монтаж деревянных лестниц. Устройство деревянного перекрытия Способы организации пространства в ландшафтной архитектуре
Способы организации пространства в ландшафтной архитектуре Основы общественного производства
Основы общественного производства Процедура выбора страховой компании для строительной организации ООО Паркинг-М
Процедура выбора страховой компании для строительной организации ООО Паркинг-М Разработка технологии внесения растворов жидких комплексных удобрений (жку) в посевы сельскохозяйственных культур
Разработка технологии внесения растворов жидких комплексных удобрений (жку) в посевы сельскохозяйственных культур Традиционные общества востока
Традиционные общества востока Кошки
Кошки Христианин в труде
Христианин в труде День космонавтики.
День космонавтики. Порядок проверки и замены компрессора Dvm plus III
Порядок проверки и замены компрессора Dvm plus III 20231021_lyubit_svoego_podrostka_2012
20231021_lyubit_svoego_podrostka_2012 Ислам мәдениеті
Ислам мәдениеті Виды химической связи
Виды химической связи Деловая игра Знатоки ФГОС ДО
Деловая игра Знатоки ФГОС ДО Рейди мэйд в искусстве XX века
Рейди мэйд в искусстве XX века Роль воспитателя в процессе музык. воспитания
Роль воспитателя в процессе музык. воспитания образование в жизни человека
образование в жизни человека Моделирование и конструирование
Моделирование и конструирование Ознакомление детей дошкольного возраста с изобразительным искусством
Ознакомление детей дошкольного возраста с изобразительным искусством Проецирование. Проекция
Проецирование. Проекция Döwletleriň syýasy kartada şekillendirilşi
Döwletleriň syýasy kartada şekillendirilşi Современные способы обеззараживания воды
Современные способы обеззараживания воды Экономическая сущность предпринимательской деятельности
Экономическая сущность предпринимательской деятельности Эксплуатация системы кондиционирования воздуха пассажирских вагонов в пути следования
Эксплуатация системы кондиционирования воздуха пассажирских вагонов в пути следования Театр Моды Силуэт, коллекция Цвета жизни
Театр Моды Силуэт, коллекция Цвета жизни