- Алгоритмы поиска. Двоичный поиск в упорядоченном массиве. Бинарное дерево поиска

Содержание
- 4. Двоичный поиск в упорядоченном массиве 1 2 3 4 5 6 7 8 9 10 11
- 8. Бинарные деревья поиска
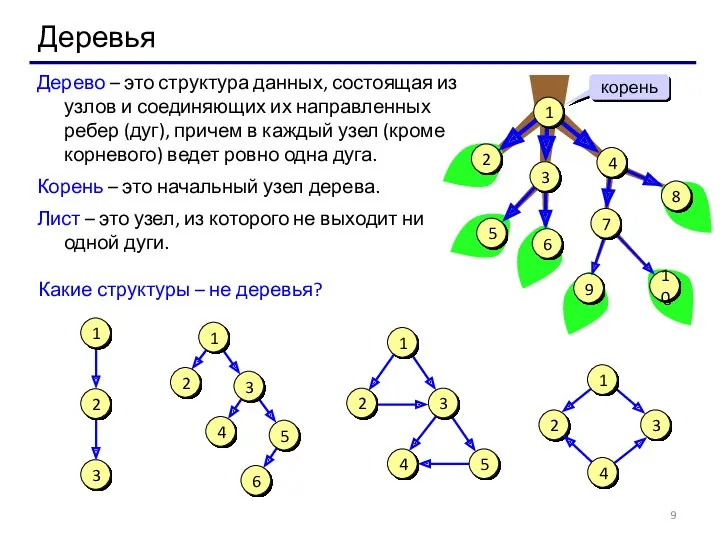
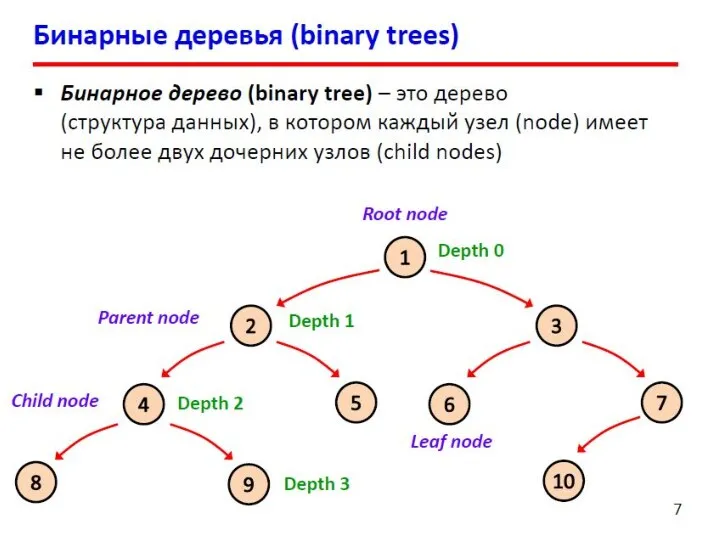
- 9. Деревья Дерево – это структура данных, состоящая из узлов и соединяющих их направленных ребер (дуг), причем
- 10. Деревья Предок узла x – это узел, из которого существует путь по стрелкам в узел x.
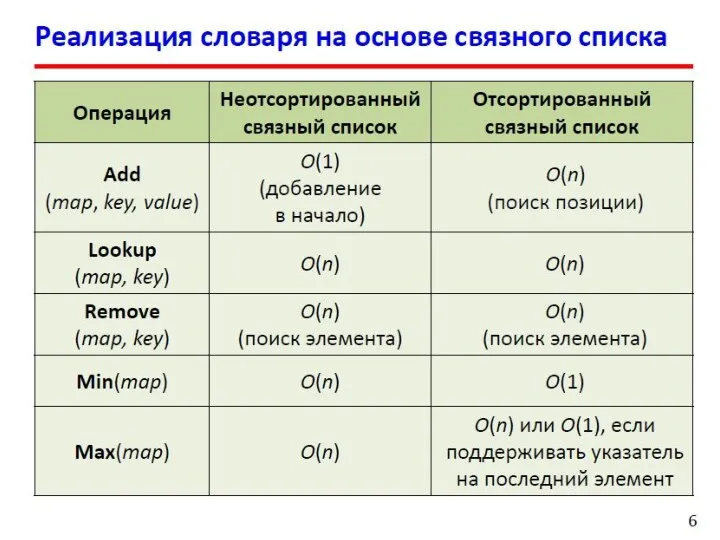
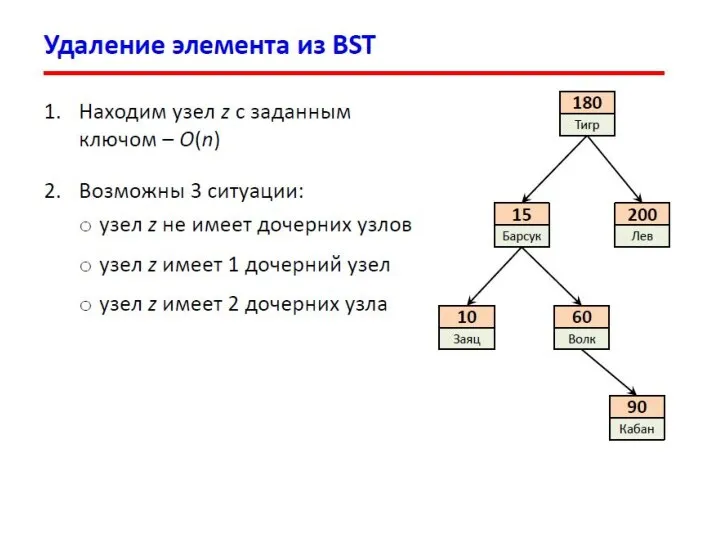
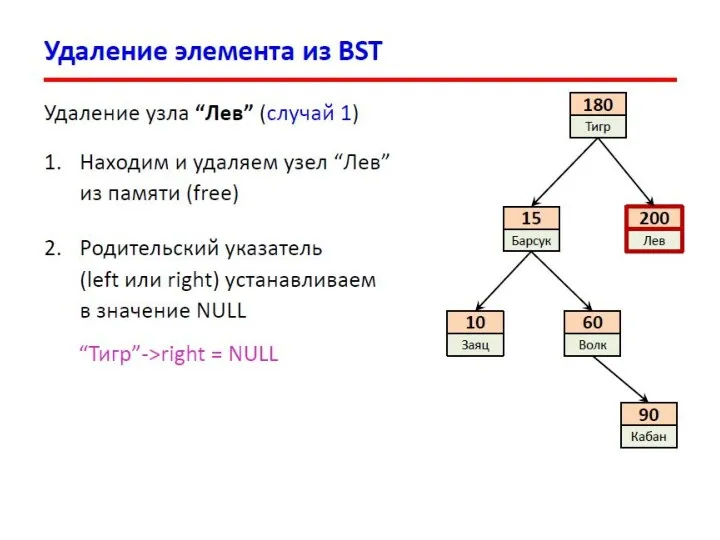
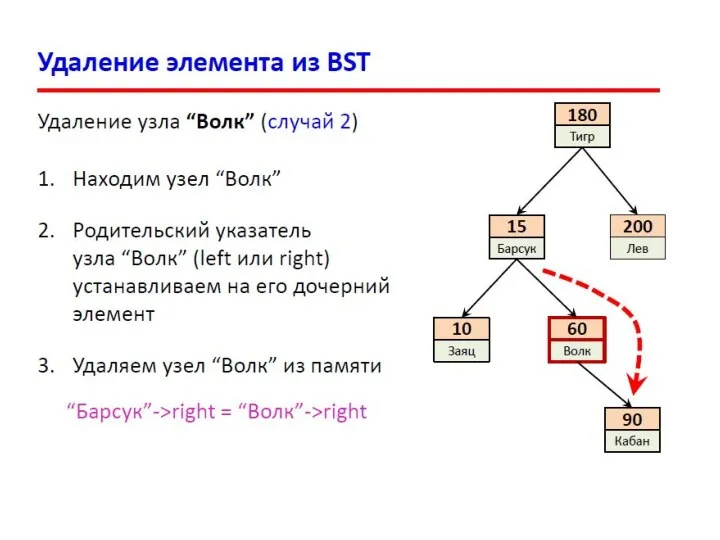
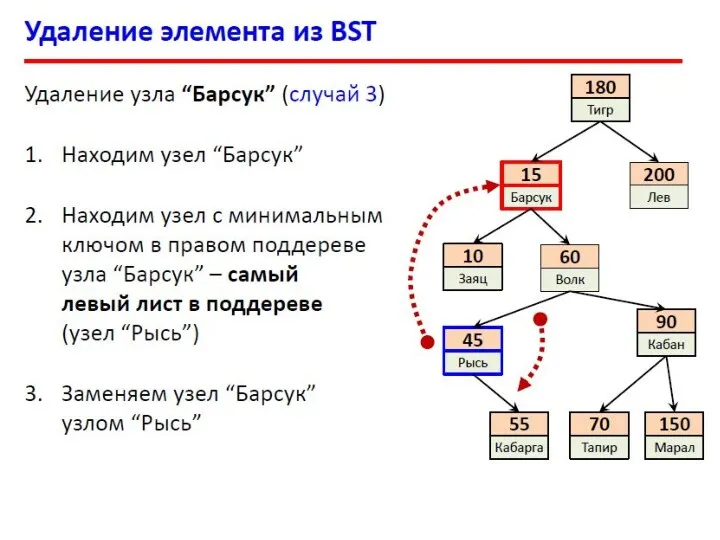
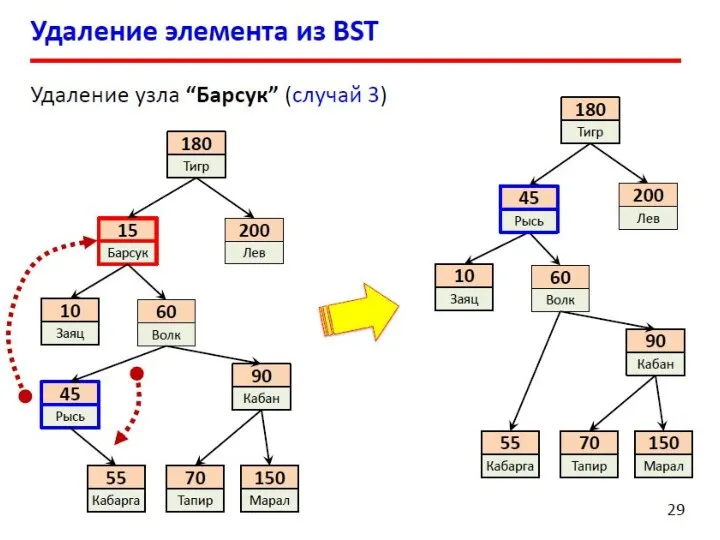
- 13. Двоичные деревья поиска Слева от каждого узла находятся узлы с меньшими ключами, а справа – с
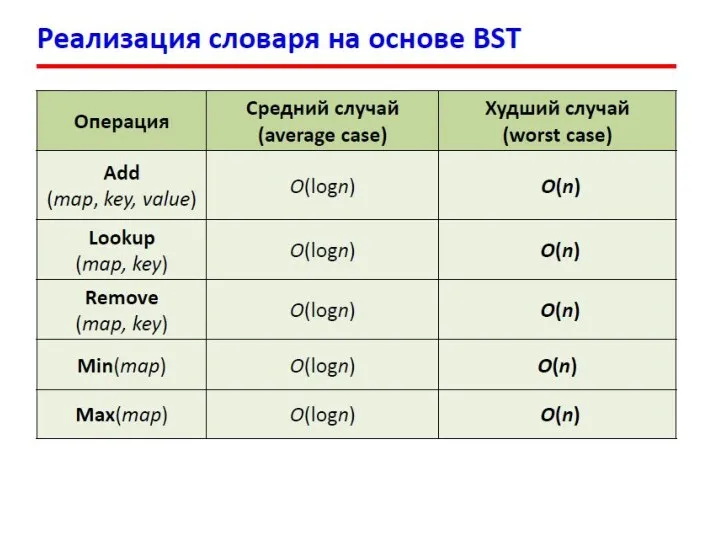
- 14. Двоичные деревья поиска Поиск в массиве (N элементов): При каждом сравнении отбрасывается 1 элемент. Число сравнений
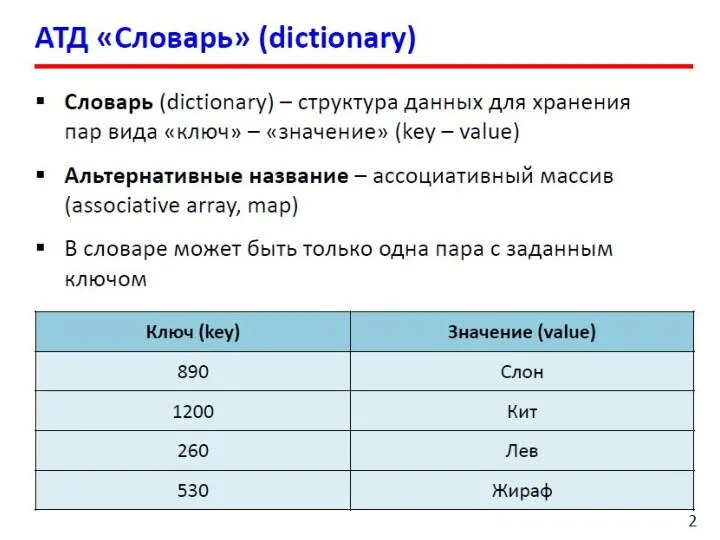
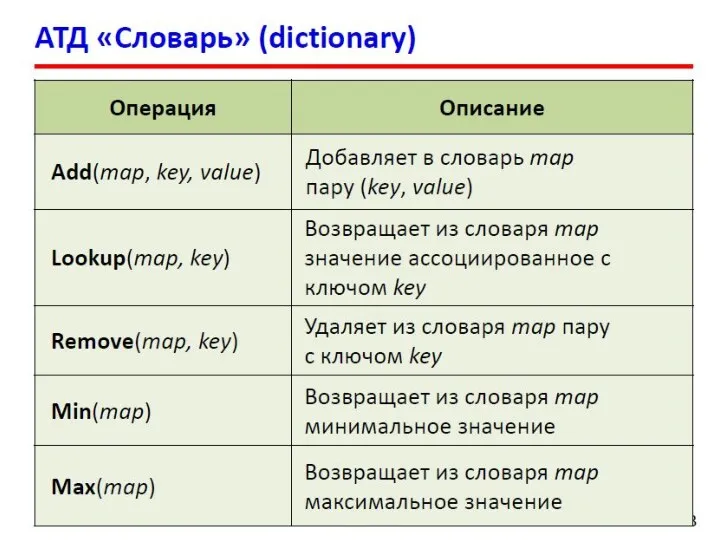
- 16. Двоичные деревья Структура узла: Применение: поиск данных в специально построенных деревьях (базы данных); сортировка данных; вычисление
- 17. Структура узла C# class BinaryTreeNode where T : IComparable { private T value; private BinaryTreeNode leftChild;
- 18. Класс дерева class BinaryTree : ICollection where T : IComparable { private BinaryTreeNode root; private Comparison
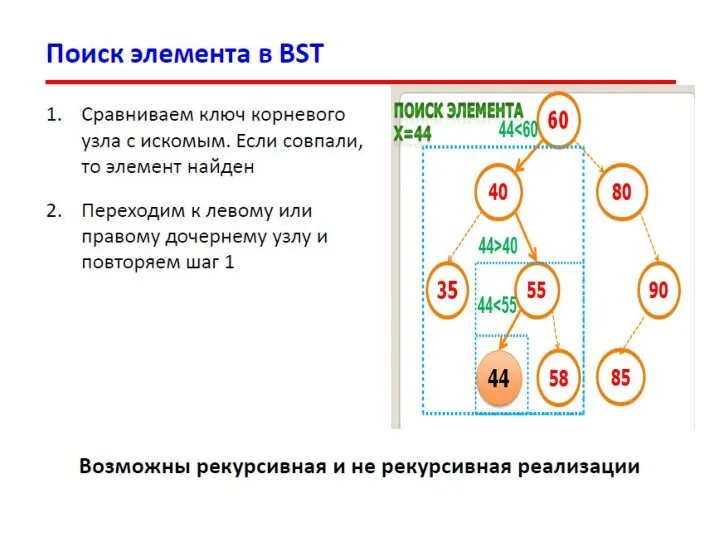
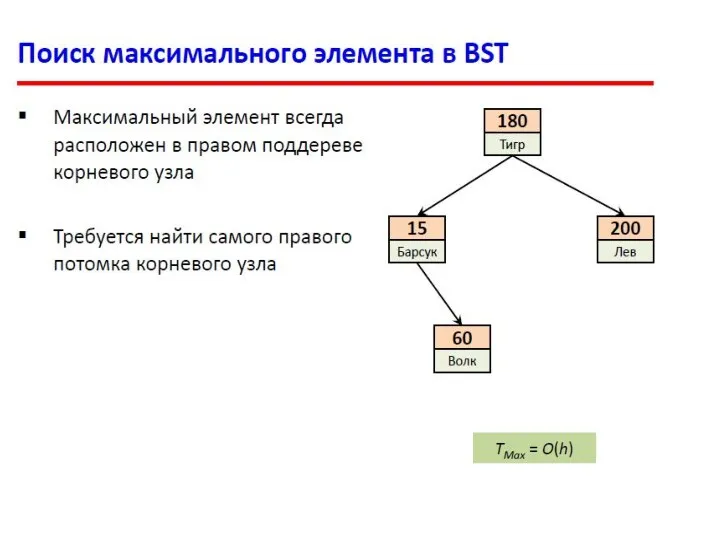
- 23. Деревья поиска. Индексация и поиск данных. 8 10 9 Поиск в дереве по ключу Ищем ключ
- 25. public BinaryTreeNode minimum() { BinaryTreeNode current, last; current = root; // Обход начинается с корневого узла
- 27. Tree_Successor (Tree,15)=17 Tree_Successor (Tree,13)=15 Поиск следующего элемента
- 33. Обход дерева Обход дерева – это перечисление всех узлов в определенном порядке. Обход ЛКП («левый –
- 34. ПРЯМОЙ ОБХОД PreOrderTraversal 60 40 35 55 58 80 90 44 79 60-40-35-55-44-58-80-77-79-90 77
- 35. СИММЕТРИЧНЫЙ ОБХОД InOrderTraversal 35-40-44-55-58-60-77-79-80-90 60 40 35 55 58 80 90 44 79 77
- 36. ОБРАТНЫЙ ОБХОД PostOrderTraversal 35-44-58-55-40-79-77-90-80-60 60 40 35 55 58 80 90 44 79 77
- 37. Обход в ширину производится с помощью очереди. Первоначально в очередь помещается корень, затем, пока очередь не
- 38. Обход дерева – реализация //--------------------------------------------- // Функция LKP – обход дерева в порядке ЛКП // (левый
- 39. Индексация данных С помощью поиска по индексу можно получить ответы на вопросы: Какое слово встречается ровно
- 40. Разбор арифметических выражений a b + c d + 1 - / Как вычислять автоматически: Инфиксная
- 41. Построение дерева Алгоритм: если first=last (остался один символ – число), то создать новый узел и записать
- 42. Как найти последнюю операцию? Порядок выполнения операций умножение и деление; сложение и вычитание. Приоритет (старшинство) –
- 47. Скачать презентацию

Двоичный поиск в упорядоченном массиве
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
0
1
3
4
8
10
14
16
21
24
27
31
33
36
38
42
44
50
51
53
59
33
private static int binSearch(int[] data, int key)
Двоичный поиск в упорядоченном массиве
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
0
1
3
4
8
10
14
16
21
24
27
31
33
36
38
42
44
50
51
53
59
33
private static int binSearch(int[] data, int key)



Бинарные деревья поиска
Бинарные деревья поиска
Деревья
Дерево – это структура данных, состоящая из узлов и соединяющих их
Деревья
Дерево – это структура данных, состоящая из узлов и соединяющих их

Деревья
Предок узла x – это узел, из которого существует путь по
Деревья
Предок узла x – это узел, из которого существует путь по

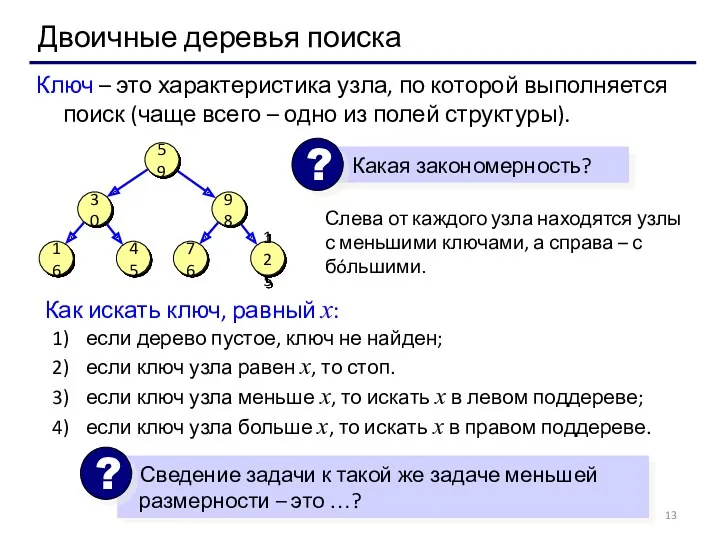
Двоичные деревья поиска
Слева от каждого узла находятся узлы с меньшими ключами,
Двоичные деревья поиска
Слева от каждого узла находятся узлы с меньшими ключами,
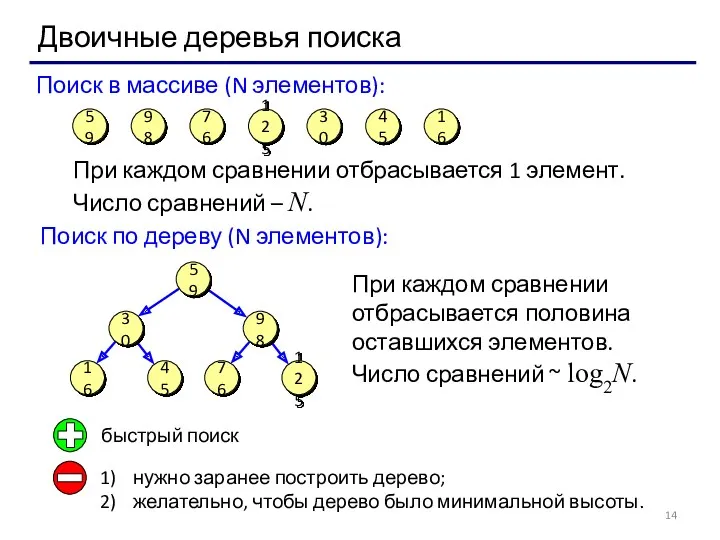
Двоичные деревья поиска
Поиск в массиве (N элементов):
При каждом сравнении отбрасывается 1
Двоичные деревья поиска
Поиск в массиве (N элементов):
При каждом сравнении отбрасывается 1
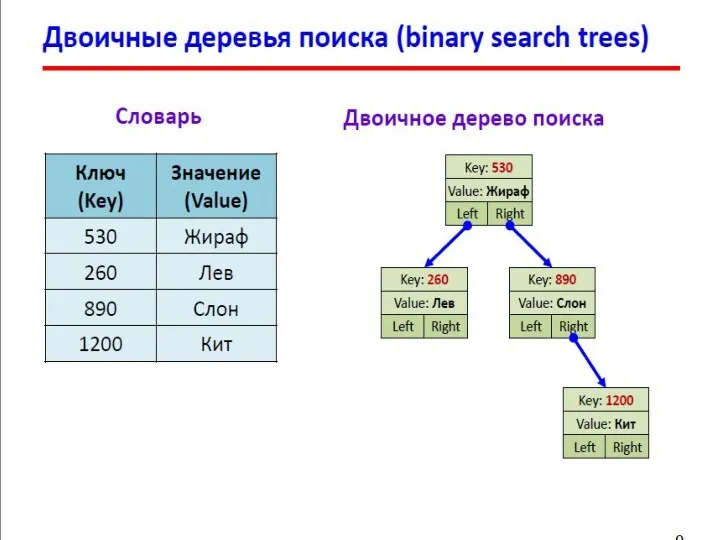

Двоичные деревья
Структура узла:
Применение:
поиск данных в специально построенных деревьях
(базы данных);
сортировка данных;
вычисление арифметических
Двоичные деревья
Структура узла:
Применение:
поиск данных в специально построенных деревьях
(базы данных);
сортировка данных;
вычисление арифметических

Структура узла C#
class BinaryTreeNode where T : IComparable
{ private
Структура узла C#
class BinaryTreeNode
{ private

Класс дерева
class BinaryTree : ICollection
where T : IComparable
Класс дерева
class BinaryTree
where T : IComparable


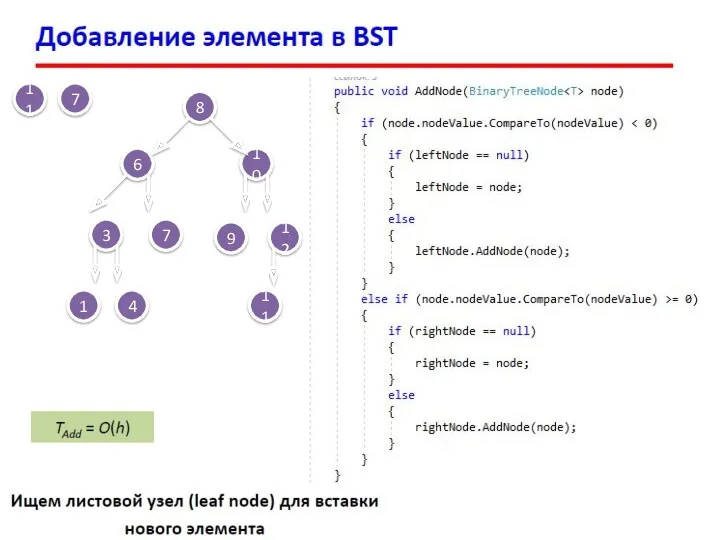
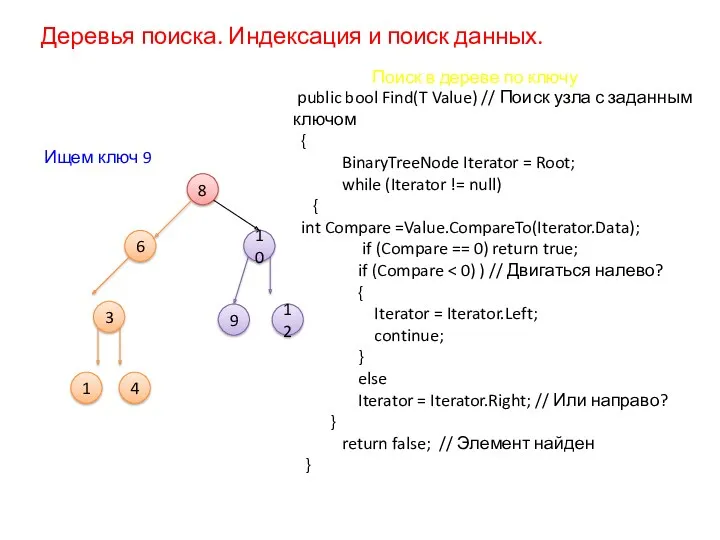
Деревья поиска. Индексация и поиск данных.
8
10
9
Поиск в дереве по ключу
Ищем ключ
Деревья поиска. Индексация и поиск данных.
8
10
9
Поиск в дереве по ключу
Ищем ключ

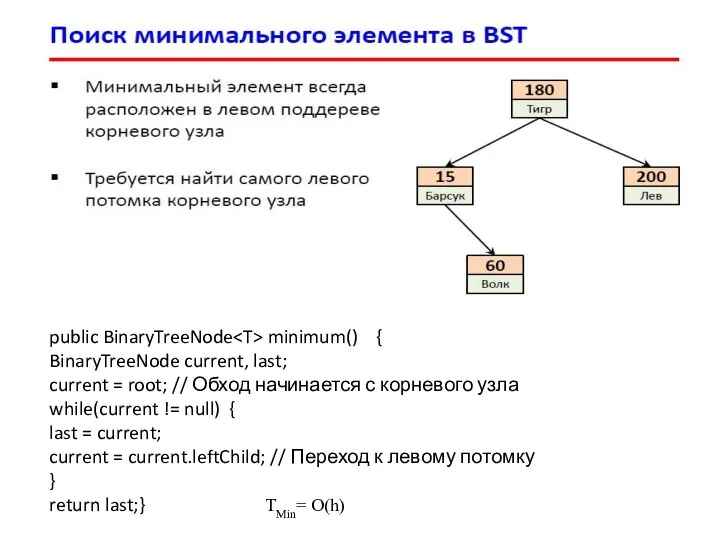
public BinaryTreeNode minimum() {
BinaryTreeNode current, last;
current = root; // Обход начинается
public BinaryTreeNode
BinaryTreeNode current, last;
current = root; // Обход начинается
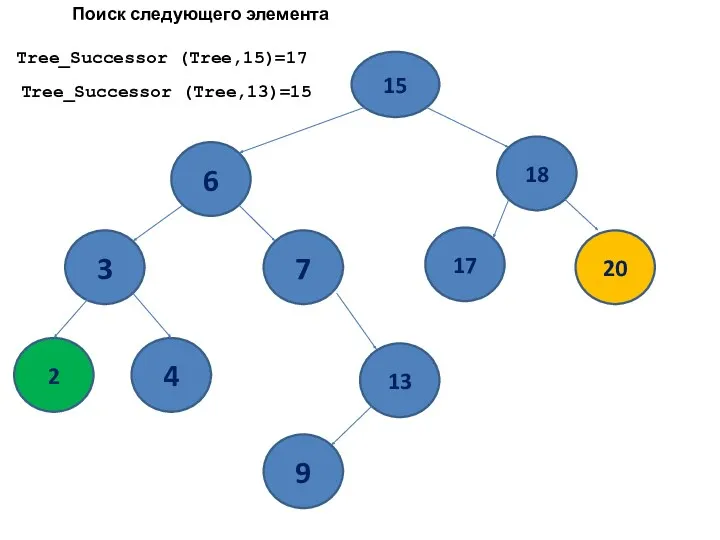
Tree_Successor (Tree,15)=17
Tree_Successor (Tree,13)=15
Поиск следующего элемента
Tree_Successor (Tree,15)=17
Tree_Successor (Tree,13)=15
Поиск следующего элемента
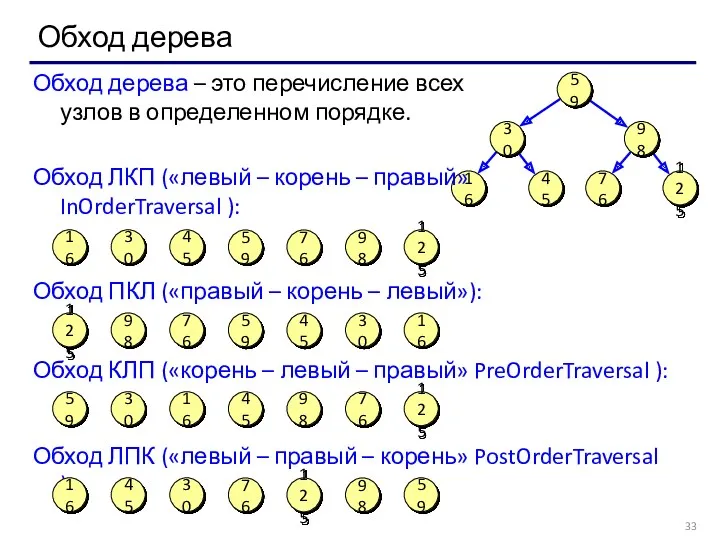
Обход дерева
Обход дерева – это перечисление всех узлов в определенном порядке.
Обход
Обход дерева
Обход дерева – это перечисление всех узлов в определенном порядке.
Обход
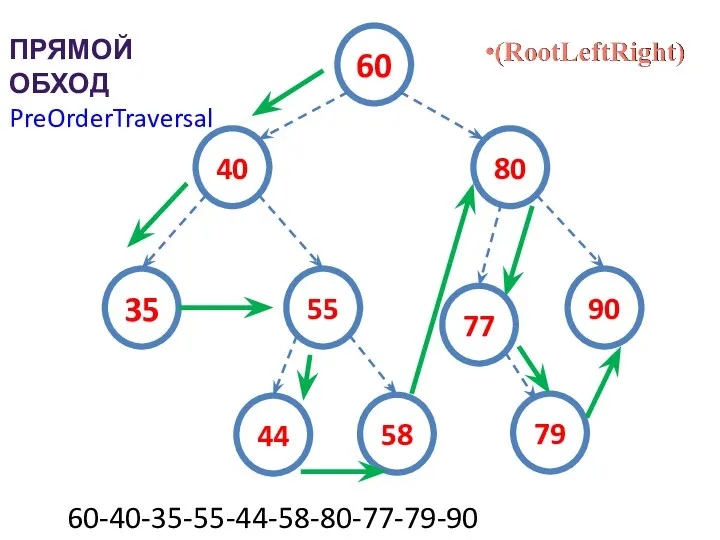
ПРЯМОЙ ОБХОД
PreOrderTraversal
60
40
35
55
58
80
90
44
79
60-40-35-55-44-58-80-77-79-90
77
ПРЯМОЙ ОБХОД
PreOrderTraversal
60
40
35
55
58
80
90
44
79
60-40-35-55-44-58-80-77-79-90
77
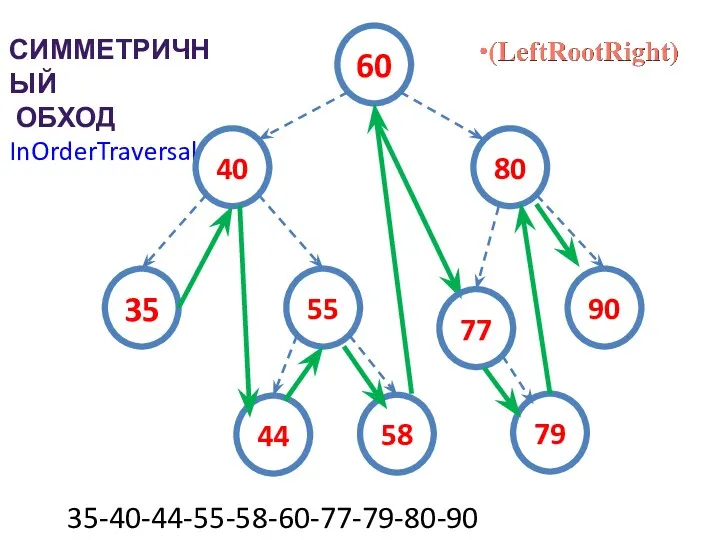
СИММЕТРИЧНЫЙ
ОБХОД
InOrderTraversal
35-40-44-55-58-60-77-79-80-90
60
40
35
55
58
80
90
44
79
77
СИММЕТРИЧНЫЙ
ОБХОД
InOrderTraversal
35-40-44-55-58-60-77-79-80-90
60
40
35
55
58
80
90
44
79
77
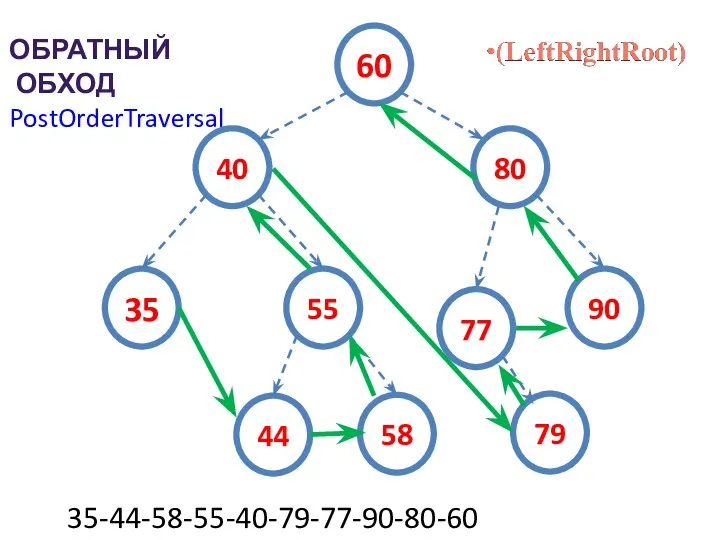
ОБРАТНЫЙ
ОБХОД
PostOrderTraversal
35-44-58-55-40-79-77-90-80-60
60
40
35
55
58
80
90
44
79
77
ОБРАТНЫЙ
ОБХОД
PostOrderTraversal
35-44-58-55-40-79-77-90-80-60
60
40
35
55
58
80
90
44
79
77
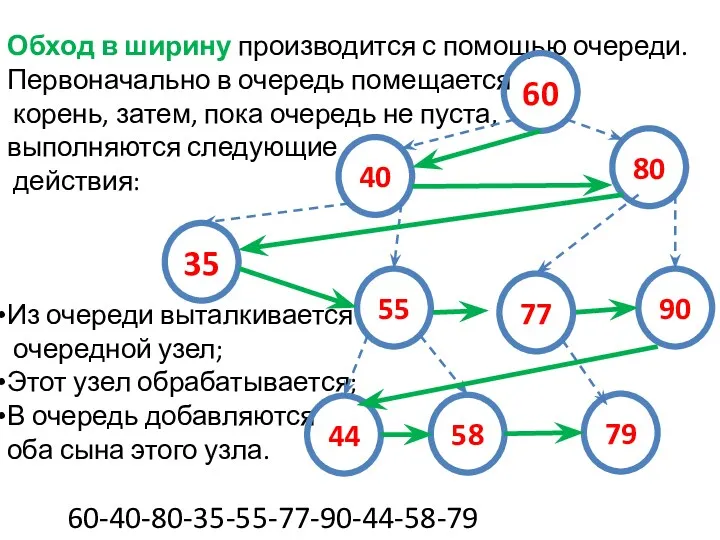
Обход в ширину производится с помощью очереди. Первоначально в очередь помещается
Обход в ширину производится с помощью очереди. Первоначально в очередь помещается

Обход дерева – реализация
//---------------------------------------------
// Функция LKP – обход дерева в порядке
Обход дерева – реализация
//---------------------------------------------
// Функция LKP – обход дерева в порядке
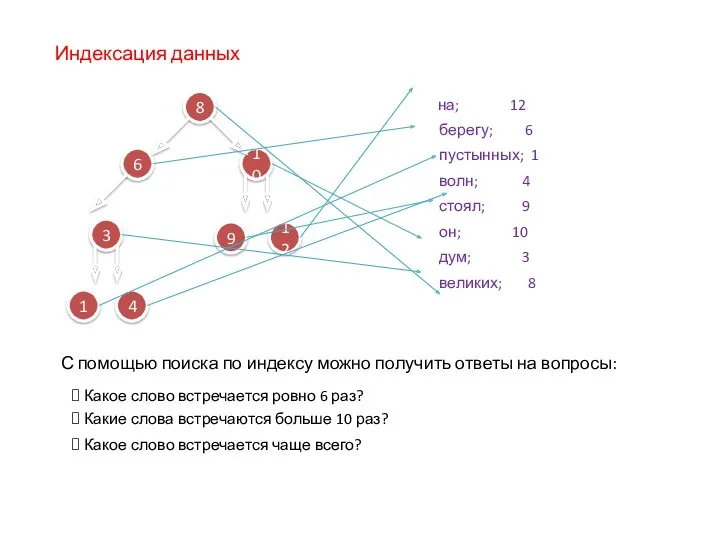
Индексация данных
С помощью поиска по индексу можно получить ответы на вопросы:
Индексация данных
С помощью поиска по индексу можно получить ответы на вопросы:
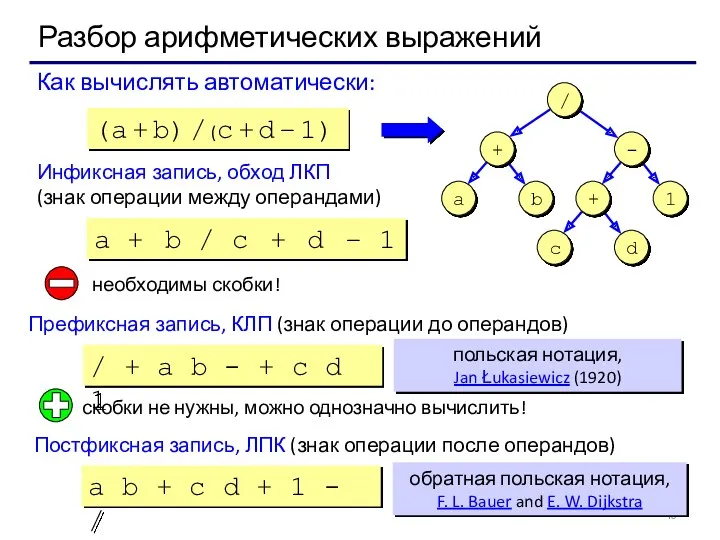
Разбор арифметических выражений
a b + c d + 1 - /
Как
Разбор арифметических выражений
a b + c d + 1 - /
Как
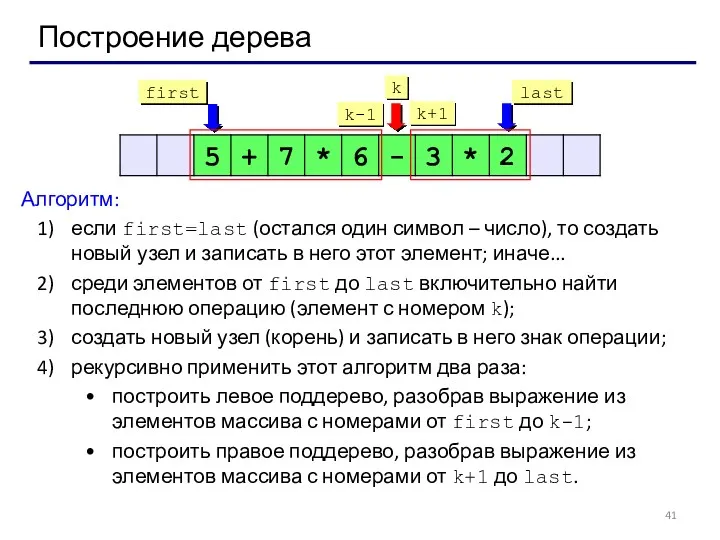
Построение дерева
Алгоритм:
если first=last (остался один символ – число), то создать новый
Построение дерева
Алгоритм:
если first=last (остался один символ – число), то создать новый

Как найти последнюю операцию?
Порядок выполнения операций
умножение и деление;
сложение и вычитание.
Приоритет (старшинство)
Как найти последнюю операцию?
Порядок выполнения операций
умножение и деление;
сложение и вычитание.
Приоритет (старшинство)

 Компьютерные вирусы и антивирусные программы
Компьютерные вирусы и антивирусные программы Windows Forms
Windows Forms Основи геоінформаційних систем і технологій
Основи геоінформаційних систем і технологій Яндекс.Такси для бизнеса
Яндекс.Такси для бизнеса Моделирование технологической операции химико-механической планаризации диоксида кремния
Моделирование технологической операции химико-механической планаризации диоксида кремния Lucius SlidesCarnival
Lucius SlidesCarnival Упражнение 1: Проектирование СХД
Упражнение 1: Проектирование СХД Искусственный интеллект
Искусственный интеллект Занятие 1. Знакомство с программой Adobe Photoshop
Занятие 1. Знакомство с программой Adobe Photoshop Интернет как глобальная информационная система. Сетевые информационные технологии
Интернет как глобальная информационная система. Сетевые информационные технологии Моделирование, формализация, визуализация
Моделирование, формализация, визуализация Рисование в текстовом редакторе
Рисование в текстовом редакторе Структура IR сайта. Главная страница
Структура IR сайта. Главная страница Социальные сети
Социальные сети Разработка платформы для блогинга о путешествиях с использованием фреймворка Bootstrap
Разработка платформы для блогинга о путешествиях с использованием фреймворка Bootstrap Программное управление компьютером. Классификация программного обеспечения. Операционные системы
Программное управление компьютером. Классификация программного обеспечения. Операционные системы Роль автоматизированных систем в правовой сфере
Роль автоматизированных систем в правовой сфере Разработка автоматизированной системы управления заявками на информационно-технологические услуги
Разработка автоматизированной системы управления заявками на информационно-технологические услуги Алгоритмизация и программирование. Язык Python
Алгоритмизация и программирование. Язык Python Agile тестирование
Agile тестирование Тема урока: Язык разметки гипертекста HTML
Тема урока: Язык разметки гипертекста HTML Устройство ввода информации. Клавиатура
Устройство ввода информации. Клавиатура Методы атак
Методы атак Тестирование программных средств
Тестирование программных средств Полномочия SQL Server
Полномочия SQL Server Доставка для интернет-магазинов
Доставка для интернет-магазинов Роль интернета в жизни общества
Роль интернета в жизни общества Анализ алгоритма, содержащего цикл и ветвление. Решение 20 задачи ЕГЭ
Анализ алгоритма, содержащего цикл и ветвление. Решение 20 задачи ЕГЭ