- Анализ символьных последовательности различной языковой природы

Содержание
- 2. Объект исследования: символьные последовательности различной языковой природы. Σ – непустое конечное множество символов (алфавит); T =
- 3. ДНК и аминокислотные последовательности ДНК: Σ = {A, C, G, T}, РНК: Σ = {A, C,
- 4. Polytene chromosomes Cytophotomap of arm A of the species C. piger
- 5. Пример древнерусской церковной рукописи
- 6. Примеры начертаний: – крюк: e2; – палка; – чашка: d4c4 – стрела простая: f1 (e1…) –
- 7. Двознаменник
- 8. Кодировка песнопений из двознаменника Первый и шестой символ кода – степенные и указательные пометы Степенные –
- 9. Пример кодировки песнопения из двознаменника (m0401-c2Во)(v0121-e2нми)(r0121-e2зе)(r0111-e2мле) (r0211-e4d4и)(r1941-c4d4e2не)(p1011-d1бо)(v0901-c4e4и) (p0302-d4c4вну)/ (-0501Td2e2ши) (*1021-f1 )(-0511-d4e4гла)(#0141-f2го)(-1601Ld4e4лы) (-0901-d4c4мо)(-1002-d1я)(-1001-c1 )(m0211-c4H4воз) (-0511-c4d4гла)/ (v0121-e2го)(r0121-e2лю)(r0211-e4d4бо)(-0511-c4d4на) (v0301-e2зе)(p1001-d1мли)(v0905Td2e2бо)(p0111-d2жи)
- 10. Основные задачи анализа текста поиск образцов; восстановление структуры текста: выявление повторов (периодичностей, симметрий …); сравнение последовательностей:
- 11. Формальные языки и грамматики Σ – алфавит; T = t1t2…tN (ti ∈ Σ, 1 ≤ i
- 12. Порождающей грамматикой называется четверка G = (Σ, N, P, S), где Σ – алфавит терминальных символов,
- 13. Иерархия Хомского Пусть G = (Σ, N, P, S) – грамматика. G называется: праволинейной, если каждое
- 14. Пример формальной грамматики Пусть G = ({a,b,c}, {A,B,S}, P, S), где правила вывода P имеют вид:
- 15. Пример. Арифметические выражения Σ = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, +,
- 16. Конечные автоматы − средство распознавания Детерминированный конечный автомат – это пятерка M = (S, Σ, δ,
- 18. Скачать презентацию

Объект исследования: символьные последовательности различной языковой природы.
Σ – непустое конечное
Объект исследования: символьные последовательности различной языковой природы.
Σ – непустое конечное
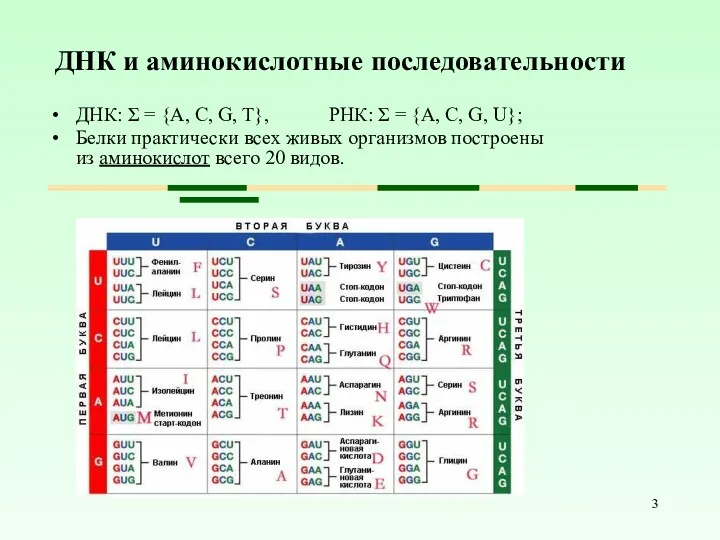
ДНК и аминокислотные последовательности
ДНК: Σ = {A, C, G, T}, РНК:
ДНК и аминокислотные последовательности
ДНК: Σ = {A, C, G, T}, РНК:

Polytene chromosomes
Cytophotomap of arm A of the species C. piger
Polytene chromosomes
Cytophotomap of arm A of the species C. piger

Пример древнерусской церковной рукописи
Пример древнерусской церковной рукописи

Примеры начертаний:
– крюк: e2; – палка; – чашка: d4c4
– стрела простая:
Примеры начертаний:
– крюк: e2; – палка; – чашка: d4c4
– стрела простая:

Двознаменник
Двознаменник
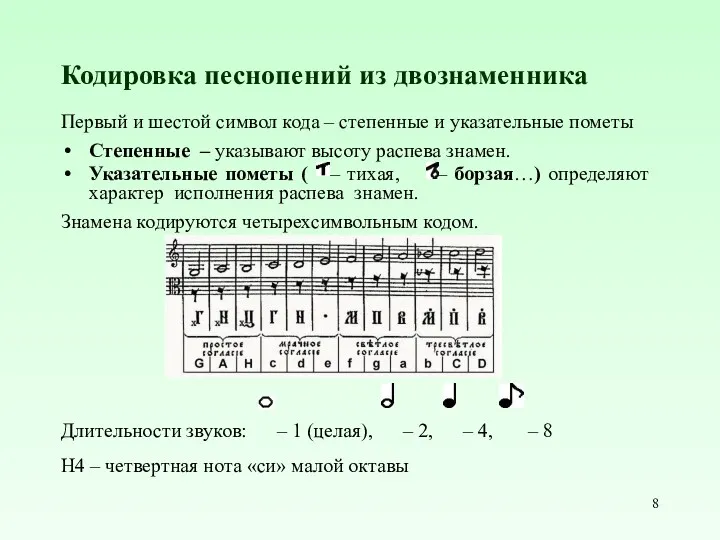
Кодировка песнопений из двознаменника
Первый и шестой символ кода – степенные и
Кодировка песнопений из двознаменника
Первый и шестой символ кода – степенные и

Пример кодировки песнопения из двознаменника
(m0401-c2Во)(v0121-e2нми)(r0121-e2зе)(r0111-e2мле)
(r0211-e4d4и)(r1941-c4d4e2не)(p1011-d1бо)(v0901-c4e4и)
(p0302-d4c4вну)/
(-0501Td2e2ши)
(*1021-f1 )(-0511-d4e4гла)(#0141-f2го)(-1601Ld4e4лы)
(-0901-d4c4мо)(-1002-d1я)(-1001-c1 )(m0211-c4H4воз)
(-0511-c4d4гла)/
(v0121-e2го)(r0121-e2лю)(r0211-e4d4бо)(-0511-c4d4на)
(v0301-e2зе)(p1001-d1мли)(v0905Td2e2бо)(p0111-d2жи)
(p1861-c2d1я)(p0201-d2чю)(m0301-c2де)(-2801-H1са.)/@
Пример кодировки песнопения из двознаменника
(m0401-c2Во)(v0121-e2нми)(r0121-e2зе)(r0111-e2мле)
(r0211-e4d4и)(r1941-c4d4e2не)(p1011-d1бо)(v0901-c4e4и)
(p0302-d4c4вну)/
(-0501Td2e2ши)
(*1021-f1 )(-0511-d4e4гла)(#0141-f2го)(-1601Ld4e4лы)
(-0901-d4c4мо)(-1002-d1я)(-1001-c1 )(m0211-c4H4воз)
(-0511-c4d4гла)/
(v0121-e2го)(r0121-e2лю)(r0211-e4d4бо)(-0511-c4d4на)
(v0301-e2зе)(p1001-d1мли)(v0905Td2e2бо)(p0111-d2жи)
(p1861-c2d1я)(p0201-d2чю)(m0301-c2де)(-2801-H1са.)/@

Основные задачи анализа текста
поиск образцов;
восстановление структуры текста: выявление повторов
Основные задачи анализа текста
поиск образцов;
восстановление структуры текста: выявление повторов

Формальные языки и грамматики
Σ – алфавит;
T = t1t2…tN (ti ∈
Формальные языки и грамматики
Σ – алфавит;
T = t1t2…tN (ti ∈

Порождающей грамматикой называется четверка
G = (Σ, N, P, S), где
Порождающей грамматикой называется четверка
G = (Σ, N, P, S), где

Иерархия Хомского
Пусть G = (Σ, N, P, S) – грамматика.
Иерархия Хомского
Пусть G = (Σ, N, P, S) – грамматика.

Пример формальной грамматики
Пусть G = ({a,b,c}, {A,B,S}, P, S),
где правила
Пример формальной грамматики
Пусть G = ({a,b,c}, {A,B,S}, P, S),
где правила

Пример. Арифметические выражения
Σ = {0, 1, 2, 3, 4, 5, 6,
Пример. Арифметические выражения
Σ = {0, 1, 2, 3, 4, 5, 6,
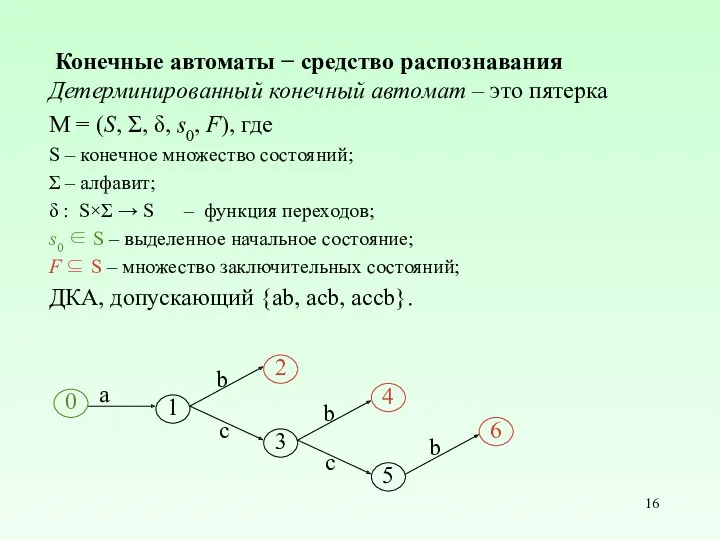
Конечные автоматы − средство распознавания
Детерминированный конечный автомат – это пятерка
M
Конечные автоматы − средство распознавания
Детерминированный конечный автомат – это пятерка
M
 Умный словарь (тезаурус) по теме Машинное обучение
Умный словарь (тезаурус) по теме Машинное обучение Построение Standby Database на основе технологии Oracle Active Data Guard
Построение Standby Database на основе технологии Oracle Active Data Guard OpenGL установка
OpenGL установка Основы программирования в среде delphi. Сборник упражнений
Основы программирования в среде delphi. Сборник упражнений Нейронные сети
Нейронные сети Российские СПС Гарант и Консультант Плюс Лекция 15
Российские СПС Гарант и Консультант Плюс Лекция 15 Прототип мобильного приложения для обучения правильной технике свинга при помощи AI
Прототип мобильного приложения для обучения правильной технике свинга при помощи AI Алгоритмическая конструкция ветвление
Алгоритмическая конструкция ветвление Архитектура ЭВМ. Процессор
Архитектура ЭВМ. Процессор Faýllar sistemasynyň obýektleri bilen işlemek Lokal kompýuter tory barada düşünje “Tor gurşawy “ papkasy
Faýllar sistemasynyň obýektleri bilen işlemek Lokal kompýuter tory barada düşünje “Tor gurşawy “ papkasy Модели процесса создания программного обеспечения. Лекция 4
Модели процесса создания программного обеспечения. Лекция 4 Инструкция по созданию автособираемого оглавления в Microsoft Word 2013
Инструкция по созданию автособираемого оглавления в Microsoft Word 2013 Лабораторная работа № 2. Анализ главных компонент
Лабораторная работа № 2. Анализ главных компонент Программное обеспечение ПК
Программное обеспечение ПК Алгоритм создания визитных карточек с использованием программы Paint
Алгоритм создания визитных карточек с использованием программы Paint Разработка программных модулей. Графические построения. Контурные фигуры
Разработка программных модулей. Графические построения. Контурные фигуры Power Point. Урок 2
Power Point. Урок 2 Синтаксис и программные конструкции VBA. Лекция 2
Синтаксис и программные конструкции VBA. Лекция 2 Autodesk Vault Professional
Autodesk Vault Professional Лекция 4
Лекция 4 Правила заполнения ежемесячной отчетности партнеров по непродленным договорам ИТС
Правила заполнения ежемесячной отчетности партнеров по непродленным договорам ИТС Информационные технологии в профессиональной деятельности
Информационные технологии в профессиональной деятельности Информационные ресурсы интернета
Информационные ресурсы интернета Хмарні IDE
Хмарні IDE Киберриски. Защита персональных сайтов
Киберриски. Защита персональных сайтов Использование современных информационных технологий на уроках обслуживающего труда
Использование современных информационных технологий на уроках обслуживающего труда Системы электронного документооборота
Системы электронного документооборота Принципы технологии модерации.
Принципы технологии модерации.