- Decompiler internals: microcode

Содержание
- 2. (c) 2018 Ilfak Guilfanov Presentation Outline Decompiler architecture Overview of the microcode Opcodes and operands Stack
- 3. (c) 2018 Ilfak Guilfanov Hex-Rays Decompiler Interactive, fast, robust, and programmable decompiler Can handle x86, x64,
- 4. (c) 2018 Ilfak Guilfanov Decompiler architecture It uses very straightforward sequence of steps: Generate microcode Transform
- 5. (c) 2018 Ilfak Guilfanov Decompiler architecture We will focus on the first two steps: Generate microcode
- 6. (c) 2018 Ilfak Guilfanov Why microcode? It helps to get rid of the complexity of processor
- 7. (c) 2018 Ilfak Guilfanov Is implementing an IR difficult? Your call :) How many IR languages
- 8. (c) 2018 Ilfak Guilfanov Why not use an existing IR? There are tons of other intermediate
- 9. (c) 2018 Ilfak Guilfanov A long evolution I started to work on the microcode in 1998
- 10. (c) 2018 Ilfak Guilfanov Design highlights Simplicity: No processor specific stuff One microinstruction does one thing
- 11. (c) 2018 Ilfak Guilfanov Generated microcode Initially the microcode looks like RISC code: Memory loads and
- 12. (c) 2018 Ilfak Guilfanov Initial microcode: very verbose 2. 0 mov ebx.4, eoff.4 ; 4014FB u=ebx.4
- 13. (c) 2018 Ilfak Guilfanov The first optimization pass 2. 0 ldx ds.2, (ebx.4+#4.4), eax.4 ; 4014FB
- 14. (c) 2018 Ilfak Guilfanov Further microcode transformations And the final code is: This code is ready
- 15. (c) 2018 Ilfak Guilfanov Minor details Reading microcode is not easy (but hey, it was not
- 16. (c) 2018 Ilfak Guilfanov Opcodes: constants and move Copy from (l) to (d)estination Operand sizes must
- 17. (c) 2018 Ilfak Guilfanov Opcodes: changing operand size Copy from (l) to (d)estination Operand sizes must
- 18. (c) 2018 Ilfak Guilfanov Opcodes: load and store {sel, off} is a segment:offset pair Usually seg
- 19. (c) 2018 Ilfak Guilfanov Opcodes: comparisons Compare (l)left against (r)right The result is stored into (d)estination,
- 20. (c) 2018 Ilfak Guilfanov Opcodes: arithmetic and bitwise operations Operand sizes must be the same The
- 21. (c) 2018 Ilfak Guilfanov Opcodes: shifts (and rotations?) Shift (l)eft by the amount specified in (r)ight
- 22. (c) 2018 Ilfak Guilfanov Opcodes: condition codes Perform the operation on (l)left and (r)ight Generate carry
- 23. (c) 2018 Ilfak Guilfanov Opcodes: unconditional flow control Initially calls have only the callee address The
- 24. (c) 2018 Ilfak Guilfanov Opcodes: conditional jumps Compare (l)eft against (r)right and jump to (d)estination if
- 25. (c) 2018 Ilfak Guilfanov Opcodes: floating point operations Basically we have conversions and a few arithmetic
- 26. (c) 2018 Ilfak Guilfanov Opcodes: miscellaneous Some operations can not be expressed in microcode If possible,
- 27. (c) 2018 Ilfak Guilfanov More opcodes? We quickly reviewed all 72 instructions Probably we should extend
- 28. (c) 2018 Ilfak Guilfanov Operands! As everyone else, initially we had only: constant integer numbers registers
- 29. (c) 2018 Ilfak Guilfanov Register operands The microcode engine provides unlimited (in theory) number of microregisters
- 30. (c) 2018 Ilfak Guilfanov Stack as microregisters I was reluctant to introduce a new operand type
- 31. (c) 2018 Ilfak Guilfanov Stack as viewed by the decompiler Shadow stkargs Input stkargs Return address
- 32. (c) 2018 Ilfak Guilfanov More operand types! 64-bit values are represented as pairs of registers Usually
- 33. (c) 2018 Ilfak Guilfanov Scattered operands The nightmare has just begun, in fact Modern compilers use
- 34. (c) 2018 Ilfak Guilfanov A simple scattered return value A function that returns a struct in
- 35. (c) 2018 Ilfak Guilfanov A simple scattered return value …and the output is: Our decompiler managed
- 36. (c) 2018 Ilfak Guilfanov More detailed look at microcode transformations The initial “preoptimization” step uses very
- 37. (c) 2018 Ilfak Guilfanov Global optimization We build the control flow graph Perform data flow analysis
- 38. (c) 2018 Ilfak Guilfanov Synthetic assertion instructions If jump is not taken, then we know that
- 39. (c) 2018 Ilfak Guilfanov Simple algebraic transformations We have implemented (in plain C++) hundreds of very
- 40. (c) 2018 Ilfak Guilfanov More complex rules For example, this rule recognizes 64-bit subtractions: We have
- 41. (c) 2018 Ilfak Guilfanov Data dependency dependent rules Naturally, all these rules are compiler-independent, they use
- 42. (c) 2018 Ilfak Guilfanov Interblock rules Some rules work across multiple blocks: jl xh, yh, SUCCESS
- 43. (c) 2018 Ilfak Guilfanov Interblock rules: signed division by power2 Signed division is sometimes replaced by
- 44. (c) 2018 Ilfak Guilfanov Hooks It is possible to hook to the optimization engine and add
- 45. (c) 2018 Ilfak Guilfanov ARM hooks For example, the ARM decompiler has the following rule: so
- 46. (c) 2018 Ilfak Guilfanov Data flow analysis In fact virtually all transformation rules are based on
- 47. (c) 2018 Ilfak Guilfanov Use-def lists Similar lists are maintained for each block. Instead of calculating
- 48. (c) 2018 Ilfak Guilfanov Usefulness of use-def lists Based on use-def lists of each block the
- 49. (c) 2018 Ilfak Guilfanov Global propagation in action Image we have code like this: mov #5.4,
- 50. (c) 2018 Ilfak Guilfanov Global propagation in action The use-def chains clearly show that esi is
- 51. (c) 2018 Ilfak Guilfanov Data flow analysis The devil is in details Our analysis engine can
- 52. (c) 2018 Ilfak Guilfanov Aliasability Take this example: can we claim that %stkvar == 1 after
- 53. (c) 2018 Ilfak Guilfanov Stack as viewed by the decompiler Shadow stkargs Input stkargs Return address
- 54. (c) 2018 Ilfak Guilfanov Minimal stack reference Aliasability is unsolvable problem in general We should optimize
- 55. (c) 2018 Ilfak Guilfanov Minstkref propagation We use the control flow graph: lea ecx, [esp+10] ;
- 56. (c) 2018 Ilfak Guilfanov Testing the microcode Microcode if verified for consistency after every transformation BTW,
- 57. (c) 2018 Ilfak Guilfanov Publishing microcode The microcode API for C++ will be available in the
- 59. Скачать презентацию

(c) 2018 Ilfak Guilfanov
Presentation Outline
Decompiler architecture
Overview of the microcode
Opcodes and operands
Stack
(c) 2018 Ilfak Guilfanov
Presentation Outline
Decompiler architecture
Overview of the microcode
Opcodes and operands
Stack

(c) 2018 Ilfak Guilfanov
Hex-Rays Decompiler
Interactive, fast, robust, and programmable decompiler
Can handle
(c) 2018 Ilfak Guilfanov
Hex-Rays Decompiler
Interactive, fast, robust, and programmable decompiler
Can handle

(c) 2018 Ilfak Guilfanov
Decompiler architecture
It uses very straightforward sequence of steps:
Generate
(c) 2018 Ilfak Guilfanov
Decompiler architecture
It uses very straightforward sequence of steps:
Generate

(c) 2018 Ilfak Guilfanov
Decompiler architecture
We will focus on the first two
(c) 2018 Ilfak Guilfanov
Decompiler architecture
We will focus on the first two

(c) 2018 Ilfak Guilfanov
Why microcode?
It helps to get rid of the
(c) 2018 Ilfak Guilfanov
Why microcode?
It helps to get rid of the
(c) 2018 Ilfak Guilfanov
Is implementing an IR difficult?
Your call :)
How many
(c) 2018 Ilfak Guilfanov
Is implementing an IR difficult?
Your call :)
How many

(c) 2018 Ilfak Guilfanov
Why not use an existing IR?
There are tons
(c) 2018 Ilfak Guilfanov
Why not use an existing IR?
There are tons

(c) 2018 Ilfak Guilfanov
A long evolution
I started to work on the
(c) 2018 Ilfak Guilfanov
A long evolution
I started to work on the

(c) 2018 Ilfak Guilfanov
Design highlights
Simplicity:
No processor specific stuff
One microinstruction does one
(c) 2018 Ilfak Guilfanov
Design highlights
Simplicity:
No processor specific stuff
One microinstruction does one

(c) 2018 Ilfak Guilfanov
Generated microcode
Initially the microcode looks like RISC code:
Memory
(c) 2018 Ilfak Guilfanov
Generated microcode
Initially the microcode looks like RISC code:
Memory

(c) 2018 Ilfak Guilfanov
Initial microcode: very verbose
2. 0 mov ebx.4, eoff.4
(c) 2018 Ilfak Guilfanov
Initial microcode: very verbose
2. 0 mov ebx.4, eoff.4

(c) 2018 Ilfak Guilfanov
The first optimization pass
2. 0 ldx ds.2, (ebx.4+#4.4),
(c) 2018 Ilfak Guilfanov
The first optimization pass
2. 0 ldx ds.2, (ebx.4+#4.4),

(c) 2018 Ilfak Guilfanov
Further microcode transformations
And the final code is:
This
(c) 2018 Ilfak Guilfanov
Further microcode transformations
And the final code is: This

(c) 2018 Ilfak Guilfanov
Minor details
Reading microcode is not easy (but hey,
(c) 2018 Ilfak Guilfanov
Minor details
Reading microcode is not easy (but hey,

(c) 2018 Ilfak Guilfanov
Opcodes: constants and move
Copy from (l) to (d)estination
Operand
(c) 2018 Ilfak Guilfanov
Opcodes: constants and move
Copy from (l) to (d)estination
Operand

(c) 2018 Ilfak Guilfanov
Opcodes: changing operand size
Copy from (l) to (d)estination
Operand
(c) 2018 Ilfak Guilfanov
Opcodes: changing operand size
Copy from (l) to (d)estination
Operand

(c) 2018 Ilfak Guilfanov
Opcodes: load and store
{sel, off} is a segment:offset
(c) 2018 Ilfak Guilfanov
Opcodes: load and store
{sel, off} is a segment:offset

(c) 2018 Ilfak Guilfanov
Opcodes: comparisons
Compare (l)left against (r)right
The result is stored
(c) 2018 Ilfak Guilfanov
Opcodes: comparisons
Compare (l)left against (r)right
The result is stored

(c) 2018 Ilfak Guilfanov
Opcodes: arithmetic and bitwise operations
Operand sizes must be
(c) 2018 Ilfak Guilfanov
Opcodes: arithmetic and bitwise operations
Operand sizes must be

(c) 2018 Ilfak Guilfanov
Opcodes: shifts (and rotations?)
Shift (l)eft by the amount
(c) 2018 Ilfak Guilfanov
Opcodes: shifts (and rotations?)
Shift (l)eft by the amount

(c) 2018 Ilfak Guilfanov
Opcodes: condition codes
Perform the operation on (l)left and
(c) 2018 Ilfak Guilfanov
Opcodes: condition codes
Perform the operation on (l)left and

(c) 2018 Ilfak Guilfanov
Opcodes: unconditional flow control
Initially calls have only the
(c) 2018 Ilfak Guilfanov
Opcodes: unconditional flow control
Initially calls have only the

(c) 2018 Ilfak Guilfanov
Opcodes: conditional jumps
Compare (l)eft against (r)right and jump
(c) 2018 Ilfak Guilfanov
Opcodes: conditional jumps
Compare (l)eft against (r)right and jump

(c) 2018 Ilfak Guilfanov
Opcodes: floating point operations
Basically we have conversions and
(c) 2018 Ilfak Guilfanov
Opcodes: floating point operations
Basically we have conversions and

(c) 2018 Ilfak Guilfanov
Opcodes: miscellaneous
Some operations can not be expressed in
(c) 2018 Ilfak Guilfanov
Opcodes: miscellaneous
Some operations can not be expressed in

(c) 2018 Ilfak Guilfanov
More opcodes?
We quickly reviewed all 72 instructions
Probably we
(c) 2018 Ilfak Guilfanov
More opcodes?
We quickly reviewed all 72 instructions
Probably we

(c) 2018 Ilfak Guilfanov
Operands!
As everyone else, initially we had only:
constant integer
(c) 2018 Ilfak Guilfanov
Operands!
As everyone else, initially we had only:
constant integer

(c) 2018 Ilfak Guilfanov
Register operands
The microcode engine provides unlimited (in theory)
(c) 2018 Ilfak Guilfanov
Register operands
The microcode engine provides unlimited (in theory)

(c) 2018 Ilfak Guilfanov
Stack as microregisters
I was reluctant to introduce a
(c) 2018 Ilfak Guilfanov
Stack as microregisters
I was reluctant to introduce a

(c) 2018 Ilfak Guilfanov
Stack as viewed by the decompiler
Shadow stkargs
Input stkargs
Return
(c) 2018 Ilfak Guilfanov
Stack as viewed by the decompiler
Shadow stkargs
Input stkargs
Return

(c) 2018 Ilfak Guilfanov
More operand types!
64-bit values are represented as pairs
(c) 2018 Ilfak Guilfanov
More operand types!
64-bit values are represented as pairs

(c) 2018 Ilfak Guilfanov
Scattered operands
The nightmare has just begun, in fact
Modern
(c) 2018 Ilfak Guilfanov
Scattered operands
The nightmare has just begun, in fact
Modern

(c) 2018 Ilfak Guilfanov
A simple scattered return value
A function that returns
(c) 2018 Ilfak Guilfanov
A simple scattered return value
A function that returns

(c) 2018 Ilfak Guilfanov
A simple scattered return value
…and the output is:
Our
(c) 2018 Ilfak Guilfanov
A simple scattered return value
…and the output is:
Our

(c) 2018 Ilfak Guilfanov
More detailed look at microcode transformations
The initial “preoptimization”
(c) 2018 Ilfak Guilfanov
More detailed look at microcode transformations
The initial “preoptimization”

(c) 2018 Ilfak Guilfanov
Global optimization
We build the control flow graph
Perform data
(c) 2018 Ilfak Guilfanov
Global optimization
We build the control flow graph
Perform data

(c) 2018 Ilfak Guilfanov
Synthetic assertion instructions
If jump is not taken, then
(c) 2018 Ilfak Guilfanov
Synthetic assertion instructions
If jump is not taken, then

(c) 2018 Ilfak Guilfanov
Simple algebraic transformations
We have implemented (in plain C++)
(c) 2018 Ilfak Guilfanov
Simple algebraic transformations
We have implemented (in plain C++)

(c) 2018 Ilfak Guilfanov
More complex rules
For example, this rule recognizes 64-bit
(c) 2018 Ilfak Guilfanov
More complex rules
For example, this rule recognizes 64-bit

(c) 2018 Ilfak Guilfanov
Data dependency dependent rules
Naturally, all these rules are
(c) 2018 Ilfak Guilfanov
Data dependency dependent rules
Naturally, all these rules are
(c) 2018 Ilfak Guilfanov
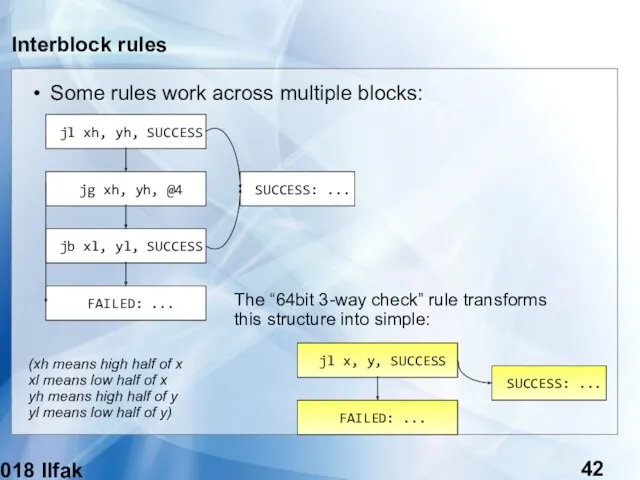
Interblock rules
Some rules work across multiple blocks:
jl xh,
(c) 2018 Ilfak Guilfanov
Interblock rules
Some rules work across multiple blocks:
jl xh,

(c) 2018 Ilfak Guilfanov
Interblock rules: signed division by power2
Signed division is
(c) 2018 Ilfak Guilfanov
Interblock rules: signed division by power2
Signed division is

(c) 2018 Ilfak Guilfanov
Hooks
It is possible to hook to the optimization
(c) 2018 Ilfak Guilfanov
Hooks
It is possible to hook to the optimization

(c) 2018 Ilfak Guilfanov
ARM hooks
For example, the ARM decompiler has the
(c) 2018 Ilfak Guilfanov
ARM hooks
For example, the ARM decompiler has the

(c) 2018 Ilfak Guilfanov
Data flow analysis
In fact virtually all transformation rules
(c) 2018 Ilfak Guilfanov
Data flow analysis
In fact virtually all transformation rules

(c) 2018 Ilfak Guilfanov
Use-def lists
Similar lists are maintained for each block.
(c) 2018 Ilfak Guilfanov
Use-def lists
Similar lists are maintained for each block.

(c) 2018 Ilfak Guilfanov
Usefulness of use-def lists
Based on use-def lists of
(c) 2018 Ilfak Guilfanov
Usefulness of use-def lists
Based on use-def lists of

(c) 2018 Ilfak Guilfanov
Global propagation in action
Image we have code like
(c) 2018 Ilfak Guilfanov
Global propagation in action
Image we have code like

(c) 2018 Ilfak Guilfanov
Global propagation in action
The use-def chains clearly show
(c) 2018 Ilfak Guilfanov
Global propagation in action
The use-def chains clearly show

(c) 2018 Ilfak Guilfanov
Data flow analysis
The devil is in details
Our analysis
(c) 2018 Ilfak Guilfanov
Data flow analysis
The devil is in details
Our analysis

(c) 2018 Ilfak Guilfanov
Aliasability
Take this example:
can we claim that %stkvar ==
(c) 2018 Ilfak Guilfanov
Aliasability
Take this example: can we claim that %stkvar ==

(c) 2018 Ilfak Guilfanov
Stack as viewed by the decompiler
Shadow stkargs
Input stkargs
Return
(c) 2018 Ilfak Guilfanov
Stack as viewed by the decompiler
Shadow stkargs
Input stkargs
Return

(c) 2018 Ilfak Guilfanov
Minimal stack reference
Aliasability is unsolvable problem in general
We
(c) 2018 Ilfak Guilfanov
Minimal stack reference
Aliasability is unsolvable problem in general
We

(c) 2018 Ilfak Guilfanov
Minstkref propagation
We use the control flow graph:
lea ecx,
(c) 2018 Ilfak Guilfanov
Minstkref propagation
We use the control flow graph:
lea ecx,

(c) 2018 Ilfak Guilfanov
Testing the microcode
Microcode if verified for consistency after
(c) 2018 Ilfak Guilfanov
Testing the microcode
Microcode if verified for consistency after

(c) 2018 Ilfak Guilfanov
Publishing microcode
The microcode API for C++ will be
(c) 2018 Ilfak Guilfanov
Publishing microcode
The microcode API for C++ will be
 Distributed file system
Distributed file system Основные алгоритмические конструкции: следование, ветвление, повторение
Основные алгоритмические конструкции: следование, ветвление, повторение Інформаційна війна та маніпулювання
Інформаційна війна та маніпулювання Основы языка JavaScript
Основы языка JavaScript Циклы. Итерационные циклы
Циклы. Итерационные циклы Human-computer interaction
Human-computer interaction Инструкция по работе в приложении Омобус
Инструкция по работе в приложении Омобус Разработка системы обеспечения безопасности данных корпоративной сети организации
Разработка системы обеспечения безопасности данных корпоративной сети организации Арифметические операции в позиционных системах счисления
Арифметические операции в позиционных системах счисления Информационное общество
Информационное общество Группа услуг Автосекретарь
Группа услуг Автосекретарь Блок-схема алгоритма. Линейный алгоритм
Блок-схема алгоритма. Линейный алгоритм Сборка ПК
Сборка ПК Множества. Массивы (Delphi)
Множества. Массивы (Delphi) Преподавание информатики в условиях введения ФГОС нового поколения.
Преподавание информатики в условиях введения ФГОС нового поколения. Презентация Классификация понятий
Презентация Классификация понятий Безопасность уровня операционных систем
Безопасность уровня операционных систем Администрирование в ЛВС
Администрирование в ЛВС Виртуальный батл. Конкурс Разминка
Виртуальный батл. Конкурс Разминка Введение в PHP
Введение в PHP Классификация современных ЭВМ. Основные характеристики больших ЭВМ. Самые мощные компьютеры на планете
Классификация современных ЭВМ. Основные характеристики больших ЭВМ. Самые мощные компьютеры на планете Прототип. Средства создания прототипа. Технология работы в программе прототипирования
Прототип. Средства создания прототипа. Технология работы в программе прототипирования Прикладной уровень и протоколы
Прикладной уровень и протоколы Анализ затрат на информационное обеспечение деятельности компании
Анализ затрат на информационное обеспечение деятельности компании Adapters. AutoCompleteTextView
Adapters. AutoCompleteTextView Сетевое взаимодействие школьных библиотек: состояние, проблемы, перспективы. Блог школьной библиотеки
Сетевое взаимодействие школьных библиотек: состояние, проблемы, перспективы. Блог школьной библиотеки Информационные и управляющие системы
Информационные и управляющие системы Системы управления базами данных и базами знаний. Функциональные возможности СУБД
Системы управления базами данных и базами знаний. Функциональные возможности СУБД