- Динамически структуры данных. Односвязные списки

Содержание
- 2. План лекции Управление памятью в программировании Понятие динамических структур данных Типы динамических структур Односвязный линейный список
- 3. Управление памятью в программировании
- 4. Управление памятью Бурное развитие прогресса и повсеместное внедрение компьютеров и компьютерных технологий в общественную жизнь породило
- 5. Управление памятью На сегодняшний день способы обработки и хранения информации значительно упростились, появились программные средства, которые
- 6. Управление памятью В любой информационной системе ключевым элементом является память. Управление памятью - одна из главных
- 7. Модель памяти Когда начинается выполнение программы, написанной на языке С++, компилятор резервирует память: для ее кода
- 8. Модель памяти Статическая — выделение памяти до начала исполнения программы. Такая память доступна на протяжении всего
- 9. Модель памяти Автоматическая —автоматически выделяет аргументы и локальные переменные функции, а также прочую метаинформацию при вызове
- 10. Модель памяти Динамическая память — выделение памяти из ОС по требованию приложения. После выделения памяти в
- 11. Динамические структуры данных
- 12. Динамические структуры данных Динамические структуры данных – это любая структура данных, занимаемая объем памяти, который не
- 13. Динамические структуры данных Структуры одного типа можно объединять не только в массивы. Их можно связывать между
- 14. Динамические структуры данных Общие определения: Потомок — элемент структуры, идущий после текущего. В зависимости от вида
- 15. Списки Динамические структуры представляют собой отдельные элементы, связанные с помощью ссылок. Каждый элемент (узел) состоит из
- 16. Списки Список — это линейная динамическая структура данных, у каждого элемента может быть только один предок
- 17. Типы списков Односвязный список — элемент имеет указатель только на своего потомка.
- 18. Типы списков Двусвязный список — элемент имеет указатели и на потомка, и на родителя.
- 19. Типы списков Замкнутый (кольцевой, циклический) список — головной и хвостовой элементы которого указывают друг на друга.
- 20. Типы списков Стек - извлечение и добавление элементов в нем происходит по правилу «Последний пришел, первый
- 21. Типы списков Очередь - список, операции чтения и добавления элементов в котором подвержены правилу «Первый пришел,
- 22. Достоинства эффективное добавление и удаление элементов размер ограничен только объёмом памяти компьютера и разрядностью указателей динамическое
- 23. Недостатки сложность прямого доступа к элементу, а именно определения физического адреса по его индексу (порядковому номеру)
- 24. Односвязные линейные списки
- 25. Односвязные списки Односвязный линейный список – это динамический список, в котором каждый узел содержит всего одну
- 26. Односвязные списки Узел представляет собой структуру, которая содержит поля данные и указатель на такой же узел.
- 27. Односвязные списки В программе надо объявить два новых типа данных – узел списка Node и указатель
- 28. Односвязные списки Например, опишем односвязный список для представления словаря русских слов. Узел представляет собой структуру, которая
- 29. Односвязные списки. Операции Операции над односвязными списками: Создание нового узла. Добавление узла: В начало списка В
- 30. Создание нового узла Для того, чтобы добавить узел к списку, необходимо создать его, то есть выделить
- 31. Добавление узла в начало списка При добавлении нового узла NewNode в начало списка надо: 1) установить
- 32. Добавление узла в начало списка По такой схеме работает функция AddFirst. Предполагается, что адрес начала списка
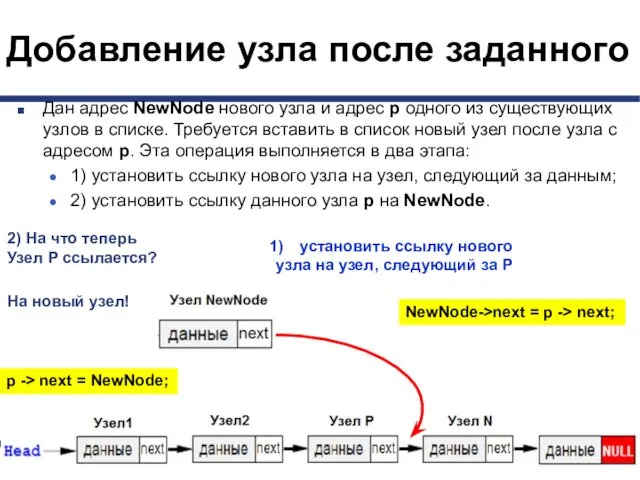
- 33. Добавление узла после заданного Дан адрес NewNode нового узла и адрес p одного из существующих узлов
- 34. Добавление узла после заданного По такой схеме работает функция AddAfter. Передавать будем адрес узла после которого,
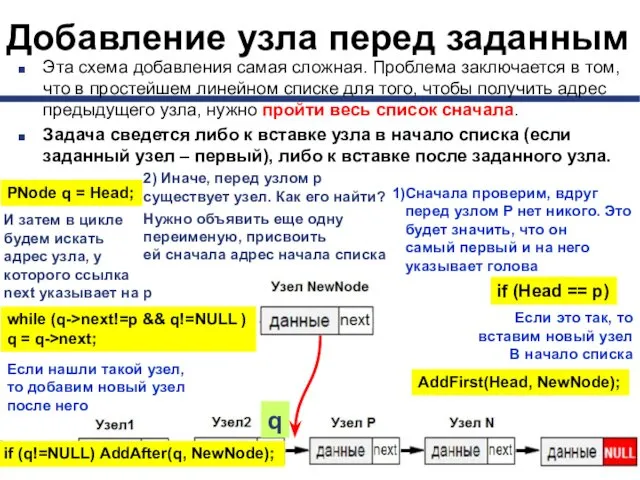
- 35. Добавление узла перед заданным Эта схема добавления самая сложная. Проблема заключается в том, что в простейшем
- 36. Добавление узла перед заданным void AddBefore(PNode &Head, PNode p, PNode NewNode) { PNode q = Head;
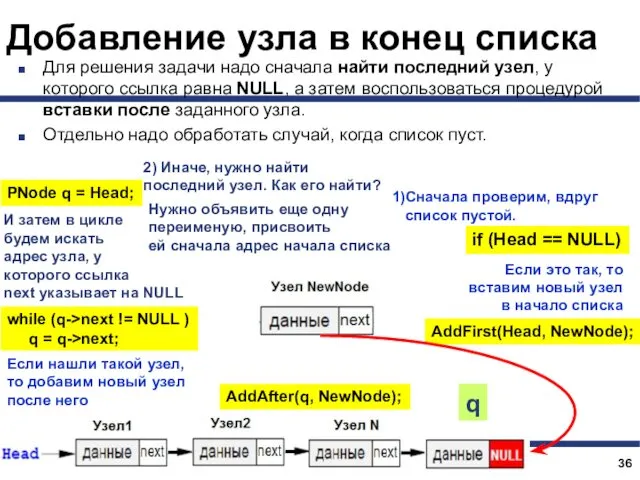
- 37. Добавление узла в конец списка Для решения задачи надо сначала найти последний узел, у которого ссылка
- 38. Добавление узла в конец списка void AddLast(PNode &Head, PNode NewNode) { PNode q = Head; if
- 39. Проход по списку PNode p = Head; while ( p != NULL ) { p =
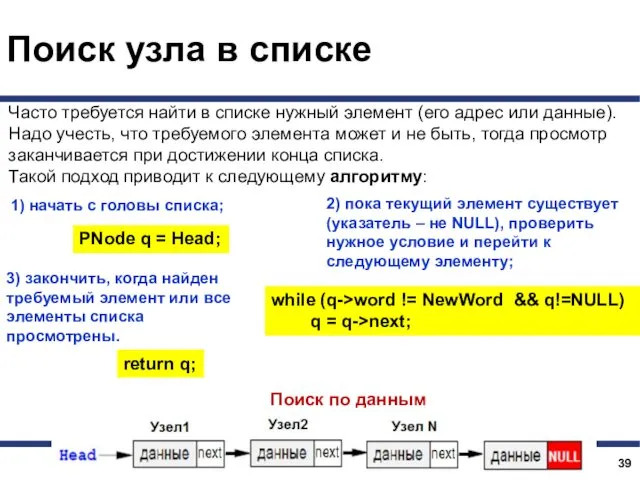
- 40. Поиск узла в списке Часто требуется найти в списке нужный элемент (его адрес или данные). Надо
- 41. Поиск узла в списке PNode Find (PNode Head, string NewWord) { PNode q = Head; while
- 42. Поиск узла по порядку в списке Вернемся к задаче построения алфавитного словаря. Для того, чтобы добавить
- 43. Поиск узла по порядку в списке 1) начать с головы списка; 2) пока текущий элемент существует
- 44. Поиск узла по порядку в списке PNode FindPlace (PNode Head, string NewWord) { PNode q =
- 45. Удаление узла Эта процедура также связана с поиском заданного узла по всему списку, так как нам
- 46. Удаление узла 1) Найдем узел, который ссылается на удаляемый узел 2) Изменяем ссылку у предыдущего узла
- 47. Удаление узла void DeleteNode(PNode &Head, PNode OldNode) { PNode q = Head; if (Head == OldNode)
- 48. Пример программы на односвязный линейный список
- 49. Пример. Односвязный список словарь #include #include using namespace std; // описание динамической структуры struct Node {
- 50. Пример (продолжение) int main() { PNode Head = NULL; PNode pnew, pfind; int t; string newslovo;
- 51. Пример (продолжение) case 1 : cout cin>>newslovo; pnew=CreateNode(newslovo); //создаем новый узел if (Head==NULL) AddFirst (Head, pnew)
- 52. Спасибо за внимание!
- 54. Скачать презентацию

План лекции
Управление памятью в программировании
Понятие динамических структур данных
Типы динамических структур
Односвязный линейный
План лекции
Управление памятью в программировании
Понятие динамических структур данных
Типы динамических структур
Односвязный линейный

Управление памятью в программировании
Управление памятью в программировании

Управление памятью
Бурное развитие прогресса и повсеместное внедрение компьютеров и компьютерных технологий
Управление памятью
Бурное развитие прогресса и повсеместное внедрение компьютеров и компьютерных технологий

Управление памятью
На сегодняшний день способы обработки и хранения информации значительно упростились,
Управление памятью
На сегодняшний день способы обработки и хранения информации значительно упростились,

Управление памятью
В любой информационной системе ключевым элементом является память.
Управление памятью
Управление памятью
В любой информационной системе ключевым элементом является память.
Управление памятью

Модель памяти
Когда начинается выполнение программы, написанной на языке С++, компилятор резервирует
Модель памяти
Когда начинается выполнение программы, написанной на языке С++, компилятор резервирует

Модель памяти
Статическая — выделение памяти до начала исполнения программы. Такая память доступна
Модель памяти
Статическая — выделение памяти до начала исполнения программы. Такая память доступна

Модель памяти
Автоматическая —автоматически выделяет аргументы и локальные переменные функции, а также
Модель памяти
Автоматическая —автоматически выделяет аргументы и локальные переменные функции, а также

Модель памяти
Динамическая память — выделение памяти из ОС по требованию приложения.
После выделения
Модель памяти
Динамическая память — выделение памяти из ОС по требованию приложения.
После выделения

Динамические структуры данных
Динамические структуры данных

Динамические структуры данных
Динамические структуры данных – это любая структура данных, занимаемая
Динамические структуры данных
Динамические структуры данных – это любая структура данных, занимаемая

Динамические структуры данных
Структуры одного типа можно объединять не только в массивы.
Динамические структуры данных
Структуры одного типа можно объединять не только в массивы.

Динамические структуры данных
Общие определения:
Потомок — элемент структуры, идущий после текущего. В зависимости
Динамические структуры данных
Общие определения:
Потомок — элемент структуры, идущий после текущего. В зависимости

Списки
Динамические структуры представляют собой отдельные элементы, связанные с помощью ссылок.
Каждый элемент
Списки
Динамические структуры представляют собой отдельные элементы, связанные с помощью ссылок.
Каждый элемент

Списки
Список — это линейная динамическая структура данных, у каждого элемента может быть
Списки
Список — это линейная динамическая структура данных, у каждого элемента может быть
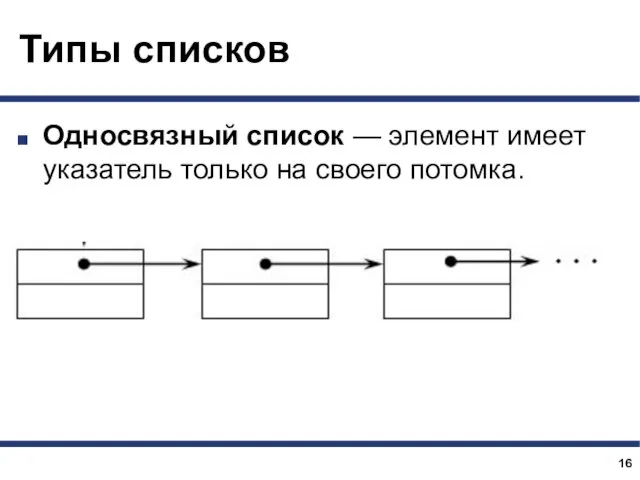
Типы списков
Односвязный список — элемент имеет указатель только на своего потомка.
Типы списков
Односвязный список — элемент имеет указатель только на своего потомка.
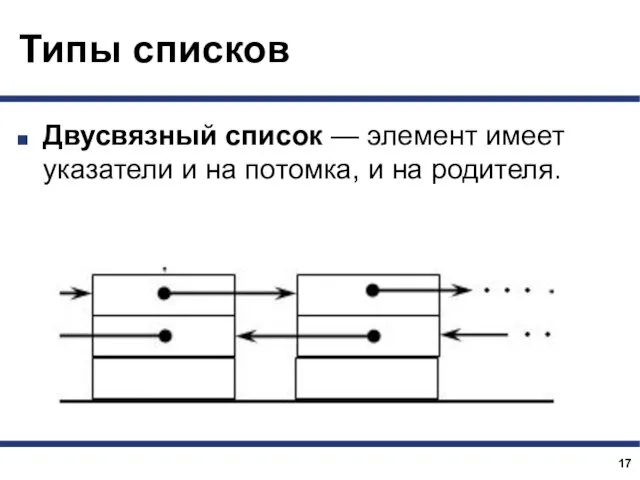
Типы списков
Двусвязный список — элемент имеет указатели и на потомка, и на родителя.
Типы списков
Двусвязный список — элемент имеет указатели и на потомка, и на родителя.
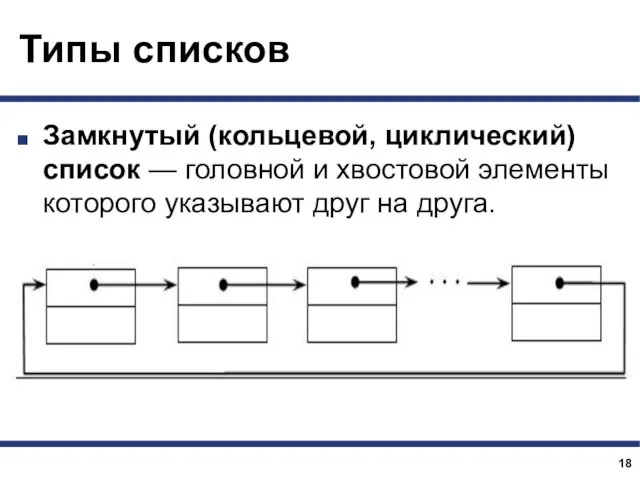
Типы списков
Замкнутый (кольцевой, циклический) список — головной и хвостовой элементы которого указывают
Типы списков
Замкнутый (кольцевой, циклический) список — головной и хвостовой элементы которого указывают
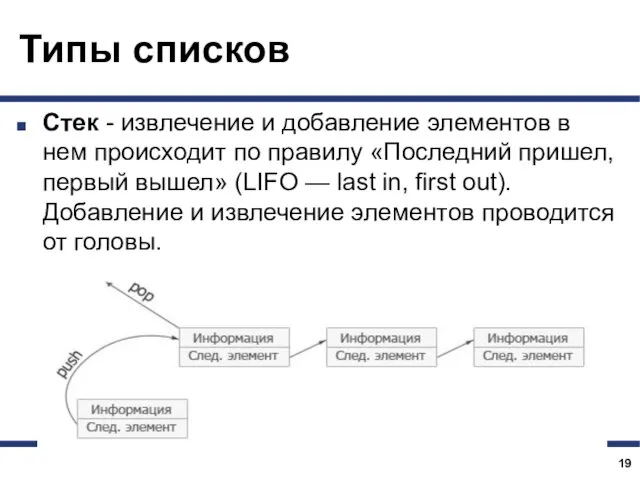
Типы списков
Стек - извлечение и добавление элементов в нем происходит по правилу
Типы списков
Стек - извлечение и добавление элементов в нем происходит по правилу
Типы списков
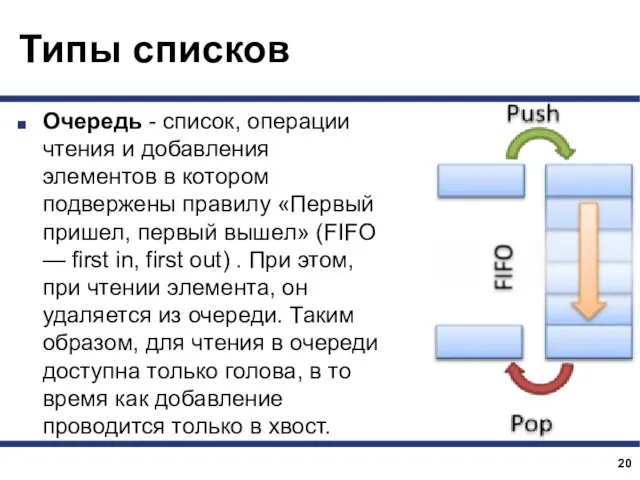
Очередь - список, операции чтения и добавления элементов в котором подвержены
Типы списков
Очередь - список, операции чтения и добавления элементов в котором подвержены

Достоинства
эффективное добавление и удаление элементов
размер ограничен только объёмом памяти компьютера и разрядностью указателей
динамическое
Достоинства
эффективное добавление и удаление элементов
размер ограничен только объёмом памяти компьютера и разрядностью указателей
динамическое

Недостатки
сложность прямого доступа к элементу, а именно определения физического адреса
Недостатки
сложность прямого доступа к элементу, а именно определения физического адреса

Односвязные линейные списки
Односвязные линейные списки

Односвязные списки
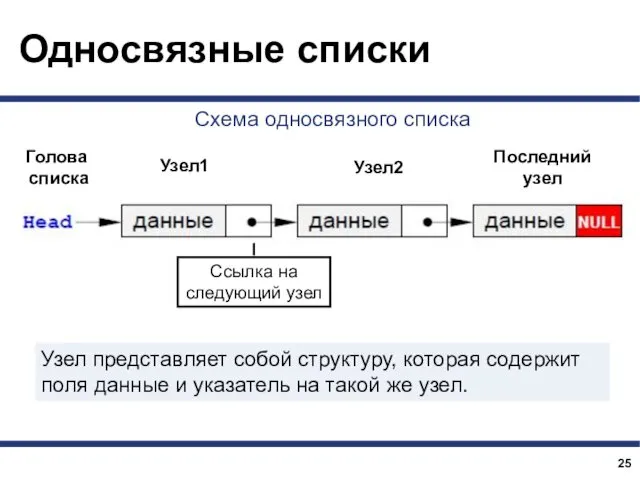
Односвязный линейный список – это динамический список, в котором каждый
Односвязные списки
Односвязный линейный список – это динамический список, в котором каждый
Односвязные списки
Узел представляет собой структуру, которая содержит поля данные и указатель
Односвязные списки
Узел представляет собой структуру, которая содержит поля данные и указатель
Односвязные списки
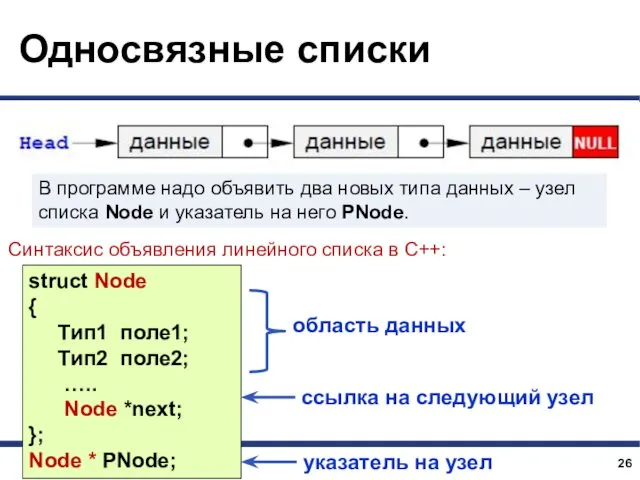
В программе надо объявить два новых типа данных – узел
Односвязные списки
В программе надо объявить два новых типа данных – узел
Односвязные списки
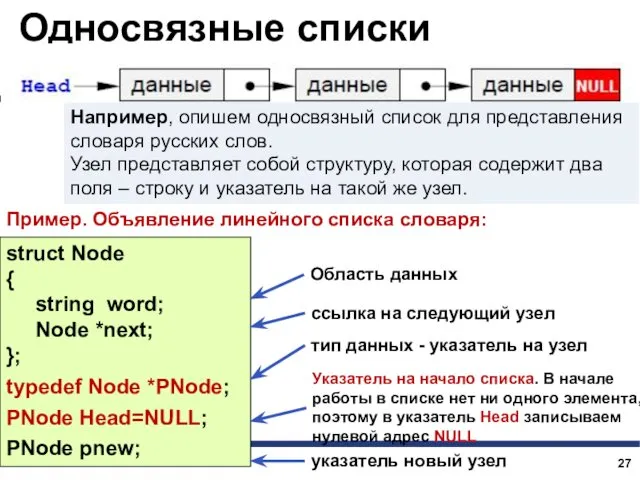
Например, опишем односвязный список для представления словаря русских слов.
Узел представляет
Односвязные списки
Например, опишем односвязный список для представления словаря русских слов.
Узел представляет

Односвязные списки. Операции
Операции над односвязными списками:
Создание нового узла.
Добавление узла:
В начало списка
В
Односвязные списки. Операции
Операции над односвязными списками:
Создание нового узла.
Добавление узла:
В начало списка
В

Создание нового узла
Для того, чтобы добавить узел к списку, необходимо создать
Создание нового узла
Для того, чтобы добавить узел к списку, необходимо создать

Добавление узла в начало списка
При добавлении нового узла NewNode в начало
Добавление узла в начало списка
При добавлении нового узла NewNode в начало

Добавление узла в начало списка
По такой схеме работает функция AddFirst. Предполагается,
Добавление узла в начало списка
По такой схеме работает функция AddFirst. Предполагается,
Добавление узла после заданного
Дан адрес NewNode нового узла и адрес p
Добавление узла после заданного
Дан адрес NewNode нового узла и адрес p

Добавление узла после заданного
По такой схеме работает функция AddAfter.
Передавать будем адрес
Добавление узла после заданного
По такой схеме работает функция AddAfter.
Передавать будем адрес
Добавление узла перед заданным
Эта схема добавления самая сложная. Проблема заключается в
Добавление узла перед заданным
Эта схема добавления самая сложная. Проблема заключается в

Добавление узла перед заданным
void AddBefore(PNode &Head, PNode p, PNode NewNode)
{
PNode q
Добавление узла перед заданным
void AddBefore(PNode &Head, PNode p, PNode NewNode)
{
PNode q
Добавление узла в конец списка
Для решения задачи надо сначала найти последний
Добавление узла в конец списка
Для решения задачи надо сначала найти последний

Добавление узла в конец списка
void AddLast(PNode &Head, PNode NewNode)
{
PNode q =
Добавление узла в конец списка
void AddLast(PNode &Head, PNode NewNode)
{
PNode q =

Проход по списку
PNode p = Head;
while ( p != NULL
Проход по списку
PNode p = Head;
while ( p != NULL
Поиск узла в списке
Часто требуется найти в списке нужный элемент (его
Поиск узла в списке
Часто требуется найти в списке нужный элемент (его

Поиск узла в списке
PNode Find (PNode Head, string NewWord)
{
PNode q
Поиск узла в списке
PNode Find (PNode Head, string NewWord)
{
PNode q

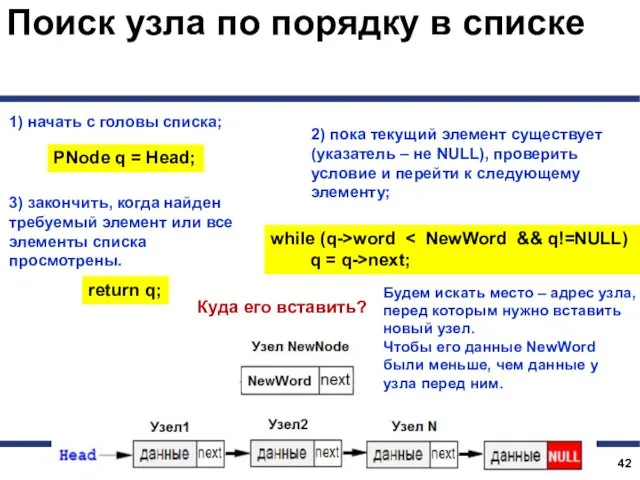
Поиск узла по порядку в списке
Вернемся к задаче построения алфавитного словаря.
Поиск узла по порядку в списке
Вернемся к задаче построения алфавитного словаря.
Поиск узла по порядку в списке
1) начать с головы списка;
2) пока
Поиск узла по порядку в списке
1) начать с головы списка;
2) пока

Поиск узла по порядку в списке
PNode FindPlace (PNode Head, string NewWord)
{
Поиск узла по порядку в списке
PNode FindPlace (PNode Head, string NewWord)
{

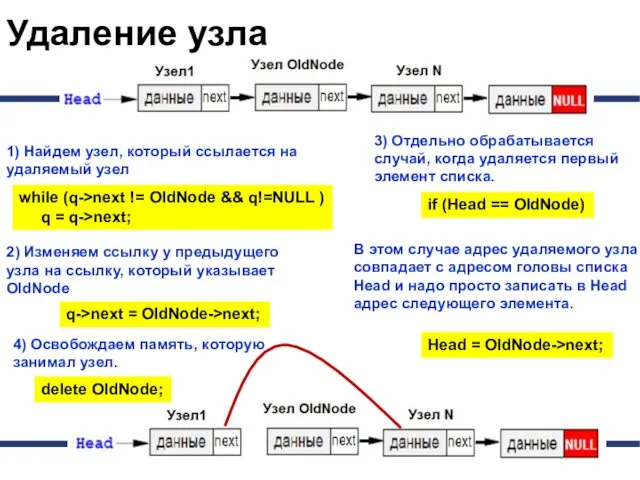
Удаление узла
Эта процедура также связана с поиском заданного узла по всему
Удаление узла
Эта процедура также связана с поиском заданного узла по всему
Удаление узла
1) Найдем узел, который ссылается на удаляемый узел
2) Изменяем
Удаление узла
1) Найдем узел, который ссылается на удаляемый узел
2) Изменяем

Удаление узла
void DeleteNode(PNode &Head, PNode OldNode)
{
PNode q = Head;
if (Head ==
Удаление узла
void DeleteNode(PNode &Head, PNode OldNode)
{
PNode q = Head;
if (Head ==

Пример программы на односвязный линейный список
Пример программы на односвязный линейный список

Пример. Односвязный список словарь
#include
#include
using namespace std;
// описание динамической
Пример. Односвязный список словарь
#include
#include
using namespace std;
// описание динамической

Пример (продолжение)
int main()
{
PNode Head = NULL;
PNode pnew, pfind;
Пример (продолжение)
int main()
{
PNode Head = NULL;
PNode pnew, pfind;

Пример (продолжение)
case 1 :
cout<<"введите новое слово = ";
cin>>newslovo;
pnew=CreateNode(newslovo); //создаем
Пример (продолжение)
case 1 :
cout<<"введите новое слово = ";
cin>>newslovo;
pnew=CreateNode(newslovo); //создаем

Спасибо за внимание!
Спасибо за внимание!
 Ideas about site. Dental laboratory
Ideas about site. Dental laboratory Разработка WPF приложений в стиле ViewModel First
Разработка WPF приложений в стиле ViewModel First Пространственная фильтрация, обработка в частотной области и восстановление изображения (Matlab)
Пространственная фильтрация, обработка в частотной области и восстановление изображения (Matlab) Концепция (архитектура) IMS. Как вписать архитектуру IMS в действующее регулирование
Концепция (архитектура) IMS. Как вписать архитектуру IMS в действующее регулирование Разработка аппаратно-программного комплекса имитации нестабильности напряжения в сетях постоянного тока
Разработка аппаратно-программного комплекса имитации нестабильности напряжения в сетях постоянного тока Поиск целевого трафика Вконтакте
Поиск целевого трафика Вконтакте Инфокоммуникационная сеть, как большая и сложная система
Инфокоммуникационная сеть, как большая и сложная система Java.SE.07 Multithreading
Java.SE.07 Multithreading Создание 3D пазл для детей младшего возраста
Создание 3D пазл для детей младшего возраста Dark-Wave
Dark-Wave Проектная тематика. Компьютерные технологии анализа данных и исследования статистических закономерностей и анализ больших данных
Проектная тематика. Компьютерные технологии анализа данных и исследования статистических закономерностей и анализ больших данных MNGT 1710 Course Resources
MNGT 1710 Course Resources Основы журналистики. Пражурналистика и формирование журналистики
Основы журналистики. Пражурналистика и формирование журналистики Создание 3D модели острова в программе Blender
Создание 3D модели острова в программе Blender Использование оборудования фирмы Iskratel для построения мультисервисных сетей
Использование оборудования фирмы Iskratel для построения мультисервисных сетей Язык UML. Диаграммы деятельности. Варианты использования
Язык UML. Диаграммы деятельности. Варианты использования PHP #1.1. Введение. Быстрый старт
PHP #1.1. Введение. Быстрый старт Разработка информационной системы для службы технической поддержки пользователей ЗАО Металлургприбор
Разработка информационной системы для службы технической поддержки пользователей ЗАО Металлургприбор SWIFT Professional Services I Alliance Lite2 Kick-off
SWIFT Professional Services I Alliance Lite2 Kick-off Операционные системы Windows от XP к 7
Операционные системы Windows от XP к 7 Программаларды өңдеудің аспаптың құралдары (ПӨАҚ)
Программаларды өңдеудің аспаптың құралдары (ПӨАҚ) Інформаційна зброя
Інформаційна зброя Способы кодирования информации
Способы кодирования информации TLS and SSL
TLS and SSL Информационная безопасность. Криптографические средства защиты данных
Информационная безопасность. Криптографические средства защиты данных Доставка терминалов. Собственный процессинг
Доставка терминалов. Собственный процессинг Введение в R
Введение в R Корпоративные информационные системы. Информационные технологии и системы в менеджменте. Тема 1
Корпоративные информационные системы. Информационные технологии и системы в менеджменте. Тема 1