- Интеграция данных

Содержание
- 2. Проблема: исходные данные – в источниках с различными моделями и представлением данных, в файлах различных форматов
- 3. Важнейший этап подготовки данных к анализу – их интеграция из множества разнородных источников в один источник,
- 4. Интеграция данных – это процесс объединения данных, находящихся в различных разнородных источниках, в единственном физическом источнике
- 5. Интеграция данных в едином источнике
- 6. Интеграция данных без физического объединения
- 7. Под источником данных в контексте рассматриваемых технологий понимается объект, содержащий структурированные данные. Замечание. Если данные в
- 8. Уровни интеграции данных Физический уровень. Данные из различных источников преобразуются к единому формату и сохраняются в
- 9. Семантический подход к интеграции Учитывает содержательную (контекстную) сторону данных. Семантическая интеграция основывается на учете природы данных.
- 10. Такие дополнительные сведения называются метаданными («данными о данных»). С помощью метаданных формируется семантический слой, который делает
- 11. Способы интеграции данных Виртуальный. Реализуется с помощью механизма доступа: при выполнении запроса пользователя формируется требуемое представление
- 12. Быстрые и медленные данные Поступают непрерывно; являются сильно детализированными (отражают элементарные события в жизни бизнеса). Отражают
- 13. В бизнес-аналитике могут использоваться как быстрые, так и медленные данные. При использовании быстрых данных задачи бизнес-аналитики
- 14. Разные цели и задачи работы с быстрыми и медленными данными формирование двух классов ИС: системы оперативного
- 15. Системы оперативного анализа OLTP ( On-Line Transaction Processing ) – оперативная (т. е. в режиме реального
- 16. Обобщенная схема движения данных в транзакционной системе: Исключение любой из операций приведет к тому, что связанная
- 17. Пример. В системе бронирования авиабилетов: запрос оператора о наличии свободных мест на рейс; ответ системы с
- 18. Транзакции в СМО выполняются десятки и сотни тысяч раз в день в огромном количестве терминалов, пунктов
- 19. Особенности OLTP-систем: запросы и отчеты являются строго регламентированными (т. к. цель – точное выполнение бизнес-функции); оператор
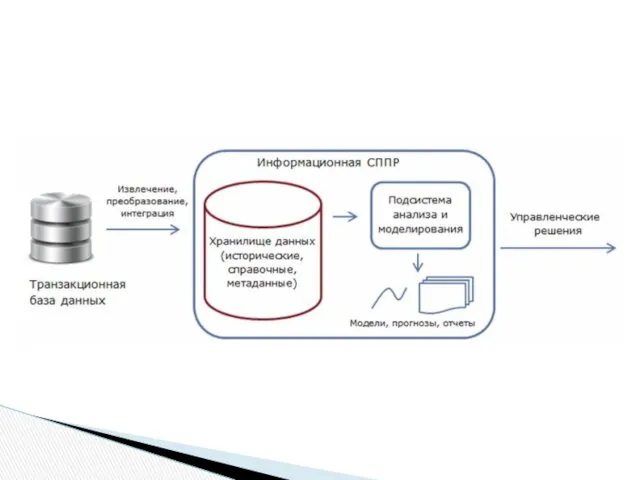
- 20. СППР В процессе эксплуатации OLTP-систем – понимание: если транзакционные данные, наколенные в OLTP-системах, не уничтожать после
- 21. Требование к СППР: возможность получения ответов на нерегламентированные запросы аналитика. Например: как изменялась динамика визитов покупателей
- 22. Вопрос: оптимальна ли OLTP-система, ориентированная на максимально быстрое выполнение простейших запросов, с точки зрения реализации аналитических
- 24. Требования к организации хранения данных в СППР: для выполнения нерегламентированных запросов необходима обработка массивов данных из
- 25. Прежде, чем подвергаться анализу, данные должны пройти подготовку, включающую извлечение и объединение данных из множества разнородных
- 26. Современная тенденция – комплексное решение задач подготовки данных в системах бизнес-аналитики. В частности, аудит, очистка и
- 27. Типы корпоративных данных
- 28. Фактографические – это данные, отражающие факты, которые описывают процессы, объекты и явления предметной области. Факт (наблюдение,
- 29. Нормативно-справочные данные включают различные словари (например, терминологические), справочники (адресов, телефонов и т. п.), классификаторы (ОКПО, ОКАТО),
- 30. Метаданные («данные о данных») – разновидность данных, носящих служебный характер. Они не отражают течение бизнес-процессов компании,
- 31. Виды метаданных: технические – обеспечивают функционирование баз данных и выполнение запросов к ним; бизнес-метаданные определяют сущности,
- 32. Первичные источники данных Первичными называются источники, данные в которых являются результатом непосредственной регистрации и измерения характеристик
- 33. Виды первичных источников данных. Транзакционные системы и БД. Унаследованные системы. Системы, реализованные на основе устаревших технологий,
- 34. Вторичные источники данных Вторичными называются источники, которые получают данные не в процессе их сбора или регистрации,
- 35. Виды вторичных источников данных. Область временного хранения. Используется для промежуточной обработки (очистки, трансформации) и синхронизации данных
- 36. ETL – комплекс программно-аппаратных средств, реализующий извлечение данных из различных источников; преобразование их к единому формату
- 37. Вариант структуры процессов ETL
- 38. «Тонкое место» – преобразование данных в зоне временного хранения: вычислительные затраты при увеличении объема извлекаемых данных
- 39. Решением проблемы может быть перенос большей части ETL-операций из зоны временного хранения в интегрированный источник: данные
- 40. Вариант структуры процессов ELT
- 41. Преимущества такого решения: сокращение времени между извлечением данных и загрузкой в ХД; данные поступают в ХД,
- 42. Качество данных – ключевой фактор обеспечения корректных и практически полезных результатов. При этом: факторы, вызывающие низкое
- 43. Полнота данных – все данные, связанные с некоторым бизнес-процессом, собраны и представлены в полном объеме (отсутствуют
- 44. Непротиворечивость – связана с пониманием данных. Например: таблицы, содержащие данные о различных бизнес-объектах, могут иметь одинаковые
- 45. Наиболее эффективный подход к обеспечению качества данных – организация потока соответствующих работ параллельно основному потоку, связанному
- 46. В процессе ETL – как элемент подготовки данных к интеграции. В консолидированных источниках – как элемент
- 47. Уровни очистки данных
- 48. 3. Аудит и профайлинг данных (основные понятия)
- 49. Процедуры, связанные с обеспечением качества данных, выполняются в рамках специального бизнес-процесса, называемого аудитом качества данных. Аудит
- 50. Профайлинг данных – процесс изучения данных с целью понимания их структуры, содержимого и оценки качества. Аудит
- 51. Обычно включает в себя следующие этапы: структурный анализ – проверку целостности таблиц данных (может быть нарушена
- 52. В Data Mining наиболее востребованы следующие задачи: общая статистика по выборке; обнаружение пропусков; обнаружение выбросов и
- 53. Наиболее предпочтительный подход к организации процесса: обработка наиболее очевидных проблем перед загрузкой данных в единый интегрированный
- 54. В соответствии с этим – два вида профайлинга: внешний (выполняется до загрузки в единый интегрированный источник);
- 55. Формируется для того, чтобы пользователь мог разработать правильную стратегию предварительной обработки данных. Такой отчет обычно содержит
- 56. Отчет по результатам профайлинга данных
- 57. Обычно включает следующие характеристики: минимальное и максимальное значения; среднее; медиана; среднеквадратичное отклонение; сумма и квадратичная сумма
- 58. Гистограмма распределения значений поля позволяет определить характер факторов, снижающих качество данных; выбрать лучший метод предварительной обработки
- 59. Индикаторы качества данных – это показатели, характеризующие качество набора данных в целом. Примеры. Доля записей, не
- 60. Примеры. Отношение числа записей набора данных к числу столбцов (наблюдений на предиктор, Evidence per Value –
- 61. Контроль очевидного несоответствия данных в логически связанных полях. Выполняется с помощью некоторых правил. Примеры правил: возраст
- 62. Красным цветом выделены номера строк с несоответствиями данных в связанных полях. Взаимные проверки
- 63. Под сложными ошибками обычно понимают такие, которые невозможно выявить без привлечения знаний об особенностях и логике
- 65. Скачать презентацию

Проблема:
исходные данные – в источниках с различными моделями и представлением данных,
Проблема:
исходные данные – в источниках с различными моделями и представлением данных,

Важнейший этап подготовки данных к анализу – их интеграция из множества
Важнейший этап подготовки данных к анализу – их интеграция из множества

Интеграция данных – это процесс объединения данных, находящихся в различных разнородных
Интеграция данных – это процесс объединения данных, находящихся в различных разнородных
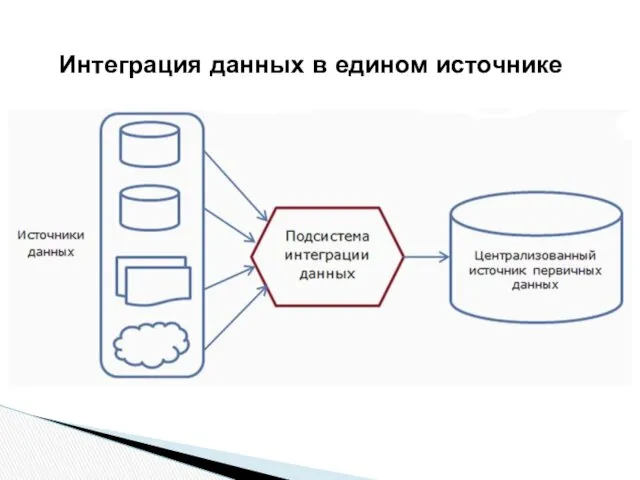
Интеграция данных в едином источнике
Интеграция данных в едином источнике
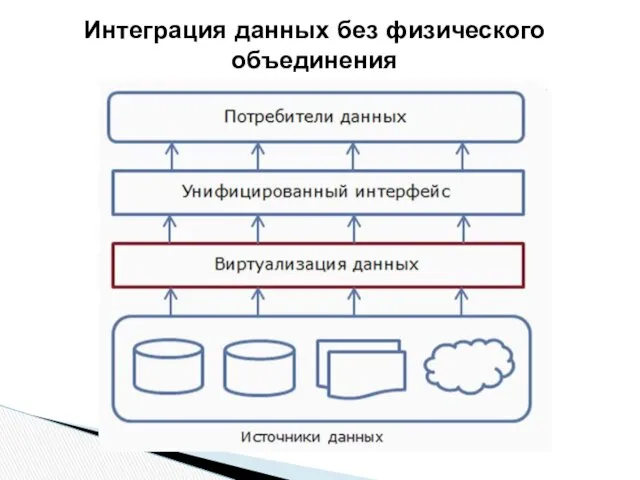
Интеграция данных без физического объединения
Интеграция данных без физического объединения

Под источником данных в контексте рассматриваемых технологий понимается объект, содержащий структурированные
Под источником данных в контексте рассматриваемых технологий понимается объект, содержащий структурированные

Уровни интеграции данных
Физический уровень.
Данные из различных источников преобразуются к единому формату
Уровни интеграции данных
Физический уровень.
Данные из различных источников преобразуются к единому формату

Семантический подход к интеграции
Учитывает содержательную (контекстную) сторону данных.
Семантическая интеграция основывается на
Семантический подход к интеграции
Учитывает содержательную (контекстную) сторону данных.
Семантическая интеграция основывается на

Такие дополнительные сведения называются метаданными («данными о данных»).
С помощью метаданных формируется
Такие дополнительные сведения называются метаданными («данными о данных»).
С помощью метаданных формируется

Способы интеграции данных
Виртуальный.
Реализуется с помощью механизма доступа: при выполнении запроса пользователя
Способы интеграции данных
Виртуальный.
Реализуется с помощью механизма доступа: при выполнении запроса пользователя
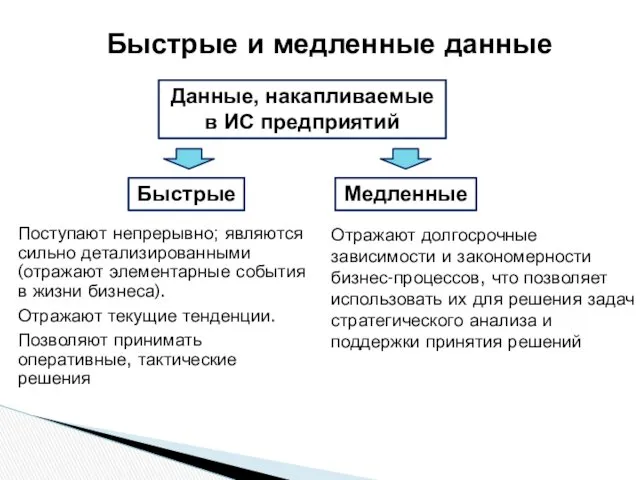
Быстрые и медленные данные
Поступают непрерывно; являются сильно детализированными (отражают элементарные события
Быстрые и медленные данные
Поступают непрерывно; являются сильно детализированными (отражают элементарные события

В бизнес-аналитике могут использоваться как быстрые, так и медленные данные.
При
В бизнес-аналитике могут использоваться как быстрые, так и медленные данные.
При
Разные цели и задачи работы с быстрыми и медленными данными
формирование двух
Разные цели и задачи работы с быстрыми и медленными данными
формирование двух

Системы оперативного анализа
OLTP ( On-Line Transaction Processing ) – оперативная (т.
Системы оперативного анализа
OLTP ( On-Line Transaction Processing ) – оперативная (т.
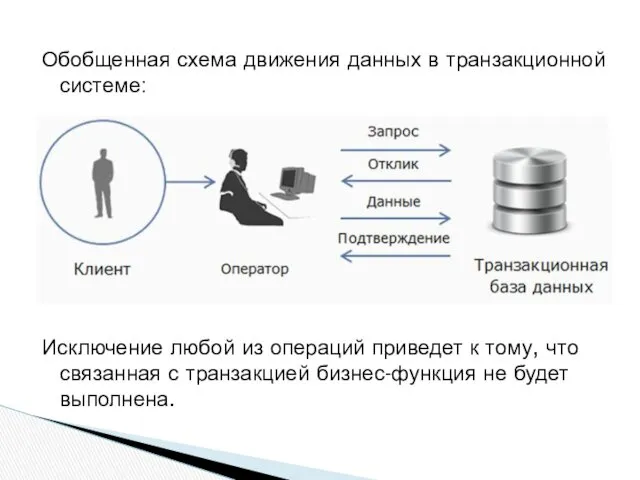
Обобщенная схема движения данных в транзакционной системе:
Исключение любой из операций приведет
Обобщенная схема движения данных в транзакционной системе:
Исключение любой из операций приведет

Пример.
В системе бронирования авиабилетов:
запрос оператора о наличии свободных мест на рейс;
ответ
Пример.
В системе бронирования авиабилетов:
запрос оператора о наличии свободных мест на рейс;
ответ

Транзакции в СМО выполняются десятки и сотни тысяч раз в день
Транзакции в СМО выполняются десятки и сотни тысяч раз в день

Особенности OLTP-систем:
запросы и отчеты являются строго регламентированными (т. к. цель
Особенности OLTP-систем:
запросы и отчеты являются строго регламентированными (т. к. цель

СППР
В процессе эксплуатации OLTP-систем – понимание:
если транзакционные данные, наколенные в OLTP-системах,
СППР
В процессе эксплуатации OLTP-систем – понимание:
если транзакционные данные, наколенные в OLTP-системах,

Требование к СППР:
возможность получения ответов на нерегламентированные запросы аналитика.
Например: как изменялась
Требование к СППР:
возможность получения ответов на нерегламентированные запросы аналитика.
Например: как изменялась
Вопрос:
оптимальна ли OLTP-система, ориентированная на максимально быстрое выполнение простейших запросов, с
Вопрос:
оптимальна ли OLTP-система, ориентированная на максимально быстрое выполнение простейших запросов, с

Требования к организации хранения данных в СППР:
для выполнения нерегламентированных запросов необходима
Требования к организации хранения данных в СППР:
для выполнения нерегламентированных запросов необходима

Прежде, чем подвергаться анализу, данные должны пройти подготовку, включающую
извлечение и объединение
Прежде, чем подвергаться анализу, данные должны пройти подготовку, включающую
извлечение и объединение

Современная тенденция – комплексное решение задач подготовки данных в системах бизнес-аналитики.
В
Современная тенденция – комплексное решение задач подготовки данных в системах бизнес-аналитики.
В
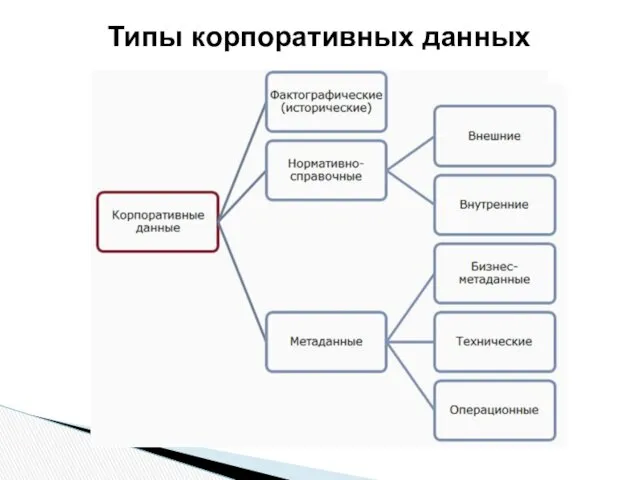
Типы корпоративных данных
Типы корпоративных данных

Фактографические – это данные, отражающие факты, которые описывают процессы, объекты
Фактографические – это данные, отражающие факты, которые описывают процессы, объекты

Нормативно-справочные данные включают различные словари (например, терминологические), справочники (адресов, телефонов
Нормативно-справочные данные включают различные словари (например, терминологические), справочники (адресов, телефонов

Метаданные («данные о данных») – разновидность данных, носящих служебный характер.
Они
Метаданные («данные о данных») – разновидность данных, носящих служебный характер.
Они

Виды метаданных:
технические – обеспечивают функционирование баз данных и выполнение запросов к
Виды метаданных:
технические – обеспечивают функционирование баз данных и выполнение запросов к

Первичные источники данных
Первичными называются источники, данные в которых являются результатом непосредственной
Первичные источники данных
Первичными называются источники, данные в которых являются результатом непосредственной

Виды первичных источников данных.
Транзакционные системы и БД.
Унаследованные системы.
Системы, реализованные на основе
Виды первичных источников данных.
Транзакционные системы и БД.
Унаследованные системы.
Системы, реализованные на основе

Вторичные источники данных
Вторичными называются источники, которые получают данные не в процессе
Вторичные источники данных
Вторичными называются источники, которые получают данные не в процессе

Виды вторичных источников данных.
Область временного хранения.
Используется для промежуточной обработки (очистки, трансформации)
Виды вторичных источников данных.
Область временного хранения.
Используется для промежуточной обработки (очистки, трансформации)

ETL – комплекс программно-аппаратных средств, реализующий
извлечение данных из различных источников;
преобразование их
ETL – комплекс программно-аппаратных средств, реализующий
извлечение данных из различных источников;
преобразование их
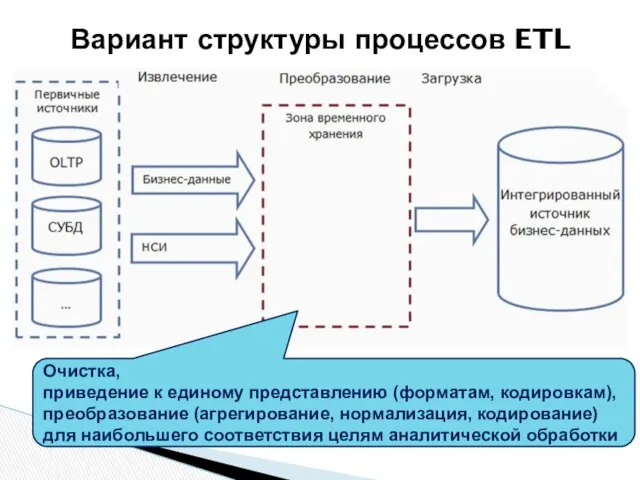
Вариант структуры процессов ETL
Вариант структуры процессов ETL

«Тонкое место» – преобразование данных в зоне временного хранения:
вычислительные затраты при
«Тонкое место» – преобразование данных в зоне временного хранения:
вычислительные затраты при

Решением проблемы может быть перенос большей части ETL-операций из зоны временного
Решением проблемы может быть перенос большей части ETL-операций из зоны временного
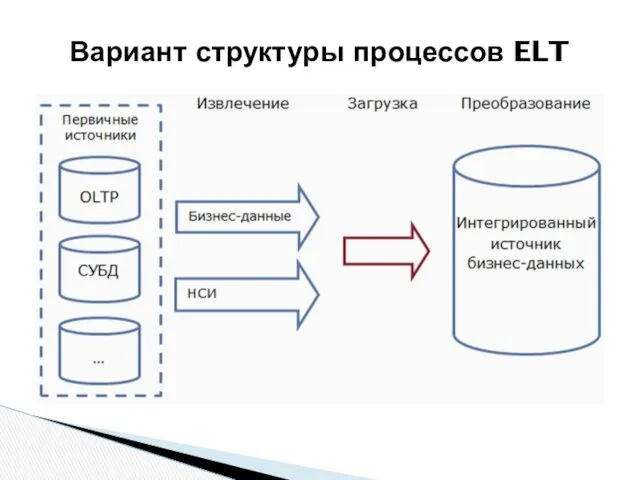
Вариант структуры процессов ELT
Вариант структуры процессов ELT

Преимущества такого решения:
сокращение времени между извлечением данных и загрузкой в ХД;
данные
Преимущества такого решения:
сокращение времени между извлечением данных и загрузкой в ХД;
данные

Качество данных – ключевой фактор обеспечения корректных и практически полезных результатов.
При
Качество данных – ключевой фактор обеспечения корректных и практически полезных результатов.
При

Полнота данных – все данные, связанные с некоторым бизнес-процессом, собраны и
Полнота данных – все данные, связанные с некоторым бизнес-процессом, собраны и

Непротиворечивость – связана с пониманием данных.
Например: таблицы, содержащие данные о
Непротиворечивость – связана с пониманием данных.
Например: таблицы, содержащие данные о
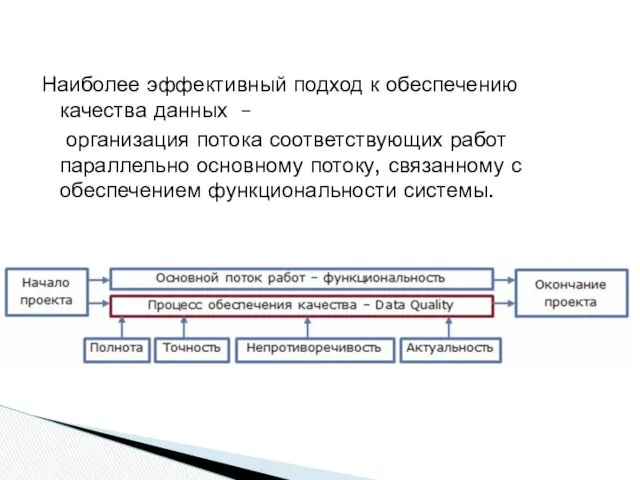
Наиболее эффективный подход к обеспечению качества данных –
организация потока соответствующих
Наиболее эффективный подход к обеспечению качества данных –
организация потока соответствующих

В процессе ETL – как элемент подготовки данных к интеграции.
В консолидированных
В процессе ETL – как элемент подготовки данных к интеграции.
В консолидированных
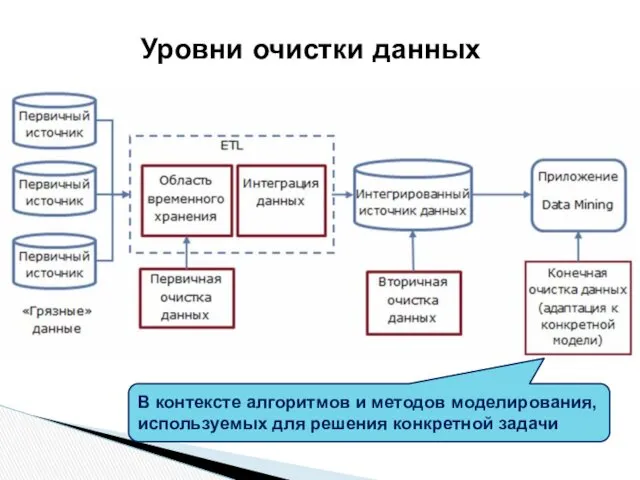
Уровни очистки данных
Уровни очистки данных

3. Аудит и профайлинг данных (основные понятия)
3. Аудит и профайлинг данных (основные понятия)

Процедуры, связанные с обеспечением качества данных, выполняются в рамках специального бизнес-процесса,
Процедуры, связанные с обеспечением качества данных, выполняются в рамках специального бизнес-процесса,

Профайлинг данных – процесс изучения данных с целью понимания их структуры,
Профайлинг данных – процесс изучения данных с целью понимания их структуры,

Обычно включает в себя следующие этапы:
структурный анализ – проверку целостности таблиц
Обычно включает в себя следующие этапы:
структурный анализ – проверку целостности таблиц

В Data Mining наиболее востребованы следующие задачи:
общая статистика по выборке;
обнаружение
В Data Mining наиболее востребованы следующие задачи:
общая статистика по выборке;
обнаружение
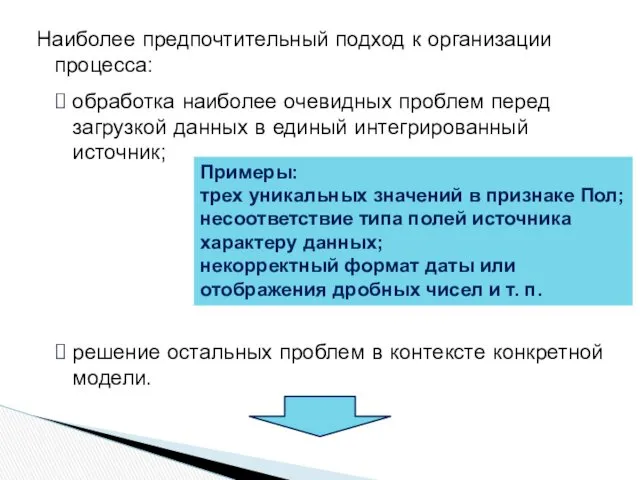
Наиболее предпочтительный подход к организации процесса:
обработка наиболее очевидных проблем перед загрузкой
Наиболее предпочтительный подход к организации процесса:
обработка наиболее очевидных проблем перед загрузкой
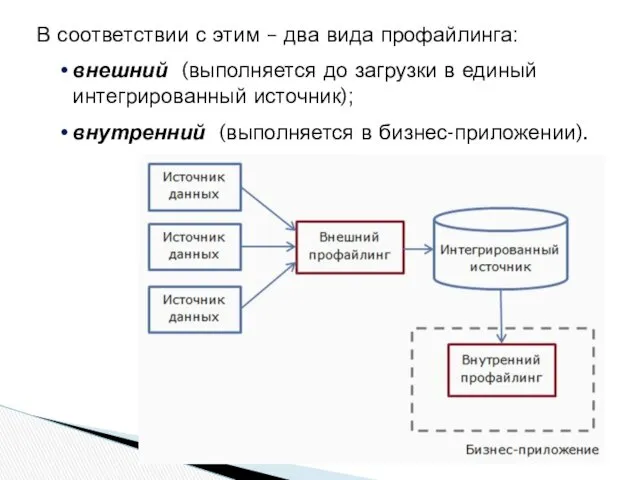
В соответствии с этим – два вида профайлинга:
внешний (выполняется до загрузки
В соответствии с этим – два вида профайлинга:
внешний (выполняется до загрузки

Формируется для того, чтобы пользователь мог разработать правильную стратегию предварительной обработки
Формируется для того, чтобы пользователь мог разработать правильную стратегию предварительной обработки
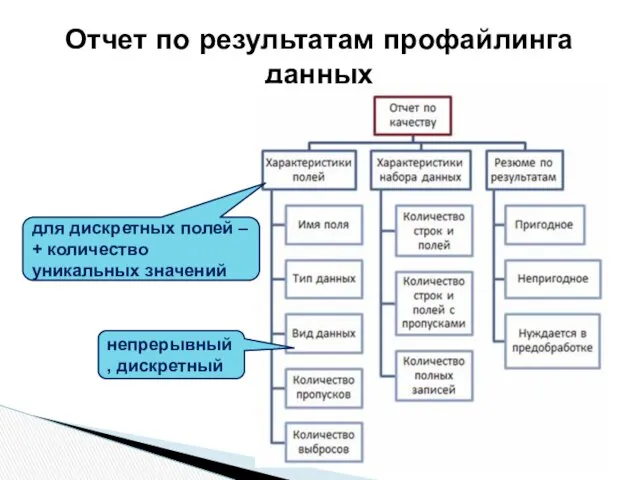
Отчет по результатам профайлинга данных
Отчет по результатам профайлинга данных

Обычно включает следующие характеристики:
минимальное и максимальное значения;
среднее;
медиана;
среднеквадратичное отклонение;
сумма и квадратичная
Обычно включает следующие характеристики:
минимальное и максимальное значения;
среднее;
медиана;
среднеквадратичное отклонение;
сумма и квадратичная
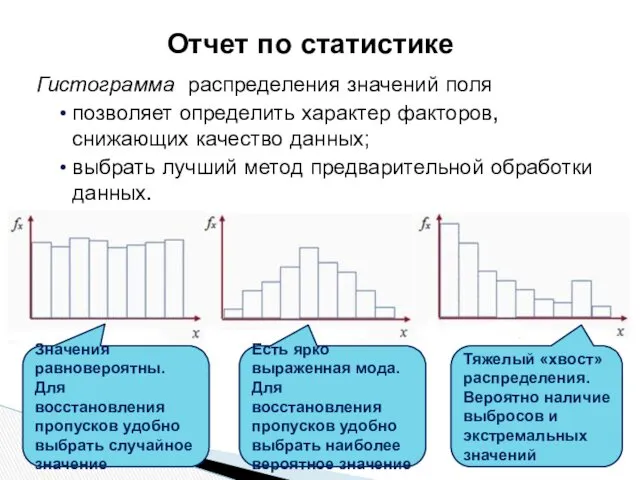
Гистограмма распределения значений поля
позволяет определить характер факторов, снижающих качество данных;
выбрать лучший
Гистограмма распределения значений поля
позволяет определить характер факторов, снижающих качество данных;
выбрать лучший

Индикаторы качества данных – это показатели, характеризующие качество набора данных в
Индикаторы качества данных – это показатели, характеризующие качество набора данных в

Примеры.
Отношение числа записей набора данных к числу столбцов (наблюдений на предиктор,
Примеры.
Отношение числа записей набора данных к числу столбцов (наблюдений на предиктор,

Контроль очевидного несоответствия данных в логически связанных полях. Выполняется с помощью
Контроль очевидного несоответствия данных в логически связанных полях. Выполняется с помощью
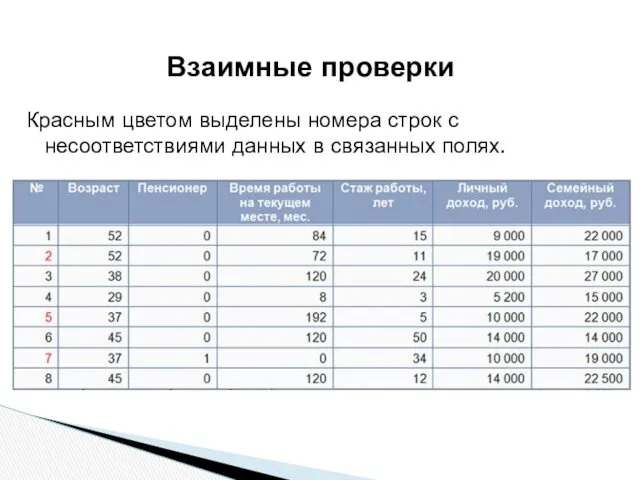
Красным цветом выделены номера строк с несоответствиями данных в связанных полях.
Взаимные
Красным цветом выделены номера строк с несоответствиями данных в связанных полях.
Взаимные

Под сложными ошибками обычно понимают такие, которые невозможно выявить без привлечения
Под сложными ошибками обычно понимают такие, которые невозможно выявить без привлечения
 Все про блогерство від А до Я
Все про блогерство від А до Я Проблемы использования нейронных сетей в строительстве
Проблемы использования нейронных сетей в строительстве Эффективная презентация
Эффективная презентация E-publishing versus paper publishing
E-publishing versus paper publishing Изкуствен интелект
Изкуствен интелект Алгоритм
Алгоритм Списки. Способы создания и считывания списков
Списки. Способы создания и считывания списков Что можно выбрать в компьютерном меню школьной столовой
Что можно выбрать в компьютерном меню школьной столовой Основы HTML. Создание сайтов в текстовом редакторе
Основы HTML. Создание сайтов в текстовом редакторе Кодирование сообщений, коды Фано, Шеннона и Хаффмана
Кодирование сообщений, коды Фано, Шеннона и Хаффмана Операционная система Windows
Операционная система Windows Transonic Flow Over a NACA 0012 Airfoil
Transonic Flow Over a NACA 0012 Airfoil Моделирование как метод познания. Информатика. 9 класс
Моделирование как метод познания. Информатика. 9 класс Спільне використання ресурсів локальної мережі
Спільне використання ресурсів локальної мережі Компонент Таймер
Компонент Таймер Введение в системное программирование. Лекция 1
Введение в системное программирование. Лекция 1 Информационные сети и телекоммуникации
Информационные сети и телекоммуникации Устройство персонального компьютера
Устройство персонального компьютера Концепции MRP, MRP II, ERP
Концепции MRP, MRP II, ERP Указатели. Использование указателей. Динамическая память. Лекция 3
Указатели. Использование указателей. Динамическая память. Лекция 3 Основы языка СИ++
Основы языка СИ++ Исследование безопасности беспроводных точек доступа
Исследование безопасности беспроводных точек доступа This is your presentation title
This is your presentation title 12 беспроигрышных приёмов и типичные ошибки + ЛИД
12 беспроигрышных приёмов и типичные ошибки + ЛИД Системи управління базами даних: основи побудови та моделі організації
Системи управління базами даних: основи побудови та моделі організації Измерение информации. Содержательный (вероятностный) подход
Измерение информации. Содержательный (вероятностный) подход Основы тестирования
Основы тестирования Язык программирования С. Типы данных. Приведение типов. (Лекция 4)
Язык программирования С. Типы данных. Приведение типов. (Лекция 4)