- Intro to Machine Learning. Lecture 7

Содержание
- 2. Recap Decision Trees (in class) for classification Using categorical predictors Using classification error as our metric
- 3. Impurity Measures: Covered in Lab last Week Node impurity measures for two-class classification, as a function
- 4. Practice Yourself For each criteria, solve to figure out which split will it favor.
- 5. Today’s Objectives Overfitting in Decision Trees (Tree Pruning) Ensemble Learning ( combine the power of multiple
- 6. Overfitting in Decision Trees
- 7. Decision Boundaries at Different Depths
- 8. Generally Speaking
- 9. Decision Tree Over fitting on Real Data
- 10. Simple is Better When two trees have the same classification error on validation set, choose the
- 11. Modified Tree Learning Problem
- 12. Finding Simple Trees Early Stopping: Stop learning before the tree becomes too complex Pruning: Simplify tree
- 13. Criteria 1 for Early Stopping Limit the depth: stop splitting after max_depth is reached
- 14. Criteria 2 for Early Stopping
- 15. Criteria 3 for Early Stopping
- 16. Early Stopping: Summary
- 17. Pruning To simplify a tree, we need to define what do we mean by simplicity of
- 18. Which Tree is Simpler?
- 19. Which Tree is Simpler
- 20. Thus, Our Measure of Complexity
- 21. New Optimization Goal Total Cost = Measure of Fit + Measure of Complexity Measure of Fit
- 22. Tree Pruning Algorithm Let T be the final tree Start at the bottom of T and
- 23. prune_split
- 24. Ensemble Learning
- 25. Bias and Variance A complex model could exhibit high variance A simple model could exhibit high
- 26. Ensemble Classifier in General
- 27. Ensemble Classifier in General
- 28. Ensemble Classifier in General
- 29. Important A necessary and sufficient condition for an ensemble of classifiers to be more accurate than
- 30. Bagging: Reducing Variance using An Ensemble of Classifiers from Bootstrap Samples
- 31. Aside: Bootstrapping Creating new datasets from the training data with replacement
- 32. Training Set Voting Bootstrap Samples Classifiers Predictions Final Prediction New Data Bagging
- 33. Why Bagging Works?
- 34. Bagging Summary Bagging was first proposed by Leo Breiman in a technical report in 1994 He
- 35. Random Forests – Example of Bagging
- 36. Making a Prediction
- 37. Boosting: Converting Weak Learners to Strong Learners through Ensemble Learning
- 38. Boosting and Bagging Works in a similar way as bagging. Except: Models are built sequentially: each
- 39. Boosting: (1) Train A Classifier
- 40. Boosting: (2) Train Next Classifier by Focusing More on the Hard Points
- 41. What does it mean to focus more?
- 42. Example (Unweighted): Learning a Simple Decision Stump
- 43. Example (Weighted): Learning a Decision Stump on Weighted Data
- 44. Boosting
- 45. AdaBoost (Example of Boosting) Weight of the model New weights of the data points
- 47. Weighted Classification Error
- 48. AdaBoost: Computing Classifier’s Weights
- 49. AdaBoost
- 51. AdaBoost: Recomputing A Sample’s Weight Increase, Decrease, or Keep the Same
- 52. AdaBoost: Recomputing A Sample’s Weight
- 53. AdaBoost
- 54. AdaBoost: Normalizing Sample Weights
- 55. AdaBoost
- 56. Self Study What is the effect of of: Increasing the number of classifiers in bagging vs.
- 57. Boosting Summary
- 59. Скачать презентацию

Recap
Decision Trees (in class)
for classification
Using categorical predictors
Using classification error as our
Recap
Decision Trees (in class)
for classification
Using categorical predictors
Using classification error as our
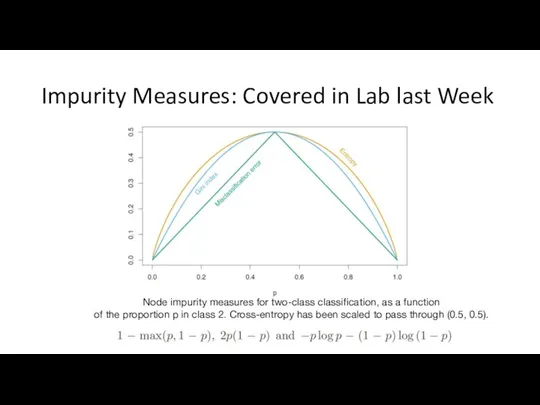
Impurity Measures: Covered in Lab last Week
Node impurity measures for two-class
Impurity Measures: Covered in Lab last Week
Node impurity measures for two-class

Practice Yourself
For each criteria, solve to figure out which split will
Practice Yourself
For each criteria, solve to figure out which split will

Today’s Objectives
Overfitting in Decision Trees (Tree Pruning)
Ensemble Learning ( combine the
Today’s Objectives
Overfitting in Decision Trees (Tree Pruning)
Ensemble Learning ( combine the

Overfitting in Decision Trees
Overfitting in Decision Trees
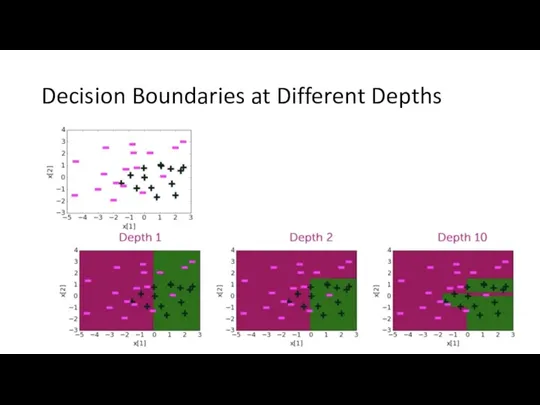
Decision Boundaries at Different Depths
Decision Boundaries at Different Depths

Generally Speaking
Generally Speaking
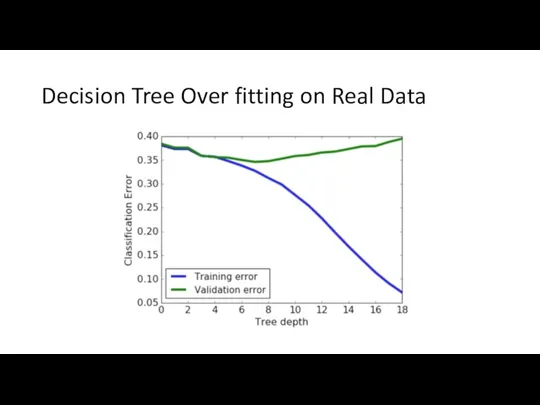
Decision Tree Over fitting on Real Data
Decision Tree Over fitting on Real Data

Simple is Better
When two trees have the same classification error on
Simple is Better
When two trees have the same classification error on

Modified Tree Learning Problem
Modified Tree Learning Problem

Finding Simple Trees
Early Stopping: Stop learning before the tree becomes too
Finding Simple Trees
Early Stopping: Stop learning before the tree becomes too
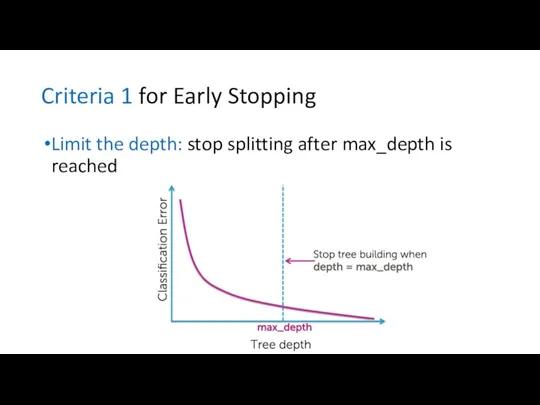
Criteria 1 for Early Stopping
Limit the depth: stop splitting after
Criteria 1 for Early Stopping
Limit the depth: stop splitting after
Criteria 2 for Early Stopping
Criteria 2 for Early Stopping
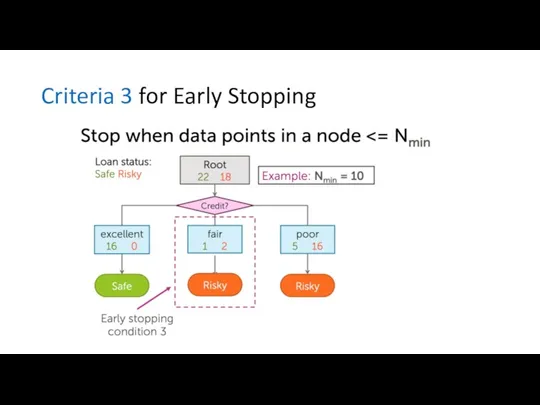
Criteria 3 for Early Stopping
Criteria 3 for Early Stopping

Early Stopping: Summary
Early Stopping: Summary
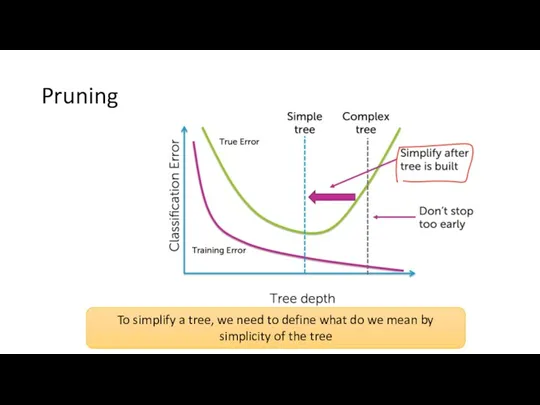
Pruning
To simplify a tree, we need to define what do we
Pruning
To simplify a tree, we need to define what do we
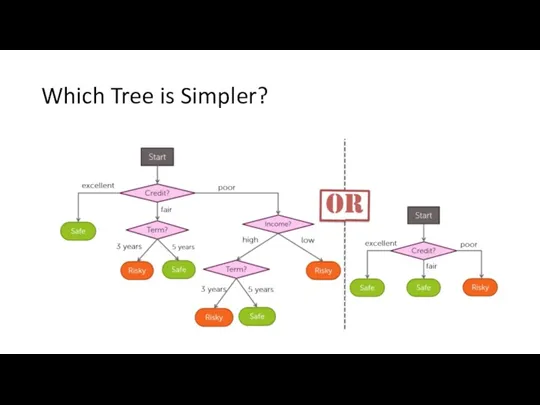
Which Tree is Simpler?
Which Tree is Simpler?
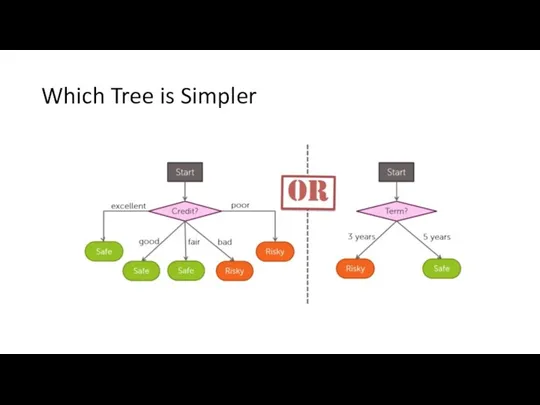
Which Tree is Simpler
Which Tree is Simpler
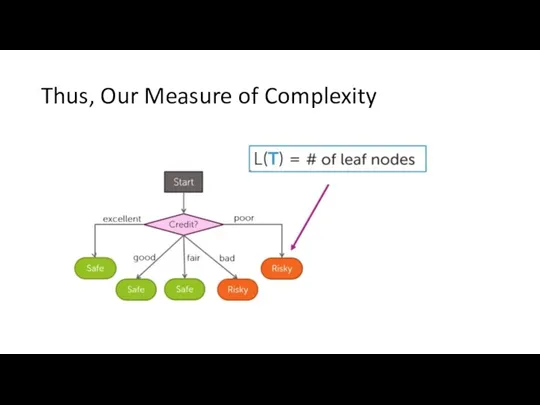
Thus, Our Measure of Complexity
Thus, Our Measure of Complexity

New Optimization Goal
Total Cost = Measure of Fit + Measure of
New Optimization Goal
Total Cost = Measure of Fit + Measure of

Tree Pruning Algorithm
Let T be the final tree
Start at the bottom
Tree Pruning Algorithm
Let T be the final tree
Start at the bottom

prune_split
prune_split

Ensemble Learning
Ensemble Learning

Bias and Variance
A complex model could exhibit high variance
A simple model
Bias and Variance
A complex model could exhibit high variance
A simple model

Ensemble Classifier in General
Ensemble Classifier in General

Ensemble Classifier in General
Ensemble Classifier in General

Ensemble Classifier in General
Ensemble Classifier in General

Important
A necessary and sufficient condition for an ensemble of classifiers to
Important
A necessary and sufficient condition for an ensemble of classifiers to

Bagging: Reducing Variance using An Ensemble of Classifiers from Bootstrap Samples
Bagging: Reducing Variance using An Ensemble of Classifiers from Bootstrap Samples

Aside: Bootstrapping
Creating new datasets from the training data with replacement
Aside: Bootstrapping
Creating new datasets from the training data with replacement
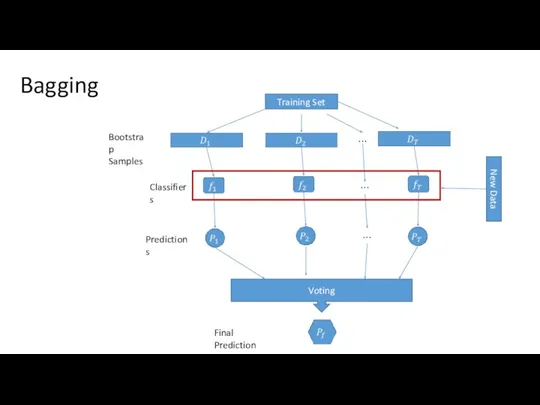
Training Set
Voting
Bootstrap
Samples
Classifiers
Predictions
Final Prediction
New Data
Bagging
Training Set
Voting
Bootstrap
Samples
Classifiers
Predictions
Final Prediction
New Data
Bagging

Why Bagging Works?
Why Bagging Works?

Bagging Summary
Bagging was first proposed by Leo Breiman in a technical
Bagging Summary
Bagging was first proposed by Leo Breiman in a technical

Random Forests – Example of Bagging
Random Forests – Example of Bagging

Making a Prediction
Making a Prediction

Boosting: Converting Weak Learners to Strong Learners through Ensemble Learning
Boosting: Converting Weak Learners to Strong Learners through Ensemble Learning

Boosting and Bagging
Works in a similar way as bagging.
Except:
Models are built
Boosting and Bagging
Works in a similar way as bagging.
Except:
Models are built
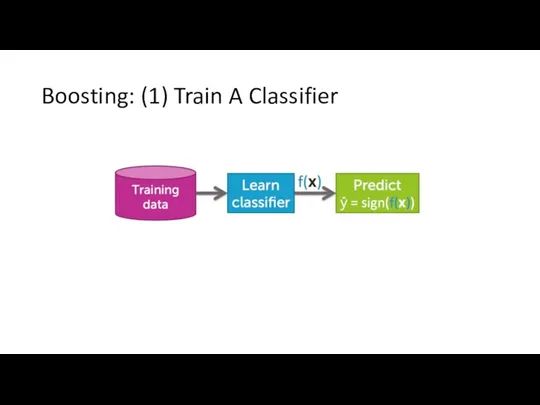
Boosting: (1) Train A Classifier
Boosting: (1) Train A Classifier
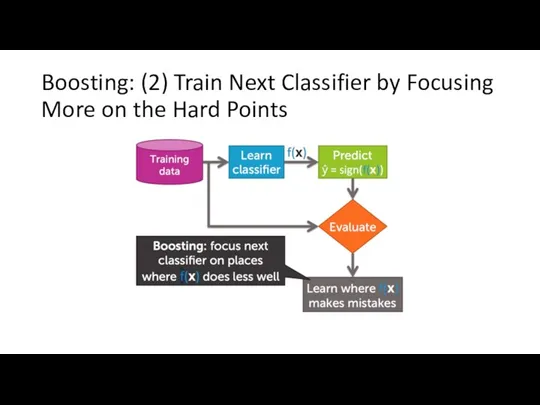
Boosting: (2) Train Next Classifier by Focusing More on the Hard
Boosting: (2) Train Next Classifier by Focusing More on the Hard

What does it mean to focus more?
What does it mean to focus more?
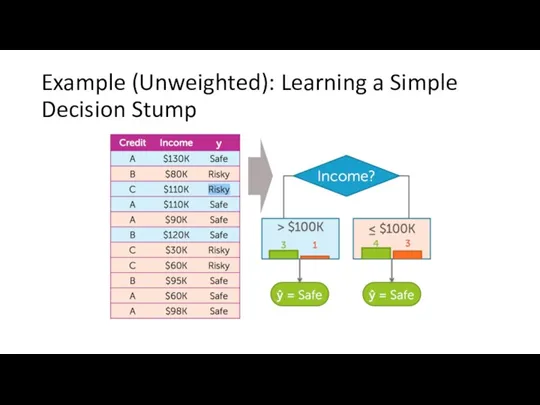
Example (Unweighted): Learning a Simple Decision Stump
Example (Unweighted): Learning a Simple Decision Stump

Example (Weighted): Learning a Decision Stump on Weighted Data
Example (Weighted): Learning a Decision Stump on Weighted Data
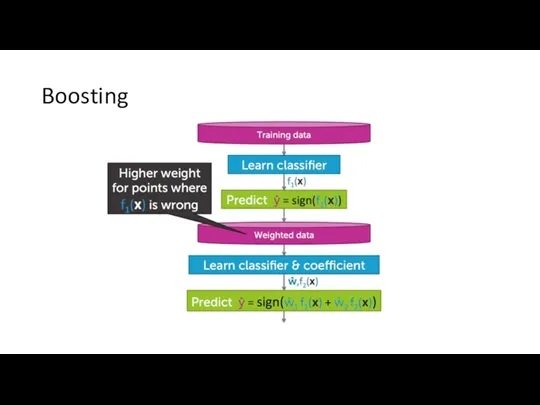
Boosting
Boosting

AdaBoost (Example of Boosting)
Weight of the model
New weights of the data
AdaBoost (Example of Boosting)
Weight of the model
New weights of the data


Weighted Classification Error
Weighted Classification Error

AdaBoost: Computing Classifier’s Weights
AdaBoost: Computing Classifier’s Weights

AdaBoost
AdaBoost


AdaBoost: Recomputing A Sample’s Weight
Increase, Decrease, or Keep the Same
AdaBoost: Recomputing A Sample’s Weight
Increase, Decrease, or Keep the Same

AdaBoost: Recomputing A Sample’s Weight
AdaBoost: Recomputing A Sample’s Weight

AdaBoost
AdaBoost

AdaBoost: Normalizing Sample Weights
AdaBoost: Normalizing Sample Weights

AdaBoost
AdaBoost

Self Study
What is the effect of of:
Increasing the number of classifiers
Self Study
What is the effect of of:
Increasing the number of classifiers

Boosting Summary
Boosting Summary
 Внеклассное мероприятие. Путешествие с Инфознайкой
Внеклассное мероприятие. Путешествие с Инфознайкой Intencje i przechowywanie danych
Intencje i przechowywanie danych Здравствуй, мир! Основы программирования
Здравствуй, мир! Основы программирования Управление вводом-выводом
Управление вводом-выводом 9_5.1
9_5.1 Построение диаграмм и графиков в электронных таблицах
Построение диаграмм и графиков в электронных таблицах Соціальні сервіси WEB 2.0
Соціальні сервіси WEB 2.0 Додаткові способи введення та виведення даних. (Лекція 10)
Додаткові способи введення та виведення даних. (Лекція 10) Фейк-новости
Фейк-новости Информационная безопасность в образовательной организации
Информационная безопасность в образовательной организации Локальные и глобальные компьютерные сети
Локальные и глобальные компьютерные сети Построение и исследование физической модели
Построение и исследование физической модели Криптовалюта: опыт биткоинов
Криптовалюта: опыт биткоинов Отчеты сводных таблиц
Отчеты сводных таблиц The ways we use computer
The ways we use computer Городской сетевой клуб. Запуск проекта Некрасовская республика
Городской сетевой клуб. Запуск проекта Некрасовская республика Простейшие программы
Простейшие программы Информационные ресурсы общества
Информационные ресурсы общества Система и окружающая среда. Урок информатики в 7 классе
Система и окружающая среда. Урок информатики в 7 классе Функции повышения надёжности сети
Функции повышения надёжности сети Обучение Opti 4G
Обучение Opti 4G Проектирование ER-диаграммы
Проектирование ER-диаграммы Взаимодействие между процессами
Взаимодействие между процессами Введение в базы данных
Введение в базы данных Информация. Измерение количества информации
Информация. Измерение количества информации Комп'ютерна графіка та робота з нею
Комп'ютерна графіка та робота з нею Введение в искусственный интеллект. Тема 1
Введение в искусственный интеллект. Тема 1 Оформление научной работы
Оформление научной работы