- Intro to Natural language processing

Содержание
- 2. Definition Natural language processing is a field of computer science, artificial intelligence, and computational linguistics concerned
- 3. Common NLP Tasks Part-of-Speech Tagging Named Entity Recognition Spam Detection Thesaurus Syntactic Parsing Word Sense Disambiguation
- 4. NLTK
- 5. NLTK Language: Python Area: Natural Language Processing Usage: Symbolic and statistical natural language processing Advantages: easy-to-use
- 6. Tokenization
- 7. Tokenization tokenization is the process of breaking a stream of text up into words, phrases, symbols,
- 8. Tokenization into sentences into words nltk.tokenize.sent_tokenize() nltk.tokenize.word_tokenize() ! punctuation == word
- 9. Tokenize not-english text There are total 17 european languages that NLTK support for sentence tokenize, and
- 10. price . The U.S. and China increased the number of supercomputers price . The U.S. and
- 11. Stop Words
- 14. Stop Words Lists from nltk.corpus import stopwords stop = set(stopwords.words('english')) Terrier stop word list – this
- 15. Remove Punctuation
- 16. Regular Expressions a sequence of characters that define a search pattern Wikipedia
- 18. '[^a-zA-Z0-9_ ]' Regex, any symbol but letters, numbers, ‘_’ and space re.sub(pattern, repl, string, count=0, flags=0)¶
- 19. price U.S. China increased number supercomputers price U.S. China increased number supercomputers price U.S. China increase
- 20. Stemming
- 21. Stemming stemming is the process of reducing inflected (or sometimes derived) words to their word stem,
- 22. Lemmatization
- 23. Lemmatization lemmatisation (or lemmatization) is the process of grouping together the inflected forms of a word
- 24. cats dishes wolves are stopping enjoyed cat dish wolf be stop enjoy Lemmatization result
- 26. the lemmatize method default pos argument is “n” == noun!
- 27. Speech Tagging
- 28. Simplified Tagset of NLTK
- 29. More about tags NLTK provides documentation for each tag, which can be queried using the tag,
- 30. Word Count
- 32. Syntax Trees
- 33. With appropriate pre-processing, it is competitive in this domain with more advanced methods including support vector
- 34. Clustering with scikit-learn
- 35. fetch_20newsgroups subset: ‘train’ or ‘test’, ‘all’, optional : categories: None or collection of string or unicode
- 36. Clustering. Bag of words
- 37. TF-IDF term frequency-inverse document frequency - a numerical statistic that is intended to reflect how important
- 38. sklearn.TfidfVectorizer preprocessor : callable or None (default) tokenizer : callable or None (default) stop_words : string
- 39. k-means 1. k initial "means" (in this case k=3) are randomly generated within the data domain
- 40. sklearn.KMeans n_clusters : int, optional, default: 8 max_iter : int, default: 300 n_init : int, default:
- 41. Metrics Homogeneity: All of its clusters contain only data points which are members of a single
- 42. Results
- 44. Скачать презентацию

Definition
Natural language processing is a field of computer science, artificial intelligence, and computational linguistics concerned with
Definition
Natural language processing is a field of computer science, artificial intelligence, and computational linguistics concerned with

Common NLP Tasks
Part-of-Speech Tagging
Named Entity Recognition
Spam Detection
Thesaurus
Syntactic Parsing
Word Sense Disambiguation
Sentiment Analysis
Topic
Common NLP Tasks
Part-of-Speech Tagging
Named Entity Recognition
Spam Detection
Thesaurus
Syntactic Parsing
Word Sense Disambiguation
Sentiment Analysis
Topic

NLTK
NLTK

NLTK
Language: Python
Area: Natural Language Processing
Usage: Symbolic and statistical natural language processing
Advantages:
easy-to-use
NLTK
Language: Python
Area: Natural Language Processing
Usage: Symbolic and statistical natural language processing
Advantages:
easy-to-use

Tokenization
Tokenization

Tokenization
tokenization is the process of breaking a stream of text up
Tokenization
tokenization is the process of breaking a stream of text up
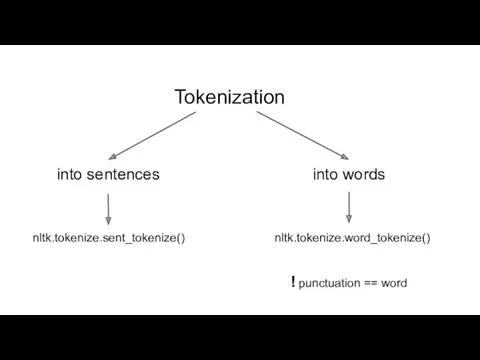
Tokenization
into sentences
into words
nltk.tokenize.sent_tokenize()
nltk.tokenize.word_tokenize()
! punctuation == word
Tokenization
into sentences
into words
nltk.tokenize.sent_tokenize()
nltk.tokenize.word_tokenize()
! punctuation == word

Tokenize not-english text
There are total 17 european languages that NLTK support
Tokenize not-english text
There are total 17 european languages that NLTK support
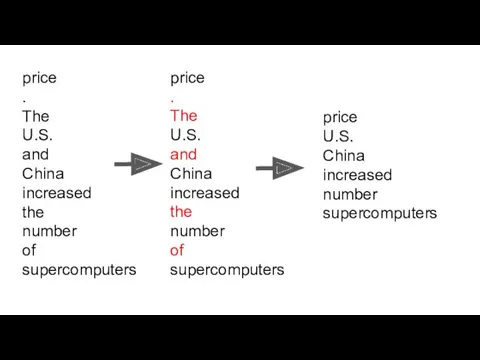
price
.
The
U.S.
and
China
increased
the
number
of
supercomputers
price
.
The
U.S.
and
China
increased
the
number
of
supercomputers
price
U.S.
China
increased
number
supercomputers
price
.
The
U.S.
and
China
increased
the
number
of
supercomputers
price
.
The
U.S.
and
China
increased
the
number
of
supercomputers
price
U.S.
China
increased
number
supercomputers

Stop Words
Stop Words



Stop Words Lists
from nltk.corpus import stopwords
stop = set(stopwords.words('english'))
Terrier stop word list
Stop Words Lists
from nltk.corpus import stopwords
stop = set(stopwords.words('english'))
Terrier stop word list

Remove Punctuation
Remove Punctuation

Regular Expressions
a sequence of characters that define a search pattern
Wikipedia
Regular Expressions
a sequence of characters that define a search pattern
Wikipedia
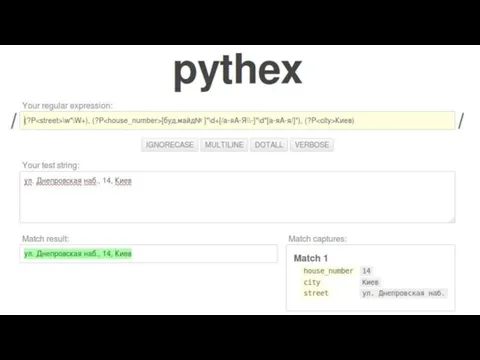
!['[^a-zA-Z0-9_ ]' Regex, any symbol but letters, numbers, ‘_’ and](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/96136/slide-17.jpg)
'[^a-zA-Z0-9_ ]'
Regex, any symbol but letters, numbers, ‘_’ and space
re.sub(pattern,
'[^a-zA-Z0-9_ ]'
Regex, any symbol but letters, numbers, ‘_’ and space
re.sub(pattern,
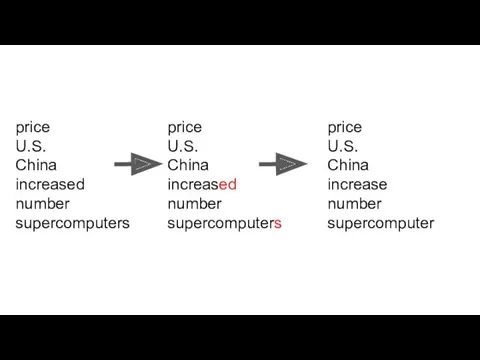
price
U.S.
China
increased
number
supercomputers
price
U.S.
China
increased
number
supercomputers
price
U.S.
China
increase
number
supercomputer
price
U.S.
China
increased
number
supercomputers
price
U.S.
China
increased
number
supercomputers
price
U.S.
China
increase
number
supercomputer

Stemming
Stemming
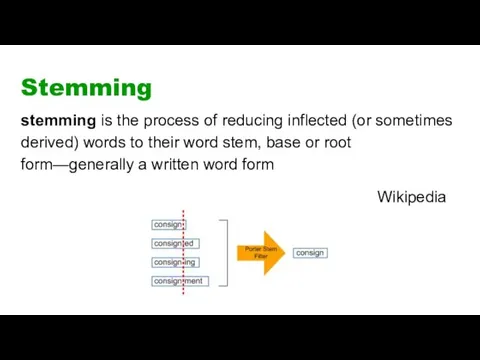
Stemming
stemming is the process of reducing inflected (or sometimes derived) words
Stemming
stemming is the process of reducing inflected (or sometimes derived) words

Lemmatization
Lemmatization

Lemmatization
lemmatisation (or lemmatization) is the process of grouping together the inflected
Lemmatization
lemmatisation (or lemmatization) is the process of grouping together the inflected

cats
dishes
wolves
are
stopping
enjoyed
cat
dish
wolf
be
stop
enjoy
Lemmatization result
cats
dishes
wolves
are
stopping
enjoyed
cat
dish
wolf
be
stop
enjoy
Lemmatization result


the lemmatize method default pos argument is “n” == noun!
the lemmatize method default pos argument is “n” == noun!

Speech Tagging
Speech Tagging

Simplified Tagset of NLTK
Simplified Tagset of NLTK

More about tags
NLTK provides documentation for each tag, which can be
More about tags
NLTK provides documentation for each tag, which can be

Word Count
Word Count

Syntax Trees
Syntax Trees

With appropriate pre-processing, it is competitive in this domain with more
With appropriate pre-processing, it is competitive in this domain with more

Clustering with scikit-learn
Clustering with scikit-learn

fetch_20newsgroups
subset: ‘train’ or ‘test’, ‘all’, optional :
categories: None or collection of
fetch_20newsgroups
subset: ‘train’ or ‘test’, ‘all’, optional :
categories: None or collection of

Clustering. Bag of words
Clustering. Bag of words

TF-IDF
term frequency-inverse document frequency - a numerical statistic that is intended
TF-IDF
term frequency-inverse document frequency - a numerical statistic that is intended

sklearn.TfidfVectorizer
preprocessor : callable or None (default)
tokenizer : callable or None (default)
stop_words : string
sklearn.TfidfVectorizer
preprocessor : callable or None (default)
tokenizer : callable or None (default)
stop_words : string
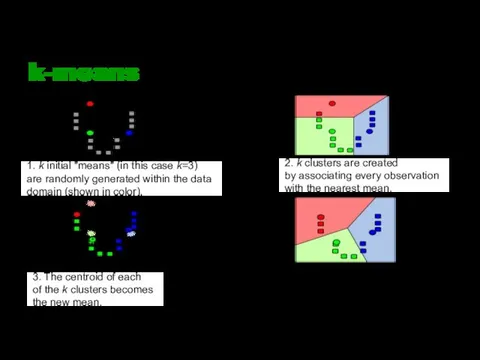
k-means
1. k initial "means" (in this case k=3)
are randomly generated within the data
k-means
1. k initial "means" (in this case k=3)
are randomly generated within the data

sklearn.KMeans
n_clusters : int, optional, default: 8
max_iter : int, default: 300
n_init : int, default: 10
Number
sklearn.KMeans
n_clusters : int, optional, default: 8
max_iter : int, default: 300
n_init : int, default: 10
Number

Metrics
Homogeneity:
All of its clusters contain only data points which are members
Metrics
Homogeneity: All of its clusters contain only data points which are members

Results
Results
 Case Simulation
Case Simulation Использование методов типа ветвей и границ для решения экстремальных задач на графах
Использование методов типа ветвей и границ для решения экстремальных задач на графах Информационные системы
Информационные системы Программирование на языке Python
Программирование на языке Python Технологии баз данных
Технологии баз данных Своя игра. Лабиринт информации
Своя игра. Лабиринт информации Геймінг – це гра у відеоігри на колективних турнірах
Геймінг – це гра у відеоігри на колективних турнірах Дополнительные возможности HTML и CSS. XML-технологии и их применение
Дополнительные возможности HTML и CSS. XML-технологии и их применение Базы данных. Введение в курс баз данных
Базы данных. Введение в курс баз данных Кто играл в PACMAN? Какие правила игры?
Кто играл в PACMAN? Какие правила игры? Сетевые операционные системы
Сетевые операционные системы конспект урока Моделирование
конспект урока Моделирование Решение задач в Mathcad и Excel. Использование функции IF (ЕСЛИ). Лабораторная работа №1
Решение задач в Mathcad и Excel. Использование функции IF (ЕСЛИ). Лабораторная работа №1 Архитектура и система команд процесоров Intel. (Тема 1)
Архитектура и система команд процесоров Intel. (Тема 1) Викторина по информатике (презентация)
Викторина по информатике (презентация) Час кода в России
Час кода в России Обзор периферийных устройств, дополняющих линейку ПЛК ОВЕН
Обзор периферийных устройств, дополняющих линейку ПЛК ОВЕН Язык С++: новые возможности. (Лекция 1)
Язык С++: новые возможности. (Лекция 1) Обзор компьютера
Обзор компьютера This is your presentation title
This is your presentation title Основные компоненты компьютера и их функции
Основные компоненты компьютера и их функции Поняття про мультимедіа. ( 6 клас)
Поняття про мультимедіа. ( 6 клас) Разработка программно-информационного ядра информационной системы на основе СУБД
Разработка программно-информационного ядра информационной системы на основе СУБД Робота з елементами форми
Робота з елементами форми 001 Ancient Greek History - Essential Chronology
001 Ancient Greek History - Essential Chronology Команда Select (лекция 2)
Команда Select (лекция 2) Презентация к уроку Носители информации (3 класс)
Презентация к уроку Носители информации (3 класс) Графическая информация
Графическая информация