- Машинное обучение. Введение

Содержание
- 2. Машинное обучение (англ. machine learning, ML) — класс методов искусственного интеллекта, характерной чертой которых является не
- 3. Обучение с учителем: Данные размечены, правильные ответы на задачу известны. Обучение без учителя: Данные не размечены,
- 4. 1950-е годы - новаторские исследования в области машинного обучения с использованием простых алгоритмов; 1960-е годы -
- 5. 1951 - первая нейронная сеть; 1952 - компьютеры, играющие в шашки; 1972 - создан язык Пролог;
- 6. Крупномасштабная модель языка построенная на алгоритмах без учителя, которая генерирует согласованные абзацы текста, достигает современного уровня
- 7. “The scary thing about GPT-2-generated text is that it flows very naturally if you’re just skimming,
- 8. The scientist named the population, after their distinctive horn, Ovid’s Unicorn. These four-horned, silver-white unicorns were
- 9. 2016: AlphaGo впервые обыграл профессионального игрока в го без каких-либо ограничений; 2017: AlphaGo побеждает Ли Седоля;
- 10. Достижения машинного обучения: GAN
- 11. Достижения машинного обучения: GAN
- 12. Достижения машинного обучения: GPT-2 https://www.gwern.net/TWDNE
- 13. Достижения машинного обучения: Nvidia GauGAN
- 14. Проблемы машинного обучения: выбор модели и гиперпараметров Дозировка Смертность 0
- 15. Проблемы машинного обучения: adversarial examples
- 16. Проблемы машинного обучения: adversarial examples
- 17. Игра – лодочные гонки, где ИИ вознаграждался ростом счета за поражение целей, приводит к тому, что
- 18. Планирование миссии НАСА на Марс, оптимизирующее потребление пищи/воды/электричества для общего выживания в человеко-днях, дает оптимальный план:
- 19. Сначала ИИ завершает первый уровень, а затем начинает переходить с платформы на платформу, как кажется случайным
- 20. Контролируемое обучение - это задача машинного обучения, состоящая в формировании функции, которая отображает входные данные в
- 21. Дилемма смещения–дисперсии Чем гибче алгоритм, тем выше дисперсия. Чем менее гибкий алгоритм, тем выше смещение. Сложность
- 22. В линейной регрессии отношения моделируются с использованием функций линейного предиктора, чьи неизвестные параметры модели оцениваются по
- 23. Семейство простых «вероятностных классификаторов», основанное на применении теоремы Байеса с сильными (наивными) предположениями о независимости между
- 24. Три слоя узлов: входной слой, скрытый слой и выходной слой; Использует обратное распространение ошибки для обучения;
- 25. Каждый внутренний узел представляет собой «тест» для атрибута; Каждая ветвь представляет результат теста; Каждый лист представляет
- 26. Недостатки: Нестабильное: небольшие изменения в данных могут привести к значительным изменениям в дереве решений. Неточное. Многие
- 27. Множество деревьев решений, выводящих класс, который является модой классов (классификация) или средним прогнозом (регрессия) отдельных деревьев.
- 28. Gradient Boosting объединяет множество слабых моделей машинного обучения в одну сильную итеративным способом, обычно используется с
- 29. Регрессия: Средняя абсолютная ошибка, среднеквадратичная ошибка. Классификация: Точность, полнота, accuracy. Оценки качества моделей
- 30. Прогноз погоды; Прогнозы продолжительности поездки; Медицинские диагнозы; Прогнозы продуктивности нефтяных скважин; Прогнозы продолжительности вычислений на HPC;
- 31. Wu & Zhang 2016, «Automated Inference on Criminality using Face Images» - попытка по стандартизированным фото
- 32. Кластеризация Иерархическая кластеризация; K-средние; DBSCAN; Обнаружение аномалий Метод локальных выбросов Нейронные сети GAN Подходы машинного обучения
- 33. Агломерация: это подход «снизу вверх»: каждое наблюдение начинает в своем собственном кластере, и пары кластеров объединяются
- 34. Целью является разделение n наблюдений на k кластеров, в которых каждое наблюдение принадлежит кластеру с ближайшим
- 35. Density-based spatial clustering of applications with noise. Группирует в один кластер точки, которые находятся рядом и
- 36. Сравнивая локальную плотность объекта с локальными плотностями его соседей, можно идентифицировать области с одинаковой плотностью и
- 37. Генеративная сеть генерирует кандидатов, а дискриминационная сеть оценивает их. Известный набор данных служит начальными данными обучения
- 38. Успехи обучения без учителя
- 39. Провалы обучения без учителя
- 40. Внутренняя оценка: Коэффициент силуэта сравнивает среднее расстояние до элементов в одном кластере со средним расстоянием до
- 41. Scikit-learn: линейная и логистическая регрессии, деревья решений, кластеризация, k-средние и т. д. TensorFlow: DeepLearning, поддержка GPU.
- 42. Выбор модели на примере scikit-learn
- 43. Hadoop для машинного обучения Классификация и регрессия Линейные модели (SVM, логистическая регрессия, линейная регрессия) Наивный байесовский
- 44. Заключение Машинное обучение позволяет решать задачи, которые казались фантастикой ещё 5 лет назад; Машинное обучение требует
- 46. Скачать презентацию

Машинное обучение (англ. machine learning, ML) — класс методов искусственного интеллекта, характерной чертой
Машинное обучение (англ. machine learning, ML) — класс методов искусственного интеллекта, характерной чертой

Обучение с учителем:
Данные размечены, правильные ответы на задачу известны.
Обучение без учителя:
Данные
Обучение с учителем:
Данные размечены, правильные ответы на задачу известны.
Обучение без учителя:
Данные

1950-е годы - новаторские исследования в области машинного обучения с использованием
1950-е годы - новаторские исследования в области машинного обучения с использованием

1951 - первая нейронная сеть;
1952 - компьютеры, играющие в шашки;
1972 -
1951 - первая нейронная сеть;
1952 - компьютеры, играющие в шашки;
1972 -

Крупномасштабная модель языка построенная на алгоритмах без учителя, которая генерирует согласованные
Крупномасштабная модель языка построенная на алгоритмах без учителя, которая генерирует согласованные

“The scary thing about GPT-2-generated text is that it flows very
“The scary thing about GPT-2-generated text is that it flows very

The scientist named the population, after their distinctive horn, Ovid’s Unicorn.
The scientist named the population, after their distinctive horn, Ovid’s Unicorn.

2016: AlphaGo впервые обыграл профессионального игрока в го без каких-либо ограничений;
2017:
2016: AlphaGo впервые обыграл профессионального игрока в го без каких-либо ограничений;
2017:

Достижения машинного обучения: GAN
Достижения машинного обучения: GAN

Достижения машинного обучения: GAN
Достижения машинного обучения: GAN

Достижения машинного обучения: GPT-2
https://www.gwern.net/TWDNE
Достижения машинного обучения: GPT-2
https://www.gwern.net/TWDNE

Достижения машинного обучения: Nvidia GauGAN
Достижения машинного обучения: Nvidia GauGAN
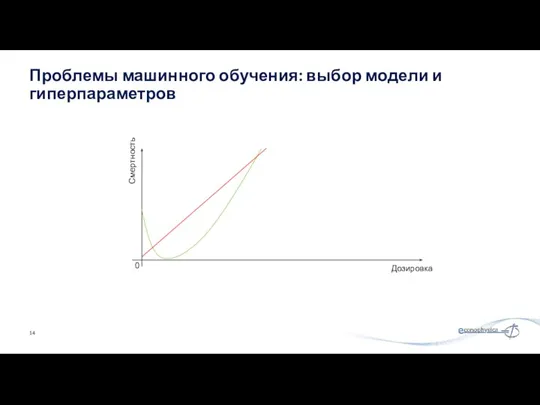
Проблемы машинного обучения: выбор модели и гиперпараметров
Дозировка
Смертность
0
Проблемы машинного обучения: выбор модели и гиперпараметров
Дозировка
Смертность
0

Проблемы машинного обучения: adversarial examples
Проблемы машинного обучения: adversarial examples

Проблемы машинного обучения: adversarial examples
Проблемы машинного обучения: adversarial examples

Игра – лодочные гонки, где ИИ вознаграждался ростом счета за поражение
Игра – лодочные гонки, где ИИ вознаграждался ростом счета за поражение

Планирование миссии НАСА на Марс, оптимизирующее потребление пищи/воды/электричества для общего выживания
Планирование миссии НАСА на Марс, оптимизирующее потребление пищи/воды/электричества для общего выживания

Сначала ИИ завершает первый уровень, а затем начинает переходить с платформы
Сначала ИИ завершает первый уровень, а затем начинает переходить с платформы

Контролируемое обучение - это задача машинного обучения, состоящая в формировании функции,
Контролируемое обучение - это задача машинного обучения, состоящая в формировании функции,

Дилемма смещения–дисперсии
Чем гибче алгоритм, тем выше дисперсия. Чем менее гибкий алгоритм,
Дилемма смещения–дисперсии
Чем гибче алгоритм, тем выше дисперсия. Чем менее гибкий алгоритм,

В линейной регрессии отношения моделируются с использованием функций линейного предиктора, чьи
В линейной регрессии отношения моделируются с использованием функций линейного предиктора, чьи

Семейство простых «вероятностных классификаторов», основанное на применении теоремы Байеса с сильными
Семейство простых «вероятностных классификаторов», основанное на применении теоремы Байеса с сильными
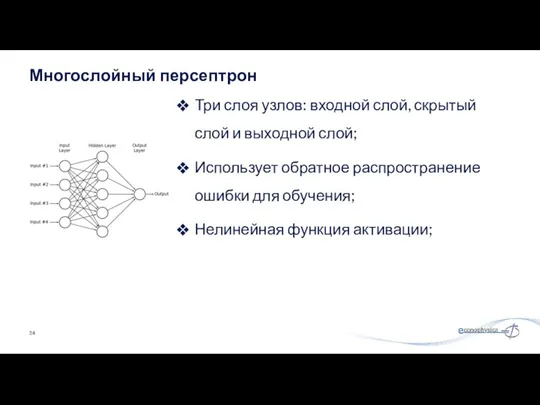
Три слоя узлов: входной слой, скрытый слой и выходной слой;
Использует обратное
Три слоя узлов: входной слой, скрытый слой и выходной слой;
Использует обратное
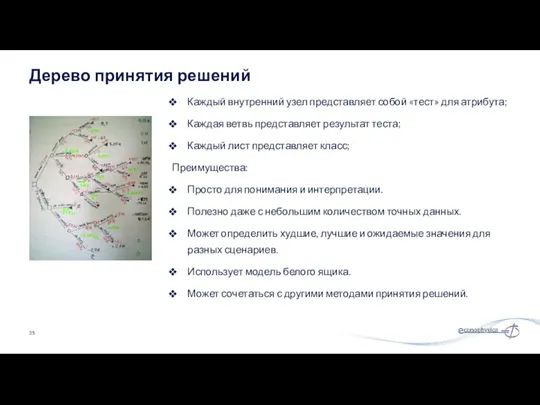
Каждый внутренний узел представляет собой «тест» для атрибута;
Каждая ветвь представляет результат
Каждый внутренний узел представляет собой «тест» для атрибута;
Каждая ветвь представляет результат
Недостатки:
Нестабильное: небольшие изменения в данных могут привести к значительным изменениям в
Недостатки:
Нестабильное: небольшие изменения в данных могут привести к значительным изменениям в
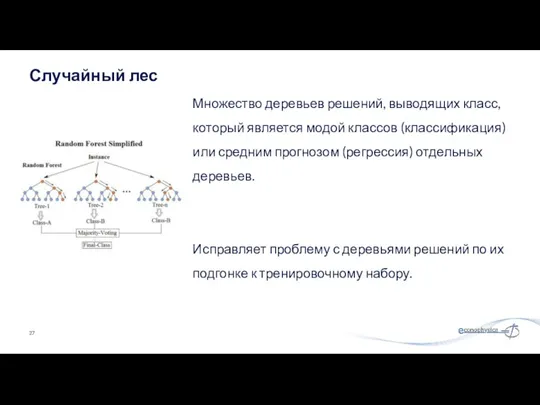
Множество деревьев решений, выводящих класс, который является модой классов (классификация) или
Множество деревьев решений, выводящих класс, который является модой классов (классификация) или

Gradient Boosting объединяет множество слабых моделей машинного обучения в одну сильную
Gradient Boosting объединяет множество слабых моделей машинного обучения в одну сильную
Регрессия:
Средняя абсолютная ошибка, среднеквадратичная ошибка.
Классификация:
Точность, полнота, accuracy.
Оценки качества моделей
Регрессия:
Средняя абсолютная ошибка, среднеквадратичная ошибка.
Классификация:
Точность, полнота, accuracy.
Оценки качества моделей

Прогноз погоды;
Прогнозы продолжительности поездки;
Медицинские диагнозы;
Прогнозы продуктивности нефтяных скважин;
Прогнозы продолжительности вычислений на
Прогноз погоды;
Прогнозы продолжительности поездки;
Медицинские диагнозы;
Прогнозы продуктивности нефтяных скважин;
Прогнозы продолжительности вычислений на

Wu & Zhang 2016, «Automated Inference on Criminality using Face Images»
Wu & Zhang 2016, «Automated Inference on Criminality using Face Images»

Кластеризация
Иерархическая кластеризация;
K-средние;
DBSCAN;
Обнаружение аномалий
Метод локальных выбросов
Нейронные сети
GAN
Подходы машинного обучения без учителя
Кластеризация
Иерархическая кластеризация;
K-средние;
DBSCAN;
Обнаружение аномалий
Метод локальных выбросов
Нейронные сети
GAN
Подходы машинного обучения без учителя

Агломерация: это подход «снизу вверх»: каждое наблюдение начинает в своем собственном
Агломерация: это подход «снизу вверх»: каждое наблюдение начинает в своем собственном

Целью является разделение n наблюдений на k кластеров, в которых каждое
Целью является разделение n наблюдений на k кластеров, в которых каждое

Density-based spatial clustering of applications with noise.
Группирует в один кластер точки,
Density-based spatial clustering of applications with noise.
Группирует в один кластер точки,

Сравнивая локальную плотность объекта с локальными плотностями его соседей, можно идентифицировать
Сравнивая локальную плотность объекта с локальными плотностями его соседей, можно идентифицировать

Генеративная сеть генерирует кандидатов, а дискриминационная сеть оценивает их.
Известный набор данных
Генеративная сеть генерирует кандидатов, а дискриминационная сеть оценивает их.
Известный набор данных
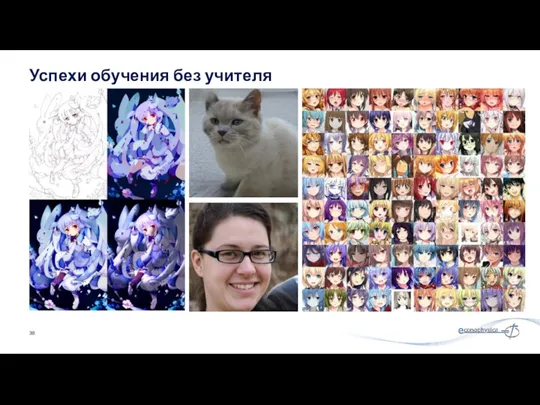
Успехи обучения без учителя
Успехи обучения без учителя

Провалы обучения без учителя
Провалы обучения без учителя

Внутренняя оценка:
Коэффициент силуэта сравнивает среднее расстояние до элементов в одном кластере
Внутренняя оценка:
Коэффициент силуэта сравнивает среднее расстояние до элементов в одном кластере

Scikit-learn: линейная и логистическая регрессии, деревья решений, кластеризация, k-средние и т.
Scikit-learn: линейная и логистическая регрессии, деревья решений, кластеризация, k-средние и т.
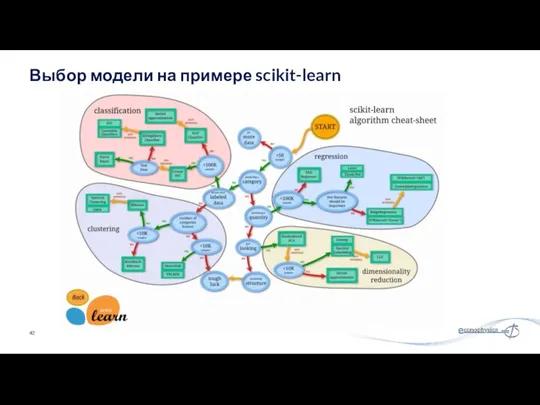
Выбор модели на примере scikit-learn
Выбор модели на примере scikit-learn

Hadoop для машинного обучения
Классификация и регрессия
Линейные модели (SVM, логистическая регрессия, линейная
Hadoop для машинного обучения
Классификация и регрессия
Линейные модели (SVM, логистическая регрессия, линейная

Заключение
Машинное обучение позволяет решать задачи, которые казались фантастикой ещё 5 лет
Заключение
Машинное обучение позволяет решать задачи, которые казались фантастикой ещё 5 лет
 Линейный (одномерный) массив
Линейный (одномерный) массив Программирование разветвляющихся алгоритмов. Начала программирования. Информатика. 8 класс
Программирование разветвляющихся алгоритмов. Начала программирования. Информатика. 8 класс Основные характеристики операционных систем
Основные характеристики операционных систем Библиотека Tkinter. Разработка графических пользовательских интерфейсов
Библиотека Tkinter. Разработка графических пользовательских интерфейсов Проектирование беспроводной сети в офисе
Проектирование беспроводной сети в офисе Клиенты из интернета
Клиенты из интернета Кибернетическая модель управления
Кибернетическая модель управления 51083fc6-0a47-43cf-a4c7-f9191f6b8c83
51083fc6-0a47-43cf-a4c7-f9191f6b8c83 Развитие многоуровневых машин
Развитие многоуровневых машин Методическая подготовка и сопровождение педагогов сельской школы
Методическая подготовка и сопровождение педагогов сельской школы Базы данных и СУБД
Базы данных и СУБД Моделирование. Модели и моделирование
Моделирование. Модели и моделирование Большие данные в контексте цифровизации образования от понятия к технологиям обработки
Большие данные в контексте цифровизации образования от понятия к технологиям обработки Отчет по оценке сайта в сервисе Яндекс.Толока
Отчет по оценке сайта в сервисе Яндекс.Толока Регистрация на сайте Госуслуги
Регистрация на сайте Госуслуги Организация администрирования компьютерных сетей. СУБД MySQL
Организация администрирования компьютерных сетей. СУБД MySQL использование ИКТ в ДОУ
использование ИКТ в ДОУ Структура. Шапка сайта. Меню сайта
Структура. Шапка сайта. Меню сайта Основы алгоритмизации. Подготовка к ГИА. 9 класс
Основы алгоритмизации. Подготовка к ГИА. 9 класс Облачные технологии
Облачные технологии Дерево игры. Поиск выигрышной стратегии
Дерево игры. Поиск выигрышной стратегии Программирование на языке Python. Простейшие программы
Программирование на языке Python. Простейшие программы Локальные вычислительные сети
Локальные вычислительные сети Теория нечетких систем. Программные средства, реализующие технологию нечеткого моделирования
Теория нечетких систем. Программные средства, реализующие технологию нечеткого моделирования Программирование на Python. Урок 13. Игровое меню и события
Программирование на Python. Урок 13. Игровое меню и события Как создать презентацию
Как создать презентацию Личный кабинет подрядной организации
Личный кабинет подрядной организации Практична робота №5 Створення анімованих моделей явищ та процесів
Практична робота №5 Створення анімованих моделей явищ та процесів