- Memory Data Flow

Содержание
- 2. Memory Data Flow Memory Data Flow Memory Data Dependences Load Bypassing Load Forwarding Speculative Disambiguation The
- 3. Memory Data Dependences Besides branches, long memory latencies are one of the biggest performance challenges today.
- 4. Memory Data Dependences “Memory Aliasing” = Two memory references involving the same memory location (collision of
- 5. Total Order of Loads and Stores Keep all loads and stores totally in order with respect
- 6. Illustration of Total Order
- 7. Load Bypassing Loads can be allowed to bypass stores (if no aliasing). Two separate reservation stations
- 8. Illustration of Load Bypassing
- 9. Load Forwarding If a subsequent load has a dependence on a store still in the store
- 10. Illustration of Load Forwarding
- 11. The DAXPY Example Total Order
- 12. Performance Gains From Weak Ordering
- 13. Optimizing Load/Store Disambiguation Non-speculative load/store disambiguation Loads wait for addresses of all prior stores Full address
- 14. Speculative Disambiguation What if aliases are rare? Loads don’t wait for addresses of all prior stores
- 15. Speculative Disambiguation: Load Bypass Load Queue Store Queue Agen Reorder Buffer Mem i1: st R3, MEM[R8]:
- 16. Speculative Disambiguation: Load Forward Load Queue Store Queue Agen Reorder Buffer Mem i1: st R3, MEM[R8]:
- 17. Speculative Disambiguation: Safe Speculation Load Queue Store Queue Agen Reorder Buffer Mem i1: st R3, MEM[R8]:
- 18. Speculative Disambiguation: Violation Load Queue Store Queue Agen Reorder Buffer Mem i1: st R3, MEM[R8]: ??
- 19. Use of Prediction If aliases are rare: static prediction Predict no alias every time Why even
- 20. Load/Store Disambiguation Discussion RISC ISA: Many registers, most variables allocated to registers Aliases are rare Most
- 21. The Memory Bottleneck
- 22. Load/Store Processing For both Loads and Stores: Effective Address Generation: Must wait on register value Must
- 23. Easing The Memory Bottleneck
- 24. Memory Bottleneck Techniques Dynamic Hardware (Microarchitecture): Use Multiple Load/Store Units (need multiported D-cache) Use More Advanced
- 25. Caches and Performance Caches Enable design for common case: cache hit Cycle time, pipeline organization Recovery
- 26. Performance Impact Cache hit latency Included in “pipeline” portion of CPI E.g. IBM study: 1.15 CPI
- 27. Cache Hit continued Cycle stealing common Address generation Array access > cycle Clean, FSD cycle boundaries
- 28. Cache Hits and Performance Cache hit latency determined by: Cache organization Associativity Parallel tag checks expensive,
- 29. Cache Misses and Performance Miss penalty Detect miss: 1 or more cycles Find victim (replace block):
- 30. Cache Miss Rate Determined by: Program characteristics Temporal locality Spatial locality Cache organization Block size, associativity,
- 31. Improving Locality Instruction text placement Profile program, place unreferenced or rarely referenced paths “elsewhere” Maximize temporal
- 32. Improving Locality Data placement, access order Arrays: “block” loops to access subarray that fits into cache
- 33. Cache Miss Rates: 3 C’s [Hill] Compulsory miss First-ever reference to a given block of memory
- 34. Cache Miss Rate Effects Number of blocks (sets x associativity) Bigger is better: fewer conflicts, greater
- 35. Cache Miss Rate Subtle tradeoffs between cache organization parameters Large blocks reduce compulsory misses but increase
- 36. Cache Miss Rates: 3 C’s Vary size and associativity Compulsory misses are constant Capacity and conflict
- 37. Cache Miss Rates: 3 C’s Vary size and block size Compulsory misses drop with increased block
- 39. Скачать презентацию

Memory Data Flow
Memory Data Flow
Memory Data Dependences
Load Bypassing
Load
Memory Data Flow
Memory Data Flow
Memory Data Dependences
Load Bypassing
Load
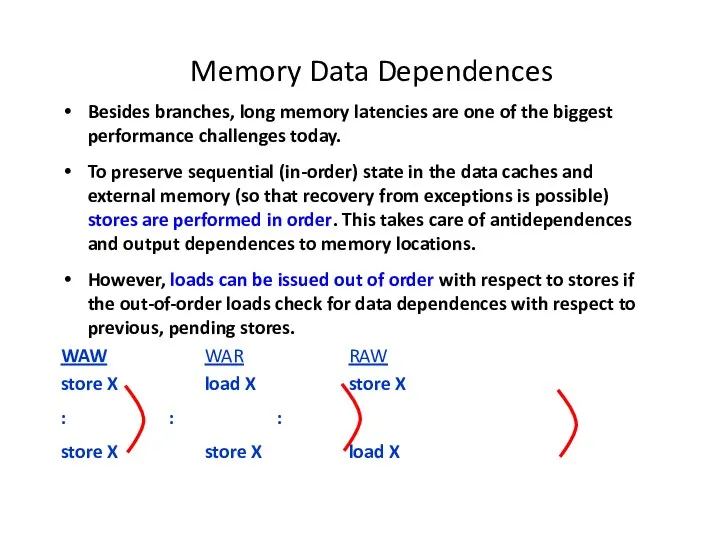
Memory Data Dependences
Besides branches, long memory latencies are one of the
Memory Data Dependences
Besides branches, long memory latencies are one of the

Memory Data Dependences
“Memory Aliasing” = Two memory references involving the same
Memory Data Dependences
“Memory Aliasing” = Two memory references involving the same

Total Order of Loads and Stores
Keep all loads and stores totally
Total Order of Loads and Stores
Keep all loads and stores totally
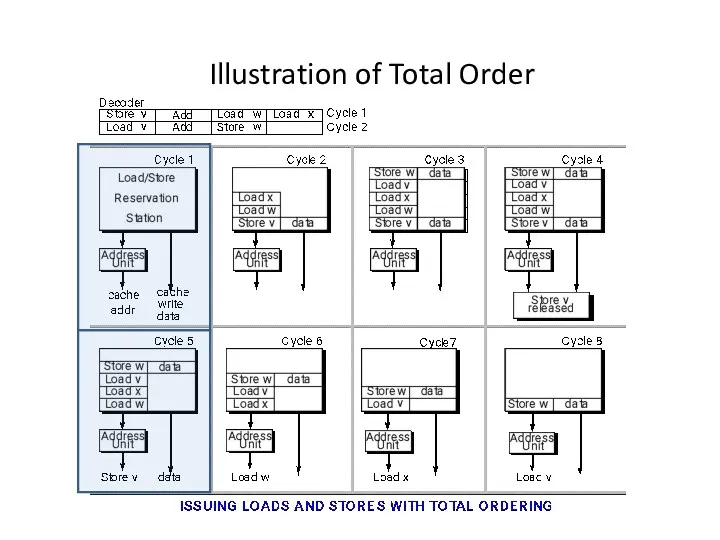
Illustration of Total Order
Illustration of Total Order

Load Bypassing
Loads can be allowed to bypass stores (if no aliasing).
Two
Load Bypassing
Loads can be allowed to bypass stores (if no aliasing).
Two
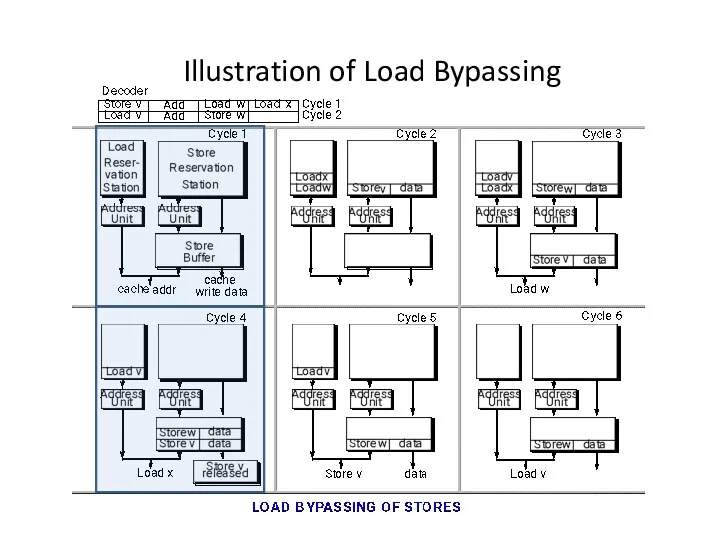
Illustration of Load Bypassing
Illustration of Load Bypassing

Load Forwarding
If a subsequent load has a dependence on a store
Load Forwarding
If a subsequent load has a dependence on a store
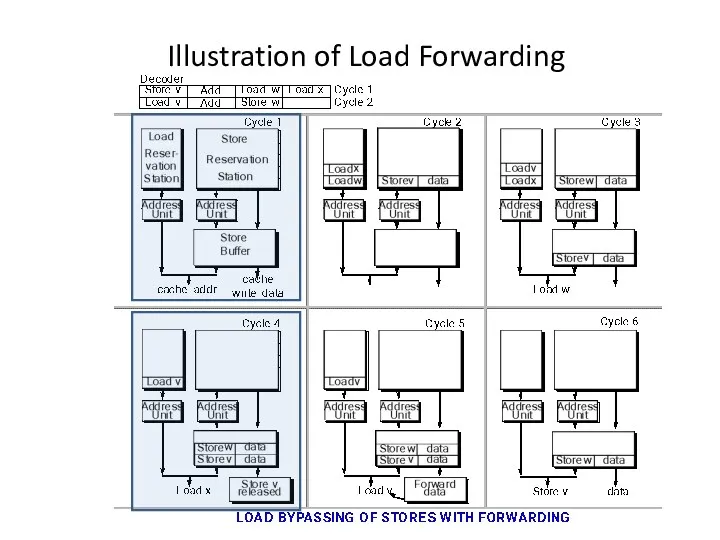
Illustration of Load Forwarding
Illustration of Load Forwarding
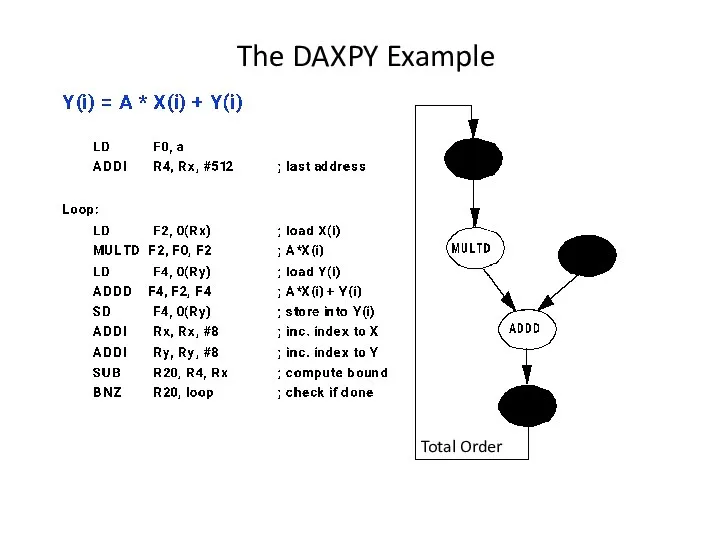
The DAXPY Example
Total Order
The DAXPY Example
Total Order
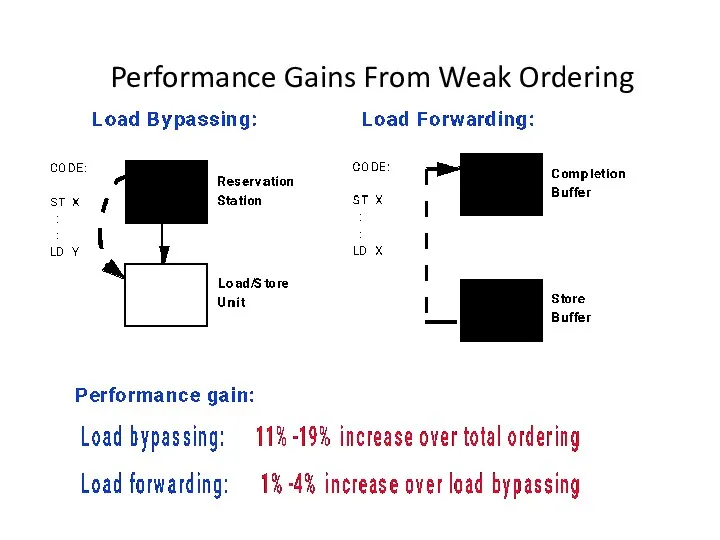
Performance Gains From Weak Ordering
Performance Gains From Weak Ordering

Optimizing Load/Store Disambiguation
Non-speculative load/store disambiguation
Loads wait for addresses of all prior
Optimizing Load/Store Disambiguation
Non-speculative load/store disambiguation
Loads wait for addresses of all prior

Speculative Disambiguation
What if aliases are rare?
Loads don’t wait for addresses of
Speculative Disambiguation
What if aliases are rare?
Loads don’t wait for addresses of
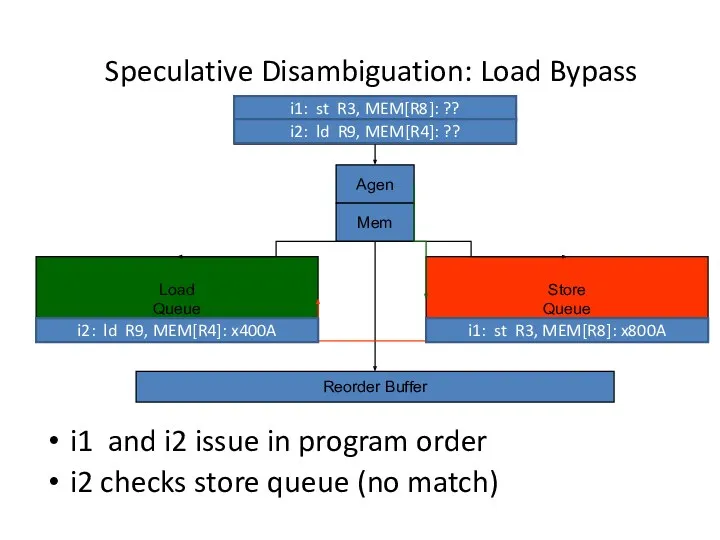
Speculative Disambiguation: Load Bypass
Load
Queue
Store
Queue
Agen
Reorder Buffer
Mem
i1: st R3, MEM[R8]: ??
i2: ld R9,
Speculative Disambiguation: Load Bypass
Load
Queue
Store
Queue
Agen
Reorder Buffer
Mem
i1: st R3, MEM[R8]: ??
i2: ld R9,
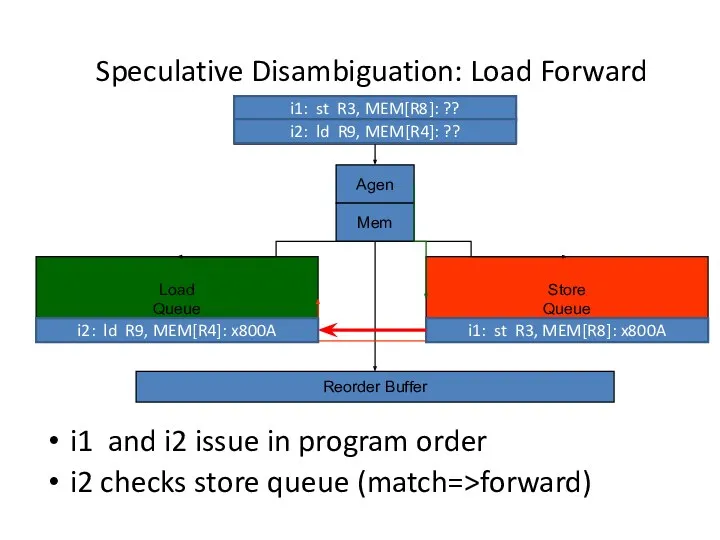
Speculative Disambiguation: Load Forward
Load
Queue
Store
Queue
Agen
Reorder Buffer
Mem
i1: st R3, MEM[R8]: ??
i2: ld R9,
Speculative Disambiguation: Load Forward
Load
Queue
Store
Queue
Agen
Reorder Buffer
Mem
i1: st R3, MEM[R8]: ??
i2: ld R9,
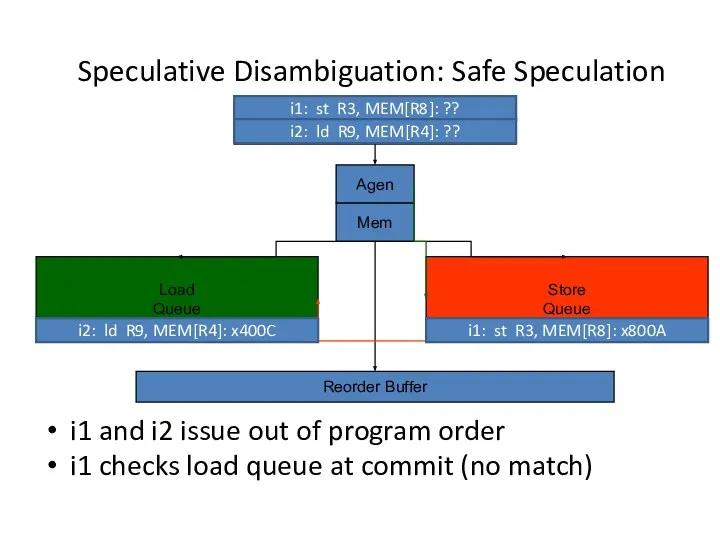
Speculative Disambiguation: Safe Speculation
Load
Queue
Store
Queue
Agen
Reorder Buffer
Mem
i1: st R3, MEM[R8]: ??
i2: ld R9,
Speculative Disambiguation: Safe Speculation
Load
Queue
Store
Queue
Agen
Reorder Buffer
Mem
i1: st R3, MEM[R8]: ??
i2: ld R9,
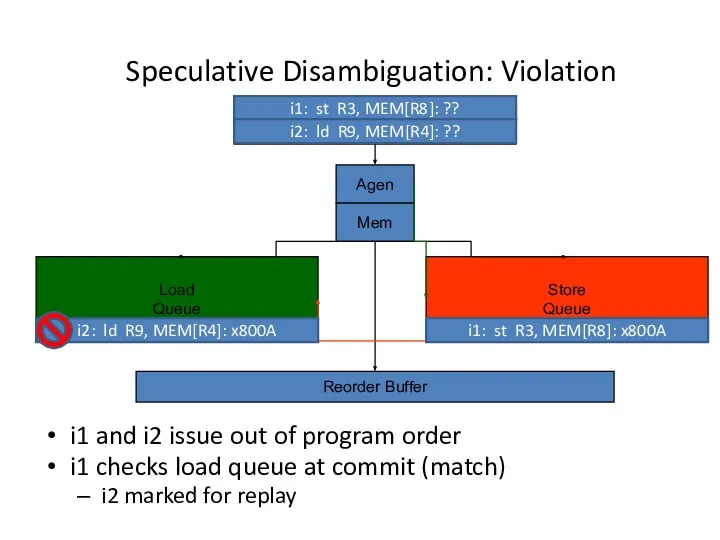
Speculative Disambiguation: Violation
Load
Queue
Store
Queue
Agen
Reorder Buffer
Mem
i1: st R3, MEM[R8]: ??
i2: ld R9, MEM[R4]:
Speculative Disambiguation: Violation
Load
Queue
Store
Queue
Agen
Reorder Buffer
Mem
i1: st R3, MEM[R8]: ??
i2: ld R9, MEM[R4]:

Use of Prediction
If aliases are rare: static prediction
Predict no alias every
Use of Prediction
If aliases are rare: static prediction
Predict no alias every

Load/Store Disambiguation Discussion
RISC ISA:
Many registers, most variables allocated to registers
Aliases are
Load/Store Disambiguation Discussion
RISC ISA:
Many registers, most variables allocated to registers
Aliases are
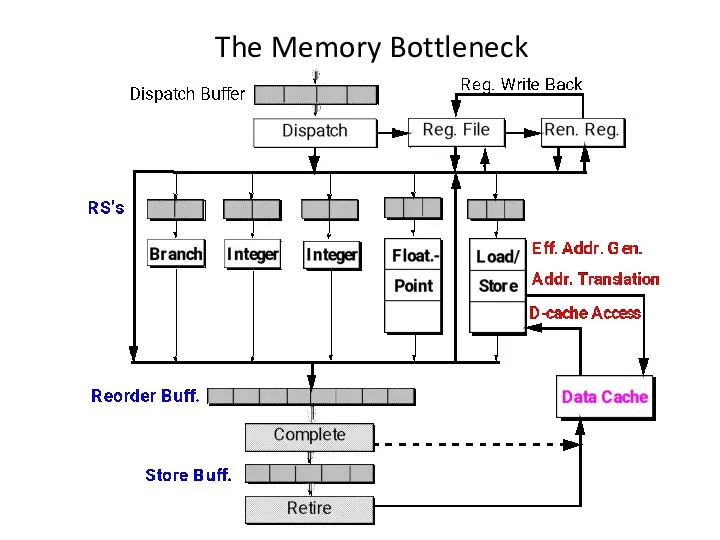
The Memory Bottleneck
The Memory Bottleneck

Load/Store Processing
For both Loads and Stores:
Effective Address Generation:
Must wait on register
Load/Store Processing
For both Loads and Stores:
Effective Address Generation:
Must wait on register
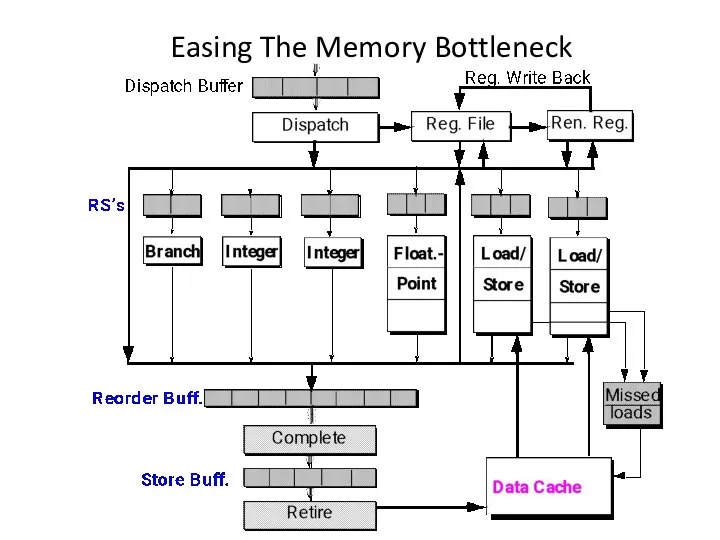
Easing The Memory Bottleneck
Easing The Memory Bottleneck

Memory Bottleneck Techniques
Dynamic Hardware (Microarchitecture):
Use Multiple Load/Store Units (need multiported D-cache)
Use
Memory Bottleneck Techniques
Dynamic Hardware (Microarchitecture):
Use Multiple Load/Store Units (need multiported D-cache)
Use

Caches and Performance
Caches
Enable design for common case: cache hit
Cycle time, pipeline
Caches and Performance
Caches
Enable design for common case: cache hit
Cycle time, pipeline

Performance Impact
Cache hit latency
Included in “pipeline” portion of CPI
E.g. IBM study:
Performance Impact
Cache hit latency
Included in “pipeline” portion of CPI
E.g. IBM study:

Cache Hit continued
Cycle stealing common
Address generation < cycle
Array access > cycle
Clean,
Cache Hit continued
Cycle stealing common
Address generation < cycle
Array access > cycle
Clean,

Cache Hits and Performance
Cache hit latency determined by:
Cache organization
Associativity
Parallel tag checks
Cache Hits and Performance
Cache hit latency determined by:
Cache organization
Associativity
Parallel tag checks

Cache Misses and Performance
Miss penalty
Detect miss: 1 or more cycles
Find victim
Cache Misses and Performance
Miss penalty
Detect miss: 1 or more cycles
Find victim

Cache Miss Rate
Determined by:
Program characteristics
Temporal locality
Spatial locality
Cache organization
Block size, associativity, number
Cache Miss Rate
Determined by:
Program characteristics
Temporal locality
Spatial locality
Cache organization
Block size, associativity, number

Improving Locality
Instruction text placement
Profile program, place unreferenced or rarely referenced paths
Improving Locality
Instruction text placement
Profile program, place unreferenced or rarely referenced paths

Improving Locality
Data placement, access order
Arrays: “block” loops to access subarray that
Improving Locality
Data placement, access order
Arrays: “block” loops to access subarray that
![Cache Miss Rates: 3 C’s [Hill] Compulsory miss First-ever reference](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/400725/slide-32.jpg)
Cache Miss Rates: 3 C’s [Hill]
Compulsory miss
First-ever reference to a given
Cache Miss Rates: 3 C’s [Hill]
Compulsory miss
First-ever reference to a given

Cache Miss Rate Effects
Number of blocks (sets x associativity)
Bigger is better:
Cache Miss Rate Effects
Number of blocks (sets x associativity)
Bigger is better:

Cache Miss Rate
Subtle tradeoffs between cache organization parameters
Large blocks reduce compulsory
Cache Miss Rate
Subtle tradeoffs between cache organization parameters
Large blocks reduce compulsory
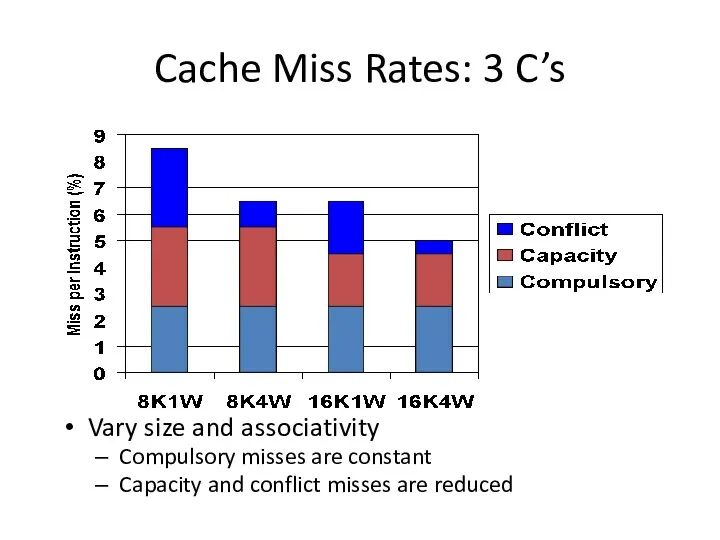
Cache Miss Rates: 3 C’s
Vary size and associativity
Compulsory misses are constant
Capacity
Cache Miss Rates: 3 C’s
Vary size and associativity
Compulsory misses are constant
Capacity
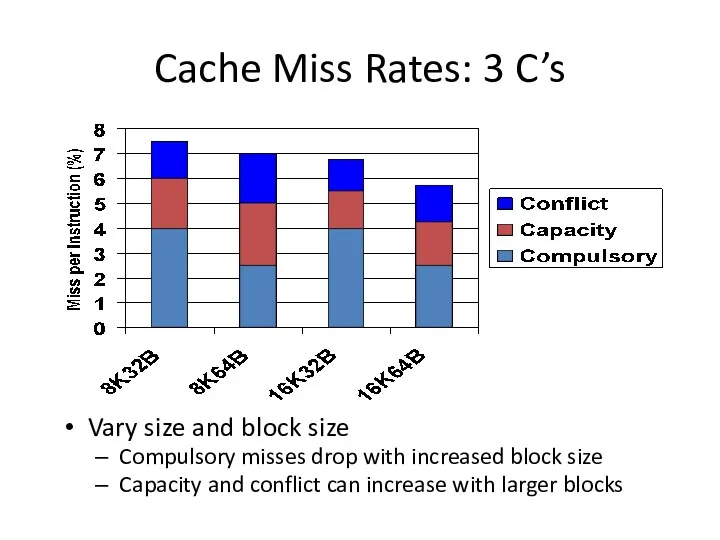
Cache Miss Rates: 3 C’s
Vary size and block size
Compulsory misses drop
Cache Miss Rates: 3 C’s
Vary size and block size
Compulsory misses drop
 Основные алгоритмические структуры
Основные алгоритмические структуры Табличное решение логических задач. (§ 2.6. 7 класс)
Табличное решение логических задач. (§ 2.6. 7 класс) Программа Microsoft word 2003. Списки
Программа Microsoft word 2003. Списки Электронды есептеуіш машиналардың аналогтық және цифрлық. Ақпаратты өңдеудің ақпараттық және бағдарламалық тәсілдері
Электронды есептеуіш машиналардың аналогтық және цифрлық. Ақпаратты өңдеудің ақпараттық және бағдарламалық тәсілдері Госорган в соцсетях. Жизнь или имитация
Госорган в соцсетях. Жизнь или имитация Современный медиатекст как средство социально-психологического воздействия: речевые стратегии и тактики
Современный медиатекст как средство социально-психологического воздействия: речевые стратегии и тактики Информация и информационные процессы
Информация и информационные процессы Правовые и этические нормы информационной деятельности человека
Правовые и этические нормы информационной деятельности человека Бұлттық есептеулер
Бұлттық есептеулер Программирование на языке Python. 9 класс
Программирование на языке Python. 9 класс Getting more physical in Call of Duty
Getting more physical in Call of Duty Культура оформлення комп’ютерної презентації
Культура оформлення комп’ютерної презентації Введение в САПР. Принципы построения САПР
Введение в САПР. Принципы построения САПР Основы классификации и структурирования информации
Основы классификации и структурирования информации Текстовый процессор MS Word
Текстовый процессор MS Word Язык программирования Java. Многопоточное программирование
Язык программирования Java. Многопоточное программирование Тема мастер класса: Роль текущего повторения для достижения результатов обучения.
Тема мастер класса: Роль текущего повторения для достижения результатов обучения. Динамическое моделирование. Моделирование физических законов
Динамическое моделирование. Моделирование физических законов Таблицы. Графические изображения. OpenOffice Writer Обработка текстовой информации
Таблицы. Графические изображения. OpenOffice Writer Обработка текстовой информации Протоколы и стеки протоколов
Протоколы и стеки протоколов 1C: ERP Управление предприятием. Новый помощник исправления остатков товаров организаций
1C: ERP Управление предприятием. Новый помощник исправления остатков товаров организаций Polymorphism. Создание проекта
Polymorphism. Создание проекта Информационные технологии: современные тренды
Информационные технологии: современные тренды Метод анализа иерархий
Метод анализа иерархий Добавляем эффект свечения для изображения в Фотошоп
Добавляем эффект свечения для изображения в Фотошоп Прошлое и будущее нейросетей: история развития и перспективы
Прошлое и будущее нейросетей: история развития и перспективы Устройства ввода
Устройства ввода АҚШ баспасөзі
АҚШ баспасөзі