- Модели данных. (Лекция 5)

Содержание
- 2. Модель данных – совокупность структур данных и операций их обработки (логическая структура данных в БД). иерархическая
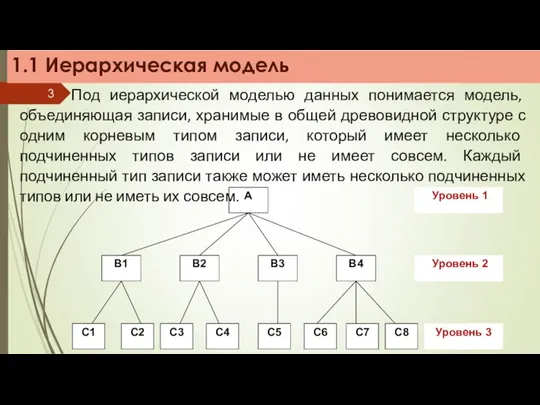
- 3. 1.1 Иерархическая модель Под иерархической моделью данных понимается модель, объединяющая записи, хранимые в общей древовидной структуре
- 4. Основные понятия: уровень узел (элемент) связь Узел – представляет объект предметной области. Объекты могут иметь как
- 5. 1.1 Иерархическая модель
- 6. Поиск указанного экземпляра БД Переход от одного дерева к другому Переход от одной записи к другой
- 7. 1.1 Иерархическая модель Самая сильная сторона иерархических структур — это скорость вставки новых узлов. Данные там
- 8. 1.1 Иерархическая модель 2. ОДНА ВЕРШИНА И МНОЖЕСТВО ВЕТВЕЙ Вообще — это классическая key-value база. А
- 9. 1.1 Иерархическая модель 3 ДВУХУРОВНЕВОЕ ДЕРЕВО, У КАЖДОГО УЗЛА ВТОРОГО УРОВНЯ ФИКСИРОВАННОЕ ЧИСЛО ВЕТВЕЙ
- 10. 1.1 Иерархическая модель 4 Объекты с подобъектами
- 11. 1.1 Иерархическая модель 5 Иерархические документы: XML, JSON Самый простой способ раскладки XML на глобалы, это
- 12. 1.1 Иерархическая модель 6 Одинаковые структуры, связанные иерархическими отношениями База дебютов. Можно в качестве значения индекса
- 13. 1.1 Иерархическая модель 6 Одинаковые структуры, связанные иерархическими отношениями Структура офисов продаж, структура людей в МЛМ.
- 14. 1.1 Иерархическая модель
- 15. 1.1 Иерархическая модель При вставке информации (комaнда Set) автоматически происходят 3 вещи: 1 Сохранение данных на
- 16. 1.1 Иерархическая модель При работе с обобщенной древовидной структурой используются два метода доступа ко всем узлам
- 17. ЛЕКЦИЯ 2 Достоинства эффективное использование памяти ЭВМ; хорошие показатели времени выполнения основных операций над данными. Недостатки
- 18. 1.2 Сетевая модель Под сетевой моделью данных понимается модель, состоящая из записей, элементов данных и связей
- 19. Позволяет отображать разнообразные связи элементов данных в виде произвольного графа, тем самым обобщая иерархическую модель. Структура
- 20. ЛЕКЦИЯ 2 1.2 Сетевая модель В качестве базовой физической структуры данных выступает сеть, в которой записи
- 21. ЛЕКЦИЯ 2 1.2 Сетевая модель
- 22. 1.2 Сетевая модель
- 23. Пример эквивалентных древовидных структур Партия товара 4 В С 1.2 Сетевая модель
- 24. ЛЕКЦИЯ 2 Основные операции манипулирования данными: поиск записей в БД; переход от предка к первому потомку;
- 25. Достоинства возможность эффективной реализации по показателям затрат памяти и оперативной обработки; большие возможности по сравнению с
- 26. Реляционная модель состоит из трех частей*: Структурной части. Целостной части. Манипуляционной части. * Крис Дейт. Введение
- 27. Целостная часть описывает ограничения специального вида, которые должны выполняться для любых отношений в любых реляционных базах
- 28. Таблица отражает тип объекта реального мира (сущность), а каждая ее строка (кортеж) – конкретный объект. Например,
- 29. 1.3 Реляционная модель Реляционная модель поддерживает связи типа «один к одному» и «один ко многим». Связи
- 30. Достоинства простота представления данных (таблица); минимальная избыточность данных, что достигается путем нормализации таблиц; независимость приложений пользователя
- 31. 1.3 Реляционная модель Доминирование реляционной модели в современных СУБД обусловлено рядом причин, в числе которых: наличие
- 32. 1.3 Реляционная модель Обычно различают три класса СУБД, обеспечивающих работу иерархических, сетевых и реляционных моделей. Можно
- 33. INVOICES (накладные) INVOICES_ITEMS (накладные_товары) 1.4 Постреляционная модель
- 34. Классическая реляционная модель предполагает неделимость данных хранящихся в полях записей таблицы (1 нормальная форма). Постреляционная модель
- 35. 1.4 Постреляционная модель Для выполнения постреляционного запроса должны быть реализованы соответствующие механизмы выборки. Постреляционная модель поддерживает
- 36. Недостатки: сложность решения проблемы обеспечения целостности и непротиворечивости данных (ограничения целостности накладываются на процедурном уровне. Для
- 37. Существует 2 направления в развитии ИС: системы оперативной или транзакционной обработки информации (весьма эффективны реляционные модели);
- 38. Основные понятия: Агрегируемость данных – возможность рассмотрения информации на разных уровнях ее обобщения. Историчность данных –
- 39. а) реляционное представление данных б) многомерное представление Пример: ЛЕКЦИЯ 2 1.5 Многомерная модель данных
- 40. Измерение (Dimension) – множество однотипных данных, образующих одну из граней многомерного объекта (гиперкуба). Ячейка гиперкуба (Cell)
- 41. ЛЕКЦИЯ 2 1.5 Многомерная модель данных
- 42. 1.5 Многомерная модель данных Достоинства Многомерная модель обладает большей наглядностью и информативностью, чем информационная модель. Удобство
- 43. 1.6 Объектно-ориентированная модель
- 44. Структура объектно-ориентированной БД графически представима в виде дерева, узлами которого являются объекты. Объектом является любой экземпляр
- 45. ЛЕКЦИЯ 2 Родовые отношения между объектами в БД образуют связную иерархию объектов и реализуются путем задания
- 47. Скачать презентацию

Модель данных – совокупность структур данных и операций их обработки (логическая
Модель данных – совокупность структур данных и операций их обработки (логическая
1.1 Иерархическая модель
Под иерархической моделью данных понимается модель, объединяющая записи, хранимые
1.1 Иерархическая модель
Под иерархической моделью данных понимается модель, объединяющая записи, хранимые

Основные понятия:
уровень
узел (элемент)
связь
Узел – представляет объект предметной области. Объекты могут иметь
Основные понятия:
уровень
узел (элемент)
связь
Узел – представляет объект предметной области. Объекты могут иметь
1.1 Иерархическая модель
1.1 Иерархическая модель

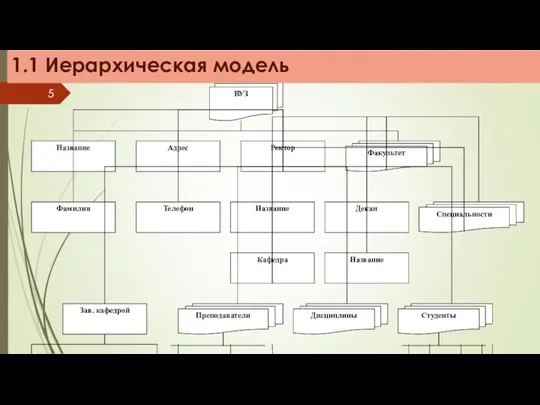
Поиск указанного экземпляра БД
Переход от одного дерева к другому
Переход от одной
Поиск указанного экземпляра БД
Переход от одного дерева к другому
Переход от одной

1.1 Иерархическая модель
Самая сильная сторона иерархических структур — это скорость вставки
1.1 Иерархическая модель
Самая сильная сторона иерархических структур — это скорость вставки

1.1 Иерархическая модель
2. ОДНА ВЕРШИНА И МНОЖЕСТВО ВЕТВЕЙ
Вообще — это классическая
1.1 Иерархическая модель
2. ОДНА ВЕРШИНА И МНОЖЕСТВО ВЕТВЕЙ
Вообще — это классическая
1.1 Иерархическая модель
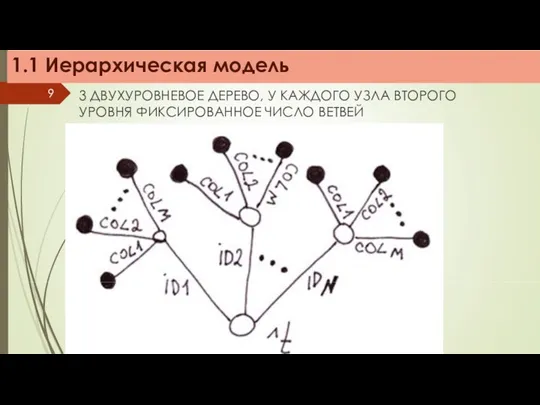
3 ДВУХУРОВНЕВОЕ ДЕРЕВО, У КАЖДОГО УЗЛА ВТОРОГО УРОВНЯ ФИКСИРОВАННОЕ
1.1 Иерархическая модель
3 ДВУХУРОВНЕВОЕ ДЕРЕВО, У КАЖДОГО УЗЛА ВТОРОГО УРОВНЯ ФИКСИРОВАННОЕ
1.1 Иерархическая модель
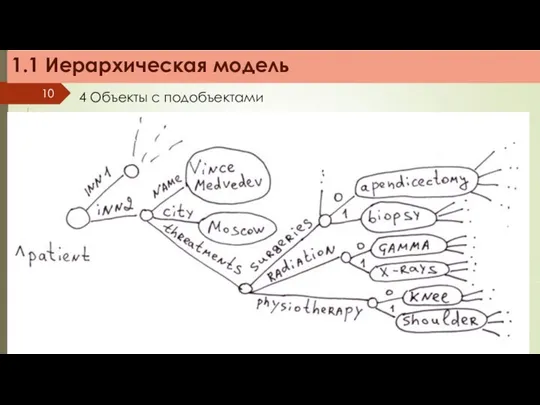
4 Объекты с подобъектами
1.1 Иерархическая модель
4 Объекты с подобъектами

1.1 Иерархическая модель
5 Иерархические документы: XML, JSON
Самый простой способ раскладки XML
1.1 Иерархическая модель
5 Иерархические документы: XML, JSON
Самый простой способ раскладки XML
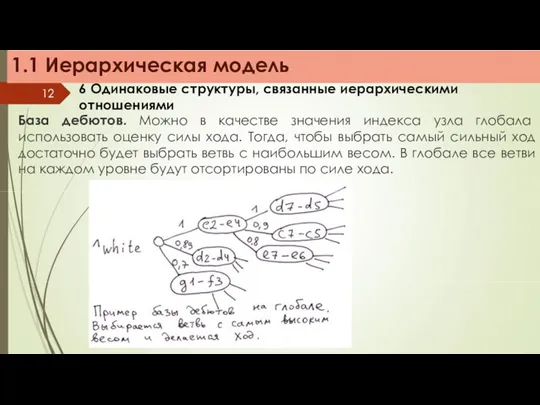
1.1 Иерархическая модель
6 Одинаковые структуры, связанные иерархическими отношениями
База дебютов. Можно в
1.1 Иерархическая модель
6 Одинаковые структуры, связанные иерархическими отношениями
База дебютов. Можно в
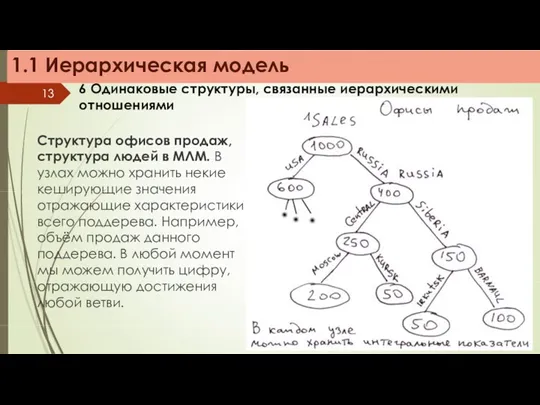
1.1 Иерархическая модель
6 Одинаковые структуры, связанные иерархическими отношениями
Структура офисов продаж, структура
1.1 Иерархическая модель
6 Одинаковые структуры, связанные иерархическими отношениями
Структура офисов продаж, структура

1.1 Иерархическая модель
1.1 Иерархическая модель

1.1 Иерархическая модель
При вставке информации (комaнда Set) автоматически происходят 3 вещи:
1
1.1 Иерархическая модель
При вставке информации (комaнда Set) автоматически происходят 3 вещи:
1

1.1 Иерархическая модель
При работе с обобщенной древовидной структурой используются два метода
1.1 Иерархическая модель
При работе с обобщенной древовидной структурой используются два метода

ЛЕКЦИЯ 2
Достоинства
эффективное использование памяти ЭВМ;
хорошие показатели времени выполнения основных операций
ЛЕКЦИЯ 2
Достоинства
эффективное использование памяти ЭВМ;
хорошие показатели времени выполнения основных операций
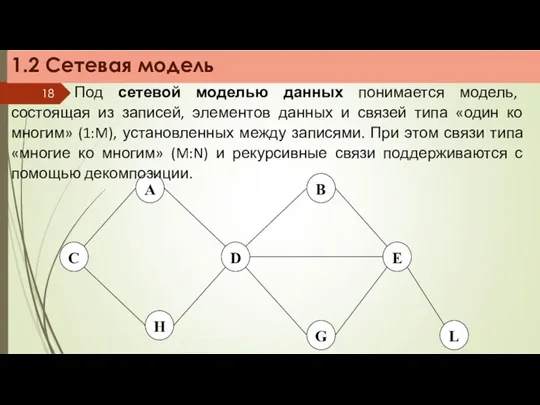
1.2 Сетевая модель
Под сетевой моделью данных понимается модель, состоящая из записей,
1.2 Сетевая модель
Под сетевой моделью данных понимается модель, состоящая из записей,

Позволяет отображать разнообразные связи элементов данных в виде произвольного графа, тем
Позволяет отображать разнообразные связи элементов данных в виде произвольного графа, тем

ЛЕКЦИЯ 2
1.2 Сетевая модель
В качестве базовой физической структуры данных выступает сеть,
ЛЕКЦИЯ 2
1.2 Сетевая модель
В качестве базовой физической структуры данных выступает сеть,
ЛЕКЦИЯ 2
1.2 Сетевая модель
ЛЕКЦИЯ 2
1.2 Сетевая модель
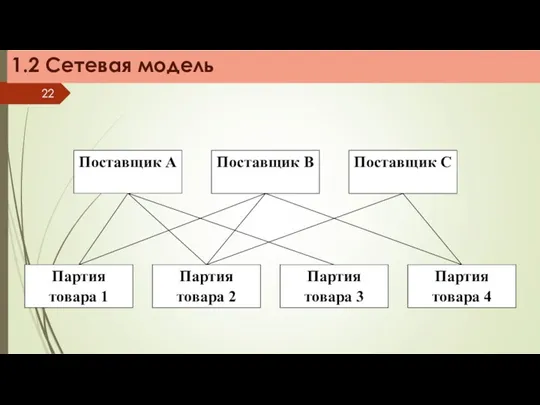
1.2 Сетевая модель
1.2 Сетевая модель
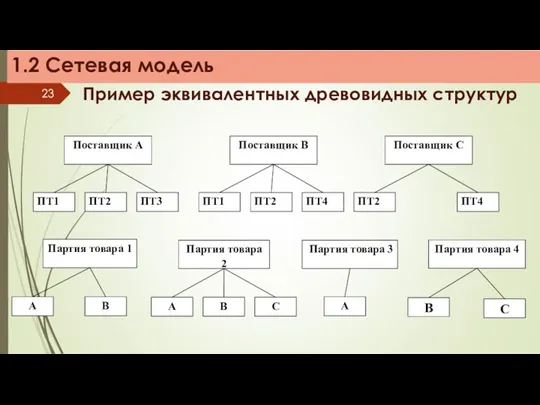
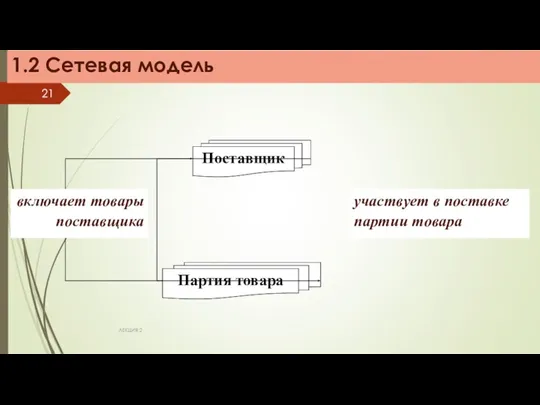
Пример эквивалентных древовидных структур
Партия товара 4
В
С
1.2 Сетевая модель
Пример эквивалентных древовидных структур
Партия товара 4
В
С
1.2 Сетевая модель

ЛЕКЦИЯ 2
Основные операции
манипулирования данными:
поиск записей в БД;
переход от предка к
ЛЕКЦИЯ 2
Основные операции
манипулирования данными:
поиск записей в БД;
переход от предка к

Достоинства
возможность эффективной реализации по показателям затрат памяти и оперативной обработки;
большие возможности
Достоинства
возможность эффективной реализации по показателям затрат памяти и оперативной обработки;
большие возможности

Реляционная модель
состоит из трех частей*:
Структурной части.
Целостной части.
Манипуляционной части.
* Крис Дейт.
Реляционная модель
состоит из трех частей*:
Структурной части.
Целостной части.
Манипуляционной части.
* Крис Дейт.

Целостная часть описывает ограничения специального вида, которые должны выполняться для любых
Целостная часть описывает ограничения специального вида, которые должны выполняться для любых

Таблица отражает тип объекта реального мира (сущность), а каждая ее строка
Таблица отражает тип объекта реального мира (сущность), а каждая ее строка
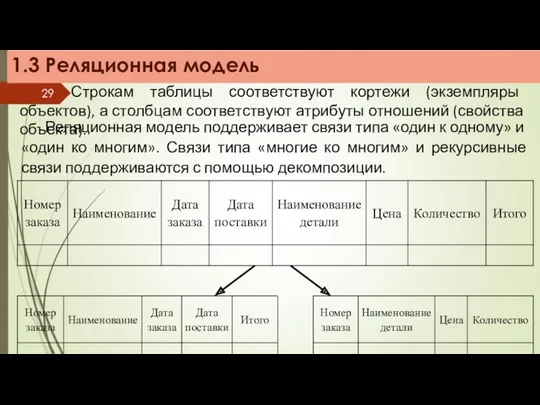
1.3 Реляционная модель
Реляционная модель поддерживает связи типа «один к одному»
1.3 Реляционная модель
Реляционная модель поддерживает связи типа «один к одному»

Достоинства
простота представления данных (таблица);
минимальная избыточность данных, что достигается путем нормализации таблиц;
независимость
Достоинства
простота представления данных (таблица);
минимальная избыточность данных, что достигается путем нормализации таблиц;
независимость

1.3 Реляционная модель
Доминирование реляционной модели в современных СУБД обусловлено рядом причин,
1.3 Реляционная модель
Доминирование реляционной модели в современных СУБД обусловлено рядом причин,

1.3 Реляционная модель
Обычно различают три класса СУБД, обеспечивающих работу иерархических, сетевых
1.3 Реляционная модель
Обычно различают три класса СУБД, обеспечивающих работу иерархических, сетевых
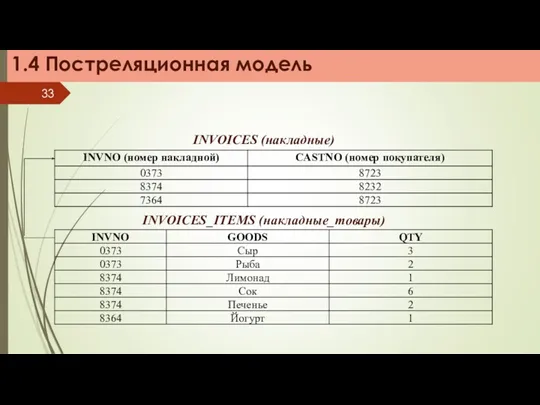
INVOICES (накладные)
INVOICES_ITEMS (накладные_товары)
1.4 Постреляционная модель
INVOICES (накладные)
INVOICES_ITEMS (накладные_товары)
1.4 Постреляционная модель
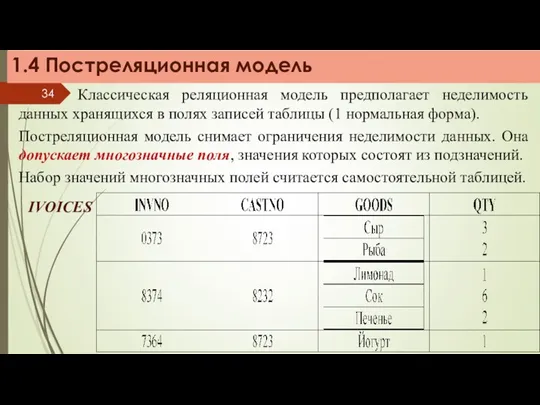
Классическая реляционная модель предполагает неделимость данных хранящихся в полях записей таблицы
Классическая реляционная модель предполагает неделимость данных хранящихся в полях записей таблицы

1.4 Постреляционная модель
Для выполнения постреляционного запроса должны быть реализованы соответствующие механизмы
1.4 Постреляционная модель
Для выполнения постреляционного запроса должны быть реализованы соответствующие механизмы

Недостатки:
сложность решения проблемы обеспечения целостности и непротиворечивости данных (ограничения целостности накладываются
Недостатки:
сложность решения проблемы обеспечения целостности и непротиворечивости данных (ограничения целостности накладываются

Существует 2 направления в развитии ИС:
системы оперативной или транзакционной обработки информации
Существует 2 направления в развитии ИС:
системы оперативной или транзакционной обработки информации

Основные понятия:
Агрегируемость данных – возможность рассмотрения информации на разных уровнях ее
Основные понятия:
Агрегируемость данных – возможность рассмотрения информации на разных уровнях ее
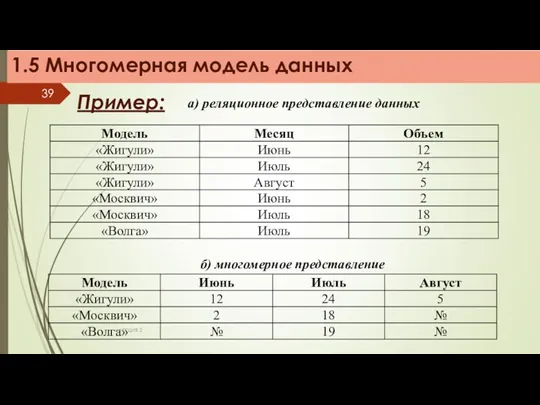
а) реляционное представление данных
б) многомерное представление
Пример:
ЛЕКЦИЯ 2
1.5 Многомерная модель данных
а) реляционное представление данных
б) многомерное представление
Пример:
ЛЕКЦИЯ 2
1.5 Многомерная модель данных

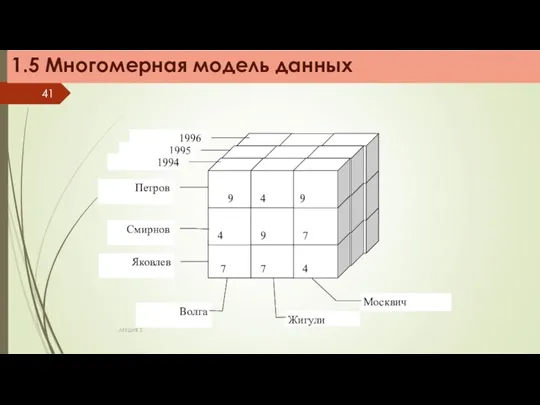
Измерение (Dimension) – множество однотипных данных, образующих одну из граней многомерного
Измерение (Dimension) – множество однотипных данных, образующих одну из граней многомерного
ЛЕКЦИЯ 2
1.5 Многомерная модель данных
ЛЕКЦИЯ 2
1.5 Многомерная модель данных

1.5 Многомерная модель данных
Достоинства
Многомерная модель обладает большей наглядностью и информативностью, чем
1.5 Многомерная модель данных
Достоинства
Многомерная модель обладает большей наглядностью и информативностью, чем
1.6 Объектно-ориентированная модель
1.6 Объектно-ориентированная модель

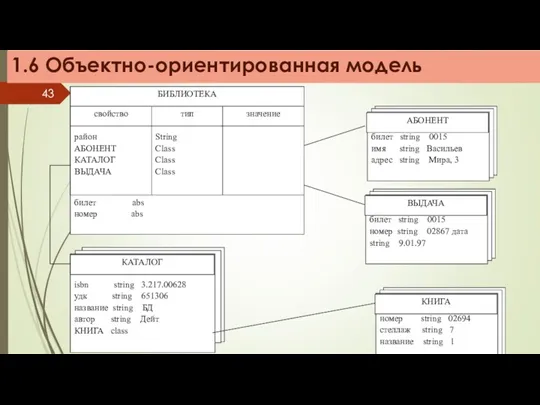
Структура объектно-ориентированной БД графически представима в виде дерева, узлами которого являются
Структура объектно-ориентированной БД графически представима в виде дерева, узлами которого являются

ЛЕКЦИЯ 2
Родовые отношения между объектами в БД образуют связную иерархию объектов
ЛЕКЦИЯ 2
Родовые отношения между объектами в БД образуют связную иерархию объектов
 Ideas about site. Dental laboratory
Ideas about site. Dental laboratory Разработка WPF приложений в стиле ViewModel First
Разработка WPF приложений в стиле ViewModel First Пространственная фильтрация, обработка в частотной области и восстановление изображения (Matlab)
Пространственная фильтрация, обработка в частотной области и восстановление изображения (Matlab) Концепция (архитектура) IMS. Как вписать архитектуру IMS в действующее регулирование
Концепция (архитектура) IMS. Как вписать архитектуру IMS в действующее регулирование Разработка аппаратно-программного комплекса имитации нестабильности напряжения в сетях постоянного тока
Разработка аппаратно-программного комплекса имитации нестабильности напряжения в сетях постоянного тока Поиск целевого трафика Вконтакте
Поиск целевого трафика Вконтакте Инфокоммуникационная сеть, как большая и сложная система
Инфокоммуникационная сеть, как большая и сложная система Java.SE.07 Multithreading
Java.SE.07 Multithreading Создание 3D пазл для детей младшего возраста
Создание 3D пазл для детей младшего возраста Dark-Wave
Dark-Wave Проектная тематика. Компьютерные технологии анализа данных и исследования статистических закономерностей и анализ больших данных
Проектная тематика. Компьютерные технологии анализа данных и исследования статистических закономерностей и анализ больших данных MNGT 1710 Course Resources
MNGT 1710 Course Resources Основы журналистики. Пражурналистика и формирование журналистики
Основы журналистики. Пражурналистика и формирование журналистики Создание 3D модели острова в программе Blender
Создание 3D модели острова в программе Blender Использование оборудования фирмы Iskratel для построения мультисервисных сетей
Использование оборудования фирмы Iskratel для построения мультисервисных сетей Язык UML. Диаграммы деятельности. Варианты использования
Язык UML. Диаграммы деятельности. Варианты использования PHP #1.1. Введение. Быстрый старт
PHP #1.1. Введение. Быстрый старт Разработка информационной системы для службы технической поддержки пользователей ЗАО Металлургприбор
Разработка информационной системы для службы технической поддержки пользователей ЗАО Металлургприбор SWIFT Professional Services I Alliance Lite2 Kick-off
SWIFT Professional Services I Alliance Lite2 Kick-off Операционные системы Windows от XP к 7
Операционные системы Windows от XP к 7 Программаларды өңдеудің аспаптың құралдары (ПӨАҚ)
Программаларды өңдеудің аспаптың құралдары (ПӨАҚ) Інформаційна зброя
Інформаційна зброя Способы кодирования информации
Способы кодирования информации TLS and SSL
TLS and SSL Информационная безопасность. Криптографические средства защиты данных
Информационная безопасность. Криптографические средства защиты данных Доставка терминалов. Собственный процессинг
Доставка терминалов. Собственный процессинг Введение в R
Введение в R Корпоративные информационные системы. Информационные технологии и системы в менеджменте. Тема 1
Корпоративные информационные системы. Информационные технологии и системы в менеджменте. Тема 1