разделимыми, без ошибок классифицируются большинством методов классификации, однако, понимая это, лучшими методами классификации в данном случае будут являться линейные, т.к. они являются наиболее простыми и быстрыми и наименее трудоёмкими
Постановка задачи: Провести оценку классификации предоставленных данных различными методами и произвести оценку эффективности
Метод решения: Обработка данных их классификация с использованием возможностей Jupyter lab
Рисунок 7 — Матрица диаграммы рассеивания
PCA(n_components=2)
Массив train: (48, 16)
Массив test: (16, 16)
Массив train_PCA: (48, 2)
Массива test_PCA: (16, 2)
Таблица 1 — Сравнение методов классификации с PCA и без
НЕТ ИССЛЕДОВАНИЯ!!!
НУЖНО НА ВСЕХ МЕТОДАХ ПРОСМОТРЕТЬ ВСЕ ПАРАМЕТРЫ(КОТОРЫЕ МЫ ИЗУЧАЛИ) В РАЗНЫХ КОМБИНАЦИЯХ И ЭТО ПРЕДСТАВИТЬ!
СКАЗАТЬ С КАКИМИ ПАРАМЕТРАМИ ЛУЧШЕ!

 Искусственный интеллект как ключевой драйвер цифровизации. Возможности и вызовы
Искусственный интеллект как ключевой драйвер цифровизации. Возможности и вызовы Методы проектирования МКА
Методы проектирования МКА Концептуальное проектирование базы данных
Концептуальное проектирование базы данных Веб-дизайн и разработка. Техническое описание компетенции
Веб-дизайн и разработка. Техническое описание компетенции Компьютерные сети
Компьютерные сети Как создать опрос в Google Form
Как создать опрос в Google Form Грошові перекази та інтернет- магазини
Грошові перекази та інтернет- магазини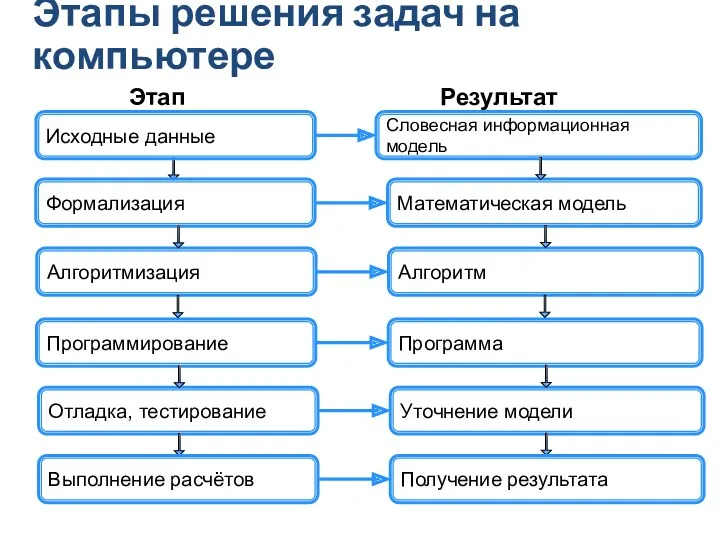 Этапы решения задач на компьютере
Этапы решения задач на компьютере Справочные, энциклопедические издания. Терминологические, лингвистические словари
Справочные, энциклопедические издания. Терминологические, лингвистические словари Компоненты ЛВС. Сетевое оборудование
Компоненты ЛВС. Сетевое оборудование Переменные в Scratch
Переменные в Scratch Разработка сайта “Интернет - магазин одежды Dieshh
Разработка сайта “Интернет - магазин одежды Dieshh Як стати профі. Що має знати веб-розробник
Як стати профі. Що має знати веб-розробник Scratch Урок 7. Проект 6. Меняем фон сцены
Scratch Урок 7. Проект 6. Меняем фон сцены Брейн-ринг
Брейн-ринг Построение диаграмм с использованием Мастера диаграмм при изучении текстового процессора Microsoft Word
Построение диаграмм с использованием Мастера диаграмм при изучении текстового процессора Microsoft Word Understanding Databases
Understanding Databases Программирование на языке ассемблер. Система команд процессора
Программирование на языке ассемблер. Система команд процессора Районная научно-практическая конференция для учащихся 5-8 классов Шаг в науку Тема: Российские чемпионы и призёры Олимпиады в Сочи 2014 . проект.
Районная научно-практическая конференция для учащихся 5-8 классов Шаг в науку Тема: Российские чемпионы и призёры Олимпиады в Сочи 2014 . проект. Сетевое оборудование
Сетевое оборудование SVG: Syntax Sprites Animation
SVG: Syntax Sprites Animation Phone paint detector. Главные проблемы
Phone paint detector. Главные проблемы Языки программирования
Языки программирования Лекция 6. Сетевые методы и графы в автоматизированном управлении
Лекция 6. Сетевые методы и графы в автоматизированном управлении Компьютерные сети. Общая характеристика и классификация компьютерных сетей
Компьютерные сети. Общая характеристика и классификация компьютерных сетей Принципы построения ОС. Основные принципы построения ОС
Принципы построения ОС. Основные принципы построения ОС Патентные базы данных в сети интернет. Международные и национальные проекты
Патентные базы данных в сети интернет. Международные и национальные проекты Состав компьютера
Состав компьютера