- Описательная статистика. Группировка данных. Лекция 2

Содержание
- 2. 2.1. Группировка данных
- 3. Обработку данных полезно начать с их группировки… Группировка - это систематизация первичных данных, направленная на извлечение
- 4. Пример: медицинские сведения Пол (м, ж) Возраст (полных лет) Группа крови (I, II, III, IV) Систолическое
- 5. Группировка количественных данных : по значениям вариант по классам Представление частотного распределения графически
- 6. При небольшом n и незначительной вариации признака, количественные данные группируют по значениям вариант (полигон распределения)
- 7. Гистограмма: данные группируются по классам
- 8. Какую информацию дает вариационный ряд и его график? Границы изменчивости признака: минимальное и максимальное значение вариант,
- 9. Характер вариации признака: исследователь может установить симметричность распределения
- 10. а также моду (наиболее часто встречающееся значение) (хi): 2 3 4 5 (fi): 1 2 5
- 11. Круговые диаграммы (Pie chart) (для качественных признаков) Включают все категории которые формируют совокупность Используют, чтобы изобразить
- 12. 2.2. Среднее значение и стандартное отклонение
- 13. Любое нормальное распределение можно описать с помощью всего двух параметров: среднего значения (µ) и стандартного отклонения
- 14. ВЫБОРОЧНАЯ СРЕДНЯЯ (англ.: sample mean) (= средняя арифметическая)
- 15. ВЗВЕШЕННАЯ СРЕДНЯЯ (англ.: Weighted mean):
- 16. СРЕДНЯЯ ГЕОМЕТРИЧЕСКАЯ (англ.: Geometric mean):
- 17. Выборка 1 Выборка 2 2.5 Одинаковы ли выборки ???????
- 18. Выборка 1 Выборка 2 2.5 Размах Размах = 3 Размах = 1
- 19. Размах одинаковый 10 15 20 25 30 35 40 45 50 10 28 28 30 30
- 20. Находим расстояние, на котором находится каждая единица изучаемой выборки от среднего значения: Избавляемся от отрицательных значений
- 21. Усредняем вычисленные расстояния и получаем дисперсию (англ.: variance): SS (sum of squares) – сумма квадратов
- 22. Извлекая корень из дисперсии, получаем стандартное отклонение (англ.: standard deviation; SD):
- 23. Несмещенные оценки дисперсии и стандартного отклонения (для малых n): ЧИСЛО СТЕПЕНЕЙ СВОБОДЫ (df)
- 24. 2.3. Медиана и процентили
- 25. Для нахождения: выстроить данные min max если n нечетное, ищем центральное значение (n+1)/2 если n четное,
- 26. Медиана Значение, половина данных в совокупности больше которого, а половина – меньше n – нечетное: 34
- 27. n – четное: 30 33 34 37 40 41 42 43 44 45 n=10 Mе= X(n+1)/2=X(9+1)/2=X5.5=
- 28. ВЫВОДЫ: Если известно, что выборка скорее всего принадлежит к совокупности с нормальным распределением, для ее описания
- 30. Скачать презентацию

2.1. Группировка данных
2.1. Группировка данных

Обработку данных полезно начать с их группировки…
Группировка - это систематизация первичных
Обработку данных полезно начать с их группировки…
Группировка - это систематизация первичных

Пример: медицинские сведения
Пол (м, ж)
Возраст (полных лет)
Группа крови (I, II, III,
Пример: медицинские сведения
Пол (м, ж)
Возраст (полных лет)
Группа крови (I, II, III,
Группировка
количественных данных :
по значениям вариант
по классам
Представление частотного распределения графически
Группировка
количественных данных :
по значениям вариант
по классам
Представление частотного распределения графически
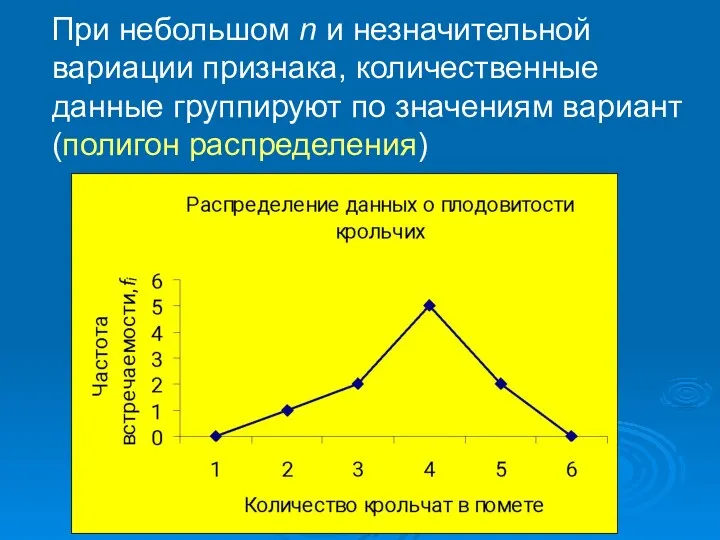
При небольшом n и незначительной вариации признака, количественные данные группируют
При небольшом n и незначительной вариации признака, количественные данные группируют
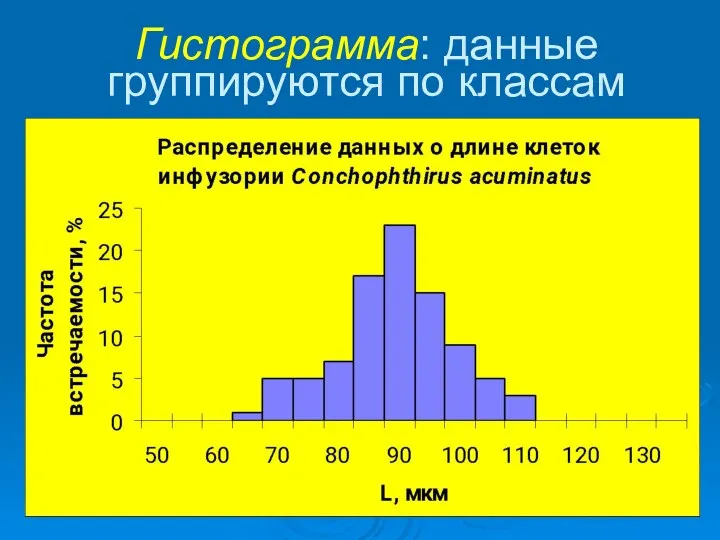
Гистограмма: данные группируются по классам
Гистограмма: данные группируются по классам

Какую информацию дает вариационный ряд и его график?
Границы изменчивости признака: минимальное
Какую информацию дает вариационный ряд и его график?
Границы изменчивости признака: минимальное
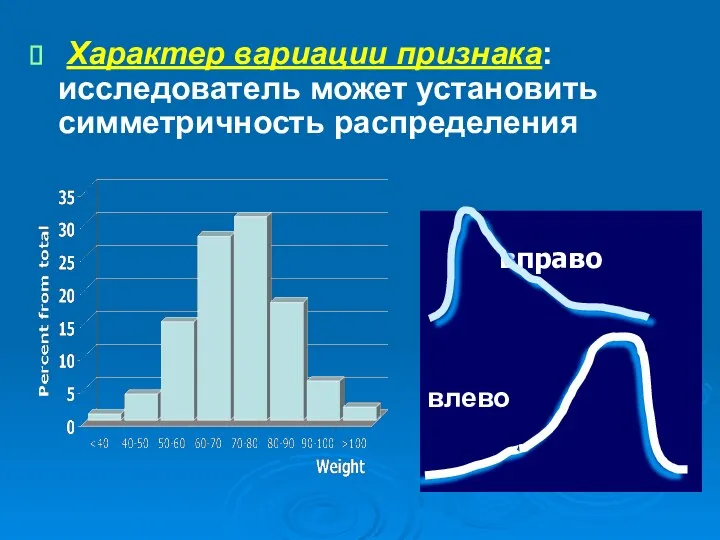
Характер вариации признака: исследователь может установить симметричность распределения
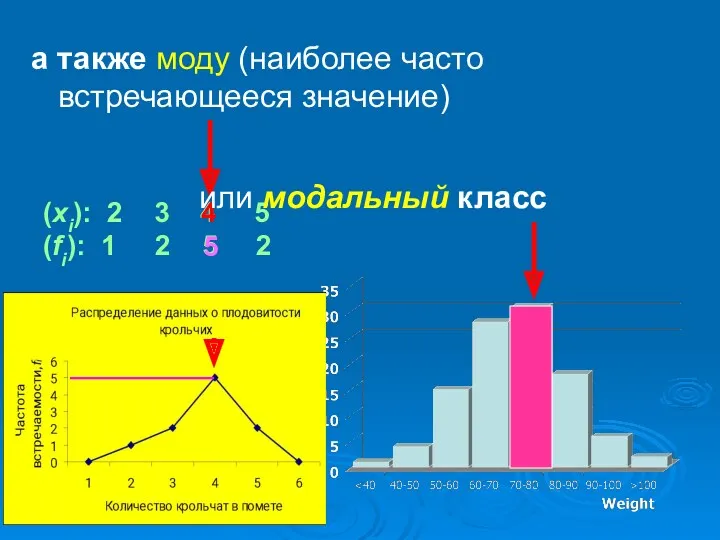
а также моду (наиболее часто встречающееся значение)
(хi): 2 3 4 5
(fi):
(хi): 2 3 4 5
(fi):

Круговые диаграммы (Pie chart)
(для качественных признаков)
Включают все категории которые формируют
Круговые диаграммы (Pie chart)
(для качественных признаков)
Включают все категории которые формируют

2.2. Среднее значение и стандартное отклонение
2.2. Среднее значение и стандартное отклонение

Любое нормальное распределение можно описать с помощью всего двух параметров:
среднего
Любое нормальное распределение можно описать с помощью всего двух параметров: среднего

ВЫБОРОЧНАЯ СРЕДНЯЯ
(англ.: sample mean)
(= средняя арифметическая)
ВЫБОРОЧНАЯ СРЕДНЯЯ
(англ.: sample mean)
(= средняя арифметическая)

ВЗВЕШЕННАЯ СРЕДНЯЯ
(англ.: Weighted mean):
ВЗВЕШЕННАЯ СРЕДНЯЯ
(англ.: Weighted mean):

СРЕДНЯЯ ГЕОМЕТРИЧЕСКАЯ (англ.: Geometric mean):
СРЕДНЯЯ ГЕОМЕТРИЧЕСКАЯ (англ.: Geometric mean):

Выборка 1
Выборка 2
2.5
Одинаковы ли выборки ???????
Выборка 1
Выборка 2
2.5
Одинаковы ли выборки ???????
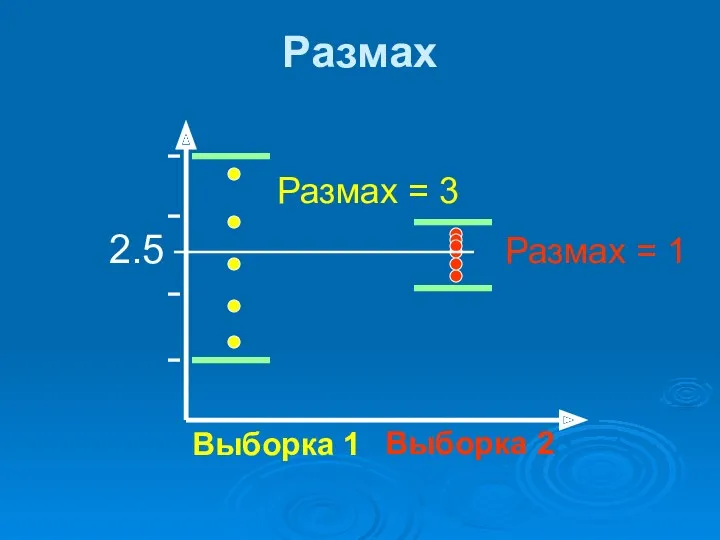
Выборка 1
Выборка 2
2.5
Размах
Размах = 3
Размах = 1
Выборка 1
Выборка 2
2.5
Размах
Размах = 3
Размах = 1

Размах одинаковый
10 15 20 25 30 35 40 45 50
10 28
Размах одинаковый
10 15 20 25 30 35 40 45 50
10 28

Находим расстояние, на котором находится каждая единица изучаемой выборки от среднего
Находим расстояние, на котором находится каждая единица изучаемой выборки от среднего

Усредняем вычисленные расстояния и получаем дисперсию (англ.: variance):
SS (sum of squares)
Усредняем вычисленные расстояния и получаем дисперсию (англ.: variance):
SS (sum of squares)

Извлекая корень из дисперсии, получаем стандартное отклонение (англ.: standard deviation; SD):
Извлекая корень из дисперсии, получаем стандартное отклонение (англ.: standard deviation; SD):

Несмещенные оценки дисперсии и стандартного отклонения (для малых n):
ЧИСЛО СТЕПЕНЕЙ СВОБОДЫ
Несмещенные оценки дисперсии и стандартного отклонения (для малых n):
ЧИСЛО СТЕПЕНЕЙ СВОБОДЫ

2.3. Медиана и процентили
2.3. Медиана и процентили

Для нахождения:
выстроить данные min max
если n нечетное, ищем центральное значение (n+1)/2
если
Для нахождения:
выстроить данные min max
если n нечетное, ищем центральное значение (n+1)/2
если
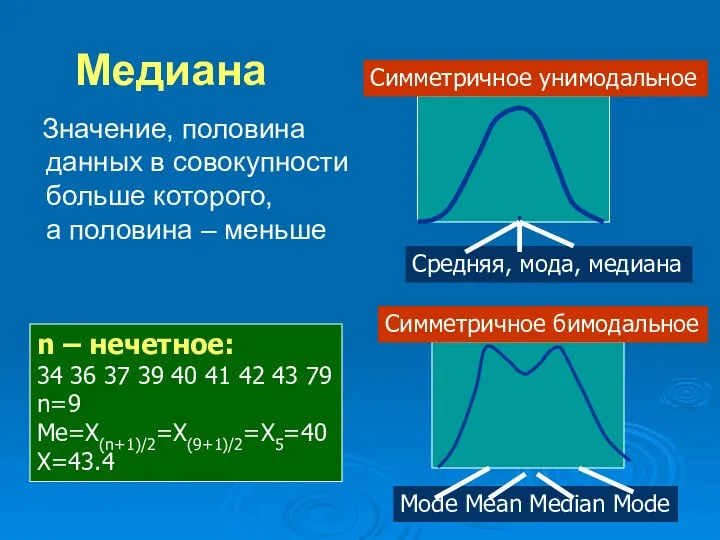
Медиана
Значение, половина данных в совокупности больше которого,
а половина –
Медиана
Значение, половина данных в совокупности больше которого, а половина –

n – четное:
30 33 34 37 40 41 42 43 44
n – четное:
30 33 34 37 40 41 42 43 44

ВЫВОДЫ:
Если известно, что выборка скорее всего принадлежит к совокупности с нормальным
ВЫВОДЫ:
Если известно, что выборка скорее всего принадлежит к совокупности с нормальным
 Уровень приложений. Основы сетевых технологий
Уровень приложений. Основы сетевых технологий Front-end разработка
Front-end разработка Безопасный Интернет
Безопасный Интернет Основы теории компьютерной безопасности
Основы теории компьютерной безопасности Создание учебных курсов в системе Moodle
Создание учебных курсов в системе Moodle Стандарт OpenMP. Информационные ресурсы. Лекция 3
Стандарт OpenMP. Информационные ресурсы. Лекция 3 Динамические переменные и массивы
Динамические переменные и массивы Информатика для детей
Информатика для детей Бази даних. Системи управління базами даних
Бази даних. Системи управління базами даних Текстовый процессор Microsoft Word 2010
Текстовый процессор Microsoft Word 2010 Программирование на алгоритмическом языке (§ 62 - § 68)
Программирование на алгоритмическом языке (§ 62 - § 68)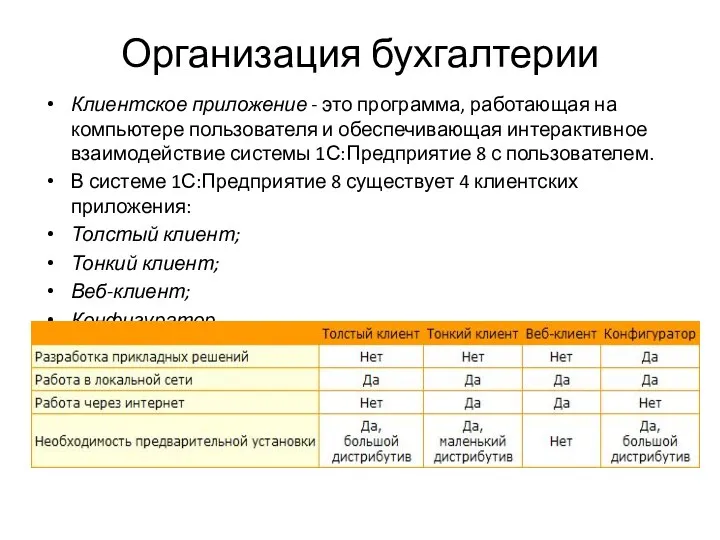 Организация бухгалтерии
Организация бухгалтерии Flex-box - система компоновки элементов
Flex-box - система компоновки элементов Тэгтердің атрибуттары. Мәтінді. Безендіру
Тэгтердің атрибуттары. Мәтінді. Безендіру Протокол HTTP
Протокол HTTP ЭВМ и периферийные устройства. Системы ввода-вывода. (Лекция 6)
ЭВМ и периферийные устройства. Системы ввода-вывода. (Лекция 6) 46_Yaroslavskaya_Sasha
46_Yaroslavskaya_Sasha Игра. Условное представление.часть1
Игра. Условное представление.часть1 Информационные технологии в школе.
Информационные технологии в школе. Flutter в действии
Flutter в действии Объектно-признаковые ИПЯ
Объектно-признаковые ИПЯ Математические модели и области их применения
Математические модели и области их применения Базы данных SQL
Базы данных SQL Преобразования типов. Лекция 4
Преобразования типов. Лекция 4 Социальные сети в жизни обучающихся
Социальные сети в жизни обучающихся Графические возможности PascalABC
Графические возможности PascalABC Решение задач ЕГЭ типа А5
Решение задач ЕГЭ типа А5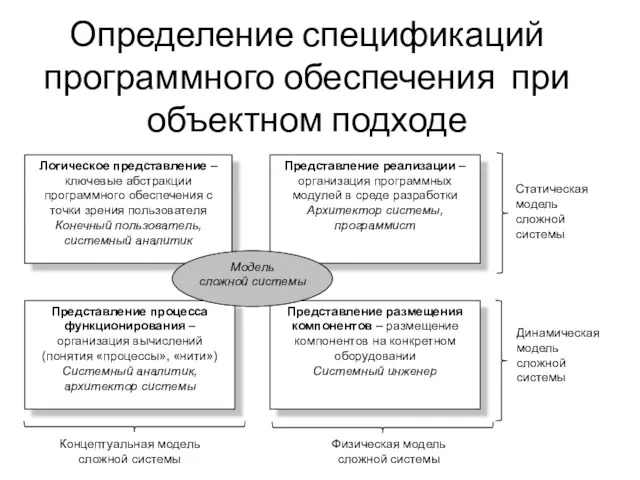 Определение спецификаций программного обеспечения при объектном подходе
Определение спецификаций программного обеспечения при объектном подходе