- Описательные статистики. Корреляционная матрица. Лекция 3

Содержание
- 2. Для выбора переменной, описательные статистики которой нас интересуют, надо нажать кнопку Variables и в открывшемся окне
- 3. Посчитаем описательные статистики для файла Страны мира, рассмотренном на предыдущем занятии.
- 4. Для запуска программы в верхнем меню Statistics надо выбрать команду Basic Statistic Tables (основные статистики/таблицы).
- 5. В появившемся меню надо выбрать команду Descriptive statistics (описательные статистики)
- 6. Откроется окно на вкладке Быстрый, воспользуемся кнопкой Переменные,
- 7. Укажем 3 количественные переменные и перейдем на вкладку дополнительно , где приведены основные статистики, характеризующие случайные
- 9. Рассмотрим более подробно дополнительные статистики, предусмотренные в этом модуле. Статистики, используемые в данном модуле, в основном
- 10. Квантиль, соответствующая вероятности p, это значение переменной, ниже которой находится p-я часть (доля) выборки. Квантили, соответствующие
- 11. Мода – это значение переменной, соответствующее наибольшей частоте появления переменной в выборке. Как правило, используется для
- 12. Range (размах) – это разность между максимальным и минимальным значениями выборки. Quartiles range (квартильный размах) равен
- 13. Нажмем на кнопку Подробные описательные статистики на вкладке Дополнительно, или Быстро. Вычисление медианы для Пром.: 26,
- 14. Между переменными (случайными величинами) может существовать функциональная связь, проявляющаяся в том, что одна из них определяется
- 15. Если переменные независимы, то коэффициент корреляции равен 0 (обратное утверждение верно только для переменных, имеющих нормальное
- 16. Для построения корреляционной матрицы в верхнем меню Statistics надо выбрать команду Basic Statistic Tables, откроется меню
- 19. Если нажать на кнопку Матричная диаграмма рассеяния, то появится график на котором будут изображены парные диаграммы
- 21. Если нажать на кнопку Графики, то появится 3 диаграммы рассеяний с доверительными интервалами на 3 отдельных
- 24. Если перейти на вкладку Опции, то можно в таблицу отобразить уровни значимости коэффициентов корреляции, построить более
- 27. Скачать презентацию

Для выбора переменной, описательные статистики которой нас интересуют, надо нажать
Для выбора переменной, описательные статистики которой нас интересуют, надо нажать
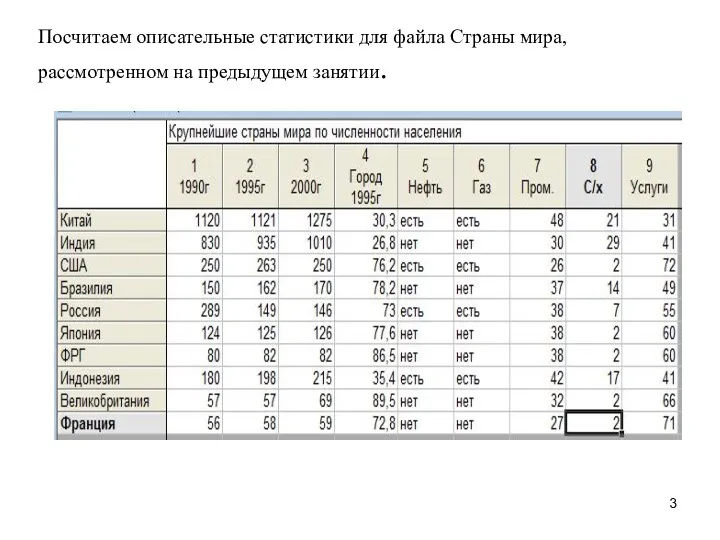
Посчитаем описательные статистики для файла Страны мира, рассмотренном на предыдущем занятии.
Посчитаем описательные статистики для файла Страны мира, рассмотренном на предыдущем занятии.
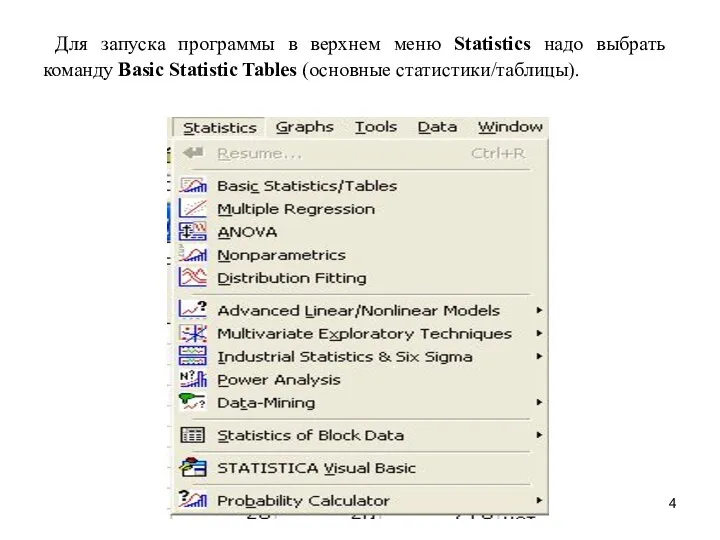
Для запуска программы в верхнем меню Statistics надо выбрать команду
Для запуска программы в верхнем меню Statistics надо выбрать команду
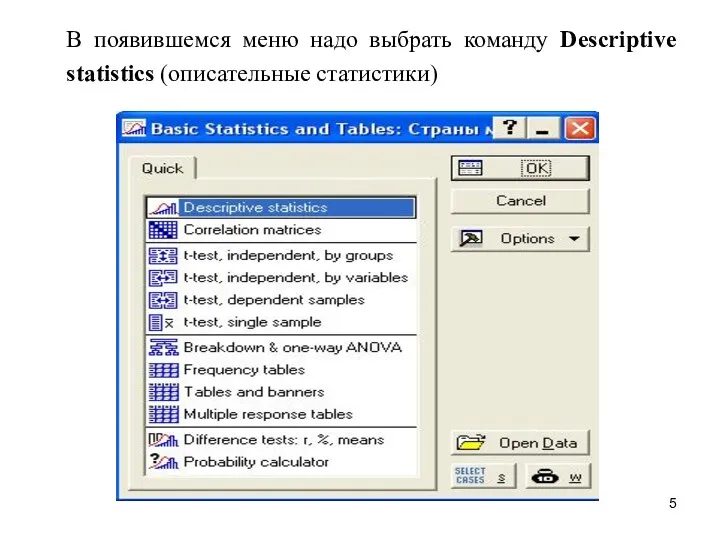
В появившемся меню надо выбрать команду Descriptive statistics (описательные статистики)
В появившемся меню надо выбрать команду Descriptive statistics (описательные статистики)
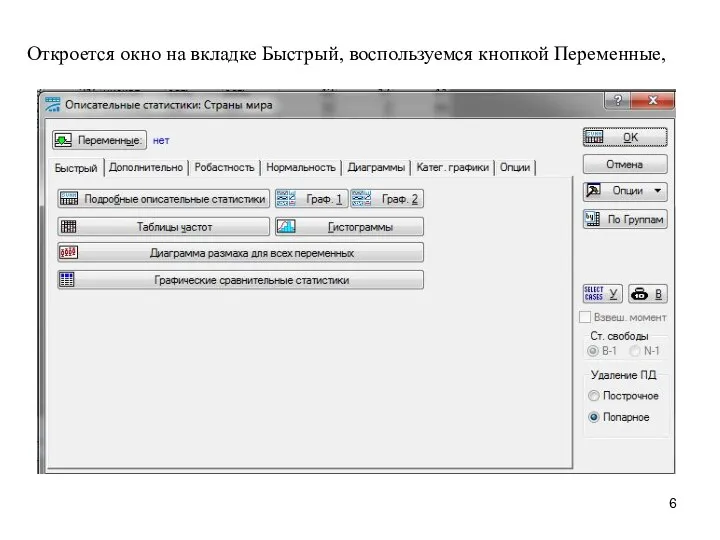
Откроется окно на вкладке Быстрый, воспользуемся кнопкой Переменные,
Откроется окно на вкладке Быстрый, воспользуемся кнопкой Переменные,
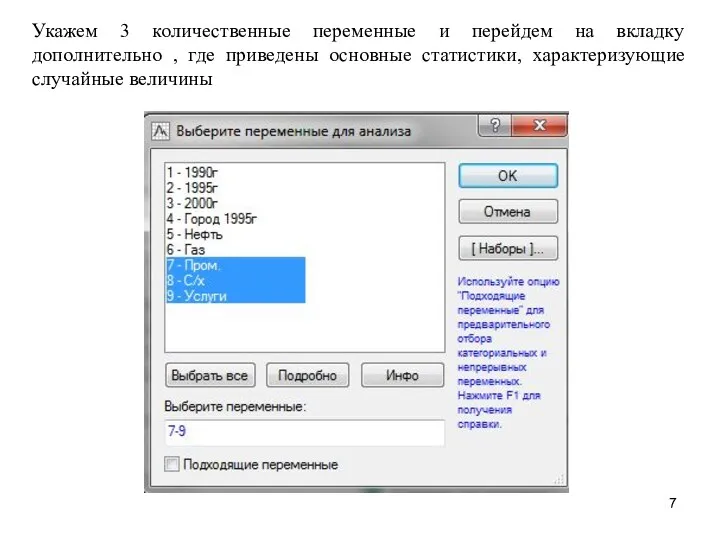
Укажем 3 количественные переменные и перейдем на вкладку дополнительно , где
Укажем 3 количественные переменные и перейдем на вкладку дополнительно , где
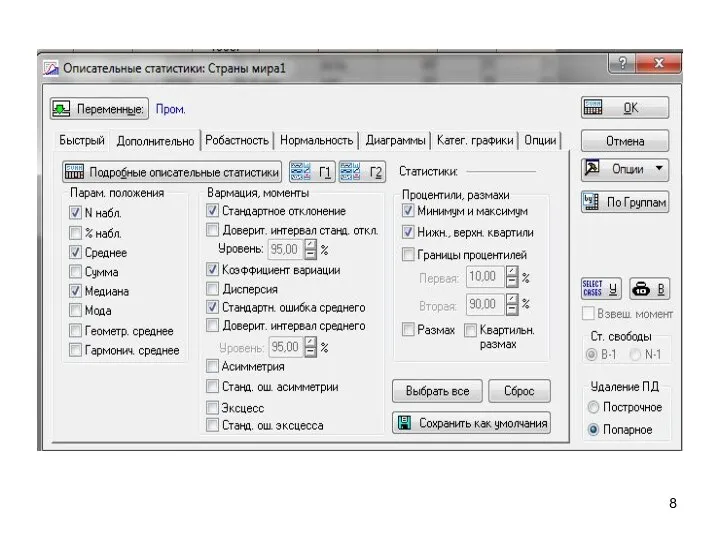

Рассмотрим более подробно дополнительные статистики, предусмотренные в этом модуле. Статистики,
Рассмотрим более подробно дополнительные статистики, предусмотренные в этом модуле. Статистики,

Квантиль, соответствующая вероятности p, это значение переменной, ниже которой находится
Квантиль, соответствующая вероятности p, это значение переменной, ниже которой находится

Мода – это значение переменной, соответствующее наибольшей частоте появления переменной
Мода – это значение переменной, соответствующее наибольшей частоте появления переменной

Range (размах) – это разность между максимальным и минимальным значениями
Range (размах) – это разность между максимальным и минимальным значениями
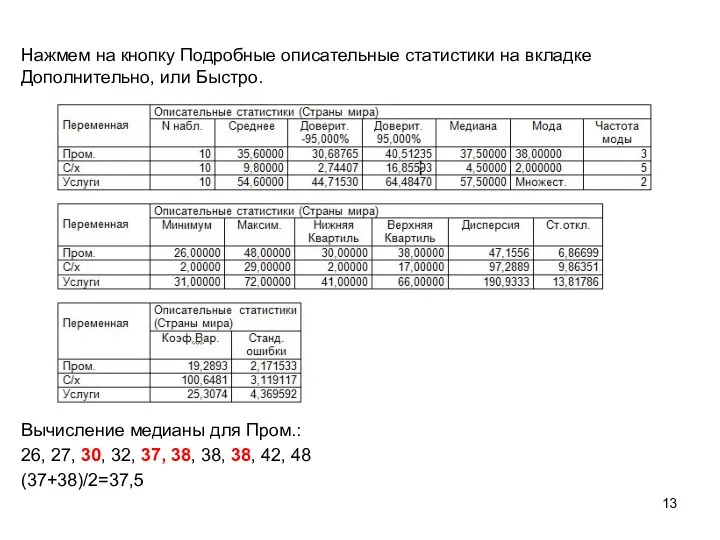
Нажмем на кнопку Подробные описательные статистики на вкладке Дополнительно, или Быстро.
Нажмем на кнопку Подробные описательные статистики на вкладке Дополнительно, или Быстро.

Между переменными (случайными величинами) может существовать функциональная связь, проявляющаяся в
Между переменными (случайными величинами) может существовать функциональная связь, проявляющаяся в

Если переменные независимы, то коэффициент корреляции равен 0 (обратное утверждение
Если переменные независимы, то коэффициент корреляции равен 0 (обратное утверждение

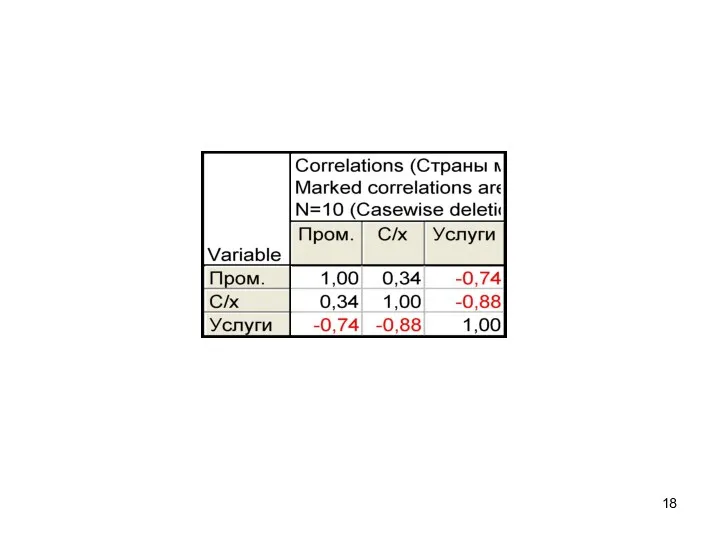
Для построения корреляционной матрицы в верхнем меню Statistics надо выбрать
Для построения корреляционной матрицы в верхнем меню Statistics надо выбрать
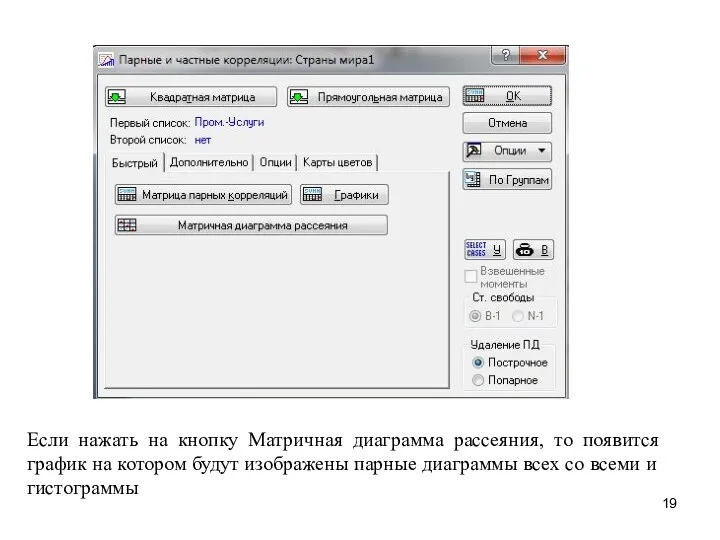
Если нажать на кнопку Матричная диаграмма рассеяния, то появится график на
Если нажать на кнопку Матричная диаграмма рассеяния, то появится график на


Если нажать на кнопку Графики, то появится 3 диаграммы рассеяний с
Если нажать на кнопку Графики, то появится 3 диаграммы рассеяний с


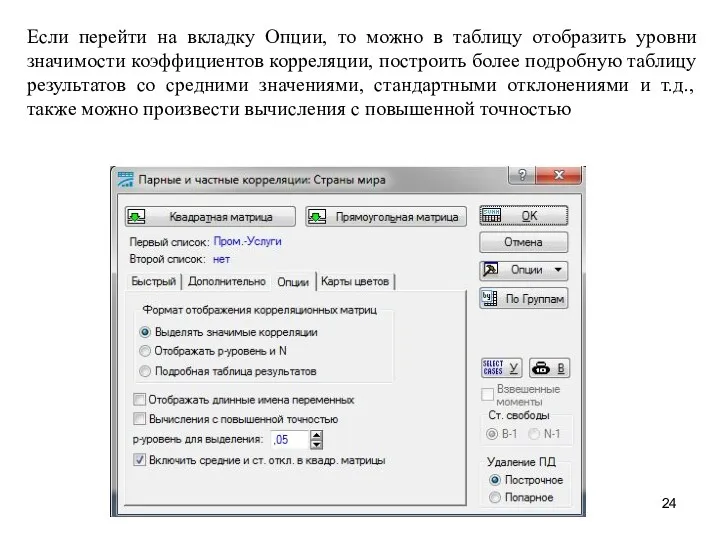
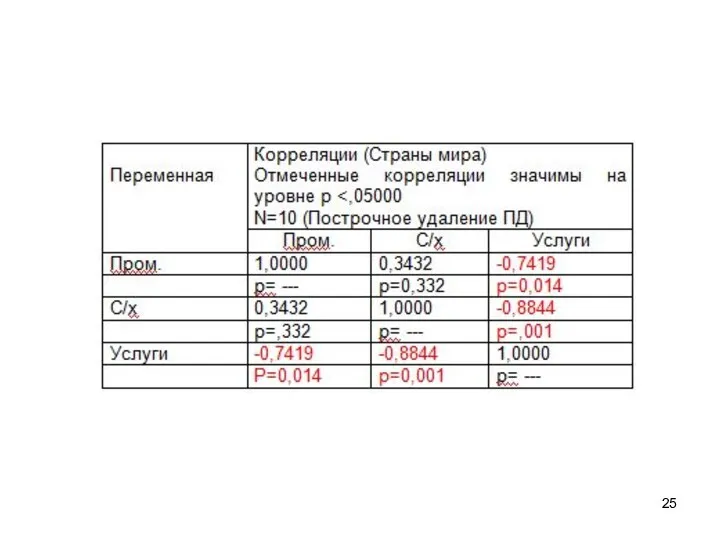
Если перейти на вкладку Опции, то можно в таблицу отобразить уровни
Если перейти на вкладку Опции, то можно в таблицу отобразить уровни
 Операционные системы Windows
Операционные системы Windows ПО Oracle для построения ХД
ПО Oracle для построения ХД Мемы и русский язык
Мемы и русский язык Лекция 1. Классы памяти (auto, register, extern, static.) в C
Лекция 1. Классы памяти (auto, register, extern, static.) в C Элементы алгебры логики. Математические основы информатики
Элементы алгебры логики. Математические основы информатики Программа для составления расписания занятий
Программа для составления расписания занятий Технология клиент-сервер. Лекция 1
Технология клиент-сервер. Лекция 1 ЕГЭ по информатике 2014. Задачи А7
ЕГЭ по информатике 2014. Задачи А7 Опрацювання текстових даних
Опрацювання текстових даних Принципи функціонування електронної пошти. Огляд програм для роботи з електронною поштою. Робота з поштою через веб-інтерфейс
Принципи функціонування електронної пошти. Огляд програм для роботи з електронною поштою. Робота з поштою через веб-інтерфейс Python nima?
Python nima? Обозначение основных плоскостей проекций
Обозначение основных плоскостей проекций Магистрально-модульный принцип построения компьютера
Магистрально-модульный принцип построения компьютера Анализ методов информационной безопасности настройки СУБД Oracle
Анализ методов информационной безопасности настройки СУБД Oracle Кибер-квиз. Безопасный интернет
Кибер-квиз. Безопасный интернет Цифровая схемотехника и архитектура компьютера. Иеархия памяти и подсистема ввода-вывода. (Глава 8)
Цифровая схемотехника и архитектура компьютера. Иеархия памяти и подсистема ввода-вывода. (Глава 8) Компьютерные сети
Компьютерные сети Инструкция по работе с сервисом Tiny Tap
Инструкция по работе с сервисом Tiny Tap Ассемблер Atmel AVR. Занятие №1: Архитектура AVR, схемотехника ЭВМ
Ассемблер Atmel AVR. Занятие №1: Архитектура AVR, схемотехника ЭВМ Vse_leksii_oib
Vse_leksii_oib Разработка урока информатики в 5 классе на тему: Главное меню. Запуск программ
Разработка урока информатики в 5 классе на тему: Главное меню. Запуск программ Стандартные функции системы muLisp
Стандартные функции системы muLisp Магистрально-модульный принцип построения компьютера
Магистрально-модульный принцип построения компьютера Компания DLink. Основы построения сетей
Компания DLink. Основы построения сетей Defeating Windows memory forensics
Defeating Windows memory forensics Электронная цифровая подпись
Электронная цифровая подпись Проектирование и разработка сайта для аниме магазина ANIMYT
Проектирование и разработка сайта для аниме магазина ANIMYT Библиотека сегодня
Библиотека сегодня