- Параллельное и распределенное программирование

Содержание
- 2. План лекции OpenCL архитектура Простейшая программа
- 3. OpenCL архитектура OpenCL позволяет проводить параллельные вычисления на гетерогенных устройствах Процессоры, графические процессоры, ПЛИС и т.
- 4. Модель платформы OpenCL Модель платформы описывает вычислительные ресурсы, используемые OpenCL и их взаимосвязь между собой Каждая
- 5. Модель платформы OpenCL Модель платформы определяет хост (Host), подключенный к одному или нескольким вычислительным устройствам Устройство
- 6. Host/Devices Хост - это любой процессор, на котором работает библиотека OpenCL Процессоры x86 в целом Устройства
- 7. Модель платформы OpenCL
- 8. Модель платформы. Аппаратная система
- 9. Обнаружение платформ Платформа выбирается с помощью двойного вызова API Первый вызов используется для получения количества платформ,
- 10. Обнаружение платформ cl_int clGetPlatformInfo( cl_platform_id platform, cl_platform_info param_name, size_t param_value_size, void *param_value, size_t *param_value_size_ret) Информация о
- 11. Обнаружение устройств на платформе Получить устройства cl_int clGetDeviceIDs( cl_platform_id platformID, cl_device_type nDeviceType, cl_uint nNumEntries, cl_device_id *pDevices,
- 12. Контекст Контекст - это среда для управления объектами и ресурсами OpenCL Для управления программами OpenCL следующее
- 13. Программная модель Хост-программа Программа для устройства Набор ядер
- 14. Программная модель. Основные определения Ядро (kernel) – функция, исполняемая устройством. Имеет в описании спецификацию __kernel. Программа
- 15. Объекты (1/2) Объект (object) – абстрактное представление ресурса, управляемого OpenCL API (объект ядра, памяти и т.д.).
- 16. Объекты (2/2) Объект события (event object) – хранит состояние команды. Предназначен для синхронизации. Объект буфера (buffer
- 17. Контекст Функция создает контекст с учетом списка устройств Аргумент properties указывает, какую платформу использовать (если NULL
- 18. Очередь команд Очередь команд - это механизм, по которому хост запрашивает, чтобы действие выполнялось устройством (т.
- 19. Очередь команд Поскольку очередь команд нацелена на одно устройство, для каждого устройства требуется отдельная очередь команд
- 20. События События (Events) - это механизм OpenCL для определения зависимостей между командами Все вызовы OpenCL API
- 21. Синхронизация очередей Вызов clFinish блокирует хост-программу до тех пор, пока все команды не будут завершены На
- 22. Привязка на стороне устройства (Device) OpenCL 2.0 представил командные очереди на стороне устройства Позволяет устройству вставлять
- 23. Объекты памяти Объектами памяти являются дескрипторы данных, к которым может обращаться ядро Типы объектов OpenCL -
- 24. Буфер данных Одномерный массив в памяти хоста или устройства Копирование clEnqueue{Read,Write,Copy}Buffer() Блокирующее/неблокирующее Отображение clEnqueue{Map,Unmap}Buffer()
- 25. Создание буфера // создание буфера cl_mem clCreateBuffer( cl_context context, cl_mem_flags nFlags, size_t uSize, void *pvHostPtr, cl_int
- 26. Передача данных Хотя среда OpenCL отвечает за обеспечение доступности данных ядром, явные команды передачи памяти могут
- 27. Буфер данных // копирование буфера cl_int clEnqueueCopyBuffer( cl_command_queue command_queue, cl_mem src_buffer, cl_mem dst_buffer, size_t uSrcOffset, size_t
- 28. Буфер данных // чтение буфера cl_int clEnqueueReadBuffer( cl_command_queue command_queue, cl_mem buffer, cl_bool bBlockingRead, size_t uOffset, size_t
- 29. Буфер данных // отображение буфера в память управляющего узла void *clEnqueueMapBuffer( cl_command_queue command_queue, cl_mem buffer, cl_bool
- 30. Буфер данных // завершение отображения буфера в память cl_int clEnqueueUnmapMemObject( cl_command_queue command_queue, cl_mem memobj, void *pvMappedPtr,
- 31. Программа Программный объект представляет собой набор ядер OpenCL, функции и данные, используемые ядрами (исходный код (текст)
- 32. Программа Исполняемый код устройства >= 1 ядер Создание clCreateProgramWith{Source,Binary}() Сборка clBuildProgram() clGetProgramBuildInfo()
- 33. Создание объекта программы Эта функция создает программный объект из строк исходного кода count указывает количество строк
- 34. Сборка программы Эта функция компилирует и связывает исполняемый файл из объекта программы для каждого устройства в
- 35. Ядро «Точка входа» в устройство Создание clCreateKernel(), clCreateKernelsInProgram() Параметры clSetKernelArg() Запуск clEnqueueNDRangeKernel() — на решётке
- 36. Kernels Ядро - это функция, объявленная в программе, которая выполняется на устройстве OpenCL Объект ядра -
- 37. Создание ядра Создает ядро из данной программы Созданное ядро задается строкой, которая соответствует имени функции внутри
- 38. Runtime Compilation of OpenCL kernels Существуют высокие накладные расходы для компиляции программ и создания ядер Каждая
- 39. Reporting Compile Errors Если программа не скомпилирована в OpenCL требуется явно запрашивать вывод компилятора Сбой компиляции
- 40. Задание аргументов ядра Объекты памяти и отдельные значения данных могут быть заданы как аргументы ядра Аргументы
- 41. Модель исполнения Массивно параллельные программы обычно пишутся так, что каждый поток вычисляет один элемент задачи Для
- 42. Модель исполнения Рассмотрим простое векторное сложение 8 элементов Требуются 2 входных буфера (A, B) и 1
- 43. Модель исполнения Модель исполнения OpenCL предназначена для масштабирования Каждый экземпляр ядра называется рабочим элементом (хотя обычно
- 44. Модель исполнения. Индексное пространство (1/3) Gx , Gy – глобальные размеры; Sx, Sy – локальные размеры
- 45. Модель исполнения. Индексное пространство (2/3)
- 46. Модель исполнения. Функции рабочих элементов (3/3) Таблица 11 – Функции рабочих элементов get_global_size(0) == get_local_size(0) *
- 47. Модель платформы OpenCL. Иерархия памяти закрытая память; локальная память; константная память; глобальная память; хост-память.
- 48. Модель платформы OpenCL. Соответствие иерархий Таблица – Квалификаторы адресного пространства Таблица – Квалификаторы доступа
- 49. Модель исполнения OpenCL. Квалификаторы либо __xxx, либо xxx • квалификатор kernel • Функция является ядром •
- 50. Общее адресное пространство Одно общее адресное пространство добавляется после OpenCL 2.0 Поддержка преобразования указателей в и
- 51. Написание функции ядра Один экземпляр ядра выполняется для каждого рабочего элемента Ядра: Необходимо начинать с ключевого
- 52. Написание функции ядра: идентификаторы адресного пространства Внутри ядра объекты памяти задаются с использованием классификаторов типов __global:
- 53. Сложение векторов. Пример Parallel Software – SPMD 0 1 2 3 4 5 6 7 8
- 54. Сложение векторов. Пример __kernel void dp_add( int nNumElements, __global const float *pcfA, __global const float *pcfB,
- 55. Последовательность. Сложение векторов 8.1 Создание трех буферов clCreateBuffer(два буфера для входных векторов CL_MEM_READ_ONLY, один – для
- 56. Написание функции ядра: выполнение ядра на устройстве Необходимо установить размеры индексного пространства и (необязательно) размеров рабочей
- 57. Executing Kernels Сообщает устройству, связанному с командной очередью, о начале выполнения указанного ядра Необходимо указать глобальное
- 58. Освобождение ресурсов Объекты OpenCL должны быть освобождены после их использования Для большинства типов OpenCL существует команда
- 59. Простейшая программа #include #include const int g_cuNumItems = 128; const char *g_pcszSource = "__kernel void memset(__global
- 60. Простейшая программа (продолжение) int main() { // 1. Получение платформы cl_uint uNumPlatforms; clGetPlatformIDs(0, NULL, &uNumPlatforms); std::cout
- 61. Простейшая программа (продолжение) // 3. Получение номера CL устройства cl_device_id deviceID; cl_uint uNumGPU; clGetDeviceIDs( pPlatforms[1], CL_DEVICE_TYPE_DEFAULT,
- 62. Простейшая программа (продолжение) // 6. Создание очереди команд errcode_ret = 0; cl_queue_properties qprop[] = {0 };
- 63. Простейшая программа (продолжение) // // 8. Сборка программы // cl_int errcode = clBuildProgram( program, 1, &deviceID,
- 64. Простейшая программа (продолжение) // // 10. Создание буфера // cl_mem buffer = clCreateBuffer( context, CL_MEM_WRITE_ONLY, g_cuNumItems
- 65. Простейшая программа (продолжение) // // 12. Запуск ядра // size_t uGlobalWorkSize = g_cuNumItems; clEnqueueNDRangeKernel( queue, kernel,
- 66. Простейшая программа (продолжение) // // 13. Отображение буфера в память управляющего узла // cl_uint *puData =
- 67. Простейшая программа (продолжение) // // 14. Использование результатов // for (int i = 0; i std::cout
- 68. Простейшая программа (продолжение) // // 16. Удаление объектов и освобождение памяти // управляющего узла // clReleaseMemObject(buffer);
- 69. Последовательность Получение платформы Получение номера CL устройства Создание контекста Создание очереди команд Создание программы Сборка программы
- 70. Программная модель OpenCL Параллелизм на уровне данных сопоставление между рабочими элементами и элементами в объекте памяти
- 71. Скалярные типы OpenCL
- 72. Векторные типы OpenCL Значение n: 2, 3, 4, 8, 16
- 73. Транспонирование матрицы. Пример __kernel void transpose( __global float *pfOData, __global float *pfIData, int nOffset, int nWidth,
- 74. Транспонирование матрицы. Пример if ((uXIndex + nOffset { unsigned int uIndexIn = uYIndex * uWidth +
- 75. Система компиляции OpenCL Ядро OpenCL обычно преобразуется в двоичное представление промежуточного языка Обычными промежуточными представлениями являются
- 76. Ссылки http://www.khronos.org/opencl/ http://developer.nvidia.com/object/opencl.html http://developer.amd.com/gpu/atistreamsdk/pages/default.aspx http://www.alphaworks.ibm.com/tech/opencl
- 78. Скачать презентацию

План лекции
OpenCL архитектура
Простейшая программа
План лекции
OpenCL архитектура
Простейшая программа

OpenCL архитектура
OpenCL позволяет проводить параллельные вычисления на гетерогенных устройствах
Процессоры, графические процессоры,
OpenCL архитектура
OpenCL позволяет проводить параллельные вычисления на гетерогенных устройствах
Процессоры, графические процессоры,

Модель платформы OpenCL
Модель платформы описывает вычислительные ресурсы, используемые OpenCL и их
Модель платформы OpenCL
Модель платформы описывает вычислительные ресурсы, используемые OpenCL и их
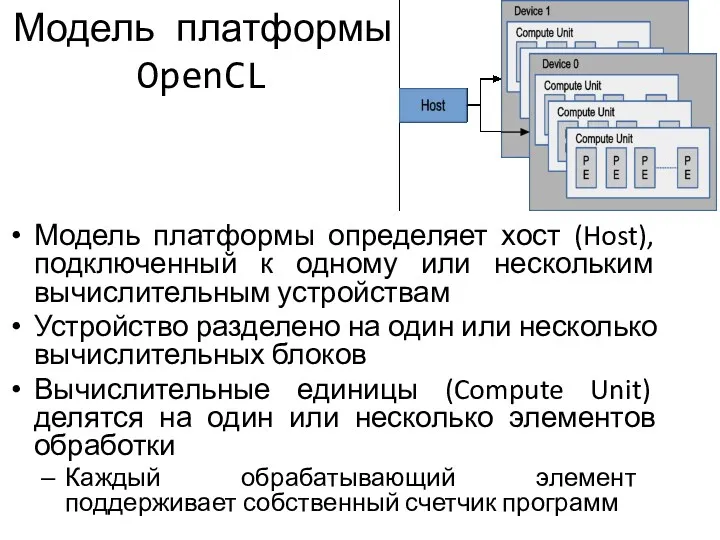
Модель платформы OpenCL
Модель платформы определяет хост (Host), подключенный к одному или
Модель платформы OpenCL
Модель платформы определяет хост (Host), подключенный к одному или

Host/Devices
Хост - это любой процессор, на котором работает библиотека OpenCL
Процессоры x86
Host/Devices
Хост - это любой процессор, на котором работает библиотека OpenCL
Процессоры x86
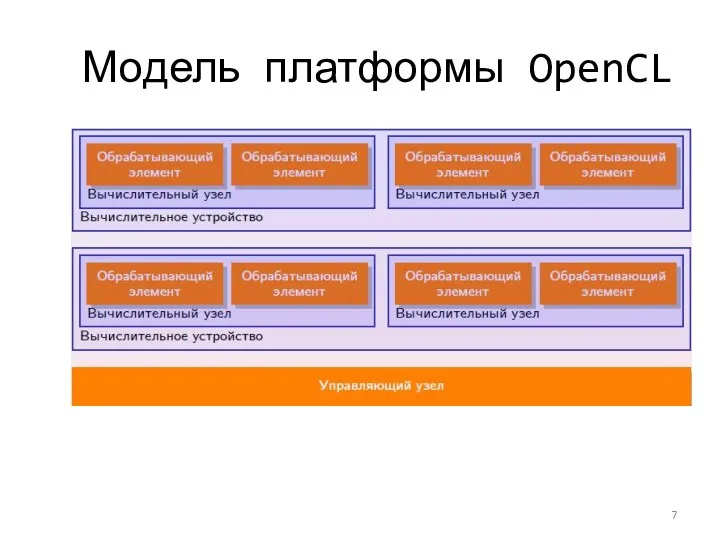
Модель платформы OpenCL
Модель платформы OpenCL
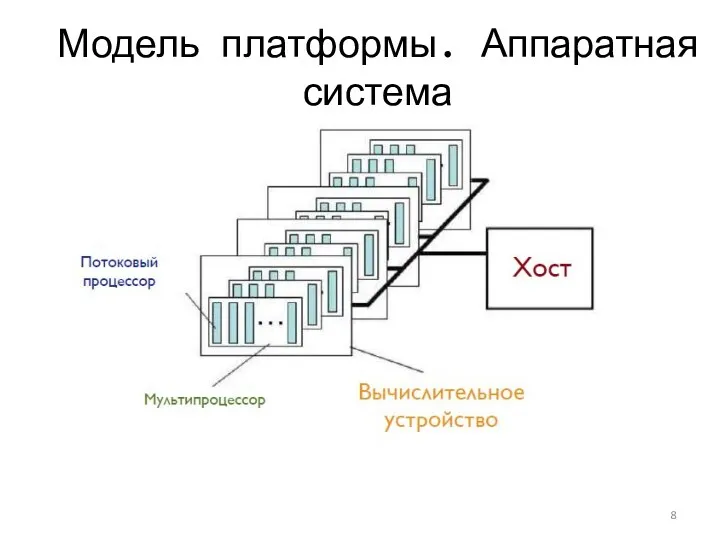
Модель платформы. Аппаратная система
Модель платформы. Аппаратная система

Обнаружение платформ
Платформа выбирается с помощью двойного вызова API
Первый вызов используется для
Обнаружение платформ
Платформа выбирается с помощью двойного вызова API
Первый вызов используется для

Обнаружение платформ
cl_int clGetPlatformInfo( cl_platform_id platform,
cl_platform_info param_name,
size_t param_value_size,
void *param_value,
size_t
Обнаружение платформ
cl_int clGetPlatformInfo( cl_platform_id platform,
cl_platform_info param_name,
size_t param_value_size,
void *param_value,
size_t

Обнаружение устройств на платформе
Получить устройства
cl_int clGetDeviceIDs(
cl_platform_id platformID,
cl_device_type nDeviceType, cl_uint nNumEntries,
cl_device_id *pDevices,
Обнаружение устройств на платформе
Получить устройства
cl_int clGetDeviceIDs(
cl_platform_id platformID,
cl_device_type nDeviceType, cl_uint nNumEntries,
cl_device_id *pDevices,

Контекст
Контекст - это среда для управления объектами и ресурсами OpenCL
Для управления
Контекст
Контекст - это среда для управления объектами и ресурсами OpenCL
Для управления

Программная модель
Хост-программа
Программа для устройства
Набор ядер
Программная модель
Хост-программа
Программа для устройства
Набор ядер

Программная модель. Основные определения
Ядро (kernel) – функция, исполняемая устройством. Имеет в
Программная модель. Основные определения
Ядро (kernel) – функция, исполняемая устройством. Имеет в

Объекты (1/2)
Объект (object) – абстрактное представление ресурса, управляемого OpenCL API (объект
Объекты (1/2)
Объект (object) – абстрактное представление ресурса, управляемого OpenCL API (объект

Объекты (2/2)
Объект события (event object) – хранит состояние команды. Предназначен для
Объекты (2/2)
Объект события (event object) – хранит состояние команды. Предназначен для

Контекст
Функция создает контекст с учетом списка устройств
Аргумент properties указывает, какую платформу
Контекст
Функция создает контекст с учетом списка устройств
Аргумент properties указывает, какую платформу

Очередь команд
Очередь команд - это механизм, по которому хост запрашивает, чтобы
Очередь команд
Очередь команд - это механизм, по которому хост запрашивает, чтобы

Очередь команд
Поскольку очередь команд нацелена на одно устройство, для каждого устройства
Очередь команд
Поскольку очередь команд нацелена на одно устройство, для каждого устройства

События
События (Events) - это механизм OpenCL для определения зависимостей между командами
Все
События
События (Events) - это механизм OpenCL для определения зависимостей между командами
Все

Синхронизация очередей
Вызов clFinish блокирует хост-программу до тех пор, пока все команды
Синхронизация очередей
Вызов clFinish блокирует хост-программу до тех пор, пока все команды

Привязка на стороне устройства (Device)
OpenCL 2.0 представил командные очереди на стороне
Привязка на стороне устройства (Device)
OpenCL 2.0 представил командные очереди на стороне

Объекты памяти
Объектами памяти являются дескрипторы данных, к которым может обращаться ядро
Типы
Объекты памяти
Объектами памяти являются дескрипторы данных, к которым может обращаться ядро
Типы

Буфер данных
Одномерный массив в памяти хоста или устройства
Копирование
clEnqueue{Read,Write,Copy}Buffer()
Блокирующее/неблокирующее
Буфер данных
Одномерный массив в памяти хоста или устройства
Копирование
clEnqueue{Read,Write,Copy}Buffer()
Блокирующее/неблокирующее
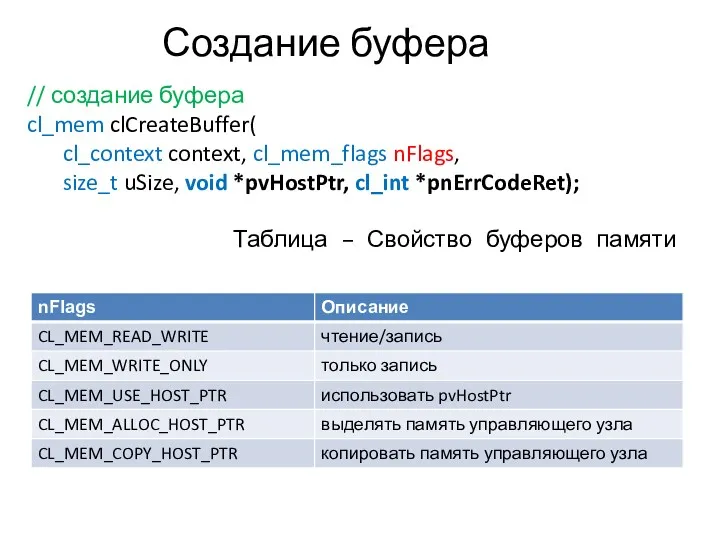
Создание буфера
// создание буфера
cl_mem clCreateBuffer(
cl_context context, cl_mem_flags nFlags,
size_t uSize, void *pvHostPtr,
Создание буфера
// создание буфера
cl_mem clCreateBuffer(
cl_context context, cl_mem_flags nFlags,
size_t uSize, void *pvHostPtr,

Передача данных
Хотя среда OpenCL отвечает за обеспечение доступности данных ядром, явные
Передача данных
Хотя среда OpenCL отвечает за обеспечение доступности данных ядром, явные

Буфер данных
// копирование буфера
cl_int clEnqueueCopyBuffer(
cl_command_queue command_queue,
cl_mem src_buffer,
cl_mem dst_buffer,
size_t uSrcOffset,
size_t uDstOffset,
size_t uBytes,
cl_uint
Буфер данных
// копирование буфера
cl_int clEnqueueCopyBuffer(
cl_command_queue command_queue,
cl_mem src_buffer,
cl_mem dst_buffer,
size_t uSrcOffset,
size_t uDstOffset,
size_t uBytes,
cl_uint

Буфер данных
// чтение буфера
cl_int clEnqueueReadBuffer(
cl_command_queue command_queue,
cl_mem buffer,
cl_bool bBlockingRead,
size_t
Буфер данных
// чтение буфера
cl_int clEnqueueReadBuffer(
cl_command_queue command_queue,
cl_mem buffer,
cl_bool bBlockingRead,
size_t

Буфер данных
// отображение буфера в память управляющего узла
void *clEnqueueMapBuffer(
cl_command_queue command_queue,
cl_mem buffer,
cl_bool
Буфер данных
// отображение буфера в память управляющего узла
void *clEnqueueMapBuffer(
cl_command_queue command_queue,
cl_mem buffer,
cl_bool

Буфер данных
// завершение отображения буфера в память
cl_int clEnqueueUnmapMemObject(
cl_command_queue command_queue,
cl_mem memobj,
void *pvMappedPtr,
cl_uint
Буфер данных
// завершение отображения буфера в память
cl_int clEnqueueUnmapMemObject(
cl_command_queue command_queue,
cl_mem memobj,
void *pvMappedPtr,
cl_uint

Программа
Программный объект представляет собой набор ядер OpenCL, функции и данные, используемые
Программа
Программный объект представляет собой набор ядер OpenCL, функции и данные, используемые

Программа
Исполняемый код устройства
>= 1 ядер
Создание
clCreateProgramWith{Source,Binary}()
Сборка
clBuildProgram()
Программа
Исполняемый код устройства
>= 1 ядер
Создание
clCreateProgramWith{Source,Binary}()
Сборка
clBuildProgram()

Создание объекта программы
Эта функция создает программный объект из строк исходного кода
count
Создание объекта программы
Эта функция создает программный объект из строк исходного кода
count

Сборка программы
Эта функция компилирует и связывает исполняемый файл из объекта программы
Сборка программы
Эта функция компилирует и связывает исполняемый файл из объекта программы

Ядро
«Точка входа» в устройство
Создание
clCreateKernel(),
clCreateKernelsInProgram()
Параметры
clSetKernelArg()
Запуск
clEnqueueNDRangeKernel()
Ядро
«Точка входа» в устройство
Создание
clCreateKernel(),
clCreateKernelsInProgram()
Параметры
clSetKernelArg()
Запуск
clEnqueueNDRangeKernel()

Kernels
Ядро - это функция, объявленная в программе, которая выполняется на устройстве
Kernels
Ядро - это функция, объявленная в программе, которая выполняется на устройстве

Создание ядра
Создает ядро из данной программы
Созданное ядро задается строкой, которая соответствует
Создание ядра
Создает ядро из данной программы
Созданное ядро задается строкой, которая соответствует
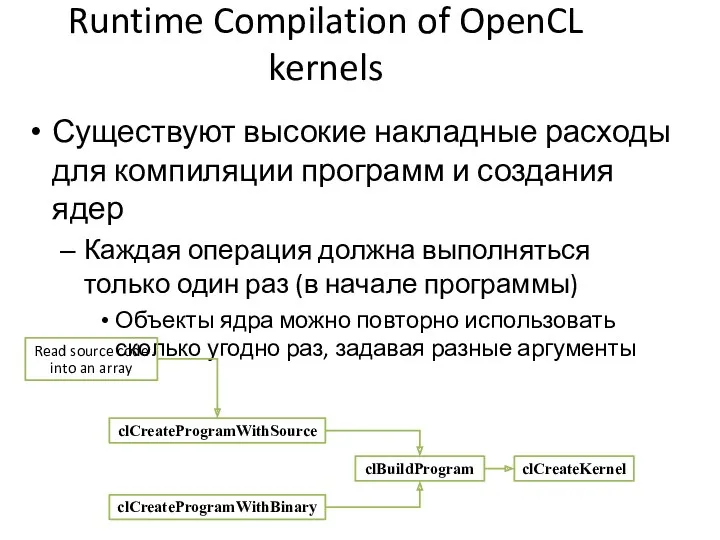
Runtime Compilation of OpenCL kernels
Существуют высокие накладные расходы для компиляции программ
Runtime Compilation of OpenCL kernels
Существуют высокие накладные расходы для компиляции программ

Reporting Compile Errors
Если программа не скомпилирована в OpenCL требуется явно запрашивать
Reporting Compile Errors
Если программа не скомпилирована в OpenCL требуется явно запрашивать

Задание аргументов ядра
Объекты памяти и отдельные значения данных могут быть заданы
Задание аргументов ядра
Объекты памяти и отдельные значения данных могут быть заданы

Модель исполнения
Массивно параллельные программы обычно пишутся так, что каждый поток вычисляет
Модель исполнения
Массивно параллельные программы обычно пишутся так, что каждый поток вычисляет
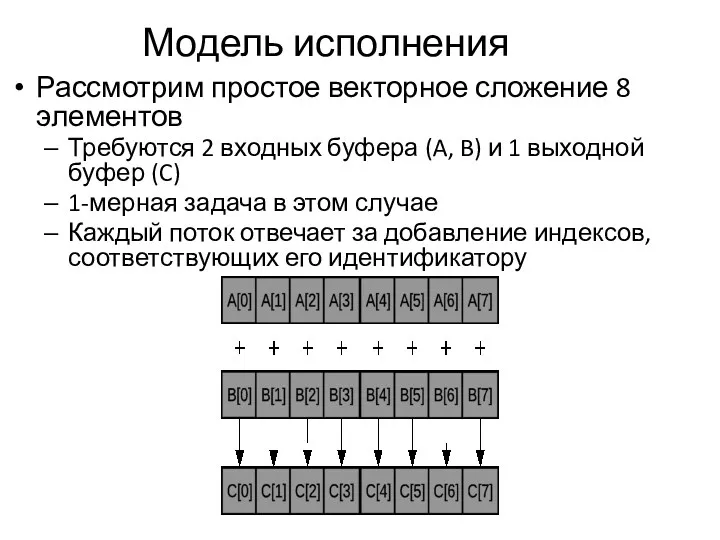
Модель исполнения
Рассмотрим простое векторное сложение 8 элементов
Требуются 2 входных буфера (A,
Модель исполнения
Рассмотрим простое векторное сложение 8 элементов
Требуются 2 входных буфера (A,

Модель исполнения
Модель исполнения OpenCL предназначена для масштабирования
Каждый экземпляр ядра называется рабочим
Модель исполнения
Модель исполнения OpenCL предназначена для масштабирования
Каждый экземпляр ядра называется рабочим
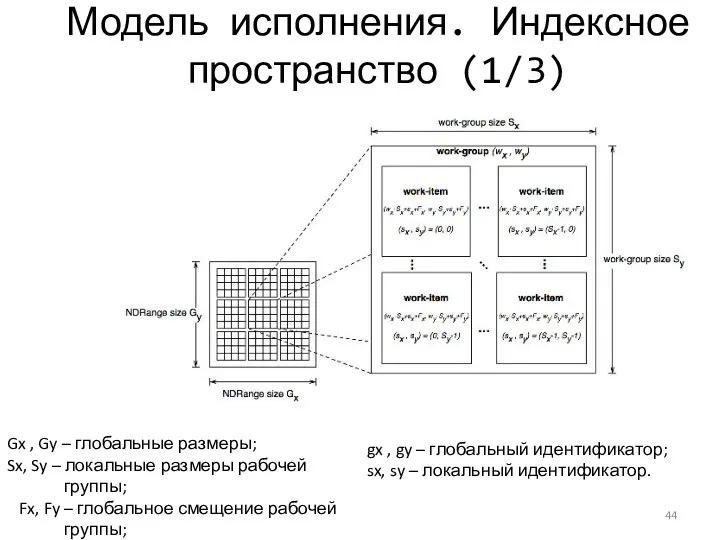
Модель исполнения. Индексное пространство (1/3)
Gx , Gy – глобальные размеры;
Sx, Sy
Модель исполнения. Индексное пространство (1/3)
Gx , Gy – глобальные размеры;
Sx, Sy

Модель исполнения. Индексное пространство (2/3)
Модель исполнения. Индексное пространство (2/3)

Модель исполнения. Функции рабочих элементов (3/3)
Таблица 11 – Функции рабочих элементов
get_global_size(0)
Модель исполнения. Функции рабочих элементов (3/3)
Таблица 11 – Функции рабочих элементов
get_global_size(0)
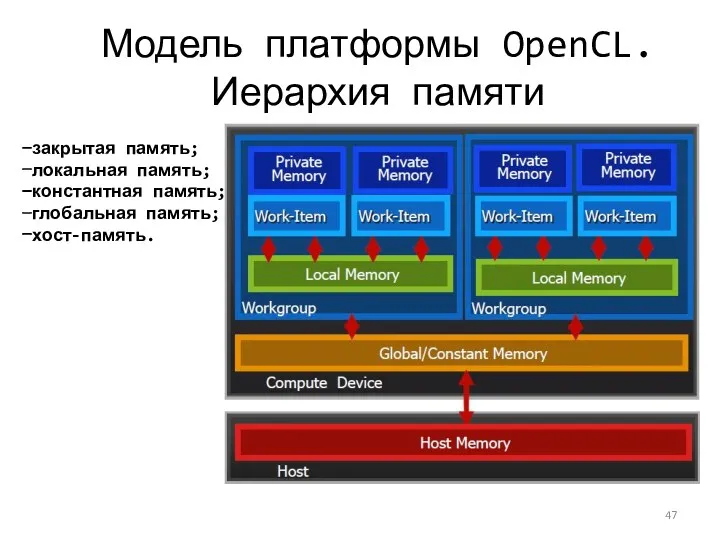
Модель платформы OpenCL. Иерархия памяти
закрытая память;
локальная память;
константная память;
глобальная память;
хост-память.
Модель платформы OpenCL. Иерархия памяти
закрытая память;
локальная память;
константная память;
глобальная память;
хост-память.

Модель платформы OpenCL. Соответствие иерархий
Таблица – Квалификаторы адресного пространства
Таблица – Квалификаторы
Модель платформы OpenCL. Соответствие иерархий
Таблица – Квалификаторы адресного пространства
Таблица – Квалификаторы

Модель исполнения OpenCL. Квалификаторы
либо __xxx, либо xxx
• квалификатор kernel
• Функция
Модель исполнения OpenCL. Квалификаторы
либо __xxx, либо xxx
• квалификатор kernel
• Функция

Общее адресное пространство
Одно общее адресное пространство добавляется после OpenCL 2.0
Поддержка преобразования
Общее адресное пространство
Одно общее адресное пространство добавляется после OpenCL 2.0
Поддержка преобразования

Написание функции ядра
Один экземпляр ядра выполняется для каждого рабочего элемента
Ядра:
Необходимо начинать
Написание функции ядра
Один экземпляр ядра выполняется для каждого рабочего элемента
Ядра:
Необходимо начинать

Написание функции ядра: идентификаторы адресного пространства
Внутри ядра объекты памяти задаются с
Написание функции ядра: идентификаторы адресного пространства
Внутри ядра объекты памяти задаются с
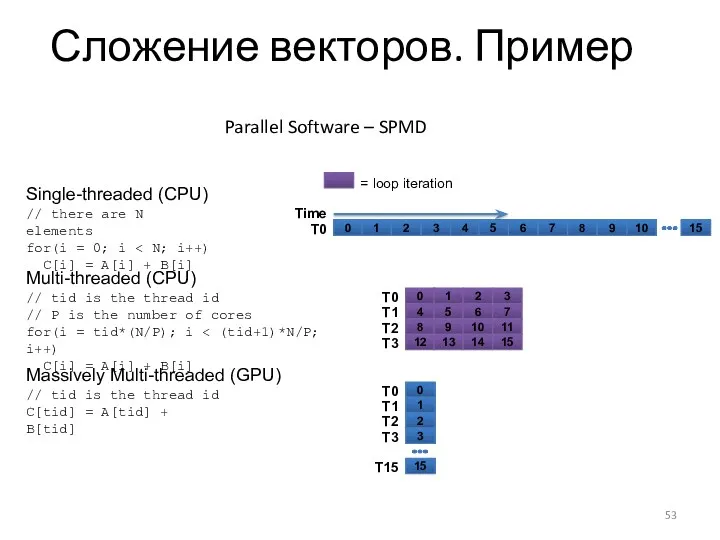
Сложение векторов. Пример
Parallel Software – SPMD
0
1
2
3
4
5
6
7
8
9
15
10
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
0
1
2
3
15
= loop iteration
Time
T0
T0
T1
T2
T3
T0
T1
T2
T3
T15
Сложение векторов. Пример
Parallel Software – SPMD
0
1
2
3
4
5
6
7
8
9
15
10
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
0
1
2
3
15
= loop iteration
Time
T0
T0
T1
T2
T3
T0
T1
T2
T3
T15

Сложение векторов. Пример
__kernel void dp_add(
int nNumElements,
__global const float *pcfA,
__global const float
Сложение векторов. Пример
__kernel void dp_add(
int nNumElements,
__global const float *pcfA,
__global const float

Последовательность. Сложение векторов
8.1 Создание трех буферов clCreateBuffer(два буфера для входных
Последовательность. Сложение векторов
8.1 Создание трех буферов clCreateBuffer(два буфера для входных

Написание функции ядра: выполнение ядра на устройстве
Необходимо установить размеры индексного пространства
Написание функции ядра: выполнение ядра на устройстве
Необходимо установить размеры индексного пространства

Executing Kernels
Сообщает устройству, связанному с командной очередью, о начале выполнения указанного
Executing Kernels
Сообщает устройству, связанному с командной очередью, о начале выполнения указанного

Освобождение ресурсов
Объекты OpenCL должны быть освобождены после их использования
Для большинства типов
Освобождение ресурсов
Объекты OpenCL должны быть освобождены после их использования
Для большинства типов

Простейшая программа
#include
#include
const int g_cuNumItems = 128;
const char *g_pcszSource =
"__kernel
Простейшая программа
#include
#include
const int g_cuNumItems = 128;
const char *g_pcszSource =
"__kernel

Простейшая программа (продолжение)
int main()
{
// 1. Получение платформы
cl_uint uNumPlatforms;
clGetPlatformIDs(0, NULL, &uNumPlatforms);
std::cout <<
Простейшая программа (продолжение)
int main()
{
// 1. Получение платформы
cl_uint uNumPlatforms;
clGetPlatformIDs(0, NULL, &uNumPlatforms);
std::cout <<

Простейшая программа (продолжение)
// 3. Получение номера CL устройства
cl_device_id deviceID;
cl_uint uNumGPU;
clGetDeviceIDs( pPlatforms[1],
Простейшая программа (продолжение)
// 3. Получение номера CL устройства
cl_device_id deviceID;
cl_uint uNumGPU;
clGetDeviceIDs( pPlatforms[1],

Простейшая программа (продолжение)
// 6. Создание очереди команд
errcode_ret = 0;
cl_queue_properties qprop[] =
Простейшая программа (продолжение)
// 6. Создание очереди команд
errcode_ret = 0;
cl_queue_properties qprop[] =

Простейшая программа (продолжение)
//
// 8. Сборка программы
//
cl_int errcode = clBuildProgram(
program, 1, &deviceID,
Простейшая программа (продолжение)
//
// 8. Сборка программы
//
cl_int errcode = clBuildProgram(
program, 1, &deviceID,

Простейшая программа (продолжение)
//
// 10. Создание буфера
//
cl_mem buffer = clCreateBuffer(
context, CL_MEM_WRITE_ONLY,
g_cuNumItems *
Простейшая программа (продолжение)
//
// 10. Создание буфера
//
cl_mem buffer = clCreateBuffer(
context, CL_MEM_WRITE_ONLY,
g_cuNumItems *

Простейшая программа (продолжение)
//
// 12. Запуск ядра
//
size_t uGlobalWorkSize = g_cuNumItems;
clEnqueueNDRangeKernel(
queue, kernel, 1,
Простейшая программа (продолжение)
//
// 12. Запуск ядра
//
size_t uGlobalWorkSize = g_cuNumItems;
clEnqueueNDRangeKernel(
queue, kernel, 1,

Простейшая программа (продолжение)
//
// 13. Отображение буфера в память управляющего узла
//
cl_uint *puData
Простейшая программа (продолжение)
//
// 13. Отображение буфера в память управляющего узла
//
cl_uint *puData

Простейшая программа (продолжение)
//
// 14. Использование результатов
//
for (int i = 0; i
Простейшая программа (продолжение)
//
// 14. Использование результатов
//
for (int i = 0; i

Простейшая программа (продолжение)
//
// 16. Удаление объектов и освобождение памяти
// управляющего
Простейшая программа (продолжение)
//
// 16. Удаление объектов и освобождение памяти
// управляющего

Последовательность
Получение платформы
Получение номера CL устройства
Создание контекста
Создание очереди команд
Создание
Последовательность
Получение платформы
Получение номера CL устройства
Создание контекста
Создание очереди команд
Создание

Программная модель OpenCL
Параллелизм на уровне данных
сопоставление между рабочими элементами и элементами
Программная модель OpenCL
Параллелизм на уровне данных
сопоставление между рабочими элементами и элементами
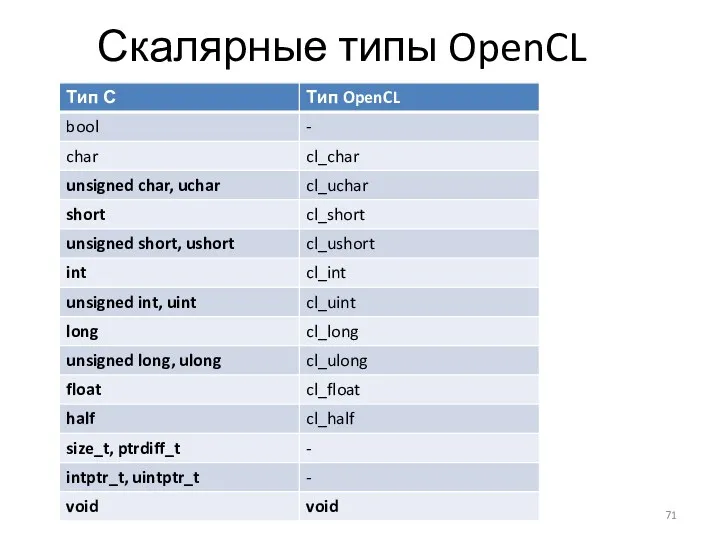
Скалярные типы OpenCL
Скалярные типы OpenCL
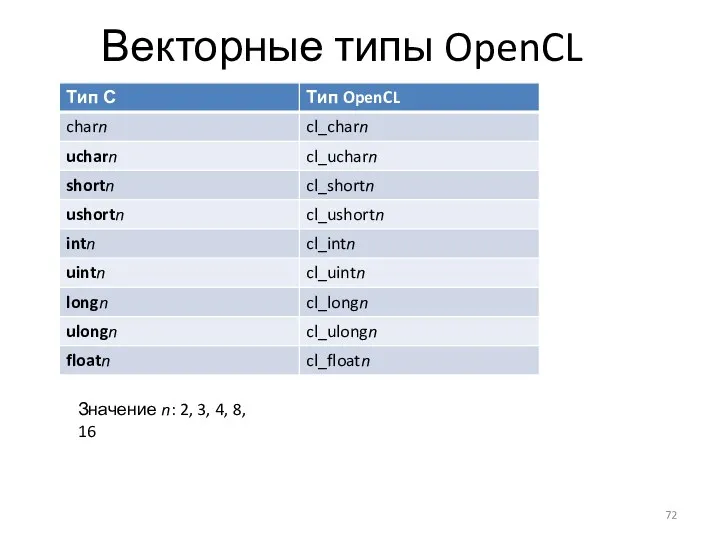
Векторные типы OpenCL
Значение n: 2, 3, 4, 8, 16
Векторные типы OpenCL
Значение n: 2, 3, 4, 8, 16

Транспонирование матрицы. Пример
__kernel void transpose(
__global float *pfOData,
__global float *pfIData,
int nOffset, int
Транспонирование матрицы. Пример
__kernel void transpose(
__global float *pfOData,
__global float *pfIData,
int nOffset, int

Транспонирование матрицы. Пример
if ((uXIndex + nOffset < nWidth) && (uYIndex <
Транспонирование матрицы. Пример
if ((uXIndex + nOffset < nWidth) && (uYIndex <
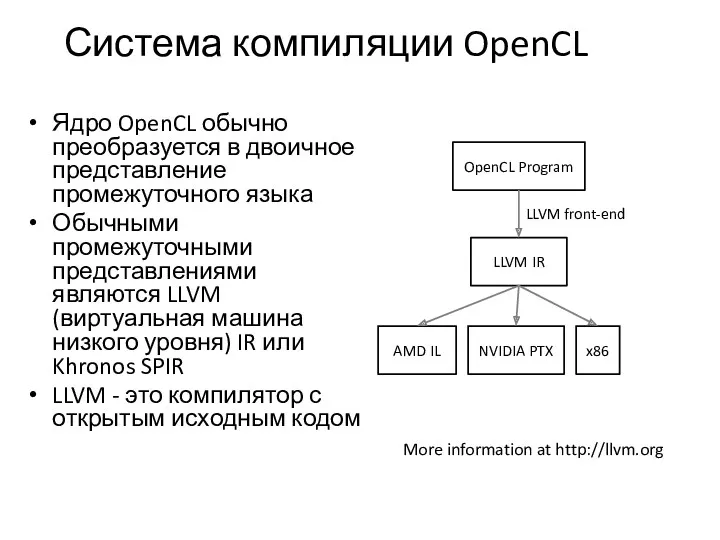
Система компиляции OpenCL
Ядро OpenCL обычно преобразуется в двоичное представление промежуточного языка
Обычными
Система компиляции OpenCL
Ядро OpenCL обычно преобразуется в двоичное представление промежуточного языка
Обычными

Ссылки
http://www.khronos.org/opencl/
http://developer.nvidia.com/object/opencl.html
http://developer.amd.com/gpu/atistreamsdk/pages/default.aspx
http://www.alphaworks.ibm.com/tech/opencl
Ссылки
http://www.khronos.org/opencl/
http://developer.nvidia.com/object/opencl.html
http://developer.amd.com/gpu/atistreamsdk/pages/default.aspx
http://www.alphaworks.ibm.com/tech/opencl
 Основы объектно-ориентированного программирования. Часть 2
Основы объектно-ориентированного программирования. Часть 2 VR/Ar-технологии. Сейчас и перспективы
VR/Ar-технологии. Сейчас и перспективы Отображение информации с помощью аудио и видео средств вычислительной техники
Отображение информации с помощью аудио и видео средств вычислительной техники Презентация урока по информатике Конъюнция и Дизъюнкция
Презентация урока по информатике Конъюнция и Дизъюнкция Future of technology and newest inventions
Future of technology and newest inventions Защита информации. Классификация каналов утечки информации
Защита информации. Классификация каналов утечки информации Основы логики. Алгебра высказываний
Основы логики. Алгебра высказываний Синтаксис программы, операторы, комментарии, техника программирования. Основные принципы программирования
Синтаксис программы, операторы, комментарии, техника программирования. Основные принципы программирования Создание приложения для шифрования и дешифрования текста
Создание приложения для шифрования и дешифрования текста Основы языка Pascal. Графика
Основы языка Pascal. Графика Коллектив разработчиков. Лидер
Коллектив разработчиков. Лидер Алгоритм индуцирования знаний из БД
Алгоритм индуцирования знаний из БД Введение в инженерию программного обеспечения
Введение в инженерию программного обеспечения Создание презентаций в Microsoft Power Point 2010
Создание презентаций в Microsoft Power Point 2010 Системы перевода и распознавания текстов
Системы перевода и распознавания текстов Табличный процессор (электронная таблица EXCEL)
Табличный процессор (электронная таблица EXCEL) Информационно-справочные системы и информационно-поисковые технологии. Информационно-справочные системы в области строительства
Информационно-справочные системы и информационно-поисковые технологии. Информационно-справочные системы в области строительства Текущий контроль. Канальний уровень. Технология Ethernet
Текущий контроль. Канальний уровень. Технология Ethernet Программирование циклических алгоритмов. Начала программирования
Программирование циклических алгоритмов. Начала программирования Определение технологии конструирования программного обеспечения
Определение технологии конструирования программного обеспечения Базы Данных
Базы Данных Как создать интернет-магазин в Facebook и Instagram, без сайта
Как создать интернет-магазин в Facebook и Instagram, без сайта Комп’ютерні мережі
Комп’ютерні мережі Организация пространства устройства ввода и вывода
Организация пространства устройства ввода и вывода Розв’язування компетентнісних задач
Розв’язування компетентнісних задач Введение в Windows Forms
Введение в Windows Forms Презентация к первому уроку информатики по Босовой Л.Л. Информация-компьютер-информатика
Презентация к первому уроку информатики по Босовой Л.Л. Информация-компьютер-информатика Обработка информации и алгоритмы
Обработка информации и алгоритмы