- Параллельное программирование. OpenMP

Содержание
- 2. Литература: Методическое пособие А. С. Антонова «Введение в параллельные вычисления» Лекции по параллельным вычислениям: учеб. пособие
- 3. Распределенная система — это набор независимых компьютеров, представляющиеся их пользователям единой объединенной системой. Эндрю Таненбаум, Мартин
- 4. Закон Амдала 4
- 5. Параллельная обработка данных Параллельная обработка данных, воплощая идею одновременного выполнения нескольких действий, имеет две разновидности: конвейерность,
- 6. Классификация М. Флинна
- 7. Суперкомпьютеры Кластеры Grid-системы Некоторые примеры II-вычислительных систем
- 8. Суперкомпьютеры Суперкомпьютер МГУ «Ломоносов» Суперкомпьютер – вычислительная машина, значительно превосходящая по своим техническим параметрам большинство существующих
- 9. Кластеры Кластер «TEdge-Mini» Кластер – группа компьютеров, объединенных в локальную вычислительную сеть (ЛВС) и способных работать
- 10. Grid-системы Grid-система – группа слабосвязанных компьютеров, объединенных с помощью локальной вычислительной сети и способных выполнять вычисления
- 11. Проблемы координации Для координации задач, выполняемых параллельно, требуется обеспечить связь между ними и синхронизацию их работы.
- 12. «Гонка» данных Если несколько задач одновременно попытаются изменить некоторую общую область данных, а конечное значение данных
- 13. Бесконечная отсрочка Если одна или несколько задач ожидают сеанса связи до своего выполнения, то в случае,
- 14. Взаимоблокировка Взаимная блокировка (deadlock) — ситуация, при которой несколько процессов находятся в состоянии бесконечного ожидания ресурсов,
- 15. Трудности организации связи Многие распространенные параллельные среды (например, кластеры) зачастую состоят из гетерогенных компьютерных сетей. Гетерогенные
- 16. Модели параллельных вычислений POSIX Threads - стандарт для нитей. Стандарт определяет API для создания и манипуляции
- 17. POSIX Threads POSIX определяет основной набор функций и структур данных, чтобы многопоточный код можно было легко
- 18. PVM (Parallel Virtual Machine) PVM представляет собой набор программных средств и библиотек, которые эмулируют общецелевые, гибкие
- 19. MPI (Message Passing Interface) Базовым механизмом связи между MPI процессами является передача и приём сообщений. Сообщение
- 20. OpenMP OpenMP предполагается SPMD-модель (Single Program Multiple Data) параллельного программирования, в рамках которой для всех параллельных
- 21. CUDA (Compute Unified Device Architecture) Технология CUDA вводит ряд дополнительных расширений для языка C, которые необходимы
- 22. Использование моделей ПВ : При необходимости решения задач распределенных вычислений на базе SMP-систем (Symmetric Multiprocessing), в
- 23. Основные понятия Компиляция программы Модель параллельной программы Директивы и функции Выполнение программы Замер времени
- 24. OpenMP OpenMP (Open Multi-Processing) — открытый стандарт для распараллеливания программ на языках Си, Си++ и Фортран.
- 25. Преимущества OpenMP 1. Разработчик не создает новую параллельную программу, а просто последовательно добавляет в текст последовательной
- 26. Модель параллельной программы OpenMP предполагается SPMD-модель (Single Program Multiple Data) параллельного программирования, в рамках которой для
- 27. Компиляция программы Для использования механизмов OpenMP нужно скомпилировать программу компилятором, поддерживающим OpenMP, с указанием соответствующего ключа
- 28. Использование OpenMP Заголовочный файл библиотеки называется omp.h: #include Директивы OpenMP для C/C++ в общем случае выглядят
- 29. Пример 1 #include "stdafx.h" #include #include "windows.h" #include using namespace std; int main(){ SetConsoleCP(1251); SetConsoleOutputCP(1251); cout
- 30. Директивы и функции Формат директивы на Си/Си++: #pragma omp directive-name [опция[[,] опция]...] Ассоциированные с директивы OpenMP
- 31. Замер времени Функции для работы с системным таймером: omp_get_wtime() - возвращает в вызвавшей нити астрономическое время
- 32. Пример 2 #include "stdafx.h" #include #include "windows.h" #include using namespace std; int main(){ SetConsoleCP(1251); SetConsoleOutputCP(1251); double
- 33. Параллельные и последовательные области Параллельные и последовательные области Директива parallel Сокращённая запись Переменные среды и вспомогательные
- 34. Параллельные и последовательные области В момент запуска программы порождается единственная нить-мастер или «основная» нить. Основная нить
- 35. Пример 3 #include "stdafx.h" #include #include "windows.h" #include using namespace std; int main(){ SetConsoleCP(1251); SetConsoleOutputCP(1251); printf("Последовательная
- 36. Опции parallel • if(условие) – выполнение параллельной области по условию. Вхождение в параллельную область осуществляется только
- 37. Опции parallel private(список) – задаёт список переменных, для которых порождается локальная копия в каждой нити; начальное
- 38. Пример 4 //Подсчет общего количества порождённых нитей #include "stdafx.h" #include #include "windows.h" #include using namespace std;
- 39. Переменные среды и вспомогательные функции Перед запуском программы количество нитей, выполняющих параллельную область, можно задать, определив
- 40. Пример 5 // Демонстрация применение функции omp_set_num_threads() и опции num_threads. #include "stdafx.h" #include #include "windows.h" #include
- 41. Переменные среды и вспомогательные функции В некоторых случаях система может динамически изменять количество нитей, используемых для
- 42. Пример 6 #include "stdafx.h" #include #include "windows.h" #include using namespace std; int main(int argc, char *argv[]){
- 43. Переменные среды и вспомогательные функции Функция omp_get_max_threads() возвращает максимально допустимое число нитей для использования в следующей
- 44. Пример 7 #include "stdafx.h" #include #include "windows.h" #include using namespace std; int main(int argc, char *argv[]){
- 45. Результаты выполнения (пример 7). Часть 1, нить 0 - 0 Часть 1, нить 0 - 5
- 46. Переменные среды и вспомогательные функции Узнать значение переменной OMP_NESTED можно при помощи функции omp_get_nested(): int omp_get_nested(void);
- 47. Пример 8 #include "stdafx.h" #include #include "windows.h" #include using namespace std; void mode(void){ if(omp_in_parallel()) cout else
- 48. Результаты выполнения примера 8 Последовательная область Параллельная область Параллельная область Параллельная область Параллельная область Параллельная область
- 49. Директива single Директивы single для выполнения только один раз : #pragma omp single [опция [[,] опция]...]
- 50. Все опции указываются у директивы single, Какая именно нить будет выполнять выделенный участок программы, не специфицируется.
- 51. Пример 9 #include "stdafx.h" #include #include "windows.h" #include using namespace std; int main(int argc, char *argv[]){
- 52. Результаты выполнения примера 9 Сообщение 1 Сообщение 1 Сообщение 2 Сообщение 1 Сообщение 2 Сообщение 1
- 53. Пример 10 #include "stdafx.h" #include #include "windows.h" #include using namespace std; int main(int argc, char *argv[]){
- 54. Результаты выполнения примера 10 Значение n (начало)0 Значение n (начало)6 Значение n (начало)4 Значение n (начало)5
- 55. Директивы master и barrier Директивы master выделяют участок кода, который будет выполнен только нитью-мастером. Остальные нити
- 56. Пример 11 #include "stdafx.h" #include #include "windows.h" #include using namespace std; int main(int argc, char *argv[]){
- 58. Скачать презентацию

Литература:
Методическое пособие А. С. Антонова «Введение в параллельные вычисления»
Лекции по параллельным
Литература:
Методическое пособие А. С. Антонова «Введение в параллельные вычисления»
Лекции по параллельным

Распределенная система — это набор независимых компьютеров, представляющиеся их пользователям единой

Закон Амдала
4
Закон Амдала
4
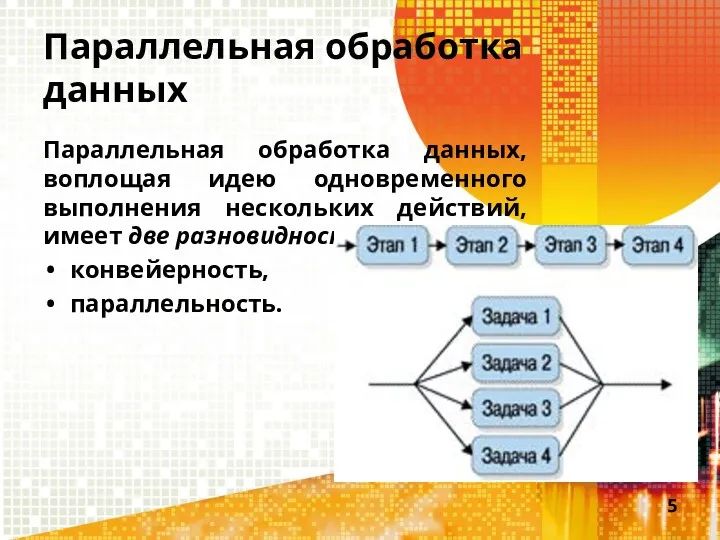
Параллельная обработка данных
Параллельная обработка данных, воплощая идею одновременного выполнения нескольких действий,
Параллельная обработка данных
Параллельная обработка данных, воплощая идею одновременного выполнения нескольких действий,
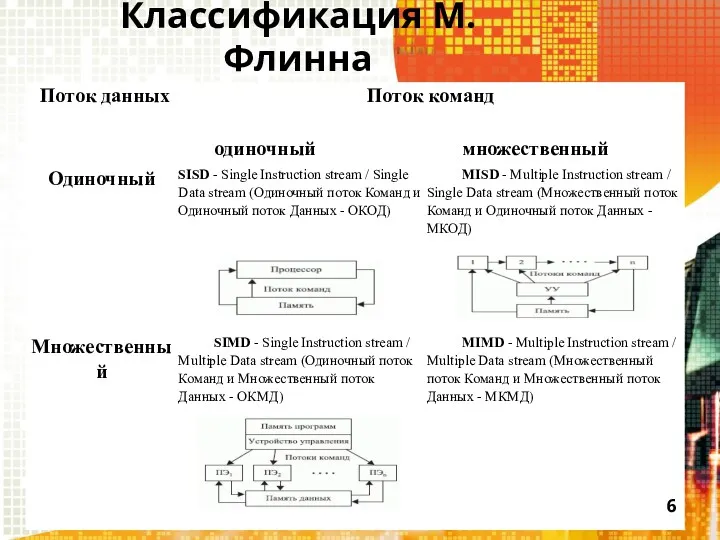
Классификация М. Флинна
Классификация М. Флинна

Суперкомпьютеры
Кластеры
Grid-системы
Некоторые примеры
II-вычислительных систем
Суперкомпьютеры
Кластеры
Grid-системы
Некоторые примеры
II-вычислительных систем

Суперкомпьютеры
Суперкомпьютер МГУ «Ломоносов»
Суперкомпьютер – вычислительная машина, значительно превосходящая по своим техническим
Суперкомпьютеры
Суперкомпьютер МГУ «Ломоносов»
Суперкомпьютер – вычислительная машина, значительно превосходящая по своим техническим

Кластеры
Кластер «TEdge-Mini»
Кластер – группа компьютеров, объединенных в локальную вычислительную сеть (ЛВС)
Кластеры
Кластер «TEdge-Mini»
Кластер – группа компьютеров, объединенных в локальную вычислительную сеть (ЛВС)

Grid-системы
Grid-система – группа слабосвязанных компьютеров, объединенных с помощью локальной вычислительной сети
Grid-системы
Grid-система – группа слабосвязанных компьютеров, объединенных с помощью локальной вычислительной сети

Проблемы координации
Для координации задач, выполняемых параллельно, требуется обеспечить связь между ними
Проблемы координации
Для координации задач, выполняемых параллельно, требуется обеспечить связь между ними

«Гонка» данных
Если несколько задач одновременно попытаются изменить некоторую общую область данных,
«Гонка» данных
Если несколько задач одновременно попытаются изменить некоторую общую область данных,

Бесконечная отсрочка
Если одна или несколько задач ожидают сеанса связи до своего
Бесконечная отсрочка
Если одна или несколько задач ожидают сеанса связи до своего
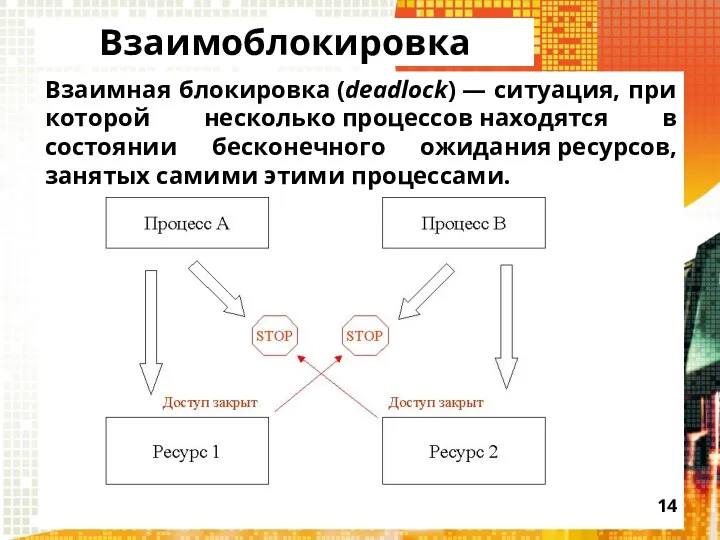
Взаимоблокировка
Взаимная блокировка (deadlock) — ситуация, при которой несколько процессов находятся в состоянии бесконечного ожидания ресурсов, занятых
Взаимоблокировка
Взаимная блокировка (deadlock) — ситуация, при которой несколько процессов находятся в состоянии бесконечного ожидания ресурсов, занятых

Трудности организации связи
Многие распространенные параллельные среды (например, кластеры) зачастую состоят из
Трудности организации связи
Многие распространенные параллельные среды (например, кластеры) зачастую состоят из

Модели параллельных вычислений
POSIX Threads - стандарт для нитей. Стандарт определяет
Модели параллельных вычислений
POSIX Threads - стандарт для нитей. Стандарт определяет

POSIX Threads
POSIX определяет основной набор функций и структур данных, чтобы
POSIX Threads
POSIX определяет основной набор функций и структур данных, чтобы

PVM (Parallel Virtual Machine)
PVM представляет собой набор программных средств и библиотек,
PVM (Parallel Virtual Machine)
PVM представляет собой набор программных средств и библиотек,

MPI (Message Passing Interface)
Базовым механизмом связи между MPI процессами является передача
MPI (Message Passing Interface)
Базовым механизмом связи между MPI процессами является передача

OpenMP
OpenMP предполагается SPMD-модель (Single Program Multiple Data) параллельного программирования, в рамках
OpenMP
OpenMP предполагается SPMD-модель (Single Program Multiple Data) параллельного программирования, в рамках

CUDA (Compute Unified Device Architecture)
Технология CUDA вводит ряд дополнительных расширений для
CUDA (Compute Unified Device Architecture)
Технология CUDA вводит ряд дополнительных расширений для

Использование моделей ПВ :
При необходимости решения задач распределенных вычислений на базе
Использование моделей ПВ :
При необходимости решения задач распределенных вычислений на базе

Основные понятия
Компиляция программы
Модель параллельной программы
Директивы и функции
Выполнение программы
Замер времени
Основные понятия
Компиляция программы
Модель параллельной программы
Директивы и функции
Выполнение программы
Замер времени

OpenMP
OpenMP (Open Multi-Processing) — открытый стандарт для распараллеливания программ на языках Си, Си++ и Фортран. Описывает совокупность директив компилятора, библиотечных процедур и переменных
OpenMP
OpenMP (Open Multi-Processing) — открытый стандарт для распараллеливания программ на языках Си, Си++ и Фортран. Описывает совокупность директив компилятора, библиотечных процедур и переменных

Преимущества OpenMP
1. Разработчик не создает новую параллельную программу, а просто
Преимущества OpenMP
1. Разработчик не создает новую параллельную программу, а просто

Модель параллельной программы
OpenMP предполагается SPMD-модель (Single Program Multiple Data) параллельного программирования,
Модель параллельной программы
OpenMP предполагается SPMD-модель (Single Program Multiple Data) параллельного программирования,
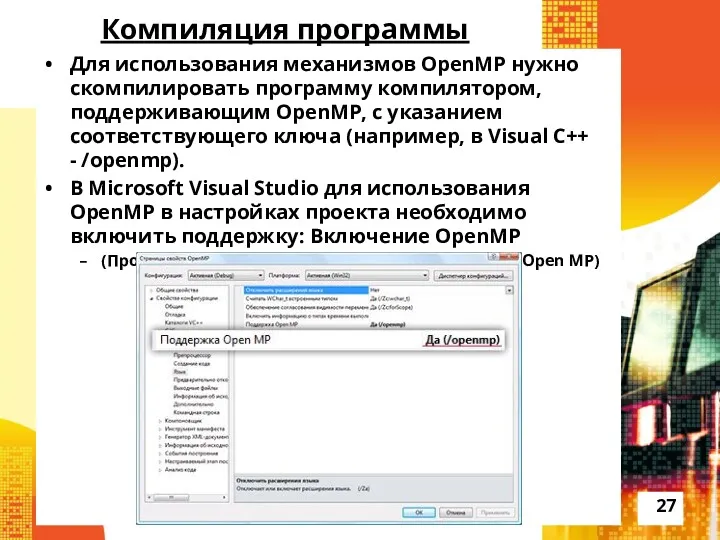
Компиляция программы
Для использования механизмов OpenMP нужно скомпилировать программу компилятором, поддерживающим OpenMP,
Компиляция программы
Для использования механизмов OpenMP нужно скомпилировать программу компилятором, поддерживающим OpenMP,

Использование OpenMP
Заголовочный файл библиотеки называется omp.h:
#include
Директивы OpenMP для C/C++
Использование OpenMP
Заголовочный файл библиотеки называется omp.h:
#include
Директивы OpenMP для C/C++

Пример 1
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
Пример 1
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;

Директивы и функции
Формат директивы на Си/Си++:
#pragma omp directive-name [опция[[,] опция]...]
Ассоциированные
Директивы и функции
Формат директивы на Си/Си++:
#pragma omp directive-name [опция[[,] опция]...]
Ассоциированные

Замер времени
Функции для работы с системным таймером:
omp_get_wtime() - возвращает в вызвавшей
Замер времени
Функции для работы с системным таймером:
omp_get_wtime() - возвращает в вызвавшей

Пример 2
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
Пример 2
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;

Параллельные и
последовательные области
Параллельные и последовательные области
Директива parallel
Сокращённая запись
Переменные среды и
Параллельные и
последовательные области
Параллельные и последовательные области
Директива parallel
Сокращённая запись
Переменные среды и

Параллельные и последовательные области
В момент запуска программы порождается единственная нить-мастер или
Параллельные и последовательные области
В момент запуска программы порождается единственная нить-мастер или

Пример 3
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
int
Пример 3
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
int

Опции parallel
• if(условие) – выполнение параллельной области по условию. Вхождение в
Опции parallel
• if(условие) – выполнение параллельной области по условию. Вхождение в

Опции parallel
private(список) – задаёт список переменных, для которых порождается локальная
Опции parallel
private(список) – задаёт список переменных, для которых порождается локальная
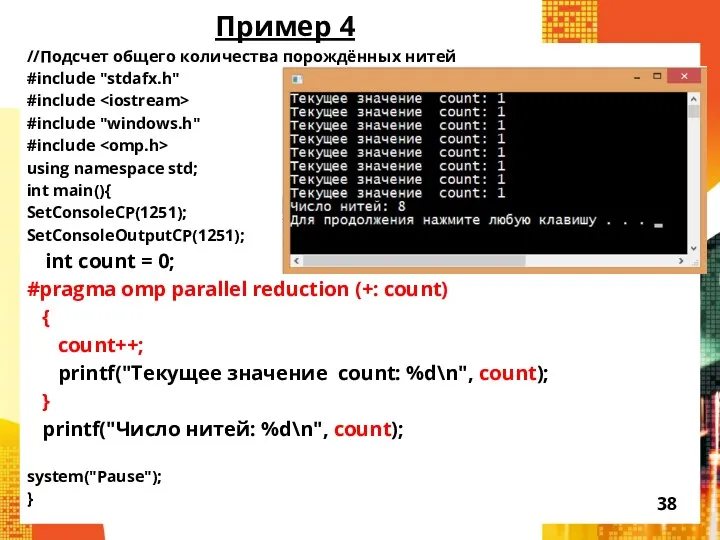
Пример 4
//Подсчет общего количества порождённых нитей
#include "stdafx.h"
#include
#include "windows.h"
#include
Пример 4
//Подсчет общего количества порождённых нитей
#include "stdafx.h"
#include
#include "windows.h"
#include

Переменные среды и вспомогательные функции
Перед запуском программы количество нитей, выполняющих параллельную
Переменные среды и вспомогательные функции
Перед запуском программы количество нитей, выполняющих параллельную
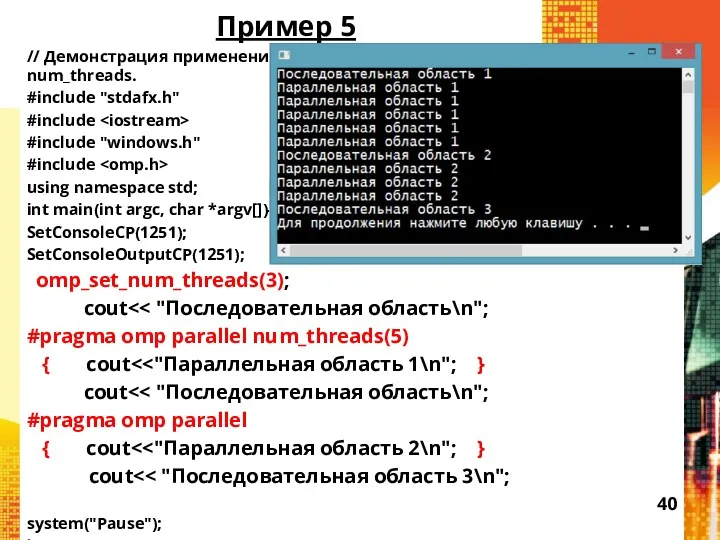
Пример 5
// Демонстрация применение функции omp_set_num_threads() и опции num_threads.
#include "stdafx.h"
Пример 5
// Демонстрация применение функции omp_set_num_threads() и опции num_threads.
#include "stdafx.h"

Переменные среды и вспомогательные функции
В некоторых случаях система может динамически изменять
Переменные среды и вспомогательные функции
В некоторых случаях система может динамически изменять

Пример 6
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace
Пример 6
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace

Переменные среды и вспомогательные функции
Функция omp_get_max_threads() возвращает максимально допустимое число нитей
Переменные среды и вспомогательные функции
Функция omp_get_max_threads() возвращает максимально допустимое число нитей

Пример 7
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace
Пример 7
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace

Результаты выполнения (пример 7).
Часть 1, нить 0 - 0
Часть 1, нить
Результаты выполнения (пример 7).
Часть 1, нить 0 - 0
Часть 1, нить

Переменные среды и вспомогательные функции
Узнать значение переменной OMP_NESTED можно при помощи
Переменные среды и вспомогательные функции
Узнать значение переменной OMP_NESTED можно при помощи

Пример 8
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace
Пример 8
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace

Результаты выполнения примера 8
Последовательная область
Параллельная область
Параллельная область
Параллельная область
Параллельная область
Параллельная область
Параллельная область
Параллельная
Результаты выполнения примера 8
Последовательная область
Параллельная область
Параллельная область
Параллельная область
Параллельная область
Параллельная область
Параллельная область
Параллельная

Директива single
Директивы single для выполнения только один раз :
#pragma omp
Директива single
Директивы single для выполнения только один раз :
#pragma omp

Все опции указываются у директивы single, Какая именно нить будет выполнять
Все опции указываются у директивы single, Какая именно нить будет выполнять

Пример 9
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
Пример 9
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;

Результаты выполнения примера 9
Сообщение 1
Сообщение 1
Сообщение 2
Сообщение 1
Сообщение 2
Сообщение 1
Сообщение 2
Сообщение
Результаты выполнения примера 9
Сообщение 1
Сообщение 1
Сообщение 2
Сообщение 1
Сообщение 2
Сообщение 1
Сообщение 2
Сообщение

Пример 10
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
Пример 10
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
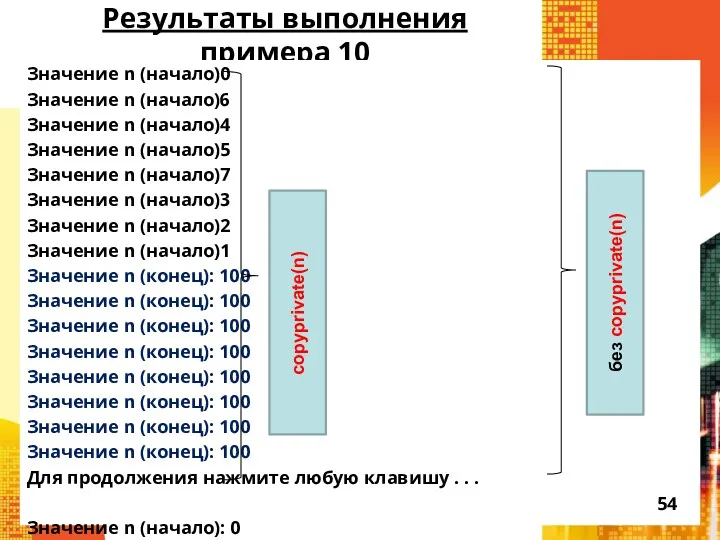
Результаты выполнения примера 10
Значение n (начало)0
Значение n (начало)6
Значение n (начало)4
Значение n
Результаты выполнения примера 10
Значение n (начало)0
Значение n (начало)6
Значение n (начало)4
Значение n

Директивы master и barrier
Директивы master выделяют участок кода, который будет
Директивы master и barrier
Директивы master выделяют участок кода, который будет

Пример 11
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
Пример 11
#include "stdafx.h"
#include
#include "windows.h"
#include
using namespace std;
 Разработка рекомендаций по оценке безопасности информационных систем
Разработка рекомендаций по оценке безопасности информационных систем Принципы работы в сети. Исключения
Принципы работы в сети. Исключения Частотные методы улучшения изображений. Лекция 3
Частотные методы улучшения изображений. Лекция 3 Программы Microsoft Office: PowerPoint 2010, Word 2010
Программы Microsoft Office: PowerPoint 2010, Word 2010 Стандартизация сетей. Модель OSI
Стандартизация сетей. Модель OSI Пример слайда. Sydney Opera House is Australia’s
Пример слайда. Sydney Opera House is Australia’s История технологий шифрования
История технологий шифрования Основные команды ассемблера
Основные команды ассемблера Вкладені цикли. Покрокове введення та виведення даних. Лекція №8
Вкладені цикли. Покрокове введення та виведення даних. Лекція №8 Media & newspapers
Media & newspapers Сборочное моделирование. Решения по управлению жизненным циклом, продукт IBM/Dassault Systemes
Сборочное моделирование. Решения по управлению жизненным циклом, продукт IBM/Dassault Systemes Российское движение школьников. Информационно-медийное направление
Российское движение школьников. Информационно-медийное направление Интернет-коммуникации. Автоматизация
Интернет-коммуникации. Автоматизация Графический метод решения уравнений в Excel
Графический метод решения уравнений в Excel Электронный листок нетрудоспособности на территории Ленинградской области
Электронный листок нетрудоспособности на территории Ленинградской области Построение и анализ алгоритмов. Алгоритмы на графах. МОД в задаче коммивояжёра. (Лекция 6.2)
Построение и анализ алгоритмов. Алгоритмы на графах. МОД в задаче коммивояжёра. (Лекция 6.2) История серии видеоигр: Crysis, Wolfenstein, Dead Space
История серии видеоигр: Crysis, Wolfenstein, Dead Space Блогеры вместо СМИ
Блогеры вместо СМИ Путешествие по сказкам. Блок-схема. 6 класс
Путешествие по сказкам. Блок-схема. 6 класс Массивы. Строки. Пользовательские типы.(Тема 3)
Массивы. Строки. Пользовательские типы.(Тема 3) Интерактивная компьютерная графика
Интерактивная компьютерная графика Кодирование и шифрование данных
Кодирование и шифрование данных Мобильное рабочее место
Мобильное рабочее место Электронные таблицы. Программа MS Excel
Электронные таблицы. Программа MS Excel Візуальна система формування набору об’єктів нерухомості на карті
Візуальна система формування набору об’єктів нерухомості на карті Создание и форматирование таблиц в текстовом редакторе
Создание и форматирование таблиц в текстовом редакторе Текстовые редакторы. Урок 10
Текстовые редакторы. Урок 10 Создание веб-сайтов
Создание веб-сайтов