- Параллельные компьютерные архитектуры

Содержание
- 2. Мультипроцессоры и мультикомпьютеры В любой параллельной компьютерной системе процессоры, выполняющие разные части единого задания, должны как-то
- 3. Мультипроцессоры Параллельный компьютер, в котором все процессоры совместно используют общую физическую память, называется мультипроцессором, или системой
- 4. Все процессоры в мультипроцессоре используют единое адресное пространство → функционирует только одна копия операционной системы Организация,
- 5. Мультикомпьютеры Во втором варианте параллельной архитектуры каждый процессор имеет собственную память, доступную только этому процессору Такая
- 6. Поскольку процессоры в мультикомпьютере не могут взаимодействовать друг с другом простыми обращениями к общей памяти, процессоры
- 7. При отсутствии общей памяти, реализованной аппаратно, предполагается определенная программная структура Пример: Сначала процессору 0 нужно как-то
- 8. Вопрос? Зачем вообще создавать мультикомпьютеры, если мультипроцессоры гораздо проще программировать?
- 9. Вопрос? Ответ Создать большой мультикомпьютер проще и дешевле, чем мультипроцессор с таким же количеством процессоров. Реализация
- 10. Дилемма Мультипроцессоры сложно разрабатывать, но легко программировать, а мультикомпьютеры легко строить, но трудно программировать
- 11. Гибридные системы Различные реализации совместной память можно реализовывать по-разному, причем каждый вариант будет иметь достоинства и
- 12. Уровни реализации общей памяти Компьютерные системы не монолитны, а имеют многоуровневую структуру а) общая память, реализованная
- 13. Уровни, на которых можно реализовать общую память: аппаратная реализация (а); ОС (б); программная реализация (в)
- 14. Классификация параллельных компьютерных систем В основе классификации лежат понятия потоков команд и потоков данных. Поток команд
- 15. SISD (Single Instruction stream Single Data stream) SISD - один поток команд с одним потоком данных)
- 16. SIMD (Single Instruction-stream Multiple Data-stream) SIMD - один поток команд с несколькими потоками данных, имеется один
- 17. MISD (Multiple Instruction-stream Single Data-stream) MISD— несколько потоков команд с одним потоком данных) - несколько команд
- 18. MIMD (Multiple Instruction-stream Multiple Data- stream) MIMD— несколько потоков команд с несколькими потоками данных - несколько
- 20. Семантика памяти Семантику памяти можно рассматривать как контракт между программным и аппаратным обеспечением памяти. Если программное
- 21. Строгая состоятельность При любом считывании из адреса х всегда возвращается значение самой последней записи в х.
- 22. Секвенциальная состоятельность В соответствии с этой моделью при наличии нескольких запросов на чтение и запись порядок
- 23. Пример Предположим, процессор 1 записывает значение 100 в слово х, а через 1 нс процессор 2
- 24. Возможные варианты очередности событий В первом варианте оба процессора получают значение 200 в каждой из двух
- 25. Правила секвенциальной состоятельности не выглядят столь «жестокими», как правила строгой состоятельности Даже если несколько событий совершаются
- 26. Процессорная состоятельность Не слишком строгая модель, но зато ее легче реализовать на больших мультипроцессорах Свойства: 1.
- 27. Два процессора (1 и 2) начинают три операции записи значений 1А, 1В, 1С и 2А, 2В,
- 28. Слабая состоятельность В модели слабой состоятельности не гарантируется, что операции записи, произведенные одним процессором, будут восприниматься
- 29. Свободная состоятельность Используется нечто похожее на критические секции программы - если процесс выходит за пределы критической
- 30. Чтобы считать или записать совместно используемую переменную, процессор (то есть его программное обеспечение) сначала должен выполнить
- 31. Когда начинается следующая операция acquire, производится проверка, все ли предыдущие операции release завершены Если нет, то
- 32. UMA-мультипроцессоры в симметричных мультипроцессорных архитектурах UMA (Uniform Memory Access) — однородный доступ к памяти В UMA-машинах
- 33. Варианты мультипроцессора на одной шине: без кэш-памяти (а); с кэш-памятью (б); с кэш-памятью и отдельными модулями
- 34. Согласованность кэш-памяти Проблема согласованности кэшей Протоколы согласования кэшей Следящий кэш- контроллер кэш-памяти, мониторит запросы, идущие по
- 35. Сквозная запись Стратегия обновления Стратегия объявления данных недействительными
- 36. Протокол отложенной записи MESI (Invalid, Shared, Exclusive, Modified — недействительный, разделяемый, эксклюзивный, модифицированный) недействительный — элемент
- 38. NUMA-мультипроцессоры NUMA (NonUniform Memory Access) - неоднородный доступ к памяти NUMA-машины имеют три ключевые характеристики, которые
- 39. Если время доступа к удаленной памяти не замаскировано кэшированием (кэш отсутствует), такая система называется NC-NUMA (No
- 40. NUMA-мультипроцессор Sun Fire E25K Система Е25К содержит 18 наборов плат, каждый набор состоит из платы процессор-память,
- 41. Мультипроцессор Е25К компании Sun Microsystems
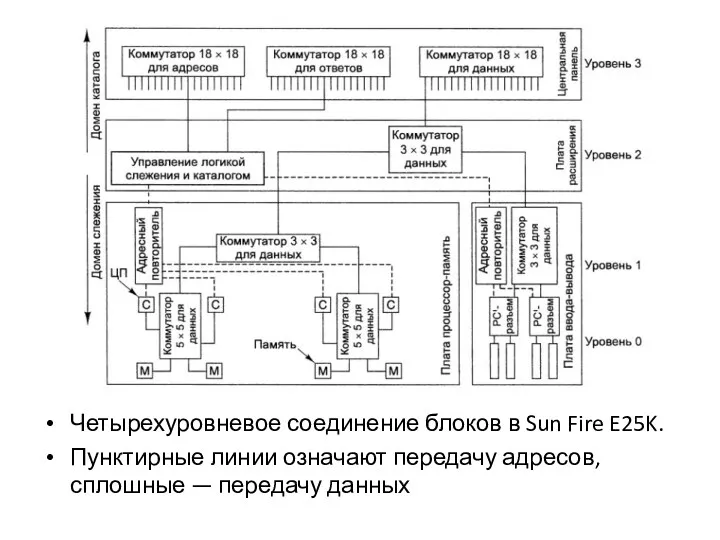
- 42. Четырехуровневое соединение блоков в Sun Fire E25K. Пунктирные линии означают передачу адресов, сплошные — передачу данных
- 43. Общая память На самом нижнем уровне адресное пространство объемом 576 Гбайт разбивается на 2^29 блоков по
- 44. Каждый блок памяти (и каждая строка кэша всех микросхем) может находиться в одном из трех состояний:
- 45. На уровне наборов плат логика слежения обеспечивает каждому процессору возможность сверять поступающие запросы со списком блоков
- 46. За счет распределения нагрузки между разными устройствами на разных платах Sun Fire E25K может работать с
- 47. СОМА-мультипроцессоры СОМА (Cache Only Memory Access) — доступ только к кэш-памяти Использования основной памяти каждого процессора
- 49. Скачать презентацию
Мультипроцессоры и мультикомпьютеры
В любой параллельной компьютерной системе процессоры, выполняющие разные части единого задания,
Мультипроцессоры и мультикомпьютеры
В любой параллельной компьютерной системе процессоры, выполняющие разные части единого задания,

Мультипроцессоры
Параллельный компьютер, в котором все процессоры совместно используют общую физическую память, называется мультипроцессором,
Мультипроцессоры
Параллельный компьютер, в котором все процессоры совместно используют общую физическую память, называется мультипроцессором,
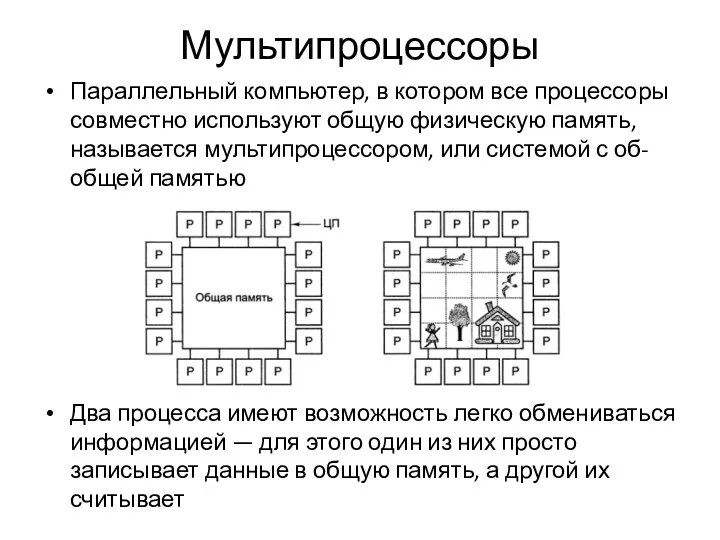
Все процессоры в мультипроцессоре используют единое адресное пространство → функционирует только одна копия
Все процессоры в мультипроцессоре используют единое адресное пространство → функционирует только одна копия

Мультикомпьютеры
Во втором варианте параллельной архитектуры каждый процессор имеет собственную память, доступную только этому
Мультикомпьютеры
Во втором варианте параллельной архитектуры каждый процессор имеет собственную память, доступную только этому

Поскольку процессоры в мультикомпьютере не могут взаимодействовать друг с другом простыми обращениями к
Поскольку процессоры в мультикомпьютере не могут взаимодействовать друг с другом простыми обращениями к
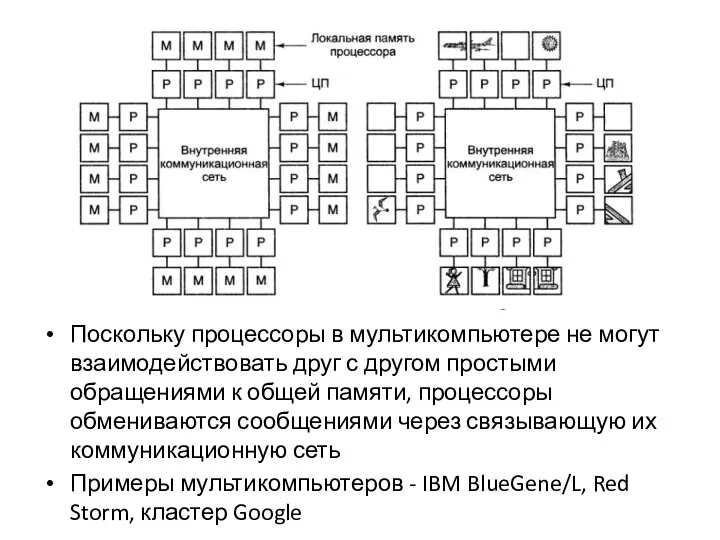
При отсутствии общей памяти, реализованной аппаратно, предполагается определенная программная структура
Пример: Сначала процессору 0
При отсутствии общей памяти, реализованной аппаратно, предполагается определенная программная структура
Пример: Сначала процессору 0

Вопрос?
Зачем вообще создавать мультикомпьютеры, если мультипроцессоры гораздо проще программировать?
Вопрос?
Зачем вообще создавать мультикомпьютеры, если мультипроцессоры гораздо проще программировать?

Вопрос?
Ответ
Создать большой мультикомпьютер проще и дешевле, чем мультипроцессор с таким же количеством процессоров.
Вопрос?
Ответ
Создать большой мультикомпьютер проще и дешевле, чем мультипроцессор с таким же количеством процессоров.

Дилемма
Мультипроцессоры сложно разрабатывать, но легко программировать, а мультикомпьютеры легко строить, но трудно
Дилемма
Мультипроцессоры сложно разрабатывать, но легко программировать, а мультикомпьютеры легко строить, но трудно

Гибридные системы
Различные реализации совместной память можно реализовывать по-разному, причем каждый вариант будет иметь
Гибридные системы
Различные реализации совместной память можно реализовывать по-разному, причем каждый вариант будет иметь

Уровни реализации общей памяти
Компьютерные системы не монолитны, а имеют многоуровневую структуру
а) общая память,
Уровни реализации общей памяти
Компьютерные системы не монолитны, а имеют многоуровневую структуру
а) общая память,

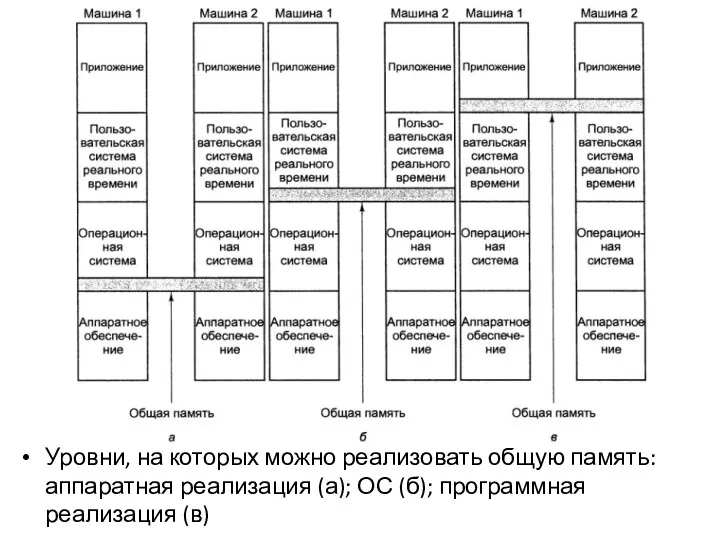
Уровни, на которых можно реализовать общую память: аппаратная реализация (а); ОС (б); программная
Уровни, на которых можно реализовать общую память: аппаратная реализация (а); ОС (б); программная
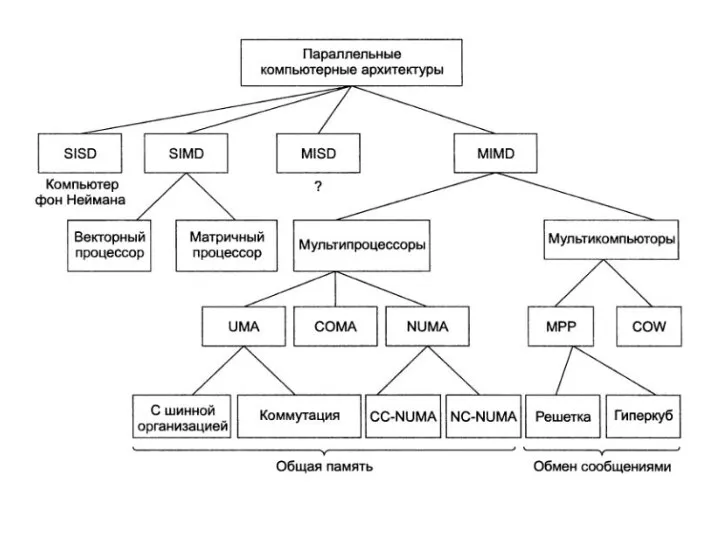
Классификация параллельных компьютерных систем
В основе классификации лежат понятия потоков команд и потоков данных.
Классификация параллельных компьютерных систем
В основе классификации лежат понятия потоков команд и потоков данных.

SISD (Single Instruction stream Single Data stream)
SISD - один поток команд с одним
SISD (Single Instruction stream Single Data stream)
SISD - один поток команд с одним

SIMD (Single Instruction-stream Multiple Data-stream)
SIMD - один поток команд с несколькими потоками данных,
SIMD (Single Instruction-stream Multiple Data-stream)
SIMD - один поток команд с несколькими потоками данных,

MISD (Multiple Instruction-stream Single Data-stream)
MISD— несколько потоков команд с одним потоком данных) -
MISD (Multiple Instruction-stream Single Data-stream)
MISD— несколько потоков команд с одним потоком данных) -

MIMD (Multiple Instruction-stream Multiple Data- stream)
MIMD— несколько потоков команд с несколькими потоками данных
MIMD (Multiple Instruction-stream Multiple Data- stream)
MIMD— несколько потоков команд с несколькими потоками данных

Семантика памяти
Семантику памяти можно рассматривать как контракт между программным и аппаратным обеспечением памяти.
Семантика памяти
Семантику памяти можно рассматривать как контракт между программным и аппаратным обеспечением памяти.

Строгая состоятельность
При любом считывании из адреса х всегда возвращается значение самой последней записи
Строгая состоятельность
При любом считывании из адреса х всегда возвращается значение самой последней записи

Секвенциальная состоятельность
В соответствии с этой моделью при наличии нескольких запросов на чтение и
Секвенциальная состоятельность
В соответствии с этой моделью при наличии нескольких запросов на чтение и

Пример
Предположим, процессор 1 записывает значение 100 в слово х, а через 1 нс
Пример
Предположим, процессор 1 записывает значение 100 в слово х, а через 1 нс
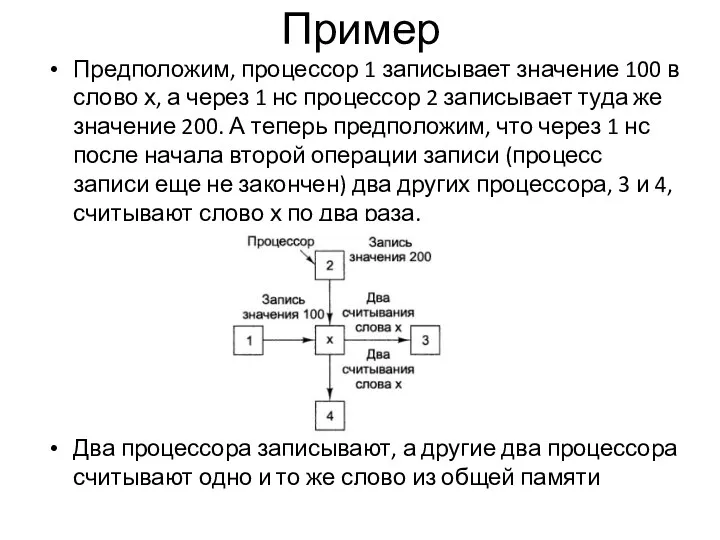
Возможные варианты очередности событий
В первом варианте оба процессора получают значение 200 в каждой
Возможные варианты очередности событий
В первом варианте оба процессора получают значение 200 в каждой

Правила секвенциальной состоятельности не выглядят столь «жестокими», как правила строгой состоятельности
Даже если несколько
Правила секвенциальной состоятельности не выглядят столь «жестокими», как правила строгой состоятельности
Даже если несколько

Процессорная состоятельность
Не слишком строгая модель, но зато ее легче реализовать на больших мультипроцессорах
Процессорная состоятельность
Не слишком строгая модель, но зато ее легче реализовать на больших мультипроцессорах

Два процессора (1 и 2) начинают три операции записи значений 1А, 1В, 1С
Два процессора (1 и 2) начинают три операции записи значений 1А, 1В, 1С

Слабая состоятельность
В модели слабой состоятельности не гарантируется, что операции записи, произведенные одним процессором,
Слабая состоятельность
В модели слабой состоятельности не гарантируется, что операции записи, произведенные одним процессором,
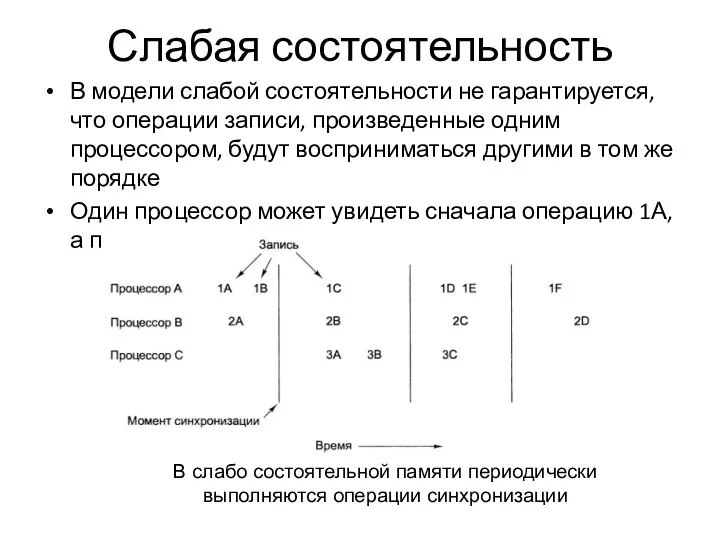
Свободная состоятельность
Используется нечто похожее на критические секции программы - если процесс выходит за
Свободная состоятельность
Используется нечто похожее на критические секции программы - если процесс выходит за

Чтобы считать или записать совместно используемую переменную, процессор (то есть его программное обеспечение)
Чтобы считать или записать совместно используемую переменную, процессор (то есть его программное обеспечение)

Когда начинается следующая операция acquire, производится проверка, все ли предыдущие операции release завершены
Когда начинается следующая операция acquire, производится проверка, все ли предыдущие операции release завершены

UMA-мультипроцессоры в симметричных мультипроцессорных архитектурах
UMA (Uniform Memory Access) — однородный доступ к памяти
В
UMA-мультипроцессоры в симметричных мультипроцессорных архитектурах
UMA (Uniform Memory Access) — однородный доступ к памяти
В

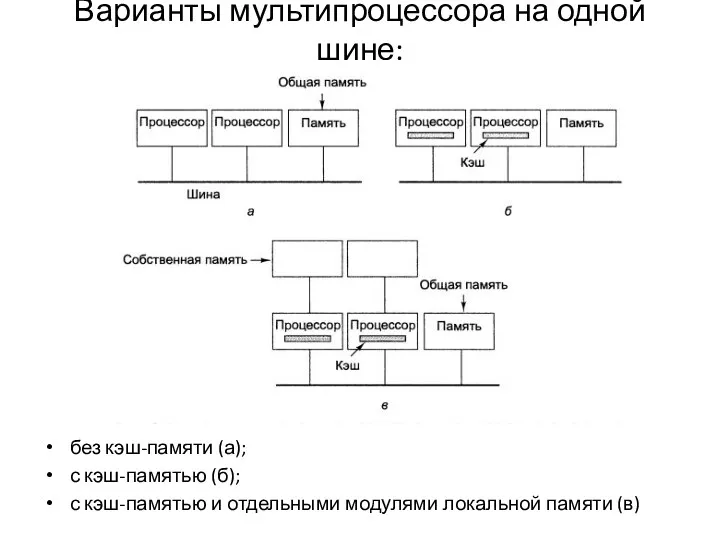
Варианты мультипроцессора на одной шине:
без кэш-памяти (а);
с кэш-памятью (б);
с кэш-памятью и
Варианты мультипроцессора на одной шине:
без кэш-памяти (а);
с кэш-памятью (б);
с кэш-памятью и
Согласованность кэш-памяти
Проблема согласованности кэшей
Протоколы согласования кэшей
Следящий кэш- контроллер кэш-памяти, мониторит запросы, идущие по
Согласованность кэш-памяти
Проблема согласованности кэшей
Протоколы согласования кэшей
Следящий кэш- контроллер кэш-памяти, мониторит запросы, идущие по

Сквозная запись
Стратегия обновления
Стратегия объявления данных недействительными
Сквозная запись
Стратегия обновления
Стратегия объявления данных недействительными

Протокол отложенной записи
MESI (Invalid, Shared, Exclusive, Modified — недействительный, разделяемый, эксклюзивный, модифицированный)
недействительный —
Протокол отложенной записи
MESI (Invalid, Shared, Exclusive, Modified — недействительный, разделяемый, эксклюзивный, модифицированный)
недействительный —


NUMA-мультипроцессоры
NUMA (NonUniform Memory Access) - неоднородный доступ к памяти
NUMA-машины имеют три ключевые характеристики,
NUMA-мультипроцессоры
NUMA (NonUniform Memory Access) - неоднородный доступ к памяти
NUMA-машины имеют три ключевые характеристики,

Если время доступа к удаленной памяти не замаскировано кэшированием (кэш отсутствует), такая система
Если время доступа к удаленной памяти не замаскировано кэшированием (кэш отсутствует), такая система

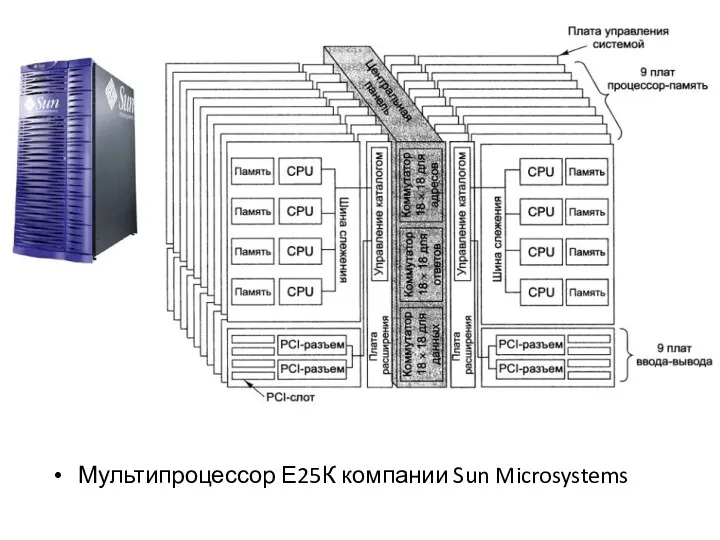
NUMA-мультипроцессор Sun Fire E25K
Система Е25К содержит 18 наборов плат, каждый набор состоит из
NUMA-мультипроцессор Sun Fire E25K
Система Е25К содержит 18 наборов плат, каждый набор состоит из

Мультипроцессор Е25К компании Sun Microsystems
Мультипроцессор Е25К компании Sun Microsystems
Четырехуровневое соединение блоков в Sun Fire E25K.
Пунктирные линии означают передачу адресов, сплошные —
Четырехуровневое соединение блоков в Sun Fire E25K.
Пунктирные линии означают передачу адресов, сплошные —
Общая память
На самом нижнем уровне адресное пространство объемом 576 Гбайт разбивается на 2^29
Общая память
На самом нижнем уровне адресное пространство объемом 576 Гбайт разбивается на 2^29

Каждый блок памяти (и каждая строка кэша всех микросхем) может находиться в одном
Каждый блок памяти (и каждая строка кэша всех микросхем) может находиться в одном

На уровне наборов плат логика слежения обеспечивает каждому процессору возможность сверять поступающие запросы
На уровне наборов плат логика слежения обеспечивает каждому процессору возможность сверять поступающие запросы

За счет распределения нагрузки между разными устройствами на разных платах Sun Fire E25K
За счет распределения нагрузки между разными устройствами на разных платах Sun Fire E25K

СОМА-мультипроцессоры
СОМА (Cache Only Memory Access) — доступ только к кэш-памяти
Использования основной памяти
СОМА-мультипроцессоры
СОМА (Cache Only Memory Access) — доступ только к кэш-памяти
Использования основной памяти

 Сайт andreevats.ru
Сайт andreevats.ru Решение задач части В демоверсии ЕГЭ-2013 по информатике
Решение задач части В демоверсии ЕГЭ-2013 по информатике Оформление документов по вознаграждению (инструкция для агентов)
Оформление документов по вознаграждению (инструкция для агентов) Артқы фон мен ойын кейіпкерлері
Артқы фон мен ойын кейіпкерлері 7-3-3
7-3-3 Лайфхаки Word
Лайфхаки Word Техника безопасности на уроках информатики
Техника безопасности на уроках информатики Применение мультимедиа и гипертекстовой технологии в системах поддержки управленческих решений
Применение мультимедиа и гипертекстовой технологии в системах поддержки управленческих решений Evolution media
Evolution media Представление о программных средах компьютерной графики. Лекция 18
Представление о программных средах компьютерной графики. Лекция 18 Отчет по сайту https://www.fanera-laverna.ru
Отчет по сайту https://www.fanera-laverna.ru Разработка программного обеспечения
Разработка программного обеспечения компьютерный тест по теме Множества (информатика по программе Горячева А.В., 4 класс)
компьютерный тест по теме Множества (информатика по программе Горячева А.В., 4 класс) Апгрейд телефонов для школьников
Апгрейд телефонов для школьников Что такое личный бренд?
Что такое личный бренд? Строки в С++
Строки в С++ Аппаратные и программные средства организации компьютерных сетей
Аппаратные и программные средства организации компьютерных сетей Понятие информации. Способы представления и кодирования информации. История развития ВТ
Понятие информации. Способы представления и кодирования информации. История развития ВТ Читаем в школе и дома. Внеклассное чтение для детей младшего и среднего школьного возраста. Путешествие по сайтам
Читаем в школе и дома. Внеклассное чтение для детей младшего и среднего школьного возраста. Путешествие по сайтам Простейшие программы
Простейшие программы Линейный алгоритм
Линейный алгоритм Dressage Training Tips from Experts
Dressage Training Tips from Experts Кросс-медиа
Кросс-медиа Технологии программирования
Технологии программирования Классификация современных компьютеров
Классификация современных компьютеров Создание Web-сайта. Структура Web-сайта
Создание Web-сайта. Структура Web-сайта Алгоритмы
Алгоритмы Технология обработки текстовой информации
Технология обработки текстовой информации