- Подсказки для оптимизатора

Содержание
- 2. План запроса Практически любую задачу по получению каких-либо результатов из базы данных можно решить несколькими способами,
- 3. Как это выглядит в ORACLE APEX?
- 4. Некоторые термины в плане запроса TABLE ACCESS FULL — сервер просмотрит все записи таблицы. TABLE ACCESS
- 5. Некоторые термины в плане запроса SORT MERGE JOIN — используется для соединения записей нескольких независимых источников.
- 6. Анализ плана запроса При анализе плана запроса необходимо примерно представлять объемы записей в таблицах и наличие
- 7. Full Table Scan (Table Access Full). Может показаться, что доступ к данным таблицы быстрее осуществлять через
- 8. Nested Loops Такое соединение может использоваться оптимизатором, когда небольшой основной набор записей (стоит первым в плане
- 9. Hash Joins Используется при соединении больших наборов данных. Оптимизатор использует наименьший из наборов данных для построения
- 10. Sort Merge Join Данное соединение может быть применено для независимых наборов данных. Обычно Oracle выбирает такую
- 11. Cartesian Joins Это соединение используется, когда одна и более таблиц не имеют никаких условий соединения с
- 12. Определение Подсказка (hint) – это указание оптимизатору на необходимость исполнения определенной формы доступа к данным на
- 13. Синтаксис {DELETE|INSERT|SELECT|UPDATE} /*+ hint [text] [hint[text]]... */... or {DELETE|INSERT|SELECT|UPDATE} --+ hint [text] [hint[text]]...
- 14. Примеры ====================================================== SELECT /*+ ALL_ROWS */ empno, ename, sal, job FROM emp WHERE ename = ‘CAT’;
- 15. Что будет, если подсказка написана неправильно… ORACLE игнорирует подсказки, которые не следуют за ключевыми словами DELETE,
- 16. Группы подсказок Подсказки можно разделить на следующие группы: подсказки задающие цели оптимизации подсказки задающие методы доступа
- 17. Подсказки, задающие цели оптимизации ALL_ROWS FIRST_ROWS(n) CHOOSE RULE
- 18. Пример (ALL_ROWS) SELECT /*+ ALL_ROWS */ employee_id, last_name, salary, job_id FROM employees
- 19. Пример (FIRST_ROWS(n)) SELECT /*+ FIRST_ROWS(10) */ empno, ename, sal, job FROM emp
- 20. Пример (CHOOSE) SELECT /*+ CHOOSE */ empno, ename, sal, job FROM emp WHERE empno = 7566;
- 21. Пример (RULE) SELECT --+ RULE empno, ename, sal, job FROM emp WHERE empno = 7566;
- 22. Подсказки, задающие методы доступа FULL ROWID INDEX INDEX_ASC INDEX_DESC INDEX_FFS NO_INDEX INDEX_COMBINE INDEX_JOIN ….
- 23. Пример (FULL) SELECT /*+ FULL(e) */ employee_id, last_name FROM hr.employees e WHERE last_name LIKE ‘%A’;
- 24. Пример (ROWID) SELECT /*+ROWID(emp)*/ * FROM emp WHERE rowid > 'AAAAtkAABAAAFNTAAA' AND empno = 155;
- 25. Пример (INDEX) SELECT /*+ INDEX (employees emp_department_ix)*/ employee_id, department_id FROM employees WHERE department_id > 50;
- 26. Пример (INDEX_ASC)
- 27. Пример (INDEX_ASC)
- 28. Пример (INDEX_ASC)
- 29. Пример (INDEX_DESC) SELECT /*+ INDEX_DESC(emp pk_emp) */ empno , ename FROM emp SELECT /*+ INDEX_DESC(emp pk_emp)
- 30. Пример (INDEX_FFS) SELECT /*+INDEX_FFS(emp emp_empno)*/ empno FROM emp WHERE empno > 200;
- 31. Пример (NO_INDEX) SELECT /*+NO_INDEX(emp emp_empno)*/ empno FROM emp WHERE empno > 200;
- 32. Пример (INDEX_COMBINE) SELECT /*+ INDEX_COMBINE(e emp_manager_ix emp_department_ix) */ * FROM employees e WHERE manager_id = 108
- 33. Пример (INDEX_JOIN) SELECT /*+ INDEX_JOIN(e emp_manager_ix emp_department_ix) */ department_id FROM employees e WHERE manager_id Оптимизатору рекомендовано
- 34. Подсказки для операции соединения (JOIN) USE_NL - использовать вложенные циклы для соединения указанных в подсказке таблиц;
- 35. Пример (USE_NL) SELECT /*+ USE_NL(customers) to get first row faster */ accounts.balance, customers.last_name, customers.first_name FROM accounts,
- 36. Пример (USE_MERGE) SELECT /*+USE_MERGE(emp dept)*/ * FROM emp, dept WHERE emp.deptno = dept.deptno;
- 37. Другие подсказки MATERIALIZE – материализовать промежуточную таблицу PARALLEL – распараллелить выполнение запроса И др.
- 38. Сбор статистики, полезной для оптимизатора Статистика по таблицам Количество записей Количество блоков Средняя длина записи Статистика
- 39. Процедуры для сбора статистики (пакет DBMS_STATS) GATHER_INDEX_STATS GATHER_TABLE_STATS GATHER_SCHEMA_STATS GATHER_DATABASE_STATS GATHER_SYSTEM_STATS Примечание: эти процедуры не запускаются
- 40. Представления словаря для просмотра статистики DBA_TABLES DBA_TAB_COL_STATISTICS DBA_INDEXES
- 41. Пример SELECT TABLE_NAME, NUM_ROWS, BLOCKS, AVG_ROW_LEN, TO_CHAR(LAST_ANALYZED, 'MM/DD/YYYY HH24:MI:SS') FROM DBA_TABLES WHERE TABLE_NAME IN ('SO_LINES_ALL','SO_HEADERS_ALL','SO_LAST_ALL');
- 43. Скачать презентацию

План запроса
Практически любую задачу по получению каких-либо результатов из базы данных
План запроса
Практически любую задачу по получению каких-либо результатов из базы данных
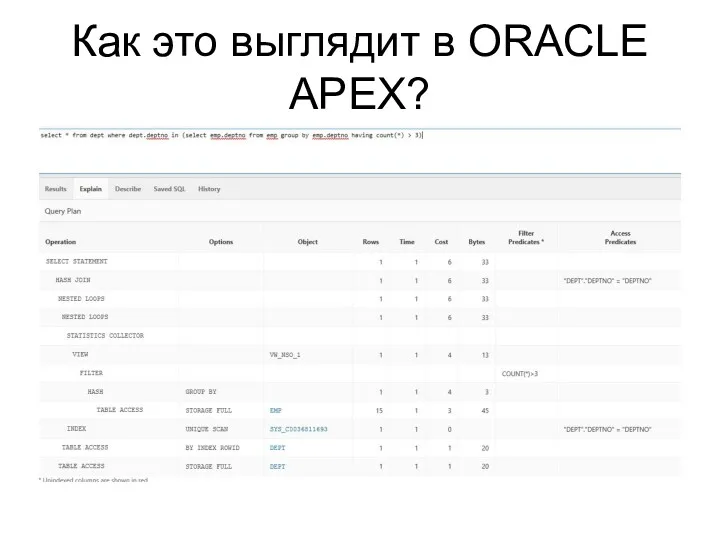
Как это выглядит в ORACLE APEX?
Как это выглядит в ORACLE APEX?

Некоторые термины в плане запроса
TABLE ACCESS FULL — сервер просмотрит все
Некоторые термины в плане запроса
TABLE ACCESS FULL — сервер просмотрит все

Некоторые термины в плане запроса
SORT MERGE JOIN — используется для соединения
Некоторые термины в плане запроса
SORT MERGE JOIN — используется для соединения

Анализ плана запроса
При анализе плана запроса необходимо примерно представлять объемы записей
Анализ плана запроса
При анализе плана запроса необходимо примерно представлять объемы записей

Full Table Scan (Table Access Full).
Может показаться, что доступ к данным
Full Table Scan (Table Access Full).
Может показаться, что доступ к данным

Nested Loops
Такое соединение может использоваться оптимизатором, когда небольшой основной набор записей
Nested Loops
Такое соединение может использоваться оптимизатором, когда небольшой основной набор записей

Hash Joins
Используется при соединении больших наборов данных. Оптимизатор использует наименьший из
Hash Joins
Используется при соединении больших наборов данных. Оптимизатор использует наименьший из

Sort Merge Join
Данное соединение может быть применено для независимых наборов данных.
Sort Merge Join
Данное соединение может быть применено для независимых наборов данных.

Cartesian Joins
Это соединение используется, когда одна и более таблиц не имеют
Cartesian Joins
Это соединение используется, когда одна и более таблиц не имеют

Определение
Подсказка (hint) – это указание оптимизатору на необходимость исполнения определенной формы
Определение
Подсказка (hint) – это указание оптимизатору на необходимость исполнения определенной формы
![Синтаксис {DELETE|INSERT|SELECT|UPDATE} /*+ hint [text] [hint[text]]... */... or {DELETE|INSERT|SELECT|UPDATE} --+ hint [text] [hint[text]]...](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/180638/slide-12.jpg)
Синтаксис
{DELETE|INSERT|SELECT|UPDATE} /*+ hint [text] [hint[text]]... */...
or
{DELETE|INSERT|SELECT|UPDATE} --+ hint [text] [hint[text]]...
Синтаксис
{DELETE|INSERT|SELECT|UPDATE} /*+ hint [text] [hint[text]]... */...
or
{DELETE|INSERT|SELECT|UPDATE} --+ hint [text] [hint[text]]...

Примеры
======================================================
SELECT
/*+ ALL_ROWS */
empno, ename, sal, job
FROM emp
WHERE
Примеры
======================================================
SELECT
/*+ ALL_ROWS */
empno, ename, sal, job
FROM emp
WHERE

Что будет, если подсказка написана неправильно…
ORACLE игнорирует подсказки, которые не
Что будет, если подсказка написана неправильно…
ORACLE игнорирует подсказки, которые не

Группы подсказок
Подсказки можно разделить на следующие группы:
подсказки задающие цели оптимизации
подсказки задающие
Группы подсказок
Подсказки можно разделить на следующие группы:
подсказки задающие цели оптимизации
подсказки задающие

Подсказки, задающие цели оптимизации
ALL_ROWS
FIRST_ROWS(n)
CHOOSE
RULE
Подсказки, задающие цели оптимизации
ALL_ROWS
FIRST_ROWS(n)
CHOOSE
RULE

Пример (ALL_ROWS)
SELECT /*+ ALL_ROWS */
employee_id,
last_name,
salary,
Пример (ALL_ROWS)
SELECT /*+ ALL_ROWS */
employee_id,
last_name,
salary,

Пример (FIRST_ROWS(n))
SELECT
/*+ FIRST_ROWS(10) */
empno, ename, sal, job
FROM emp
Пример (FIRST_ROWS(n))
SELECT
/*+ FIRST_ROWS(10) */
empno, ename, sal, job
FROM emp

Пример (CHOOSE)
SELECT
/*+ CHOOSE */
empno, ename, sal, job
FROM emp
Пример (CHOOSE)
SELECT
/*+ CHOOSE */
empno, ename, sal, job
FROM emp

Пример (RULE)
SELECT
--+ RULE
empno, ename, sal, job
FROM emp
WHERE
Пример (RULE)
SELECT
--+ RULE
empno, ename, sal, job
FROM emp
WHERE

Подсказки, задающие методы доступа
FULL
ROWID
INDEX
INDEX_ASC
INDEX_DESC
INDEX_FFS
NO_INDEX
INDEX_COMBINE
INDEX_JOIN
….
Подсказки, задающие методы доступа
FULL
ROWID
INDEX
INDEX_ASC
INDEX_DESC
INDEX_FFS
NO_INDEX
INDEX_COMBINE
INDEX_JOIN
….

Пример (FULL)
SELECT /*+ FULL(e) */
employee_id,
last_name
FROM hr.employees
Пример (FULL)
SELECT /*+ FULL(e) */
employee_id,
last_name
FROM hr.employees

Пример (ROWID)
SELECT
/*+ROWID(emp)*/ *
FROM emp
WHERE rowid > 'AAAAtkAABAAAFNTAAA'
AND
Пример (ROWID)
SELECT
/*+ROWID(emp)*/ *
FROM emp
WHERE rowid > 'AAAAtkAABAAAFNTAAA'
AND

Пример (INDEX)
SELECT /*+ INDEX (employees emp_department_ix)*/ employee_id, department_id
FROM employees
WHERE
Пример (INDEX)
SELECT /*+ INDEX (employees emp_department_ix)*/ employee_id, department_id
FROM employees
WHERE
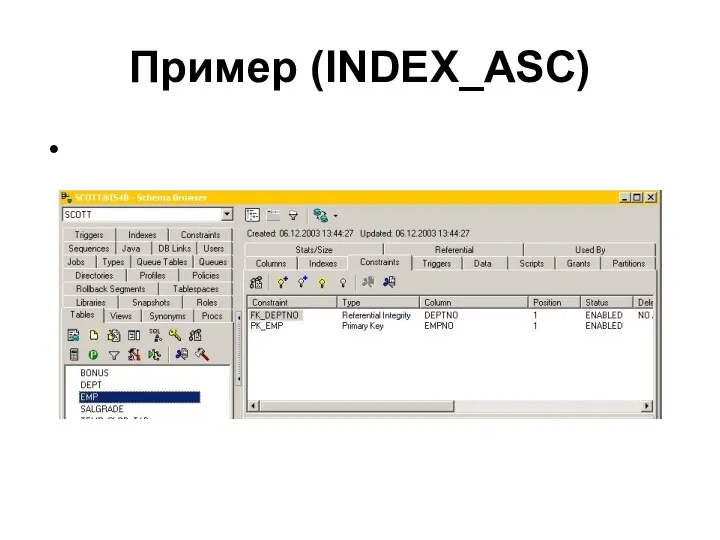
Пример (INDEX_ASC)
Пример (INDEX_ASC)
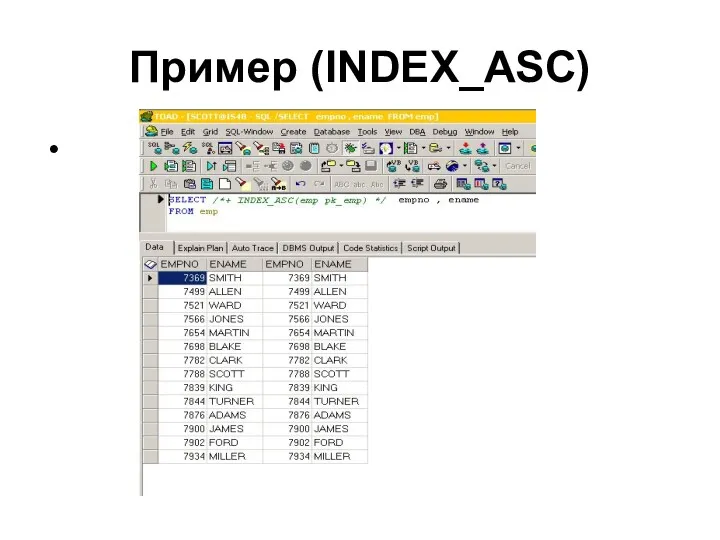
Пример (INDEX_ASC)
Пример (INDEX_ASC)
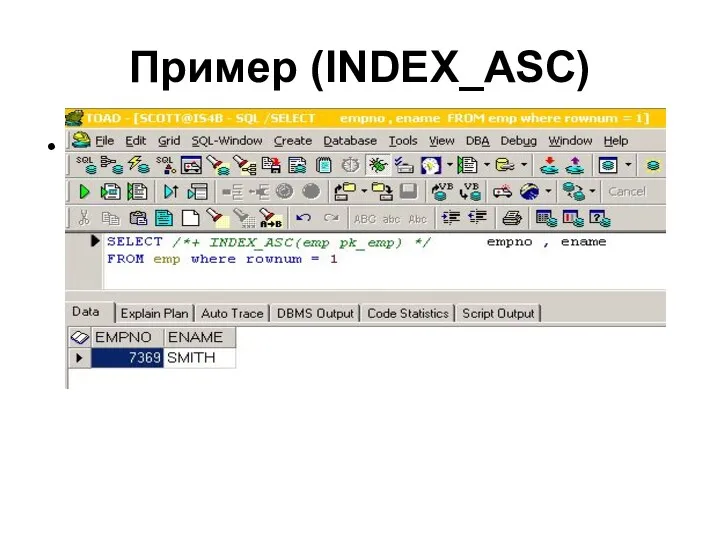
Пример (INDEX_ASC)
Пример (INDEX_ASC)

Пример (INDEX_DESC)
SELECT /*+ INDEX_DESC(emp pk_emp) */
empno , ename
FROM emp
SELECT
Пример (INDEX_DESC)
SELECT /*+ INDEX_DESC(emp pk_emp) */
empno , ename
FROM emp
SELECT

Пример (INDEX_FFS)
SELECT
/*+INDEX_FFS(emp emp_empno)*/ empno
FROM emp
WHERE empno > 200;
Пример (INDEX_FFS)
SELECT
/*+INDEX_FFS(emp emp_empno)*/ empno
FROM emp
WHERE empno > 200;

Пример (NO_INDEX)
SELECT
/*+NO_INDEX(emp emp_empno)*/
empno
FROM emp
WHERE empno > 200;
Пример (NO_INDEX)
SELECT
/*+NO_INDEX(emp emp_empno)*/
empno
FROM emp
WHERE empno > 200;

Пример (INDEX_COMBINE)
SELECT
/*+ INDEX_COMBINE(e emp_manager_ix emp_department_ix) */ *
FROM employees
Пример (INDEX_COMBINE)
SELECT
/*+ INDEX_COMBINE(e emp_manager_ix emp_department_ix) */ *
FROM employees

Пример (INDEX_JOIN)
SELECT
/*+ INDEX_JOIN(e emp_manager_ix emp_department_ix) */ department_id
FROM employees e
Пример (INDEX_JOIN)
SELECT
/*+ INDEX_JOIN(e emp_manager_ix emp_department_ix) */ department_id
FROM employees e

Подсказки для операции соединения (JOIN)
USE_NL - использовать вложенные циклы для соединения
Подсказки для операции соединения (JOIN)
USE_NL - использовать вложенные циклы для соединения

Пример (USE_NL)
SELECT
/*+ USE_NL(customers) to get first row faster */
Пример (USE_NL)
SELECT
/*+ USE_NL(customers) to get first row faster */

Пример (USE_MERGE)
SELECT
/*+USE_MERGE(emp dept)*/ *
FROM emp, dept
WHERE emp.deptno =
Пример (USE_MERGE)
SELECT
/*+USE_MERGE(emp dept)*/ *
FROM emp, dept
WHERE emp.deptno =

Другие подсказки
MATERIALIZE – материализовать промежуточную таблицу
PARALLEL – распараллелить выполнение запроса
И др.
Другие подсказки
MATERIALIZE – материализовать промежуточную таблицу
PARALLEL – распараллелить выполнение запроса
И др.

Сбор статистики, полезной для оптимизатора
Статистика по таблицам
Количество записей
Сбор статистики, полезной для оптимизатора
Статистика по таблицам
Количество записей

Процедуры для сбора статистики (пакет DBMS_STATS)
GATHER_INDEX_STATS
GATHER_TABLE_STATS
GATHER_SCHEMA_STATS
GATHER_DATABASE_STATS
GATHER_SYSTEM_STATS
Примечание: эти
Процедуры для сбора статистики (пакет DBMS_STATS)
GATHER_INDEX_STATS
GATHER_TABLE_STATS
GATHER_SCHEMA_STATS
GATHER_DATABASE_STATS
GATHER_SYSTEM_STATS
Примечание: эти

Представления словаря для просмотра статистики
DBA_TABLES
DBA_TAB_COL_STATISTICS
DBA_INDEXES
Представления словаря для просмотра статистики
DBA_TABLES
DBA_TAB_COL_STATISTICS
DBA_INDEXES

Пример
SELECT TABLE_NAME,
NUM_ROWS,
BLOCKS,
AVG_ROW_LEN,
TO_CHAR(LAST_ANALYZED,
'MM/DD/YYYY HH24:MI:SS')
Пример
SELECT TABLE_NAME,
NUM_ROWS,
BLOCKS,
AVG_ROW_LEN,
TO_CHAR(LAST_ANALYZED,
'MM/DD/YYYY HH24:MI:SS')
 Лекция 2. Основные конструкции OpenMP
Лекция 2. Основные конструкции OpenMP Сетевые сервисы
Сетевые сервисы Решение задач ЕГЭ типа В9
Решение задач ЕГЭ типа В9 Компоненты образовательных ИТ-технологий
Компоненты образовательных ИТ-технологий Параллельное программирование для ресурсоёмких задач численного моделирования в физике. Лекция 2
Параллельное программирование для ресурсоёмких задач численного моделирования в физике. Лекция 2 Repository and Unit of Work
Repository and Unit of Work Лекция №7. Системы автоматизированного проектирования (САПР)
Лекция №7. Системы автоматизированного проектирования (САПР) Базы данных. Процедуры и функции
Базы данных. Процедуры и функции Примеры разработки программ-функций в системе MATHCAD. Лекция 7
Примеры разработки программ-функций в системе MATHCAD. Лекция 7 Создание простой диаграммы в Excel 2010
Создание простой диаграммы в Excel 2010 Установка дистрибутивов
Установка дистрибутивов Threads. Выполнение инструкций потоками
Threads. Выполнение инструкций потоками Информационные процессы и системы
Информационные процессы и системы Сортировка методом пузырька
Сортировка методом пузырька Рекрутинг в инстаграм
Рекрутинг в инстаграм Цветовые модели компьютерной графики
Цветовые модели компьютерной графики Людино-комп'ютерна взаємодія та проектування інтерфейсів користувача
Людино-комп'ютерна взаємодія та проектування інтерфейсів користувача Технологии локальных сетей. (Тема 3)
Технологии локальных сетей. (Тема 3) Разработка информационной системы для ТОО Fin-apps
Разработка информационной системы для ТОО Fin-apps Технологии и средства обработки текста
Технологии и средства обработки текста Программирование многоядерных архитектур
Программирование многоядерных архитектур Системы автоматизированного проектирования технологических процессов. Программное обеспечение САПР ТП. (Лекция 3)
Системы автоматизированного проектирования технологических процессов. Программное обеспечение САПР ТП. (Лекция 3) Почему классический CTF должен умереть
Почему классический CTF должен умереть Белгілі бір бағдарламаны жугізушілер қандай болуы керек
Белгілі бір бағдарламаны жугізушілер қандай болуы керек Об оформлении газет
Об оформлении газет Этические проблемы сетевой журналистики
Этические проблемы сетевой журналистики Циклы в языкеПаскаль
Циклы в языкеПаскаль Школа подготовки технических администраторов. (Занятие 16)
Школа подготовки технических администраторов. (Занятие 16)