- Програма автоматичного визначення кодової таблиці текстового файлу

Содержание
- 2. Зміст Короткі відомості ASCII Windows-1251 Unicode Версії Юнікод UTF-8 UTF-16 і UTF32 Розробка програми Інтерфейс програми
- 3. Мета роботи Розробити програму автоматичного визначення кодової таблиці текстового файлу
- 4. Короткі відомості Безліч символів, за допомогою яких записується текст, називається алфавітом. Число символів в алфавіті -
- 5. ASCII ASCII (англ. American Standard Code for Information Interchange) - американський стандартний код для обміну інформацією.
- 6. Таблиця ASCII Зміст
- 7. Windows-1251 Windows-1251 (також вживаються назви Win1251, CP1251) — кодування символів, що є стандартним 8-бітовим кодуванням для
- 8. Таблиця Windows-1251 Зміст
- 9. Має три недоліки: мала (рядкова) буква «я» має код 0xFF (255 в 10-овій системі). Вона є
- 10. Unicode Юнікод (англ. Unicode) - стандарт кодування символів, що включає в себе знаки майже всіх письмових
- 11. Стандарт складається з двох основних частин: універсального набору символів (англ. Universal character set, UCS) і сімейства
- 12. Cпособи представлення Юнікод має кілька форм представлення (англ. Unicode transformation format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE)
- 13. Версії Юнікода
- 14. UTF-8 UTF-8 - уявлення Юникода, що забезпечує найбільшу компактність і зворотну сумісність з 7-бітної системою ASCII;
- 15. UTF-16 і UTF-32 UTF-16 - кодування, що дозволяє записувати символи Юнікоду в діапазонах U + 0000
- 16. Розробка програми Рис. Алгоритм Зміст
- 17. Інтерфейс програми Зміст
- 18. Існуючі програми для перевірки кодування NotePad++ http://foxtools.ru/Text Зміст
- 19. Тестування програми Зміст
- 20. Висновок При виконанні розрахунково-графічної роботи було розглянуто кодування файлів. Було описано основні кодування текстових файлів. У
- 21. Список літератури Вернер.М. Основы кодирования. Учебник для ВУЗов. Москва: Техносфера. 2004. – 288с. Dave Tomas, Endi
- 23. Скачать презентацию

Зміст
Короткі відомості
ASCII
Windows-1251
Unicode
Версії Юнікод
UTF-8
UTF-16 і UTF32
Розробка програми
Інтерфейс програми
Існуючі програми для перевірки кодування
Тестування
Висновок
Список
Зміст
Короткі відомості
ASCII
Windows-1251
Unicode
Версії Юнікод
UTF-8
UTF-16 і UTF32
Розробка програми
Інтерфейс програми
Існуючі програми для перевірки кодування
Тестування
Висновок
Список

Мета роботи
Розробити програму автоматичного визначення кодової таблиці текстового файлу
Мета роботи
Розробити програму автоматичного визначення кодової таблиці текстового файлу

Короткі відомості
Безліч символів, за допомогою яких записується текст, називається алфавітом.
Число символів
Короткі відомості
Безліч символів, за допомогою яких записується текст, називається алфавітом.
Число символів

ASCII
ASCII (англ. American Standard Code for Information Interchange) - американський стандартний
ASCII
ASCII (англ. American Standard Code for Information Interchange) - американський стандартний

Таблиця ASCII
Зміст
Таблиця ASCII
Зміст

Windows-1251
Windows-1251 (також вживаються назви Win1251, CP1251) — кодування символів, що є стандартним 8-бітовим кодуванням для
Windows-1251
Windows-1251 (також вживаються назви Win1251, CP1251) — кодування символів, що є стандартним 8-бітовим кодуванням для
Таблиця Windows-1251
Зміст
Таблиця Windows-1251
Зміст

Має три недоліки:
мала (рядкова) буква «я» має код 0xFF (255 в
Має три недоліки:
мала (рядкова) буква «я» має код 0xFF (255 в

Unicode
Юнікод (англ. Unicode) - стандарт кодування символів, що включає в себе
Unicode
Юнікод (англ. Unicode) - стандарт кодування символів, що включає в себе

Стандарт складається з двох основних частин: універсального набору символів (англ. Universal
Стандарт складається з двох основних частин: універсального набору символів (англ. Universal

Cпособи представлення
Юнікод має кілька форм представлення (англ. Unicode transformation format, UTF):
Cпособи представлення
Юнікод має кілька форм представлення (англ. Unicode transformation format, UTF):

Версії Юнікода
Версії Юнікода

UTF-8
UTF-8 - уявлення Юникода, що забезпечує найбільшу компактність і зворотну сумісність
UTF-8
UTF-8 - уявлення Юникода, що забезпечує найбільшу компактність і зворотну сумісність

UTF-16 і UTF-32
UTF-16 - кодування, що дозволяє записувати символи Юнікоду в
UTF-16 і UTF-32
UTF-16 - кодування, що дозволяє записувати символи Юнікоду в

Розробка програми
Рис. Алгоритм
Зміст
Розробка програми
Рис. Алгоритм
Зміст
Інтерфейс програми
Зміст
Інтерфейс програми
Зміст
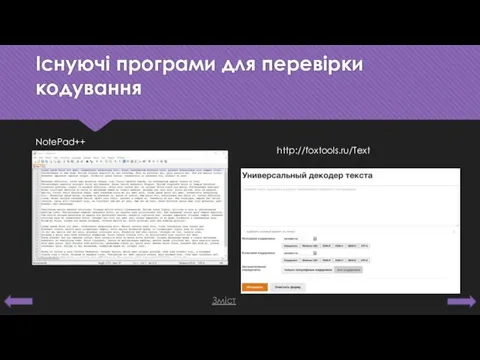
Існуючі програми для перевірки кодування
NotePad++
http://foxtools.ru/Text
Зміст
Існуючі програми для перевірки кодування
NotePad++
http://foxtools.ru/Text
Зміст
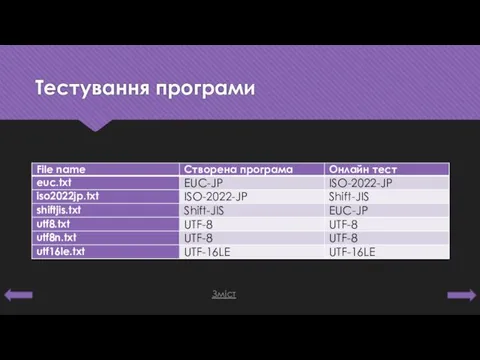
Тестування програми
Зміст
Тестування програми
Зміст

Висновок
При виконанні розрахунково-графічної роботи було розглянуто кодування файлів. Було описано основні
Висновок
При виконанні розрахунково-графічної роботи було розглянуто кодування файлів. Було описано основні

Список літератури
Вернер.М. Основы кодирования. Учебник для ВУЗов. Москва: Техносфера. 2004. –
Список літератури
Вернер.М. Основы кодирования. Учебник для ВУЗов. Москва: Техносфера. 2004. –
 Разработка рекомендаций по оценке безопасности информационных систем
Разработка рекомендаций по оценке безопасности информационных систем Принципы работы в сети. Исключения
Принципы работы в сети. Исключения Частотные методы улучшения изображений. Лекция 3
Частотные методы улучшения изображений. Лекция 3 Программы Microsoft Office: PowerPoint 2010, Word 2010
Программы Microsoft Office: PowerPoint 2010, Word 2010 Стандартизация сетей. Модель OSI
Стандартизация сетей. Модель OSI Пример слайда. Sydney Opera House is Australia’s
Пример слайда. Sydney Opera House is Australia’s История технологий шифрования
История технологий шифрования Основные команды ассемблера
Основные команды ассемблера Вкладені цикли. Покрокове введення та виведення даних. Лекція №8
Вкладені цикли. Покрокове введення та виведення даних. Лекція №8 Media & newspapers
Media & newspapers Сборочное моделирование. Решения по управлению жизненным циклом, продукт IBM/Dassault Systemes
Сборочное моделирование. Решения по управлению жизненным циклом, продукт IBM/Dassault Systemes Российское движение школьников. Информационно-медийное направление
Российское движение школьников. Информационно-медийное направление Интернет-коммуникации. Автоматизация
Интернет-коммуникации. Автоматизация Графический метод решения уравнений в Excel
Графический метод решения уравнений в Excel Электронный листок нетрудоспособности на территории Ленинградской области
Электронный листок нетрудоспособности на территории Ленинградской области Построение и анализ алгоритмов. Алгоритмы на графах. МОД в задаче коммивояжёра. (Лекция 6.2)
Построение и анализ алгоритмов. Алгоритмы на графах. МОД в задаче коммивояжёра. (Лекция 6.2) История серии видеоигр: Crysis, Wolfenstein, Dead Space
История серии видеоигр: Crysis, Wolfenstein, Dead Space Блогеры вместо СМИ
Блогеры вместо СМИ Путешествие по сказкам. Блок-схема. 6 класс
Путешествие по сказкам. Блок-схема. 6 класс Массивы. Строки. Пользовательские типы.(Тема 3)
Массивы. Строки. Пользовательские типы.(Тема 3) Интерактивная компьютерная графика
Интерактивная компьютерная графика Кодирование и шифрование данных
Кодирование и шифрование данных Мобильное рабочее место
Мобильное рабочее место Электронные таблицы. Программа MS Excel
Электронные таблицы. Программа MS Excel Візуальна система формування набору об’єктів нерухомості на карті
Візуальна система формування набору об’єктів нерухомості на карті Создание и форматирование таблиц в текстовом редакторе
Создание и форматирование таблиц в текстовом редакторе Текстовые редакторы. Урок 10
Текстовые редакторы. Урок 10 Создание веб-сайтов
Создание веб-сайтов