- Распределенные информационные системы

Содержание
- 2. Реализация взаимодействия между компонентами в распределенных системах В распределенных системах взаимодействие между компонентами реализуется средствами операционных
- 3. Мультипрограммирование или многозадачный режим работы
- 4. ОС пакетной обработки Размещение нескольких заданий в памяти. Пример ОС: DOS, OS/360 – фирма IBM Время
- 5. Системы разделения времени Квантование времени (MULTICS 1968) Задача 1 Задача 2 Задача 3 . . .
- 6. Процессы выполнения Для выполнения программ операционная система создает несколько виртуальных процессоров, по одному для каждой программы.
- 7. Понятие процесса Процессом, называют программу в момент выполнения, в некоторых ОС исполняемую программу называют задачей, процесс
- 8. Таблица процессов Это массив (или связанный список) структур хранящий информацию о процессах исполняемых системой. Каждому процессу
- 9. Составляющие процесса В режиме выполнения: адресное пространство процесса в оперативной памяти ЭВМ; информация о процессе и
- 10. Жизненный цикл процесса в ОС Включает в себя следующие стадии: Создание процесса; выполнение процесса; уничтожение процесса.
- 11. Системные вызовы управляющие процессами Процесс создается родительским процессом с помощью обращения к функции ядра «создать процесс».
- 12. Смена режимов работы процессора при выполнении системного вызова
- 13. Виды системных вызовов связанных с процессами создание процесса; освобождение или выделение дополнительной памяти процессу; ожидание завершения
- 14. Системные вызовы 6 – переключение в режим ядра; 7 – проверка номера системного вызова и передача
- 15. Выполнение вызовов Win32 API (Windows 2000) 2б, 3б и 4б. Для других вызовов Win32 API выбирает
- 16. Сигналы передаваемые процессам Сигналы являются программными аналогами аппаратных прерываний и могут быть сгенерированы по различным причинам,
- 17. Дерево процессов Если процесс может создавать несколько других процессов (называющихся дочерними процессами), а эти процессы, в
- 18. Идентификация процессов в системе Для идентификации процессов в системе используются идентификаторы процессов PIDs (Process Identificator) PID
- 19. Связанные процессы и межпроцессное взаимодействие Связанные процессы — это те, которые объединены для выполнения некоторой задачи,
- 20. Взаимоблокировка процессов Когда взаимодействуют два или более процессов, они могут попадать в патовые ситуации, из которых
- 21. Пример тупика
- 22. Потоки выполнения Хотя процессы являются строительными блоками распределенных систем, практика показывает, что дробления на процессы, предоставляемого
- 23. Понятие потока выполнения Основная причина использования потоков заключается в том, что во многих приложениях одновременно происходит
- 24. Преимущества потоков выполнения Возможность использования параллельными процессами единого адресного пространства и всех имеющихся данных. Эта возможность
- 25. Процессы и потоки Между потоками одного процесса нет полной защиты, потому что, во-первых, это невозможно, а
- 26. Потоки в локальных системах
- 27. Межпроцессное взаимодействие Многопоточная структура часто используется при построении больших приложений. Подобные приложения часто разрабатываются в виде
- 28. “Стоимость” переключения контекстов процессов Рассмотрим состояние кэша процессора: а) состояние кэша перед прерыванием, блок D является
- 29. Потоки выполнения в нераспределенных системах Имеется особая причина использовать потоки выполнения: многие приложения просто легче разрабатывать,
- 30. Реализация потоков выполнения Потоки выполнения обычно существуют в виде пакетов. Подобные пакеты содержат механизмы для создания
- 31. Преимущества потоков выполнения на пользовательском уровне (1) Библиотека для работы с потоками выполнения на пользовательском уровне
- 32. Преимущества потоков выполнения на пользовательском уровне (2) Второе преимущество потоков выполнения на пользовательском уровне состоит в
- 33. Реализация потоков в ядре Для потоков реализуемых на уровне ядра вся информация о потоках аналогична той,
- 34. Модель многие-к-одному Many-to-one threading model - когда несколько потоков отображаются на один планируемый процесс. В результате
- 35. Модель один-к-одному One-to-one threading model – каждый процесс имеет только один поток, который диспетчируется независимо от
- 36. Гибридная реализация потоков Здесь используются потоки на уровне ядра и один или несколько потоков на пользовательском
- 37. Использование потоков против применения группы конкурирующих процессов Применение потоков является способом одновременного и параллельного исполнения в
- 38. Потоки в распределенных системах
- 39. Почему потоки применяют в РС Важнейшим свойством потоков выполнения является возможность выполнения системных блокирующих вызовов, без
- 40. Многопоточные клиенты Для обеспечения высокой степени прозрачности клиенты должны обладать поддержкой работы в многопоточном режиме. Например
- 41. Многопоточные серверы Рассмотрим файловый сервер. Обычно файловый сервер ожидает обращений от клиентов с запросами на выполнение
- 42. Три способа построения сервера
- 43. Виртуализация
- 44. Понятие виртуализации В компьютерных технологиях под термином "виртуализация" обычно понимается абстракция вычислительных ресурсов и предоставление пользователю
- 45. Виртуализация ЭВМ Виртуализация серверов — размещение нескольких логических серверов в рамках одного физического. Цели виртуализации: Предоставить
- 46. Виртуализация ресурсов физического сервера Виртуализация ресурсов физического сервера позволяет: гибко распределять их между приложениями, каждое из
- 47. Цели виртуализации Первые версии гипервизоров отличались относительной медлительностью и действительно приводили к серьезному снижению производительности по
- 48. История виртуализации (1) 1965. Выражение “Hypervisor” впервые появилось применительно к ПО обработки RPQ на ЭВМ IBM
- 49. История виртуализации (2) Первый гипервизор VM/370 В начале 70-х гипервизор СР-67, был переработан в виде OS
- 50. История виртуализации (3) 1980-90 г.г. В это время основные работы в области виртуализации велись в направлении
- 51. История виртуализации (3) Позднее в "битву“включились такие компании как: Parallels (ранее SWsoft), продукты Parallels Workstation, Parallels
- 52. История виртуализации (4) 2011г. Сформулированы основные модели развертывания и признаки облачных вычислений. В основе облачных вычислений
- 53. Виртуальная машина Достоинства: Эффективность использования ресурсов Масштабируемость Простые резервное копирование и миграция Гибкость Недостатки: Проблема в
- 54. Рост стоимости и числа виртуализированных ЦОД в период 1996-2013 Рост доли затрат на управление управления виртуализацией.
- 55. Принципы виртуализации В реальной программной системе имеется ряд интерфейсов, начиная с базового набора команд ЦПУ и
- 56. Виртуализация и раcпределенные системы Рассмотрим случай, когда необдходимо, обеспечить исполнение программы разработанной для аппаратной платформы А,
- 57. Типы виртуализации. Имеется несколько способов реализации виртуализации в зависимости от типа интерфейса компьютерной системы, используемого для
- 58. Принципы виртуализации В компьютерной системе имеется ряд интерфейсов, начиная с базового набора команд ЦПУ и кончая
- 59. Виды интерфейсов в компьютерной системе В компьютерной системе в общем случае выделяют 4 слоя, связанные тремя
- 60. Архитектура операционной системы с ядром в привилегированном режиме Обеспечить привилегии операционной системе невозможно без специальных средств
- 61. Смена режимов при выполнении системного вызова к привилегированному ядру Архитектура ОС, основанная на привилегированном ядре и
- 62. Способы реализации прикладных программных сред Создание полноценной прикладной среды, полностью совместимой со средой другой операционной системы,
- 63. Типы виртуализации Тип виртуализации определяются типом интерфейса на котором она выполняется: Виртуализация на уровне набора команд
- 64. Два способа реализации виртуализации Суть виртуализации – имитация поведения интерфейса компьютерной системы. Существуют два способа реализации
- 65. Виртуализация на уровне среды исполнения прикладной программы. Виртуальная машина одного процесса. В этом случае среда исполнения
- 66. Требования к архитектуре ЭВМ, для поддержки виртуализации В 1974 году двое ученых из Калифорнийского университета (Лос-Анджелес),
- 67. Проблемы виртуализации в архитектуре Intel x86 В наборе команд Intel x86 (включая и х64) имеются команды
- 68. Монитор виртуальных машин Идея монитора виртуальных машин не нова. Она была предложена еще в 1974 г.
- 69. Два подхода к реализации монитора виртуальных машин Имеются два подхода к построению мониторов виртуальных машин: Эмуляция
- 70. Монитор виртуальных машин исполняемый как отдельная ОС (Гипервизор первого типа) На аппаратные средства устанавливается специализированная ОС
- 71. Монитор виртуальных машин исполняемый в среде хозяйской ОС (Гипервизор второго типа) Монитор виртуальных машин работает в
- 72. Паравиртуализация техника виртуализации, при которой гостевые операционные системы подготавливаются для исполнения в виртуализированной среде, для чего
- 73. Архитектура физической машины (a) и три архитектуры виртуализации (b-d) Монитор виртуальных машин (VMM – Virtual Machine
- 74. Виртуализация на уровне операционной системы — виртуализирует физический сервер на уровне ОС, позволяя запускать изолированные виртуальные
- 75. Контейнерная виртуализация в Linux Экземпляры пространств пользователя (часто называемые контейнерами или зонами) с точки зрения пользователя
- 76. Виртуализация против контейнеризации
- 77. Виртуализация и распределенные системы Одной из важнейшей причиной, но не единственной, появления технологии виртуализации, явилась необходимость
- 78. Основы облачных вычислений
- 79. Что это такое ? (1) Пользователь: 1. Сегодня под облачными вычислениями обычно понимают возможность получения необходимых
- 80. Что это такое ?(2) Руководитель ИТ: 1. Это новый подход, позволяющий снизить сложность ИТ-систем, благодаря применению
- 81. Понятие облачные вычисления Под облачными вычислениями мы понимаем программно-аппаратное обеспечение, доступное пользователю через Интернет или локальную
- 82. Признаки облачных вычислений Самообслуживание по требованию в условиях мультиарендности. Широкий (универсальный и высокоскоростной) сетевой доступ. Объединение
- 83. Один облачный сервер обходится дешевле, чем сервер, приобретенный и установленный самой компанией: более разумное расходование электроэнергии
- 84. Общая архитектура облачных вычислений
- 85. Общая архитектура облаков Включает следующие компоненты: ЦОДы – центры обработки данных; платформы снабжения виртуализированными вычислительными, сетевыми
- 86. Многоуровневая архитектура облака Используется для описания моделей обслуживания пользователей и развертывания Архитектура облака разработана как 3-х
- 87. Сервисные модели облачных вычислений
- 88. Уровень инфраструктуры (IaaS) Служит основой для создания других уровней облака. Строится на основе виртуализированных вычислительных, сетевых
- 89. Уровень платформы (PaaS) Предназначен для общего в том числе и для повторного использования коллекции программных ресурсов.
- 90. Уровень приложений (SaaS) Формируется совокупностью всех программных модулей необходимых для выполнения приложений SaaS. Сервисные приложения обслуживающие
- 91. Облачные вычисления как эволюция архитектуры корпоративных приложений Облачные вычисления – это следующий шаг в эволюции архитектуры
- 92. Определение облачных вычислений по NIST
- 93. Облачный стек
- 94. Архитектурная модель. Участники процесса.
- 95. Взаимодействие между ролями в облачных вычислениях
- 96. Облачный Провайдер - высокоуровневый взгляд
- 97. Кто чем управляет в облаке
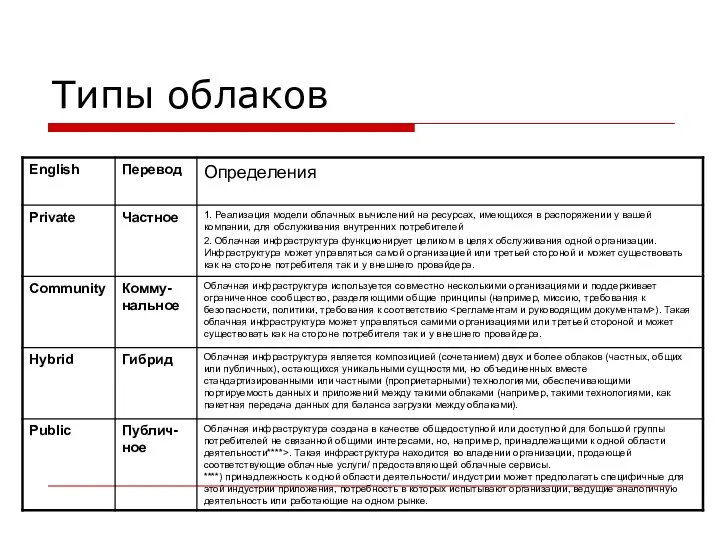
- 98. Типы облаков
- 99. Внутреннее частное облако «Облачная инфраструктура функционирует целиком в целях обслуживания одной организации. Инфраструктура управляется самой организацией
- 100. Внешнее частное облако «Облачная инфраструктура функционирует целиком в целях обслуживания одной организации. Инфраструктура управляется третьей стороной
- 101. Гибридное облако
- 102. Архитектура AWS (Amazon Web Services) Службы AWS: EC2 – Elastic Compute Cloud; SQS – Simple QueueService;
- 103. Назначение и функции сервисов AWS
- 104. Подходы к проектированию процессов выполняемых компонентами РС
- 105. Клиенты РС
- 106. Функции клиента РС Основное назначение: Предоставление пользователю возможности взаимодействовать с сервером и получать нужный вид обслуживания.
- 107. Сетевые пользовательские интерфейсы При работе в сети пользователю требуется доступ к ресурсам сервера. Имеется два основных
- 108. Пример: Система X-Window Одним из старейших, но широко распространенных протоколов удаленного обеспечения пользовательского графического интерфейса является
- 109. Организация X Window Сердцем X является X Kernel. Оно содержит все драйвера устройств относящихся к терминалу
- 110. Тонкий сетевой клиент Недостатки X Window: X приложение в процессе своей работы посылает по сети команды,
- 111. Технология NX Основана на исходном протоколе X Window, со следующими улучшениями: Использование сжатия данных при передаче;
- 112. VNC Является альтернативой X Window, в которой приложение полностью управляет отображением на удаленном дисплее, в плоть
- 113. THINC Недостатком передачи сырых данных пикселей по сравнению с высоуровневыми протоколами такими как X Window является,
- 114. Клиентское ПО прозрачного доступа Во многих случаях требуется обеспечить прозрачное выполнение обработки данных на клиенте и
- 115. Прозрачная транзакция с помощью решений размещаемых на клиенте Часто прозрачность репликации реализуется с помощью ПО размещаемом
- 116. Сервера РС
- 117. Общие проблемы создания серверов РС Сервер реализуется средствами исполнения процессов обеспечивающих реализацию сервиса, потребителями которого являются
- 118. Параллельный сервер против итерационного В случае использования параллельной работы сервера, поступающий запрос перехватывается соответствующим процессом приема
- 119. Конечная точка подключения к серверу Конечная точка подключения – это URL, при обращении к которому выполняется
- 120. Прерываемый сервер При создании сервера следует принимать во внимание когда и как работа сервера может быть
- 121. Сервер с фиксацией состояния Сервер с фиксацией состояния (stateful server) хранит и обрабатывает информацию о своих
- 122. Достоинства и недостатки сервера с фиксацией состояния Достоинства: Рост производительности по сравнению с серверами без фиксации
- 123. Сервер без состояния Сервер без фиксации состояния (stateless sewer) не сохраняет информацию о состоянии своих клиентов
- 124. Серверы объектов Сервер объектов {object sewer) — это сервер, ориентированный на поддержку распределенных объектов. Важная разница
- 125. Обращение к объектам Объект состоит из двух частей: данных, отражающих его состояние, и кода, образующего реализацию
- 126. Способы обращению к объектам. Политика активизации Для любого объекта, к которому происходит обращение, сервер объектов должен
- 127. Адаптер объектов Нужен механизм группирования объектов в соответствии с политикой активизации каждого из них. Этот механизм
- 128. Реализация адаптера Реализация адаптера не зависит от объектов, обращения к которым он обрабатывает. Соответственно, можно создать
- 129. Пример: EJB Java Enterprise Beans по сути является объектом, который располагается на сервере и предоставляет для
- 130. Пример: Веб-сервер Apache Сервер Apache исполняется в среде APR - Apache Portable Runtime, которая предоставляет платформо-независимый
- 131. Кластера серверов В вычислительных кластерах один узел играет роль управляющего. Остальные узлы являются вычислительными. Управляющий кластер
- 132. Локальные кластера серверов. Общая организация. Кластер серверов представляет собой распределенную систему имеющую логическую в 3-х уровневую
- 133. Диспетчирование запросов в локальных кластерах серверов Стандартным способом получения доступа к кластеру установление TCP соединения в
- 134. Эффективное раcпределение на основе контента запроса В случаях, когда разные сервера кластера предоставляют услуги различных служб,
- 135. Глобальные кластеры серверов Облачные провайдеры Amazon и Google имеют собственные ЦОД в разных частях мира, в
- 136. Политика перенаправления Необходимость выбора сервера ближайшего к источнику запроса порождает проблему политики перенаправления. Если предположить, что
- 137. Диспетчирование запросов в глобальных кластерах серверов Надежное определение требуемого сервера может быть достигнуто с помощью механизма
- 138. Миграция кода
- 139. Основания для переноса кода Традиционно перенос кода в распределенных системах происходит в форме переноса процессов (process
- 140. Пример: Файловый сервер Например, рассмотрим сервер, реализующий стандартизованный интерфейс к файловой системе. Чтобы предоставить удаленному клиенту
- 141. Модели переноса кода Перенос кода в широком смысле связан с переносом программ с машины на машину
- 142. Модель слабой мобильности Согласно этой модели допускается перенос только сегмента кода, возможно вместе с некоторыми данными
- 143. Модель сильной мобильности Характерная черта сильной мобильности — то, что работающий процесс может быть приостановлен, перенесен
- 144. Инициатор переносимости кода Независимо от того, является мобильность слабой или сильной, следует провести разделение на: системы
- 145. Четыре варианта переноса кода Различные варианты переноса кода в зависимости от: - вида мобильности (сильная/слабая); -
- 146. Удаленное клонирование процессов Помимо переноса работающего процесса, называемого также миграцией процесса, сильная мобильность может также осуществляться
- 147. Миграция кода в гетерогенных системах Перенос в гетерогенных системах требует, чтобы поддерживались все эти платформы, то
- 148. Методы портирования процессов в гетерогенных системах. В разные годы были предложены следующие способы обеспечения мобильности кода
- 149. Влияние миграции кода на время ответа ВМ При миграции виртуальной машины время неактивности этой ВМ составляет
- 151. Скачать презентацию
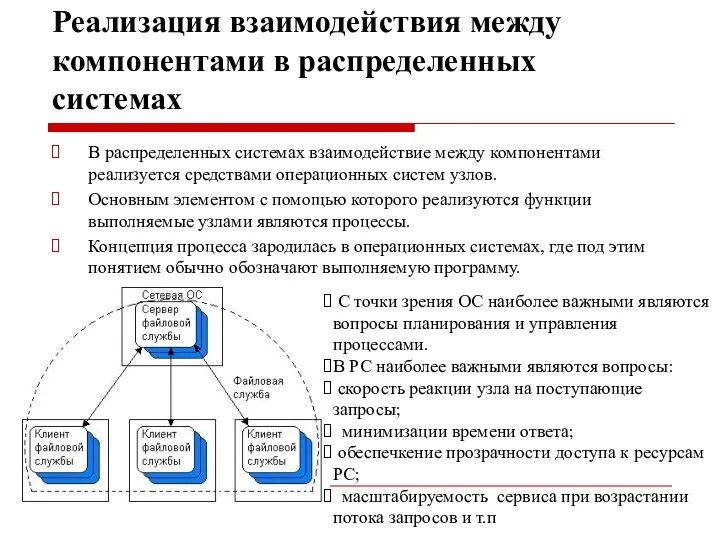
Реализация взаимодействия между компонентами в распределенных системах
В распределенных системах взаимодействие между
Реализация взаимодействия между компонентами в распределенных системах
В распределенных системах взаимодействие между

Мультипрограммирование или многозадачный режим работы
Мультипрограммирование или многозадачный режим работы
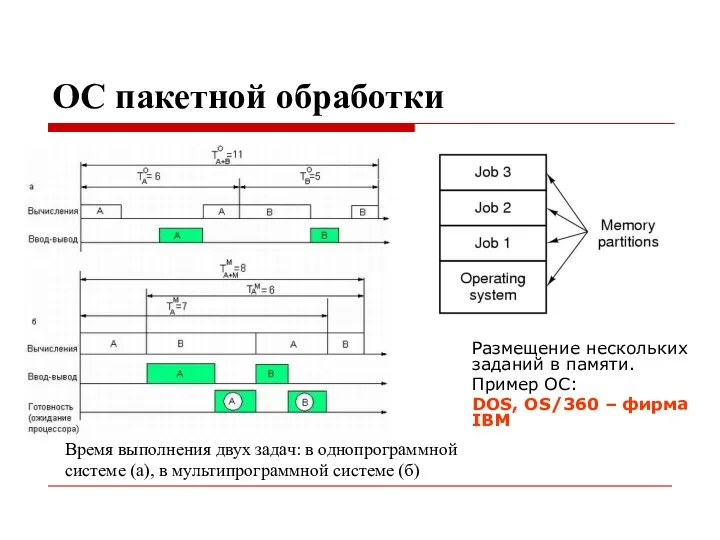
ОС пакетной обработки
Размещение нескольких заданий в памяти.
Пример ОС:
DOS, OS/360 – фирма
ОС пакетной обработки
Размещение нескольких заданий в памяти.
Пример ОС:
DOS, OS/360 – фирма
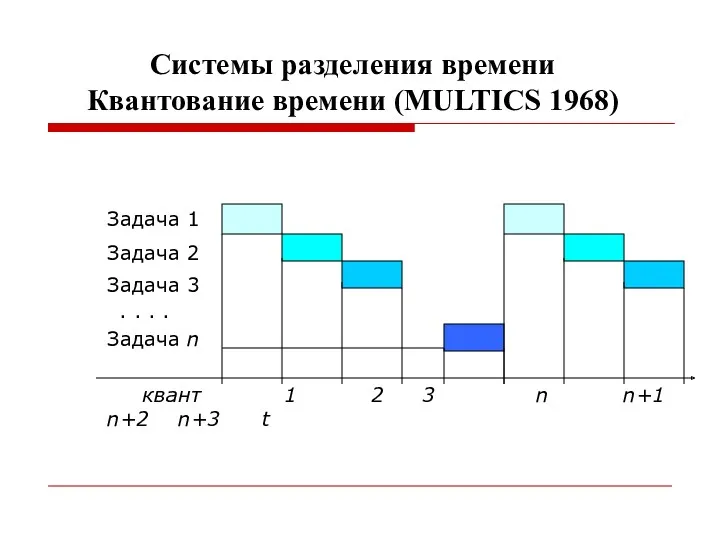
Системы разделения времени
Квантование времени (MULTICS 1968)
Задача 1
Задача 2
Задача 3
. .
Системы разделения времени
Квантование времени (MULTICS 1968)
Задача 1
Задача 2
Задача 3
. .

Процессы выполнения
Для выполнения программ операционная система создает несколько виртуальных процессоров, по
Процессы выполнения
Для выполнения программ операционная система создает несколько виртуальных процессоров, по

Понятие процесса
Процессом, называют программу в момент выполнения, в некоторых ОС исполняемую
Понятие процесса
Процессом, называют программу в момент выполнения, в некоторых ОС исполняемую

Таблица процессов
Это массив (или связанный список) структур хранящий информацию о процессах
Таблица процессов
Это массив (или связанный список) структур хранящий информацию о процессах

Составляющие процесса
В режиме выполнения:
адресное пространство процесса в оперативной памяти ЭВМ;
информация о
Составляющие процесса
В режиме выполнения:
адресное пространство процесса в оперативной памяти ЭВМ;
информация о

Жизненный цикл процесса в ОС
Включает в себя следующие стадии:
Создание процесса;
выполнение процесса;
уничтожение
Жизненный цикл процесса в ОС
Включает в себя следующие стадии:
Создание процесса;
выполнение процесса;
уничтожение

Системные вызовы управляющие процессами
Процесс создается родительским процессом с помощью обращения к
Системные вызовы управляющие процессами
Процесс создается родительским процессом с помощью обращения к
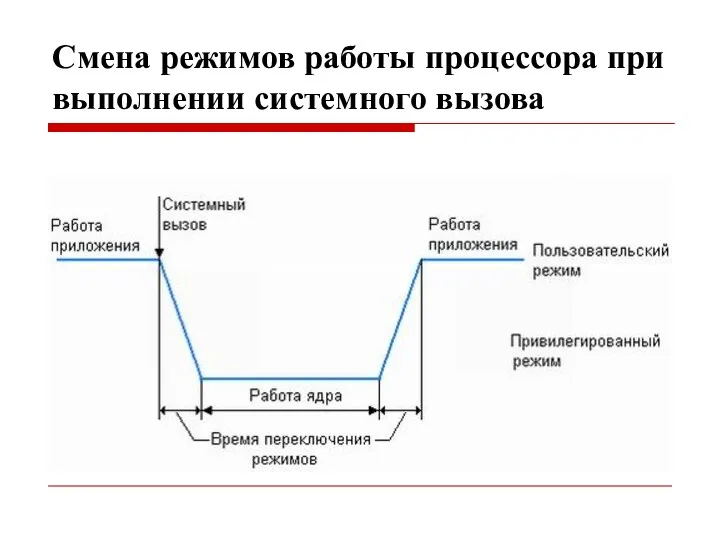
Смена режимов работы процессора при выполнении системного вызова
Смена режимов работы процессора при выполнении системного вызова

Виды системных вызовов связанных с процессами
создание процесса;
освобождение или выделение дополнительной памяти
Виды системных вызовов связанных с процессами
создание процесса;
освобождение или выделение дополнительной памяти
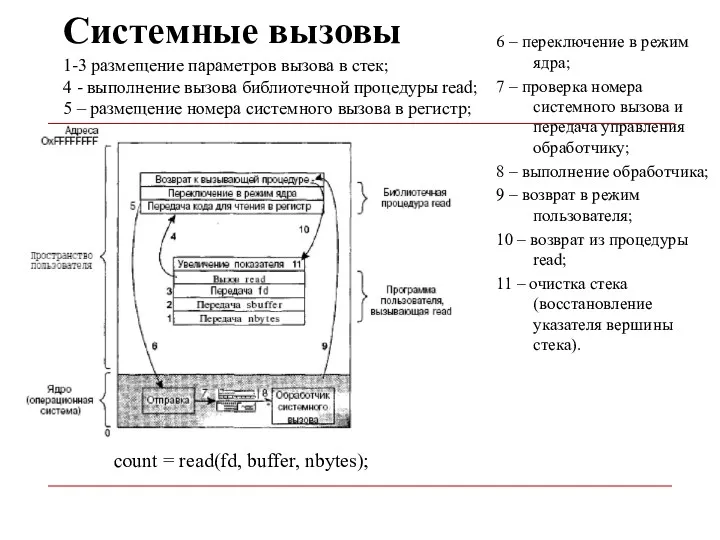
Системные вызовы
6 – переключение в режим ядра;
7 – проверка номера системного
Системные вызовы
6 – переключение в режим ядра;
7 – проверка номера системного
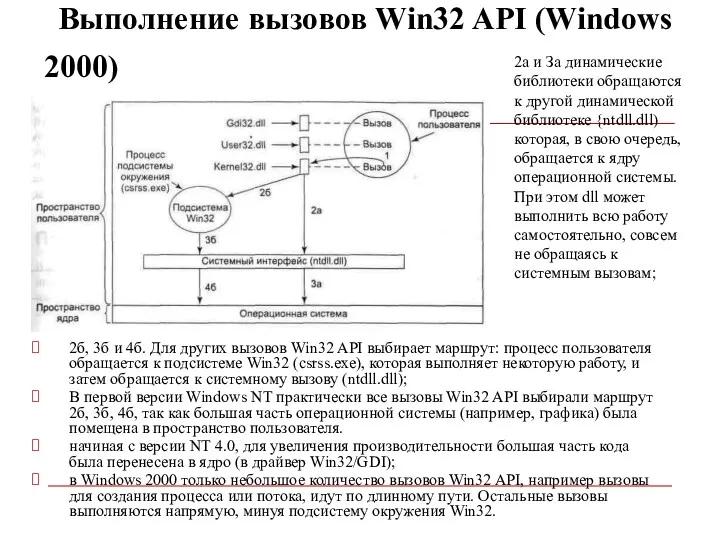
Выполнение вызовов Win32 API (Windows 2000)
2б, 3б и 4б.
Выполнение вызовов Win32 API (Windows 2000)
2б, 3б и 4б.

Сигналы передаваемые процессам
Сигналы являются программными аналогами аппаратных прерываний и могут быть
Сигналы передаваемые процессам
Сигналы являются программными аналогами аппаратных прерываний и могут быть
Дерево процессов
Если процесс может создавать несколько других процессов (называющихся дочерними процессами),
Дерево процессов
Если процесс может создавать несколько других процессов (называющихся дочерними процессами),

Идентификация процессов в системе
Для идентификации процессов в системе используются идентификаторы процессов
Идентификация процессов в системе
Для идентификации процессов в системе используются идентификаторы процессов

Связанные процессы и межпроцессное взаимодействие
Связанные процессы — это те, которые объединены
Связанные процессы и межпроцессное взаимодействие
Связанные процессы — это те, которые объединены
Взаимоблокировка процессов
Когда взаимодействуют два или более процессов, они могут попадать в
Взаимоблокировка процессов
Когда взаимодействуют два или более процессов, они могут попадать в
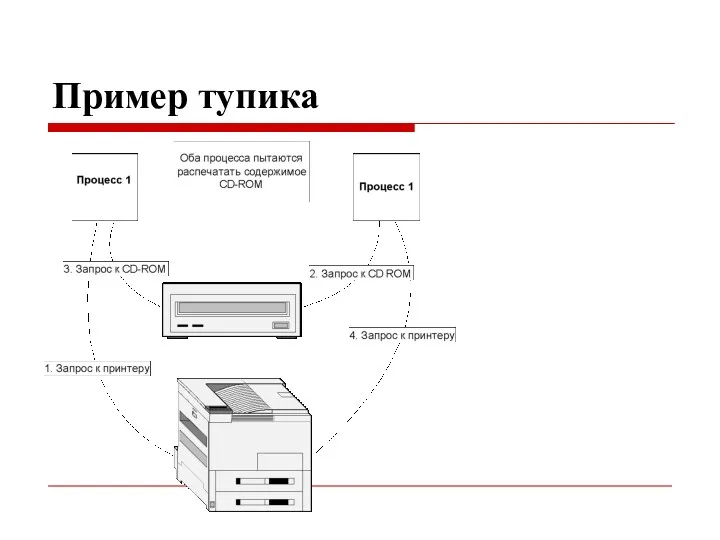
Пример тупика
Пример тупика

Потоки выполнения
Хотя процессы являются строительными блоками распределенных систем, практика показывает, что
Потоки выполнения
Хотя процессы являются строительными блоками распределенных систем, практика показывает, что

Понятие потока выполнения
Основная причина использования потоков заключается в том, что во
Понятие потока выполнения
Основная причина использования потоков заключается в том, что во

Преимущества потоков выполнения
Возможность использования параллельными процессами единого адресного пространства и всех
Преимущества потоков выполнения
Возможность использования параллельными процессами единого адресного пространства и всех
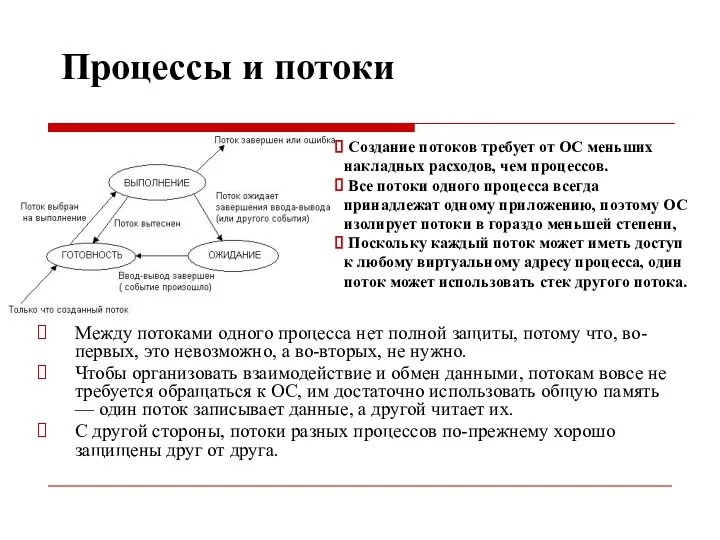
Процессы и потоки
Между потоками одного процесса нет полной защиты, потому что,
Процессы и потоки
Между потоками одного процесса нет полной защиты, потому что,

Потоки в локальных системах
Потоки в локальных системах

Межпроцессное взаимодействие
Многопоточная структура часто используется при построении больших приложений. Подобные приложения
Межпроцессное взаимодействие
Многопоточная структура часто используется при построении больших приложений. Подобные приложения

“Стоимость” переключения контекстов процессов
Рассмотрим состояние кэша процессора:
а) состояние кэша перед прерыванием,
“Стоимость” переключения контекстов процессов
Рассмотрим состояние кэша процессора:
а) состояние кэша перед прерыванием,

Потоки выполнения в нераспределенных системах
Имеется особая причина использовать потоки выполнения:
многие
Потоки выполнения в нераспределенных системах
Имеется особая причина использовать потоки выполнения:
многие

Реализация потоков выполнения
Потоки выполнения обычно существуют в виде пакетов. Подобные пакеты
Реализация потоков выполнения
Потоки выполнения обычно существуют в виде пакетов. Подобные пакеты
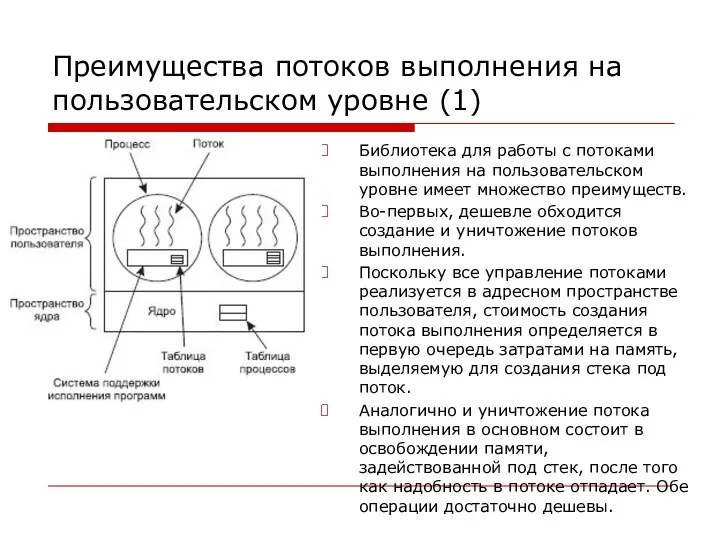
Преимущества потоков выполнения на пользовательском уровне (1)
Библиотека для работы с потоками
Преимущества потоков выполнения на пользовательском уровне (1)
Библиотека для работы с потоками

Преимущества потоков выполнения на пользовательском уровне (2)
Второе преимущество потоков выполнения на
Преимущества потоков выполнения на пользовательском уровне (2)
Второе преимущество потоков выполнения на
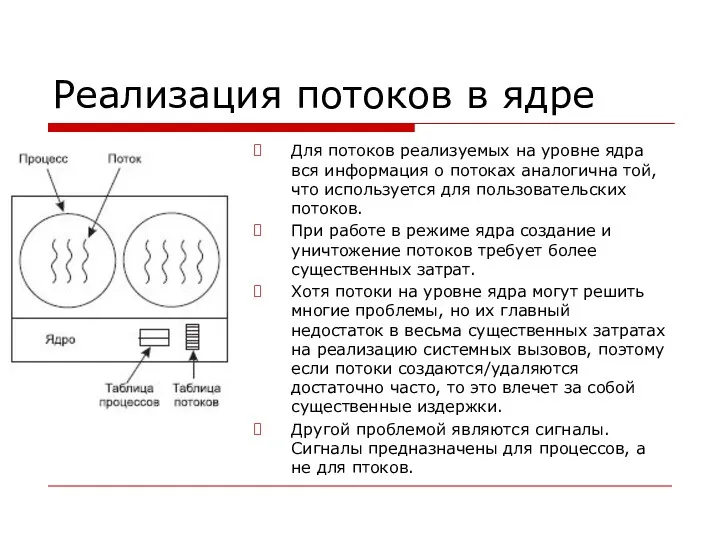
Реализация потоков в ядре
Для потоков реализуемых на уровне ядра вся информация
Реализация потоков в ядре
Для потоков реализуемых на уровне ядра вся информация
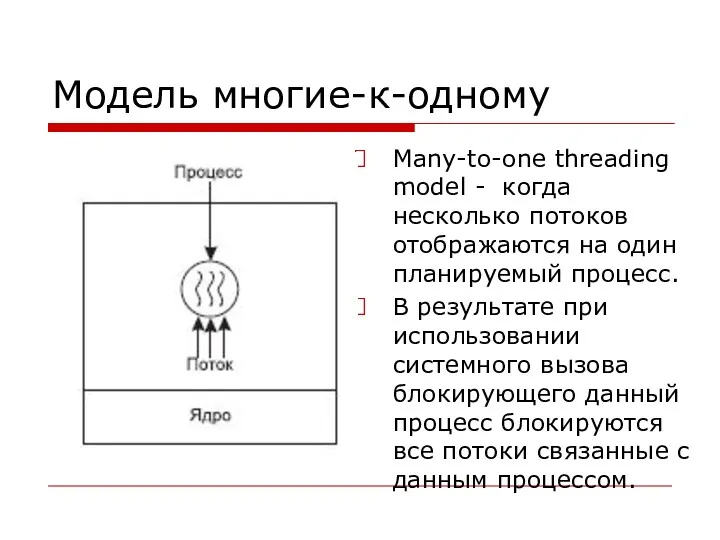
Модель многие-к-одному
Many-to-one threading model - когда несколько потоков отображаются на один
Модель многие-к-одному
Many-to-one threading model - когда несколько потоков отображаются на один
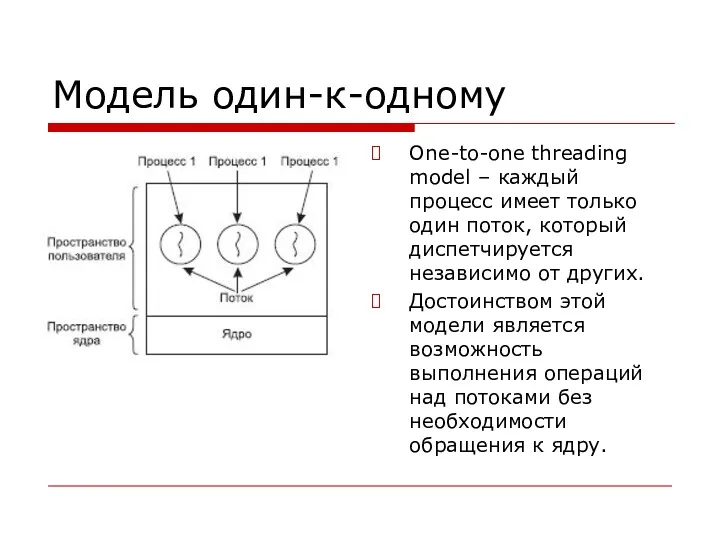
Модель один-к-одному
One-to-one threading model – каждый процесс имеет только один поток,
Модель один-к-одному
One-to-one threading model – каждый процесс имеет только один поток,
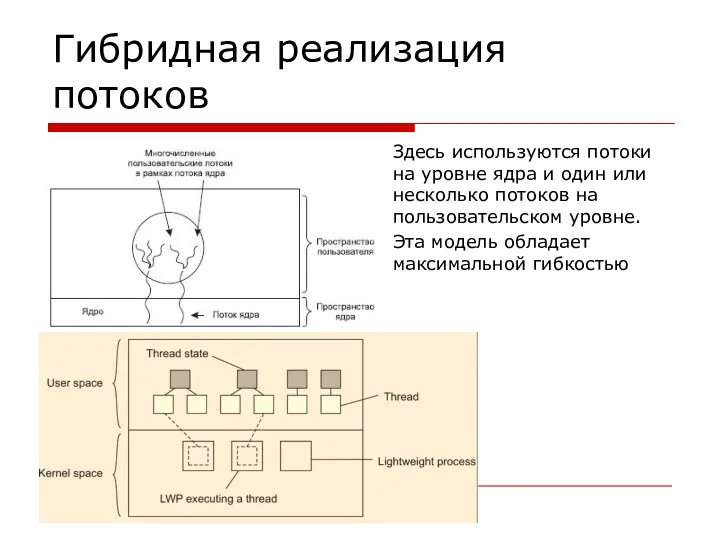
Гибридная реализация потоков
Здесь используются потоки на уровне ядра и один или
Гибридная реализация потоков
Здесь используются потоки на уровне ядра и один или

Использование потоков против применения группы конкурирующих процессов
Применение потоков является способом одновременного
Использование потоков против применения группы конкурирующих процессов
Применение потоков является способом одновременного

Потоки в распределенных системах
Потоки в распределенных системах

Почему потоки применяют в РС
Важнейшим свойством потоков выполнения является возможность выполнения
Почему потоки применяют в РС
Важнейшим свойством потоков выполнения является возможность выполнения

Многопоточные клиенты
Для обеспечения высокой степени прозрачности клиенты должны обладать поддержкой работы
Многопоточные клиенты
Для обеспечения высокой степени прозрачности клиенты должны обладать поддержкой работы
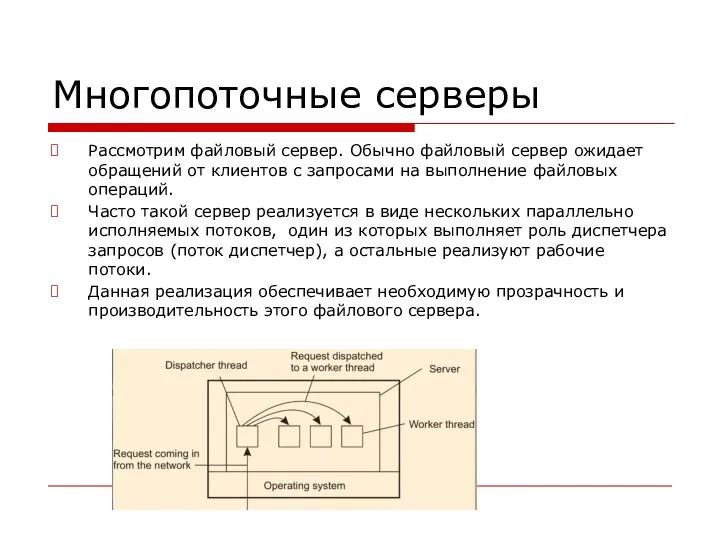
Многопоточные серверы
Рассмотрим файловый сервер. Обычно файловый сервер ожидает обращений от клиентов
Многопоточные серверы
Рассмотрим файловый сервер. Обычно файловый сервер ожидает обращений от клиентов

Три способа построения сервера
Три способа построения сервера

Виртуализация
Виртуализация

Понятие виртуализации
В компьютерных технологиях под термином "виртуализация" обычно понимается абстракция вычислительных
Понятие виртуализации
В компьютерных технологиях под термином "виртуализация" обычно понимается абстракция вычислительных

Виртуализация ЭВМ
Виртуализация серверов — размещение нескольких логических серверов в рамках одного
Виртуализация ЭВМ
Виртуализация серверов — размещение нескольких логических серверов в рамках одного
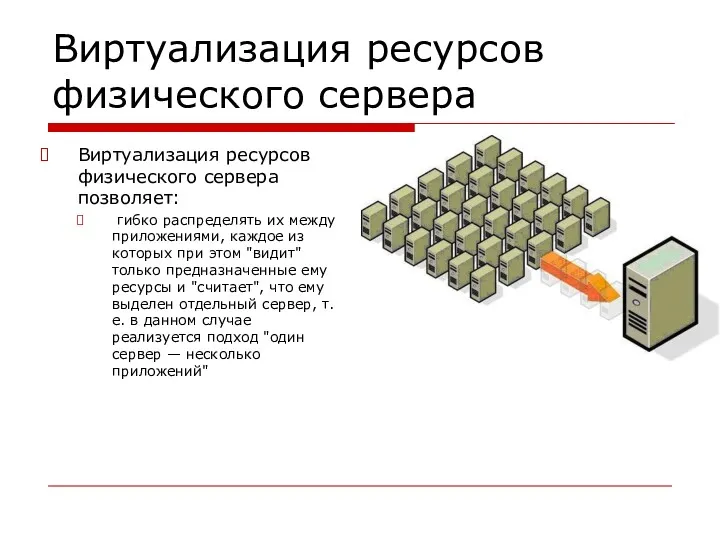
Виртуализация ресурсов физического сервера
Виртуализация ресурсов физического сервера позволяет:
гибко распределять их
Виртуализация ресурсов физического сервера
Виртуализация ресурсов физического сервера позволяет:
гибко распределять их
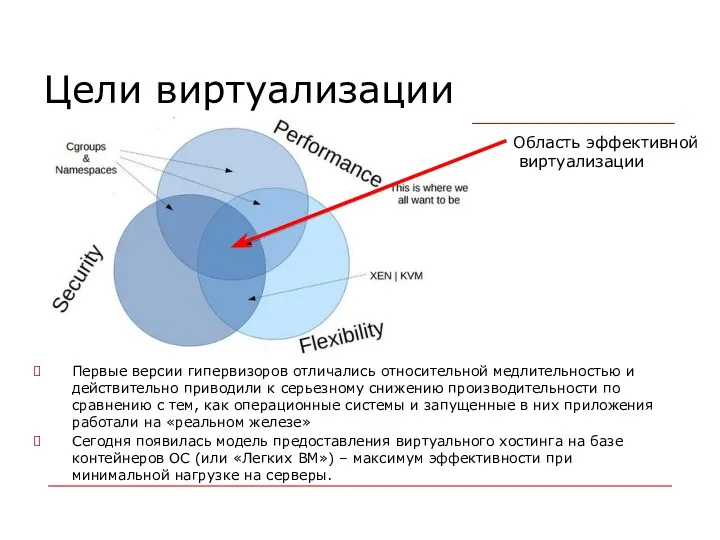
Цели виртуализации
Первые версии гипервизоров отличались относительной медлительностью и действительно приводили к
Цели виртуализации
Первые версии гипервизоров отличались относительной медлительностью и действительно приводили к

История виртуализации (1)
1965. Выражение “Hypervisor” впервые появилось применительно к ПО обработки
История виртуализации (1)
1965. Выражение “Hypervisor” впервые появилось применительно к ПО обработки

История виртуализации (2)
Первый гипервизор VM/370
В начале 70-х гипервизор СР-67, был переработан
История виртуализации (2)
Первый гипервизор VM/370
В начале 70-х гипервизор СР-67, был переработан

История виртуализации (3)
1980-90 г.г. В это время основные работы в области
История виртуализации (3)
1980-90 г.г. В это время основные работы в области

История виртуализации (3)
Позднее в "битву“включились такие компании как:
Parallels (ранее SWsoft), продукты
История виртуализации (3)
Позднее в "битву“включились такие компании как:
Parallels (ранее SWsoft), продукты
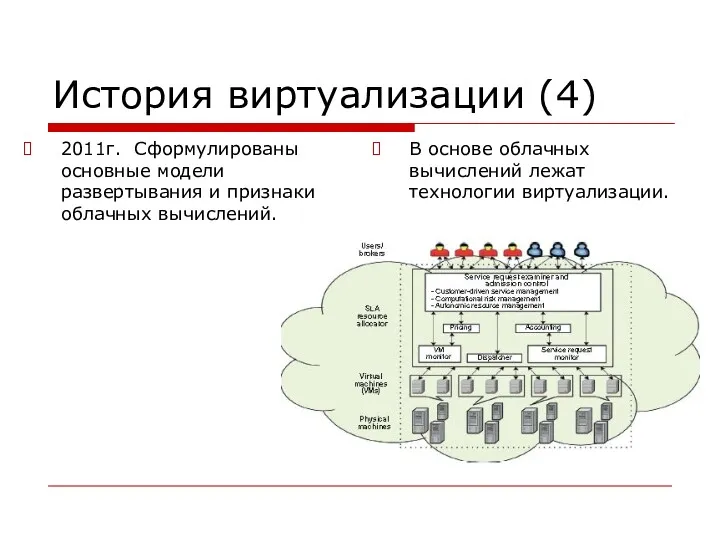
История виртуализации (4)
2011г. Сформулированы основные модели развертывания и признаки облачных вычислений.
История виртуализации (4)
2011г. Сформулированы основные модели развертывания и признаки облачных вычислений.
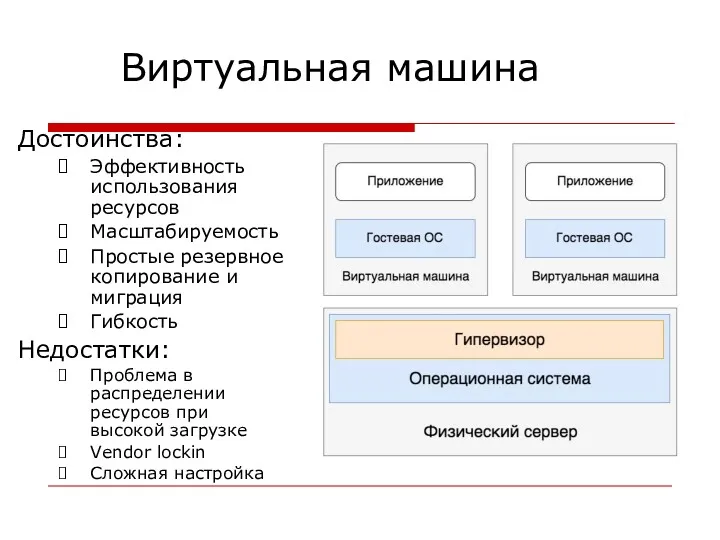
Виртуальная машина
Достоинства:
Эффективность использования ресурсов
Масштабируемость
Простые резервное копирование и миграция
Гибкость
Недостатки:
Проблема в распределении ресурсов
Виртуальная машина
Достоинства:
Эффективность использования ресурсов
Масштабируемость
Простые резервное копирование и миграция
Гибкость
Недостатки:
Проблема в распределении ресурсов
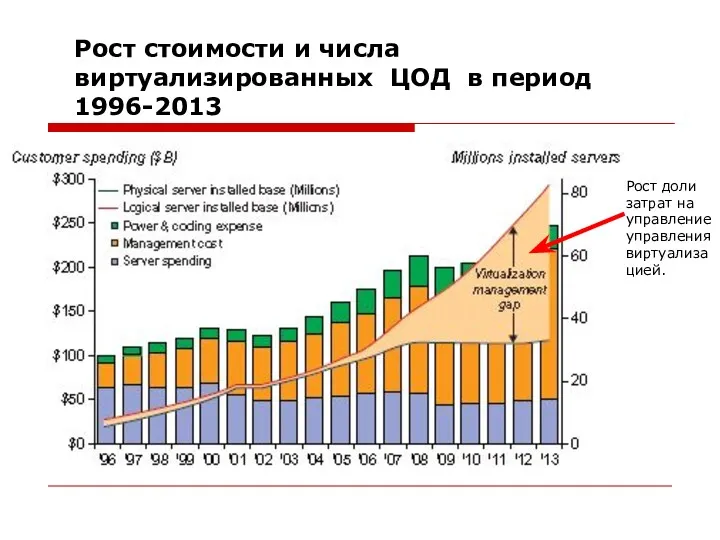
Рост стоимости и числа виртуализированных ЦОД в период 1996-2013
Рост доли затрат
Рост стоимости и числа виртуализированных ЦОД в период 1996-2013
Рост доли затрат

Принципы виртуализации
В реальной программной системе имеется ряд интерфейсов, начиная с базового
Принципы виртуализации
В реальной программной системе имеется ряд интерфейсов, начиная с базового
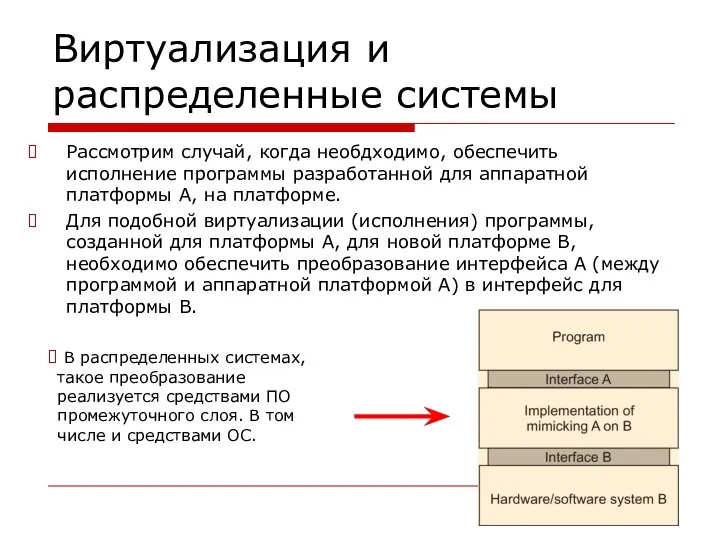
Виртуализация и раcпределенные системы
Рассмотрим случай, когда необдходимо, обеспечить исполнение программы разработанной
Виртуализация и раcпределенные системы
Рассмотрим случай, когда необдходимо, обеспечить исполнение программы разработанной
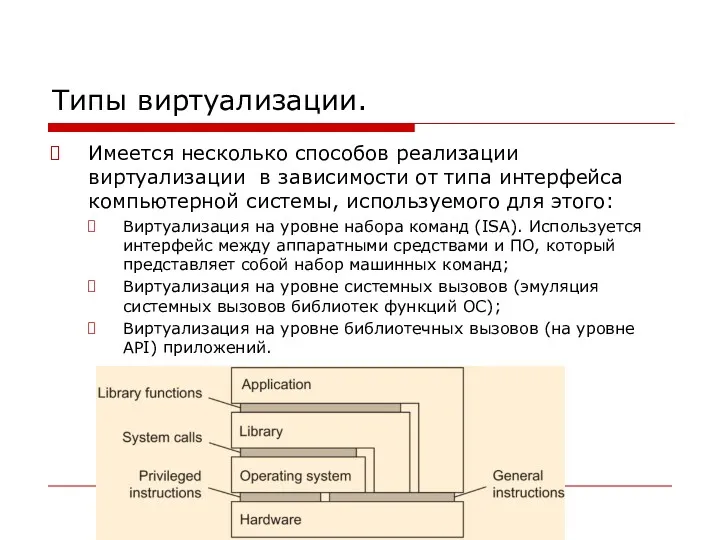
Типы виртуализации.
Имеется несколько способов реализации виртуализации в зависимости от типа интерфейса
Типы виртуализации.
Имеется несколько способов реализации виртуализации в зависимости от типа интерфейса

Принципы виртуализации
В компьютерной системе имеется ряд интерфейсов, начиная с базового набора
Принципы виртуализации
В компьютерной системе имеется ряд интерфейсов, начиная с базового набора
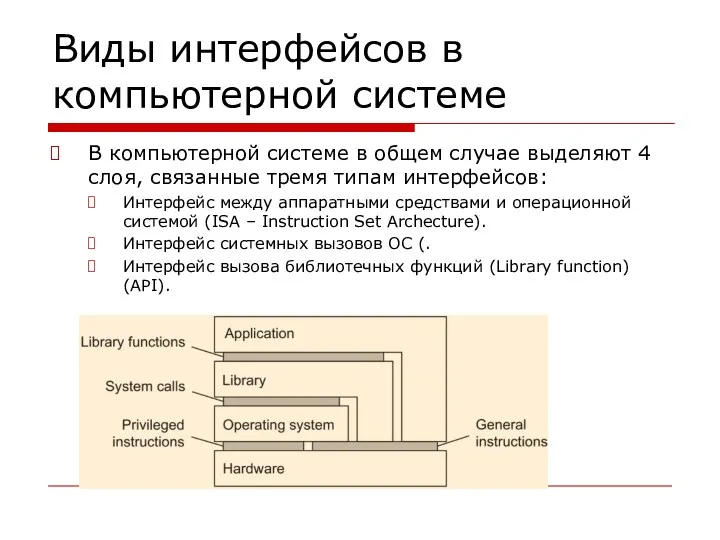
Виды интерфейсов в компьютерной системе
В компьютерной системе в общем случае выделяют
Виды интерфейсов в компьютерной системе
В компьютерной системе в общем случае выделяют
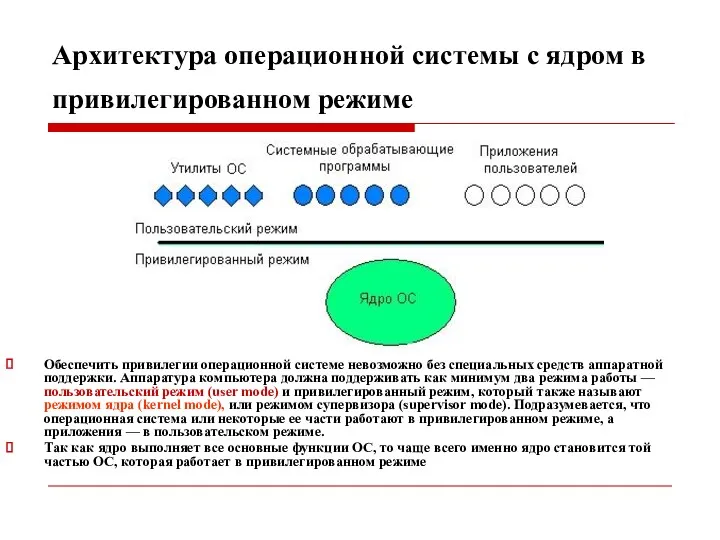
Архитектура операционной системы с ядром в привилегированном режиме
Обеспечить привилегии операционной
Архитектура операционной системы с ядром в привилегированном режиме
Обеспечить привилегии операционной
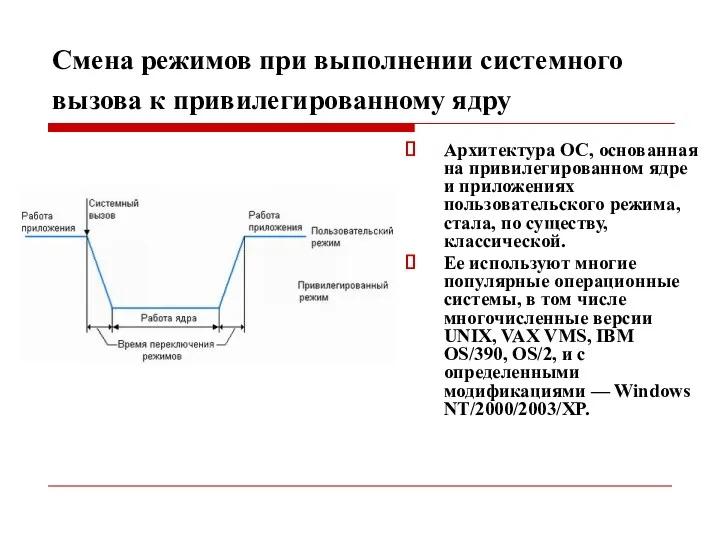
Смена режимов при выполнении системного вызова к привилегированному ядру
Архитектура ОС,
Смена режимов при выполнении системного вызова к привилегированному ядру
Архитектура ОС,
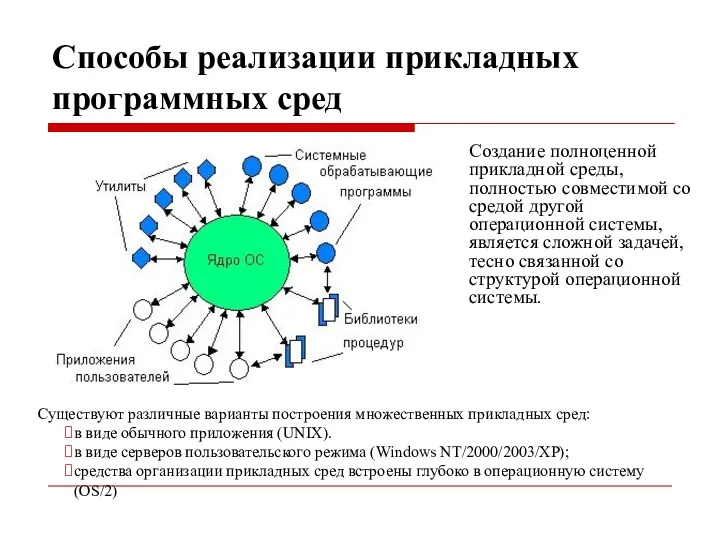
Способы реализации прикладных программных сред
Создание полноценной прикладной среды, полностью совместимой со
Способы реализации прикладных программных сред
Создание полноценной прикладной среды, полностью совместимой со
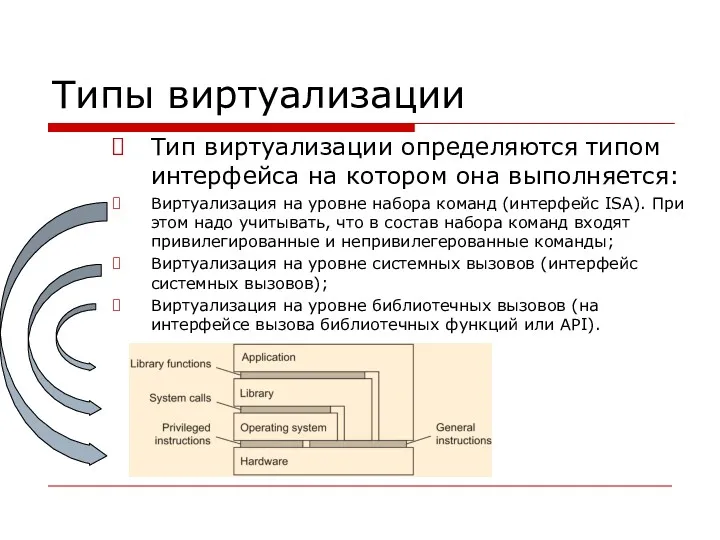
Типы виртуализации
Тип виртуализации определяются типом интерфейса на котором она выполняется:
Виртуализация на
Типы виртуализации
Тип виртуализации определяются типом интерфейса на котором она выполняется:
Виртуализация на

Два способа реализации виртуализации
Суть виртуализации – имитация поведения интерфейса компьютерной системы.
Два способа реализации виртуализации
Суть виртуализации – имитация поведения интерфейса компьютерной системы.
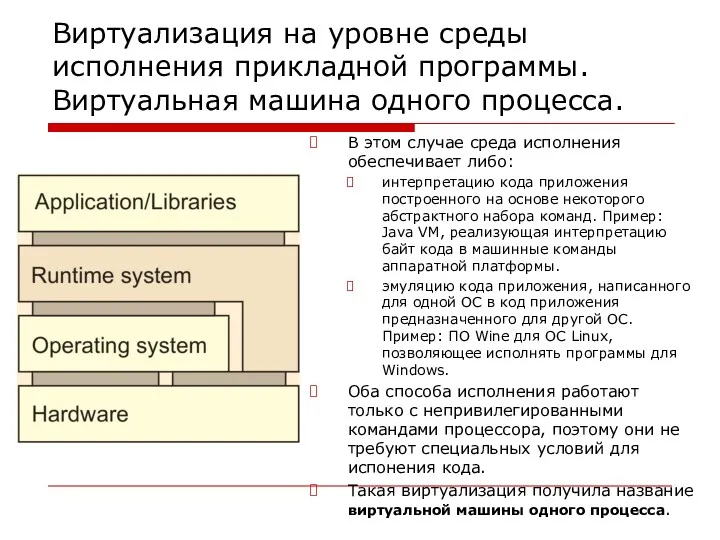
Виртуализация на уровне среды исполнения прикладной программы. Виртуальная машина одного процесса.
В
Виртуализация на уровне среды исполнения прикладной программы. Виртуальная машина одного процесса.
В

Требования к архитектуре ЭВМ, для поддержки виртуализации
В 1974 году двое ученых
Требования к архитектуре ЭВМ, для поддержки виртуализации
В 1974 году двое ученых

Проблемы виртуализации в архитектуре Intel x86
В наборе команд Intel x86 (включая
Проблемы виртуализации в архитектуре Intel x86
В наборе команд Intel x86 (включая

Монитор виртуальных машин
Идея монитора виртуальных машин не нова. Она была предложена
Монитор виртуальных машин
Идея монитора виртуальных машин не нова. Она была предложена

Два подхода к реализации монитора виртуальных машин
Имеются два подхода к построению
Два подхода к реализации монитора виртуальных машин
Имеются два подхода к построению
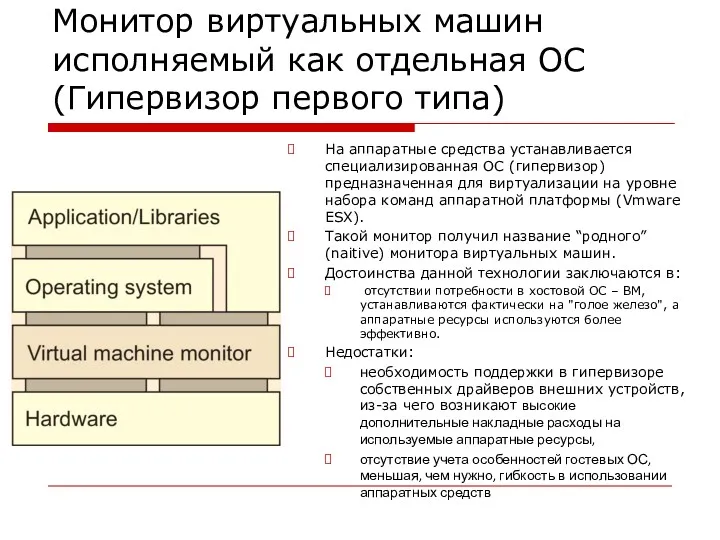
Монитор виртуальных машин исполняемый как отдельная ОС
(Гипервизор первого типа)
На аппаратные
Монитор виртуальных машин исполняемый как отдельная ОС
(Гипервизор первого типа)
На аппаратные
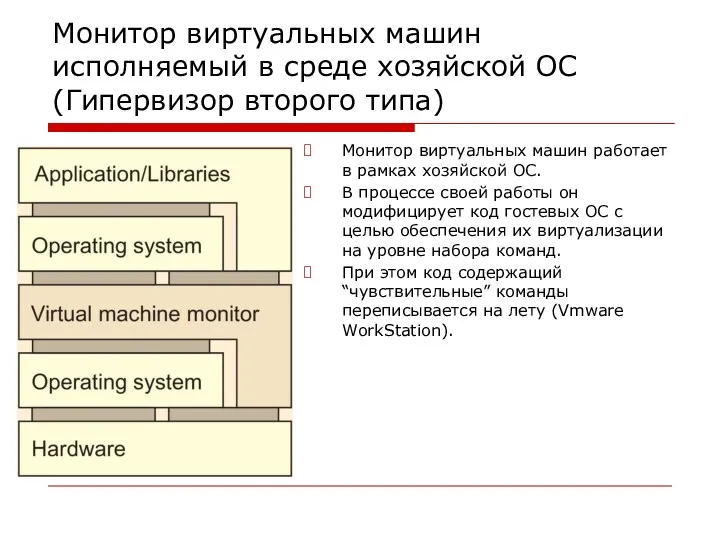
Монитор виртуальных машин исполняемый в среде хозяйской ОС
(Гипервизор второго типа)
Монитор виртуальных
Монитор виртуальных машин исполняемый в среде хозяйской ОС
(Гипервизор второго типа)
Монитор виртуальных

Паравиртуализация
техника виртуализации, при которой гостевые операционные системы подготавливаются для исполнения в
Паравиртуализация
техника виртуализации, при которой гостевые операционные системы подготавливаются для исполнения в
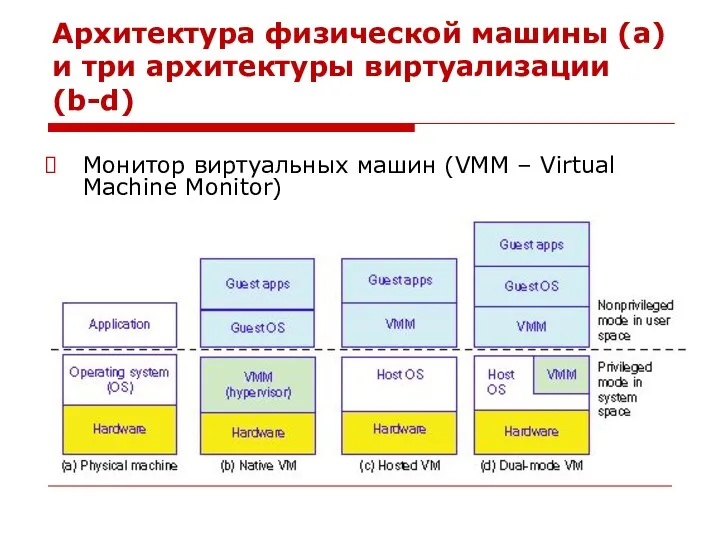
Архитектура физической машины (a) и три архитектуры виртуализации (b-d)
Монитор виртуальных машин
Архитектура физической машины (a) и три архитектуры виртуализации (b-d)
Монитор виртуальных машин

Виртуализация на уровне операционной системы
— виртуализирует физический сервер на уровне ОС,
Виртуализация на уровне операционной системы
— виртуализирует физический сервер на уровне ОС,

Контейнерная виртуализация в Linux
Экземпляры пространств пользователя (часто называемые контейнерами или зонами) с точки зрения
Контейнерная виртуализация в Linux
Экземпляры пространств пользователя (часто называемые контейнерами или зонами) с точки зрения
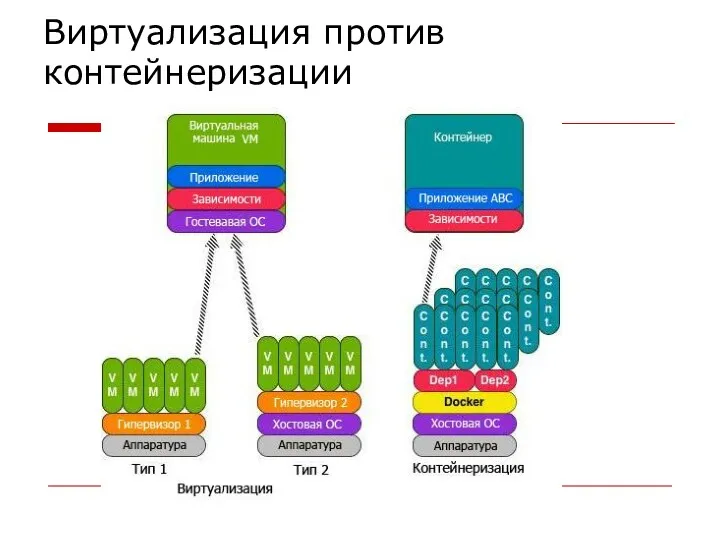
Виртуализация против контейнеризации
Виртуализация против контейнеризации

Виртуализация и распределенные системы
Одной из важнейшей причиной, но не единственной, появления
Виртуализация и распределенные системы
Одной из важнейшей причиной, но не единственной, появления
Основы облачных вычислений
Основы облачных вычислений

Что это такое ? (1)
Пользователь:
1. Сегодня под облачными вычислениями обычно понимают
Что это такое ? (1)
Пользователь:
1. Сегодня под облачными вычислениями обычно понимают

Что это такое ?(2)
Руководитель ИТ:
1. Это новый подход, позволяющий снизить сложность
Что это такое ?(2)
Руководитель ИТ:
1. Это новый подход, позволяющий снизить сложность

Понятие облачные вычисления
Под облачными вычислениями мы понимаем программно-аппаратное обеспечение, доступное пользователю
Понятие облачные вычисления
Под облачными вычислениями мы понимаем программно-аппаратное обеспечение, доступное пользователю
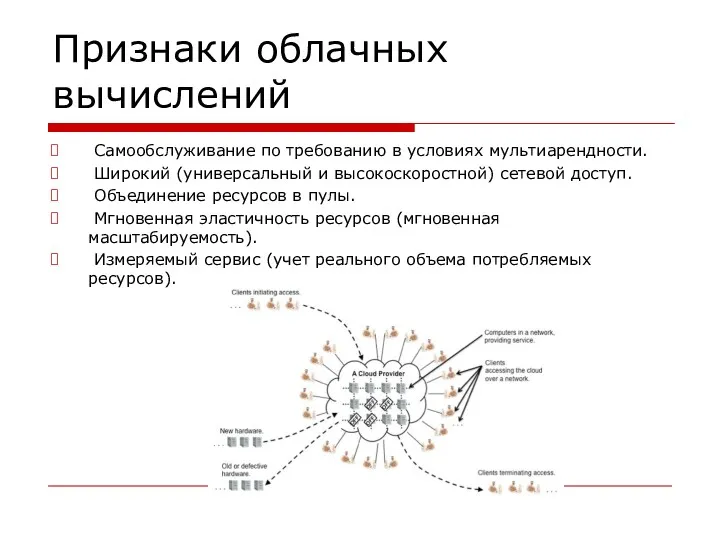
Признаки облачных вычислений
Самообслуживание по требованию в условиях мультиарендности.
Широкий
Признаки облачных вычислений
Самообслуживание по требованию в условиях мультиарендности.
Широкий
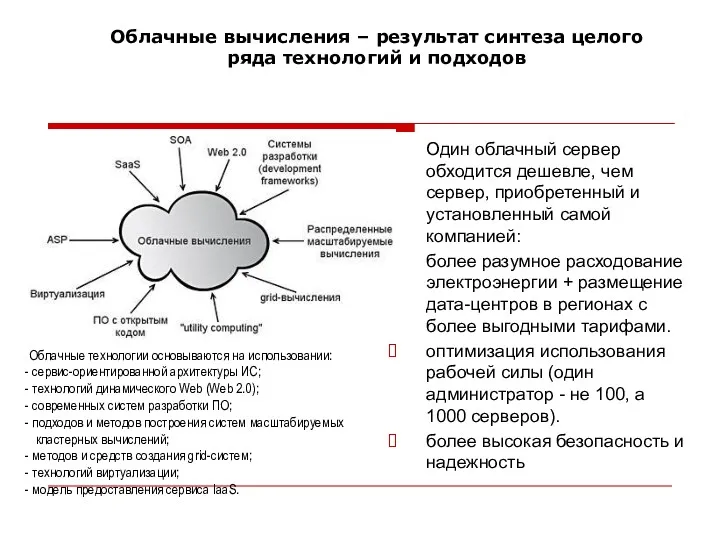
Один облачный сервер обходится дешевле, чем сервер, приобретенный и установленный самой
Один облачный сервер обходится дешевле, чем сервер, приобретенный и установленный самой
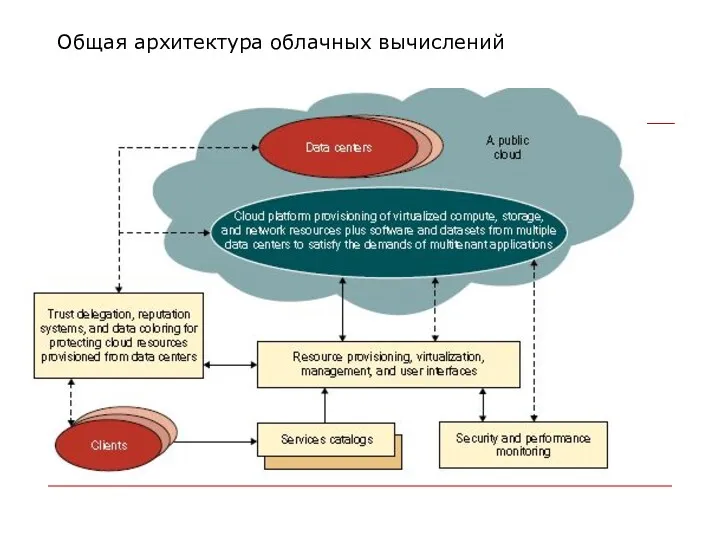
Общая архитектура облачных вычислений
Общая архитектура облачных вычислений

Общая архитектура облаков
Включает следующие компоненты:
ЦОДы – центры обработки данных;
платформы снабжения виртуализированными
Общая архитектура облаков
Включает следующие компоненты:
ЦОДы – центры обработки данных;
платформы снабжения виртуализированными
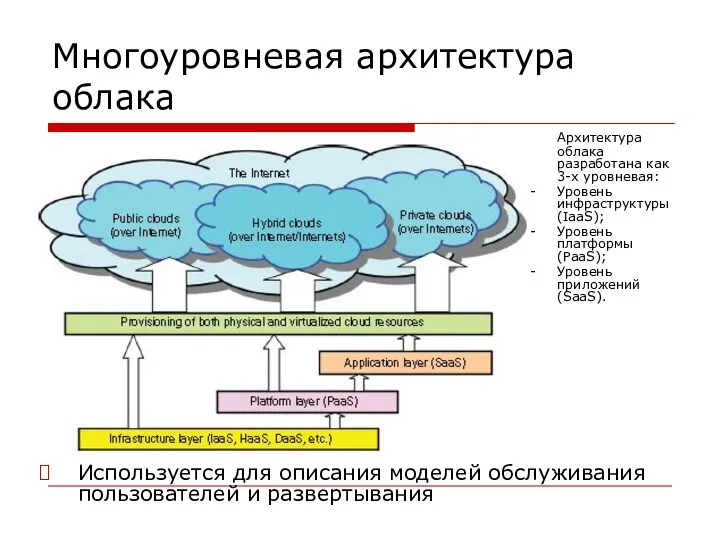
Многоуровневая архитектура облака
Используется для описания моделей обслуживания пользователей и развертывания
Архитектура облака
Многоуровневая архитектура облака
Используется для описания моделей обслуживания пользователей и развертывания
Архитектура облака

Сервисные модели облачных вычислений
Сервисные модели облачных вычислений

Уровень инфраструктуры (IaaS)
Служит основой для создания других уровней облака.
Строится на
Уровень инфраструктуры (IaaS)
Служит основой для создания других уровней облака.
Строится на

Уровень платформы (PaaS)
Предназначен для общего в том числе и для повторного
Уровень платформы (PaaS)
Предназначен для общего в том числе и для повторного
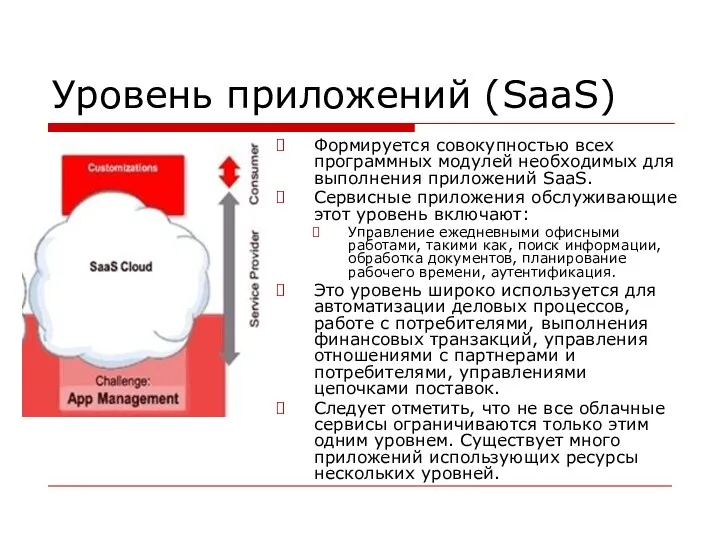
Уровень приложений (SaaS)
Формируется совокупностью всех программных модулей необходимых для выполнения приложений
Уровень приложений (SaaS)
Формируется совокупностью всех программных модулей необходимых для выполнения приложений

Облачные вычисления как эволюция архитектуры корпоративных приложений
Облачные вычисления – это следующий
Облачные вычисления как эволюция архитектуры корпоративных приложений
Облачные вычисления – это следующий
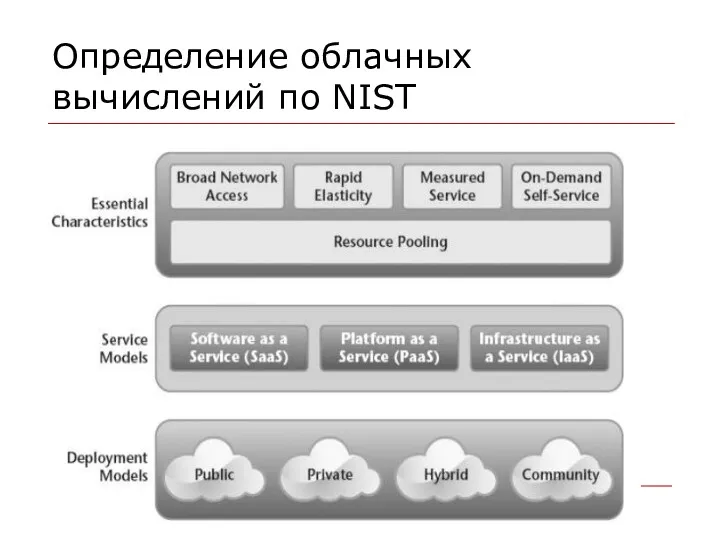
Определение облачных вычислений по NIST
Определение облачных вычислений по NIST
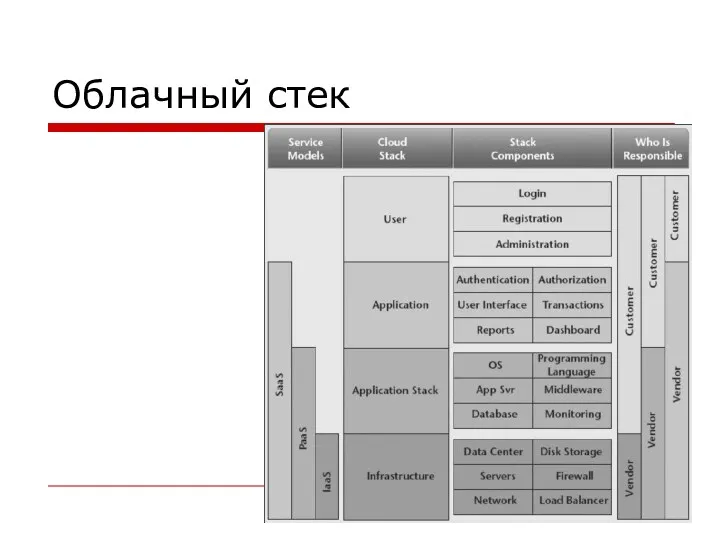
Облачный стек
Облачный стек

Архитектурная модель.
Участники процесса.
Архитектурная модель.
Участники процесса.
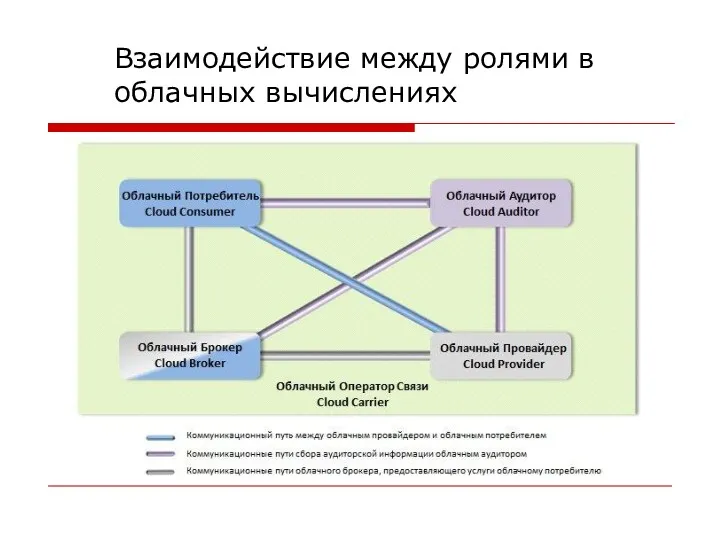
Взаимодействие между ролями в облачных вычислениях
Взаимодействие между ролями в облачных вычислениях
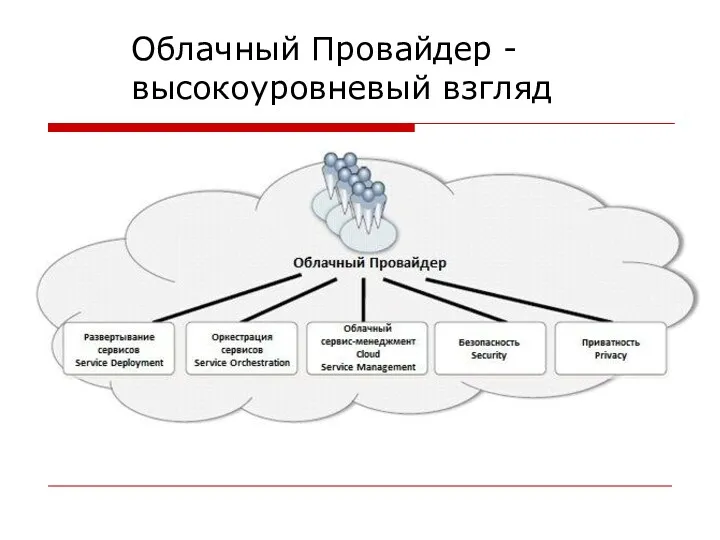
Облачный Провайдер - высокоуровневый взгляд
Облачный Провайдер - высокоуровневый взгляд
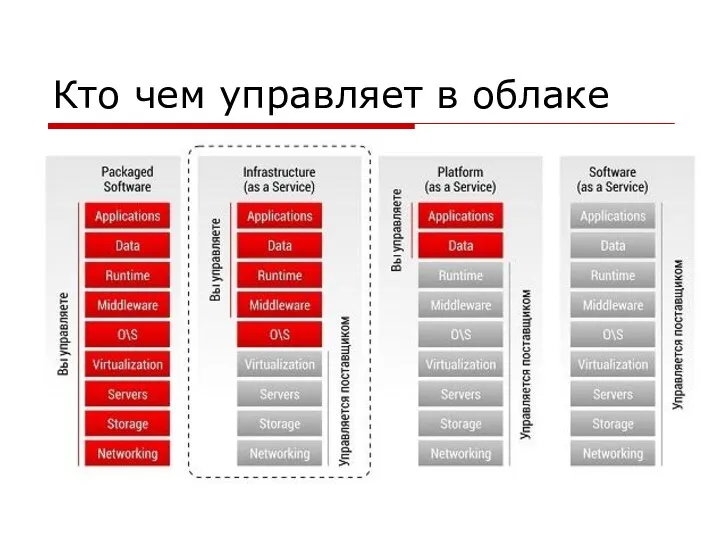
Кто чем управляет в облаке
Кто чем управляет в облаке
Типы облаков
Типы облаков
Внутреннее частное облако
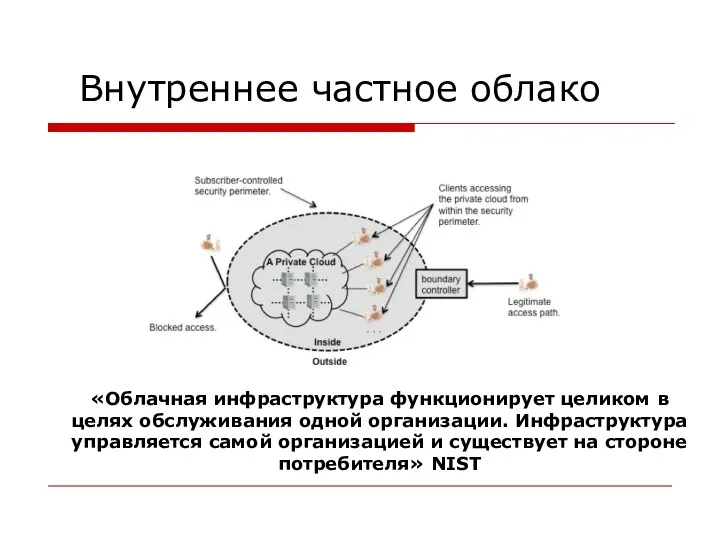
«Облачная инфраструктура функционирует целиком в целях обслуживания одной организации.
Внутреннее частное облако
«Облачная инфраструктура функционирует целиком в целях обслуживания одной организации.
Внешнее частное облако
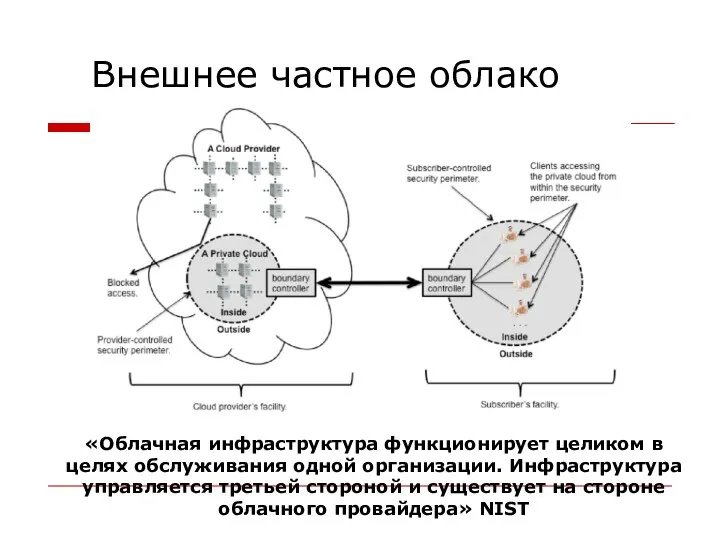
«Облачная инфраструктура функционирует целиком в целях обслуживания одной организации.
Внешнее частное облако
«Облачная инфраструктура функционирует целиком в целях обслуживания одной организации.
Гибридное облако
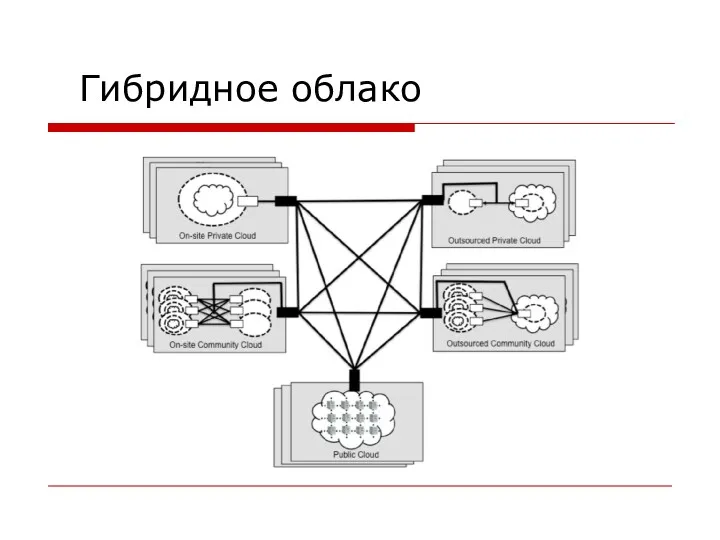
Гибридное облако
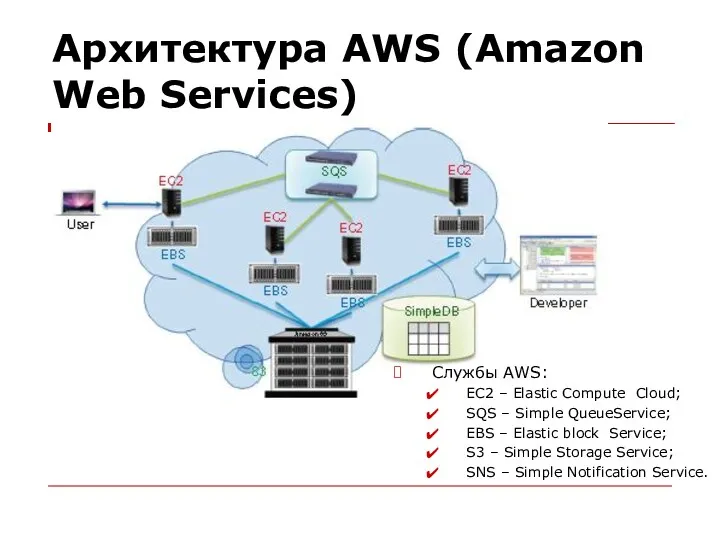
Архитектура AWS (Amazon Web Services)
Службы AWS:
EC2 – Elastic Compute Cloud;
SQS
Архитектура AWS (Amazon Web Services)
Службы AWS:
EC2 – Elastic Compute Cloud;
SQS
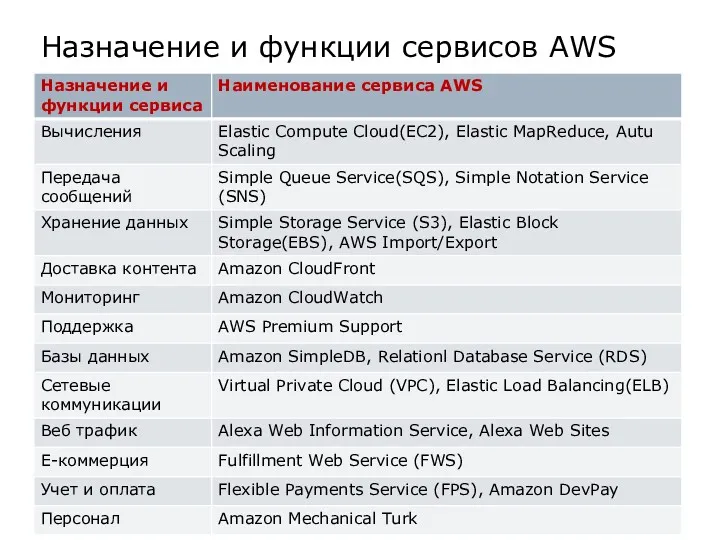
Назначение и функции сервисов AWS
Назначение и функции сервисов AWS

Подходы к проектированию процессов выполняемых компонентами РС
Подходы к проектированию процессов выполняемых компонентами РС

Клиенты РС
Клиенты РС

Функции клиента РС
Основное назначение:
Предоставление пользователю возможности взаимодействовать с сервером и получать
Функции клиента РС
Основное назначение:
Предоставление пользователю возможности взаимодействовать с сервером и получать
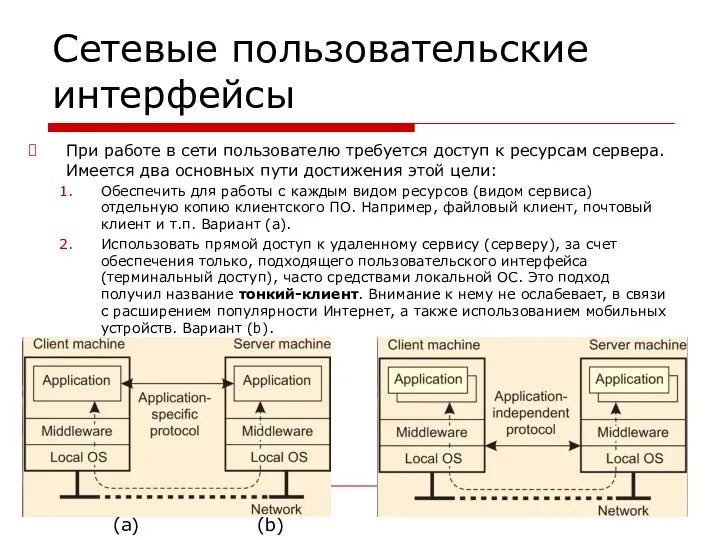
Сетевые пользовательские интерфейсы
При работе в сети пользователю требуется доступ к ресурсам
Сетевые пользовательские интерфейсы
При работе в сети пользователю требуется доступ к ресурсам

Пример: Система X-Window
Одним из старейших, но широко распространенных протоколов удаленного обеспечения
Пример: Система X-Window
Одним из старейших, но широко распространенных протоколов удаленного обеспечения
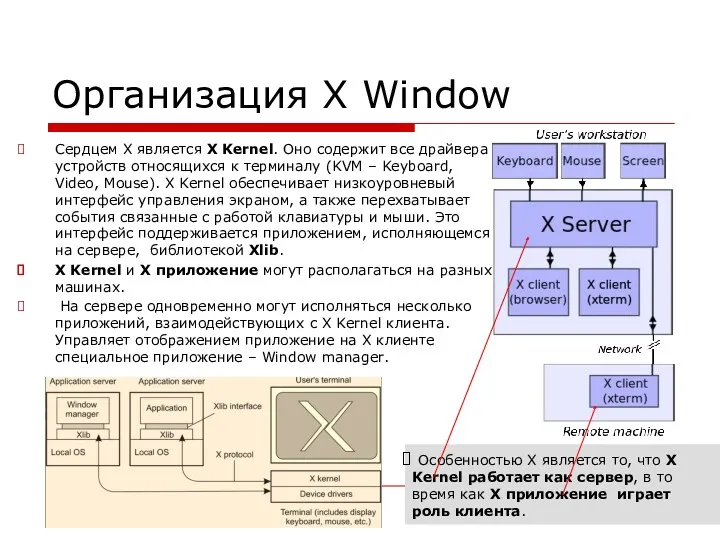
Организация X Window
Сердцем X является X Kernel. Оно содержит все драйвера
Организация X Window
Сердцем X является X Kernel. Оно содержит все драйвера

Тонкий сетевой клиент
Недостатки X Window:
X приложение в процессе своей работы посылает
Тонкий сетевой клиент
Недостатки X Window:
X приложение в процессе своей работы посылает

Технология NX
Основана на исходном протоколе X Window, со следующими улучшениями:
Использование сжатия
Технология NX
Основана на исходном протоколе X Window, со следующими улучшениями:
Использование сжатия

VNC
Является альтернативой X Window, в которой приложение полностью управляет отображением на
VNC
Является альтернативой X Window, в которой приложение полностью управляет отображением на

THINC
Недостатком передачи сырых данных пикселей по сравнению с высоуровневыми протоколами такими
THINC
Недостатком передачи сырых данных пикселей по сравнению с высоуровневыми протоколами такими

Клиентское ПО прозрачного доступа
Во многих случаях требуется обеспечить прозрачное выполнение обработки
Клиентское ПО прозрачного доступа
Во многих случаях требуется обеспечить прозрачное выполнение обработки
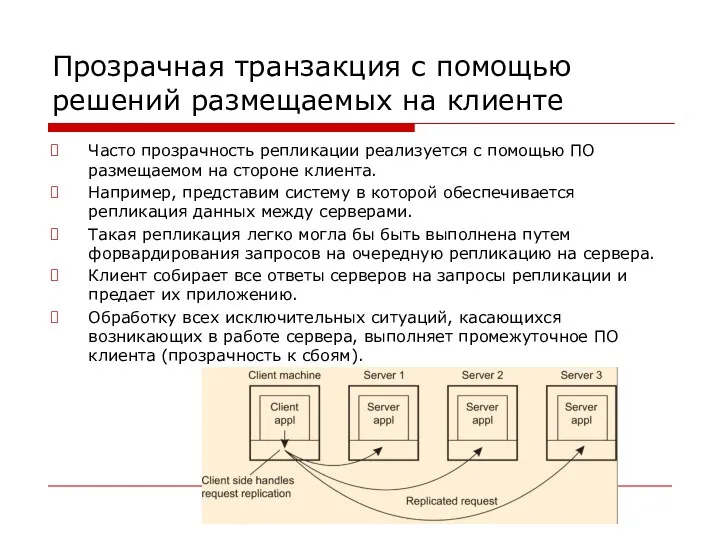
Прозрачная транзакция с помощью решений размещаемых на клиенте
Часто прозрачность репликации реализуется
Прозрачная транзакция с помощью решений размещаемых на клиенте
Часто прозрачность репликации реализуется

Сервера РС
Сервера РС

Общие проблемы создания серверов РС
Сервер реализуется средствами исполнения процессов обеспечивающих реализацию
Общие проблемы создания серверов РС
Сервер реализуется средствами исполнения процессов обеспечивающих реализацию

Параллельный сервер против
итерационного
В случае использования параллельной работы сервера, поступающий
Параллельный сервер против
итерационного
В случае использования параллельной работы сервера, поступающий
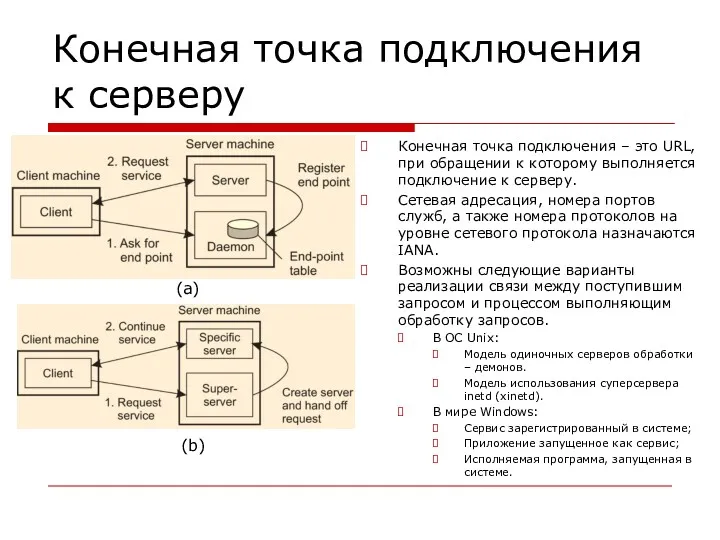
Конечная точка подключения к серверу
Конечная точка подключения – это URL, при
Конечная точка подключения к серверу
Конечная точка подключения – это URL, при

Прерываемый сервер
При создании сервера следует принимать во внимание когда и как
Прерываемый сервер
При создании сервера следует принимать во внимание когда и как

Сервер с фиксацией состояния
Сервер с фиксацией состояния (stateful server) хранит
Сервер с фиксацией состояния
Сервер с фиксацией состояния (stateful server) хранит

Достоинства и недостатки сервера с фиксацией состояния
Достоинства:
Рост производительности по сравнению с
Достоинства и недостатки сервера с фиксацией состояния
Достоинства:
Рост производительности по сравнению с

Сервер без состояния
Сервер без фиксации состояния (stateless sewer) не сохраняет информацию
Сервер без состояния
Сервер без фиксации состояния (stateless sewer) не сохраняет информацию

Серверы объектов
Сервер объектов {object sewer) — это сервер, ориентированный на поддержку
Серверы объектов
Сервер объектов {object sewer) — это сервер, ориентированный на поддержку

Обращение к объектам
Объект состоит из двух частей:
данных, отражающих его состояние,
Обращение к объектам
Объект состоит из двух частей:
данных, отражающих его состояние,

Способы обращению к объектам.
Политика активизации
Для любого объекта, к которому происходит обращение,
Способы обращению к объектам.
Политика активизации
Для любого объекта, к которому происходит обращение,
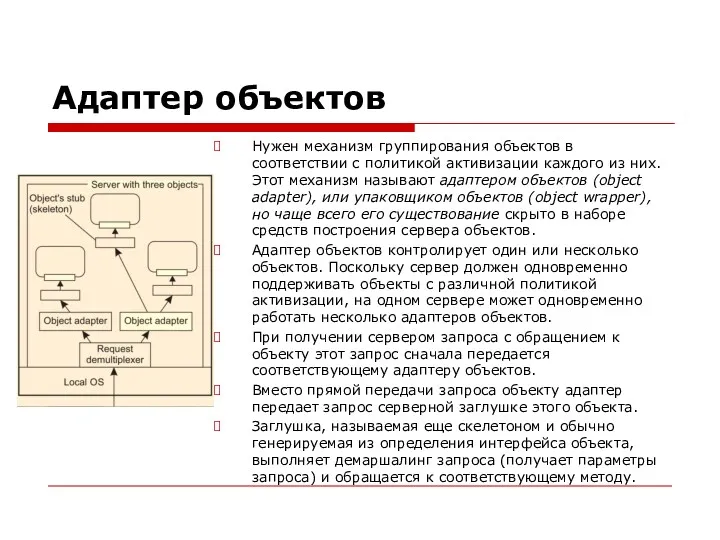
Адаптер объектов
Нужен механизм группирования объектов в соответствии с политикой активизации каждого
Адаптер объектов
Нужен механизм группирования объектов в соответствии с политикой активизации каждого
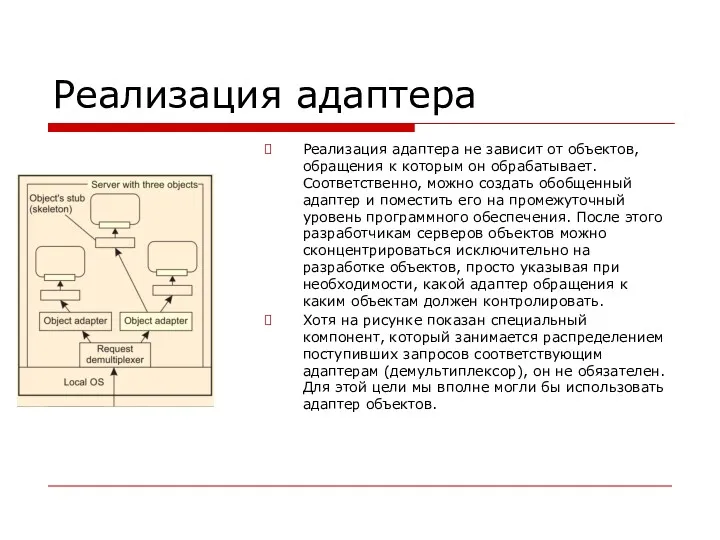
Реализация адаптера
Реализация адаптера не зависит от объектов, обращения к которым он
Реализация адаптера
Реализация адаптера не зависит от объектов, обращения к которым он
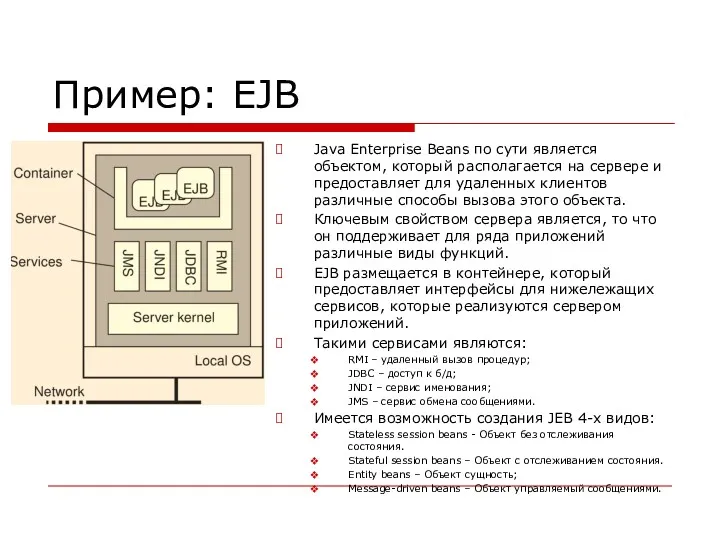
Пример: EJB
Java Enterprise Beans по сути является объектом, который располагается на
Пример: EJB
Java Enterprise Beans по сути является объектом, который располагается на
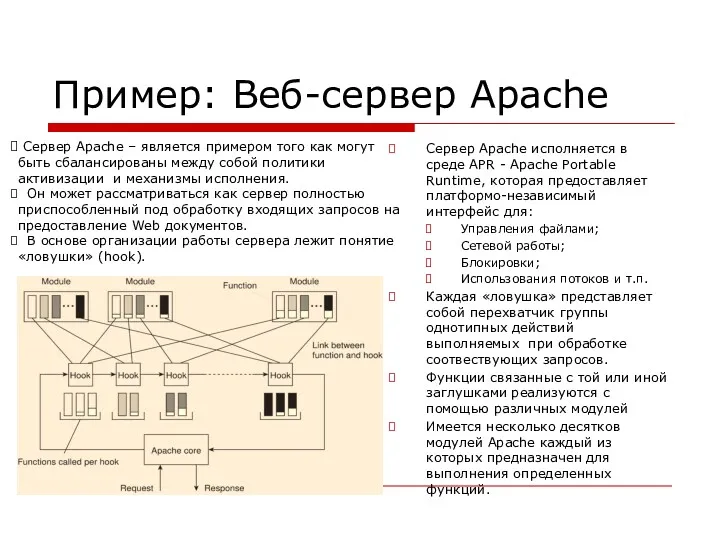
Пример: Веб-сервер Apache
Сервер Apache исполняется в среде APR - Apache Portable
Пример: Веб-сервер Apache
Сервер Apache исполняется в среде APR - Apache Portable
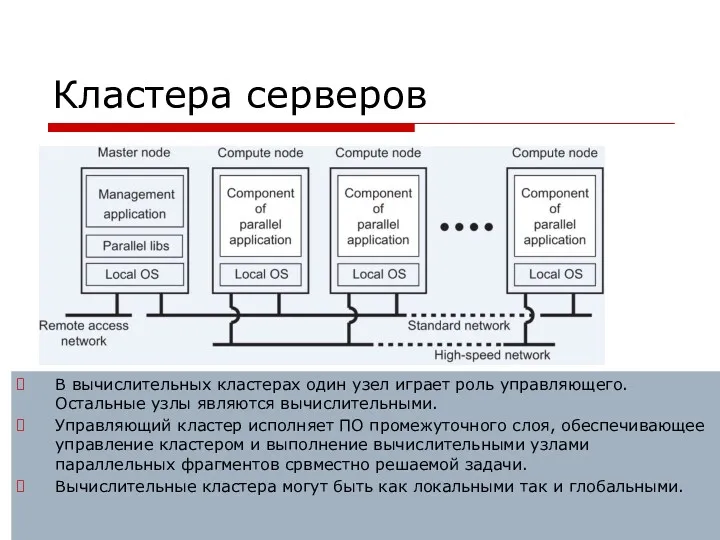
Кластера серверов
В вычислительных кластерах один узел играет роль управляющего. Остальные узлы
Кластера серверов
В вычислительных кластерах один узел играет роль управляющего. Остальные узлы
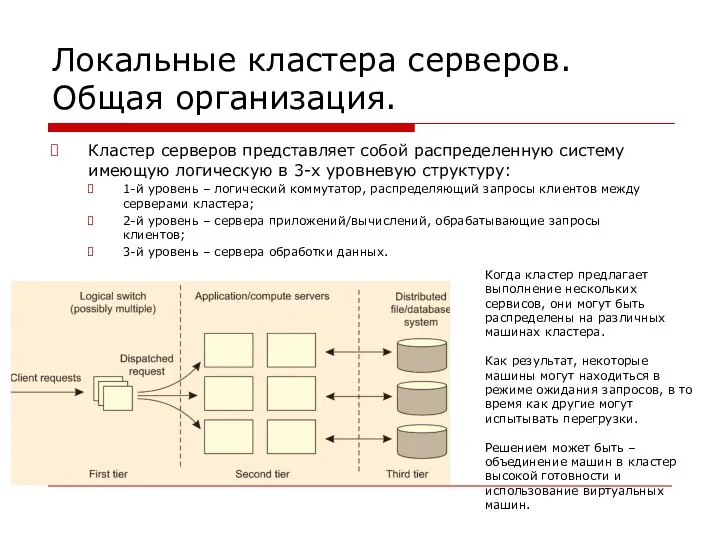
Локальные кластера серверов. Общая организация.
Кластер серверов представляет собой распределенную систему имеющую
Локальные кластера серверов. Общая организация.
Кластер серверов представляет собой распределенную систему имеющую
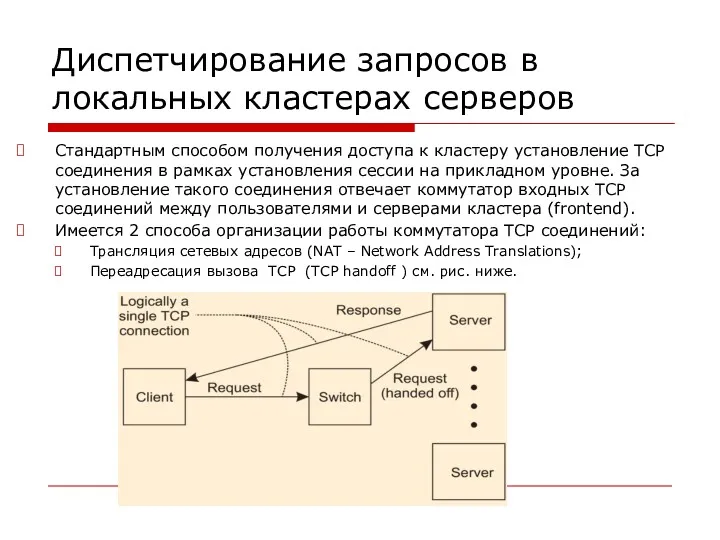
Диспетчирование запросов в локальных кластерах серверов
Стандартным способом получения доступа к кластеру
Диспетчирование запросов в локальных кластерах серверов
Стандартным способом получения доступа к кластеру
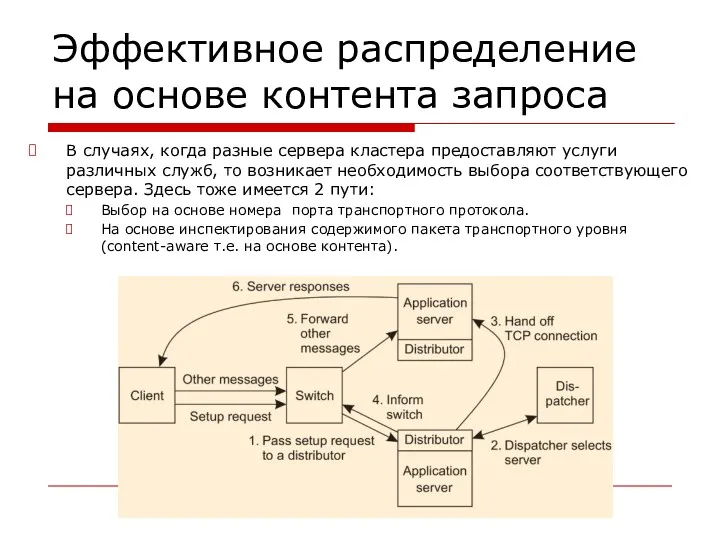
Эффективное раcпределение на основе контента запроса
В случаях, когда разные сервера кластера
Эффективное раcпределение на основе контента запроса
В случаях, когда разные сервера кластера

Глобальные кластеры серверов
Облачные провайдеры Amazon и Google имеют собственные ЦОД в
Глобальные кластеры серверов
Облачные провайдеры Amazon и Google имеют собственные ЦОД в

Политика перенаправления
Необходимость выбора сервера ближайшего к источнику запроса порождает проблему политики
Политика перенаправления
Необходимость выбора сервера ближайшего к источнику запроса порождает проблему политики
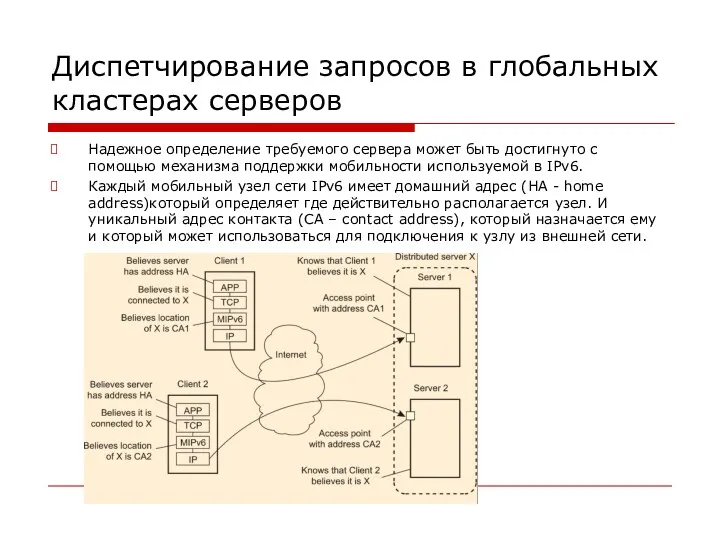
Диспетчирование запросов в глобальных кластерах серверов
Надежное определение требуемого сервера может быть
Диспетчирование запросов в глобальных кластерах серверов
Надежное определение требуемого сервера может быть

Миграция кода
Миграция кода

Основания для переноса кода
Традиционно перенос кода в распределенных системах происходит в
Основания для переноса кода
Традиционно перенос кода в распределенных системах происходит в
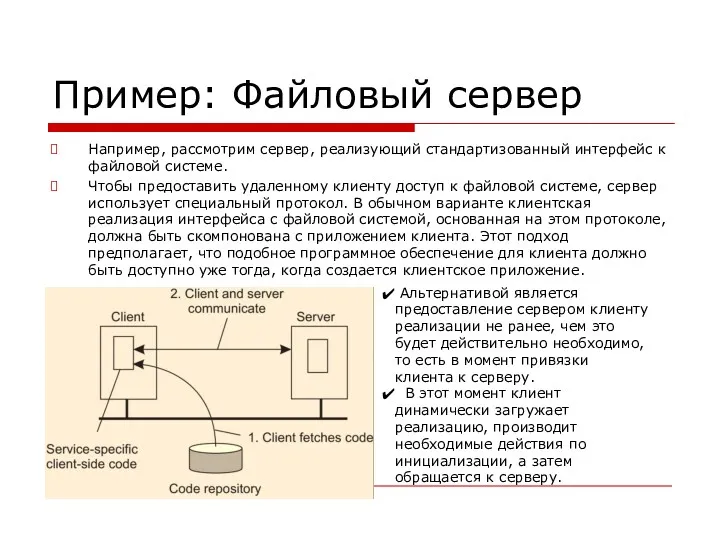
Пример: Файловый сервер
Например, рассмотрим сервер, реализующий стандартизованный интерфейс к файловой системе.
Пример: Файловый сервер
Например, рассмотрим сервер, реализующий стандартизованный интерфейс к файловой системе.

Модели переноса кода
Перенос кода в широком смысле связан с переносом программ
Модели переноса кода
Перенос кода в широком смысле связан с переносом программ

Модель слабой мобильности
Согласно этой модели допускается перенос только сегмента кода, возможно
Модель слабой мобильности
Согласно этой модели допускается перенос только сегмента кода, возможно

Модель сильной мобильности
Характерная черта сильной мобильности — то, что работающий процесс
Модель сильной мобильности
Характерная черта сильной мобильности — то, что работающий процесс

Инициатор переносимости кода
Независимо от того, является мобильность слабой или сильной, следует
Инициатор переносимости кода
Независимо от того, является мобильность слабой или сильной, следует
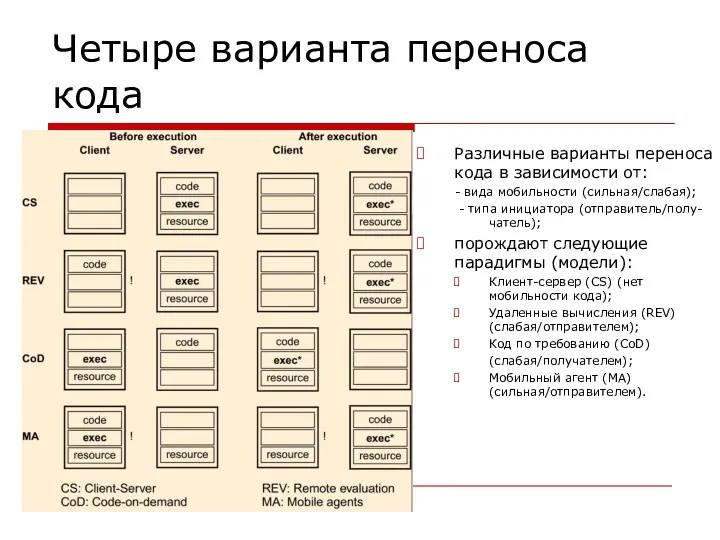
Четыре варианта переноса кода
Различные варианты переноса кода в зависимости от:
- вида
Четыре варианта переноса кода
Различные варианты переноса кода в зависимости от:
- вида

Удаленное клонирование процессов
Помимо переноса работающего процесса, называемого также миграцией процесса, сильная
Удаленное клонирование процессов
Помимо переноса работающего процесса, называемого также миграцией процесса, сильная

Миграция кода в гетерогенных системах
Перенос в гетерогенных системах требует, чтобы поддерживались
Миграция кода в гетерогенных системах
Перенос в гетерогенных системах требует, чтобы поддерживались

Методы портирования процессов в гетерогенных системах.
В разные годы были предложены следующие
Методы портирования процессов в гетерогенных системах.
В разные годы были предложены следующие
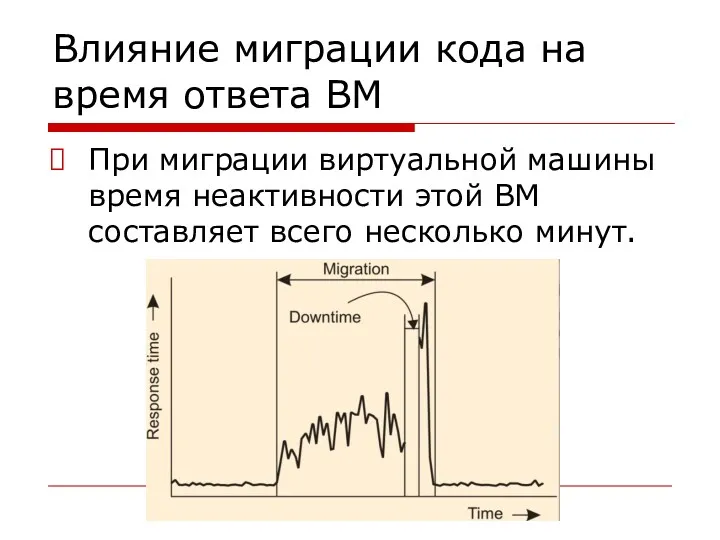
Влияние миграции кода на время ответа ВМ
При миграции виртуальной машины время
Влияние миграции кода на время ответа ВМ
При миграции виртуальной машины время
 Кодирование информации. Текст как форма представления информации
Кодирование информации. Текст как форма представления информации Эволюция развития интернета и перспективы использования новых телекоммуникационных возможностей
Эволюция развития интернета и перспективы использования новых телекоммуникационных возможностей Instructions for use edit in Google Slides edit in Powerpoint®
Instructions for use edit in Google Slides edit in Powerpoint® Создание сайта средствами HTML
Создание сайта средствами HTML Бренд-персонаж в игровой индустрии
Бренд-персонаж в игровой индустрии Помощник проектировщика
Помощник проектировщика DWIN COF Screen User Manual
DWIN COF Screen User Manual Интеллектуальные информационные системы и технологии
Интеллектуальные информационные системы и технологии Методы и средства хранения информации
Методы и средства хранения информации Педагогический проект Использование ИКТ на уроках русского языка и литературы
Педагогический проект Использование ИКТ на уроках русского языка и литературы The Language of Newspapers
The Language of Newspapers Теория автоматов и формальных языков. Структурный синтез. Триггеры
Теория автоматов и формальных языков. Структурный синтез. Триггеры Основы программирования на VBA
Основы программирования на VBA Программное обеспечение ПК
Программное обеспечение ПК План построения научной работы
План построения научной работы Новые информационные технологии. Понятие информационной технологии как составной части информатики
Новые информационные технологии. Понятие информационной технологии как составной части информатики Информация вокруг нас. (5 класс)
Информация вокруг нас. (5 класс) Java database connectivity (JDBC)
Java database connectivity (JDBC) Malicious Software. Chapter 6. Computer Security: Principles and Practice
Malicious Software. Chapter 6. Computer Security: Principles and Practice Верстка web-страниц
Верстка web-страниц Компьютерная графика
Компьютерная графика Nvidia Shadow Play
Nvidia Shadow Play Задачи
Задачи Дискретное представление информации
Дискретное представление информации Система счисления в ПК
Система счисления в ПК NP-складність і NP-повнота. Приклади наближених алгоритмів для NP-повних задач. Лекція 4
NP-складність і NP-повнота. Приклади наближених алгоритмів для NP-повних задач. Лекція 4 Массивы
Массивы Анализ отраслевого рынка – Игровая индустрия
Анализ отраслевого рынка – Игровая индустрия