- Среда программирования OpenMP. Синхронизация. (Лекция 2)

Содержание
- 2. 1. Синхронизация в среде OpenMP
- 3. 2. Пример использования директивы atomic #include #include int main(int argc, char *argv[]) { int count =
- 4. 3. Критические секции
- 5. 4. Пример использования директивы critical #include #include int main(int argc, char *argv[]) { int n; #pragma
- 6. 5. Распределение вычислений между потоками
- 7. 6. Директива master
- 8. 7. Пример использования директивы master #include int main(int argc, char *argv[]) { int n; #pragma omp
- 9. 8. Директива single Если в параллельной области какой-либо участок кода должен быть выполнен лишь один раз,
- 10. 9. Пример использования директивы single #include int main(int argc, char *argv[]) { #pragma omp parallel {
- 11. 10. Информационные зависимости
- 12. 11. Примеры информационной зависимости
- 13. 12. Информационная зависимость итераций
- 14. 13. Пример информационной зависимости итераций
- 15. 14. Разбиение на независимые блоки. Директива section
- 16. 15. Пример применения директивы sections #include #include int main(int argc, char *argv[]) { int n; #pragma
- 17. 16. Параллельные циклы
- 18. 17. Требования к оператору цикла for([целочисленный тип] i = инвариант цикла; i { ,=, =} инвариант
- 19. 18. Возможные опции: private(список) , firstprivate(список) , lastprivate(список) ; reduction(оператор:список) – задаёт оператор и список общих
- 20. 19. Использование директивы for
- 21. 20. Устранение зависимости по данным
- 22. 21. Использование опции reduction
- 24. Скачать презентацию

1. Синхронизация в среде OpenMP
1. Синхронизация в среде OpenMP

2. Пример использования директивы atomic
#include
#include
int main(int argc, char *argv[])
{
int
2. Пример использования директивы atomic
#include
#include
int main(int argc, char *argv[])
{
int

3. Критические секции
3. Критические секции

4. Пример использования директивы critical
#include
#include
int main(int argc, char
4. Пример использования директивы critical
#include
#include
int main(int argc, char

5. Распределение вычислений между потоками
5. Распределение вычислений между потоками

6. Директива master
6. Директива master

7. Пример использования директивы master
#include
int main(int argc, char *argv[])
{ int
7. Пример использования директивы master
#include
int main(int argc, char *argv[])
{ int

8. Директива single
Если в параллельной области какой-либо участок кода должен быть
8. Директива single
Если в параллельной области какой-либо участок кода должен быть

9. Пример использования директивы single
#include
int main(int argc, char *argv[])
{
#pragma omp
9. Пример использования директивы single
#include
int main(int argc, char *argv[])
{
#pragma omp

10. Информационные зависимости
10. Информационные зависимости
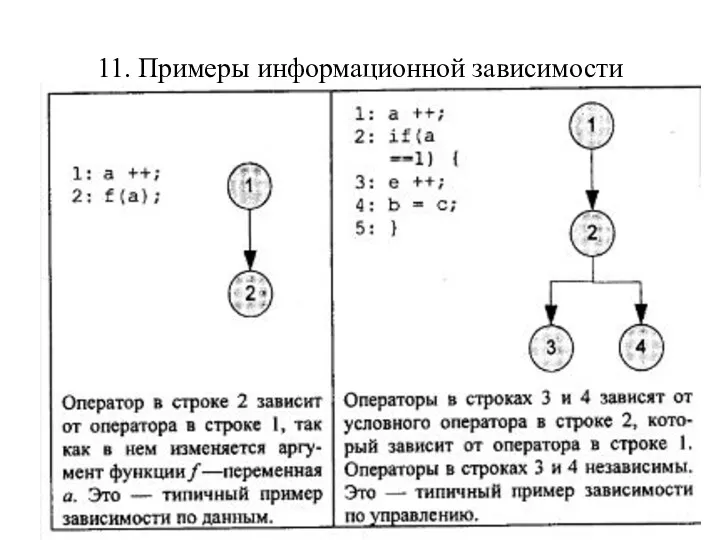
11. Примеры информационной зависимости
11. Примеры информационной зависимости

12. Информационная зависимость итераций
12. Информационная зависимость итераций
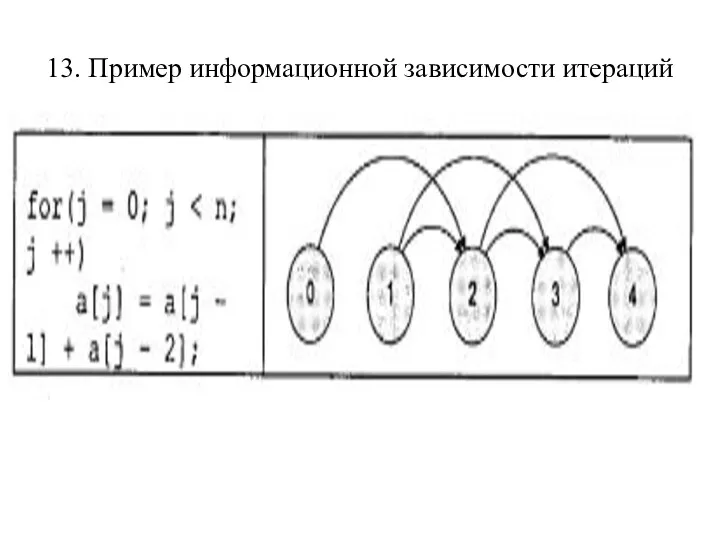
13. Пример информационной зависимости итераций
13. Пример информационной зависимости итераций

14. Разбиение на независимые блоки. Директива section
14. Разбиение на независимые блоки. Директива section

15. Пример применения директивы sections
#include
#include
int main(int argc, char *argv[])
{
15. Пример применения директивы sections
#include
#include
int main(int argc, char *argv[])
{

16. Параллельные циклы
16. Параллельные циклы
![17. Требования к оператору цикла for([целочисленный тип] i = инвариант](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/225188/slide-17.jpg)
17. Требования к оператору цикла
for([целочисленный тип] i = инвариант цикла;
i {<,>,=,<=,>=}
17. Требования к оператору цикла
for([целочисленный тип] i = инвариант цикла;
i {<,>,=,<=,>=}

18. Возможные опции:
private(список) , firstprivate(список) , lastprivate(список) ; reduction(оператор:список) – задаёт
18. Возможные опции:
private(список) , firstprivate(список) , lastprivate(список) ; reduction(оператор:список) – задаёт

19. Использование директивы for
19. Использование директивы for

20. Устранение зависимости по данным
20. Устранение зависимости по данным

21. Использование опции reduction
21. Использование опции reduction
 Введение. Системы реального времени
Введение. Системы реального времени Влияние компьютерных игр на человека
Влияние компьютерных игр на человека Формирование изображения на экране монитора
Формирование изображения на экране монитора Работа с хранилищами данных
Работа с хранилищами данных Человек и информация
Человек и информация Действия с информацией. Хранение информации
Действия с информацией. Хранение информации KNX Manufacturer Tool
KNX Manufacturer Tool Знакомство с соцсетями
Знакомство с соцсетями Использование двоичной и шестнадцатеричной систем счисления
Использование двоичной и шестнадцатеричной систем счисления Теория и методы инженерного эксперимента
Теория и методы инженерного эксперимента Теория информации. История развития систем передачи информации. Основные понятия и определения
Теория информации. История развития систем передачи информации. Основные понятия и определения Экспертные системы. Представление знаний в экспертных системах
Экспертные системы. Представление знаний в экспертных системах Реляционная модель данных. (Лекция 3)
Реляционная модель данных. (Лекция 3) Числові методи та моделювання на ЕОМ. Розв’язання системи лінійних рівнянь великої розмірності
Числові методи та моделювання на ЕОМ. Розв’язання системи лінійних рівнянь великої розмірності Классы. Лекция 8
Классы. Лекция 8 Технологии и инструменты цифровой образовательной среды (лекция 1)
Технологии и инструменты цифровой образовательной среды (лекция 1) Создание и редактирование фона. Работа с сенсорами. Создание собственного мини-проекта
Создание и редактирование фона. Работа с сенсорами. Создание собственного мини-проекта Работа с информационной системой Мониторинг оказания паллиативной медицинской помощи взрослому населению и детям
Работа с информационной системой Мониторинг оказания паллиативной медицинской помощи взрослому населению и детям 3D-панорама
3D-панорама Язык Python. Решение вычислительных задач на компьютере
Язык Python. Решение вычислительных задач на компьютере Программалық жасақтаманы таңдау
Программалық жасақтаманы таңдау Призначення. Для накопичення та аналізу значень (фінансових, кількісних) та використовується для автоматизації процесів
Призначення. Для накопичення та аналізу значень (фінансових, кількісних) та використовується для автоматизації процесів Учебная инструкция по дистанционной работе с программой Octopus
Учебная инструкция по дистанционной работе с программой Octopus Электронный документооборот в кадровой службе. Трудовая книжка
Электронный документооборот в кадровой службе. Трудовая книжка Фрагментация и персонификация контента в интернете
Фрагментация и персонификация контента в интернете Защита пользователей Windows 7
Защита пользователей Windows 7 Дизайн ЭОР (Рекомендации специалистов)
Дизайн ЭОР (Рекомендации специалистов) Защита информации и информационная безопасность при внедрении электронного документооборота
Защита информации и информационная безопасность при внедрении электронного документооборота