Свойства информации. Измерение информации. Кодирование информации. Помехоустойчивое кодирование. Код хемминга. (Лекция 2) презентация
- Свойства информации. Измерение информации. Кодирование информации. Помехоустойчивое кодирование. Код хемминга. (Лекция 2)

Содержание
- 2. Базовые понятия: точка, прямая, плоскость в геометрии, информация в информатике. Определение базовых понятий невозможно выразить через
- 3. ИНФОРМАЦИЯ Философский подход. «Информация» –взаимодействие, отражение, познание. Кибернетический подход. «Информация» соотносится – с процессами управления в
- 4. ИНФОРМАЦИЯ В информатике (традиционный подход) информация – это сведения, знания, сообщения о положении дел, которые человек
- 5. По способам восприятия: визуальная, аудиальная, тактильная, обонятельная, вкусовая. По формам представления: текстовая, числовая, графическая, музыкальная, комбинированная
- 6. СВОЙСТВА ИНФОРМАЦИИ Объективность – не зависит от чьего-либо мнения. Достоверность – отражает истинное положение дел. Полнота
- 7. СВОЙСТВА ИНФОРМАЦИИ Атрибутивные свойства: дискретность (информация состоит из отдельных частей, знаков) и непрерывность (возможность накапливать информацию).
- 8. Под информацией в кибернетике понимается любая совокупность сигналов, которую некоторая система воспринимает, хранит и выдает в
- 9. Все находится в движении, в колебательном состоянии. Колебания проявляются в виде многообразия сигналов. Человек воспринимает лишь
- 10. Тезаурус - совокупность образов объектов и событий сформированных органами чувств и отраженных на основе принятой человеком
- 11. Восприятие информации из сообщения зависит от объема тезауруса приемника. Если соответствующие понятия отсутствуют в тезаурусе, человек
- 12. Запоминание. Информация «понятная» приемнику, отобранная им, запоминается. «Запоминание характеризуется как «перекодирование» сигнала из алфавита процессов, протекающих
- 13. Сигнал - это изменяющийся во времени физический процесс. Та из характеристик, которая используется для представления сообщений,
- 14. Пример квантования и оцифровки
- 16. ИЗМЕРЕНИЕ ИНФОРМАЦИИ Вероятностный подход Алфавитный подход ИНФОРМАЦИЯ Подходы к измерению информации по отношению к человеку по
- 17. Единицы измерения информации ГОСТ 8.417-2002 : 1 Кбайт = 210 байт, 1 Мбайт= 210 Кбайт, 1
- 18. Единицы измерения информации Международная некоммерческая организация по стандартизации в области электрических, электронных и смежных технологий (МЭК)
- 19. Объёмный подход, при p(a1)= p(a2)=…= p(aN): h=log2N Вероятностный подход, с учетом частоты p(ai) появления ai в
- 20. Энтропия источника сообщений – среднее количество информации на один символ источника с учётом частоты его появления
- 21. КОДИРОВАНИЕ ИНФОРМАЦИИ. Равномерный код Равномерный код. Все кодовые комбинации содержат одинаковое количество символов. Длина равномерного кода:
- 22. Неравномерные коды. Код Шеннона-Фано КОДИРОВАНИЕ ИНФОРМАЦИИ 3. По тому же принципу каждая из полученных групп снова
- 23. Неравномерные коды. Код Шеннона-Фано Сообщение: ОТ_ТОПОТА_ТОПОТА_РОПОТА КОДИРОВАНИЕ ИНФОРМАЦИИ. Неравномерные коды
- 24. Неравномерные коды. Код Хаффмана Кодирование информации Этап сжатия. Каждый символ исходного алфавита приписывается оконечному узлу кодового
- 25. Неравномерные коды. Код Хаффмана Сообщение: ОТ_ТОПОТА_ТОПОТА_РОПОТА Кодирование информации
- 26. Условие Фано (декодируемости неравномерного кода): в префиксном коде ни одно кодовое не является началом другого кодового
- 27. Неравномерные коды. Средняя длина кодового слова Для неравномерного бинарного кода средняя длина кодового слова рассчитывается по
- 28. Теорема кодирования Шеннона *) Для любого источника сообщений и для любого способа кодирования справедливо неравенство: H
- 29. Относительная избыточность кода определяет количество избыточных знаков (нулей или единиц) на каждые 100 знаков передаваемой цепочки
- 30. 94НН03 С006Щ3НN3 П0К4ЗЫ8437, К4КN3 У9N8N73ЛЬНЫ3 83ЩN М0Ж37 93Л47Ь Н4Ш Р4ЗУМ! 8П3Ч47ЛЯЮЩN3 83ЩN! СН4Ч4Л4 Э70 6ЫЛ0 7РУ9Н0,
- 31. Классическая схема передачи информации (по К.Э.Шеннону) 1100110011001100 1100110011001100 1110110011001100 Помехоустойчивое кодирование Самоконтролирующиеся и самокорректирующиеся коды 1110110011001100
- 32. Самоконтролирующийся код – код, позволяющий автоматически обнаруживать наиболее вероятные ошибки. Самокорректирующийся код - код, позволяющий автоматически
- 33. Помехоустойчивое кодирование Самоконтролирующиеся коды Код с битом контроля чётности 1 0 0 1 1 1 0
- 34. Примеры: Кодируемое (исходное) слово -10111101 Оно содержит 6 единиц, бит чётности для него равен 1. Слово
- 35. 2. Код с контрольной суммой 4. Сложить числа, полученные в пунктах 2 и 3: 63+19=82. 5.
- 36. Алгоритм Кодирование: каждый символ исходного слова заменяется блоком из n (n-нечетное) точно таких символов. При декодировании
- 37. Определение 1. На множестве двоичных слов равной длины расстоянием Хэмминга ρ(a, b) между словами a и
- 38. Определение 2. Кодовое расстояние (d) – это минимальное значение расстояния Хемминга между двумя любыми словами алфавита
- 39. Теорема Хэмминга Для того чтобы код позволял обнаруживать ошибки в t (или менее) позициях, необходимо и
- 40. Помехоустойчивое кодирование Пример 1. A1={0000; 0111}, d(A1)=3 ⇒ код обнаруживает 2 ошибки, исправляет (локализует) одну. 1.
- 41. Помехоустойчивое кодирование Пример 2. А2={0000000000; 0000011111; 1111100000; 1111111111}, d(A2) =5 Код обнаруживает четыре одиночные ошибки, локализует
- 42. Пример 3. A3={0000; 0001; 0010; 0011; 0100; 0101; 0110; 0111; 1000; 1001; 1010; 1011; 1100; 1101;
- 43. Алгоритм построения кода Хемминга Обозначения: Hem(n,m), n , m – целые числа, n = m+r n
- 44. Для Hem(7,4) номера контрольных битов: 1, 2 и 4, остальные - информационные. Значения контрольных битов вычисляются
- 45. Помехоустойчивое кодирование Одиночная ошибка в пятом разряде принятого слова. Код Хемминга позволяет восстановить переданное слово: 1001100
- 46. Помехоустойчивое кодирование Исходное слово: 1101 Принятое слово: 1010101 Одиночных ошибок не обнаружено. Принятое слово совпадает с
- 47. 1. Семибитовое кодовое слово Хемминга с тремя проверочными символами - 1101110, номер искаженного разряда в этом
- 48. Введение в теорию алгоритмов
- 49. Введение в теорию алгоритмов Алгоритм – предписание, точный набор инструкций, описывающих порядок действий исполнителя для достижения
- 50. Свойства алгоритма 1. Дискретность – алгоритм представляет процесс решения задачи как последовательное выполнение некоторых простых шагов.
- 51. Свойства алгоритма 4. Понятность - алгоритм для исполнителя должен включать только те команды, которые ему (исполнителю)
- 52. Алгоритм всегда рассчитан на выполнение «неразмышляющим» исполнителем. Алгоритм не содержит ошибок, если он дает правильные результаты
- 53. Виды алгоритмов Механические алгоритмы - детерминированные, жесткие Гибкие алгоритмы Вероятностный (стохастический) алгоритм Эвристический алгоритм Линейный алгоритм
- 54. Разработка алгоритма решения задачи - это разбиение задачи на дискретные этапы (последовательные или параллельные), причем результаты
- 55. БЛОК-СХЕМА Типы вершин: Истина вершина слияния ориентированный граф, указывающий порядок исполнения команд алгоритма. предикатная вершина функциональная
- 56. Алгоритмические структуры http://inf1.info http://inf1.info Следование предполагает последовательное выполнение команд сверху вниз. Если алгоритм состоит только из
- 57. Алгоритмические структуры http://inf1.info http://inf1.info Ветвление Выполнение программы идет по одной из двух, нескольких или множества ветвей.
- 58. Алгоритмические структуры http://inf1.info http://inf1.info Цикл. Предполагает возможность многократного повторения определенных действий. Количество повторений зависит от условия
- 59. http://inf1.info http://inf1.info функция (подпрограмма). Команды, отделенные от основной программы, выполняются в случае их вызова из основной
- 60. http://inf1.info http://inf1.info Условие Истина Ложь Условие Истина Ложь Д1 Д1 от, до шаг Д1
- 61. Пример 1 Блок-схема алгоритма решения квадратного уравнения ТРЕНИНГ
- 62. Определить сумму положительных (Sp) и сумму отрицательных и нулевых (Sn) элементов массива а (1:5). Пример 2
- 63. Пример 3 Примем за min одно из чисел, например, min=a. Затем определяем наименьшее попарным сравнением чисел:
- 64. Пример 4 Алгоритм выполняет … а) попарную перестановку значений переменных А ⇔ В и С ⇔
- 66. Скачать презентацию

Базовые понятия:
точка, прямая, плоскость в геометрии,
информация в информатике.
Определение базовых понятий
Базовые понятия:
точка, прямая, плоскость в геометрии,
информация в информатике.
Определение базовых понятий

ИНФОРМАЦИЯ
Философский подход. «Информация» –взаимодействие, отражение, познание.
Кибернетический подход. «Информация» соотносится –
ИНФОРМАЦИЯ
Философский подход. «Информация» –взаимодействие, отражение, познание.
Кибернетический подход. «Информация» соотносится –

ИНФОРМАЦИЯ
В информатике (традиционный подход) информация – это сведения, знания, сообщения о
ИНФОРМАЦИЯ
В информатике (традиционный подход) информация – это сведения, знания, сообщения о

По способам восприятия: визуальная, аудиальная, тактильная, обонятельная, вкусовая.
По формам представления: текстовая,
По способам восприятия: визуальная, аудиальная, тактильная, обонятельная, вкусовая.
По формам представления: текстовая,

СВОЙСТВА ИНФОРМАЦИИ
Объективность – не зависит от чьего-либо мнения.
Достоверность – отражает истинное
СВОЙСТВА ИНФОРМАЦИИ
Объективность – не зависит от чьего-либо мнения.
Достоверность – отражает истинное

СВОЙСТВА ИНФОРМАЦИИ
Атрибутивные свойства: дискретность (информация состоит из отдельных частей, знаков) и
СВОЙСТВА ИНФОРМАЦИИ
Атрибутивные свойства: дискретность (информация состоит из отдельных частей, знаков) и

Под информацией в кибернетике понимается любая совокупность сигналов, которую некоторая система
Под информацией в кибернетике понимается любая совокупность сигналов, которую некоторая система

Все находится в движении, в колебательном состоянии. Колебания проявляются в виде
Все находится в движении, в колебательном состоянии. Колебания проявляются в виде

Тезаурус - совокупность образов объектов и событий сформированных органами чувств и
Тезаурус - совокупность образов объектов и событий сформированных органами чувств и
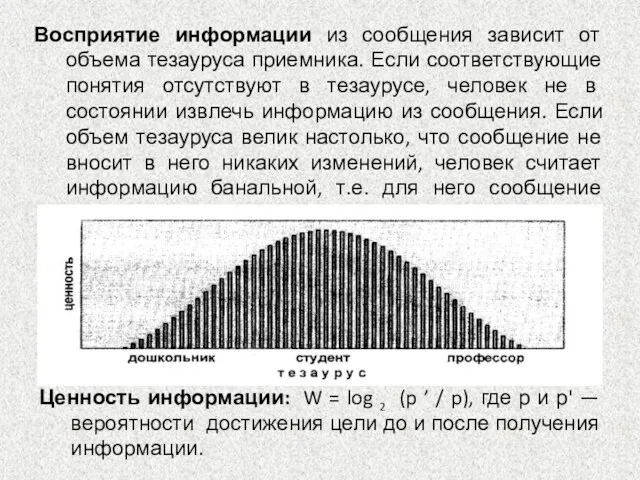
Восприятие информации из сообщения зависит от объема тезауруса приемника. Если соответствующие
Восприятие информации из сообщения зависит от объема тезауруса приемника. Если соответствующие

Запоминание. Информация «понятная» приемнику, отобранная им, запоминается. «Запоминание характеризуется как «перекодирование»
Запоминание. Информация «понятная» приемнику, отобранная им, запоминается. «Запоминание характеризуется как «перекодирование»
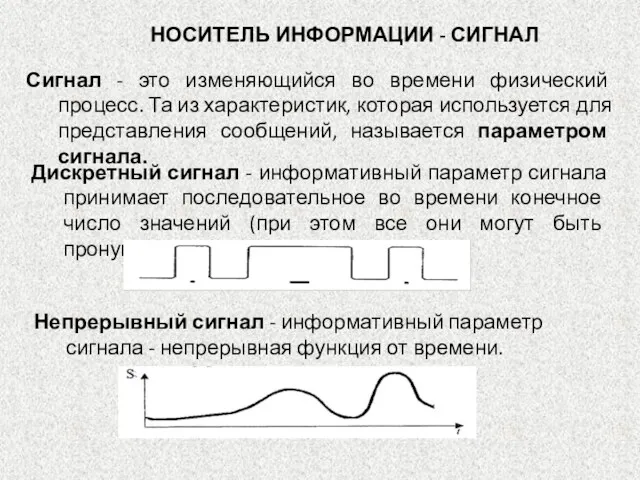
Сигнал - это изменяющийся во времени физический процесс. Та из характеристик,
Сигнал - это изменяющийся во времени физический процесс. Та из характеристик,
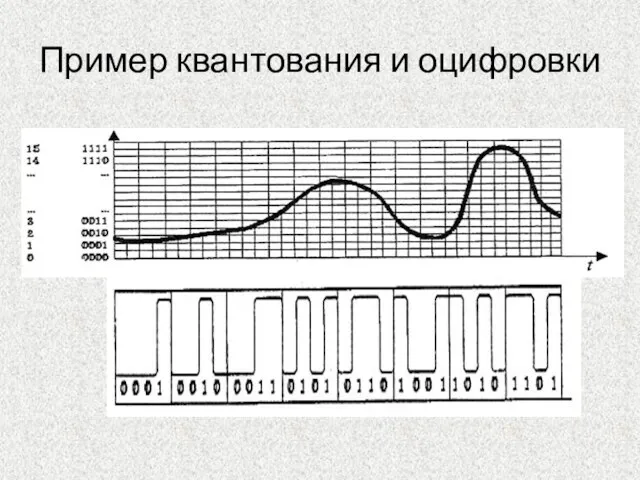
Пример квантования и оцифровки
Пример квантования и оцифровки
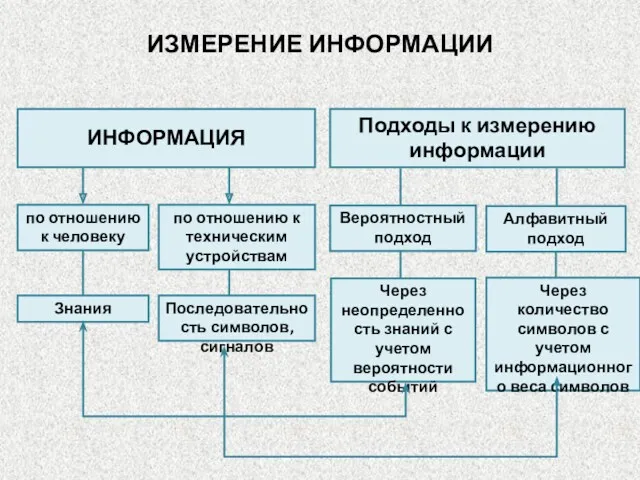
ИЗМЕРЕНИЕ ИНФОРМАЦИИ
Вероятностный подход
Алфавитный подход
ИНФОРМАЦИЯ
Подходы к измерению информации
по отношению к человеку
по отношению
ИЗМЕРЕНИЕ ИНФОРМАЦИИ
Вероятностный подход
Алфавитный подход
ИНФОРМАЦИЯ
Подходы к измерению информации
по отношению к человеку
по отношению

Единицы измерения информации
ГОСТ 8.417-2002 :
1 Кбайт = 210
Единицы измерения информации
ГОСТ 8.417-2002 :
1 Кбайт = 210
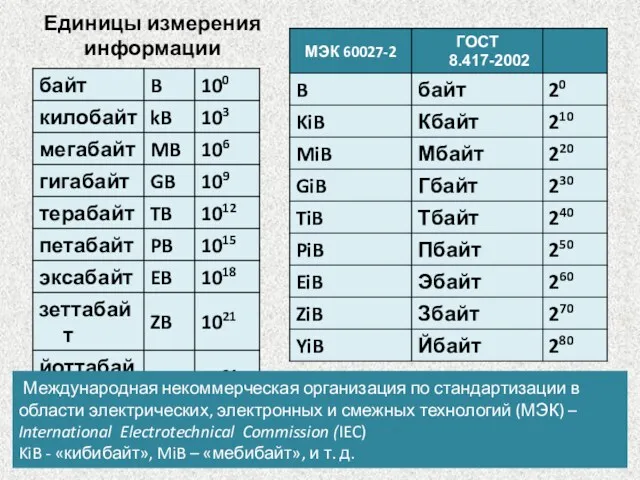
Единицы измерения информации
Международная некоммерческая организация по стандартизации в области
Единицы измерения информации
Международная некоммерческая организация по стандартизации в области

Объёмный подход, при p(a1)= p(a2)=…= p(aN):
h=log2N
Вероятностный подход, с учетом
Объёмный подход, при p(a1)= p(a2)=…= p(aN):
h=log2N
Вероятностный подход, с учетом

Энтропия источника сообщений –
среднее количество информации на один символ источника
с
Энтропия источника сообщений –
среднее количество информации на один символ источника
с

КОДИРОВАНИЕ ИНФОРМАЦИИ. Равномерный код
Равномерный код. Все кодовые комбинации содержат одинаковое количество
КОДИРОВАНИЕ ИНФОРМАЦИИ. Равномерный код
Равномерный код. Все кодовые комбинации содержат одинаковое количество

Неравномерные коды. Код Шеннона-Фано
КОДИРОВАНИЕ ИНФОРМАЦИИ
3. По тому же принципу каждая
Неравномерные коды. Код Шеннона-Фано
КОДИРОВАНИЕ ИНФОРМАЦИИ
3. По тому же принципу каждая
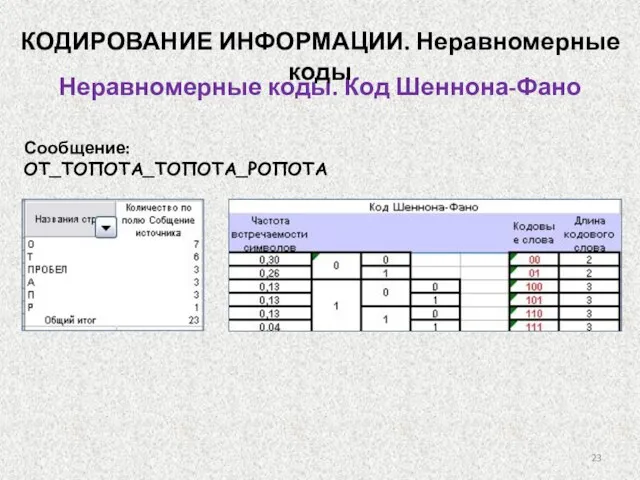
Неравномерные коды. Код Шеннона-Фано
Сообщение:
ОТ_ТОПОТА_ТОПОТА_РОПОТА
КОДИРОВАНИЕ ИНФОРМАЦИИ. Неравномерные коды
Неравномерные коды. Код Шеннона-Фано
Сообщение:
ОТ_ТОПОТА_ТОПОТА_РОПОТА
КОДИРОВАНИЕ ИНФОРМАЦИИ. Неравномерные коды

Неравномерные коды. Код Хаффмана
Кодирование информации
Этап сжатия. Каждый символ исходного алфавита
Неравномерные коды. Код Хаффмана
Кодирование информации
Этап сжатия. Каждый символ исходного алфавита
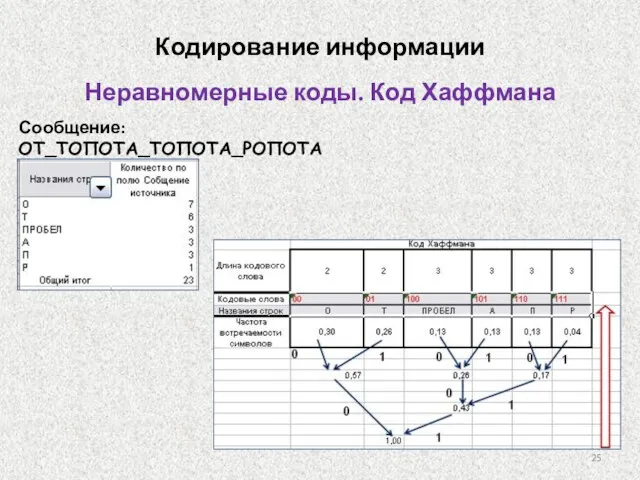
Неравномерные коды. Код Хаффмана
Сообщение:
ОТ_ТОПОТА_ТОПОТА_РОПОТА
Кодирование информации
Неравномерные коды. Код Хаффмана
Сообщение:
ОТ_ТОПОТА_ТОПОТА_РОПОТА
Кодирование информации
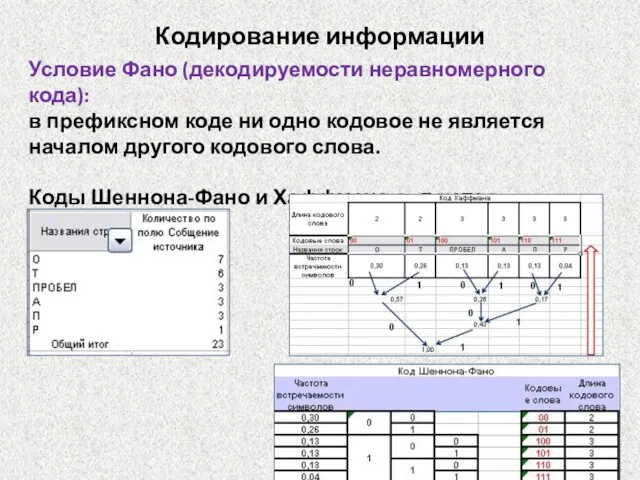
Условие Фано (декодируемости неравномерного кода):
в префиксном коде ни одно кодовое
Условие Фано (декодируемости неравномерного кода):
в префиксном коде ни одно кодовое

Неравномерные коды. Средняя длина кодового слова
Для неравномерного бинарного кода средняя
Неравномерные коды. Средняя длина кодового слова
Для неравномерного бинарного кода средняя

Теорема кодирования Шеннона *)
Для любого источника сообщений и для любого способа
Теорема кодирования Шеннона *)
Для любого источника сообщений и для любого способа

Относительная избыточность кода определяет количество избыточных знаков (нулей или единиц) на
Относительная избыточность кода определяет количество избыточных знаков (нулей или единиц) на

94НН03 С006Щ3НN3 П0К4ЗЫ8437,
К4КN3 У9N8N73ЛЬНЫ3 83ЩN М0Ж37 93Л47Ь Н4Ш Р4ЗУМ!
8П3Ч47ЛЯЮЩN3
94НН03 С006Щ3НN3 П0К4ЗЫ8437,
К4КN3 У9N8N73ЛЬНЫ3 83ЩN М0Ж37 93Л47Ь Н4Ш Р4ЗУМ!
8П3Ч47ЛЯЮЩN3
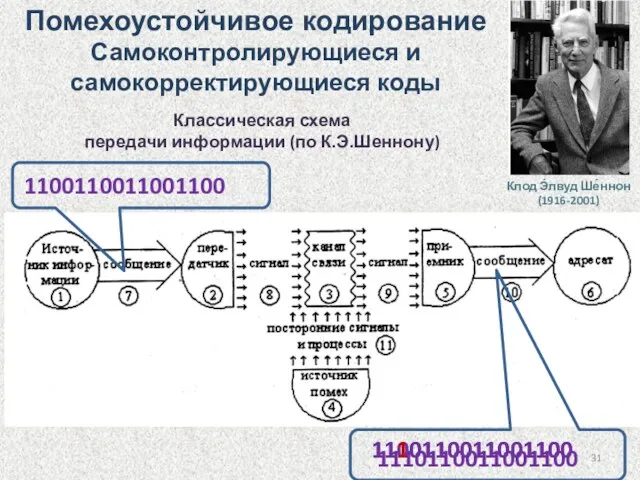
Классическая схема
передачи информации (по К.Э.Шеннону)
1100110011001100
1100110011001100
1110110011001100
Помехоустойчивое кодирование
Самоконтролирующиеся и самокорректирующиеся коды
1110110011001100
Клод
Классическая схема
передачи информации (по К.Э.Шеннону)
1100110011001100
1100110011001100
1110110011001100
Помехоустойчивое кодирование
Самоконтролирующиеся и самокорректирующиеся коды
1110110011001100
Клод

Самоконтролирующийся код – код, позволяющий автоматически обнаруживать наиболее вероятные ошибки.
Самокорректирующийся
Самокорректирующийся
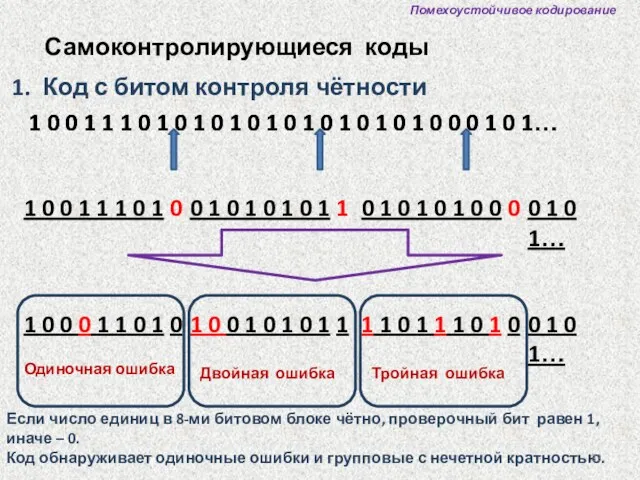
Помехоустойчивое кодирование
Самоконтролирующиеся коды
Код с битом контроля чётности
1 0 0 1 1
Помехоустойчивое кодирование
Самоконтролирующиеся коды
Код с битом контроля чётности
1 0 0 1 1

Примеры:
Кодируемое (исходное) слово -10111101
Оно содержит 6 единиц, бит чётности
Примеры:
Кодируемое (исходное) слово -10111101
Оно содержит 6 единиц, бит чётности

2. Код с контрольной суммой
4. Сложить числа, полученные в пунктах
2. Код с контрольной суммой
4. Сложить числа, полученные в пунктах

Алгоритм
Кодирование: каждый символ исходного слова заменяется блоком из n
(n-нечетное) точно
Алгоритм
Кодирование: каждый символ исходного слова заменяется блоком из n
(n-нечетное) точно

Определение 1.
На множестве двоичных слов равной длины
расстоянием Хэмминга ρ(a,
Определение 1.
На множестве двоичных слов равной длины
расстоянием Хэмминга ρ(a,

Определение 2.
Кодовое расстояние (d) – это минимальное значение расстояния Хемминга между
Определение 2.
Кодовое расстояние (d) – это минимальное значение расстояния Хемминга между

Теорема Хэмминга
Для того чтобы код позволял обнаруживать ошибки в t (или
Теорема Хэмминга
Для того чтобы код позволял обнаруживать ошибки в t (или

Помехоустойчивое кодирование
Пример 1.
A1={0000; 0111}, d(A1)=3 ⇒
код обнаруживает 2 ошибки,
Помехоустойчивое кодирование
Пример 1.
A1={0000; 0111}, d(A1)=3 ⇒
код обнаруживает 2 ошибки,

Помехоустойчивое кодирование
Пример 2.
А2={0000000000; 0000011111; 1111100000; 1111111111},
d(A2) =5
Код обнаруживает четыре
Помехоустойчивое кодирование
Пример 2.
А2={0000000000; 0000011111; 1111100000; 1111111111},
d(A2) =5
Код обнаруживает четыре

Пример 3.
A3={0000; 0001; 0010; 0011; 0100; 0101; 0110; 0111; 1000; 1001;
Пример 3.
A3={0000; 0001; 0010; 0011; 0100; 0101; 0110; 0111; 1000; 1001;
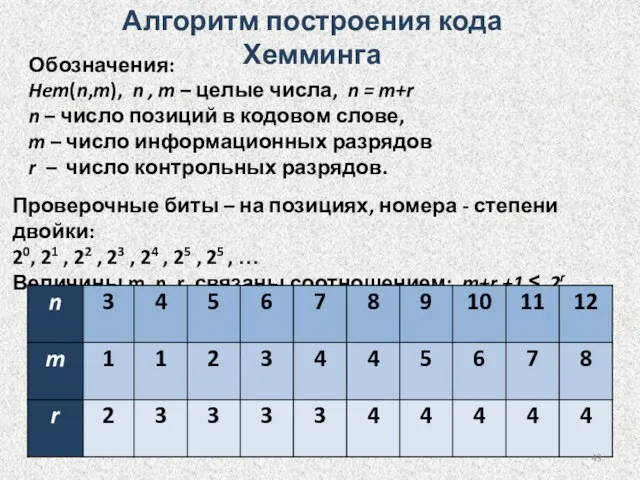
Алгоритм построения кода Хемминга
Обозначения:
Hem(n,m), n , m – целые числа,
Алгоритм построения кода Хемминга
Обозначения:
Hem(n,m), n , m – целые числа,

Для Hem(7,4) номера контрольных битов: 1, 2 и 4, остальные -
Для Hem(7,4) номера контрольных битов: 1, 2 и 4, остальные -
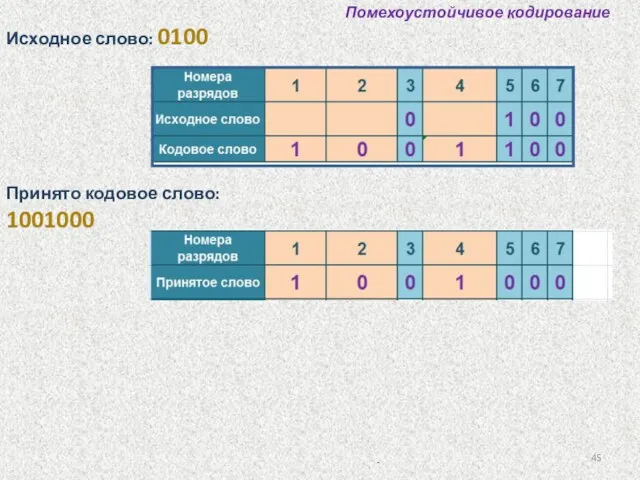
Помехоустойчивое кодирование
Одиночная ошибка в пятом разряде принятого слова.
Код Хемминга позволяет восстановить
Помехоустойчивое кодирование
Одиночная ошибка в пятом разряде принятого слова.
Код Хемминга позволяет восстановить

Помехоустойчивое кодирование
Исходное слово: 1101
Принятое слово: 1010101
Одиночных ошибок не обнаружено.
Принятое слово совпадает
Помехоустойчивое кодирование
Исходное слово: 1101
Принятое слово: 1010101
Одиночных ошибок не обнаружено.
Принятое слово совпадает

1. Семибитовое кодовое слово Хемминга с тремя проверочными символами - 1101110,
1. Семибитовое кодовое слово Хемминга с тремя проверочными символами - 1101110,

Введение в теорию алгоритмов
Введение в теорию алгоритмов

Введение в теорию алгоритмов
Алгоритм – предписание, точный набор инструкций, описывающих порядок
Введение в теорию алгоритмов
Алгоритм – предписание, точный набор инструкций, описывающих порядок

Свойства алгоритма
1. Дискретность – алгоритм представляет процесс решения задачи как последовательное
Свойства алгоритма
1. Дискретность – алгоритм представляет процесс решения задачи как последовательное

Свойства алгоритма
4. Понятность - алгоритм для исполнителя должен включать только те
Свойства алгоритма
4. Понятность - алгоритм для исполнителя должен включать только те

Алгоритм всегда рассчитан на выполнение «неразмышляющим» исполнителем.
Алгоритм не содержит
Алгоритм всегда рассчитан на выполнение «неразмышляющим» исполнителем.
Алгоритм не содержит

Виды алгоритмов
Механические алгоритмы - детерминированные, жесткие
Гибкие алгоритмы
Вероятностный (стохастический) алгоритм
Эвристический алгоритм
Линейный алгоритм
Разветвляющийся
Виды алгоритмов
Механические алгоритмы - детерминированные, жесткие
Гибкие алгоритмы
Вероятностный (стохастический) алгоритм
Эвристический алгоритм
Линейный алгоритм
Разветвляющийся

Разработка алгоритма решения задачи - это разбиение задачи на дискретные этапы
Разработка алгоритма решения задачи - это разбиение задачи на дискретные этапы
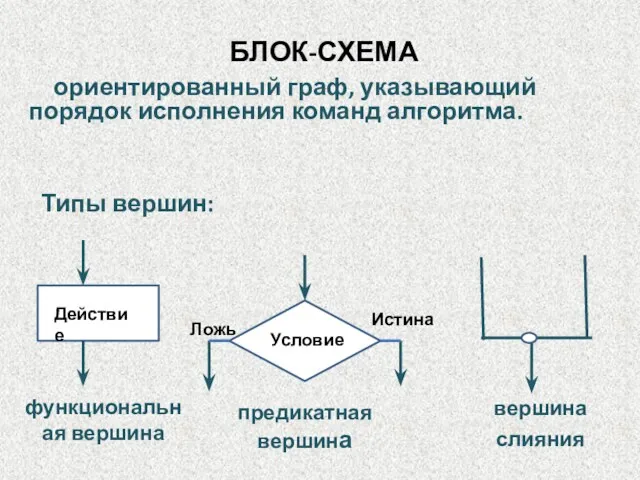
БЛОК-СХЕМА
Типы вершин:
Истина
вершина
слияния
ориентированный граф, указывающий порядок исполнения команд алгоритма.
предикатная
БЛОК-СХЕМА
Типы вершин:
Истина
вершина
слияния
ориентированный граф, указывающий порядок исполнения команд алгоритма.
предикатная
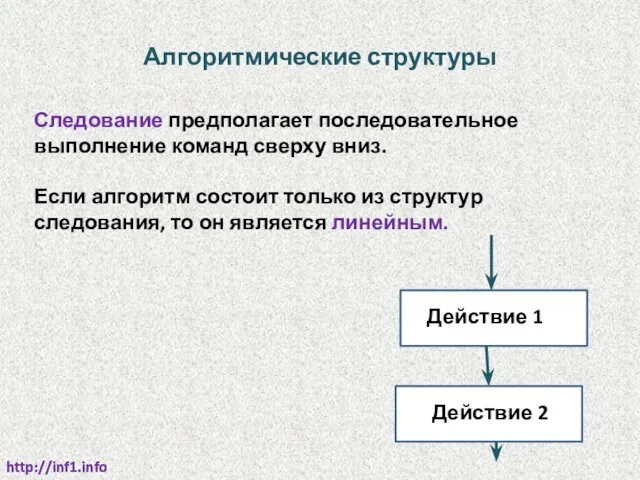
Алгоритмические структуры
http://inf1.info
http://inf1.info
Следование предполагает последовательное выполнение команд сверху вниз.
Если алгоритм
Алгоритмические структуры
http://inf1.info
http://inf1.info
Следование предполагает последовательное выполнение команд сверху вниз.
Если алгоритм
Алгоритмические структуры
http://inf1.info
http://inf1.info
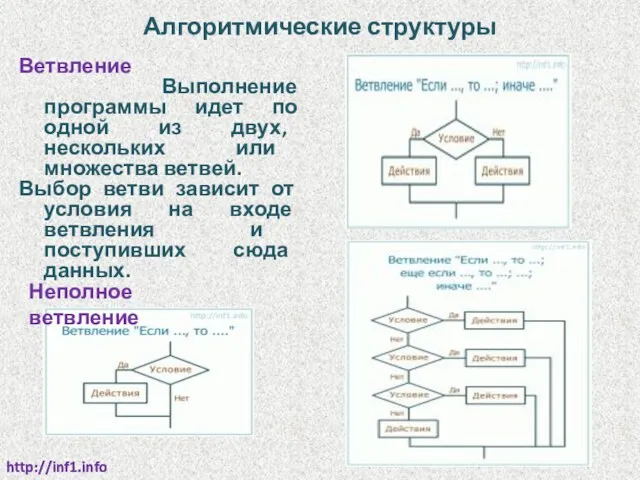
Ветвление
Выполнение программы идет по одной из двух, нескольких
Алгоритмические структуры
http://inf1.info
http://inf1.info
Ветвление
Выполнение программы идет по одной из двух, нескольких
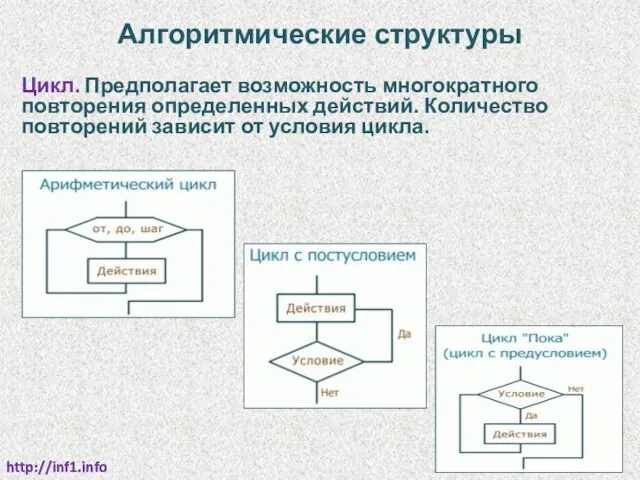
Алгоритмические структуры
http://inf1.info
http://inf1.info
Цикл. Предполагает возможность многократного повторения определенных действий. Количество повторений
Алгоритмические структуры
http://inf1.info
http://inf1.info
Цикл. Предполагает возможность многократного повторения определенных действий. Количество повторений

http://inf1.info
http://inf1.info
функция (подпрограмма). Команды, отделенные от основной программы, выполняются в случае их
http://inf1.info
http://inf1.info
функция (подпрограмма). Команды, отделенные от основной программы, выполняются в случае их
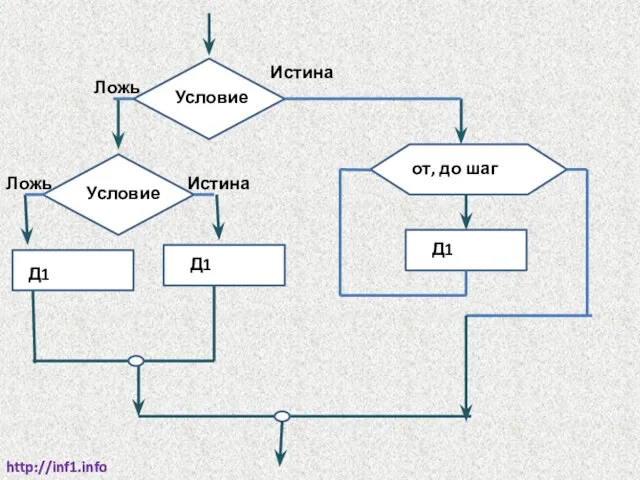
http://inf1.info
http://inf1.info
Условие
Истина
Ложь
Условие
Истина
Ложь
Д1
Д1
от, до шаг
Д1
http://inf1.info
http://inf1.info
Условие
Истина
Ложь
Условие
Истина
Ложь
Д1
Д1
от, до шаг
Д1
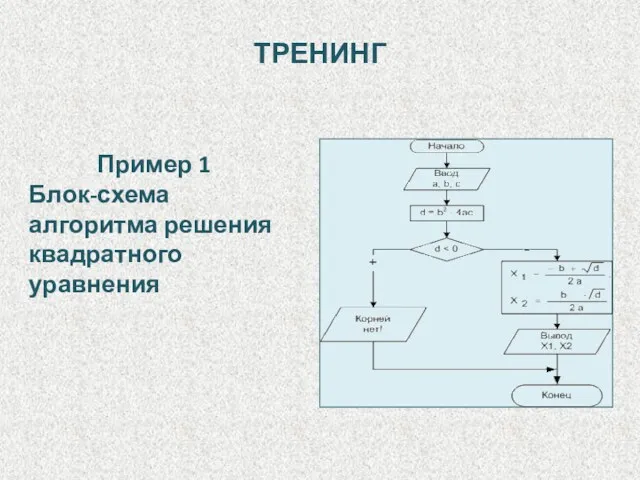
Пример 1
Блок-схема алгоритма решения квадратного уравнения
ТРЕНИНГ
Пример 1
Блок-схема алгоритма решения квадратного уравнения
ТРЕНИНГ

Определить сумму положительных (Sp)
и сумму отрицательных и нулевых (Sn)
элементов массива
Определить сумму положительных (Sp)
и сумму отрицательных и нулевых (Sn)
элементов массива
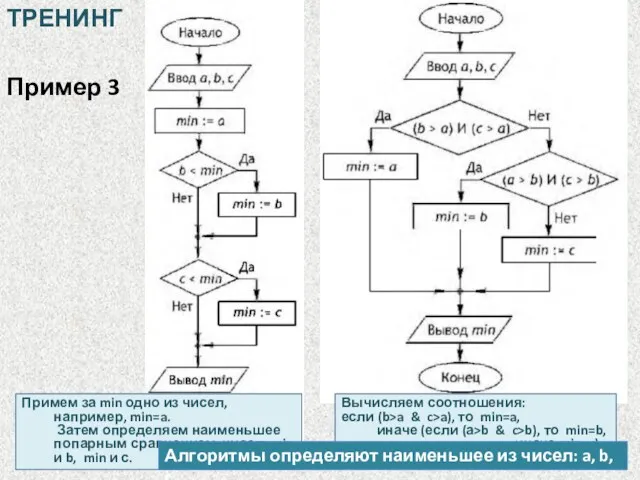
Пример 3
Примем за min одно из чисел, например, min=a.
Затем определяем
Пример 3
Примем за min одно из чисел, например, min=a. Затем определяем

Пример 4
Алгоритм выполняет …
а) попарную перестановку значений переменных
А ⇔ В
Пример 4
Алгоритм выполняет …
а) попарную перестановку значений переменных
А ⇔ В
 Компьютерные сети. Виды сетей, интернет
Компьютерные сети. Виды сетей, интернет Безопасность в сети Интернет
Безопасность в сети Интернет Презентация к уроку Линейные алгоритмы 9 класс
Презентация к уроку Линейные алгоритмы 9 класс Microsoft Office Access 2010
Microsoft Office Access 2010 Информация как объект защиты. Методы защиты информации. Правовые аспекты (лекция 12)
Информация как объект защиты. Методы защиты информации. Правовые аспекты (лекция 12) Windows 10
Windows 10 Адресация в сети. Маршрутизация
Адресация в сети. Маршрутизация Компьютерлік вирустар. Архиваторлар
Компьютерлік вирустар. Архиваторлар Нейронные сети. Возможности применения и перспективы развития
Нейронные сети. Возможности применения и перспективы развития JRE ортасының және Java SE платформасының салыстырмалы сипаттамасын орындау. Зертханалык жумыс
JRE ортасының және Java SE платформасының салыстырмалы сипаттамасын орындау. Зертханалык жумыс Робота у локальній мережі
Робота у локальній мережі Программирование на Basic
Программирование на Basic Облачные технологии в управлении проектами
Облачные технологии в управлении проектами Вычислительные машины, системы и сети. Лекция 8. Тема 11. Выбор конфигурации компьютера
Вычислительные машины, системы и сети. Лекция 8. Тема 11. Выбор конфигурации компьютера Основные понятия и определения информатики
Основные понятия и определения информатики Презентация
Презентация Газета Известия
Газета Известия Формы php
Формы php Алгоритмизация и программирование
Алгоритмизация и программирование Стеки и очереди
Стеки и очереди Этапы подготовки задачи к компьютерной обработке. 1 урок - Математическая модель, алгоритм
Этапы подготовки задачи к компьютерной обработке. 1 урок - Математическая модель, алгоритм Simulia - solutions for turbomachinery
Simulia - solutions for turbomachinery Всемирная сеть Интернет
Всемирная сеть Интернет Что такое текстовый редактор?
Что такое текстовый редактор? Влияние машинной архитектуры.Структура и принципы работы компьютера
Влияние машинной архитектуры.Структура и принципы работы компьютера Лекция 4. Устойчивость
Лекция 4. Устойчивость Информационные технологии. Лекция 1. Введение
Информационные технологии. Лекция 1. Введение Propositional logic
Propositional logic